基于數據挖掘農田灌溉工程智能應用研究
2022-09-14 05:52:10吾古麗江斯特瓦地
水利科學與寒區工程 2022年8期
關鍵詞:方法
吾古麗江·斯特瓦地
(高昌區水管總站,新疆 吐魯番 838000)
農田灌溉是在農業生產的環節,我國農業用水量占全國總水量的 十分之七以上[1]。與傳統的灌溉技術相比,智能化農田灌溉系統為機井配置了遠程智能監控設備,通過智能化建設挖掘數據,準確監測并顯示地下水位變化、土壤墑情等各項信息,極大地改善了農業生產基礎條件,提高水資源的合理利用率[2]。目前國內外對精準智能化農田灌溉工程進行了相關研究,主要分為無線傳感網絡技術、模糊控制技術、物聯網技術以及專家系統控制技術[3-4],此外還有部分學者采用無線傳感網絡、BP神經網絡預測模型以及智能灌溉專家決策系統等對智能灌溉進行了研究[5-11]。然而當前的研究,很少考慮數據來源的可靠性,因此做出來的灌溉優化設計與實際具有一定偏差。本文提出了REP數據前處理方法,先對比分析了基于參考蒸散量的預處理(REP)和等水量分布(EWD)方法在建立灌溉數據庫中的優異性,之后采用人工神經網絡、支持向量機、隨機森林、邏輯回歸、決策樹對灌溉需水量的智能預測進行了分析,研究成果可為相關工程提供參考。
1 數據收集
為了建立訓練數據集,從灌區收集了三種不同類別的數據。第一種提供了灌區作物不同生長季節的總用水量信息,第二種是研究區域內氣象站監測的氣象數據,第三種是兩種類型的空間數據:(1)土地利用覆蓋圖像,提供有關作物種植的信息。(2)土壤類型圖像,提供與研究區域相關的不同土壤類型的信息。本文選擇對作物用水有重大影響的屬性,以及在整個種植季節都可用的數據,例如,“種植期”與作物用水有著密切的關系。本文的訓練集包含由各種天氣參數屬性組成的歷史數據,如最高和最低溫度、風速、濕度、降雨、太陽輻射,以及土壤類型、作物類型和作物用水,見表1。表1中的作物用水屬性稱為“類”屬性,其他所有屬性稱為“非類”屬性。數據集是一個二維表,其中列是屬性(分類和數值),行是記錄。每條記錄保存一天內相應屬性的每日平均值。土壤類型和作物類型等屬性歸類為類別屬性,而所有其他非類別屬性歸類為數字屬性。
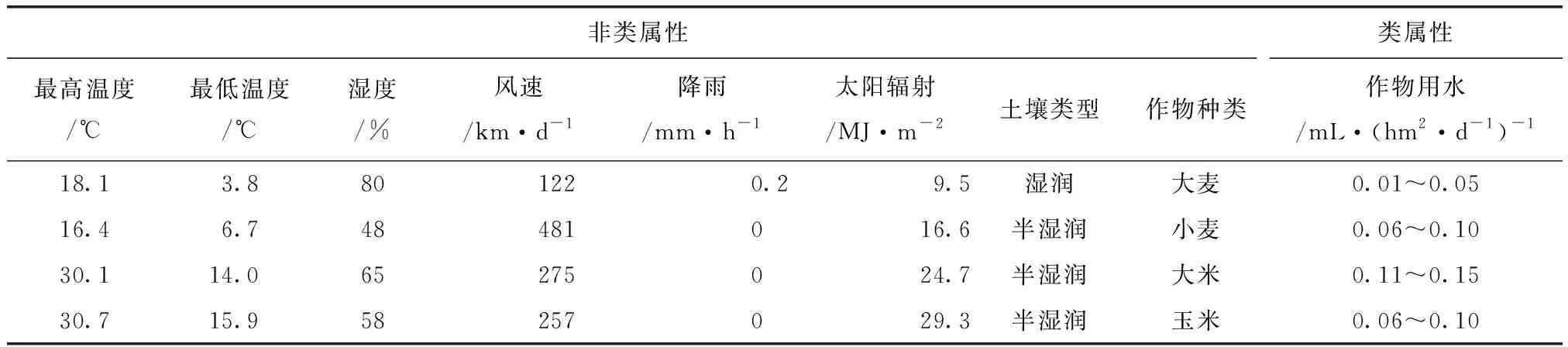
表1 各屬性組成的訓練集
2 基于REP數據預處理
第一種信息僅僅提供了灌區作物不同生長季節的總用水量信息,然而灌區并非每天供水,因此只能獲得任何特定日期的供水量信息,而無法估計特定一天作物的確切用水量。然而,為了獲得非類屬性和類屬性之間的精確關系,需要訓練數據集記錄每日作物用水量。因此,本文提出了一種數據預處理方法,稱為基于參考蒸散量的預處理(REP),用于估算農場的日常作物用水量。此外,我們還將提出的REP技術與基于等水量分布的預處理(EWD)進行了比較。在等水量分配技術(EWD)中,我們將輸送到灌區的水量除以兩次連續輸送之間的天數,可以得到每天的平均用水量。然而,如果平均分配用水,那么無論天氣條件如何,每天的用水量都是一樣的。由于實際作物用水量與天氣條件有著密切的關系,因此需要在數據集中獲得更準確的用水量數據,在精確數據集上應用分類模型來探索非類別屬性和類別屬性(作物用水)之間的精確關系。
在估計每日用水量時,考慮了參考蒸散ETo因子,作物用水量可以通過作物系數Kc和參考蒸散量ETo的乘積來計算。對于特定的生長階段,每種作物都有一個恒定的作物系數值。計算特定一天的作物用水量如下:設n為灌區連續兩次供水之間的天數,WT為n天開始時供水期間的供水量,nd中每一天的ETo值從氣象站獲得。在確定這些參數過后,計算第i天的系數xi,見式(1):
(1)
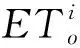
3 算法預測原理
3.1 人工神經網絡(ANN)
人工神經網絡是一種由生物啟發的,用來構建可以學習并且獨立解釋數據中聯系的計算機程序的方法。每個神經元以一組x變量(取值從1到n)的值作為輸入,計算預測的y-hat值。假設訓練集中含有m個樣本,則向量x表示其中一個樣本的各個特征的取值。此外,每個單元有自己的參數集需要學習,包括權重向量和偏差,分別用w和b表示。在每次迭代中,神經元基于本輪的權重向量計算向量x的加權平均值,再加上偏差。最后,將計算結果代入一個非線性激活函數g。其計算過程如式(2)~式(3):
(2)
yk=g(sk)
(3)
式中:角標k為第k個神經元;xj為輸入參數向量,表示未知量個數;wj,k為各參數權重;bk為閾值;yk為輸出值;g(sk)為非線性激活函數;sk為第一次進行權重分配后的輸入值。
3.2 支持向量機(SVM)
支持向量機是一種基于統計學的最先進的神經網絡方法。支持向量機算法的基礎是最大間隔分類器,最大間隔分類器雖然很簡單,但不能應用于大部分數據,因為大部分屬是非線性數據,無法用線性分類器進行分類,解決方案是對特征空間進行核函數映射,然后再運行最大間隔分類器。支持向量機的核函數映射是一種擴展特征空間的方法,核函數的核心思想是計算兩個數據點的相似度。
3.3 決策樹(DT)
決策樹是一中監督機器學習算法,該算法根據數據的特征進行逐層劃分直到劃分完所有的特征,這一過程類似于樹葉生長過程。決策樹算法可用于解決分類和回歸問題,在實際數據分析中有著廣泛的應用,比較經典的決策樹算法有CART、ID3等等。
3.4 隨機森林(RF)
隨機森林由Leo Breiman(2001)提出的一種分類算法,他通過自助法(bootstrap)重采樣技術,從原始訓練樣本集N中有放回地重復隨機抽取n個樣本生成新的訓練樣本集合訓練決策樹,然后按以上步驟生成m棵決策樹組成隨機森林,新數據的分類結果按分類樹投票多少形成的分數而定。
3.5 邏輯回歸(LR)
邏輯回歸模型的主要目標是基于訓練數據集上提取的知識預測新給定數據的標簽。邏輯回歸可以分為兩種類型:簡單邏輯回歸和多元邏輯回歸。簡單邏輯回歸用于預測類別值,因為他是分類的,并且只有兩種可能的結果,然而,多元邏輯回歸可以用來預測由三個或更多可能結果組成的類值。
4 REP與EWD前處理方法對比分析
為了評估數據預處理技術的優異,構建了兩個訓練數據集D1和D2。數據集D1使用等水量分布(EWD)方法,D2使用基于參考蒸散量的預處理(REP)方法。本文在訓練數據集上應用決策樹算法(C4.5)來提取非類屬性和類屬性之間的關系,然后將其應用于測試數據集,以測試預測準確性。之后,在D1上使用帶有反饋的三層前饋結構構建人工神經網絡,將數據集分為三部分:70%、20%和10%用于訓練、驗證和測試。網絡的訓練使用兩種不同的網絡類型,第一種是使用8個節點,1個隱藏層,第二種是使用6個節點,1個隱藏層。兩種網絡都接受了30 000次、50 000次和70 000次學習迭代的訓練。通過比較預測精度,對數據集D上的模型進行性能評估。計算時使用3折交叉驗證方法進行預測精度分析,這是一種通過將數據集劃分為三個相等部分(也稱為a倍)來測試精度的方法,其中數據集的兩部分用于訓練,第三部分用于測試。該過程持續3次,以便數據集的每個部分都用于測試一次。D總共有6070條記錄,其中2023條記錄用于每次交叉驗證中的測試。
表2為基于EWD和REP方法模型的每折的預測精度。由表可知,對于EWD方法,隨機森林方法相比其他算法預測精度都好,平均準確率為51%,而對于REP方法,在所有其他技術中,RF的預測性能仍然最好,其次是決策樹和支持向量機。其中,RF的預測準確率為78%,而DT和SVM的預測準確率分別為74%和64%,ANN和LR回歸的準確性較低,但ANN在數據集D1上的性能優于SVM。從上表還可看出,數值結果清楚地表明了基于灌溉工程和數據挖掘知識的數據預處理的有效性,REP方法處理數據的優勢明顯大于EWD方法。
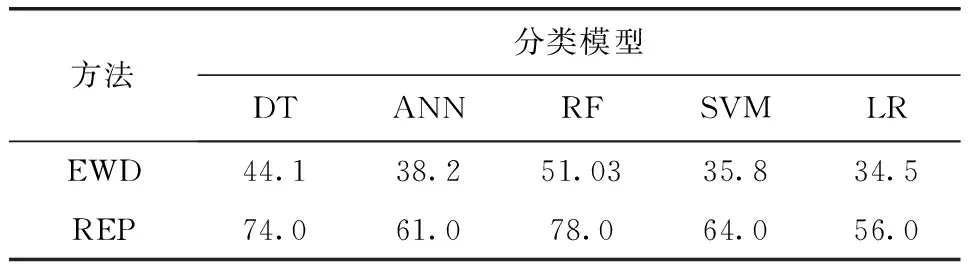
表2 基于EWD和REP方法模型的每折的預測精度
5 灌溉量預測分析
本文將6個模型均應用于灌區的每個灌溉子區域,以獲得整個種植季節的需水量,其中5個機器學習模型,1個傳統的ETo預測方法。通過將每個灌溉子區域預測需水量相加,計算每個總的需水量。為節約篇幅,只將采用RF方法的預測需水量與實際需水量之間的值給出,如圖1所示。由圖可知,RF方法在一段預測區間內均表現出良好的預測精度,實際總灌水量與預測總灌水量均保持在較小的誤差精度之內。其中,RF預測的需水量與實際耗水量更接近,準確率高達98.5%,表明該模型預測的貼近度較高。其次是DT和ANN,其準確率分別為94.0%和93.0%,這兩個指標的預測度與RF方法相差不大。從結果分析來看,本文采用的機器學習方法可為灌區的需水量預測提供較好分析工具,大幅度提升灌區用水資源配置率。
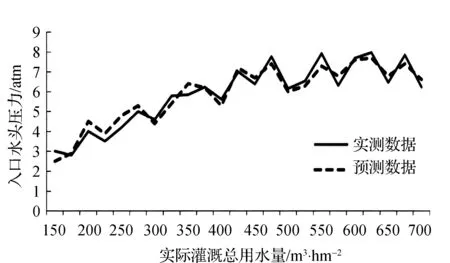
圖1 RF方法的預測需水量與實際需水量
6 結 論
本文為提高灌溉用水量預測精度,提出了一種REP數據前處理方法,先對比分析了基于參考REP和EWD方法在建立灌溉數據庫中的優異性,之后采用人工神經網絡、支持向量機、隨機森林、邏輯回歸、決策樹對灌溉需水量的智能預測進行了分析,結果表明經過REP方法處理后的數據,對后續用水量預測精度具有大幅度提升,優勢明顯大于EWD方法。此外RF預測的需水量與實際耗水量更接近,準確率高達98.5%,其次是DT和ANN,其準確率分別為94.0%和93.0%。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
