基于Albert模型的民族醫藥知識圖譜構建*
2022-09-07 12:52:18唐東昕
計算機時代 2022年9期
李 晴,唐東昕,賀 松
(貴州大學醫學院,貴州 貴陽 550025)
0 引言
中華文化博大精深,源遠流長。在醫療救治的發展過程中,五十六個民族形成了各具民族特色的防病治病的醫療方劑和用藥經驗。具有鮮明的地域性和民族性的中國少數民族醫藥是經過古人不斷切身實踐和數千次的經驗凝聚而成,是中華文化的瑰寶之一。然而有關民族醫藥的信息化資源非常稀少,只有古籍醫書記載,不便于學習和整理。將民族醫藥進行實體抽取,構建民族醫藥知識圖譜,可以方便查詢方劑的治療功效以及清楚地了解其中的關聯,便于醫護人員和研究人員高效地學習,對其進行規范性整理和保護,彰顯其民族特色,有助于推動民族醫藥的發展和傳承。
1 研究現狀
在人工智能領域中,對于醫學知識圖譜的構建始終是國內外的研究熱點。高效地將知識圖譜應用于醫學領域將給人類的醫療衛生帶來革命性的變化。張雨琪等人詳細地介紹了現有的中醫藥知識圖譜,并以知識圖譜的構建過程為主線,闡述了構建技術如何根據領域特點應用于中醫藥知識圖譜,以及其應用進展。北京大學計算語言學研究所發布的中文醫學知識圖譜CMeKG(Chinese Medical Knowledge Graph),其規模龐大,涉及醫學文本范圍廣泛。然而對于民族醫藥知識圖譜構建卻寥寥無幾,因此為保護民族醫藥的傳承和推進其不斷發展,構建民族醫藥知識圖譜有非常重要的意義。
知識圖譜是谷歌于2012 年正式提出,主要目的是為了提升谷歌的搜索質量和搜索性能。知識圖譜的定義:“A knowledge graph consists of a set of interconnected typed entities and their attributes.”即知識圖譜是由一組相互連接的類型化實體及其屬性組成。知識圖譜(Knowledge Graph,KG)作為一種用圖模型描述知識和建模世界萬物之間關聯關系的方法,通過一系列形如<頭實體,關系,尾實體〉的三元組對知識進行結構化表示。通過構建知識圖譜的方式,可以綜合分析民族醫藥方劑的治療過程,對于理解民族醫藥方劑理論,提供了高效的學習途徑。
2 方法與結果
2.1 民族醫藥數據處理
由于民族醫藥記載于古醫藥典中,因此需要將非結構化數據轉化為結構化數據,有關數據是選取于賈敏如、李星煒的《中國民族藥志要》,這本書主要涉及到44 個用藥民族,記載的藥物總共達5500 余種,民族醫藥的地域性非常明顯,其記載主要是按照如下順序:①使用的民族;②該族用的藥名或者藥物別名;③明確的藥用部位;④藥物具有正確的生物學名稱;⑤該藥物在本民族中的使用功能和主治效果。這種記載方式為后序提取文字節省精力,也便利了后序數據的整理和標注。
數據提取后整理成文本格式,刪除無效重復的數據,修改錯誤的數據,補充缺失的數據,對于中英文符號進行正確的轉換,清理文本中的停用詞以及無效字段,總共設置了如下的實體字段,具體說明見表1。
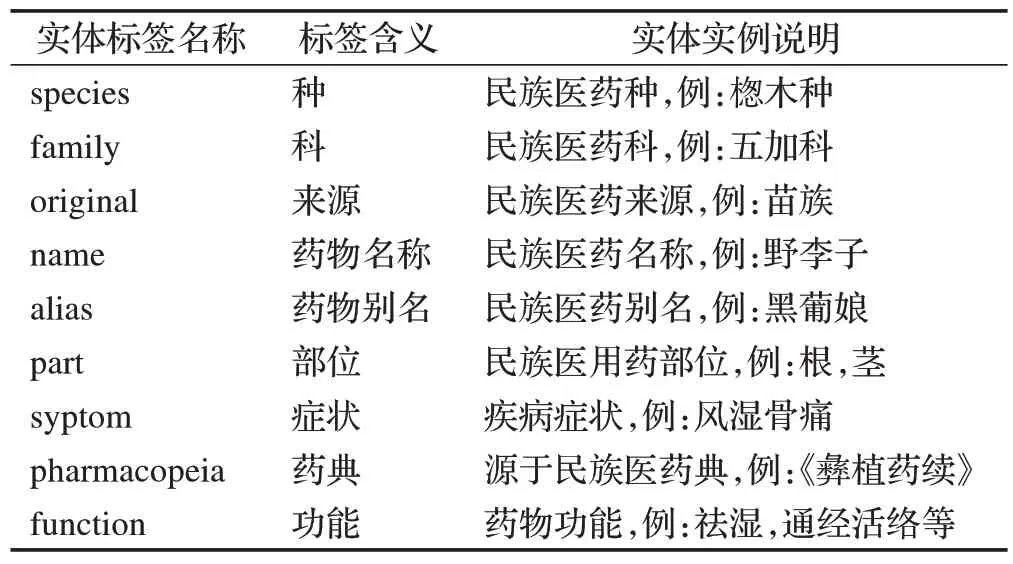
表1 民族醫藥數據字段說明
基于上述的操作,使用doccano 開源的文本標注工具進行標注。doccano主要可以進行文本分類,序列標注,以及序列到序列標注等比較常用的標注功能。民族醫藥數據集屬于文本命名實體標注范疇,對民族醫藥語料逐一進行標注。民族醫藥語料標注完成后,將數據集按照70%,20%,10%的比例隨機劃分為訓練集,測試集和驗證集,導出的數據使用相關代碼轉換為BIO三元標注方式。
2.2 基于Albert-BiLSTM-CRF模型實體識別過程
2.2.1 Albert-BiLSTM-CRF模型架構
Albert-BiLSTM-CRF 模型是進行民族醫藥專業術語的實體提取,主要包含:數據輸入層,Albert 預訓練語言模型,BiLSTM 層,CRF 層,最終是輸出層。如圖1所示。

圖1 Albert-BiLSTM-CRF模型
第一層:將預處理好的民族醫藥數據轉換為BIO格式數據輸入到模型中。
第二層:數據通過Albert預訓練語言模型,將文本轉化為動態向量,實現字符向量化。
第三層:BiLSTM 層通過獲取前后向相關的語義信息進行更深一步的語義編碼,提取文本特征,經過深層神經網絡的訓練,給出文本中各對應標簽的權重。
第四層:CRF 層根據BiLSTM 層輸出的每個實體類別標簽的概率來自動學習句子的約束條件,通過考慮文本標簽間的相關性輸出概率最大的的實體標簽序列,獲得全局最優的標簽實體。
第五層:通過CRF 層輸出的概率最大的實體標注序列來提取出民族醫藥文本中對應的實體。
2.2.2 ALBERT模型
BERT模型是谷歌于2018年提出,推動了自然語言處理領域的發展。BERT 是基于Transformer的雙向編碼表示的深度學習框架模型,Transformer 模型使用的是編碼器和解碼器的架構,編碼器是由多個網絡層疊加形成,其中主要包含多頭自注意力機制層和前反饋網絡層,這兩層又分別添加了Add&Norm 殘差模塊,將這一層的輸入信息加上輸出信息進行數據的歸一化處理和網絡子層的連接。BERT 模型使用Attention 機制能有效捕捉語句之間的雙向關系,由于BERT 模型的參數量龐大,模型訓練時間周期長,因此谷歌又推出了相較于BERT,參數量大幅度削減,輕量級的Albert模型。
Albert 模型主要是通過以下兩種方法降低模型的參數量,同時對其性能沒有造成明顯的影響。第一種方法是參數因式分解,BERT模型中的Embedding size和Hidden size是相等的,即Transformer中的輸入和輸出維度,而Albert模型中,對于詞嵌入參數進行了因式分解,將E 和H 分開設定,把原本的V*H 的大矩陣分解成了兩個小矩陣,將詞映射到低維Embedding空間E,再投影到高維隱藏空間H,則詞嵌入參數量從O(V*H)降低為O(V*E+E*H),當H 遠遠大于E 時,參數量削減非常明顯。第二種方法是跨層參數共享,BERT 模型中Transformer 每一層的參數都是獨立的,而Albert模型中,采用的是共享所有層的所有參數,再次大量縮減參數量,同時有效地提高了模型的穩定性。
Albert 模型還更改了BERT 模型中的一個子任務Next Sentence Prediction,即預測下一句損失,但由于下一句預測把主題預測和連貫性預測結合到文本任務中,而模型會傾向于關注主題來預測,并且主題預測更簡單,因此Albert 模型換成了Sentence Order Prediction,即句間連貫性預測,避免預測主題,只關注句子之間的連貫性,SOP 獲取的正負樣本均取自同一文本,正樣本是兩個連貫的語句,負樣本是交換正樣本中的兩個連貫語句的順序,SOP 只專注于預測句子之間的連貫性,使得模型能夠學習到更細粒度的區分,Albert 模型顯著地提升了下游多句子編碼任務的性能。
2.2.3 BiLSTM-CRF模型
BiLSTM-CRF 模型是由前后向LSTM 和CRF 兩個模型組合而形成的,其模型結構如圖2所示。
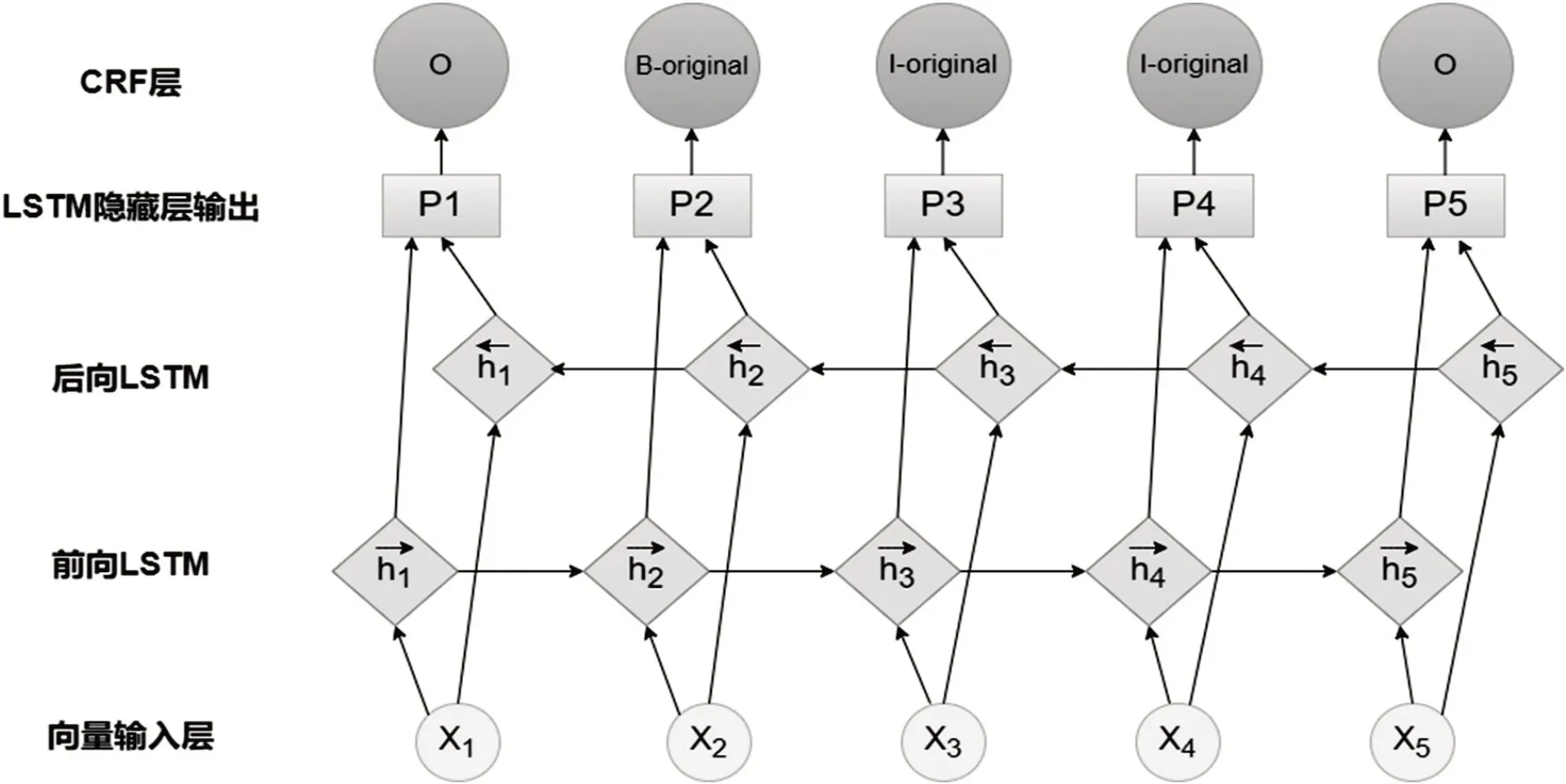
圖2 BiLSTM-CRF模型
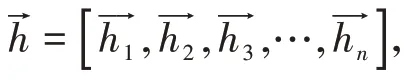
2.3 ALBBC模型實驗配置參數
2.3.1 實驗環境
實驗所采用的環境如表2所示。
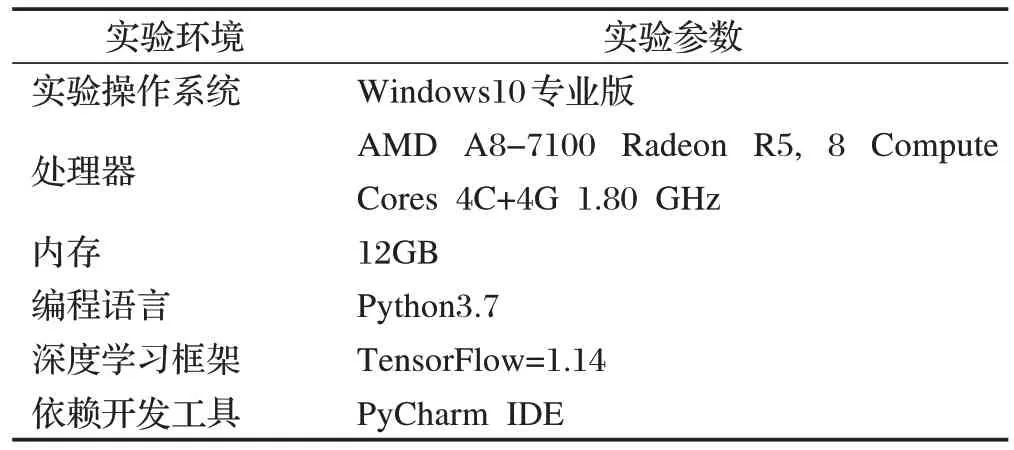
表2 實驗環境
2.3.2 Albert-BiLSTM-CRF模型參數
Albert-BiLSTM-CRF模型的實驗參數如表3所示。

表3 模型參數
2.3.3 實驗結果分析
基于模型的參數配置,圖3展示的是模型的epoch為30 時,loss 和accuracy 的變化曲線,其中訓練集和驗證集的loss基本同步下降,趨于平穩,準確率也同步提升,訓練集略微高于驗證集,說明數據在訓練集和測試集中是同分布的,在訓練集中學習到的目標特征適用于測試集,通過loss變化曲線不斷優化模型超參數,最終得到適用于數據集對應的最優參數。

圖3 ALBBC模型loss和accuracy變化曲線
實驗采用評價指標分別是精確率(Precision),召回率(Recall)和F1 值(F1-Score)來評判民族醫藥實體的識別效果,不同實體識別的效果如表4所示。
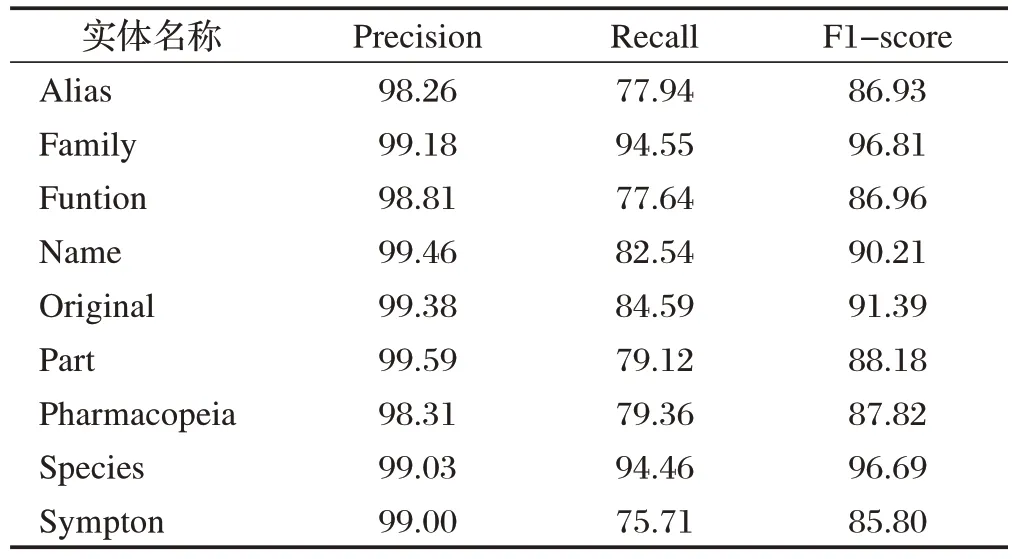
表4 實體抽取結果(單位:%)
同時為了對比本模型的有效性,選取了以下模型進行對比,取值均是經過多次實驗,取其平均值而得,如表5所示。
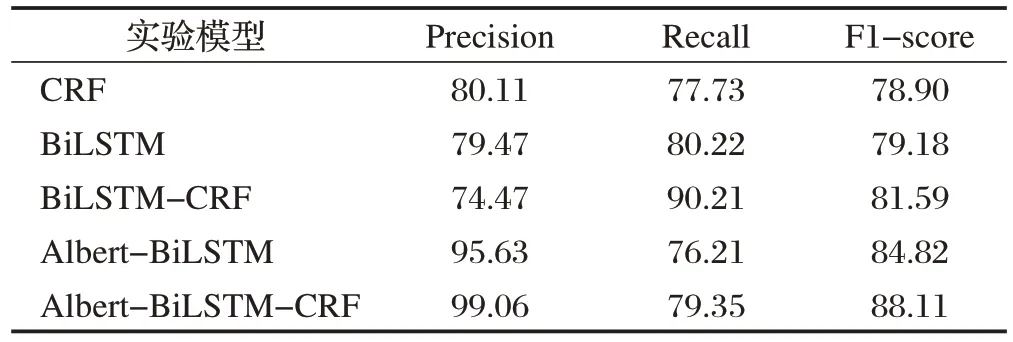
表5 不同模型的結果對比(單位:%)
表5 中展現了CRF,雙向LSTM,BiLSTM-CRF 模型,Albert-BiLSTM 模型和Albert-BiLSTM-CRF 模型的P、R、F1 值。由模型實驗對比結果可以得出,機器學習方法結果最低,BiLSTM-CRF 模型從上下文信息中高效地提取文本特征,加入Albert模型,識別效果有進一步提升,最終Albert-BiLSTM-CRF模型可以高效實現命名實體識別。
2.4 民族醫藥知識圖譜存儲及可視化
2.4.1 Neo4j圖數據庫
Neo4j是高性能的NoSQL 數據庫,同時也是目前主流數據庫中使用率較高的圖數據庫之一。Neo4j圖數據庫具備對事物的支持特性,能夠對數據的存儲進行橫向擴展,查詢語言使用Cypher并且具備強大的圖形搜索能力。Neo4j圖數據庫主要存儲數據的節點和“關系”,節點可以附帶零個或多個屬性值和“關系”,“關系”是用戶自定義實體之間的關系。
2.4.2 民族醫藥知識圖譜展示
將模型抽取的實體存儲為CSV 格式,利用Python中py2neo 模塊,將其導入Neo4j 中,通過Cypher LOAD CSV 讀取數據,在Neo4j 中直觀地展示民族醫知識圖譜,如圖4 所示。在Neo4j 中使用Cypher 查詢語句:
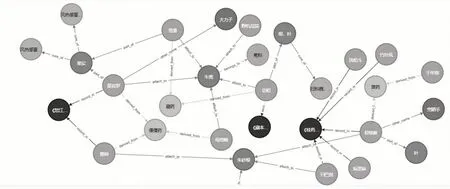
圖4 部分民族醫藥圖譜展示

其中,n1,n2 是節點,rel 是節點之間的關系,where 是過濾條件,根據自己需要查詢的信息進行篩選,return是返回需要的信息。
3 結束語
本文圍繞民族醫藥知識圖譜的構建展開,主要基于Albert-BiLSTM-CRF 模型對數據集進行命名實體識別,實體表示知識圖譜的節點,并自定義節點之間的關系,最終,通過Neo4j 實現民族醫藥知識圖譜可視化。由于Albert 模型需要大量的數據來進行訓練,而民族醫藥的數據是非結構化的,數據集有限,因此準確率還有待提高,本實驗還存在不足之處,例如還可利用知識圖譜構建民族醫藥的智能問答系統,在此領域上延伸民族醫藥的學習,挖掘更多的專業問題,更好地為學習民族醫藥提供更加高效的渠道,同時有助于積極推進民族醫藥現代化傳承與創新研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
