一種融合項目信息與信任機制的協同過濾算法
2022-09-09 15:43:58尹天賀牛存良張養碩
河北工業大學學報 2022年4期
尹天賀,牛存良,張養碩
(河北工業大學 人工智能與數據科學學院,天津 300130)
0 引言
隨著互聯網技術的飛速發展,“信息過載”已經成為傳統搜索技術不能勝任的難題,如何高效快速地在海量數據中挖掘出有價值的信息成為當今學術界研究的熱點。為了解決這一問題,推薦系統應運而生,協同過濾算法是推薦系統中應用最廣泛并且最成功的核心技術。然而,協同過濾算法面臨著嚴重的數據稀疏與冷啟動問題[1-2],這很大程度上影響了推薦系統的效率。一般而言,傳統的協同過濾算法往往基于用戶單一的歷史行為進行分析,受用戶動機和數據稀疏性干擾較強[3],基于社會學中的同質理論[4]和社交影響理論[5],將社交信任機制融入到推薦系統成為了研究熱點。Massa等[6]提出一種融入用戶顯性信任關系的推薦算法,雖然在一定程度上提高了推薦質量,但是信任關系需要用戶自己維護;Yang等[7]提出了基于用戶信任與被信任機制的社交模型,該模型考慮了用戶間信任的方向,將用戶特征映射到信任和被信任2個低維的特征空間;余永紅等[8]結合了用戶的社會地位和項目種類信息,挖掘了不同領域中用戶間的信任關系;吳賓等[9]考慮了用戶之間的影響傳播以及用戶的雙重影響,將其融入矩陣分解模型,得到了較好的推薦精度;Tang等[10]利用了社交網絡的局部與全局信息進行推薦,通過融合不同視角的社會關系提升了推薦效率。
雖然大量研究者已經考慮了用戶的社會關系,將用戶信任機制融入到推薦算法中,但忽略了2 個問題:1)在不同的領域中,用戶的信任對象是不同的,社會地位也有一定差異,通過全局信息計算出的信任度并不能很好地體現用戶在不同領域的信任與被信任程度;2)相同用戶在面對不同項目時,其偏好程度是不同的,傳統方法計算出的用戶相似度在面對不同待推薦項目時是不變的,并沒有考慮項目信息。為了解決上述問題,本文利用項目種類信息,充分分析用戶在不同領域的社會地位及其信任對象,構建特定領域的用戶信任網絡,然后將項目相似性與用戶相似度相融合,利用自適應模型計算用戶間綜合相似性,挖掘出更加精確的用戶近鄰信息。
1 推薦問題描述及協同過濾算法
1.1 推薦問題的形式化描述
假設推薦系統中含有M個用戶和N個項目,分別構成用戶集U={u1,…,um} 和項目集I={i1,…,in},其中,為用戶-項目評分矩陣[11],在評分矩陣中,rui表示用戶u對產品i的評分,通常情況下評分數據為整數,并且rui∈{0,1,2,3,4,5},評分越高代表用戶對當前項目越滿意,Iu(Iu∈I)為用戶u評過分的項目集,Uj(Uj∈U)為對項目j評過分的用戶集。在CF-PIC中,將項目按照類別進行分類,原始用戶-評分項目矩陣R根據數據集中的項目標注字段(categoryid)分為,其中k為評分數據集中項目類別的數量。
1.2 協同過濾算法的基本流程
協同過濾算法利用用戶歷史行為信息挖掘出目標用戶的最近鄰集合,根據該集合中近鄰用戶對某一項目的評價信息向目標用戶進行推薦,其一般流程包含:構建評分矩陣、獲取用戶相似度、形成近鄰、產生推薦[12],其中,如何更加客觀準確地獲取用戶相似度是當前研究工作的重點。
1.2.1 用戶相似度的計算
在協同過濾算法中,描述用戶間相似性的指標主要有2種:余弦相似度和Pearson相關系數,由于Pear?son相關系數擁有更好的中心化特性,其相較于余弦相似度擁有更加精確的衡量效果[13]。本文對Pearson 相關系數進行改進,提出融合項目信息的用戶相似度,經典的Pearson相關系數定義為
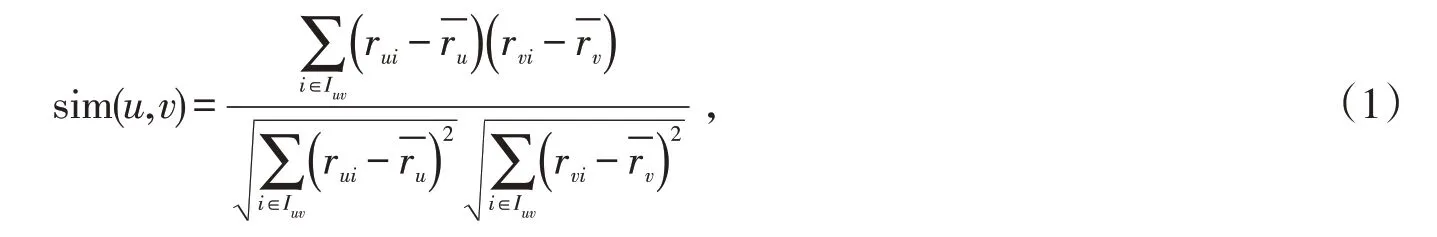
式中:Iuv表示用戶u與用戶v共同評分項目集;rui為用戶u對項目i的評分;分別表示用戶u和用戶v的評分均值。
1.2.2 評分預測
協同過濾算法認為,如果某些用戶在一類項目上擁有較為相似的評分,則認為他們在系統內的其他項目上也具有較高的相似度;根據式(1)計算出系統內用戶間相似度,構成目標用戶u的最近鄰集Su,利用Su中的用戶評分信息預測用戶u對目標項目i的評分:

2 本文CF-PIC 算法
近年來,大量研究者已經將用戶信任機制融入到推薦算法中。相較于傳統的協同過濾算法,考慮了用戶社會關系的推薦算法得到了大量應用。但是,已有的研究工作認為在各個領域內用戶的地位是相同的,并且,用戶相似度的計算方式也比較簡單,并沒有充分考慮相同用戶在面對不同項目時的偏好差異,這在很大程度上降低了推薦算法的效率。雖然鄭潔等[14]考慮了項目間的差異對于用戶的影響,但其研究局限于全局信息,在細分領域內并未研究。因此,本文充分考慮了領域間信任差異和項目間用戶相似性差異的影響,提出一種融合項目信息與信任機制的協同過濾算法(CF-PIC)。
首先,CF-PIC算法將系統內項目按照各自所屬領域進行劃分,對不同領域的數據進行獨立分析,挖掘用戶在各個領域的社會地位及推薦準確性,利用調和平均比重動態確定用戶在特定領域的綜合信任網絡;然后,根據用戶歷史評分信息度量項目間相似度,并將其融入到用戶相似度的計算中,以更加精確的區分相同用戶組面對不同項目時的相似度差異,系統獲得更加準確的用戶近鄰信息;最后,對目標用戶進行TOP-N推薦。
2.1 信任模型
本文充分考慮用戶的局部信任與全局信任信息,更全面挖掘出用戶間的綜合信任度,其中局部信任度體現了用戶間的偏好與評分水平差別。此外,研究表明用戶更傾向于“專家”的意見[15],全局信任度則體現了用戶在某個領域內的聲譽,將局部和全局信任度進行加權調和,使該算法能夠更加精確地度量用戶間的信任關系。
2.1.1 局部信任度
在之前的研究中,大部分用戶信任網絡的建立是基于用戶間共同評分或共同好友進行的,這在數據稀疏時,算法性能極度下降。陸坤等[12]認為用戶相互推薦的準確性在很大程度上能夠反映用戶間的偏好差異,但其用于判定的閾值是固定的,并不能客觀表示不同用戶對于正確推薦的定義差異,本文的局部信任度對此進行改進,將用戶間做出的正確推薦定義為正向推薦,并且將不同用戶對于某一項目的相似性融入到正向推薦的判斷中。本文的局部信任度定義如下:


2.1.2 全局信任度
一般情況下,推薦系統中用戶的評分數量越多,則其影響力越大,并且隨著評分經驗的不斷積累,其評分質量也會越來越高,更易獲得他人信任。因此,用戶的個人活躍度定義如下:


在推薦系統中,用戶評分項目數所占類目內總項目數的比重越大,或平均偏差越小,則認為用戶評分越準確,信譽度越高。用戶的全局信任度定義如下:

2.1.3 綜合信任度
綜合以上分析,同時考慮用戶的局部信任度和全局信任度,可以更加客觀準確地描述用戶間的信賴程度。因此,用戶綜合信任度定義如下:

式中:α∈[0,1] 為調和因子,由于不同用戶對局部和全局信任度的依賴程度不同,固定的調和因子不能很好地滿足系統內所有用戶的偏好需求,因此,本文采用自適應模型更新α,通過實際條件的變化動態調整全局信任度和局部信任度的比重,進一步加強系統適應性,α值的表達式如下:

2.2 融入項目信息的用戶相似度
研究表明,一組用戶在面對不同項目時,其相似度是不同的。但是,在已有的信任推薦網絡中,用戶相似度的計算方式并沒有充分結合目標項目信息,對所有待推薦項目進行評分預測時,目標用戶及其鄰居用戶的相似度是恒定不變的。例如,式(2)中用戶間的相似度在面對不同目標項目時都是sim(u,v),這種方式極大地降低了推薦系統的效率。因此本研究將項目相似性融入用戶相似性度量中。其中,項目相似性定義如下:
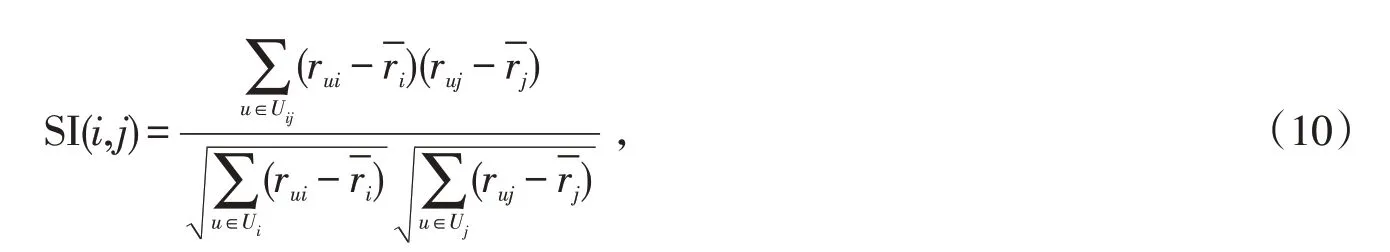
式中:Uij為對項目i和j同時評分的用戶集合;則表示項目i和項目j所獲得的所有評分均值,在計算用戶相似度時充分考慮不同項目對其值的影響,將項目間的相似度SI(i,j)融入到式(1)所示的皮爾遜相關系數中,生成融入項目信息的用戶相似度,其定義如下:
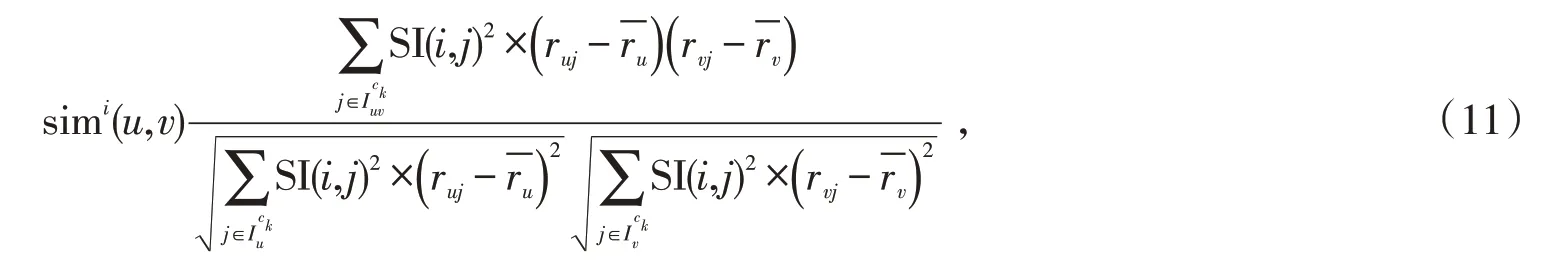
式中:ck為項目i所屬種類,用戶共同評分的種類為ck的項目集合為利用目標項目的相似度計算用戶u和用戶v在項目i上所具有的相似度simi(u,v)。一般情況下,一對用戶對于目標項目的偏好差異越小,其用戶間相似程度越高,因此,在進行評分預測時可以獲得較高的權重。
2.3 綜合相似性
本文給出的用戶綜合相似性,同時考慮了融入項目相似權重的用戶相似度和用戶綜合信任度,這兩方面在系統綜合相似性中所占的比重由調和平均比重動態決定。最終得出的用戶u和用戶v在項目i上的綜合相似性定義如下:

2.4 評分預測
將本文得出的綜合相似性替換傳統協同過濾算法中的用戶相似性,根據公式(13)對目標項目進行融入多維項目信息與用戶信任的評分預測,進而進行TOP-N推薦。

3 實驗與分析
為了驗證融入項目信息與信任機制的協同過濾算法性能,本文在真實的數據集上進行了大量實驗,并與經典的協同過濾算法和融入單一要素的推薦算法進行多維對比分析。
3.1 實驗數據集
本實驗利用真實的Epinions 數據集驗證CF-PIC算法的性能。Epinions 是國外專業的產品評論與社交網站,該網站提供了豐富的產品評分與評價信息,并在某一產品的全部評分中整理并挑選出信譽度最高的評論。Epinions 中用戶對產品的評分表示三元組為:(uid,pid,categoryid),其中categoryid 表示被評分項目的類別[16],即為本文上述中的catk值,例如,其產品按照類別分為電影類、數碼產品類和書籍類等。
本文使用的Epinions 數據集包含922 267 條評分、22 188 名用戶和296 399 個產品,其中共有27 個產品類別,用戶涉及到的產品類別數量的分布情況如圖1所示,由于用戶評分記錄遵循長尾分布,可以觀察到80%的用戶所涉及到的產品類別少于10類,這表明了單個用戶感興趣的項目類別是非常有限的,證明了本文引入項目類別信息計算用戶信任度與相似度的必要性,本文選取“Movie”,“Books”,“Education”3個類別的數據驗證本文所提出的CF-PIC算法。
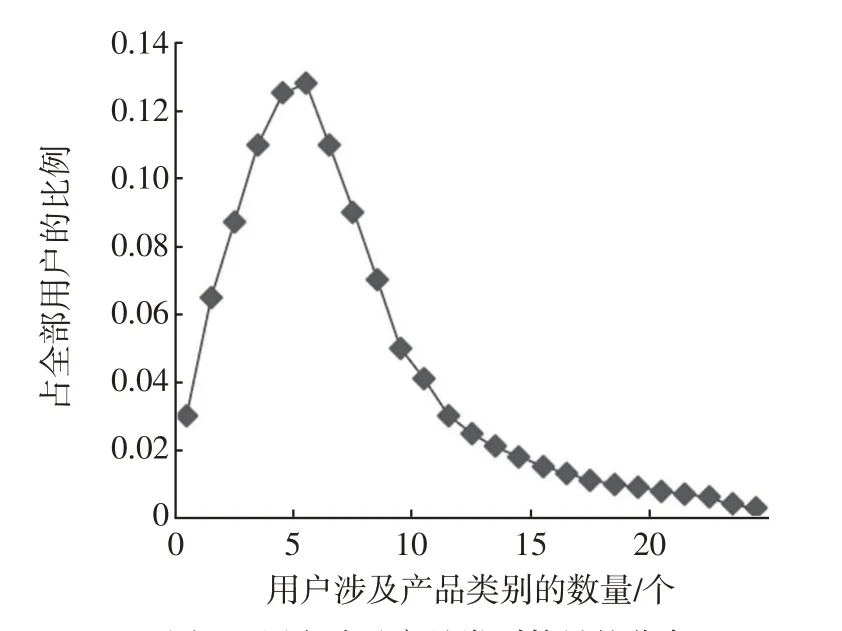
圖1 用戶涉及產品類別數量的分布Fig.1 Distribution of the number of users involved in product categories
3.2 評價指標
實驗使用當前被廣泛使用的平均絕對誤差(mean absolute error,MAE)和均方根誤差(root mean square error,RMSE)衡量各類算法的精度,MAE定義如下:

式中:N為樣本個數;MAE 表示符合條件的所有單一預測評分與全體評分算術平均值的偏差絕對值[17],MAE值越小,表明該算法擁有更好的推薦性能。RMSE則表示單一預測評分與真實評分偏差的平方與樣本個數N比值的平方根,反映了預測評分與實際評分之間的差異,RMSE定義如下:

此外,實驗對各類算法的召回率和覆蓋率進行分析,在工程領域中,召回率和覆蓋率是衡量推薦算法經濟性的重要指標,召回率表示用戶喜歡的項目被系統推薦的概率,覆蓋率表示系統所推薦項目占全部項目的比例,其大小反映了算法解決長尾問題的能力。
3.3 實驗結果及分析
根據經驗,分別在3個類目的項目中隨機選取80%的數據作為實驗訓練集,20%的數據作為實驗測試集,并且采用五折交叉驗證方法進行實驗,每組實驗獨立選取數據集和訓練集并運行5次,獲取其平均值作為該實驗的最終結果。
為了對比各類算法的性能,將本文提出的融入項目信息與信任機制的CF-PIC算法與經典的協同過濾算法CF、融入單一要素的基于用戶信任的推薦算法CF-T、基于興趣的推薦算法CF-I進行對比,依次對目標用戶選取不同的最近鄰個數K,得到各類算法在不同K值時的推薦誤差MAE與RMSE值,其對比分析結果分別如圖2和圖3所示。
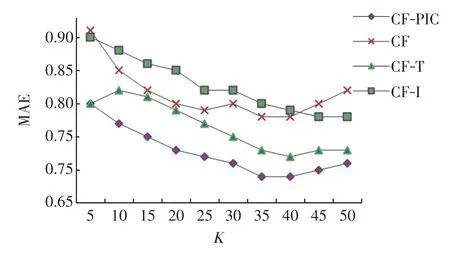
圖2 不同算法的MAE 值比較Fig.2 MAE value comparison of different algorithms
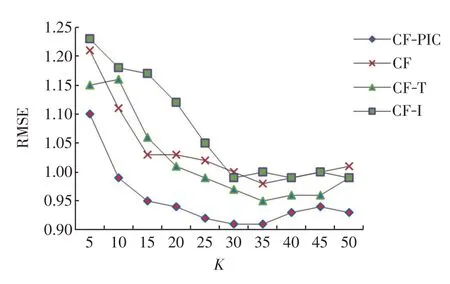
圖3 不同算法的RMSE 值比較Fig.3 RMAE value comparison of different algorithms
由圖2、圖3可知,當選取的用戶近鄰數K逐漸增大時,各個算法的MAE和RMSE值都呈先降后升的趨勢,這是由于過少的近鄰會使推薦系統所獲得的信息過于稀少,而過多的近鄰則會對推薦系統造成干擾,影響目標用戶的信息表示。本實驗中,在目標用戶鄰居數為30左右時,各類算法的MAE與RMSE值達到最優。如圖2所示,本文提出的融合項目信息與信任機制的協同過濾算法CF-PIC的MAE值最小達到了0.69,相較于傳統的協同過濾算法CF、融入信任的協同過濾算法CF-T和融入興趣的協同過濾算法CF-I分別提升了11.54%、4.2%和10.37%,如圖3 所示,本文CF-PIC 算法的RMSE 值最小達到了0.91,相較于CF、CF-T和CF-I算法分別提升了7.14%、4.21%和9.01%。
同樣采取五折交叉驗證方法,取目標用戶鄰居數為30,進一步對比各類算法的召回率與覆蓋率,如表1所示,本文提出的CF-PIC算法的召回率相較于CF-I、CF-T和CF分別提升了1.4%、1.2%和2.5%,證明了本研究通過在用戶相似度中融入項目信息可以獲得較好的用戶反饋;同樣,CF-PIC 的覆蓋率也分別提升了1.2%、0.9%和1.9%,證明了本研究在深入挖掘用戶間信任關系的同時,并沒有發生嚴重的擬合現象,反而由于充分考慮了項目的分類信息,使得覆蓋率得到了一定提高。由此可見,綜合考慮多維項目信息的情況下,將改進的用戶信任評測模型融入到協同過濾算法,可以顯著提高推薦系統的性能,證明了本研究的價值。

表1 不同算法的召回率和覆蓋率對比Tab.1 Comparison of recall rate and coverage rate of different algorithms
4 結語
為了更好地解決協同過濾算法中用戶偏好表示區分度過低和用戶信任領域模糊問題,本文結合項目的評分信息和類別信息,綜合考慮不同項目領域中用戶社會地位及推薦準確性的差異,利用調和平均比重將用戶的全局信任度與局部信任度相融合,動態的構建了用戶在特定領域的信任網絡;并且進一步將項目相似度融入到傳統的用戶相似度計算函數中,挖掘出不同項目間用戶相似度的差異。通過科學的實驗驗證,相較于傳統的協同過濾算法和融入各類單一信息的推薦算法,本文中提出的CF-PIC算法較為明顯地提高了系統的推薦準確度,使系統效率得到大幅提高。在今后的研究中,將重點挖掘時間信息和注意力機制對推薦系統的影響。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
