自適應對抗學習求解旅行商問題
2022-09-06 11:17:34熊文瑞陶繼平
計算機工程與應用 2022年17期
熊文瑞,陶繼平
1.廈門大學 航空航天學院,福建 廈門 361005
2.廈門大學 大數據智能分析與決策重點實驗室,福建 廈門 361005
在一般意義下,優化指的是按照某些確定的約束條件進行策略的選擇,在滿足約束條件的情況下,尋求在某個優化準則下的極值。組合優化問題是一類在離散狀態下求極值的優化問題。在日常生活中,特別是運作管理中,有許多組合優化問題。典型的組合優化問題有背包問題、指派問題、旅行商問題等。這些類問題與實際生產聯系緊密,具有重要的研究意義。傳統求解該類問題的方法可以分為精確算法和近似算法兩大類。
常用的精確算法有動態規劃、分支定界、枚舉等。精確算法只適用于求解小規模問題,一旦問題規模擴大,該種方法難以在較短時間得到最優解,不適用于實際的生產。
近似算法是指在合理的計算時間找到盡可能接近最優解的方法。近似算法可以分為三類:第一類是基于數學規劃的近似算法,該種方法以數學模型為基礎,采用列生成、拉格朗日松弛等方法求解問題,該類方法的優點是可以通過松弛問題的最優解為原問題提供一個下界,通過算法運行給出的問題的近似解為原問題提供上界,上下界進行比較,可以衡量算法性能;第二類是常規啟發式算法,即根據問題的特點,按照經驗或者某種規則設計的,該種方法的優點是直觀快速,但解的質量不一定好;第三類是基于智能優化的近似算法,智能算法是一種通用的算法框架,需要根據問題的特點對算法框架進行修改就可以直接應用于不同的問題。
基于數學規劃的近似算法不具有通用性且設計較為復雜。啟發式算法雖然簡單,但也存在遷移性不強的問題,一旦問題結構發生變化,原始方法將不再具有優勢,必須重新設計新的模型來進行求解。智能優化算法雖然更具通用性,但是和啟發式算法都依賴于初始解的質量。傳統方法對于每個實例的求解過程都是獨立進行,兩個算例的求解過程沒有任何聯系,算法沒有充分挖掘并利用在對不同算例求解過程中所積累的經驗。深度學習的出現,彌補了傳統方法的不足,深度學習以數據為驅動力,挖掘潛在的數據特征[1],可以自動地學習出有效的“啟發式方法”,而不需要獲取先驗知識來進行啟發式規則的設計。現有研究工作主要關注于對模型的改進,缺乏從實例的生成來解決訓練模型的泛化性。
本文以TSP 問題為例,在端到端的學習模型框架下引入對抗的思想,提出生成器加判別器的對抗訓練框架[2]來增強學習模型對于問題的泛化性。本文的貢獻如下:
(1)由隨機數據作為數據集訓練所得到的模型魯棒性較差,本文借鑒對抗攻擊與對抗防御思想,基于對抗生成模型的框架,設計神經網絡模型,使用求解器生成標簽,并使用監督學習的方式來得到對抗樣本。通過對預訓練模型的攻擊來驗證對抗樣本的效果,最終能夠產生高質量的對抗樣本。將生成器與判別器結合形成生成對抗框架,通過對抗訓練最終得到在隨機樣本和對抗樣本上都表現良好的判別器模型,實驗成功驗證了該思路的可行性。
(2)傳統對抗訓練沒有評判判別器訓練好壞程度的指標,只通過生成器模型和判別器模型固定次數的交替迭代來進行對抗訓練,本文基于判別器的更新方式設計一種自檢測更新機制,設置超參數,通過判別器的連續更新狀態來判斷是否進入生成對抗樣本的模式,通過該訓練方式所得到的模型能夠有效地降低對抗樣本的代價,避免每一步迭代過程中對抗樣本訓練欠擬合的狀況。
1 相關工作
Sequence-to-sequence[3]模型是一類針對變長輸入問題的端到端的學習模型。該模型根據輸入的序列來得到不同的輸出序列,被廣泛用在機器翻譯、自動應答等場景。由于上述模型的輸出字典大小固定,不適用于解決不同輸入長度對應的不同輸出長度的問題,Vinyals等人提出新的模型架構PointerNetwork[4]解決了該問題,該模型基于sequence-to-sequence 模型,使用LSTM[5]模型作為RNN[6]的基本單元,并在此基礎上改變attention機制[7]使其更適應于解決組合優化問題。該網絡的提出首次將深度學習引入到組合優化問題的求解,開辟了一條有別于傳統算法的研究思路。
使用監督學習在訓練效率上較非監督學習有一定的優勢,但是,對于大規模組合優化問題來說,獲取標簽的代價是昂貴的,而且所得到的模型質量取決于標簽的質量。另外,這種監督學習模型的本質是對獲取標簽算法的一種擬合,因此在求解質量上有天然的上限。針對該局限性,Bello等人[8]提出使用強化學習的方法來訓練PointerNetwork,使用類似asynchronous advantage actor-critic(A3C)[9]的強化學習訓練框架,用采樣解的代價(旅行長度)來對策略梯度進行無偏蒙特卡羅估計。該論文將TSP問題求解規模從50擴大到了100個點,同時避免了獲取高質量實例標簽的計算困難。Khalil等人[10]針對圖組合優化問題的特點提出使用structure2vec[11]來進行圖的嵌入,使用deep Q-learning[12]來學習一個圖嵌入網絡的貪婪策略,并在三種圖組合優化問題(MVC,MAXCUT,TSP)上進行驗證,取得了較啟發式算法有競爭力的解。Kool等人[13]提出使用基于transformer[14]作為網絡架構。基于架構優勢,使用自注意力機制實現了數據的并行輸入,改善了串行輸入帶來的效率低下的問題,同時使用一種類似自評價機制[15]的方法來提供強化學習的基線。該方法使TSP 問題在100 點的規模上得到了更近似于最優解的解,同時通過更改網絡解碼過程中的掩碼機制和上下文來適配不同的問題,將該網絡結構應用在其他幾個組合優化問題上,體現了該方法在解決一些沒有有效啟發式算法問題上的靈活性。
2 對抗訓練模型
本章基于TSP問題來定義對抗訓練模型,TSP問題是一個NP-hard 的組合優化問題[16]。問題可以描述為,在二維平面上有一系列分散的坐標點,要求從某一個點出發,找到一條經過各二維坐標點一次后回到出發點的最短路徑。定義一個問題實例S包含平面上的n個坐標點{(x1,y1),(x2,y2),…,(xn,yn)},定義實例的解為π=(π1,π2,…,πn),該解為坐標點的一個全排列。定義實例對應的最優路徑長度為。
對抗網絡主要由兩部分組成,分別為生成器網絡和判別器網絡,生成器和判別器的優化目標各不相同。生成器用來生成對抗樣本,生成的實例是對于判別器求解質量較差的實例。定義網絡對實例S輸出解為L(θ|S),其中θ為網絡參數。在評估解的優劣時,一般使用近似解和精確解的相對誤差,也就是gap 值作為評判標準,gap值定義如式(1):

判別器將對抗樣本和隨機樣本混合進行訓練,兩個網絡交替訓練,判別器和生成器相互博弈,最終得到泛化性增強的判別器網絡,對抗訓練模型示意圖如圖1所示。
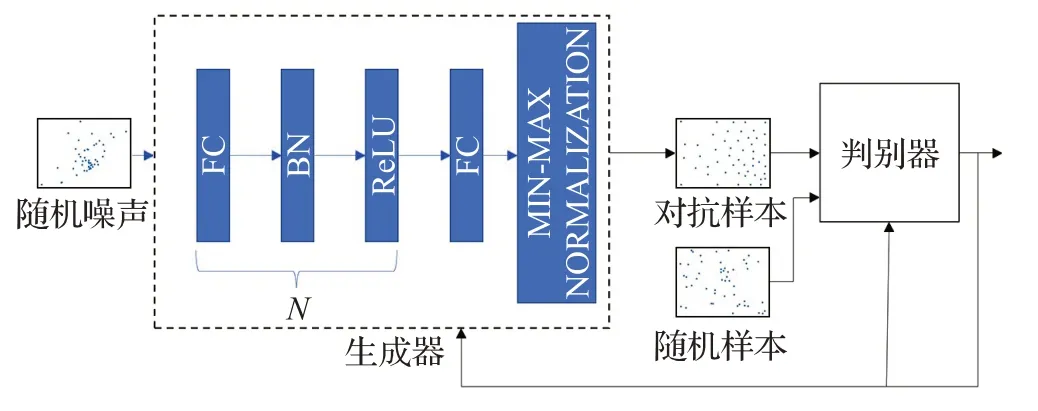
圖1 對抗訓練模型Fig.1 Adversarial training model
2.1 判別器模型
本文使用的判別器模型基于文獻[13]。模型可分為兩部分,編碼器和解碼器模型。編碼器使用自注意力機制進行特征提取。解碼器通過編碼器所提取的信息來構造上下文信息,通過注意力機制用于每一步的解碼,最后通過指針機制產生每個點被選擇的概率分布,通過不同的采樣機制來獲得實例的一個解。
編碼器部分基于transformer模型,核心部分采用三層多頭自注意力機制,同時在每一層都加入殘差連接[17]以及批規范化[18],最后一層為全連接層網絡。由于各個點的輸入不存在類似NLP輸入的順序問題,所以相比于傳統的transformer 模型,判別器網絡省略了位置編碼。編碼器將TSP問題中的每個點進行編碼,最終得到每個點關于整個實例圖的高維表示,同時將所有的點嵌入加和求平均得到關于整張圖的高維嵌入,所得到的高維表示稱為圖嵌入,編碼器網絡如圖2所示。
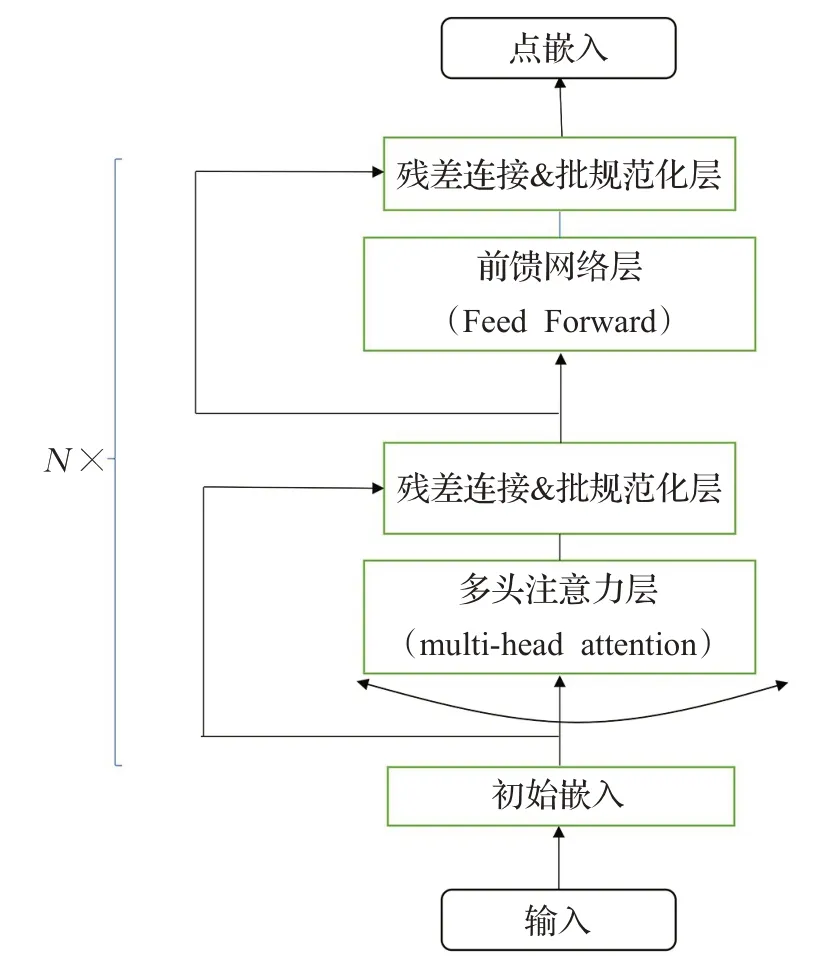
圖2 編碼器網絡圖Fig.2 Encoder model
解碼器采用逐步輸出的方式,每一步需要根據上下文信息和每個點的嵌入信息來進行解碼。解碼過程首先使用多頭自注意力機制來對上下文信息進行編碼,解碼過程中使用的上下文信息為解碼器網絡選擇的第一個點的點嵌入矩陣、圖嵌入矩陣,以及當前對應的前一個點的嵌入矩陣的拼接。在第一步解碼過程中,由于第一個點還未被選擇,所以前一個被選擇的點也不存在,使用可學習的參數矩陣作為輸入的占位符。得到上下文嵌入矩陣后,進行一次自注意力計算來完成上下文和各點嵌入矩陣的信息交換,然后使用指針機制[4]以及掩碼機制生成每個點被選擇的概率,掩碼機制使得前面每一步被選中的點下次被選中的概率為0,所有點被選擇的概率和為1。直到所有的點被選到形成實例的一個解,完成解碼過程。解碼器根據采樣方式不同可以分為兩種,一種是貪婪解碼,也就是在解碼過程中,每一步只選擇概率最大的點。另一種方式是概率解碼,也就是依據每一步解碼過程中所產生的概率分布來進行點的選擇。
2.2 生成器模型
生成器使用的是多層感知機網絡,神經網絡的前兩部分都包含一個全連接層、批規范化層、ReLU激活函數層,最后一部分為一個全連接層,生成2 維的坐標點信息。設置生成器的輸入為100維的隨機噪聲,第一層全連接網絡的節點數設置為256個,第二層全連接神經網絡的節點設置為128 個,最后一層節點數設置為兩個。隨機生成的噪聲信息在經過生成器后生成坐標集為{(x1,y1),…,(xi,yi),…,(xn,yn)} ,通過min-max 歸一化生成的新的點坐標集為,新坐標點分別為:
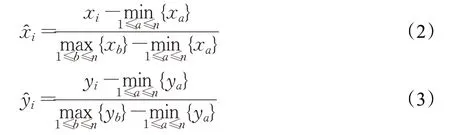
將坐標分別在兩個維度進行歸一化以匹配判別器的原始輸入。
2.3 訓練方法
對抗神經網絡包含兩部分,一部分是判別器網絡,一部分是生成器網絡,需要分別進行訓練。對于判別器,使用的是基于策略的強化學習的方法來訓練。給定一個實例S,判別器網絡在每一步解碼中給出每個點被選擇的概率,依據概率采樣可以獲得一個有效解π|s,定義損失函數為L(θ|S)=EPθ(π|s)[L(π)],L(π)為TSP 問題旅行長度的期望值。在訓練判別器時,訓練樣本為生成器所生成對抗樣本和隨機樣本的混合數據。固定生成器的參數,使用帶有基線的強化學習梯度估計器通過梯度下降的方法更新網絡參數,梯度估計如式(4)[19]:
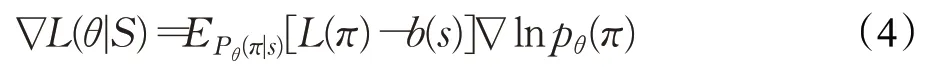
對于基準值的選擇,使用一個評判網絡,結構與主網絡相同,這種訓練方法類似于自評判機制。在訓練判別器前需要生成一份評估數據集,同時在評判網絡上通過貪婪解碼的方式生成評估數據集的解。重新生成訓練數據集,訓練數據集為隨機樣本和生成器所產生的對抗樣本,評判網絡對訓練數據使用貪婪解碼的方式為主網絡提供基準值。主網絡根據上述強化學習梯度估計更新網絡,評判網絡此時不需要進行更新。更新主網絡后,需要在主網絡上采用貪婪解碼的方式來得到評估數據集的解,根據評估數據集在主網絡和評判網絡的解通過配對T檢驗(α=5%)來判斷主網絡是否得到一定程度的改善,判定主網絡得到改善后,則將當前主網絡參數復制到評判網絡。每次參數復制后都會重新生成評估數據集以防止過擬合。
傳統的對抗學習一般在固定次數的判別器更新后切換到生成器網絡進行訓練,這種訓練方法不能對判別器的訓練現狀進行一個大概的評估,導致生成器和判別器難以訓練至收斂,訓練過程損失函數曲線震蕩嚴重。基于自評價基線的特殊性,當同一份驗證數據在判別器主網絡上的訓練難以繼續優化,判別器參數將無法更新到自評價網絡,可判定判別器網絡對于對抗樣本有了一定的學習能力,基于是否達到此狀態來判斷是否應該切換至生成器網絡來進行更新。
網絡首先從判別器開始訓練,根據以上介紹的強化學習方法進行訓練。設置超參數為n,當判別器主網絡連續n步沒有更新參數到基準網絡時,跳轉到生成器網絡的訓練階段,開始一個回合的生成器訓練,訓練結束后繼續跳轉到判別器訓練。
在訓練生成器時,需要固定判別器的參數。高維噪聲信號輸入生成器后輸出未經處理的坐標信息,將生成器生成的數據標準化后,使用Gurobi求解器求取對抗樣本實例的解作為訓練生成器的標簽,將得到的對抗樣本混合到隨機樣本中送入判別器網絡,判別器網絡此時使用的解碼方式為貪婪解碼,得到的每個實例i的解為Li(π),每個實例對應的求解標簽為y^i,使用監督學習的方法來訓練神經網絡。定義損失函數L(θ|S),使用梯度下降的方法來優化損失函數。經過判別器初始預熱訓練后,求解實例的gap值遠小于1,可以將1作為目標值,因此損失函數可以定義為式(5):
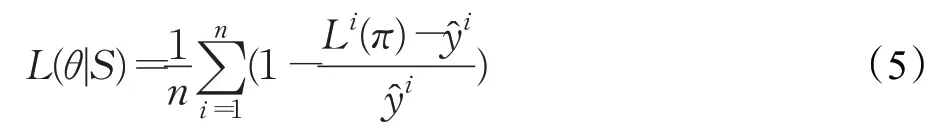
在訓練生成器時,判別器的解碼模式為貪婪解碼。當對抗樣本gap 值上升趨于平緩且判別器網絡對解的質量提升也趨于平緩時,結束對抗訓練。
3 實驗
3.1 實驗設置
3.1.1 數據集及評價指標
本文使用的數據用例包含隨機生成的用例和隨機噪聲通過生成器所生成的對抗用例,隨機生成用例是分布在正方形區域[0,1]2區間的均勻分布用例,而通過生成器所生成的對抗用例通過數據標準化來歸一化到[0,1]2區間。
本文將實驗分為兩個對照組,一組是通過隨機樣本充分訓練的預訓練模型,一組是初始化后,通過對抗訓練機制訓練的對抗訓練模型。本文將從對抗樣本和隨機樣本分別在對抗模型和預訓練模型的表現來驗證訓練效果。為了驗證生成器可以有效生成對抗樣本,需要通過對抗訓練生成對于預訓練模型gap 值較大的對抗樣本。驗證生成器有效后,再通過對抗訓練機制來訓練初始化的模型,使用預訓練模型上所得到的對抗樣本、隨機樣本以及對抗訓練中產生對抗樣本的gap 值來檢驗對抗訓練模型。
3.1.2 實驗環境
硬件環境為NVIDIA GeForce GTX1080 顯卡,16 GB 運行內存,英特爾i7-7700 處理器。軟件環境為Windows10系統,Tensorflow2.0,Pytorch0.4.1開發環境。
3.2 實驗參數設置
由于求解器求解速度限制,本文對于20規模的TSP問題,每回合處理5 000個實例,每一批次包含500個實例。對于50 規模的TSP 問題,每回合處理3 000 個實例,每一批次包含300 個實例,判別器網絡的學習速率設置為η1=10-4,生成器的學習速率設置為η1=10-3,同時生成器學習速率衰減值設置為0.96。
3.3 對抗樣本驗證
為了驗證生成器網絡能夠生成有效對抗樣本,分別在20 規模和50 規模的TSP 問題上進行驗證,判別器使用的是基于文獻[13]中的預訓練模型。固定判別器參數,生成器網絡使用監督學習的方式來獲取gap值更大的對抗樣本,訓練每一回合的批次大小和每一批次包含實例數量與上面設置相同,生成器采用Adam優化器來進行優化。訓練完畢后,對生成器進行驗證,驗證規模為500個對抗例,訓練過程如圖3。
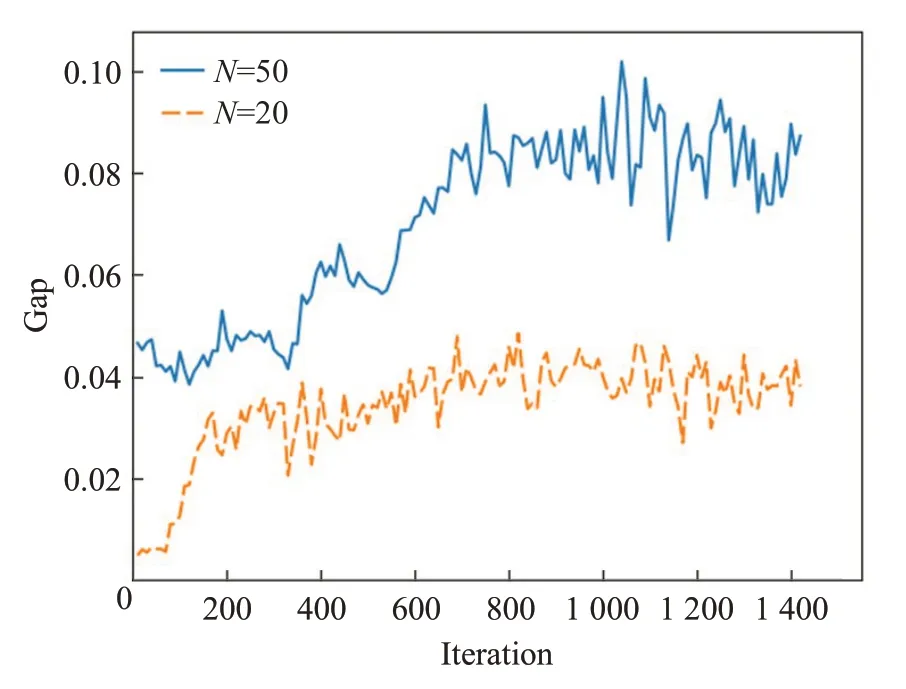
圖3 生成器訓練過程圖Fig.3 Training process of generator
可以觀察到,通過監督學習的方式不斷更新生成器網絡,最終得到了對于原預訓練判別器結果較差的解的實例,實驗證明生成器網絡能夠生成有效的對抗樣本,訓練最終結果如表1所示。
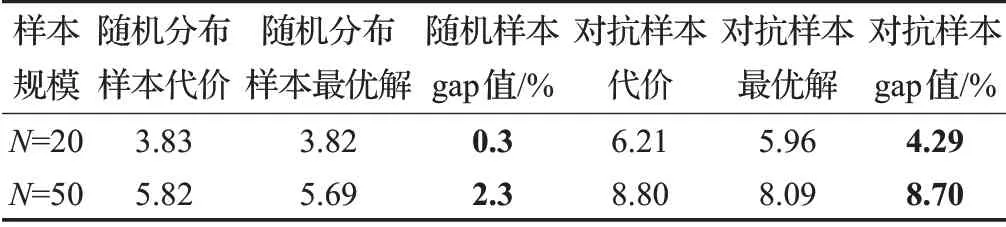
表1 生成器驗證結果Table 1 Result of generator training
3.4 對抗訓練實驗
對抗訓練階段,不使用預訓練模型,初始化判別器和生成器的參數,首先進行判別器的訓練,采用的是上述基于策略梯度的強化學習的方法。設置判別器和生成器的跳轉機制:設置TSP問題規模為20時,當判別器連續30個epoch沒有將主網絡參數更新到基準網絡時,將自動切換到生成器網絡進行訓練;當規模為50時,則設置為40個epoch。生成器網絡的回合數獨立計數,生成器的學習速率的衰減依據生成器的訓練回合數,不與判別器使用相同的回合計數。每次生成器更新完成后將生成新的混合評估數據,同時在判別器評判網絡上進行貪婪解碼,為后續主網絡更新到評判網絡提供評判標準,訓練過程如圖4、圖5所示。
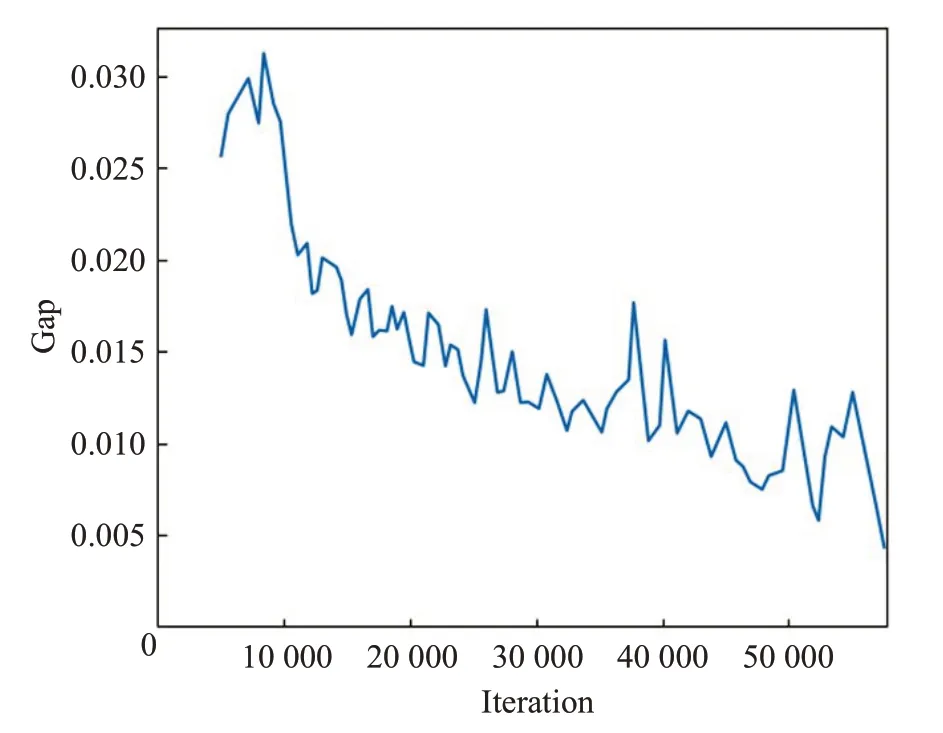
圖4 20維TSP對抗訓練過程圖Fig.4 Adversarial training process of TSP(N=20)
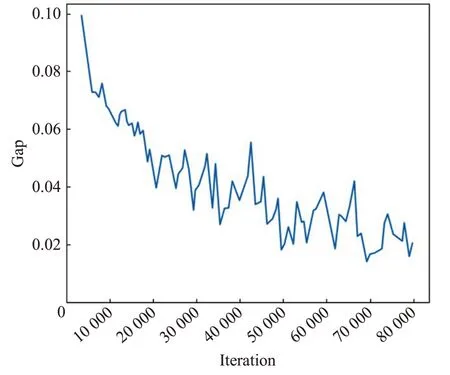
圖5 50維TSP對抗訓練過程圖Fig.5 Adversarial training process of TSP(N=50)
對抗訓練后,分別對隨機樣本、生成器所產生的對抗樣本進行測試。可以觀察到,隨機樣本和對抗樣本最終能在對抗訓練模型上取得較好的結果。同時通過預訓練模型生成的對抗樣本同樣在對抗模型上有較好的結果,證明通過對抗訓練,判別器在一定范圍上泛化能力增強。對抗訓練后的訓練結果如表2所示,對抗訓練模型與預訓練模對對抗樣本及隨機樣本的改善程度如表3所示。可以觀察到在20規模和50規模上對抗模型對對抗樣本有一定改善程度,尤其在20 規模上改善效果較為明顯,同時對隨機樣本的結果有一定削弱,改善效果要好于削弱效果,模型在原來的基礎上得到平衡。

表2 對抗訓練結果Table 2 Result of adversarial training

表3 預訓練模型對抗樣本在對抗模型上的表現Table 3 Performce of adversarial model in adversarial samples of pre-trained model
4 結語
本文提出針對組合優化問題的對抗學習框架,通過加入生成器模型,樣本生成的豐富度得到提升,進一步增強了網絡的泛化性能。在原預訓練模型上表現較差的對抗樣本,通過對抗訓練后,解的質量得到較大的提升。同時針對原判別器模型訓練方式引入一種自適應切換判別器和生成器訓練的方式,使對抗樣本能夠得到充分的擬合,同時對抗訓練后的模型對于原分布的gap值影響較小,最終整體上提升了原訓練網絡的泛化性能。
在未來工作中,將問題擴大到更大規模具有重要的實際意義。由于生成對抗樣本過程中求解標簽對問題規模的限制,通過不使用標簽的方法來得到對抗樣本也會是接下來的重點研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
