基于完全自注意力的水電樞紐缺陷識別方法
2022-09-15 06:59:38趙國川
計算機工程 2022年9期
趙國川,王 姮,張 華,龐 杰,周 建
(1.西南科技大學(xué)信息工程學(xué)院,四川綿陽 621000;2.西南科技大學(xué)特殊環(huán)境機器人技術(shù)四川省重點實驗室,四川綿陽 621000;3.清華四川能源互聯(lián)網(wǎng)研究院,成都 610000)
0 概述
水電樞紐混凝土結(jié)構(gòu)長期受到水流沖刷侵蝕,極易形成裂縫、滲漏等典型缺陷,為水電樞紐的穩(wěn)定運行帶來極大的安全隱患。目前,水電樞紐缺陷識別主要依靠人工巡檢,該方式存在周期長、效率低、風(fēng)險高等問題[1]。由于水電樞紐缺陷圖像數(shù)據(jù)具有相似干擾噪聲大、亮度不均衡、背景特征復(fù)雜等特點,導(dǎo)致基于視覺的高效、準(zhǔn)確的水電樞紐表觀缺陷識別方法的研究成為一項充滿挑戰(zhàn)性的任務(wù)。
近年來,研究人員專注于表觀缺陷自動檢測方法在道路、橋梁、管道、隧洞等領(lǐng)域的應(yīng)用研究。早期,基于顯式特征提取[2]的缺陷檢測方法通常通過手動提取缺陷的顏色、紋理、形狀等特征,并將特征送入設(shè)計的分類器,完成對缺陷圖像和正常圖像的分類。PRASANNA 等[3]提出一種用于橋梁裂縫識別的多特征分類器和機器學(xué)習(xí)分類器,雖然傳統(tǒng)基于顯式特征提取的缺陷檢測方法在缺陷識別任務(wù)上取得了一定效果,但需要手動設(shè)計特征和參數(shù),且計算步驟繁雜,在背景變化后其識別準(zhǔn)確率容易大幅降低。近年來,深度卷積神經(jīng)網(wǎng)絡(luò)(Deep Convolutional Neural Network,DCNN)在圖像分類[4-5]、目標(biāo)檢測[5]、圖像增強[6]、語義分割[7]等計算機視覺任務(wù)上取得了顯著成就,研究人員相繼提出多種深度卷積網(wǎng)絡(luò)來完成缺陷檢測任務(wù)。LEE 等[4]提出一種基于卷積神經(jīng)網(wǎng)絡(luò)和類激活映射的鋼鐵缺陷分類方法,實時診斷鋼鐵缺陷。FENG 等[5]提出一種基于Inception V3 的水利樞紐結(jié)構(gòu)損傷識別方法,利用遷移學(xué)習(xí)初始化網(wǎng)絡(luò),完成裂縫、滲水等5 種缺陷分類任務(wù)。文獻[6]在傳統(tǒng)U-Net 模型的基礎(chǔ)上構(gòu)建一種基于偏色圖像的卷積神經(jīng)網(wǎng)絡(luò)模型,不斷學(xué)習(xí)輸入圖像與輸出圖像的色彩偏差,并通過引用結(jié)構(gòu)相似性的損失函數(shù)使增強后的水下圖像與輸入的水下圖像在內(nèi)容結(jié)構(gòu)細(xì)節(jié)上保持高度相似。SUN 等[7]使用SSD 檢測網(wǎng)絡(luò)對路面裂紋進行定位及分類,并使用U-Net 網(wǎng)絡(luò)對裂紋區(qū)域進行分割,最終該網(wǎng)絡(luò)對橫向、縱向和網(wǎng)狀3 類裂紋的識別精度分別為86.6%、87.2%和85.3%。CHOI 等[8]提出SDD-Net,使用稠密空洞卷積增大卷積層感受野及降低參數(shù)量,通過特征金字塔池化模塊融合多尺度特征,大幅提升裂縫分割速度。卷積架構(gòu)為網(wǎng)絡(luò)學(xué)習(xí)提供局部相關(guān)性這一重要的歸納偏置,使網(wǎng)絡(luò)可以高效學(xué)習(xí)、迅速收斂,但該架構(gòu)獲取全局信息的能力較弱,在一定程度上限制了網(wǎng)絡(luò)性能上限。
目 前,Transformer[9]作為先進的序列數(shù)據(jù)處理模型,在機器翻譯[10]、語言建模[11]、語音識別[12]等自然語言處理(Natural Language Processing,NLP)領(lǐng)域取得了優(yōu)異成績。自注意力機制是Transformer 的核心,通過關(guān)聯(lián)每個特征點與其他特征點之間的依賴關(guān)系,形成強大的全局信息捕捉能力。受Transformer 在NLP 中取得成功的啟發(fā),研究人員開始將Transformer 應(yīng)用到圖像處理領(lǐng)域。BELLO等[13]將部分卷積層替換為自注意力層,提升了圖像分類效果,但大尺寸圖像的自注意力計算導(dǎo)致時間復(fù)雜度大幅增加,計算成本太高。WANG 等[14]提出一種循環(huán)卷積網(wǎng)絡(luò)用于場景分類,通過選擇性關(guān)注關(guān)鍵特征區(qū)域,丟棄非關(guān)鍵信息,從而提升分類性能。RAMACHANDRAN 等[15]使用自注意力機制獨立構(gòu)建網(wǎng)絡(luò),以處理視覺任務(wù)。谷歌提出一種視覺變換器(Vision Transformer,VIT)[16],完全使用自注意力機制解決計算機視覺任務(wù),在ImageNet 數(shù)據(jù)集上表現(xiàn)良好。
在水電樞紐缺陷識別過程中,網(wǎng)絡(luò)通常需要全局的視野才能準(zhǔn)確判斷是否存在缺陷及缺陷類型。深度卷積網(wǎng)絡(luò)[17]使用卷積核獲取局部感受野,通過多個卷積層堆疊獲得更大感受野,但捕捉長距離語義信息的能力仍然較弱,且網(wǎng)絡(luò)過深容易導(dǎo)致過擬合、難訓(xùn)練、參數(shù)量巨大等問題。與DCNN 不同,VIT 在進行自注意力計算時,每一個特征點都會考慮其余特征點信息,具有強大的捕捉長距離依賴能力,通過訓(xùn)練可達到自適應(yīng)調(diào)整感受野范圍的效果,因此更適合水電樞紐缺陷識別。
VIT 網(wǎng)絡(luò)首先將圖像切割為尺寸相同的圖像塊并添加序列位置信息,然后將這些序列塊送入Transformer 編碼器,最后在Transformer 的輸出過程直接完成分類任務(wù)。由于缺陷圖像具有形態(tài)多樣、尺度變化大等特點,且VIT 網(wǎng)絡(luò)在單一尺度上對分塊后的圖像塊進行自注意力計算,無法多尺度獲取缺陷圖像語義信息,因此在一定程度上限制了網(wǎng)絡(luò)對缺陷圖像的識別能力。
本文提出基于完全自注意力的水電樞紐缺陷識別網(wǎng)絡(luò)(TSDR)。受VIT 網(wǎng)絡(luò)啟發(fā),完全采用自注意力機制構(gòu)建缺陷識別網(wǎng)絡(luò),通過設(shè)計2 個不同尺寸的自注意力編碼器分支,以不同尺寸完成自注意力計算。此外,構(gòu)建一個基于類別向量的自注意力混合融合模塊,融合多尺度自注意力編碼單元提取的多尺度特征,以有效應(yīng)對水電樞紐缺陷尺度變化大、形態(tài)多樣等問題。
1 本文網(wǎng)絡(luò)
傳統(tǒng)深度卷積網(wǎng)絡(luò)使用具有局部感受野的卷積層提取圖像特征,通過全連接層輸出語義標(biāo)簽,對圖像全局信息考慮非常有限。與深度卷積網(wǎng)絡(luò)不同,本文完全使用自注意力機制構(gòu)建網(wǎng)絡(luò),通過將圖像塊序列映射至語義標(biāo)簽,以完成分類任務(wù),從而充分利用自注意力機制捕捉遠(yuǎn)程依賴關(guān)系的能力。本文提出基于完全自注意力的水電樞紐缺陷識別網(wǎng)絡(luò),其結(jié)構(gòu)如圖1 所示。可以看出,本文網(wǎng)絡(luò)由線性嵌入層、多尺度自注意力編碼器和多層感知機3 部分組成,其中多尺度自注意力編碼器包括多尺度自注意力編碼單元和自注意力混合融合模塊。線性嵌入層將圖像分為不重疊的圖像塊并添加位置編碼,多尺度自注意力編碼單元采用2 條分支提取不同尺度自注意力特征,通過自注意力混合融合模塊融合多尺度自注意力特征,提升語義表達能力,將融合后的自注意力特征送入多層感知機獲得分類結(jié)果。

圖1 本文網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Structure of network in this paper
1.1 線性嵌入層
如圖1(a)所示,線性嵌入層位于網(wǎng)絡(luò)前端,對缺陷圖像進行分塊操作,可以得到不重疊且尺寸固定的圖像塊,將其映射為嵌入向量,再添加類別向量和位置編碼。標(biāo)準(zhǔn)Transformer 輸入是一維序列,為了使其能夠處理二維圖像數(shù)據(jù),線性嵌入層首先將圖片X∈RH×W×C分為二維圖像序列塊Xp∈RN×P2×C。其中:(H,W)是圖片的分辨率;C是圖像通道數(shù);(P,P)是每個圖像塊的分塊尺寸;主分支PL=16;副分支是圖像塊的數(shù)量。通過可學(xué)習(xí)嵌入矩陣e將圖像序列塊線性投影至一維嵌入向量,形狀為1×D,其中D是嵌入向量深度,主分支為768,副分支為384,并增加一個與嵌入向量形狀相同的可學(xué)習(xí)類別向量xclass與嵌入向量并列送入多尺度自注意力編碼器。由于在分割圖像塊的過程中容易丟失圖像塊之間的位置關(guān)系,為保持圖像塊的空間排列,每一個嵌入向量和類別向量都需要加入位置編碼Epos∈R(N+1)×D,最后得到具有標(biāo)記的嵌入圖像序列z0,其表達式如式(1)所示:

已知VIT 網(wǎng)絡(luò)中一維和二維的位置編碼分類效果幾乎相同[16],因此,本文采用計算簡單的一維位置編碼保存圖像嵌入序列的位置信息。
1.2 多尺度自注意力編碼器
將線性嵌入層輸出的圖像嵌入序列作為多尺度自注意力編碼器的輸入。圖像塊分辨率直接影響自注意力網(wǎng)絡(luò)的缺陷識別準(zhǔn)確率和復(fù)雜度,低分辨率圖像塊可以為自注意力網(wǎng)絡(luò)帶來更高的識別準(zhǔn)確率,但同時會帶來更大的計算量和內(nèi)存占用。因此,本文提出多尺度自注意力編碼器,設(shè)計雙分支結(jié)構(gòu)對2 種不同分辨率圖像塊進行自注意力計算,2 個分支以類別向量為標(biāo)識進行多尺度混合融合,獲得分類預(yù)測結(jié)果。
圖1(b)所示為多尺度自注意力編碼,可以看到,該編碼器由K組多尺度自注意力編碼單元和自注意力混合融合模塊級聯(lián)組成。每個多尺度自注意力編碼單元包括2 條自注意力編碼分支:主分支使用16×16 大尺寸圖像塊、嵌入向量深度為768、4 個自注意力編碼單元;副分支使用14×14 小尺寸圖像塊、嵌入向量深度為384、1 個自注意力編碼單元。自注意力混合融合模塊將一個分支的類別向量與另一個分支的嵌入向量進行自注意力計算,融合多尺度特征。
1.2.1 多尺度自注意力編碼單元
圖2 所示為多尺度自注意力編碼單元結(jié)構(gòu),由2 個自注意力編碼單元組成。如圖2(a)所示,自注意力編碼單元完全依靠自注意力機制實現(xiàn),由L個相同層組成,每一層主要由多頭自注意力層(Multi-Head Self Attention,MSA)和多層感知器(Multi-Layer Perceptron,MLP)2 個組件組成。其中,多層感知器由2 個全連接層和中間的GeLu 激活函數(shù)組成,2 個組件均采用殘差結(jié)構(gòu),并在前端使用層歸一化。MSA 和MLP 的表達式分別如式(2)和式(3)所示:


圖2 自注意力編碼單元結(jié)構(gòu)Fig.2 Structure of self-attention encoder unit
圖2(b)所示為多頭自注意力層,是自注意力編碼單元的核心組件,由線性層、自注意力頭、連接層及最后的線性映射層組成。自注意力頭通過計算圖像嵌入序列中每個元素與其他元素的相關(guān)性,從而完成自注意力計算。計算方法如下:首先,自注意力頭將嵌入圖像序列z0中的每個元素與3 個可學(xué)習(xí)的自注意力權(quán)重矩陣(Wq,Wk,Wv)相乘(如式(4)所示),生成(q,k,v)3 個值,通過計算(q,k,v)的點積學(xué)習(xí)自注意力權(quán)重;然后,自注意力頭計算嵌入圖像序列中元素q向量與其他元素k向量之間的點積,確定該元素與其他元素的相關(guān)性,再將點積的結(jié)果縮放后送入softmax(式(5)),其中縮放因子Dk為注意力權(quán)重矩陣Wk的維度;最后,自注意力頭將嵌入圖像序列所有元素的v向量乘以softmax 的輸出,獲取注意力得分最高的序列,完成自注意力計算(式(6))。多頭自注意力層采用12 個自注意力頭堆疊而成,并行執(zhí)行以上自注意力計算過程,并將結(jié)果拼接后通過可學(xué)習(xí)的線性映射層投影到高維空間(式(7))。

1.2.2 自注意力混合融合模塊
令xi為分支i的嵌入圖像序列(包括類別向量和嵌入向量),i表示分支L或者分支S,分別表示i分支的類別向量和嵌入向量。為有效獲取多尺度特征,自注意力混合融合模塊首先將每個分支的類別向量作為標(biāo)識,與另一分支的嵌入向量進行自注意力計算,再投影回所屬分支。由于類別向量已經(jīng)在所屬分支的所有嵌入向量中學(xué)習(xí)到充分的語義信息,因此與另一個不同尺寸分支的嵌入向量進行自注意力計算可以學(xué)習(xí)該分支不同尺度特征,實現(xiàn)多尺度特征融合。類別向量在與另一分支融合多尺度特征后,在下一個自注意力編碼單元中可以將從另一分支學(xué)習(xí)到的語義信息傳遞給所屬分支的嵌入向量,豐富所屬分支的語義信息。主、副分支以相同方法進行自注意力融合過程,如圖3 所示為主分支L的自注意混合融合模塊,下面將以圖3 為例詳細(xì)分析融合過程。

圖3 自注意力混合融合模塊Fig.3 Self-attention fusion module

其中:fL(·)為線性投影函數(shù),能夠?qū)⒅鞣种ь悇e向量經(jīng)過線性投影變換至副分支嵌入向量形狀。然后,將相乘(如式(9)所示),生成(q,k,v)。最后,計算向量q和向量k的點積并將其送入softmax 函數(shù)中,再將結(jié)果與向量v相乘,獲得融合后的類別向量CA(x'L),完成自注意力融合計算,該過程的計算表達式如式(10)所示:

2 實驗結(jié)果與分析
本節(jié)驗證本文提出的基于完全自注意力的水電樞紐缺陷識別方法的有效性。首先,設(shè)計一系列消融實驗評估多尺度自注意力編碼單元和自注意力混合融合模塊的性能;然后,調(diào)整多尺度自注意力編碼器超參數(shù),測試本文方法不同體積模型的性能;最后,與一種機器學(xué)習(xí)方法和3 個經(jīng)典深度卷積網(wǎng)絡(luò)進行對比實驗。
2.1 數(shù)據(jù)集
本實驗選取的缺陷數(shù)據(jù)集由清華四川能源互聯(lián)網(wǎng)研究院提供,通過壩面無人機[18]和隧洞機器人[19]搭載多種傳感器在四川某水電站壩面、引水隧洞、泄洪洞、消力池廊道等樞紐結(jié)構(gòu)處采集數(shù)據(jù)。數(shù)據(jù)集共有18 605 張分辨率為224×224 像素的RGB 圖像(如表1 所示),包含無損、裂縫、滲漏、露筋和脫落5 個類別,每個類別包含3 700 余張圖像樣本,所有樣本均由水利專家進行標(biāo)注。實驗過程中訓(xùn)練集、驗證集、測試集的比例為8:1:1,其中驗證集和測試集采取不放回隨機抽取策略,抽取完成后剩余的數(shù)據(jù)組成訓(xùn)練集。

表1 數(shù)據(jù)集分布Table 1 Distribution of dataset
2.2 實驗環(huán)境及方法
為了對本文方法的有效性進行合理評估,所有實驗硬件、軟件環(huán)境和實驗方法均保持一致。
硬件環(huán)境:中央處理器(Central Processing Unit,CPU)和圖像處理器(Graphics Processing Unit,GPU)分別為Intel?Xeon?CPU E5-2620 v4 @ 2.10 GHz 和2 塊NVIDIA GTX TITAN Xp,24 GB;系統(tǒng)內(nèi)存是32 GB。
軟件環(huán)境:操作系統(tǒng)采用Ubuntu18.04;編程語言為Python 3.6;深度學(xué)習(xí)框架為Pytorch 1.8.0、CUDA 10.2。
訓(xùn)練參數(shù):優(yōu)化器采用學(xué)習(xí)率為0.000 1 的Adam 方法,使用預(yù)熱的方法動態(tài)調(diào)整學(xué)習(xí)率,批處理大小為32。
2.3 訓(xùn)練圖像預(yù)處理
針對水電樞紐缺陷圖像亮度差異大、背景干擾噪聲復(fù)雜、獲取難度高、可用圖像少等問題,本文采用隨機亮度調(diào)整、翻轉(zhuǎn)、擦除、混合和剪切混合[20]共5 種圖像增強增廣策略處理訓(xùn)練集圖像,為網(wǎng)絡(luò)提供具有挑戰(zhàn)性的樣本,提高模型泛化能力。針對訓(xùn)練集中每張缺陷圖像,以上5 種圖像增強增廣策略獨立發(fā)生,發(fā)生的概率為0.5,訓(xùn)練集中5 類原始缺陷圖像共計14 889 張,經(jīng)圖像增強增廣策略后,增加缺陷圖像共計37 222 張,最終訓(xùn)練集缺陷圖像共計52 111 張。驗證集和測試集不進行圖像增強增廣操作。
圖4 所示為各類典型樣本的預(yù)處理效果,圖4(b)和圖4(c)分別為隨機亮度調(diào)整和翻轉(zhuǎn)操作,分別屬于常用顏色空間變換和幾何變換的圖像預(yù)處理方法。
生病時,每個人都想在能力范圍內(nèi)找到最合適的治療方案,盡早擺脫疾病的困擾。但因看病耗時費力等現(xiàn)狀,讓很多患者習(xí)慣在就診前托熟人、選醫(yī)院、尋良藥……其實,有很多顧慮都是我們的心理作用,有時,我們大可不必“小題大做”,按常規(guī)診治,照樣可以找回健康。

圖4 各類典型樣本的預(yù)處理效果Fig.4 Pretreatment effect of various typical samples
圖4(d)所示為擦除操作,將缺陷圖像中的隨機區(qū)域替換為隨機大小的黑色像素。該方法鼓勵模型從缺陷圖像全局的上下文中學(xué)習(xí),而不依賴于特定局部特征,可有效緩解缺陷識別過程中的遮擋問題。圖4(e)所示為混合操作,將2 個同類缺陷圖像進行線性組合,生成新的訓(xùn)練樣本。該過程的表達式如式(11)所示:

設(shè)(Xi,yi)和(Xj,yj)是從訓(xùn)練集中隨機抽取的2 個樣本,將2 個樣本進行線性插值,獲得新樣本,以增強模型應(yīng)對水電樞紐缺陷識別中復(fù)雜背景干擾噪聲的魯棒性。
圖4(f)所示為剪切混合操作,將缺陷圖像中隨機區(qū)域替換為同類別另一張缺陷圖片相同大小區(qū)域。上文提到的擦除方法會出現(xiàn)隱藏缺陷對象重要部分的情況,在一定程度上會導(dǎo)致缺陷特征信息丟失,但使用剪切混合方法可以緩解該問題。
2.4 實驗評價指標(biāo)
為評估本文方法的性能,實驗采用宏查準(zhǔn)率Pmacro、宏召回率Rmacro和宏F1 分?jǐn)?shù)Fmacro作為評價指標(biāo),其表達式如下所示:
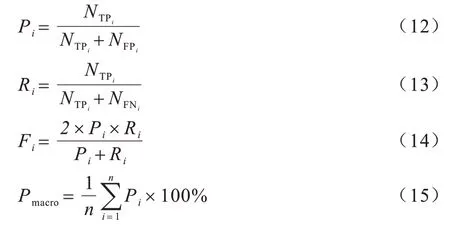

其中:n為缺陷類別數(shù)量;NTPi是第i類中正確預(yù)測的缺陷類別個數(shù);NFPi是第i類中錯誤預(yù)測i類缺陷為其他類別的個數(shù);NFNi是第i類中錯誤預(yù)測其他缺陷為i類缺陷的個數(shù);Pi是第i類的查準(zhǔn)率;Ri是第i類的召回率;Fi是第i類的綜合度量指標(biāo)(F1s)。
2.5 訓(xùn)練過程及結(jié)果分析
交叉熵表示2 個概率分布之間的距離,本文模型采用交叉熵?fù)p失計算網(wǎng)絡(luò)預(yù)測值與真實值之間的距離,圖5 所示為本文網(wǎng)絡(luò)在訓(xùn)練過程中訓(xùn)練損失和驗證損失的變化情況。從訓(xùn)練過程中訓(xùn)練損失和驗證損失的變化情況來看,本文模型在訓(xùn)練過程中損失迅速衰減,在60 個訓(xùn)練輪數(shù)后基本穩(wěn)定收斂,宏查準(zhǔn)率最高達98.87%,模型沒有出現(xiàn)明顯的過擬合現(xiàn)象,具有良好的泛化性能和穩(wěn)定的識別能力。

圖5 訓(xùn)練過程中損失衰減和準(zhǔn)確率變化曲線Fig.5 Curve of loss attenuation and accuracy change during training

表2 本文方法的缺陷識別混淆矩陣Table 2 Confusion matrix of defect recognition of method in this paper

表3 本文方法的缺陷識別指標(biāo)Table 3 Defect recognition index of method in this paper
2.6 消融實驗
為驗證本文提出的各項改進方法對模型性能的影響,在VIT-Base 的基礎(chǔ)上逐個添加本文提出的系列改進方法,實驗結(jié)果如表4 所示。其中,單獨測試自注意力混合融合模塊性能時,僅使用主分支通路,將當(dāng)前自注意力編碼單元的類別向量與上一級自注意力編碼單元的嵌入向量送入自注意力混合融合模塊,輸出網(wǎng)絡(luò)預(yù)測結(jié)果,以驗證自注意力混合融合模塊的有效性。

表4 不同改進方法對模型性能影響的評估結(jié)果Table 4 Evaluation results of the impact of different improvement methods on model performance %
從表4 可以看出,與改進前的VIT-Base 相比,多尺度自注意力編碼單元的評價指標(biāo)Pmacro、Rmacro和Fmacro分別提升了3.07、2.98、3.15 個百分點;自注意力混合融合模塊的Pmacro、Rmacro和Fmacro指標(biāo)分別提升了0.84、1.27、1.25 個百分點;在多尺度自注意力編碼單元的基礎(chǔ)上,自注意力混合融合模塊的Pmacro、Rmacro和Fmacro指標(biāo)分別提升了4.21、4.20、4.28 個百分點;多尺度自注意力編碼單元與自注意力混合模塊級聯(lián)作用貢獻最大,相比于VIT-Base 方法,其Pmacro、Rmacro和Fmacro指標(biāo)分別提升了7.28、7.18、7.43 個百分點。此外,本文方法宏查準(zhǔn)率達98.87%,充分說明本文方法對水電樞紐缺陷的識別效果有針對性提升。
為探究本文方法的實時性相關(guān)指標(biāo),本文從模型參數(shù)量、模型存儲大小、計算量和推理時間4 個方面進行測試評估。本文方法通過調(diào)整多尺度自注意力編碼器的超參數(shù)測試網(wǎng)絡(luò)不同體積的版本。具體地,TSDR-M 是小型版本,采用1 個多尺度自注意力編碼器,主分支嵌入向量深度為384,副分支嵌入向量深度為192,自注意力頭的數(shù)量為6;TSDR-B 是中型版本,采用3 個多尺度自注意力編碼器,主分支嵌入向量深度為768,副分支嵌入向量深度為384,自注意力頭數(shù)量為12;TSDR-L 是大型版本,采用6 個多尺度自注意力編碼器,主分支嵌入向量深度為768,副分支嵌入向量深度為384,自注意力頭的數(shù)量為12。
從表5 可以看出,針對尺寸為224×224×3 的輸入圖片,本文方法的大型版本模型參數(shù)量和計算量為VIT-Base 方法的1/4,推理時間降至3.37 ms,且獲得最高宏F1 分?jǐn)?shù)98.87%;本文方法小型版本的模型參數(shù)量為2×106個,推理時間僅需1.51 ms,且識別效果優(yōu)于VIT-Base 方法。實驗結(jié)果表明,本文方法能滿足水電樞紐缺陷識別工程現(xiàn)場較高的實時性要求,具備一定的工程應(yīng)用價值。

表5 本文方法的缺陷識別指標(biāo)Table 5 Defect identification index of method in this paper
2.7 對比實驗
經(jīng)典的機器學(xué)習(xí)分類方法需要手動選擇圖像特征,如支持向量機(Support Vector Machine,SVM)[21];卷積架構(gòu)的深度學(xué)習(xí)方法通過堆疊卷積層自動提取特征,如ResNet-50等。為進一步驗證本文方法的有效性,將本文方法與SVM、ResNet-50[22]、MobileNet v3[23]和改進的Inception v3[5]等經(jīng)典缺陷識別方法進行對比實驗。為保證實驗的客觀性,SVM 相關(guān)實驗采用簡易的SVM 機器學(xué)習(xí)庫SVMUTIL,該數(shù)據(jù)庫包括特征提取算法和用于圖像分類的SVM;ResNet-50 和MobileNet v3 實驗部分采用Pytorch 官方網(wǎng)絡(luò)實現(xiàn);改進的Inception v3 與本文方法使用同一個數(shù)據(jù)集,并在本文環(huán)境下進行網(wǎng)絡(luò)復(fù)現(xiàn)。
由表6 可知,SVM 方法對無損和裂縫2 個類別識別較好,但對脫落、露筋、滲漏識別精度非常低,F(xiàn)macro為58.94%。

表6 SVM 方法的缺陷識別結(jié)果Table 6 Defect identification results of SVM method
由表7 可知,ResNet-50 對無損、裂縫和露筋3 個類別識別較好,但對滲漏和脫落識別精度較低,F(xiàn)macro為85.04%。

表7 ResNet-50 方法的缺陷識別結(jié)果Table 7 Defect identification results of ResNet-50 method
由表8 可知,MobileNet v3 對無損、裂縫和露筋3 個類別識別較好,但對滲漏識別精度較低,對脫落識別最差,F(xiàn)macro為92.86%。

表8 MobileNet v3 方法的缺陷識別結(jié)果Table 8 Defect identification results of MobileNet v3 method
由表9 可知,改進的Inception v3 對5 個類別識別效果均較好,識別精度超90%,但對脫落和露筋兩項重大缺陷的識別精度不夠高,對露筋識別最差,查準(zhǔn)率為92.1%,F(xiàn)macro為96.88%。

表9 改進Inception v3 方法的缺陷識別結(jié)果Table 9 Defect identification results of the improved Inception v3 method
由表10 可知,SVM 方法的缺陷識別精度最低,主要原因是SVM 通過手動選擇圖像特征,不能有效提取圖像特征,無法獲得好的識別效果。ResNet-50缺陷識別精度高于SVM 方法,主要原因是水電樞紐缺陷圖像具有相似干擾噪聲大、背景特征復(fù)雜、尺度變化大等特點,深度卷積網(wǎng)絡(luò)通過堆疊卷積層構(gòu)建網(wǎng)絡(luò),并自動提取特征,能有效緩解背景噪聲干擾。MobileNet v3 通過神經(jīng)結(jié)構(gòu)搜索構(gòu)建網(wǎng)絡(luò),結(jié)合特征通道注意力,加強網(wǎng)絡(luò)學(xué)習(xí)能力,從而提高深度卷積網(wǎng)絡(luò)缺陷識別性能。改進的Inception v3 方法針對水電樞紐缺陷特點進行改進,以適應(yīng)缺陷識別場景,獲得了較高缺陷識別指標(biāo)。以上基于卷積架構(gòu)的缺陷識別方法雖然取得了一定的缺陷識別效果,但由于卷積架構(gòu)不能充分獲取長距離全局依賴信息,易受到局部特征干擾,無法獲得更好的缺陷識別效果。本文提出基于完全自注意力的水電樞紐缺陷識別方法,充分利用自注意力機制對長距離依賴關(guān)系的強大捕捉能力,通過多尺度自注意力編碼單元提取全局語義特征,在全局視野上有效識別缺陷。此外,通過自注意力混合融合模塊提取多尺度語義信息,有效緩解了缺陷圖像形態(tài)多樣、尺寸變化大的問題。在訓(xùn)練過程中,使用一系列圖像增強增廣策略增加樣本多樣性,提高了模型的泛化能力。

表10 不同缺陷識別方法的macro-F1s 指標(biāo)比較Table 10 Comparison of macro-F1s index of different defect identification methods %
3 結(jié)束語
本文提出一種基于完全自注意力的水電樞紐缺陷識別方法,采用雙分支結(jié)構(gòu)的多尺度自注意力編碼單元挖掘缺陷圖像長距離的全局信息,增強全局語義表達能力。通過自注意力混合融合模塊融合2 條分支的多尺度特征,有效緩解缺陷尺度差異大等問題,提升缺陷識別精度。實驗結(jié)果表明,本文方法的缺陷識別效果優(yōu)于SVM、ResNet-50、MobileNet v3等主流缺陷識別方法,宏查準(zhǔn)率達98.87%。但本文所采用的位置編碼方法只能編碼固定大小的圖片,無法實現(xiàn)不同尺寸圖片的輸入,下一步將通過嵌入卷積層實現(xiàn)編碼目的,并利用卷積操作收集圖像塊之間的位置信息,從而實現(xiàn)不同尺寸圖片的輸入。
猜你喜歡
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
