高分辨率遙感影像輸電桿塔智能檢測方法
2022-09-12 09:25:22宋成根張正鵬趙瑞山卜麗靜
遙感信息 2022年3期
宋成根,張正鵬,趙瑞山,卜麗靜
(1.遼寧工程技術大學 測繪與地理科學學院,遼寧 阜新 123000;2.湘潭大學 自動化與電子信息學院,湖南 湘潭 411105)
0 引言
隨著科學技術的飛速發(fā)展,工業(yè)生產水平和人民生活水平的提高,各種電器設備在人民的生活中被使用,巨大的電能消耗導致舊的電網已經不能滿足人們越來越高的生活需要。2020年數(shù)據(jù)顯示,配電網覆蓋率達到90%,輸電桿塔是承載電網重要的基礎設施,然而每年輸電桿塔都會新建、拆除以及遭受自然、人為破壞。輸電桿塔信息得不到及時的更新,將會影響電網的安全高效運行。國家電網的智能化是電網行業(yè)的共同發(fā)展目標,高壓輸電桿塔的自動檢測在國家電網的智能化中極其重要。另一方面,遙感技術快速發(fā)展,遙感影像分辨率越來越高,為遙感圖像的目標檢測開辟了更好的前景[1],同時,利用遙感影像進行大面積的輸電桿塔目標檢測可加快電網行業(yè)的智能化。但是,目前基于遙感影像的電塔檢測方法一般采用人工解譯或者是機器檢測,人工解譯需花費大量的人力物力,并且受人的主觀影響,機器檢測的方法泛化能力差,無法適應輸電桿塔的多樣性。常用的桿塔目標檢測可以分為傳統(tǒng)方法和深度學習方法。傳統(tǒng)方法采用滑動窗口進行圖片中的顏色、紋理、形狀等特征的提取,分類器根據(jù)特征對其進行分類和識別。鄒棟[2]采用直線段檢測算法(a line segment detector,LSD)和角點檢測(Harris),實現(xiàn)電塔的初定位,最后通過方向梯度直方圖特征(histogram of oriented gradient,HOG)進行支持向量機(support vector machine,SVM)分類器的訓練,采用訓練好的分類器去除偽目標,實現(xiàn)桿塔的最終定位,具有較好的識別效果。劉操等[3]通過改進的HOG特征提取方法將多通道特征進行融合,最后采用SVM對融合后的特征進行分類器訓練和車輛目標檢測。柳長安等[4]通過融合飛行機器人的GPS信息和電力桿塔的GIS信息,得到電力桿塔在飛行機器人拍攝得到的圖像中的位置,再采用可變形的組件模型(deformable part model,DPM)進行特征提取和SVM進行目標檢測識別。
近些年來,深度學習的快速發(fā)展得到廣泛關注,它能夠從海量影像數(shù)據(jù)中學習目標特征[5],為自動提取目標特征提供了一個有效的框架。自R-CNN[6]的橫空出世,之后的目標檢測逐漸進入深度學習的時代。楊知等[7]基于SAR影像對輸電桿塔的檢測,采用YOLOv2和VGG模型聯(lián)級的目標檢測算法,首先使用YOLOv2對整景的輸電桿塔進行識別,再使用VGG對識別結果進行假陽性消除,雖然提高了檢測精度,但是檢測速度大幅度下降。梁懌清[8]基于YOLOv3的高分辨率SAR影像的輸電桿塔目標檢測,將原始網絡的輸入改為適應目標尺寸大小的960×960,結合focal loss[9]思想改進損失函數(shù),改善了YOLOv3的誤檢、漏檢現(xiàn)象,但存在迭代時間長的問題。韋汶妍等[10]采用Faster R-CNN算法對輸電桿塔檢測,利用VGG16作為特征提取網絡,進行遷移學習,提高了檢測精度,縮短訓練時間但是檢測時間并沒有改善。
綜上,傳統(tǒng)的目標檢測算法由于其約束條件較多,在特定的場景下有較好的效果,環(huán)境發(fā)生變化時存在誤檢和漏檢的問題,并且存在特征構建復雜、檢測精度不高、檢測速率較低等問題,處理過程較為復雜。雖然目前深度學習目標檢測算法有一些改進,但并沒有針對密集目標的檢測進行改進,并且目前算法主要是針對SAR影像、地面拍攝影像的輸電桿塔檢測,對于高分辨率遙感影像的輸電桿塔檢測研究較少。
在數(shù)據(jù)集制作過程中發(fā)現(xiàn),同一類別的輸電桿塔大目標與小目標的特征差異較大,不同拍攝角度導致輸電桿塔呈現(xiàn)不同形狀,背景復雜且存在同一類目標相互遮擋的情況,最終導致電塔檢測不準確。因此,本文對YOLOv3算法進行改進,解決上述問題,提出了高分辨率遙感影像的輸電桿塔智能檢測方法。而且,目前公開的大型數(shù)據(jù)集如DOTA[11]、VEDAI[12]等主要包含汽車、輪船、飛機、球場等常見目標,但沒有公開的高分辨率遙感影像輸電桿塔的數(shù)據(jù)集,因此,本文制作的輸電桿塔目標數(shù)據(jù)集對后續(xù)輸電桿塔的檢測研究和發(fā)展具有重要實際應用價值。
1 輸電桿塔數(shù)據(jù)集制作
1.1 數(shù)據(jù)來源
收集了中俄邊境、江蘇省、廣州省等地區(qū)輸電桿塔的航空遙感影像共1 110景,分辨率為0.5 m,詳細參數(shù)見表1。影像數(shù)據(jù)集包含不同背景、形狀的輸電桿塔復雜情況,如圖1所示。

表1 航空遙感影像數(shù)據(jù)參數(shù)
原始影像大小為30 000像素×20 000像素,通過Python程序進行圖像裁剪,人工篩選獲取不同背景、不同成像形狀的輸電桿塔數(shù)據(jù)集。針對原始影像中輸電桿塔的尺寸特點,為了能夠更好保證輸電桿塔樣本的完整性,本文數(shù)據(jù)集圖片裁剪尺寸大小為640像素×640像素。
1.2 數(shù)據(jù)集制作
為了滿足目標檢測的通用標準格式,本文采用PASCAL VOC[13]格式標準制作輸電桿塔數(shù)據(jù)集,數(shù)據(jù)集的詳細制作過程如下。
1)利用LableImg軟件進行圖片中輸電桿塔目標的手動標注。LableImg是由Python編寫的,QT作為圖形界面,用于深度學習數(shù)據(jù)集制作的圖片標注工具。人工進行輸電桿塔的識別,使用輸電桿塔的最小外接矩形將目標選中,設置目標類別名稱為“tower”,該軟件生成與圖片對應的可擴展標記語言xml格式文件。xml文件保存了圖片中目標的類別名稱和相對應的位置信息,其中標注的矩形框如圖2(b)所示。xml文件中的(xmin,ymin)為圖2(b)標注數(shù)據(jù)示例圖中綠色矩形框的左上角坐標,(xmax,ymax)為矩形框的右下角坐標。
2)利用xml文件保存輸電桿塔在圖中的位置信息如圖2(c)所示。根據(jù)YOLOv3的訓練要求,將xml文件進行格式轉換,主要包含訓練圖片的路徑、目標坐標和目標類別信息。
1.3 數(shù)據(jù)集擴充
不同于汽車、輪船目標,輸電桿塔屬于塔狀建筑物,在影像中隨著拍攝角度的不同,輸電桿塔呈現(xiàn)出的形狀差異較大,其結構屬于空間桁架結構,背景更為復雜。由于輸電桿塔目標檢測只有一類、影像數(shù)據(jù)有限,為提高模型的泛化能力,防止訓練模型過擬合,需要對數(shù)據(jù)集進行數(shù)據(jù)擴充操作,主要采用平移、旋轉、顏色變化等方式,如圖3所示。
1.4 遷移學習
為解決數(shù)據(jù)少的問題,本文采用遷移學習進行模型的訓練。基于此,本文使用COCO[14](common objects in context)數(shù)據(jù)集作為源域,本文的輸電桿塔數(shù)據(jù)集作為目標域,使用COCO數(shù)據(jù)集學習到的模型參數(shù)來訓練YOLOv3輸電桿塔檢測模型。
首先修改網絡結構。因為COCO數(shù)據(jù)集包括80個類別,YOLOv3層輸出為255,本文的輸電桿塔檢測只有一個類別,所以將YOLOv3層輸出改為18。使用預訓練權重文件,凍結主干網絡的提取層參數(shù)不參與訓練。因為主干網絡已經使用大量的圖片訓練過具有良好的特征提取能力,所以直接將主干網絡的特征提取遷移到輸電桿塔的特征提取中。訓練其余層進行參數(shù)微調,訓練過程中損失趨于平穩(wěn)時進行解凍,全部層參與訓練,使得提取到的特征更適合輸電桿塔的目標檢測,從而實現(xiàn)源域到輸電桿塔目標域的遷移學習。與從零開始訓練相比,使用遷移學習能夠很大程度上縮短訓練時間,并且得到更好的特征提取效果,完成目標檢測任務[15]。
2 輸電桿塔目標檢測算法改進
2.1 YOLOv3算法介紹
深度學習目標檢測主要分為雙階段(two-stage)和單階段(one-stage)算法,其中two-stage目標檢測算法主要包括Fast R-CNN[16]、Faster R-CNN[17]等,one-stage目標檢測算法主要包括YOLOv1[18]、SSD[19]、YOLOv2[20]、YOLOv3[21]算法等。YOLOv3是在YOLOv1、YOLOv2基礎上進行改進,使用Darknet-53網絡,并且采用多個尺度融合的方式做檢測,對小目標的檢測精度有很大改善。其中YOLOv3是目前為止速度和精度最為均衡的目標檢測網絡,并且在目標檢測任務中性能表現(xiàn)尤為突出。
YOLOv3的特征提取網絡主要由1×1和3×3的卷積層組成,由于引入殘差結構[22]、錨點機制(anchor)和特征金字塔模塊,使得YOLOv3算法有更強的特征提取能力、更高的檢測精度以及更好的小目標檢測效果。在對416像素×416像素圖像進行特征提取過程中,借鑒特征金字塔網絡思想,分別在13×13、26×26和52×52 3個特征尺度分配3個不同大小的預選框進行預測,從而實現(xiàn)端到端的目標檢測。YOLOv3算法的損失函數(shù)由位置誤差損失(中心坐標、長寬損失)、置信度損失、類別損失[23]共3個部分組成。
2.2 先驗框選擇
YOLOv3算法的先驗框是通過COCO數(shù)據(jù)集采用K-means聚類算法得到,YOLOv3算法中的3個預測尺度分別對應3組先驗框,如(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90)、(156,198)、(373,326)分別對應52×52、26×26、13×13 3種尺度的特征圖。由于COCO數(shù)據(jù)集包含20個類別并且目標尺寸差異較大,并不適用于輸電桿塔檢測,因此采用K-means聚類算法對輸電桿塔數(shù)據(jù)集進行多次聚類求得平均聚類,結果為:(69,89)、(82,79)、(81,85)、(86,91)、(85,105)、(96,93)、(105,103)、(116,119)、(116,130)。
2.3 YOLOv3損失函數(shù)改進
YOLOv3的損失函數(shù)采用均方差作為目標框位置回歸損失,對目標尺度敏感。研究表明,IoU不僅能反映預測框與真實框的重疊程度,同時還具有尺度不變性。但是當預測框真實框沒有交集時,梯度消失不能夠進行損失優(yōu)化。當預測框與真實框重疊率相同時,IoU相同不能夠反映出重疊效果,如圖4所示,其中綠色框為真實框,黑色為預測框。
基于IoU存在的問題,Rezatofighi等[24]提出GIoU損失函數(shù)。雖然GIoU可以緩解非重疊情況下的梯度消失的問題,但是出現(xiàn)如圖5所示的情況時,3種情況下GIoU相同并且等于IoU,GIoU退化為IoU導致失效。
為此,Zheng等[25]提出DIoU損失函數(shù),使用距離優(yōu)化方式來解決GIoU的失效問題。為了加快模型訓練,本文采用CIoU進行損失優(yōu)化,CIoU考慮了目標框回歸的3個重要因素,即重疊面積、距離、長寬比。CIoU是在IoU的基礎上引入了最小外接矩形、歐氏距離、最小外接矩形的對角線、界框橫縱比。
2.4 非極大值抑制改進
在原始的非極大值抑制中使用IoU作為判斷條件來抑制多余的目標框,但由于IoU僅僅考慮重疊區(qū)域,經常會造成錯誤的抑制,特別是在預測框互相包含的情況下。因此將YOLOv3中的非極大值抑制算法中的判斷條件替換DIoU。DIoU同時考慮了重疊區(qū)域和兩個中心點距離,能夠改善目標重疊情況下的漏檢問題,從而提高目標的檢測精度,DIoU-NMS的公式參見文獻[25]。
3 實驗與結果分析
3.1 實驗設置
本實驗基于Pytorch1.2深度學習框架,編程語言Python3.6。
數(shù)據(jù)集劃分為訓練集、驗證集,比例為0.9、0.1,分別在輸電桿塔數(shù)據(jù)集中的訓練集和驗證集上進行訓練和驗證,數(shù)據(jù)集均為隨機分配。為了保證實驗的準確性,從與數(shù)據(jù)集無關的影像上重新制作測試數(shù)據(jù)集,數(shù)據(jù)集參數(shù)如表2所示。訓練參數(shù)設置:最大迭代世代100,選用Adam優(yōu)化器,前50世代批次大小設為8張影像(根據(jù)計算機性能來設),初始學習率為1E-4,后50世代批次大小設為4,學習率為1E-5。在調整為合適的參數(shù)之后,損失平穩(wěn)收斂。本文使用表2數(shù)據(jù)集參數(shù)進行訓練、驗證以及測試,改進后算法的Loss曲線和P-R曲線如圖6、圖7所示。

表2 數(shù)據(jù)集參數(shù) 張
圖6 Loss曲線的橫軸為epoch,縱軸為損失值。由圖6可知,改進后算法的損失值下降快速且平穩(wěn)收斂。圖7 P-R曲線的橫軸為召回率,縱軸為精確率。由圖7可知,改進后的算法在本文輸電桿塔測試集上的精確率和召回率均接近1,說明改進后算法的誤檢率和漏檢率都很低。本文將原始YOLOv3算法與SSD、Faster R-CNN算法進行了對比實驗,并且將改進后的算法在本文遙感影像輸電桿塔驗證集進行算法評估,其中驗證集的輸電桿塔數(shù)量為458個,各算法結果如表3所示。
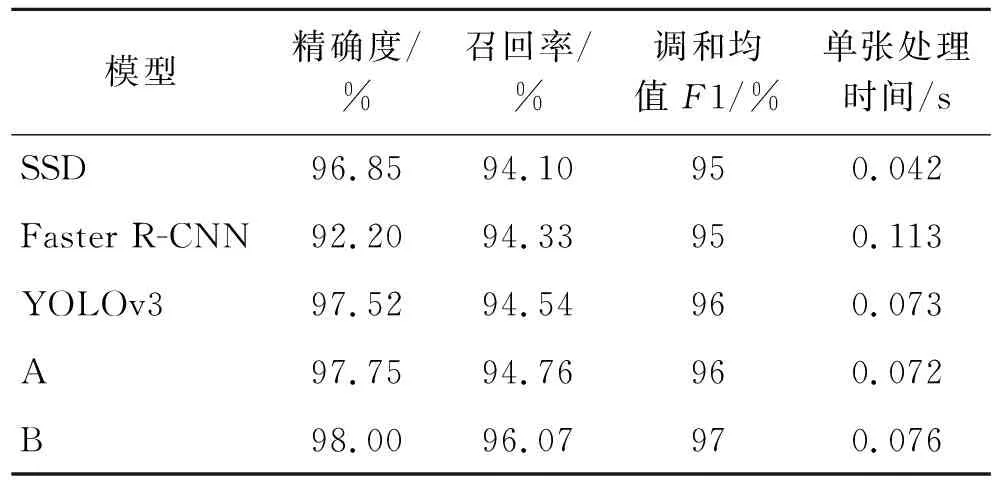
表3 各算法結果表
3.2 實驗與結果分析
由表3可知,YOLOv3算法與SSD、Faster R-CNN相比,在檢測時間相近的情況下,YOLOv3算法在各方面表現(xiàn)均優(yōu)于其他兩種算法。其中模型A是在原始YOLOv3算法上重新設置先驗框,相比原始算法,其精確度和召回率略有提升。模型B為本文改進后的算法,其精確度和召回率有小幅度提升。改進之后的算法在對輸電桿塔的檢測中提供更加精確的最小外接矩形框,對桿塔的定位提供了更準確的數(shù)據(jù),部分實驗結果如圖8所示。
由圖8(a)可知,改進的YOLOv3算法改善了輸電桿塔的誤檢。由圖8(c)可知,改進后的算法為輸電桿塔的目標檢測提供了更為精準的目標框。由圖8(b)與圖8(d)可知,改進后的算法提高了對于輸電桿塔密集目標的檢測準確度。改進后的算法對復雜背景、密集目標的高分辨率遙感影像中的輸電桿塔檢測效果有一定的提升。
4 結束語
本文提出了高分辨率遙感影像輸電桿塔智能檢測方法,在YOLOv3目標檢測算法基礎上進行改進。首先,使用平移、旋轉、顏色變化等方式進行數(shù)據(jù)擴充操作;然后,基于COCO數(shù)據(jù)集的遷移學習對YOLOv3的網絡進行參數(shù)調整;最后,通過對輸電桿塔數(shù)據(jù)集特點的分析,對先驗框進行重新聚類,對YOLOv3算法的損失函數(shù)進行了改進,并使用DIoU改進的非極大值抑制算法,在檢測過程中有效降低了目標誤檢、漏檢問題以及為輸電桿塔提供更精準的矩形框。改進后的算法在本文數(shù)據(jù)集上進行了實驗驗證。相比原始算法,改進的YOLOv3算法分別在檢測精確度和召回率上提高了0.48%、1.53%,對于變電站附近的密集輸電桿塔目標,山地、耕地的稀疏輸電桿塔目標的檢測有一定的改善,改進后的YOLOv3算法能夠更好地適應高分辨率遙感影像的輸電桿塔檢測。
總之,高分辨率遙感影像的輸電桿塔目標檢測取得了98%以上準確率的良好效果,表明深度學習算法在高分辨率遙感影像輸電桿塔檢測中的可行性,并且本文數(shù)據(jù)集的制作對后續(xù)遙感影像輸電桿塔檢測的深入研究具有一定的借鑒意義。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
海峽科技與產業(yè)(2016年3期)2016-05-17 04:32:12
