量化敏感度的個性化數據發布模型
2022-09-06 13:17:20朱理奧曹天杰
計算機應用與軟件 2022年8期
朱理奧 曹天杰
(中國礦業大學計算機科學與技術學院 江蘇 徐州 221116)
0 引 言
現如今,大數據已經成為時代熱點。人們在日常生活中的方方面面享受著大數據所帶來的便利。這是因為針對大數據的挖掘、分析和利用能夠更好地在商業、行政決策以及科學研究領域對人們提供幫助。但是由于這些數據本身來源于現實中的每個個體,它們本身包含有大量的可以與個人產生關聯的信息,甚至會包括個人所不愿意對外界披露的隱私信息。這些信息在遭到泄露之后可能會對相關聯的個人產生難以預計的后果。因此,在發布大量數據的同時保證個人隱私的技術,即數據發布隱私保護技術(Privacy Preserving in Data Publishing, PPDP)[1-2]便成為了研究的重點。這些研究的重點在于如何在保證大量數據能夠被用于大數據分析和利用的同時,保證用戶隱私不被泄露。
最開始,人們提出的數據發布模型是建立在匿名化[3]基礎上的。所謂匿名化,是指在數據發布階段,通過一定的處理,將所發布數據與個體身份的關聯打破,從而避免攻擊者利用所發布出來的數據準確確定個人。這些經典的模型包括k-匿名模型[4-5](k-Anonymity)、l-多樣性[6](l-Diversity)和t-近似[7](t-Closeness)等等。在這些經典的模型的基礎上,有很多改進的模型被提出。不過,這些傳統模型只是單純考慮了包含隱私的數據的敏感程度。對于這一敏感程度的把握往往都是根據數據發布者基于自身經驗決定,并未考慮到用戶個人對于隱私保護的需求,同時也帶來了可能的保護程度與實際所需不匹配的情況(即對于較不敏感的數據進行過度保護,對敏感程度較高的數據保護程度不足)。
當前,關于考慮用戶自身需求的隱私保護模型,已經得到了一些關注。其中有針對每一條記錄設計不同保護需求的方法[8-9],也有將個人需求作為評估標準之一的方法[10],以及為敏感屬性設置泛化樹的方法[11]。但是,針對保護程度與實際所需不匹配的問題卻并未得到重視。僅有文獻[12]提出的將敏感度量化計算的(w,l,k)-匿名模型。但是這一模型并未考慮用戶個人的隱私需求。目前尚未有研究同時解決這兩個問題。
本文針對數據發布中的隱私保護問題,基于(w,l,k)-匿名模型進行改進。在保留原本的利用量化計算來解決保護程度與實際所需不匹配的問題的基礎上,對用戶的隱私保護需求進行量化,參與敏感度的計算。本文的模型既保留了(w,l,k)-匿名模型的優勢,又具有了對用戶個性化隱私需求的支持,具有更好的隱私保護能力。
1 相關概念
本文在之后的討論中將會用到一些概念,現將對這些概念進行必要的說明。
在一個數據表中,每一條數據記錄(被稱為元組)的各個屬性可以簡單劃分為能夠直接標識個體身份的標識符屬性、組合起來可以推斷用戶身份的準標識符屬性、敏感屬性和非敏感屬性。研究中,一般假定數據表中不包含標識符屬性和非敏感屬性,主要針對敏感屬性進行隱私保護。
在討論數據發布匿名規則時,有以下一些常用定義。
1) 等價類(Equivalence Class, EC):經過匿名化處理后,所有擁有相同準標識符屬性值的元組構成一個等價類。
2)k-匿名:數據表T包含n個等價類{A1,A2,…,An}。對于T中的任意一個等價類Ai,都有:
|Ai|≥k
成立。那么則稱T滿足k-匿名。其中|Ai|表示等價類Ai中所包含的元組個數。
3)l-多樣性:數據表T包含n個等價類{A1,A2,…,An}。對于T中的任意一個等價類Ai,其包含的敏感屬性值至少有l個不同的取值,那么則稱T滿足l-多樣性。
在對數據表應用數據發布模型時,有以下幾個常用概念。
1) 泛化:指使用更具概括性意義的屬性值來對具體屬性值進行替代的過程。
2) 泛化樹:又叫泛化層次,指表示屬性值以及泛化后的屬性值之間的關聯的樹結構。
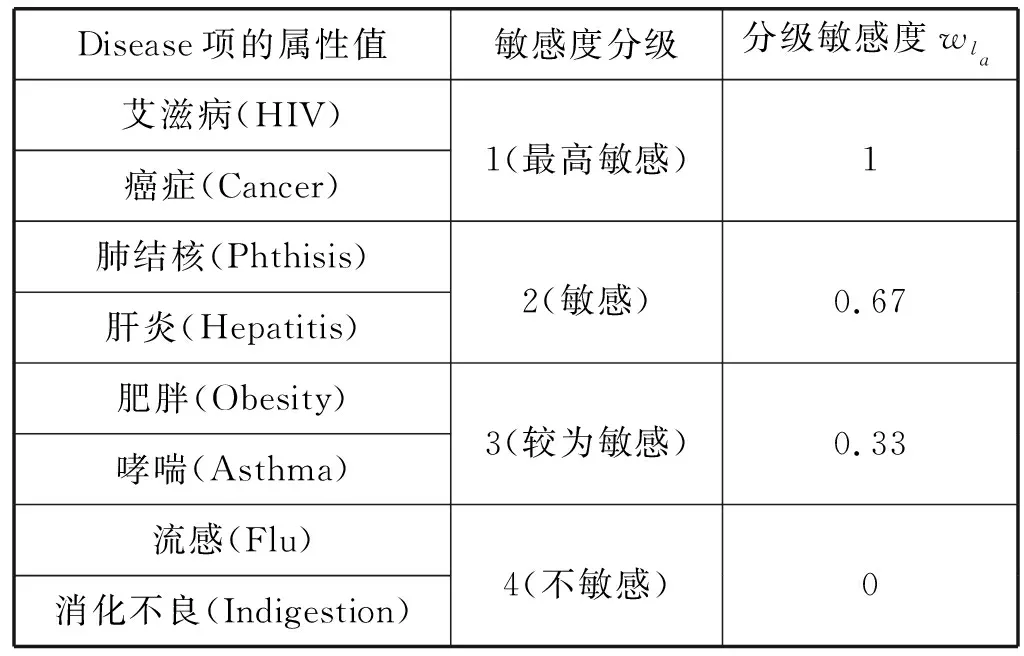
圖1是針對一個數據表中“Disease”屬性的屬性值所建立的一個泛化樹。
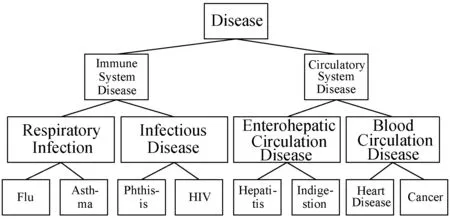
圖1 “Disease”屬性泛化樹
2 敏感度量化模型
本節將對現有的敏感度量化模型,即(w,l,k)-匿名模型進行分析,研究其所存在的不足,并且針對這些問題提出改進模型,同時給出改進后模型的實現方式。
2.1 (w,l,k)-匿名模型
文獻[12]針對數據發布模型中存在的隱私保護程度和實際所需保護不匹配的問題,提出了一個通過量化敏感度值來幫助進行數據匿名化的模型——(w,l,k)-匿名模型。
定義1((w,l,k)-匿名模型[12]) 當一個給定數據表T滿足k-匿名、l-多樣性,并且每個等價類的平均敏感度不超過w時,該數據表滿足(w,l,k)-匿名模型。
在這個模型中,等價類M的平均敏感度waverage的計算方法被定義為:
式中:wa表示敏感屬性A的某一屬性值a的敏感度。它的計算方法定義為:
wa=α×wfa+(1-α)×wlaα∈[0,1]
式中:α為用于控制敏感度對于頻率敏感度wfa和分級敏感度wla的依賴程度的全局參數,由數據發布者根據實際需要決定。wfa、wla的計算公式分別為:
式中:m表示A的屬性值按照敏感程度劃分的總等級數,fa表示屬性值a在整個數據表中的頻率,i表示該a所處于的敏感程度等級。
(w,l,k)-匿名模型一方面通過綜合考慮敏感屬性值的頻率敏感度和分級敏感度,避免了發布者完全憑借自身經驗決定隱私保護程度所帶來的主觀性過強的問題,另一方面利用量化計算來幫助發布者判斷具體所需要的隱私保護程度。但是,該模型僅僅考慮了敏感屬性值本身的敏感程度,并未考慮到用戶個人對于隱私保護的需求。在某些情況下,用戶可能會出于自身的特殊情況,對較低敏感度的敏感屬性提出較高的隱私保護需求。在這種情形下,這一模型便不再適用。
2.2 個性化(w,l,k)-匿名模型
根據上文提及到的(w,l,k)-匿名模型所存在的問題,本文針對性地提出個性化-(w,l,k)-匿名模型。在原本模型的基礎上,將用戶個人的隱私需求進行量化,參與到等價類的平均敏感程度的計算當中。
對于用戶的隱私需求,參考敏感屬性值的語義敏感度分級方法,考慮設立如表1所示的一個用戶隱私需求等級表。
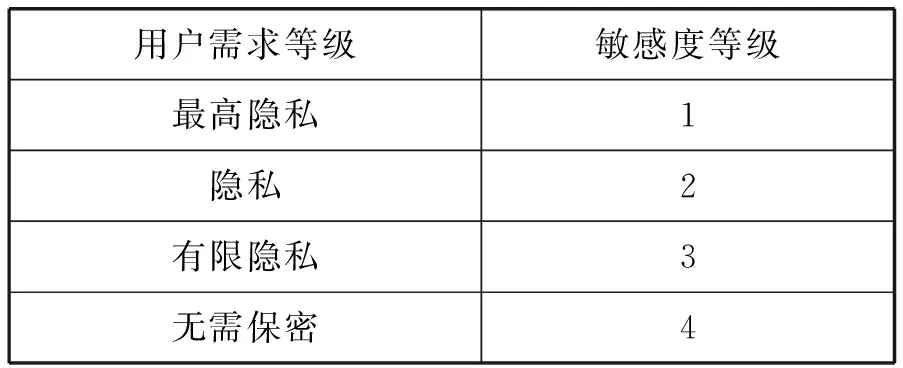
表1 用戶隱私需求等級表示例
設立用戶隱私需求等級表的目的在于,實際情況下,用戶本身僅僅能夠對自己的隱私需求有一個感性認知,而并不能直接提供一個定量數據。此外,這也便于在實際應用情形下,通過發放調查問卷的方法向用戶搜集其個性化隱私需求。
在此基礎上,給每個需求等級賦一個表征敏感度的數值,以便進行量化。數值越大,表示所要求的保護等級越高。表2便是針對表1的一個量化示例。
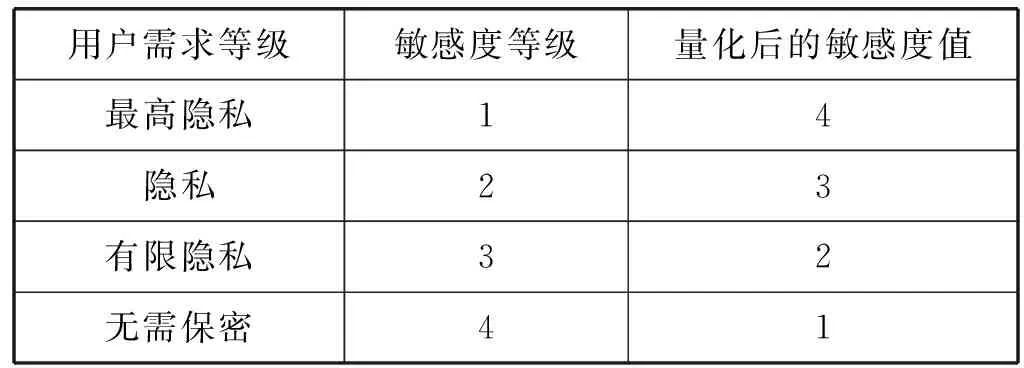
表2 對表1的量化示例
在完成了對用戶需求的量化定義之后,便可以進一步定義用戶隱私需求的計算方法。
定義2(用戶需求敏感度計算方法) 根據用戶對于隱私保護程度需求在泛化層次樹上對應的層級ipl,可以計算出用戶需求敏感度wapl:
定義3(敏感屬性值綜合敏感度計算) 考慮用戶敏感度需求的某一敏感屬性A的屬性值a的綜合敏感度wgeneral的計算方法如下:
wgeneral=max{α×wfa+(1-α)×wla,wapl}α∈[0,1]
如果α×wfa+(1-α)×wla≥wapl,此時用戶需求wapl低于屬性值敏感度權重wa,取wa作為最終的綜合敏感度;如果α×wfa+(1-α)×wla 在定義了用戶的隱私需求計算方法之后,可以給出改進模型的定義。 定義4(個性化(w,l,k)-匿名模型) 當一個給定數據表T滿足k-匿名、l-多樣性,并且每個等價類的平均綜合敏感度不超過w時,該數據表滿足要求個性化(w,l,k)-匿名模型。 其中,某個等價類M的平均綜合敏感度wgeneral_average的計算方法為: 模型中依然保留有參數α,由數據發布者根據實際情況,決定在計算屬性值敏感度權重時對語義敏感度和頻率敏感度的倚重程度。 k-匿名的要求是為了防止數據表經過匿名處理后,由于等價類中可能僅僅含有一條記錄而導致隱私泄露。l-多樣性的要求是為了防止由于等價類中敏感屬性值取值相同而導致的隱私泄露。平均綜合敏感度同時考慮到了敏感屬性值的頻率分布、語義敏感性以及用戶自身的需求,表征了等價類中各敏感屬性值在綜合這三方面的普遍敏感水平。對其進行限制便是對每一個等價類的敏感水平進行限制,防止由于一個等價類中因為包含占比過大的高敏感屬性值而導致的隱私泄露。 在模型的實現方面,本文將同文獻[12]一樣使用基于ARX框架[13]的Flash算法[14],來對個性化(w,l,k)-匿名模型進行實現。 在介紹具體實現算法之前,首先需要介紹在該算法中所使用的泛化格的概念。 定義5(泛化格) 將數據表中每個屬性的泛化程度用泛化層次高度進行表示,可以得到一個表示針對當前數據表的泛化配置的數字列表。所有的這些列表所表示的泛化配置空間,被稱為泛化格。 例如,由圖2所示的泛化層次,其對應的泛化格如圖3所示。 圖2 三個屬性的泛化層次 圖3 由圖2所產生的泛化格 泛化格通過將泛化配置簡化為一個數字組成的列表,從而簡潔方便地將針對一個特定數據表的泛化空間表示為樹的形式,為存儲和遍歷泛化空間提供了便利。 Flash算法通過對于泛化格的自下而上的二分查找,遍歷泛化格的所有節點,以便尋找到滿足匿名化方案的最優解。由于ARX框架本身對于數據表進行了大量優化,利用哈希表、快照緩沖區等方法提高了對于匿名狀態的檢查速度,對泛化格的遍歷搜索和檢查成為可能。 算法1Flash算法外循環 輸入:Laticelattice //輸入泛化格 開始 heap=newmin-heap //最小堆 for/from0tolattice.height-1do foreachnode∈level[l]do if!node.taggedthen path=FINDPATH(node) CHECKPATH(path,heap) while!heap.isEmptydo node=heap.extractMin foreachup∈node.successorsdo if!up.taggedthen path=FINDPATH(up) CHECKPATH(path,heap) 算法的外循環:主要是實現了針對泛化格的深度優先貪婪搜索。每次遇到未被標記為已被檢查過的節點,便調用FINDPATH(NODE)方法來找到一條從NODE到頂層的路徑,并且對路徑調用CHECKPATH(PATH,HEAP)方法進行檢查。 算法2FINDPATH(NODE) 輸入:Start nodenode 輸出:Path of untagged nodespath 開始 //尋找一條未被標記的節點組成的路徑 path=new list whilepath.head() !=nodedo path.add(node) foreachup∈node.successorsdo if!up.taggedthen node=up break returnpath FINDPATH(NODE)方法:針對每一個節點,尋找它首個未被標記的子節點加入路徑,直到抵達泛化格最頂端或是當前節點的所有子節點已被標記時停止。返回路徑,以便對路徑中的節點進行檢查。 算法3CHECKPATH(PATH,HEAP) 輸入:Pathpath, heapheap 開始 Low=0;high=path.size-1;optmum=null whilelow≤highdo mid=int((low+high)/2) //向下取整 node=path.get(mid) //選取中間節點進行二分搜索 ifCHECKANDTAG(NODE)then //CHECKANDTAG //(NODE)將檢查節點的匿名性,并且標記已被檢查過的節點 //當前節點符合匿名條件 optimum=node high=mid-1 else //當前節點不符合匿名條件 heap.add(node) low=mid+1 STORE(optimum) //存儲符合匿名條件的節點的局部最優 //解,因為它可能是全局最優解 檢查路徑的方法。對路徑進行二分搜索。對每一個節點調用CHECKANDTAG(NODE)方法進行匿名性檢查,判斷該節點所代表的泛化配置是否滿足匿名模型的要求。如果滿足,則將其儲存;如果不滿足,則不儲存。由于ARX框架本身進行了針對性優化,將數據表中的各個屬性值(包括泛化后的所有可能的值)轉化為數值,并且以哈希表的形式進行存儲。每次判斷匿名條件是否符合時,僅僅對受到泛化配置改變影響的部分進行修改,保留不受影響的部分,算法運行耗時較短。 將通過實驗來對本文模型和(w,l,k)-匿名模型進行比較,以便對本文模型的性能進行評估。 在評價本文提出的數據發布模型時,將從數據效用和隱私保護兩個方面進行評估。 在評價數據效用方面,將采用AECS和PM作為評估指標。 定義6(平均等價類大小[15],Average Equivalence Class Size,AECS) 數據表T中等價類的平均大小。 式中:|T|表示數據表中的總元組個數;k為k-匿名模型的參數;total_equivalence_class表示等價類的總個數。 定義7(準確度[5],Precision Metric,PM)一個表征數據表T中屬性A的各屬性值Ai泛化所帶來的損失的量。 式中:NA表示表中屬性的個數;N表示表中元組的個數;|DGHAi|表示屬性Ai的泛化層次總高度;h表示當前泛化方法下單個屬性值的泛化高度。 在評估隱私保護時,將與文獻[12]相同,使用高危等價類占比(即高危等價類占總等價類的比例)作為評估指標。 定義8(高危等價類[12]) 如果一個等價類M中具有最高敏感等級的屬性值在該等價類中的頻率之和是其在整個數據表中的頻率的5倍或以上,那么該等價類M是一個高危等價類。 一般而言,高危等價類占比越高,屬性值披露風險越大。 在數據選用方面,使用相關研究中被廣為使用的Adult數據集。這個數據集來自UCI Machine Learning Repository,是一個公開數據集。它包括了48 842條數據記錄。在刪除其中的擁有空值和不確定值得記錄之后,最終得到30 169條數據。為方便計算,隨機選取其中的30 000條數據作為實驗用數據集。與相關研究的各文獻一樣,選取{Age, Work-class, Education, Native-Country, Marital Status, Race, Sex}這幾項作為準標識符屬性。由于原數據集中并未包含敏感數據屬性,現為各數據項按照如表1所示的頻率,隨機地分配Disease數據項的各屬性值,并且由此可以計算出相應的頻率敏感度wfa。 表3 Disease數據項的各屬性值及其相應的頻率敏感度wfa 這些屬性值的敏感度分級以及每個屬性值相對應的分級敏感度如表4所示。 表4 Disease數據項的各屬性值的敏感度分級及其相應的分級敏感度wla 實驗中,為每條記錄隨機生成一個用戶隱私需求等級。其具體的分級如表5所示。 表5 用戶個人隱私需求等級及其相應的敏感度wapl 實驗中取參數α=0.5,l=4。實驗使用的CPU為Intel Core i7- 8750H,操作系統為Windows 10,編程語言為Java。實驗中選取AECS和PM作為數據效用的度量,使用高位等價類占比作為隱私保護程度的度量。由于實驗中整張表格的敏感度值的平均數為0.567,w的取值如果低于這個值可能會導致過多的數據效用損失。因此,實驗中取w=0.65。實驗將本文模型與改進前的模型進行比較。 隨著k的取值的增大,兩種模型的平均等價類大小都在減小。這是因為AECS的計算公式排除了k的取值對于等價類大小的影響。從圖4中可以看到,在k≤50時,本文模型的AECS均大于(w,l,k)-匿名模型。這是因為由于本文模型在計算綜合敏感度時,是選取了wa和wapl兩者之間的最大值。這一步導致了對于每一個敏感屬性值,必定有wgeneral≥wa。在模型參數w的取值一定的情況下,為了滿足匿名要求,應用了個性化(w,l,k)-匿名模型的數據表需要在等價類中擁有更多的元組,即令等價類更大,才能滿足同樣的匿名要求。此外,從圖4中同樣可以看出,在k=100時,兩個模型的AECS大小相等,并且在之后保持了相等的狀態。這表明隨著k的取值的增大,k逐漸取代匿名模型,成為了對于數據效用的主要影響因素。 圖4 AECS與k的取值關系 如圖5所示,PM呈現出了相同的趨勢,隨著k值的增大而減小。這是由于隨著k值的增大,等價類的總體大小在增大,在進行數據匿名化時需要對準標識符所包含的信息進行更大程度的抹除,消除每個元組的獨特性,才能讓更多的元組出于同一等價類中。(w,l,k)-匿名模型在k≤50時,具有相對于本文模型的更高的PM,但優勢很小,PM差值不足0.05,并且在k=100時被個性化(w,l,k)-匿名模型追平。正如文獻[16]所指出的,尋找一個擁有最高數據效用同時具有最優隱私保護能力的k-匿名數據集是一個NP難問題。由于本文方案提出了更高的隱私保護要求,在數據效用方面會有所犧牲。 圖5 PM與k的取值關系 在隱私保護方面的情況如圖6所示。 圖6 高危等價類占比與k的取值關系 隨著k值的增大,無論模型選擇,高危等價類占比都在減小。這是因為針對一個特定數據集,數據總量是一定的。等價類的增大將會導致等價類總數的減小,這將導致等價類中的各屬性值的分布逐漸接近于其在整張數據表中的分布。最終,當數據表內所有元組都被劃歸為一個等價類時,等價類中的屬性值分布將與在數據表中的分布一致。在k≤50時,本文模型始終具有更低的高危等價類占比。這是因為本文模型具有平均大小更大的等價類,這使得敏感屬性值的分布相比于(w,l,k)-匿名模型更接近于數據表內的分布。當k≥100時,兩個模型均不包含高危等價類。 綜合以上分析,可以得出結論:個性化(w,l,k)-匿名模型相比較于(w,l,k)-匿名模型,在實現了對用戶隱私的個性化保護的同時,犧牲了一定的數據效用,但具有更高的隱私保護能力。 本文針對現有的數據發布模型中存在的問題,在繼承了量化計算敏感程度的思路的情況下,對(w,l,k)-匿名模型進行了改進,得到了一個能夠考慮用戶自身隱私需求的數據發布模型。該模型在讓數據滿足k-匿名和l-多樣性的前提下,通過量化用戶隱私需求,并將其參與敏感度計算的方法,使得最終的等價類劃分能夠體現用戶的個性化需求。經過實驗證明,本文模型在犧牲了一定的數據效用的情況下,能夠有效地個性化地保護用戶隱私,并且具有更好的隱私保護能力。 目前考慮用戶隱私需求的模型大部分單純依賴用戶指定來確定用戶需求,這一過程存在較大主觀性。用戶有可能會高估自身信息所需要的保密等級,而這會導致毫無必要的數據效用損失。一種能夠客觀評估用戶個性化需求是否合理的方法將在未來的研究中進行探討。2.3 模型實現

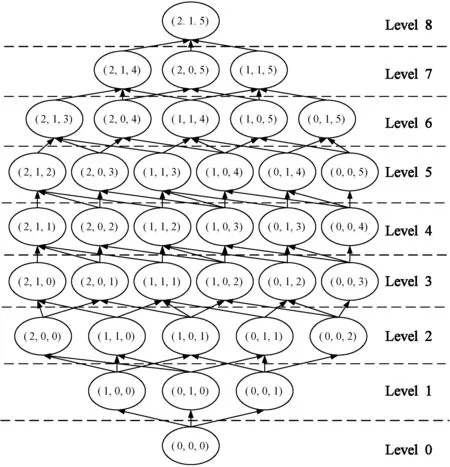
3 實 驗
3.1 模型評估指標
3.2 評估實驗設計


3.3 實驗結果



4 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:25
創業家(2015年5期)2015-02-27 07:53:25
當代修辭學(2014年3期)2014-01-21 02:30:44
