基于暗通道和改進YOLOv3的霧天車輛檢測算法
2022-09-19 04:40:08王藝鋼
物聯網技術 2022年9期
華 丹,楊 碩,2,王藝鋼
(1.沈陽化工大學 計算機科學與技術學院,遼寧 沈陽 110142;2.遼寧省化工工程工業智能化技術重點實驗室,遼寧 沈陽 110142)
0 引 言
車輛檢測是計算機視覺中的重要任務之一,在智能交通和自動駕駛等領域涉及較廣泛。在霧天環境下,圖像的對比度下降、可辨識度較低,嚴重影響車輛的檢測效果,因此提高霧天車輛檢測的準確性具有重要意義。
霧天環境下車輛檢測分為兩個階段:去霧階段和車輛檢測階段。針對去霧階段,文獻[4]提出了一種使用半全局加權最小二乘優化局部大氣光去霧的算法,提高了去霧圖像的亮度,但該算法在去霧的效果方面仍不理想。文獻[5]通過級聯直方圖均衡化和NBPC+PA模型提高了去霧后圖像的能見度,但該算法魯棒性較差。文獻[6]提出了一種融合亮度模型和梯度域濾波的算法,一定程度上提升了去霧的效果,但該算法模型較復雜,魯棒性不夠。
在車輛檢測階段,得益于深度學習強大的特征檢測能力,基于深度學習的車輛檢測算法發揮著越來越重要的作用。文獻[8]提出了一種基于Faster RCNN和增量學習的車輛目標檢測算法,改善了漏檢錯檢的問題,但該算法檢測精度較差。文獻[9]提出了一種基于改進SSD的車輛檢測算法,該算法通過網絡剪枝與參數量化融合減少了模型的冗余參數,提升了檢測速度,但檢測精度有所欠缺。文獻[10]提出了一種改進的YOLOv3算法,該算法通過增加網絡輸出層數在一定程度上提高了車輛檢測的精度,但檢測性能仍有所不足。
針對上述去霧算法效果較差、檢測算法精度較低的問題,本文提出一種基于暗通道去霧算法和改進YOLOv3模型的霧天車輛檢測算法。首先,在去霧階段通過暗通道去霧算法降低霧氣對圖像檢測的影響;其次,在車輛檢測階段使用K-means聚類算法計算出適用于車輛檢測的先驗框。YOLOv3算法的先驗框由COCO數據集的圖片進行預設,并不能完全適用于車輛檢測,針對霧天車輛數據集計算先驗框可以提高算法的精確度;最后,在YOLOv3算法的特征金字塔模塊中引入注意力機制,注意力機制可以加強算法對特征的挖掘能力,提高算法的檢測效果。
1 去霧算法
由于大氣中的微粒會對光產生大量的散射,霧天圖像質量會被不同程度地降低。基于上述原理,Narasimhan等人提出了解釋霧天圖像成像過程的大氣散射模型,該模型的數學描述如式(1)所示。
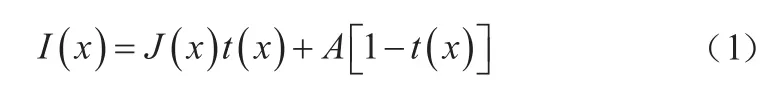
上述模型的適用條件是場景中的霧分布均勻。式中:表示像素點位置;()和()分別表示待恢復的無霧圖像和原始霧圖;()為場景透射率;表示大氣光值。
暗通道先驗理論(DCP)是對無霧圖像屬性的一種經驗性觀察,該理論認為在非天空的圖像區域,總有一些像素點至少有一個顏色通道具有接近零的像素值。暗通道先驗理論的數學描述如式(2)所示。
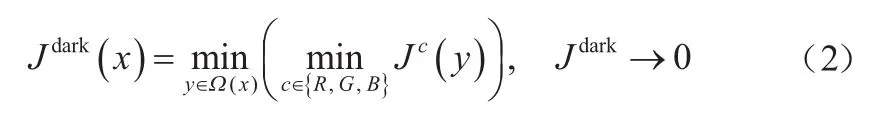
式中:()為像素點的鄰域;{,,}表示每個像素的三個顏色通道;是圖像的暗通道。
結合式(1)和式(2),可以得到圖像的粗估計透射率()為:
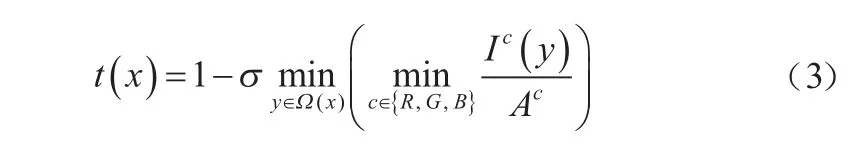
式中引入一個在[0,1]之間取值的修正參數,從而保留圖像中遠處的霧,使圖像更自然。仿真結果表明,取0.95時復原效果最好。
將得到的透射率和大氣光值代入大氣散射模型中獲得去霧圖像,再對該圖像做Gamma校正調整對比度,最終得到復原的去霧圖像。
暗通道去霧算法的效果如圖1所示。相較于原圖,暗通道去霧后的圖像更為清晰,車輛目標的輪廓更明顯,對比度更強,有利于提高檢測算法的精度。

圖1 暗通道去霧算法效果
2 改進的YOLOv3
2.1 YOLOv3原理
YOLOv3算法由主干提取網絡、特征金字塔網絡(Feature Pyramid Network, FPN)和檢測網絡三部分組成,網絡結構如圖2所示。
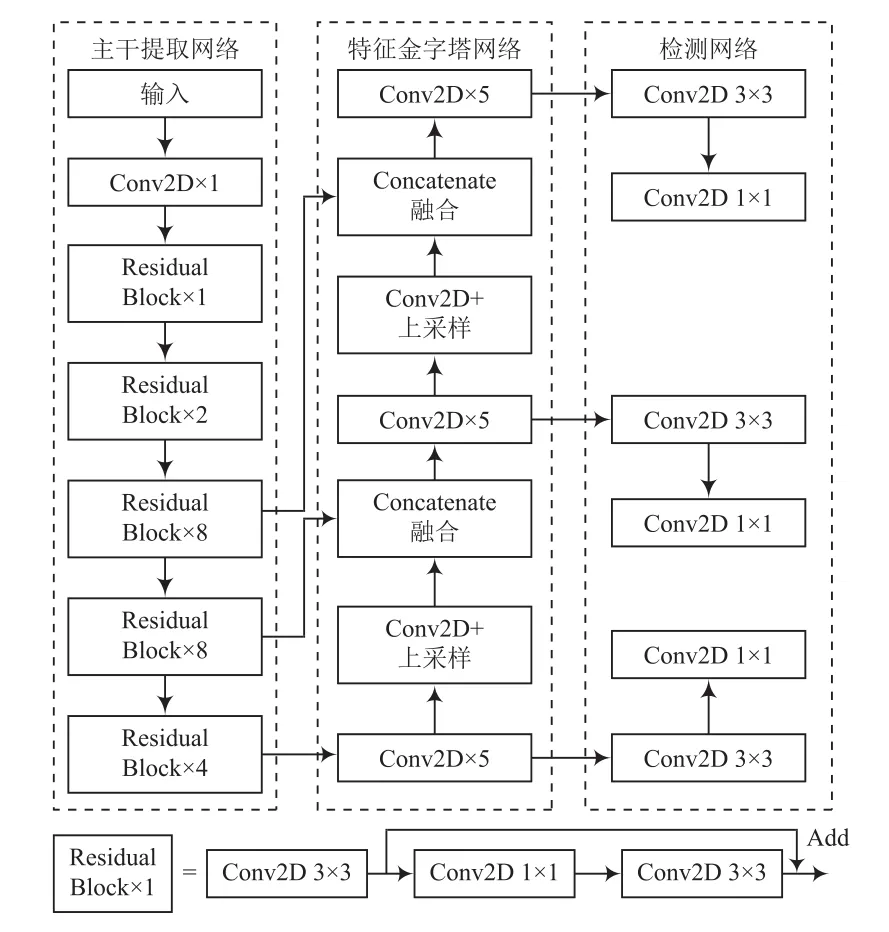
圖2 YOLOv3算法網絡結構
YOLOv3算法以DarkNet-53為主干特征提取網絡。DarkNet-53通 過 3×3和 1×1的卷積層(Convolution Layers)跳躍連接,利用L2正則化、激活函數(Leaky ReLu)和批標準化(BatchNormalization, BN)提高模型泛化能力;同時引入了殘差網絡(Residual Network),減少了多層網絡的訓練難度,提升了檢測的精度。
在特征金字塔模塊,為了獲取細粒度特征,YOLOv3對深層特征圖進行上采樣(UpSampling),再與淺層特征圖進行Concatenate拼接。拼接后的特征圖融合了深層和淺層的特征信息,提升了算法的檢測性能。
為了使算法針對不同尺度的目標具有相同的檢測效果,YOLOv3算法采用多尺度檢測網絡。從DarkNet-53中選取3種不同尺度特征圖(13×13,26×26,52×52),對這三個特征圖分別做3×3和1×1的卷積運算,并進行特征整合和通道調整,計算后的結果合并轉移給損失函數。
YOLOv3算法的損失函數為回歸損失、置信度損失和分類損失的加權和。在回歸損失中采用誤差平方和,在置信度損失和分類損失中采用交叉熵損失,各損失計算的數學描述如式(4)所示。
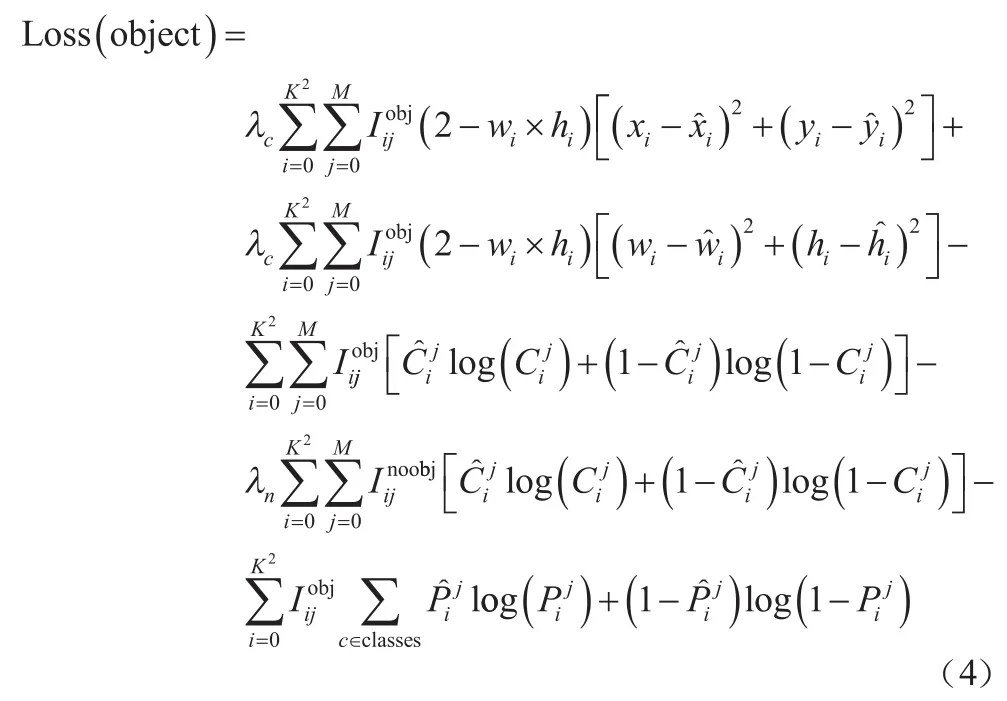

YOLOv3算法在目標檢測方面具有較好的性能,但在應用于霧天車輛檢測時存在以下問題:(1)YOLOv3算法的框不能完全適用于車輛檢測;(2)多尺度檢測網絡雖然對特征進行了整合,但是并沒有加強對特征的提取,還存在對特征挖掘不足的問題。針對以上問題,本文對YOLOv3進行了相應的改進。
2.2 K-means計算先驗框
YOLOv3算法的先驗框是根據COCO數據集預設的,不能很好地適用于本文的霧天車輛檢測數據集。為了使算法能夠更加準確和快速地對車輛進行檢測,通過K-means聚類算法對本文數據集中的真實框(Ground TrueBox)進行分析。
傳統的K-means聚類算法多以歐氏距離來計算對象間的距離,但是對先驗框使用歐氏距離計算時,大先驗框的誤差更大,因此使用改進的交并比(IOU)公式進行計算,如式(5)所示。
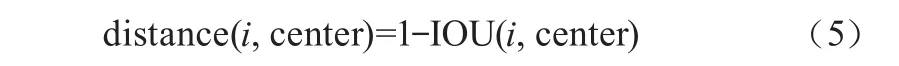
式中,IOU表示聚類中心與真實框的重合程度,其數學描述如式(6)所示。
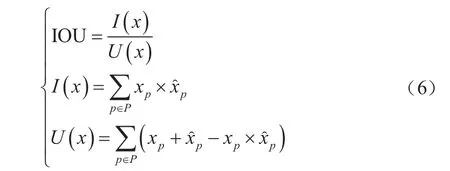
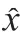
2.3 注意力機制的引入
CA(Coordinate Attention)模塊是一種融合位置信息和通道信息的注意力機制,在空間和通道維度上加強了特征挖掘能力,其網絡結構如圖3所示。
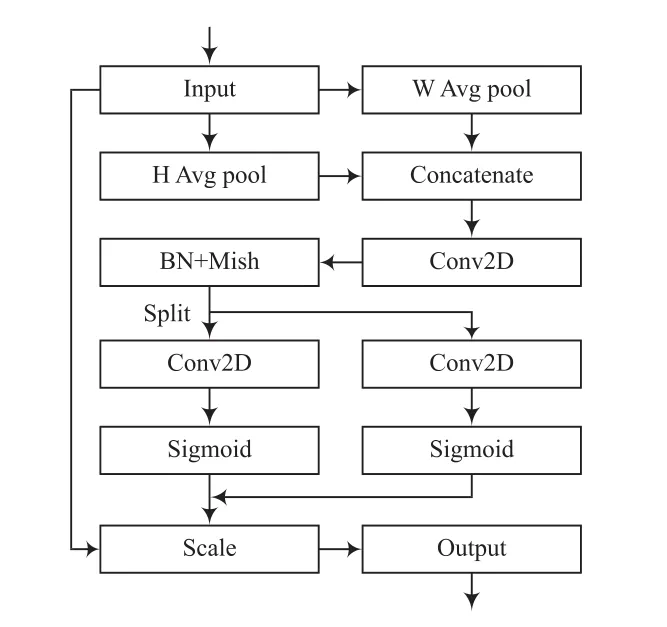
圖3 注意力機制網絡結構
全局池化可以在通道注意力中采集空間信息,但是難以保留位置信息。為了將位置信息嵌入到空間信息中,將全局池化分解為兩組一維的池化。對尺寸為××的輸入,分別使用尺寸為(,1)和(1,)的池化核沿著水平和豎直方向對每個通道進行編碼。高度為和寬度為的第個通道的輸出分別為:
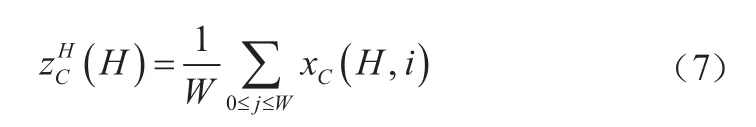
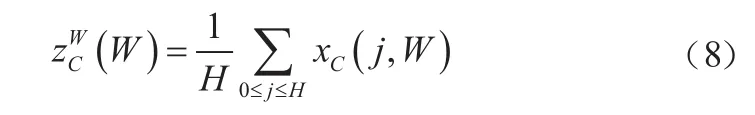
將這一對輸出的池化結果進行Concatenate級聯,然后使用一個共享的1×1卷積對其做變換,如式(9)所示。

其中,表示下采樣比例。沿著空間維度將劃分為兩個單獨的張量f∈ R和f∈ R。使用兩個 1×1 卷積F和F將特征圖f和f變換到與輸入同樣的通道數,如式(10)和式(11)所示。
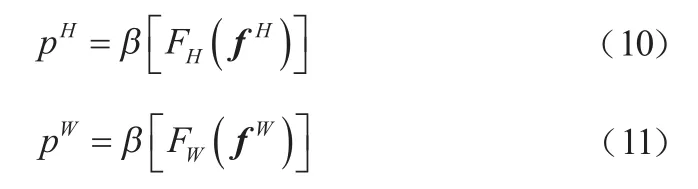
對p和p進行拓展,作為注意力權重,添加到輸入中。CA模塊的最終輸出如式(12)所示。
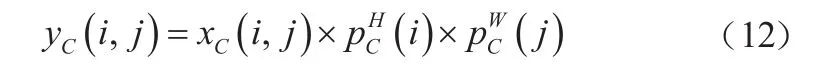
最終通過CA模塊,對輸入完成了水平和豎直方向的特征挖掘。
3 實驗分析
3.1 實驗環境與參數
本文實驗環境為:11th GenIntel Corei5-1135G7@2.4 GHz,8 GB內存,NVIDIA Geforce MX450 2 GB,64位Windows10操作系統。編程語言為Python,框架為Pytorch1.8.1,GPU加速庫為CUDA11.1和cuDNN7.65。
在本文的實驗中,將數據集圖片的尺寸統一縮放到416×416,設置參數Batchsize為4,學習率為0.001,使用Adam優化器調整網絡的學習率。實驗的訓練周期為100個Epoch,直到Loss不再變化,自動終止訓練。
3.2 數據集
本文使用的數據集為自制的霧天車輛檢測數據集,包含13 526張圖片,按照7∶2∶1的比例劃分為訓練集、驗證集和測試集。由于自制的數據集圖片數量有限,為了讓模型更好地學習到目標特征和提高魯棒性,需要對數據做數據增強。
本文采用Mosaic數據增強算法。Mosaic算法的流程有三步:(1)在數據集中隨機選取四張圖片;(2)對這些圖片進行縮放、剪切和水平變換,裁剪的過程中保留含有待檢測目標的區域;(3)將這四張圖片合并處理為一張。通過Mosaic算法的數據增強,豐富了數據集的檢測背景,提高了模型訓練后的泛化能力。本文霧天車輛數據集的Mosaic數據增強效果如圖4所示。

圖4 Mosaic數據增強效果
3.3 評價指標
對訓練后模型的檢測平均精度(mean Average Precision,mAP)進行對比。mAP的計算如式(13)~(16)所示。

式中:TP為真正例;FP為假正例;FN為負正例;為種類數。
3.4 聚類計算先驗框
對霧天車輛檢測數據集進行K-means聚類分析后,得到9種先驗框的尺寸。K-means聚類計算先驗框的結果對比見表1所列。
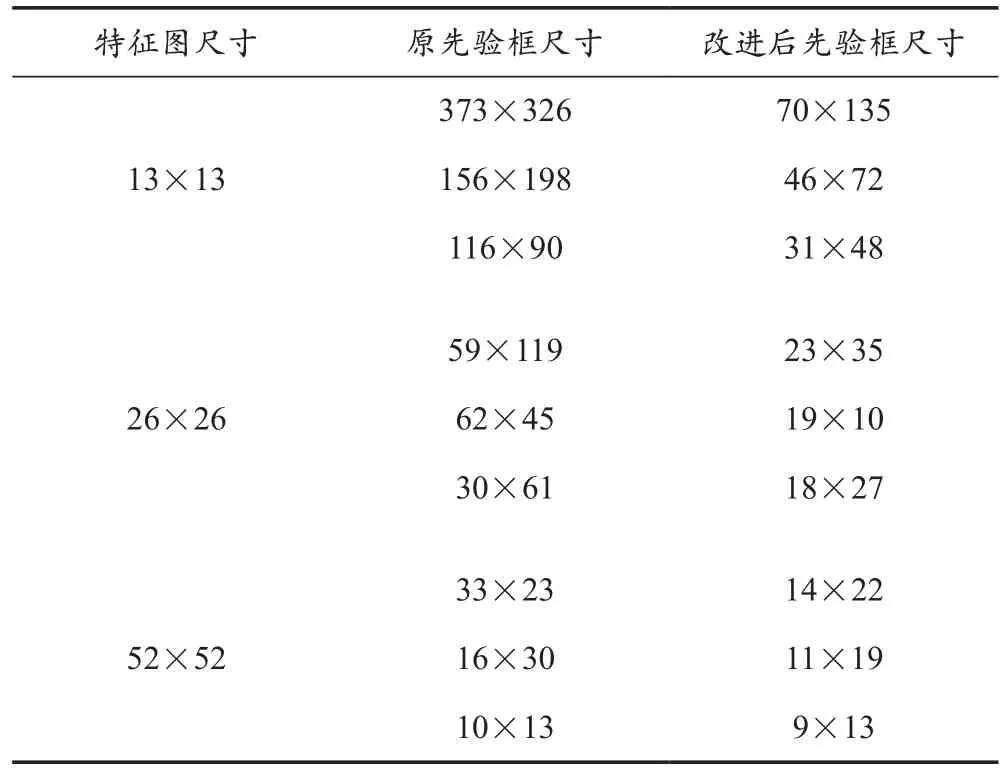
表1 K-means聚類計算先驗框結果對比
在尺寸為13×13的特征圖中具有最大的感受野,采用70×135、46×72、31×48這三種尺寸的先驗框檢測最大的車輛。相較于原先驗框的平均寬高比1.04,改進后的先驗框尺寸更小,平均寬高比為0.61,更適用于本文數據集。在尺寸為26×26的特征圖中,采用23×35、19×10、18×27這三種先驗框檢測圖像中尺寸較大的車輛。在尺寸為52×52的特征圖中具有最小的感受野,采用14×22、11×19、9×13這三種尺寸的先驗框檢測小目標車輛。綜上所述,改進后的先驗框尺寸更小,平均寬高比更適用于本文數據集,有利于提升小目標車輛的檢測精度。
3.5 對比實驗
為了驗證本文算法對霧天車輛的檢測性能,將本文算法與目標檢測算法效果良好的SSD、Faster RCNN、YOLOv2和YOLOv3在霧天車輛數據集上進行實驗對比。5種算法的實驗結果對比見表2所列。

表2 5種算法的實驗結果對比
從表2中可以看出,本文算法比SSD算法的mAP提升了11.8%。SSD的卷積層較少,特征提取不夠充分,導致檢測效果欠佳。相較于Faster RCNN,本文算法的mAP提高了5.9%。Faster RCNN 使 用 RPN(Region Proposal Networks)推薦候選區域,針對多尺度的目標不能保證較好的檢測效果。與YOLO系列的算法相比,本文算法比YOLOv2的mAP提升了14.9%,比YOLOv3提升了4.1%。本文算法基于YOLOv3進行了相應的改進和拓展,提升了對霧天車輛的檢測性能。對比本文算法和YOLOv3算法對霧天車輛檢測的效果,如圖5所示。

圖5 霧天車輛檢測效果對比
3.6 消融實驗
為了驗證本文改進方法的有效性,以及不同改進策略對檢測效果的影響,以YOLOv3算法為基礎作消融實驗,實驗結果見表3所列。
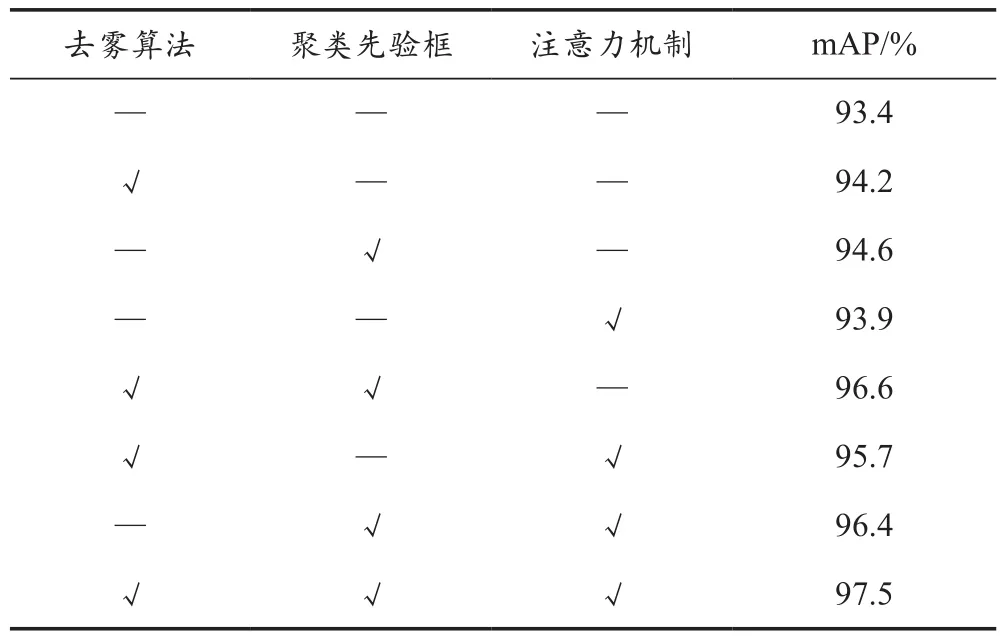
表3 消融實驗結果對比
由表3可知,單獨引入去霧算法時,算法的mAP提了0.8%;單獨使用K-means聚類計算先驗框時,mAP提升了1.2%;單獨向模型中加入注意力機制時,mAP提升了0.5%。組合使用去霧算法和聚類先驗框使算法的mAP提升了3.2%,利用去霧算法和注意力機制使算法的mAP提升了2.3%,引入聚類計算先驗框和注意力機制使算法的mAP提升了3%。最后將三種改進策略添加到模型中,得到的本文算法將mAP提升了4.1%,因此本文提出的改進策略對提升霧天車輛檢測效果具有有效性。
4 結 語
本文針對霧天車輛檢測準確率較低的問題,提出了一種基于暗通道去霧和改進YOLOv3的檢測算法。首先利用暗通道方法對圖像進行去霧,然后通過K-means聚類計算適用于車輛檢測的先驗框,最后引入注意力機制,加強了算法對特征圖的特征挖掘能力。通過以上改進,本文算法對霧天車輛檢測具有良好的性能。
與主流的目標檢測算法相比,在霧天車輛檢測數據集上,本文算法具有更好的檢測精度,mAP達到了97.5%。下一步將在引入去霧算法和網絡模型的基礎上,針對算法的復雜度進行研究,以提高算法的檢測速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
