基于t分布變異的改進麻雀搜索算法*
2022-09-05 12:24:08吳超略韋文山鄔貴昌
網絡安全與數據管理 2022年8期
關鍵詞:優化
吳超略,韋文山,郭 羿,鄔貴昌
(廣西民族大學 電子信息學院,廣西 南寧 530006)
0 引言
群智能優化算法是一種仿生算法,旨在模擬自然界中某些生物的行為或某些物理現象,因其尋優能力強、操作簡單等特點,被許多科研人員研究。常見的群智能優化算法有:粒子群優化算法(Particle Swarm Optimization,PSO)[1]、螢火蟲算法(Firefly Algorithm,FA)[2]、灰狼 優 化算 法 (Grey Wolf Optimizer,GWO)[3]、烏鴉搜索算法(Crow Search Algorithm,CSA)[4]和飛蛾火焰優化算法(Moth-Flame Optimization,MFO)[5]。受自然界中麻雀種群覓食行為的啟發,薛建凱[6]等人于2020年提出了麻雀搜索算法(Sparrow Search Algorithm,SSA)。相比之下,該算法擁有更優的收斂率、更高的精度和易于實現等特點。但是,在算法運行的末期,SSA算法也不能避免收斂速度下降、易陷入局部最優的問題。
為了改善麻雀搜索算法跳出局部最優難的問題,加強算法運行效率,許多學者提出了有效的改進策略:呂鑫等[7]通過Tent混沌序列初始化麻雀種群,同時引入高斯變異和Tent混沌擾動對個體進行變異和擾動,使算法不易陷入局部最優點;柳長安等[8]融合反向學習策略和自適應t分布變異,引入精英粒子,擴大了算法搜索范圍,增強算法后期局部搜索能力;付華等[9]在加入者位置更新時加入雞群算法的隨機跟隨策略,保證多樣性的同時又提高了搜索性能;Zhang等[10]利用Logistic混沌映射對種群位置進行初始化提高初始解的質量,為了加快SSA算法的收斂速度和效率,采用兩個自適應參數更新發現者位置和預警麻雀數量。
以上改進措施雖然能在一定程度上提高算法跳出局部最優的能力,然而,問題仍然存在,如搜索精度不夠、收斂速度不快等。基于此,本文提出一種基于t分布變異的改進麻雀搜索算法(t-SSA),該算法在加入者位置更新后,引入自適應t分布變異,對加入者位置進行擾動變異,避免陷入局部最優,提高算法的尋優精度。通過在6個基準函數上進行仿真實驗,結果表明,與SSA算法相比,t-SSA算法具有更好的優化精度和更快的收斂速度。
1 麻雀搜索算法的基本原理
麻雀搜索算法(SSA)受自然界中麻雀捕食行為和反捕食行為影響,將麻雀種群抽象為三類:發現者、加入者和預警者。其中,發現者具有較高的適應度值,負責為麻雀種群尋找食物區域,并把相關區域和方向提供給加入者;為了得到更好的食物,提高自身適應度值,加入者會一直跟隨具有較高適應度值的發現者,不斷監視發現者進而爭奪食物;當預警者發現捕食者后會立即向種群中的麻雀發出警報,此時處于種群邊沿的個體會快速地朝安全區域飛去,即反捕食行為。此外,在SSA算法中,麻雀種群的發現者和加入者的身份并不是一成不變的,假如能尋覓到更優的食物區域,每只麻雀都能是發現者,不過二者在種群總數量中的比重是固定的。
在SSA算法中,麻雀種群的表示形式為:

其中,n為麻雀的數量;d為待優化變量的維度。可用下述形式來代表麻雀種群的適應度值:

其中,f(Xn)為麻雀個體的適應度值。
對于發現者,用下式表示其位置變化:
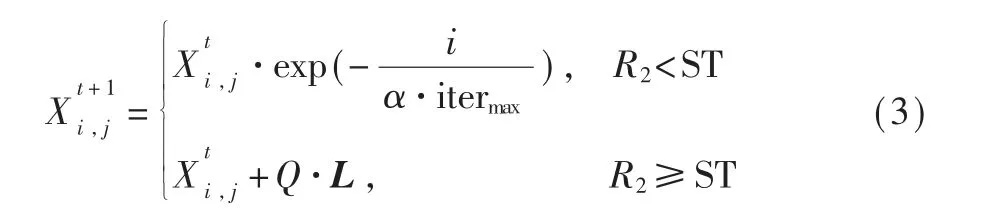
對于加入者,其位置更新公式如下:

對于預警者,數量通常占麻雀種群數量的10%~20%,且位置隨機確定,其位置更新公式如下:

2 改進的麻雀搜索算法(t-SSA)
2.1 t分布變異
t分布又稱學生t分布(Student′s t-Distribution),它的概率密度函數曲線與其自由度n有關,n的值越大,其曲線中間越高。當n=1時,有t(n=1)→C(0,1);當n=∞時,有t(n=∞)→N(0,1)。其中,C(0,1)為柯西分布,N(0,1)為高斯分布。即柯西分布和高斯分布為t分布自由度n分別為1和∞時的兩個特例。t分布的函數分布如圖1所示。

圖1 t分布函數分布圖
t分布既有柯西分布的特點,也有高斯分布的特點,本文將t分布的自由度參數用算法迭代次數代替,使t分布在算法迭代初期趨近于柯西分布,此時算法的全局尋優能力得到提升;隨著迭代次數的增加,t分布又趨近于高斯分布,提高了算法的局部搜索水平,進而提高算法的尋優精度。
本文利用當前迭代次數中發現者所能搜索到的最優位置,結合t分布變異對發現者的位置進行擾動,其公式如下:
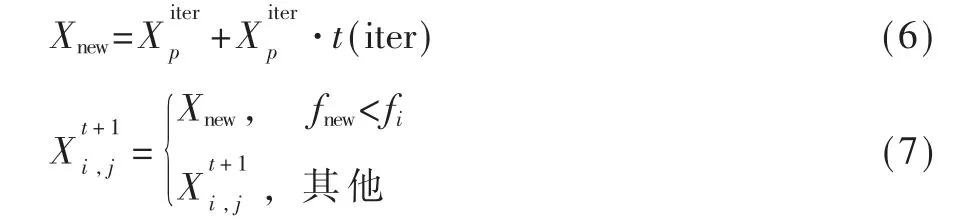
其中,Xnew表示經t分布變異擾動后的新位置;表示當前發現者所搜索到的最優位置;t(iter)表示以當前迭代次數iter為自由度的t分布;表示當前由式(4)計算得到的第i個加入者位置;fnew表示新位置的適應度值,fi表示第i個加入者的適應度值。當fnew<fi時,表示經過t分布變異擾動之后得到的新位置優于當前加入者位置,并把該位置更新給加入者。
2.2 改進的麻雀搜索算法流程
本文提出的基于t分布變異的改進麻雀搜索算法(t-SSA)步驟如下:
(1)進行初始化,并設置參數,如種群數量n、發現者數量PD、預警者數量SD、最大迭代次數itermax、安全值ST等。
(2)計算麻雀個體適應度值,記錄當前全局最優值和最劣值,及其對應位置。
(3)根據設置好的發現者數量PD,挑選適應度值較好的麻雀數量當作發現者,并按照式(3)更新發現者位置。
(4)剩余的麻雀為加入者,按照式(4)更新加入者位置。
(5)應用式(6)計算出t分布變異擾動后的新位置,并按照式(7)對加入者位置進行相應的替換。
(6)根據設置好的預警者數量SD,隨機選取部分麻雀作為預警者,并按照式(5)更新預警者位置。
(7)更新麻雀種群個體最優位置和全局最優位置。
(8)判斷當前迭代次數是否滿足算法最大迭代次數,若是,則循環結束,輸出結果;否則返回步驟(2)。
3 仿真實驗與結果分析
為驗證本文所提出的t-SSA算法的可行性和尋優能力,本文基于Intel?CoreTMi5-7200U CPU@2.50 GHz,8 GB內存,Windows 10操作系統和仿真軟件MATLAB R2019b進行仿真實驗。
3.1 對比實驗設計和參數設置
本文將t-SSA算法與3種基本算法:灰狼優化算法(GWO)[3]、飛蛾火焰優化算法(MFO)[5]和麻雀搜索算法(SSA)[6],分別測試6個基準函數(其中f1~f3為單峰函數,f4~f6為多峰函數),進行對比。 為確保實驗的公平性,將全部算法統一設置種群數量100,迭代次數200,其余算法參數見表1。6個基準測試函數具體信息見表2。選取各算法在基準測試函數獨立運行30次的結果的平均值和標準差作為實驗結果,具體實驗結果如表3所示,基準測試函數收斂情況如圖2所示。

表1 算法參數設置

表2 基準函數信息
3.2 實驗結果分析
從表3和圖2能看出,在測試單峰函數f1~f3時,t-SSA算法均取得了其理論最優值,且具有更快收斂速度和更強的魯棒性。在測試多峰函數f4~f6時,對于f4,t-SSA雖然收斂精度稍差于MFO,但與其余算法相比,其在前期的收斂速度較快;對于f5,t-SSA和SSA收斂結果相同,并且比GWO、MFO優,但從圖2可以看出,t-SSA收斂速度明顯更快;對于f6,t-SSA具有較好的尋優精度和較強的魯棒性。
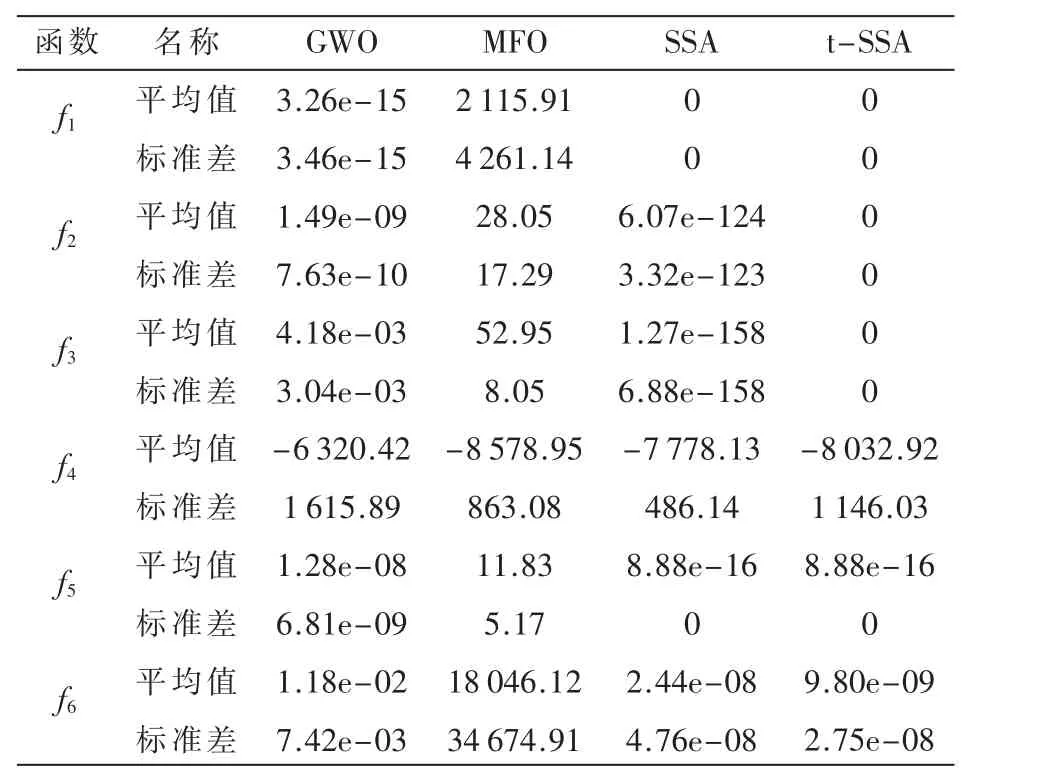
表3 算法優化結果對比
綜合來看,本文所提出的t-SSA算法較其他算法在收斂精度、收斂速度和魯棒性方面都有很大的提升,這表明本文所提出的改進策略是有效的,既提高了算法的尋優精度,又降低了算法陷入局部最優的概率,且擁有更好的性能。
3.3 Wilcoxon秩和檢驗
為進一步評估t-SSA算法的優化性能,仍需要對算法進行統計檢驗。因此,本文選擇Wilcoxon秩和檢驗驗證t-SSA算法每輪的優化結果是否與所對比算法存在明顯區別。用P表示檢驗結果,當P<5%時,說明兩種算法之間存在顯著差異;當P>5%時,說明兩種算法之間差距不明顯,性能相當。在本文3.1節同樣的實驗條件下,t-SSA分別與GWO、MFO、SSA的詳細檢驗結果P如表4所示,其中NaN代表兩個對比算法性能接近,無法比較。
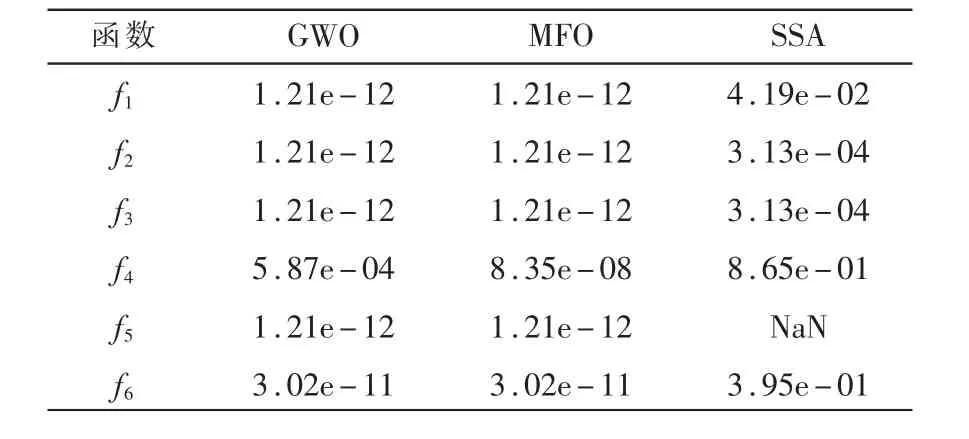
表4 Wilcoxon秩和檢驗結果
由表4可知,除t-SSA與SSA的f4、f6,其余大部分的P值都小于5%,這說明t-SSA算法與其他算法在統計上存在顯著差異。對于f5,t-SSA與SSA差異不明顯,尋優效果相當。
4 結論
為了改善麻雀搜索算法(SSA)在其運行末期出現種群多樣性下降、難以跳出局部最優等問題,本文提出一種新的改進麻雀搜索算法(t-SSA)。首先,引入自適應t分布變異,對加入者位置進行擾動變異,防止跳不出局部最優點,增強算法性能。然后,通過在6個基準函數上進行仿真實驗,結果證明本文提出的t-SSA的收斂精度與速度優于其他算法。綜合來看,本文所提出的改進方法是有效的,能夠明顯提升SSA算法的尋優性能,下一步將考慮將t-SSA算法應用于實際工程問題的優化中,驗證其在工程問題上的應用價值。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
