CLPNet:基于深度學習大規(guī)模MIMO的CSI反饋網絡
2022-09-09 01:59:58劉為波丁宇舟
無線電工程 2022年9期
劉為波,顏 彪,沈 麟,丁宇舟
(揚州大學 信息工程學院,江蘇 揚州225009)
0 引言
大規(guī)模多輸入多輸出(Multiple-Input Multiple-Output,MIMO)技術是下一代通信系統(tǒng)的核心技術之一。基站(Base Station,BS)端配置大量天線后,可以利用分集及并行接收技術極大地提升信道容量。盡管普遍采用的是時分雙工(Time Division Duplexing,TDD)操作模式,但已經證明,頻分雙工(Frequency Division Duplexing,F(xiàn)DD)大規(guī)模MIMO能夠處理由標準化帶來的低延遲需求,可能比TDD解決方案要好得多。這一特性激發(fā)并鼓勵了一些旨在減少或消除下行鏈路信道狀態(tài)信息(Channel State Information,CSI)捕獲開銷的研究。在FDD模式下,由于信道之間不存在互易性,為了在BS上實現(xiàn)預編碼的設計,設備端(User Equipment,UE)必須精確地把下行CSI反饋給BS端。然而,下行鏈路利用導頻訓練進行信道估計時,其開銷會隨著天線數量的增加呈指數性增長。因此,需要在反饋前進行CSI壓縮來減少開銷。
傳統(tǒng)的壓縮感知方法(LASSO,BM3DA-MP和TVAL3)[1-2]存在一些致命缺點,如嚴重依賴信道稀疏性假設、迭代重構信號效率低和沒有充分利用信道結構等。深度學習(Deep Learning,DL)技術的快速發(fā)展為FDD大規(guī)模MIMO系統(tǒng)中CSI的有效反饋提供了另一種可能的解決方案。CsiNet[3]首先利用機器學習方法證明了DL在CSI反饋中的有效性,這是一種新穎的CSI感知和恢復機制,可以有效地從訓練樣本中學習通道結構。CsiNet學習從CSI到接近最優(yōu)的表示(或碼字)數量的變換,以及從碼字到CSI的反變換,自然地克服了信道稀疏性前提和重構效率的局限性。在不同的壓縮率下,CsiNet的性能顯著優(yōu)于傳統(tǒng)壓縮感知(CS)方法。后續(xù)基于DL的方法大多利用了CsiNet的思想來實現(xiàn)更好的性能。Liu等[4]和Yang等[5]采用上行和下行CSI關聯(lián),這可以被視為帶有額外條件或假設的新場景。CsiNet-LSTM[6]和Attention-CSI[7]引入了長短時記憶網絡(Long Short-Term Memory,LSTM),顯著增加了計算開銷。CsiNet+[8]通過更新卷積核,在不增加額外信息的情況下提高了網絡性能,但CsiNet+的復雜性提高了很多倍。JCNet[9]和BcsiNet[10]降低了復雜度但性能也做了取舍。DN-Net[11]考慮到了實際的噪聲,提出了一種用于碼字去噪的噪聲提取單元。CRNet[12]在不增加計算復雜度的情況下優(yōu)于CsiNet。Wang等[13]提出了壓縮采樣CSI與神經網絡結合,并使用了3D卷積層,其效果優(yōu)于無采樣方法。Ji等[14]提出了偽復值網絡CLNet,將實值神經網絡模型中的實部和虛部結合起來,并采用了空間注意力模塊和通道注意力模塊。MRFNet[15]開發(fā)了一種具體多感受野和大卷積通道的神經網絡。以上大多數研究沒有考慮到編譯碼器與圖像算法的深層次結合,仿真性能和復雜度未達到理想的狀態(tài)。
本文受CLNet和MRFNet的啟發(fā),把MRFNet中編碼器部分提到的大卷積通道以及多感受野和CLNet的注意力機制進行了結合,提出了CLPNet。在譯碼器部分對大卷積核進行因子分解變?yōu)槎鄠€小卷積核,減少參數和復雜度。仿真證明,在復雜度提高很少的情況下,其性能有顯著增加。
1 系統(tǒng)模型
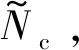
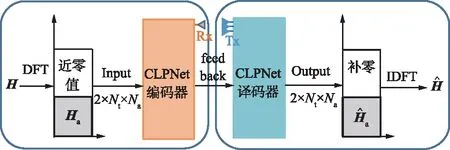
圖1 CLPNet工作流程Fig.1 Workflow of CLPNet
因此,在頻域中第n個子載波的接收信號可以表為:
(1)
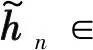
(2)
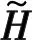
(3)
式中,F(xiàn)a∈和Fd∈Nt×Nt是DFT矩陣。對于信道延遲矩陣H,每個元素都對應一定的路徑延遲和到達角(Angle of Arrival,AOA)。在時間延遲域中,多徑到達之間的時間延遲是在有限的時間內,所以只有前幾行有非零值,其余行表示傳播延遲較大的路徑由接近零的值組成。因此,可以取前行得到矩陣Ha,不會造成太多的信息損失。接下來可以利用CSI矩陣的稀疏性來進一步壓縮。當Nt→∞時,基于CS的方法具有足夠的稀疏性,然而Nt在實際系統(tǒng)中的應用受到一定的限制,尤其是在壓縮比較大的情況下,其稀疏性不足。在本文中,考慮下行CSI反饋的編解碼網絡,將CSI矩陣Ha輸入到網絡中,UE端的編碼器部分根據給定的壓縮比η將Ha壓縮成一個長度為M的短特征向量c,然后BS端的解碼器接收碼字并將其重構為定義為CR=M/N,N即Ha的大小,本文取32×32×2=2 048。最后,通過反變換和零填充來恢復最終的H。整個反饋方案可以歸結為:
(4)
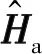
(5)
本工作只關注反饋方案,下行信道估計和上行反饋假設是理想的。此外,采用COST2100[16]模型來模擬FDD大規(guī)模MIMO系統(tǒng)的信道矩陣。
2 網絡設計
2.1 研究動機
卷積通道是一個很重要的超參數,每個通道都可以認為是一個濾波器,其參數是可學習的。卷積通道的大小和特征圖的數量緊密相連。計算機視覺[17]證明了更多的卷積通道可以捕獲更多的特征。MRFNet[15]證實了在CsiNet中壓縮比為1/4的情況下,隨著卷積通道數量的增加,室內室外環(huán)境下的性能均有提升。CRNet中證明了并行卷積層在CSI反饋中的有效性。MRFNet的實驗結果表明,大卷積核可以獲得更多的全局信息,性能有進一步的提升。CLNet編碼器端設計添加了偽復值網絡和CBAM模塊,其最后的復雜度和性能均優(yōu)于CRNet。CLNet主要是對編碼器部分進行了改進。綜合上述內容,提出了MRFNet和CLNet的優(yōu)化結構網絡——CLPNet。
2.2 CLPNet網絡
CLPNet總架構如圖2所示,為了簡單,省略了傳統(tǒng)的卷積塊。CLPNet整體來說是一個端到端的編解碼框架,主要有4個模塊,是為CSI反饋問題定制的。CSI反饋方案的性能在很大程度上取決于壓縮部分,即編碼器壓縮的信息損失越小,解壓精度越高。受UE端的計算能力和存儲的限制,深度編碼器網絡設計是難以實現(xiàn)的。因此,CLPNet的編碼器端對CLNet編碼器進行了優(yōu)化,只使用了空間注意力模塊,另使用了一個1×1的卷積塊。在2個定制塊級聯(lián)形式下,實現(xiàn)了一個復雜度較低但信息豐富的編碼器。在過去,設計CSI反饋網絡時CSI的實部和虛部是分開處理的,CSI矩陣是描述不同信號路徑的信道系數的復值。在第一個模塊,輸入的CSI首先經過偽復數值輸入層,該層將實部和虛部嵌入在一起,以保留CSI的物理信息。其次,不同的信號路徑在角延遲域中具有不同的簇效果,對應于不同的AOA和不同的路徑延遲。為了使神經網絡更加關注這些簇并抑制不必要的部分,引入了CBAM塊[18]中的空間注意力機制。
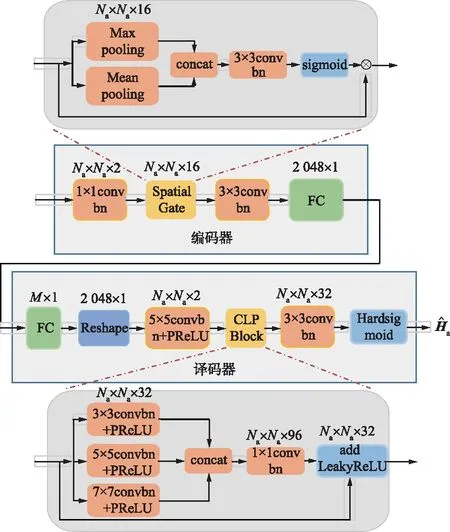
圖2 CLPNet總架構Fig.2 Overall architecture of CLPNet
2.3 編碼器
2.3.1 卷積操作
CSI矩陣是信道復系數,表示為:
(6)
式中,N為信號路徑總數;an(t)和θn(t)為在t時刻第k條路徑的衰減和相位變化。大多數的處理辦法是虛實分開,會破壞復值信道的原始物理特性。
在Encoder端進行如下操作,首先,Ftr:Ha→ρ∈Na×Na×C是一個標準的卷積操作,其中C表示卷積核的數量。給定一個輸入Fi,其通過一系列卷積變換后得到一個通道數為s2的特征。Ftr的輸出為ρ=[ρ1,ρ2,…,ρC],ρC∈Na×Na,每個卷積核f都有可學習的權重wn。CLNet的操作是通過1×1卷積核逐點卷積,這樣復系數的實部和虛部可以顯示嵌入。
卷積操作可以表示為:
(7)
式中,vc表示第c個卷積核;xs表示第s個輸入;uc表示第c個二維矩陣;下標c表示channel。
2.3.2 空間注意力塊
在角延遲域,信道系數反映了在不同分辨率下的簇效應,對應著具有特定延遲和AoAs的可分辨路徑。為了對這些簇給予更多的關注,CLPNet在編碼器部分使用了一個空間注意力模塊作為空間上的關注。如圖2上半部分的編碼器模塊所示,首先,在輸入Fi的通道C上采用平均池化和最大池化操作,生成2個2D特征映射圖,F(xiàn)avg∈Na×Na×1,F(xiàn)max∈Na×Na×1。隨后拼接2個特征映射圖生成一個壓縮的空間特性描述符Fcon∈Na×Na×2,將其與標準層卷積操作,生成2D空間注意力掩碼Fmask∈Na×Na×1,利用sigmoid函數激活掩碼,最后與原特征圖Fi相乘得到具有空間注意力的Fo,為:
Fo=Fi(σ(fc(Favg;Fmax)))。
(8)
2.4 譯碼器
CLPBlock為解碼器的主要部分。MRFNet中證明了大卷積通道的有效性,從復雜度(Flops)和性能方面綜合比較,CLPBlock中的每個卷積層的卷積通道大小為32,并有一個批歸一化(BN)函數和帶參數的PReLU激活函數。CLPBlock包含了3個不同卷積核的并行路徑,不同卷積核的大小分別為3×3,5×5,7×7。為了減少參數,5×5和7×7的卷積核通過卷積分解,分別分解為2個3×3和3個3×3卷積核的串聯(lián)形式,每個3×3卷積核后增加了激活函數使整個模型的非線性擬合能力也變強。3個通道并行輸出后進行拼接激活操作,最后通過1×1的卷積核拼接,將96的通道數減少到32并使用歸一化函數輸出,這是整個CLPBlock操作過程。卷積核的多尺度可以提取具有不同感受野下的特征,并行結構可以理解為從“復雜”輸入中提取更多信息的再提取操作,1×1卷積操作是一種特征融合和增加非線性的方法。最后,根據殘差學習的思想,添加帶有參數的LeakyRelu激活函數的相同路徑。
解碼器的輸入和輸出大小分別為M×1,2Na×Nt,頭部卷積層采用5×5卷積核性能最佳,CRNet已經證明了這一點。首先,壓縮的碼字通過FC層恢復,重塑大小為2Na×Nt,然后通過5×5卷積核串聯(lián)到CLPBlock,把卷積通道同時擴展到32通道。最后,通過一個3×3的卷積核操作后經過Hardsigmoid函數激活。由于Hardsigmoid函數沒有指數運算,因此可以減少一定的運算時間,即復雜度。
3 實驗結果與分析
3.1 實驗設置
(9)
復雜度通過Flops(每秒計算的浮點數)來衡量,epoch為1 000,batch為200。激活函數使用了帶有參數的PReLU函數、帶有泄露的LeakyReLU函數和Hardsigmoid函數。通過無錯誤反饋這個假設是合理的,因為反饋鏈路通常使用糾錯碼來保護,因此有一個非常低的錯誤率[19]。
3.2 對比分析
本方法與其他幾種只關注壓縮和恢復的方法進行了比較。不同壓縮比和在不同場景下的性能對比如表1所示。從表1可以看出,CLPNet在不同壓縮比和不同場景下的NMSE均高于其他方法的NMSE,尤其是在高壓縮比的情況下表現(xiàn)甚佳,這是因為網絡有了一個更加細化的編碼器,在空間上增加了注意力機制,即使在高壓縮比的情況下也能很好地恢復出信道矩陣。
本文對編碼器和解碼器參數數量進行了對比,如表2所示,在參數數量方面CLPNet并沒有明顯增加。但從如圖3所示的卷積通道數量與復雜度關系可以看出,隨著卷積通道的增加其復雜度有了指數性的上升,選擇32通道為一個折中情況,其復雜度并未增加太多。可以看出,整個網絡的復雜度主要來源于解碼器,如果犧牲復雜度選擇64通道,性能將會進一步提升。由于進行了卷積分解,參數相對MRFNet也有了一定的減少,并且解碼器是在BS端,可以正常部署提高性能。由表1和表2綜合得出,CLPNet編碼器復雜度增長并未太多,解碼器部分復雜度Flops相比MRFNet小很多的情況下,CLPNet的性能均超過CLNet和MRFNet兩種網絡的性能。
CLPNet,CLNet和MRFNet在1 000次迭代、壓縮比CR=1/4的室內情況下的性能曲線如圖4所示。從圖4可以看出,CLPNet網絡其收斂速度要明顯高于另外2種網絡的收斂速度,并且隨著epoch的增加,CLPNet性能依然提高。
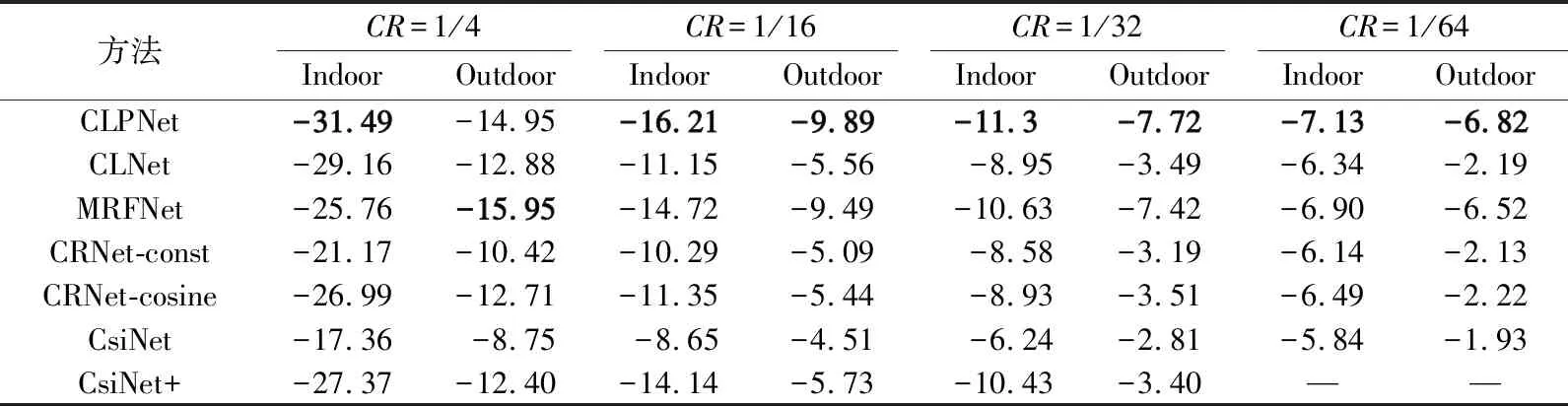
表1 不同環(huán)境下的基于DL方法的NMSE
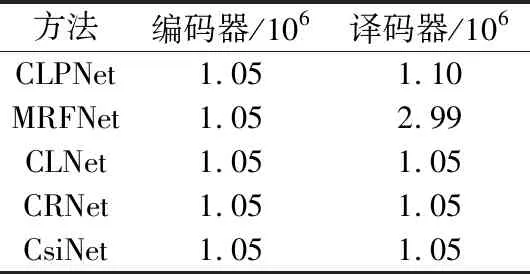
表2 編碼器和解碼器各自的參數數量
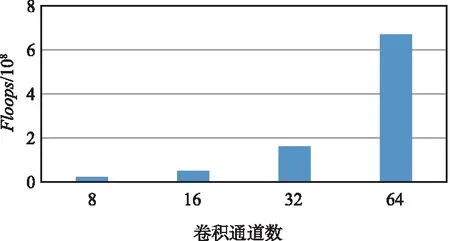
圖3 卷積通道數量與復雜度關系Fig.3 Number of convolution channels vs complexity
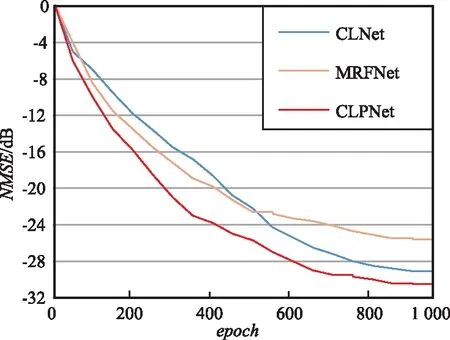
圖4 不同網絡訓練曲線Fig.4 Different network loss curves
CLNet和MRFNet兩種網絡的曲線對比可以看出,大卷積通道的優(yōu)勢在初始情況下尤為明顯,但隨著迭代次數的增加,注意力機制的優(yōu)勢慢慢明顯起來。MRFNet[15]驗證了MRF塊串聯(lián)數量增加會有進一步性能的提升,說明CLPNet通過選擇更大的卷積通道和串聯(lián)更多的CLPBlock的情況下,即犧牲更多復雜度,性能會進一步提高,最后通過實驗驗證了此猜想。
最后,本文做了2項消融研究。第1,對CLNet[14]的編碼器部分進行了消融研究,發(fā)現(xiàn)加入的SENet模塊在放入CLPNet網絡中進行訓練時,仿真性能提升不到1%,原因可能是信道矩陣對空間維度更加敏感。
第2,比較了在CR=1/4的室內環(huán)境下不同激活函數的性能比較,仿真結果如圖5所示。
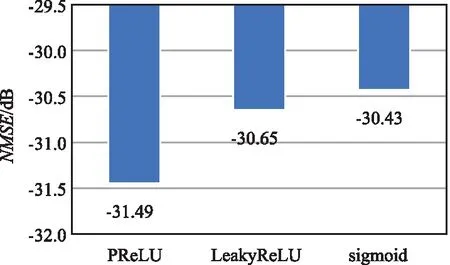
圖5 不同激活函數性能對比Fig.5 Performance of different activation functions
可以看出,帶有參數的PReLU函數相對LeakyReLU和sigmoid函數性能分別提高了2.6%和3.6%,說明帶有參數的PReLU函數更有利于網絡的訓練,并且在實際訓練記錄中顯示了其收斂速度也高于另外2種激活函數。這也證實了二值化量化聚合網絡研究[20]中的結論。
4 結束語
本文研究了5G通信系統(tǒng)下的關鍵技術,即FDD模式下的大規(guī)模MIMO的CSI反饋問題,提出了一種基于DL的網絡結構CLPNet。在整個網絡中,編碼器端的偽復值輸入層考慮到了信號的相位信息,并通過空間注意力機制分配權重增強簇的關注度;而解碼器端的網絡具有多個不同大小的卷積核提取不同特征,并具有大量卷積通道以保持豐富的信息特征。通過多個感受野的融合,可以更好地提高恢復質量。仿真結果表明,在犧牲了較小復雜度的情況下,CLPNet在不同壓縮比的情況下均得到了性能的提升。
