給水廠混凝劑智能投加模型構建與應用
2022-09-21 01:04:08劉洪波黃劍虹張國榮劉麗梅
上海理工大學學報 2022年4期
劉洪波,黃劍虹,張國榮,吳 燕,劉麗梅
(1.上海理工大學 環境與建筑學院,上海 200093;2.昆山市自來水集團有限公司,昆山 215300;3.昆山漢元經水水務科技有限公司,昆山 215300)
在城市給水處理中,為去除天然水體中的微小懸浮物及膠體,混凝過程是處理工藝中必不可少的一步。其中混凝劑的用量不僅直接決定了給水廠出水水質的好壞,也影響著水廠生產運營成本。然而混凝過程中涉及許多復雜的反應,同時由于原水水質、水量的不斷變化,對混凝劑投加量的判斷與控制并不容易[1]。隨著信息化與智能化的發展,神經網絡已被廣泛應用于工業生產過程中,基于神經網絡的混凝劑智能投加模型在給水廠中也有所應用[2]。但傳統的智能投加模型的建立缺乏大量數據支持,且對模型如何有效融入智慧水廠建設中的研究不足。本文以華東地區某給水廠為基礎,對混凝劑智能投加模型的構建以及在給水廠混凝劑加藥系統智慧化改造中的應用作了更深一步的研究。
1 水廠數據處理與分析
1.1 水廠大數據清洗
建模所用數據取自華東某給水處理廠的在線記錄數據,原水指標共6 項,包括濁度、流量、溶解氧含量(DO)、pH、總磷(TP)和氨氮。混凝劑投加量數據取自投加泵的流量記錄,所用混凝劑為液態PAC,氧化鋁含量10.3%~10.8%。所有數據每5 min 測一次,時間跨度從2020 年1 月至2022 年11 月,總計約250 萬個數據記錄。水廠運行過程中,由于各種因素的影響,記錄數據中包含了少量的誤差、異常值以及缺失值,有必要在建模前對水廠積累的大量數據進行清洗。
由于測量設備故障、設備維護與清洗等原因,在數據記錄中包含的遠超常理范圍的原水水質指標測量記錄可以被認為是粗大誤差,采用拉依達準則結合數據可視化圖將這類誤差剔除。拉依達準則通過假定數據為近似正態分布,將偏離均值3 倍標準差的觀測值作為壞值剔除[3]。呈現非正態分布的部分數據則結合數據可視化圖,劃定最小與最大觀測值,將不符合誤差要求的數據按不合格數據進行選擇性剔除。
同時在數據記錄中,受測量設備不穩定與原水水質波動等隨機因素的影響,存在大量不規律的隨機誤差。數據預處理中常用平滑濾波來消除隨機誤差[4],以波動較劇烈的2021 年9 月15 日的濁度數據為例,采用五點三次平滑濾波方法對數據進行處理。如圖1(a)所示,經過平滑濾波處理后,波動較小的隨機誤差均得到了處理,但存在一些偏離較大的隨機誤差依然難以消除。對于這類隨機誤差,可以看作連續數據局部的異常值,使用基于密度的局部離群因子(local outlier factor,LOF)算法對其進行剔除,之后使用K最近鄰插補(K-nearest neighbor imputation,KNN)算法對剔除后的空缺數據進行填補。LOF 算法是一種基于密度的無監督機器學習異常檢測方法,它通過計算每個樣本在給定的領域內相對于其臨近點的密度局部偏差,對每個樣本計算異常得分,密度遠低于其臨近點的樣本,異常得分也高于正常點,即可辨別為異常的離群值[5]。KNN 算法則在給定的缺失樣本K領域內,將距離缺失樣本最近的K個樣本的數值加權以估計缺失的數值[6]。

圖1 隨機誤差處理示例Fig.1 Example of random error processing
將上述處理手段加以結合,形成一系列隨機誤差的組合處理方法,最終處理的步驟為:a.LOF 算法剔除異常值;b.KNN 算法填補剔除后出現的空值以及原始數據中的缺失值;c.對數據進行五點三次平滑濾波處理。對于水廠的一維數據,將每組數據按時間順序編號,利用網格來做最近鄰查詢[7]。在LOF 算法與KNN 算法的計算中,均以樣本點的5 個近鄰為給定領域,同時LOF 的計算中將異常得分大于1.2 的樣本識別為異常點加以剔除。處理前后數據對比如圖1(b)所示。
由圖1(b)可知,相比未經過處理的數據,經組合處理的數據中局部的異常值已經消失,隨機噪聲也大為減少。經過處理后,數據剩余220 萬個,各項數據整合后為31 萬組數據,相比250 萬的原始數據,本研究數據清洗方式的數據損失量也在可接受的范圍內,后續使用經過組合處理的數據建立的模型也有明顯優勢。
1.2 原水指標重要性分析
雖然對混凝劑投加后水體中的混凝與沉淀反應已有大量的理論分析,但在水廠實際的生產中,原水中各因素對混凝過程的影響非常復雜[8]。因此,混凝劑的投加過程實際是一個信息不清晰的灰色系統,使用灰色關聯度分析的方法對原水指標與混凝劑投加量的聯系進行評估。灰色關聯度分析通過比較不同數列曲線的幾何形狀相似程度來判斷數據間聯系緊密程度,對數據分布規律與樣本數量均無要求,在水環境指標的分析中已有應用先例[9]。
由于各項指標有不同的計量單位,存在量綱和數據尺度上的差異,不便于比較,在分析前使用標準化的方式對數據進行無量綱化處理[10],計算公式如下:

由極大值原理可知0
對無量綱化后的數據進行灰色關聯度分析,計算各原水指標與加藥量的灰色關聯度R。R值越大代表關聯程度越高,在對混凝劑加藥量的分析中,即代表了原水指標的重要程度越高。混凝劑加藥量的灰色關聯度分析結果如表1 所示。

表1 原水指標與加藥量灰色關聯度分析結果Tab.1 Grey correlation degree analysis results of raw water indexes and dosing flow
圖2 以矩陣熱力圖的形式展示各指標之間的灰色關聯度,其中,x軸方向為比較序列,y軸方向為參考序列。

圖2 灰色關聯度矩陣熱力圖Fig.2 Heatmap of grey correlation degree matrix
通過灰色關聯度結果的分析可知,與混凝劑加藥量聯系最緊密的原水指標為流量(R=0.799),其次為濁度(R=0.752),這之后是灰色關聯度值接近pH 與氨氮(分別為0.723 與0.722),剩下的DO與TP 的灰色關聯度值相較而言則大為降低(分別為0.643 與0.642),可以認為對加藥量影響極小。這之中,原水流量改變后,生產中必然也會對混凝劑投加量進行相應調整,同時流量的改變也會帶來反應池水流速度梯度的變化,對混凝效果的影響至關重要。濁度則是衡量混凝沉淀效果的指標,原水中的濁度作為混凝劑投加過程中需要削減的主要指標,與加藥量有著相同的變化趨勢。進水pH 較高時,部分鋁鹽轉化為溶解性的Al(OH)4-,造成混凝劑吸附架橋與網捕卷掃能力下降[11]。考慮到華東某水廠原水pH 范圍在6.8~8.6 之間,存在偏高的問題,pH 與混凝劑加藥量的正相關關系應該取決于pH 升高時為保證混凝效果而增加的加藥量。對于氨氮,在水體中氨氮大多以游離氨的形態存在,難以通過混凝沉淀反應去除,其對混凝沉淀過程的影響也很小[12]。由于水廠氨氮檢測設備的最小示值較大而實際數值較小,造成氨氮的測量記錄值在幾個數值間變化,從而與加藥量數列曲線的幾何形狀相似。
2 混凝劑加藥量模型建立
2.1 BP 神經網絡模型與貝葉斯優化
BP 神經網絡是一種有多層神經元的前饋神經網絡,數據從第一層的輸入層進入網絡,經過中間層為隱藏層,最后從輸出層得到結果。在BP 神經網絡的訓練中,計算網絡輸出值與真實值之間的損失值,應用反向傳播算法(back propagation,BP),將損失從輸出層反向傳播至輸入層,調節各層連接間的權重值與偏置系數[13]。經過訓練的神經網絡損失值不斷減少,最終可以近似于任意的復雜函數。然而在上述網絡建立與訓練過程中,有大量的參數需要預先人為設置,其值的大小對BP 神經網絡的性能有決定性影響。常用的神經網絡參數的估計方法如網格搜索與隨機搜索十分耗時,為此有學者提出了貝葉斯優化等算法以提高優化效率。
貝葉斯優化是基于一種序貫的先驗優化方式,在確定優化的目標函數以及函數定義域后,先在目標函數上隨機取幾個觀測點進行觀測。根據觀測結果,使用概率代理模型對目標函數的分布進行估計,在估計的基礎上計算采集函數以選擇下次迭代過程中觀測點的位置。由此迭代,直至找到目標函數值最優的點[14]。相比于傳統的優化算法,貝葉斯優化能夠以更少的迭代次數,準確快速地得到參數的最優解[15],在面對大數據建模時可節省大量時間。
本研究基于Python 語言,對經過預處理后的共31 萬組數據進行建模與評估。在建模前,抽取部分數據使用貝葉斯優化算法對BP 神經網絡的結構與參數進行優化,后利用優化參數建模以實現混凝劑投加量的預測。
2.2 模型訓練
使用經過預處理的數據,共25 萬組數據用于訓練,將全部的6 項原水指標作為輸入訓練BP 神經網絡。為加快訓練時損失函數的收斂速度,使用經標準化處理的數據進行訓練,同時使用貝葉斯優化算法對BP 神經網絡的參數進行優化。優化的參數為:神經網絡隱含層數量、隱含層神經元數量、正則化系數、隨機批次大小、動量因子、學習率。
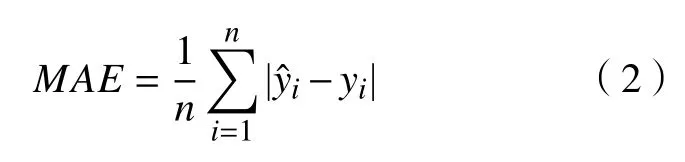
式中:n為用于預測數據的數量;與yi分別為預測值與真實值。
如圖3 所示,隨著迭代的進行,目標函數的最小值逐漸下降,經過50 次迭代后,貝葉斯優化得到最優的結果。此時模型對應的參數:隱含層為5 層;隱含層神經元數量為412;正則化系數為0.000 01;隨機批次大小為75;動量因子為0.268;學習率為0.137。

圖3 貝葉斯優化過程中最優目標函數值Fig.3 Optimal objective function value during Bayesian optimization
使用貝葉斯優化后的參數對神經網絡進行訓練,同時設置動態的學習率,在訓練過程中劃分2.5 萬組數據作為驗證集,訓練中驗證集數據預測的R2評估值若不能在10 次訓練周期中上升0.000 1,即將現有學習率除以5,持續此過程直到學習率再也無法減小。訓練過程中訓練集損失、驗證集R2與學習率的變化如圖4 所示。

圖4 BP 神經網絡訓練過程Fig.4 Training process of BP neural network
隨著訓練的進行,訓練集損失逐漸下降,驗證集R2逐漸上升,同時每當學習率改變時訓練的效果會有突然的提升。第223 次訓練周期后,驗證集R2不再上升,而訓練集損失仍逐漸下降。此時模型有過擬合的風險,于是設置訓練在經過223 次訓練周期后提前停止。
3 模型評估
使用測試集中數據對模型進行評估,其表現反映模型在新數據中的泛化能力,選取約6 萬組未經過訓練的數據對模型進行測試,占處理后總數據量的20%。評估模型預測性能的指標除MAE、R2外,還有平均絕對誤差百分比(MAPE),模型評估中MAE與MAPE的值越低、R2的值越高,即代表模型的效果越好。MAPE計算公式如下:

式中:n為用于預測數據的數量;與yi分別為預測值與真實值。
除使用經過預處理的數據以及全部的6 項原水指標作為輸入的模型A 外,以與模型A 相同的優化與訓練方式,使用未經組合處理的數據訓練模型B,以評估本研究提出的數據清洗方式對模型性能提升的表現;同時,使用在重要性分析中排名前4 的原水指標的數據訓練模型C,探究在重要性分析中排名靠后的指標對加藥量的影響。表2為對各模型預測性能的評估。

表2 不同模型預測性能比較Tab.2 Performance comparison of different models
比較不同模型預測效果的差異,其中模型A 的評估效果相較于模型B 有明顯提升,如模型A 的MAE評估值相比模型B 提升了43.9%,MAPE提高了46.5%。這表明本文提出的隨機誤差組合處理手段有效地降低了原始數據集中的隨機誤差,極大改善了所建模型的性能。而對模型C 的評估顯示,其建模效果相比另外兩個模型差距較大,說明TP 與DO 兩個原水指標對混凝劑投加量仍有一定影響,不能在建立模型時剔除。
對模型A 的預測誤差進行進一步分析,同時在測試集數據中加入與原始數據中隨機誤差分布相同的隨機噪聲,以此測試模型預測效果的魯棒性,如圖5 所示。結果表明,加入噪聲后R2的評估值為0.97,MAE的評估值為4.16 L/h,MAPE則均在3%以內,雖相比原測試集稍有降低,但總體效果與原測試集接近,模型具有較高的魯棒性。同時可以看到,模型預測值與實際值的分布大體一致,預測值的偏離較小且呈現對稱分布,可以認為模型有效地擬合了實際數據的信息。

圖5 模型A 預測誤差分析Fig.5 Prediction error analysis of model A
經過綜合評估,模型A 的性能滿足水廠生產過程中對混凝劑投加的要求,其建立過程中數據處理與訓練的方法有一定的參考價值。
4 模型應用展望
華東某飲用水處理廠的生產過程具有較為完善的自動化建設基礎,但混凝劑投加量的決定依然基于人員的經驗判斷。為此,展望未來的水廠智慧化改造,將本文建立的BP 神經網絡模型應用于水廠混凝劑智能投加控制中,智能加藥在線控制系統的框架如圖6 所示。智能加藥系統在接收并處理水質在線檢測設備傳遞的信息后,將信息向下傳遞,主要有混凝劑投加量預測與數據分析結果可視化兩項功能。

圖6 智能加藥在線控制系統框架Fig.6 Framework of intelligent dosing online control system
水質在線檢測設備得到的原水水質信息是BP 神經網絡模型預測加藥量的依據,但由于檢測設備故障或原水水質波動的原因,偶有出現缺失或異常檢測數值。在數據分析中,先將此類數值識別并替換,再向下傳遞至神經網絡模型中,使得混凝劑投加量的預測結果更為準確。另外,引入砂濾池濾前濁度作為反饋,對預測投加量進行微調,從而使出水水質更為穩定。同時,將數據分析與處理的過程實時地展示在可視化平臺中,更好地輔助人員決策。
5 結束語
混凝是飲用水制水過程中最重要的工藝,準確的混凝劑投加量對制水成本與出水水質有著重要意義。本文使用多種方式對采集的水廠歷史運行數據進行清洗,并對各原水指標與加藥量的關系進行分析。使用BP 神經網絡對濁度、流量、pH、溶解氧含量、總磷和氨氮建模以預測混凝劑的投加量,同時利用貝葉斯優化對BP 神經網絡的超參數優化求解。評估結果顯示所建模型能夠滿足水廠對混凝劑投加的要求,并在其基礎上搭建一套智能加藥在線控制系統的框架,以展望未來在水廠中的實際應用。但由于本研究條件的限制,收集的建模數據中缺少如溫度、堿度與天然有機物等在混凝機理中也存在一定影響的因素。后續可改進研究條件,獲取更多數據,探究更多影響因素與混凝劑加藥量之間的聯系,進一步提高模型精度。未來也可在水廠中進行實際部署,獲得更多的數據與運行經驗,并使用更加前沿的機器學習技術,在提高模型泛化能力的同時對控制系統加以優化。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
