基于多視角注意力機制的專利匹配方法
2022-09-05 09:26:50殷亞玨高曉雅王晶晶李壽山徐邵洋曾雨豪
中文信息學報 2022年7期
殷亞玨,高曉雅,王晶晶,李壽山,徐邵洋,曾雨豪
(蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006)
0 引言
隨著科技不斷發展,人們對知識產權保護越來越重視。專利審核是知識產權保護的一個重要環節。審核過程中為了保證申請專利產權的唯一性,需要對申請專利進行人工審查。
專利檢索是一項具有重要意義的技術,能夠協助審查員高效完成專利審核任務,而專利匹配是專利檢索技術中的一項基本環節。如何高效快速地審核當前申請專利有無相似的已申請專利,已經受到業界的廣泛關注。同時,專利匹配屬于文檔級語義匹配任務,該任務是自然語言處理領域的基礎任務,具有廣泛的應用場景,如網頁檢索、醫療案例檢索等[1]。因此,該任務也受到學術界的廣泛關注。傳統的文檔級語義匹配任務,一部分使用TF-IDF等技術構建特征結合余弦相似性[2]的度量方法, 然而,這種技術沒有考慮到文字本身的實際語義,單純以詞頻衡量詞的重要性,顯得不夠全面。近些年來,神經網絡[3]等深度學習的方法在文檔級語義匹配任務上扮演了重要的角色。該方法能考慮句子的時序關系,并結合語義,明顯提升語義匹配任務的性能。然而,已有的神經網絡方法僅考慮計算兩個句子之間兩兩的匹配度,忽略了文檔的整體信息。例如,在表1中,專利A和專利B是審查員判斷出來的兩個相似專利。在算法實現中,如果我們僅僅使用標題信息,例如,“切片裝置”“沖孔機構”等關鍵詞來判斷兩個專利的相似度,算法可能會把兩個專利判斷為不相似專利,從而得到錯誤的結論。因此,一個更好的專利匹配方法需要能夠利用整個專利里面不同的文本信息(如標題、摘要、聲明等)。如何使用專利不同字段的多文本信息是專利匹配面臨的一項挑戰。
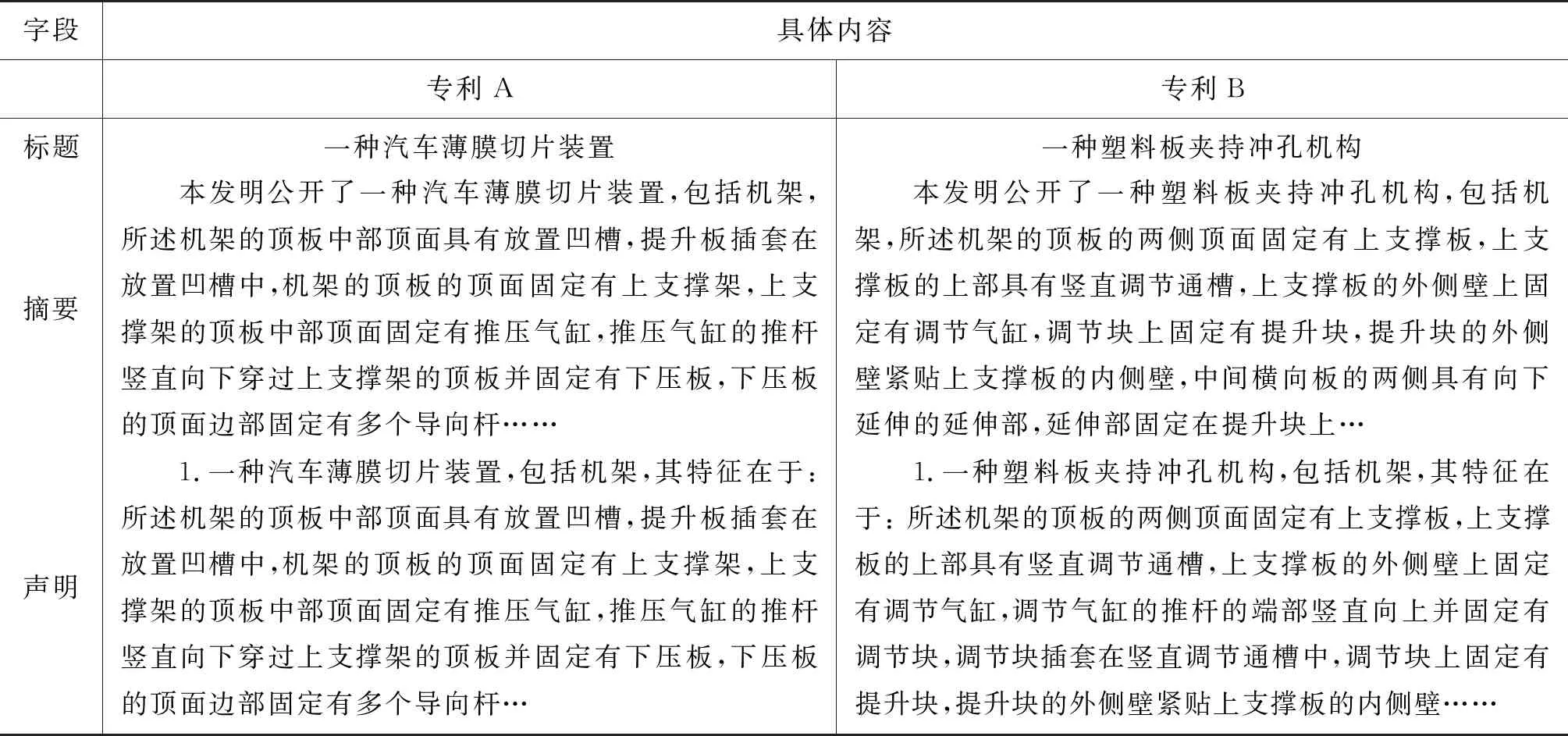
表1 專利各個關鍵字段特征的描述
此外,不同字段的文本信息對于最終的匹配具有不一樣的重要性。如圖1所示,雖然根據專利摘要和聲明信息可以判斷專利是匹配的,但是模型可能還是會傾向于關注標題信息,最終將其預測為不匹配。因此,如何在模型中充分考慮不同信息對于計算匹配的重要程度是專利匹配的面臨另一項挑戰[4]。
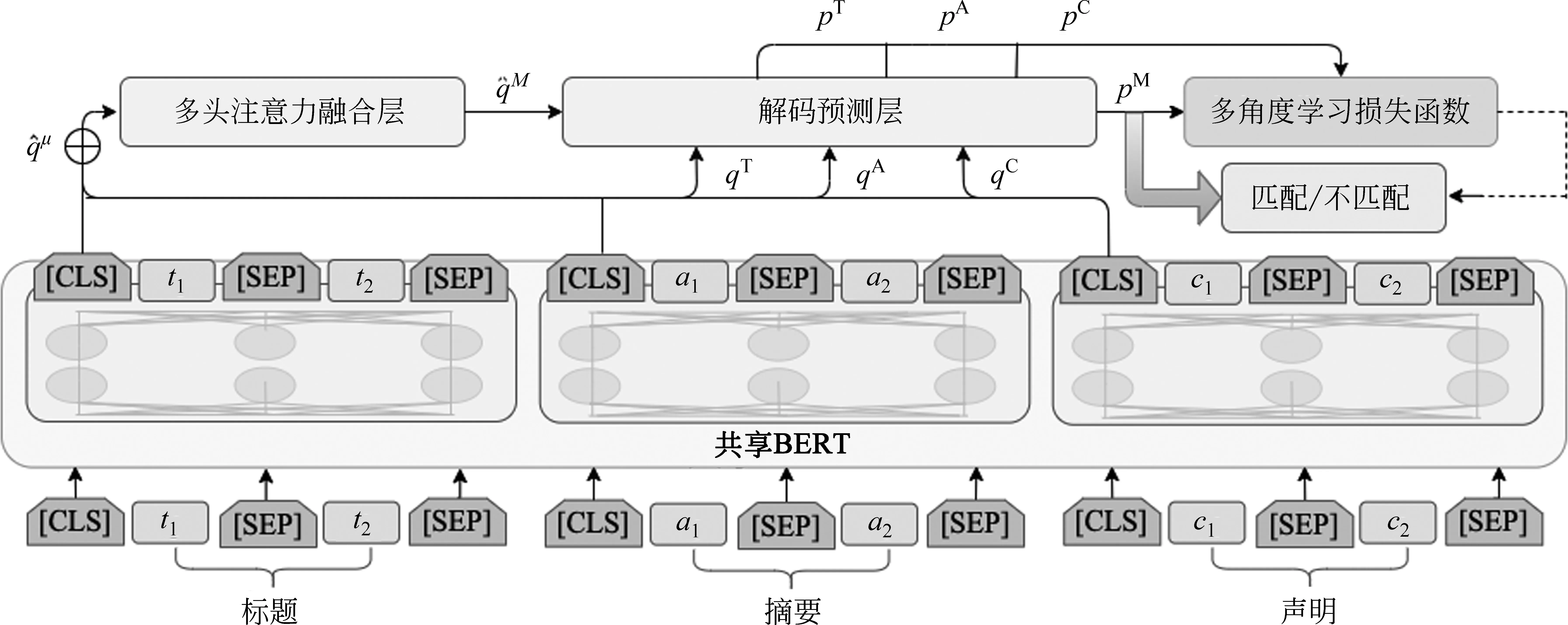
圖1 基于注意力感知的多視角學習方法框架圖
為了應對以上挑戰,本文設計了一個基于注意力感知的多視角學習模型(Multi-View Attentive Network,MVAN)。具體而言,首先,利用BERT[5]模型作為編碼層,對每個待匹配專利對各個視角的匹配特征進行提取(標題、摘要、聲明)。其次,針對如何體現不同字段文本信息的重要性的挑戰,使用多頭注意力[6]機制融合多個單視角匹配特征,從而得到多視角匹配特征。最后,針對如何使用專利不同字段的多文本信息的挑戰,本文設計了一種多視角學習機制,聯合學習單視角和多視角的匹配特征,來優化融合后的多視角匹配結果。總體而言,本文的主要貢獻為: ①首次使用深度學習方法進行專利匹配任務; ②利用多頭注意力機制融合專利不同字段信息; ③設計了一個多視角學習機制,使模型可以充分利用所有信息。
本文的組織結構為: 第1節介紹專利匹配的相關工作;第2節介紹注意力感知的多視角學習模型的具體實現方法;第3節介紹實驗結果數據并對結果進行分析;最后一節總結全文并對未來進行展望。
1 相關工作
1.1 專利匹配
專利匹配是專利檢索的重要環節,傳統的專利匹配大多基于規則模板或特征構建的方式,例如,布爾檢索[7]將文本匹配轉化成詞組間的相互匹配;BM25[8]計算查詢和文檔之間的相關性,對查詢的分詞進行語素分析,通過語素權重判定進一步獲得語素與文檔的相關性判定;向量空間模型[9]采用TF-IDF框架計算詞語權重后計算文檔和查詢的相似度作為查詢和文檔間的相關性度量;互信息[10]作為特征詞和類別之間的測度,利用互信息理論進行特征抽取,度量文本間的相互語義關系,結合統計信息的計算實現文本間的語義關系的衡量。以上特征提取方法幾乎都是基于統計學的,其中一個主要缺陷就是需要用一個很龐大的訓練集才能獲得近乎所有的對分類起關鍵作用的特征,這將使得現實應用中特征提取的效率非常低,也會直接影響整個文本匹配任務的效率。
不同于以上的所有研究,本文致力于使用深度學習方法解決匹配任務,從語義角度去學習匹配,同時本文也是應用深度學習的方法解決專利匹配任務的首次嘗試。
1.2 文檔級語義匹配
文檔級語義匹配(即專利匹配)是自然語言領域的基礎任務,一直受到廣泛的關注,有一些研究者致力于研究機器學習方法,例如,Yang利用SVM[11]算法構建分類器對樣本所屬類別進行決策分類;Adwait首次將最大熵模型應用于文本分類,并且使用了MEDEFAULT和MEIFS兩種方法對基于最大熵[12]模型和基于決策樹[13]的分類方法進行比較。這些方法均使用了局部的信息,或者僅對文本表征學習進行改進,其使用的特征對于句子層面或許是足夠的,而對于專利這種基于文檔層面的語料是很難捕獲到充足的信息的。
不同于以上的所有研究,本文提出了一個基于注意力感知[14]的多視角學習模型(Multi-View Attentive Network,MVAN),旨在使用多視角學習方法,使模型捕捉專利文本所有視角的匹配特征。
2 方法
本文提出了一個基于注意力感知的多視角學習模型MVAN。如圖1所示,MVAN模型主要由3個部分組成: ①編碼層: 利用BERT模型得到三種單視角匹配特征(標題、摘要、聲明); ②注意力感知融合層: 輸入單視角匹配特征,通過多頭注意力機制得到多視角匹配特征; ③解碼預測層: 輸入單視角特征及融合后的多視角特征,分別解碼后預測得到對應的匹配結果,最后通過多視角學習機制,利用單視角結果優化多視角結果,并將多視角優化結果視為最終的匹配結果。
2.1 多視角編碼層
由于BERT是目前自然語言處理領域中學習文本表示性能最好的模型之一,本文中,我們使用專利語料預訓練后的BERT模型(1)在實驗中,我們使用100萬條專利語料在BERT-base模型的基礎上利用預測遮蔽詞和預測下一句兩個上游任務重新預訓練。得到專利文本的單視角匹配特征表示。
具體而言,對于給定待匹配專利對的標題序列xT1、xT2,摘要序列xA1、xA2,聲明序列xC1、xC2,根據BERT中的語義匹配任務構建輸入,即在句子的開頭插入“[CLS]”標簽,句子對之間和句子末尾分別插入“[SEP]”標簽,如式(1)~式(4)所示。
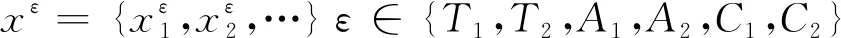
(1)
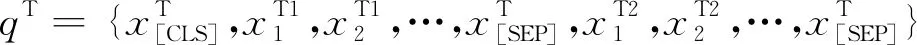
(2)
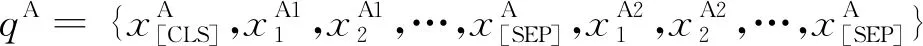
(3)
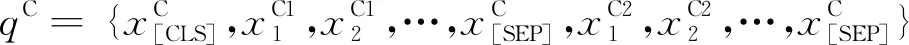
(4)
其中,qT、qA、qC分別是待匹配專利對的標題、摘要及聲明的輸入詞序列。
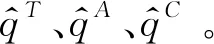
其中,μ∈{T,A,C},T表示標題,A表示摘要,C表示聲明。
2.2 注意力感知融合層

其中,stack(:)表示將三個單視角匹配特征在時間維度上做拼接操作,MA(:)為多頭注意力方法,多頭注意力機制中多頭個數H=8,權重矩陣WO∈Hd×d用于融合多頭結果。
2.3 解碼預測層
輸入單視角特征及融合后的多視角特征,各自經過線性變換后使用sigmoid函數[15]得到對應的匹配結果,如式(10)、式(11)所示。
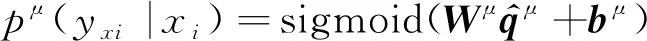
(10)
(11)
其中,yxi是專利樣本xi匹配的真實結果,Wμ∈d,WM∈d,bμ∈,bM∈是解碼層權重矩陣和偏置。在模型的預測過程中,我們僅使用多視角特征得到的匹配結果pM(yxi|xi)作為最終的結果。
2.4 訓練與優化策略
在訓練過程中,模型可能會逐漸傾向于選擇一部分特征進行學習,而利用多視角學習方法,可以幫助模型充分利用所有的特征信息[16]。因此,本文模型的目標函數由基于單視角匹配特征得到的代價函數和基于多視角匹配特征得到的代價函數組成。函數定義如式(12)、式(13)所示。
其中,LT,LA,LC是單視角匹配特征得到的代價函數,LM是多視角匹配特征得到的代價函數,權重α,β,γ,δ用來調節各視角結果的平衡。
3 實驗
本節著重介紹本文方法在專利語料數據集上的實驗結果。
3.1 實驗設置
本文中所使用的數據集是來自專利局的數據。該數據集包含了超過5 000條專利匹配的樣本,其中待匹配專利對的正負樣本數目是相同的。專利匹配的正樣本是由專利審查員通過審查給出的,專利考題和待匹配專利如果是匹配的,那么將會被專利審查員標記為一條正樣本;專利匹配的負樣本是從海量的專利語料庫中隨機抽取出的任意一條與考題不匹配的專利。每一對待匹配的專利樣本由專利的標題、摘要、權利聲明構成,最后附加上考題和待匹配專利是否匹配這一標簽。語料數據集中將專利樣本按標簽分成兩類,實驗中標簽“0”代表負樣本,標簽“1”代表正樣本。
我們首先使用BERT模型作為文本的編碼層,向量維度為768。其次,在對比實驗中,我們使用隨機向量初始化詞向量,向量維度為512。模型中所有層的權重由Glorot正則化[17]初始化,Dropout比例為0.3,Batch大小為32,其余超參根據驗證集結果調整優化。另外,我們采用學習率為0.000 02的Adam優化器優化任務中基于專利匹配的自定義損失函數,其內部用來調節各視角結果的平衡權重α,β,γ,δ分別根據對比實驗結果進行調參優化。
實驗中,我們采用準確率和F1值作為衡量專利匹配性能的評價指標。一般來說,當深度學習的模型過于復雜時,會導致其專注于解釋訓練數據,從而犧牲對未來數據的解釋能力。也是說訓練數據效果非常好,但測試數據效果大打折扣,即過擬合現象[18]。考慮到深層神經網絡因為其結構相較傳統模型有很強的表達能力,本文統計了250對、500對和2 500對匹配樣本在進行匹配任務時的準確率及F1值進行更全面的對比,表2為本文實驗的專利語料數據分布情況。
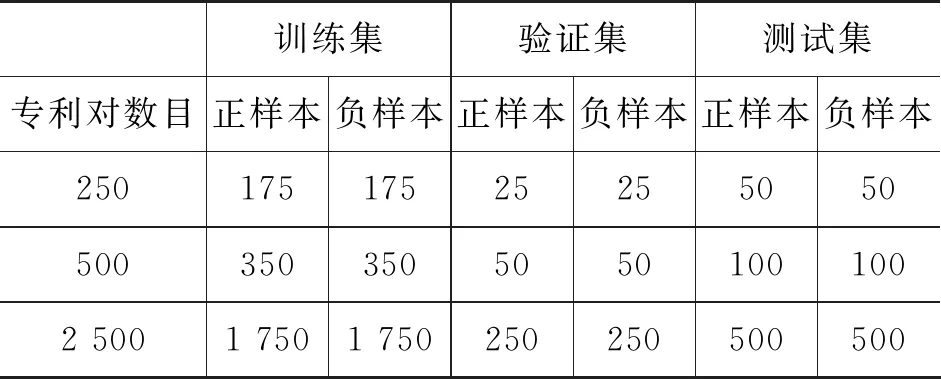
表2 本文處理后的專利數據分布
3.2 實驗結果
為了驗證本文MVAN方法對于專利匹配語料任務的有效性,我們對比了幾種常見的文本匹配基線方法:
Siamese-LSTM[19]: 一個基于LSTM模型的文本表示模型,分別利用LSTM對待比較的句對中的句子進行建模,然后計算兩個隱層向量的曼哈頓距離來評價句子相似度。由于LSTM建模過程一致,因此可以用全部句子訓練LSTM的參數,然后把參數共享給左右兩個LSTM網絡。其中,①Siamese-LSTM(標題): 僅用標題單視角特征作為輸入進行專利匹配任務; ②Siamese-LSTM(摘要): 僅把摘要單視角特征作為輸入進行專利匹配任務; ③Siamese-LSTM(聲明): 僅把聲明單視角特征作為輸入進行專利匹配任務; ④Siamese-LSTM(全字段): 使用標題、摘要、聲明三個特征拼接作為輸入進行專利匹配任務; ⑤Siamese-LSTM(融合方法): 由Siamese-LSTM直接拼接獲取專利多視角的匹配特征進行專利匹配任務; ⑥Siamese-LSTM(權重方法): 使用多頭注意力機制融合由Siamese-LSTM拼接得到的專利多視角的匹配特征進行專利匹配任務。
BERT: 自然語言處理領域中比較常用、性能較好且使用方便的文本編碼模型,模型基于注意力網絡和Transformer層,Transformer作為算法的主要框架,能更徹底地捕捉語句中的雙向關系;模型通過遮蔽詞預測和下一句預測兩個自監督學習任務學習文本的表示,用于下游具體的自然語言處理任務。在本實驗中,我們通過加載BERT預訓練好的模型進行專利匹配任務。①BERT(標題): 僅用標題單視角特征作為輸入進行專利匹配任務; ②BERT(摘要): 僅用摘要單視角特征作為輸入進行專利匹配任務; ③BERT (聲明): 僅用聲明單視角特征作為輸入進行專利匹配任務; ④BERT(全字段): 使用標題、摘要、聲明三個特征拼接作為輸入進行專利匹配任務。
MVAN w/o MA: 本文方法,但是并未使用多頭注意力機制融合多個視角的特征,直接拼接BERT得到多視角匹配特征。
MVAN w/o MVL: 本文方法,但是并未采用多視角學習機制,而是直接使用單個損失函數優化多頭注意力機制融合得到的多視角匹配特征。
3.3 實驗例子分析
表3給出了本文方法同基準方法的比較實驗結果。
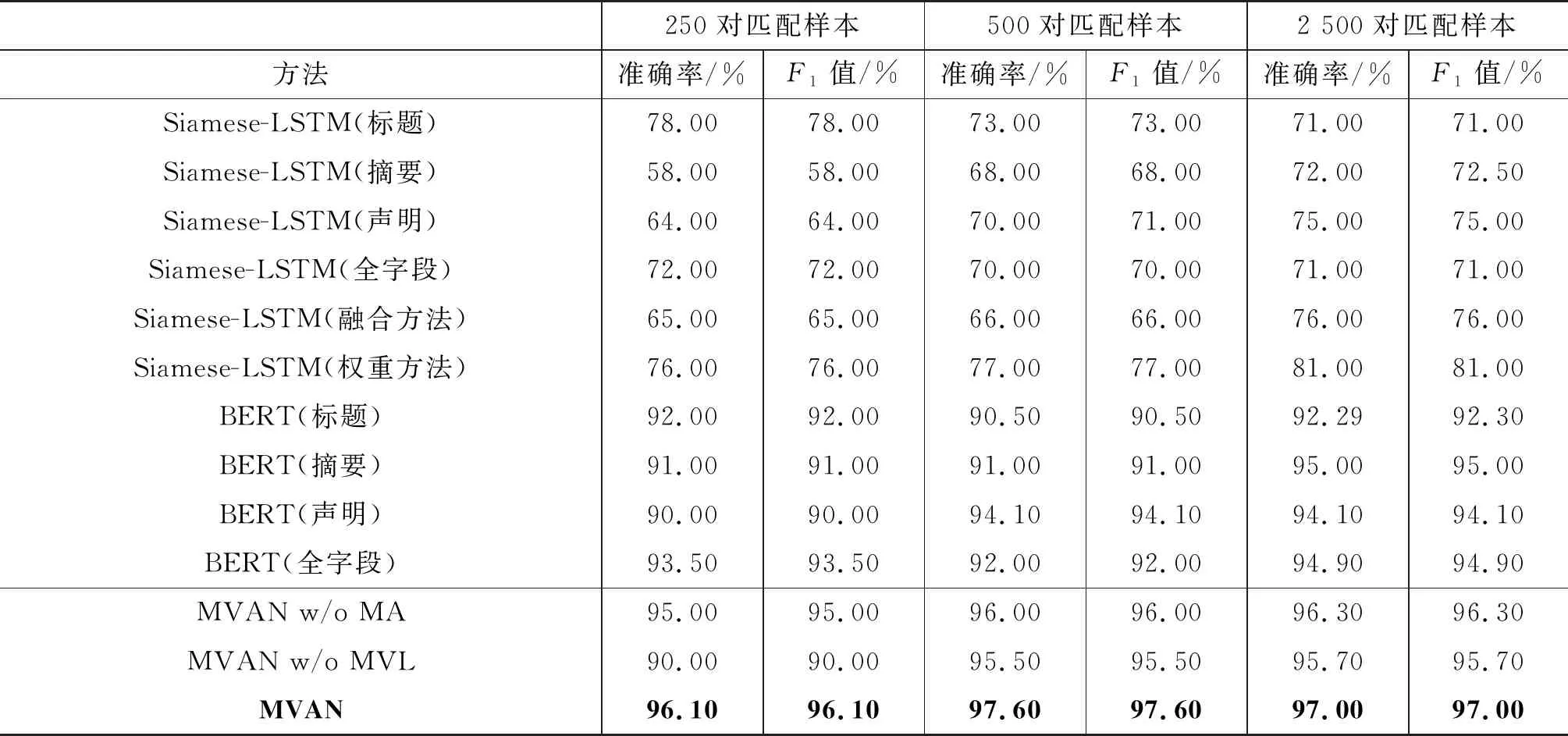
表3 本文方法與基準方法的性能比較
從表3可以看出,與一系列基準方法的性能相比,本文采用的模型明顯效果更好。首先,通過對比表3基線方法中的BERT模型和Siamese-LSTM結果,不難發現大規模數據預訓練的BERT模型在性能上明顯優于Siamese-LSTM的基準方法,因此在本文實驗中使用BERT模型作為文本的編碼層,以此提取待匹配專利樣本的特征[20]。此外,使用單個特征(標題,摘要,聲明)進行匹配時,模型關注的內容趨向單一化,很難把握到專利樣本的整體信息,在僅選擇一部分信息作為匹配判斷依據的情況下,專利匹配的效果不如結合專利多個匹配特征的方法好。其中,結合專利多個匹配特征的方法有拼接專利的各個字段作為專利匹配任務的輸入與融合專利各個字段的匹配特征進行專利匹配兩種。僅僅拼接專利的各個字段作為輸入難以讓模型很好地關注到專利各個字段的匹配信息,從而存在一定的局限性。因此,采用融合單視角匹配特征得到多視角匹配特征的方法進行專利匹配任務具有更好的表現。
MVAN模型是基于BERT模型進行改進的,首先由于當預訓練模型作用于相似度匹配任務時,其性能與一般基線模型相比達到了新的高度。因此,MVAN模型利用BERT模型對于專利語料進行編碼,對其進行更好的表示,然后將三個特征進行融合,共享一套參數進行優化。
其次,通過對比我們的多視角學習方法和僅僅使用BERT模型利用專利的單個特征進行匹配的實驗結果,我們可以看出: 由于同時利用了專利的多個特征進行匹配任務,能夠讓模型學習到專利語料多方面的信息,這使得在大部分情況下我們的模型都能夠比僅使用單個特征進行匹配任務的結果更好。
我們的MVAN模型在性能上明顯優于所有基線模型,在500條專利數據集上的準確率相較于最好的基準方法BERT提高了2.6%,1 000條數據集上提高了5.6%,5 000條提高了2.1%,這表明我們的方法適用于大規模語料上的專利匹配任務。
最后,本文進行了消融實驗,實驗結果如表4、表5所示。可以看出:
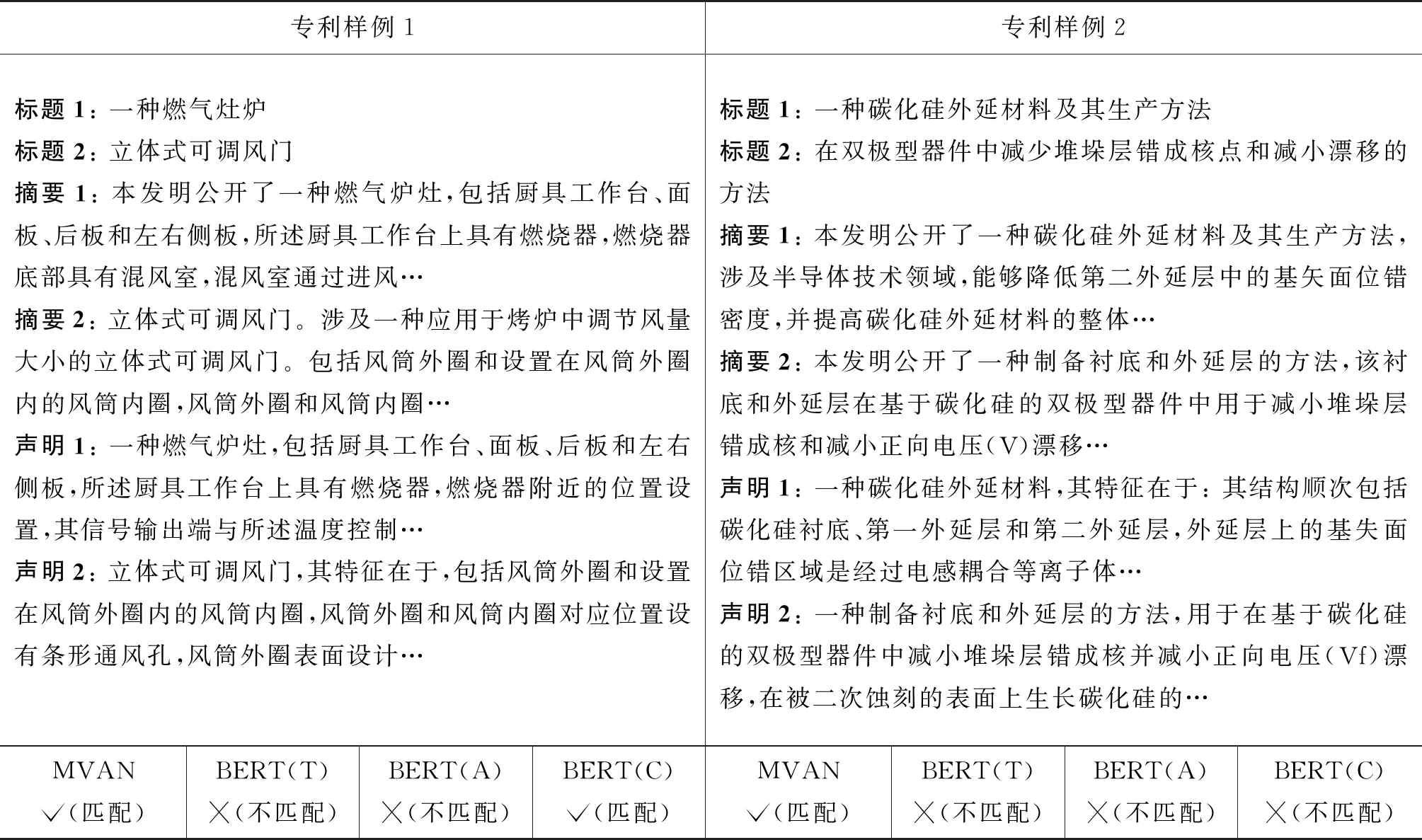
表4 實驗結果樣例分析1
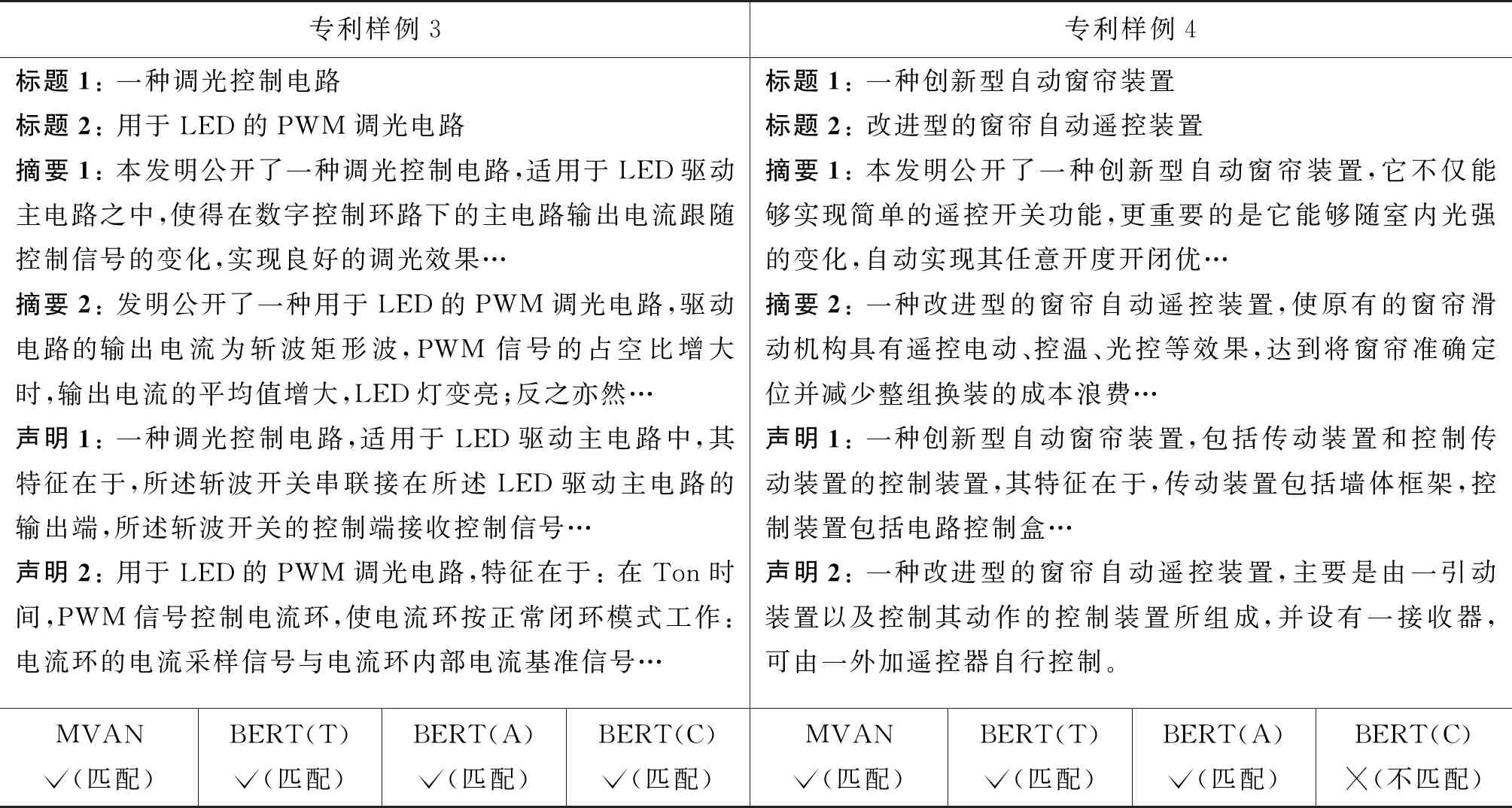
表5 實驗結果樣例分析2
(1) 本文提出的MVAN模型相較于MVAN w/o MA方法在性能上有明顯提升,其中250對專利樣本上的準確率提高了1.1%,500對專利樣本上準確率提高了1.6%,2 500對專利樣本上準確率提高了0.7%。這驗證了多頭注意力機制能夠更好地捕獲對于專利多視角特征的表示。
(2) 本文提出的MVAN模型相較于MVAN w/o MVL方法在性能上有明顯的提升,其中250對專利樣本上的準確率提高了6.1%,500對專利樣本上準確率提高了2.1%,2 500對專利樣本上準確率提高了1.3%。這驗證了多視角學習的方法能夠適用于專利匹配任務。
因此,本文提出的多視角學習思想在作用于專利這種具有多個關鍵字段信息語料的匹配任務上是非常有意義的。
4 總結
本文提出了一種基于注意力感知的多視角學習模型(MVAN),用于解決基于多字段文本信息的專利匹配任務。具體而言,首先,使用BERT模型提取待匹配專利對的單視角匹配特征;其次,使用多頭注意力機制融合單視角匹配特征,得到多視角匹配特征;最后,基于多視角學習方法,在模型訓練過程中聯合學習單視角匹配特征和多視角匹配特征得到的結果,對多視角匹配特征的結果進行優化,并將其視為最終的結果。實驗結果表明,本文提出的MVAN模型在專利匹配任務中性能明顯優于其他基準方法。
未來工作中,我們擬探索利用專利的正文信息進一步提升專利匹配的性能。此外,還將嘗試將本文的模型應用到其他文檔級匹配任務中,如法律文檔匹配等。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
