結合模糊熵和學習率自適應的GMM目標檢測算法
2022-09-07 03:19:12王德忠
計算機應用與軟件 2022年8期
王德忠 李 睿
(蘭州理工大學計算機與通信學院 甘肅 蘭州 730000)
0 引 言
目標檢測是計算機視覺領域中的重點研究課題,將視頻中的運動目標完整、準確地檢測出來是當前研究的難點[1]。在智能監(jiān)控視頻和無人機駕駛中目標檢測應用更加廣泛[2-3]。目前,比較完善的目標檢測算法有幀差法[4]、光流法[5]、背景建模法[6]。其中,背景建模法中的GMM算法相較于其他算法檢測更完整,實時性更好,許多研究人員基于GMM算法進行了改進。文獻[7]引入雙極學習率和組合權重區(qū)分背景和運動區(qū)域,并通過顏色特征和空間連通性消除陰影;文獻[8]針對抗噪性能差、易受動態(tài)背景干擾等問題,提出GMM算法結合超像素馬爾可夫隨機場(MRF)的檢測算法;文獻[9]用樣本有效因子的歷史累加量反映背景模型的質(zhì)量,并用于動態(tài)調(diào)整模型更新速度,同時對檢測出的前景區(qū)域進行目標分析,由分析結果間接控制模型更新。
以上算法雖然對GMM算法進行了改進,但是,仍然沒有解決以下兩個問題:1) GMM算法采用固定的高斯個數(shù)描述像素點的狀態(tài);2) 檢測不同視頻幀均采用固定的學習率更新,不能適應場景外部環(huán)境的變化。本文針對以上兩個不足之處提出基于模糊熵和學習率自適應的GMM目標檢測算法。首先,將檢測視頻幀分割為三個模糊子集,計算出每個模糊子集的模糊熵,通過確定熵函數(shù)的最大值確定最佳閾值并選取高斯個數(shù)。然后計算出檢測幀與參考幀之間相關性,通過對比背景變化因子和背景變化系數(shù)確定不同場景下選擇不同的學習率。
1 GMM算法
1.1 背景建模
GMM算法針對圖像中的每一個像素點建立K高斯分布,計算出每個像素點的灰度值μ0和方差σ0,通過加權和描述像素點的狀態(tài)。各項表達式如下:
(1)
(2)
(3)
(4)

1.2 匹配與更新
在t時刻,新觀測值xt需要與當前存在的k(1≤k≤K)個高斯模型進行匹配,當滿足式(5)時,當前像素點與高斯分布模型匹配,否則不匹配。
|xt-μi,t-1|≤2.5σi,t-1
(5)
式中:μi,t-1、σi,t-1分別為第i個高斯分布在t-1時刻的均值和方差。
(1) 若匹配,將匹配的高斯分布參數(shù)按式(6)-式(8)進行更新。
ωi,t=(1-α)ωi,t-1+αMi,t
(6)
μi,t=(1-β)μi,t-1+βxt
(7)
(8)

(2) 對于沒有匹配成功的模型,用當前幀的均值、初始化一個較大方差、較小權重的高斯模型,對于其他高斯模型,均值μ0和方差σ0均不變。
1.3 背景估計與前景分割
參數(shù)更新完成后,把K個高斯分布按ρi,t降序排列。選取前B個高斯分布作為背景像素的最佳描述模型。
(9)
式中:T為背景選取的閾值,一般取0.7~0.8。運動目標檢測時,當前幀的像素值與B個高斯背景模型分別進行比較,若像素值與任何一個模型匹配,該像素點為背景點,若不匹配,則為前景運動目標。
在視頻幀中,不同區(qū)域的變化狀態(tài)也是不同的,變化較大的區(qū)域呈現(xiàn)多峰狀態(tài),需要較多的高斯分布描述,變化較小的區(qū)域可能出現(xiàn)單峰狀態(tài),需要更少的高斯分布個數(shù)。固定的高斯分布描述不同區(qū)域的像素點,浪費了計算機的運算資源,提高了檢測耗時。高斯分布個數(shù)與閾值T有關,因此,實現(xiàn)閾值自適應,就能根據(jù)不同區(qū)域選擇合適的高斯分布個數(shù)。
2 模糊熵自適應選取模型個數(shù)
在集合論中,對象x與集合A的關系是“屬于”與“不屬于”[10],描述了確定的概念。Zadth為了描述“亦彼亦此”的模糊概念,提出了模糊集合概念[11]。按照模糊子集的理論,隸屬度函數(shù)μΩ(x)表征觀測空間Ω的模糊集合,μΩ(x)的大小反映了元素屬于模糊集的程度[12]。本文中,圖像X的灰度值x(x∈[0,255])為觀測空間,將圖像X劃分三個模糊子集A1、A2、A3,采用Logistic函數(shù)[13]描述三個模糊子集的隸屬度函數(shù),分別為:
(10)
(11)
(12)
式中:xA1(xi)、xA2(xi)、xA3(xi)分別為模糊子集A1、A2、A3中像素灰度值;L和k實驗取值為1和12;a的取值為[0,1],不同的取值會影響Logistic函數(shù)作為模糊算子時信息的丟失情況。當x為無窮時,值域在有限區(qū)間內(nèi),避免了過度增強和過度抑制,在參數(shù)上也易于獲取,本文選取a值為0.5。不同取值的Logistic函數(shù)圖像如圖1所示。
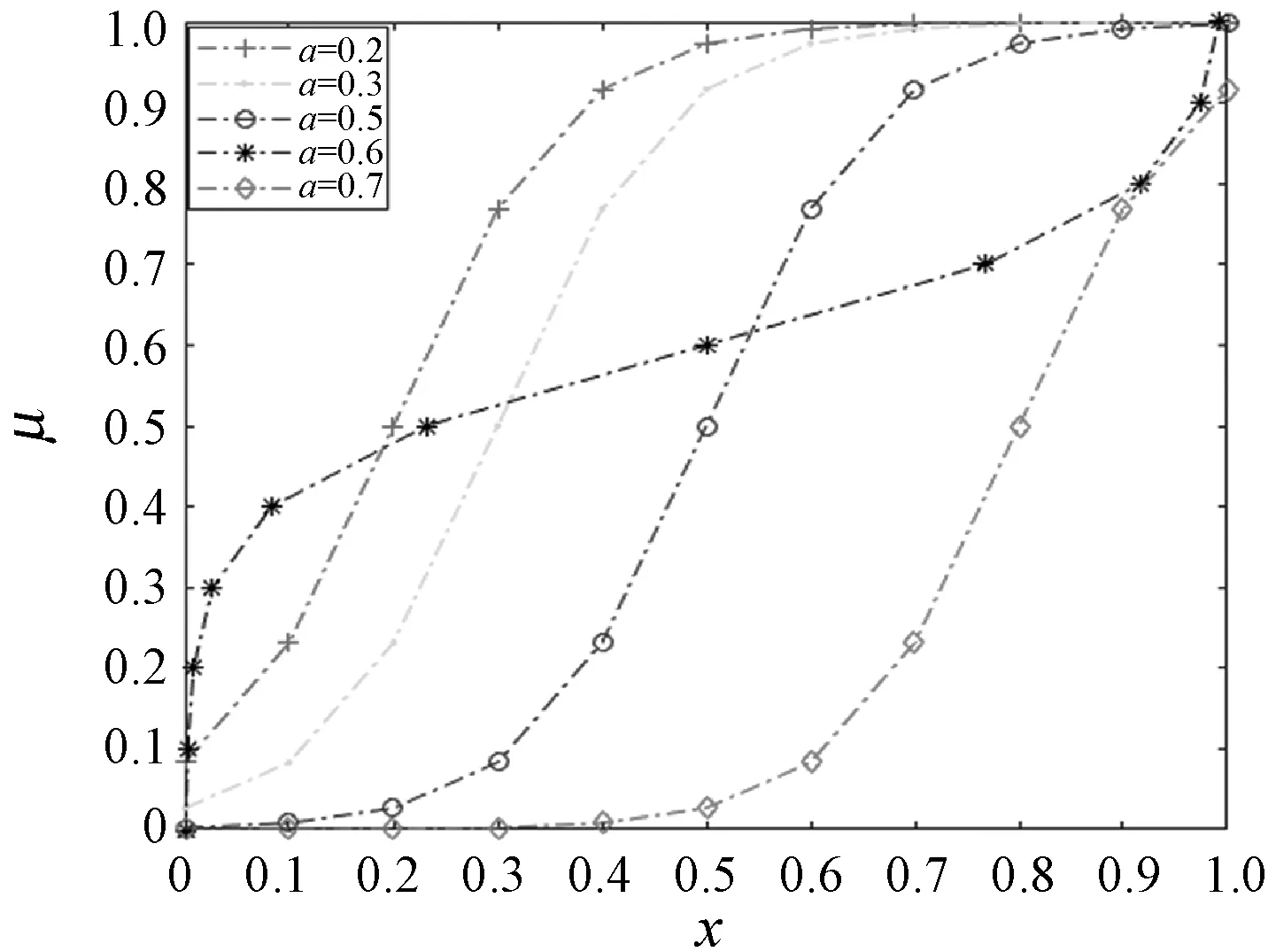
圖1 不同a值的Logistic函數(shù)曲線圖
在信息論中,熵的概念描述了研究對象的平均信息量[14]。在模糊領域中,度量模糊集合的信息量就是模糊熵,由于模糊子集的不同,圖像在不同模糊子集空間中的信息量存在差異[15]。通過最大模糊熵準則,可以確定在不同模糊子集劃分下保留圖像的最大信息量。故選用最大模熵準則確定閾值,自適應選取高斯模型個數(shù)。
假設觀測空間X上的模糊集合為Ω,根據(jù)Zadth將模糊集合Ω的模糊熵定義為:
(13)
Zadth定義的模糊熵反映了灰度直方圖和隸屬度對模糊熵的影響,對圖像的模糊度量較準確。
根據(jù)式(13)將觀測空間X的模糊熵和三個模糊子集的模糊熵分別定義為:
H(A)=H(A1)+H(A2)+H(A3)
(14)
(15)
(16)
(17)

通過式(15)-式(17)可知,模糊子集A1、A2、A3由參數(shù)t1、t2唯一確定。t1、t2將視頻幀劃分為不同變化的三個區(qū)域,分別為背景區(qū)域、噪聲區(qū)域、前景區(qū)域。其中:背景區(qū)域變化較小,甚至無變化,采用較少的高斯模型個數(shù);前景區(qū)域變化較大,需要較多的模型個數(shù);噪聲區(qū)域變化介于背景變化與目標變化區(qū)域之間,因此,模型個數(shù)的選取要按照不同區(qū)域像素點平均灰度值的關系確定。關系式如下:
(18)
(19)
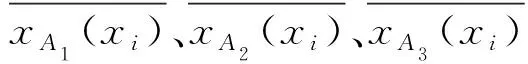
當滿足式(18)時,噪聲區(qū)域模型個數(shù)在背景區(qū)域模型個數(shù)基礎上增加1;當滿足式(19)時,模型個數(shù)增加2,噪聲區(qū)域的模型個數(shù)大于背景區(qū)域模型個數(shù),小于前景區(qū)域模型個數(shù)。式(13)取得最大值時,t1、t2為最佳分割閾值,通過閾值分割的不同區(qū)域選取合適模型個數(shù)。
3 學習率自適應環(huán)境變化
混合高斯采用固定的學習率更新背景。當學習率選擇較小時,抗干擾能力強,但是背景更新時需要更多的時間適應外部環(huán)境的變化;當學習率選擇較大時,雖然能夠快速適應外部環(huán)境的變化,但是很容易映入噪聲,降低了檢測的準確性,提高了檢測的誤檢性[16]。合適的學習率能夠適應外部環(huán)境的變化和抑制噪聲的干擾。為解決上述學習率自適應的問題,本文提出一種自適應選取學習率的方法。通過計算參考幀與檢測幀的相關系數(shù)作為學習率調(diào)整的參數(shù),然后引入背景變化因子和背景變化系數(shù),表征參考幀與檢測幀之間的背景變化和整個視頻中背景變化的情況,視頻幀相關系數(shù)為:
(20)
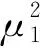
檢測幀動態(tài)背景變化因子為:
(21)
背景變化系數(shù)為:
(22)
相關系數(shù)C(I1,I2)的取值越小,表明檢測幀與相關幀之間的相關性越弱,視頻幀中背景的動態(tài)變化較大,選用較大的學習率快速適應背景的變化,C(I1,I2)的取值越大,表明兩幀之間相關性越強,背景動態(tài)變化較小,選取較小的學習率即可。本文考慮到滿足快速適應背景動態(tài)變化的同時還要抑制噪聲的引入,故最終學習率的定義如下:
(23)
式中:a1、a2、a3是調(diào)節(jié)因子,根據(jù)實驗調(diào)整得出。
算法的步驟如下:
(1) 輸入?yún)⒖紟M行模型初建,計算出前視頻幀的各項參數(shù),對像素點構造K個高斯模型。
(2) 通過模糊熵確定每一個像素點需要的高斯模型個數(shù),對已經(jīng)建立的高斯模型進行更新。
(3) 模型匹配為前景點,計算出視頻相關系數(shù)C、檢測幀動態(tài)背景變化因子γ、背景變化平均系數(shù)ζ,判斷γ和ζ的關系,如式(23)所示。模型匹配不是為前景點時,當前像素取代權值最小的高斯分布。
(4) 更新權值、方差、均值。獲得前景圖像以及權值最高的高斯模型組成背景圖像,經(jīng)過填充處理獲得前景運動目標,對檢測結果進行處理完善。算法流程如圖2所示。
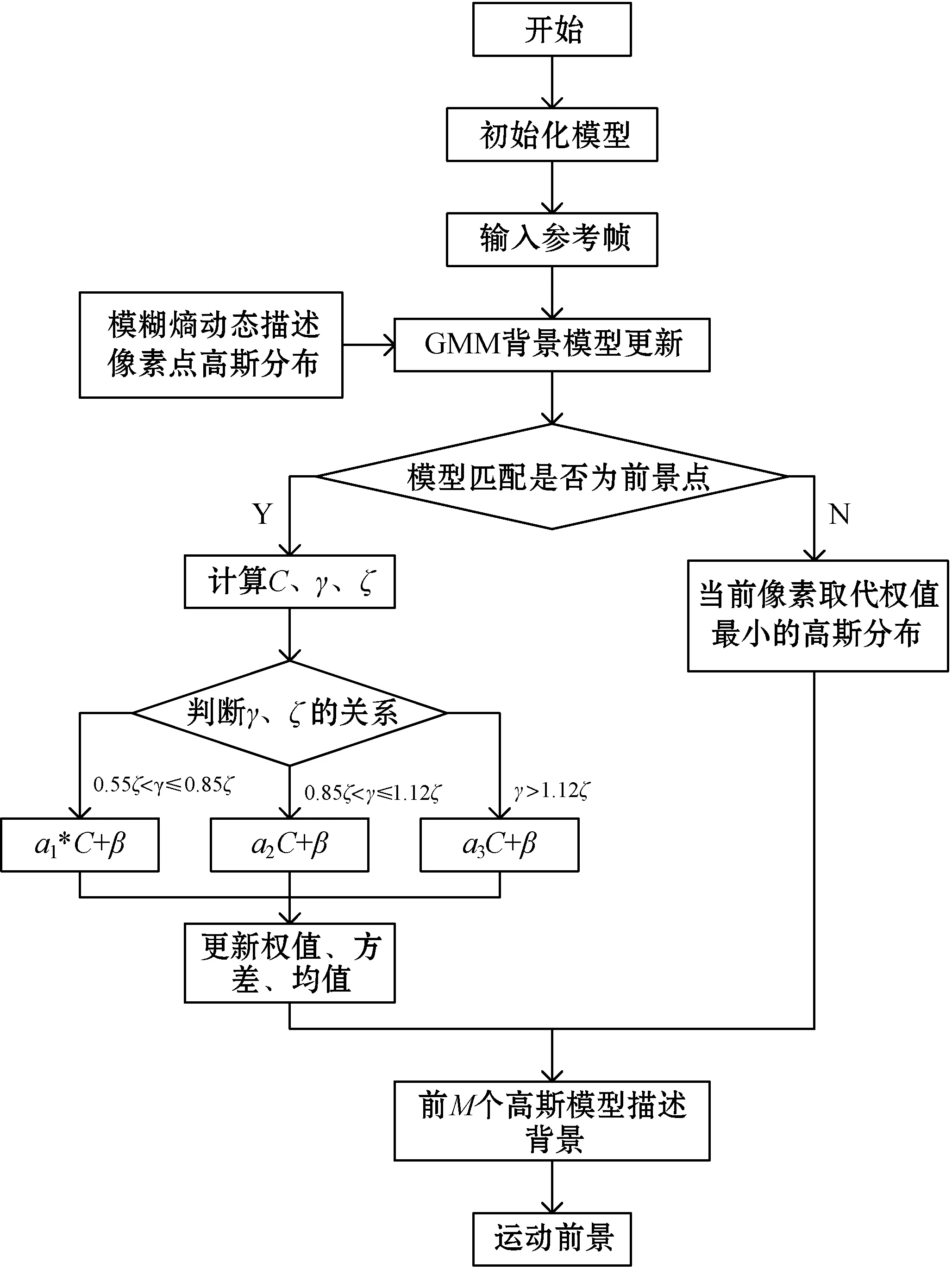
圖2 改進算法流程
4 實驗結果
文中α取值為0.017 5,實驗環(huán)境:Windows7 Inter(R) core(TM) i3 CPU M380@2.53 GHz,內(nèi)存為2 GB的PC,編程軟件為MATLAB(2015b),高斯模型的最大個數(shù)為k=5,控制參ε0為0.01。調(diào)節(jié)因子a1、a2、a3的取值分別為0.31、0.46、0.50。不同a值對處理速度和精度對比如圖3所示。
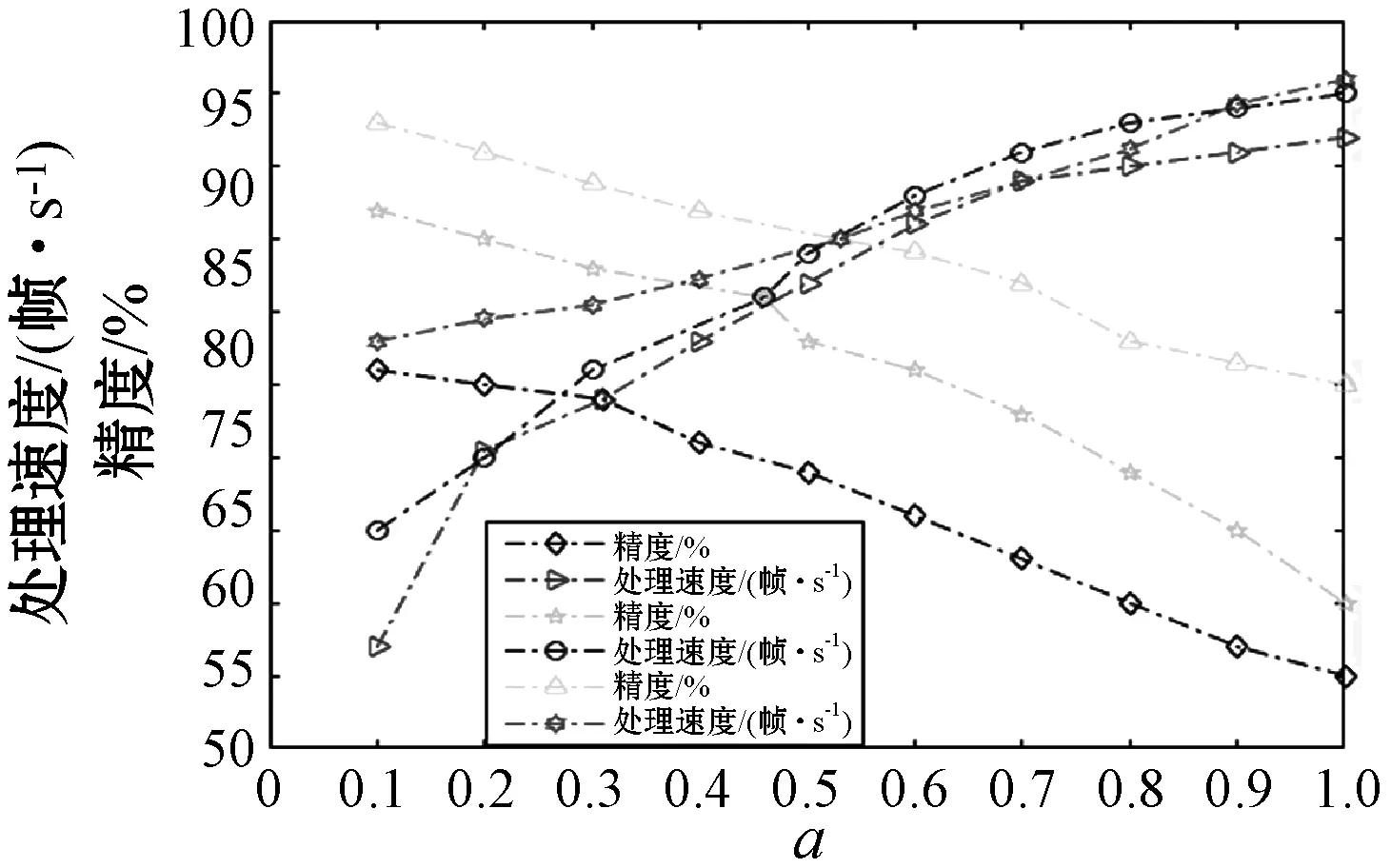
圖3 不同a值對處理速度和精度對比
選取不同的模型個數(shù)對視頻進行檢測,結果如圖4所示,可以看出:當K=3時,背景對檢測結果影響較大,GMM算法的誤檢率也比較高;K=4時,運動目標輪廓比較完整,也能夠抑制背景的影響;當K=5時,抑制背景影響效果較好,但是目標輪廓不完整;本文算法檢測出的運動目標輪廓較完整,內(nèi)部沒有出現(xiàn)空洞,運動目標完全檢測出的情況下很好地抑制了背景的影響。

(a) 原圖

(b) K=3時GMM檢測結果

(c) K=4時GMM檢測結果

(d) K=5時GMM檢測結果

(e) 本文算法檢測結果圖4 視頻1檢測結果對比
視頻中,水面的流動使得背景一直處于動態(tài)變化之中,GMM算法在學習率分別為0.001 34和0.003 52時進行檢測,由圖5可以看出:當學習率為0.001 34時,GMM算法能夠檢測出運動目標輪廓,但無法完全抑制水面波動的影響;當學習為0.003 52時,目標輪廓空洞較多,水面波動對檢測影響較大。文獻[9]中的學習率檢測時,效果均優(yōu)于以上兩種檢測結果,但是運動目標還是受到背景變化的影響。本文算法在背景波動的情況下檢測出運動目標,并且克服了水面波動對檢測結果的影響。

(a) 原圖

(b) β=0.001 34時GMM檢測結果

(c) β=0.003 52時GMM檢測結果

(d) 文獻[9]算法學習率檢測結果

(e) 本文算法檢測結果圖5 視頻2檢測結果對比
驗證算法的評價標準有很多,為了直觀地分析本文算法的各項檢測性能,針對不同視頻采取不同性能指標。視頻1采用識別率DR、誤檢率FAR、每幀節(jié)省的高斯分布個數(shù)、檢測耗時驗證算法性能。視頻2在不同學習率下采用識別率DR、誤檢率FAR、背景更新耗時三個指標對檢測結果進行定量分析。識別率DR和誤檢率FAR的表達式如下:
(24)
(25)
式中:TP為檢測出屬于真實前景的像素數(shù);FN和FP為未檢測出和錯誤檢測出前景像素數(shù)。對每一幀圖像進行多次檢測后,不同模型個數(shù)在視頻1上的識別率DR、誤檢率FAR、平均每幀節(jié)省的高斯分布個數(shù)、檢測耗時如表1所示;不同學習率在視頻2上的識別率DR、誤檢率FAR、背景更新耗時如表2所示。
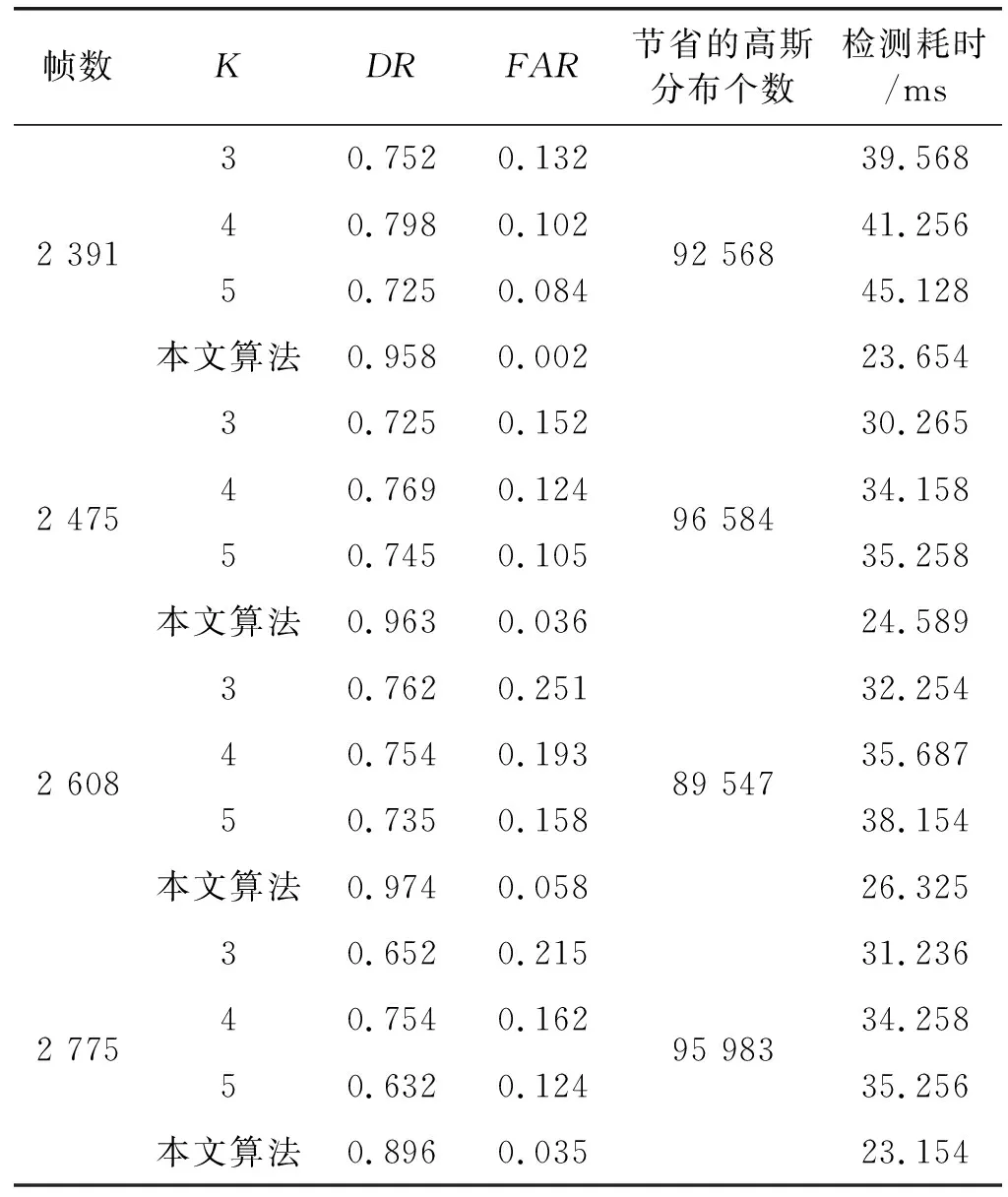
表1 不同模型個數(shù)檢測性能

表2 不同學習率檢測性能
通過表1數(shù)據(jù)分析發(fā)現(xiàn),GMM算法在不同K值下識別率和誤檢率均不同。K為3時,模型個數(shù)較少,計算機耗時較低,但是運動目標誤檢率較高;K為4時,誤檢率較高,耗時增加;K為5時,檢測耗時明顯增加,識別率較低。本文算法有效地降低了檢測耗時和誤檢率,提高了識別率,節(jié)省了較多的高斯分布個數(shù)。通過表2數(shù)據(jù)發(fā)現(xiàn),學習率不同時,檢測各項性能有較大差別。當學習率為0.001 34,識別率較高,誤檢率較低,但是背景更新耗時更長;當學習率為0.003 52時,識別率降低、誤檢率提高,但是背景更新時間降低。文獻[9]算法的檢測效果均優(yōu)于以上兩種,但是性能方面還沒有達到最優(yōu)。通過本文學習率進行檢測時,識別率提高,誤檢率降低,背景更新時間能夠滿足實時性的要求。
5 結 語
本文針對GMM算法采用固定的模型個數(shù),利用模糊子集將視頻幀分割為三部分,不同區(qū)域選擇不同個數(shù)的模型,節(jié)省每幀中高斯模型分布的個數(shù),降低計算量,提高了檢測實時性。同時為了實現(xiàn)自適應學習率,計算出檢測幀與參考幀之間的相關性,引入?yún)⒖紟c檢測幀之間的背景變化因子,與視頻幀背景變化系數(shù)作對比,從而選擇不同的學習率,不僅能夠有效地抑制噪聲干擾,還能實時地更新背景,提高檢測的準確率和實時性。接下來工作的研究重點就是在遠距離無人機拍攝的視頻下準確、完整地檢測出運動目標,并且提高算法在惡劣環(huán)境下小目標以及隱藏目標的識別率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
當代陜西(2020年14期)2021-01-08 09:30:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
光學精密工程(2016年6期)2016-11-07 09:07:19
