基于深度學(xué)習(xí)的視頻異常檢測(cè)方法綜述*
2022-09-21 08:36:32李慧斌
計(jì)算機(jī)工程與科學(xué) 2022年9期
何 平,李 剛,李慧斌,2
(1.西安交通大學(xué)數(shù)學(xué)與統(tǒng)計(jì)學(xué)院,陜西 西安 710049;2.大數(shù)據(jù)算法與分析技術(shù)國(guó)家工程實(shí)驗(yàn)室,陜西 西安 710049)
1 引言
面對(duì)日常生活中不斷涌現(xiàn)的各類安全威脅和時(shí)刻存在的突發(fā)狀況,以視頻監(jiān)控為工具進(jìn)行安防的舉措已凸顯出強(qiáng)大優(yōu)勢(shì)。近年來(lái)隨著社會(huì)經(jīng)濟(jì)的快速發(fā)展與視頻傳感技術(shù)的不斷普及,監(jiān)控系統(tǒng)已被廣泛應(yīng)用于地鐵、社區(qū)和校園等各類公共場(chǎng)所[1]。然而,規(guī)模快速增長(zhǎng)的視頻監(jiān)控系統(tǒng)所產(chǎn)生的海量視頻數(shù)據(jù)對(duì)基于人工判讀的視頻異常事件檢測(cè)帶來(lái)了巨大挑戰(zhàn)。傳統(tǒng)依靠人工觀看事后監(jiān)控影像記錄從而發(fā)現(xiàn)異常的方式不僅消耗了大量人力資源,而且還可能會(huì)造成無(wú)法及時(shí)彌補(bǔ)的錯(cuò)誤或遺漏[2]。因此,開發(fā)一種不依賴大量人力,能自動(dòng)從監(jiān)控視頻中分析并發(fā)現(xiàn)異常情況的技術(shù)顯得至關(guān)重要,這種技術(shù)即為視頻異常檢測(cè)技術(shù)。

Figure 1 General process of video anomaly detection method圖1 視頻異常檢測(cè)方法的一般流程
視頻異常通常指視頻中出現(xiàn)不正常的外觀或運(yùn)動(dòng)屬性,或在不正常的時(shí)間或空間出現(xiàn)正常的外觀或運(yùn)動(dòng)屬性[3]。由于異常樣本的稀缺性和多樣性,視頻異常檢測(cè)方法通常僅對(duì)正常樣本分布進(jìn)行建模,測(cè)試時(shí)將偏離正常樣本分布的視頻幀或視頻片段視為異常[4]。從異常類型而言,外觀異常通常指空間異常,包括像素級(jí)別的局部異常與幀級(jí)別的全局異常;運(yùn)動(dòng)異常通常指時(shí)間異常,即與時(shí)序相關(guān)的上下文異常。視頻異常檢測(cè)任務(wù)即為檢測(cè)出視頻中存在的時(shí)間異常和空間異常[5]。由于特定場(chǎng)景下監(jiān)控視頻的背景往往固定不變,所以監(jiān)控視頻為典型的單一場(chǎng)景視頻,基于單一場(chǎng)景的視頻異常檢測(cè)研究也是本文綜述的重點(diǎn)內(nèi)容。
目前,監(jiān)控視頻異常檢測(cè)領(lǐng)域主要有以下綜述文獻(xiàn):Popoola等人[6]介紹了針對(duì)人類行為的異常檢測(cè)方法,將方法劃分為聚類法、動(dòng)態(tài)Bayes和主題模型法,但由于提出時(shí)間較早,對(duì)深度學(xué)習(xí)方法覆蓋較少;Kiran等人[7]從建模角度出發(fā),將深度學(xué)習(xí)方法劃分為重構(gòu)、預(yù)測(cè)及生成方法,但文中缺少對(duì)這些方法異常檢測(cè)效果的對(duì)比分析;彭嘉麗等人[8]從學(xué)習(xí)范式角度出發(fā),總結(jié)了有監(jiān)督、弱監(jiān)督及無(wú)監(jiān)督視頻異常檢測(cè)方法;胡正平等人[9]將視頻異常檢測(cè)方法分為有監(jiān)督、半監(jiān)督和無(wú)監(jiān)督3類,但文獻(xiàn)[8,9]引用的文獻(xiàn)較少,綜述不夠詳盡;王志國(guó)等人[10]從事件提取、表示及建模角度進(jìn)行了綜述,但對(duì)深度學(xué)習(xí)方法建模描述較少。
針對(duì)以上不足,本文從區(qū)分正常視頻和異常視頻的基本原理出發(fā),對(duì)基于深度學(xué)習(xí)的監(jiān)控視頻異常檢測(cè)方法進(jìn)行全面和系統(tǒng)的綜述。本文主要貢獻(xiàn)如下所示:
(1)從基本概念、方法流程、任務(wù)類型及學(xué)習(xí)范式等方面系統(tǒng)闡述了視頻異常檢測(cè)的基本內(nèi)涵,并側(cè)重強(qiáng)調(diào)了面向?qū)嶋H需求時(shí)檢測(cè)精度與檢測(cè)效率之間的平衡問(wèn)題。
(2)從正常與異常判定的基本原理出發(fā),將基于深度學(xué)習(xí)的視頻異常檢測(cè)方法分為基于重構(gòu)的方法、基于預(yù)測(cè)的方法、基于分類的方法及基于回歸的方法4類。系統(tǒng)綜述了各類方法的基本思想、代表性文獻(xiàn)及其優(yōu)缺點(diǎn)。
(3)全面總結(jié)了現(xiàn)有單場(chǎng)景視頻異常檢測(cè)數(shù)據(jù)集與評(píng)價(jià)指標(biāo),對(duì)比分析了代表性方法的性能,并從數(shù)據(jù)集、方法以及評(píng)估指標(biāo)3個(gè)方面對(duì)異常檢測(cè)研究的未來(lái)發(fā)展方向進(jìn)行了展望。
2 視頻異常檢測(cè)概述
視頻異常檢測(cè)任務(wù)流程如圖1所示。對(duì)于給定的某一特定場(chǎng)景下的正常視頻數(shù)據(jù)樣本,首先從中提取視頻幀或視頻窗內(nèi)圖像的運(yùn)動(dòng)及外觀特征,并建立模型對(duì)正常樣本的分布進(jìn)行學(xué)習(xí)。測(cè)試時(shí),將提取的測(cè)試樣本特征輸入模型,模型依據(jù)重構(gòu)誤差、預(yù)測(cè)誤差、異常分?jǐn)?shù)和峰值信噪比等指標(biāo)對(duì)其進(jìn)行異常判定。
2.1 視頻異常檢測(cè)的基本類型
視頻異常檢測(cè)的基本類型可分為以下2種:
(1)局部異常和全局異常:局部異常通常指在適度或密集擁擠環(huán)境中某個(gè)個(gè)體的活動(dòng)明顯偏離其相鄰個(gè)體;全局異常是指特定場(chǎng)景下整體異常,也許局部個(gè)體的活動(dòng)可能是正常的。
(2)時(shí)間異常和空間異常:時(shí)間異常是指與運(yùn)動(dòng)信息相關(guān)的異常,反映視頻幀之間的變化規(guī)律;空間異常是指與位置相關(guān)的異常,反映視頻幀內(nèi)部的異常信息。
2.2 視頻異常檢測(cè)的學(xué)習(xí)范式
視頻異常檢測(cè)主要有4種學(xué)習(xí)范式,分別為有監(jiān)督、無(wú)監(jiān)督、弱監(jiān)督和自監(jiān)督。
(1)有監(jiān)督學(xué)習(xí):有監(jiān)督學(xué)習(xí)是指已知數(shù)據(jù)樣本和其一一對(duì)應(yīng)的標(biāo)簽,通過(guò)模型訓(xùn)練,將所有數(shù)據(jù)樣本映射到不同類別標(biāo)簽的過(guò)程。對(duì)于視頻異常檢測(cè),即指使用正常樣本和異常樣本以及相應(yīng)的標(biāo)簽,訓(xùn)練一個(gè)二分類器進(jìn)行異常檢測(cè)。但是,由于異常視頻的稀缺性,使得基于有監(jiān)督學(xué)習(xí)的視頻異常檢測(cè)方法較為少見(jiàn)。
(2)無(wú)監(jiān)督學(xué)習(xí):基于無(wú)監(jiān)督學(xué)習(xí)的異常視頻檢測(cè)是指不依賴視頻標(biāo)注信息,依靠樣本數(shù)據(jù)之間的相似性對(duì)正常樣本進(jìn)行學(xué)習(xí)、聚類或分布建模,測(cè)試時(shí)把遠(yuǎn)離正常樣本的視頻看作異常,進(jìn)而實(shí)現(xiàn)異常檢測(cè)。使用無(wú)監(jiān)督學(xué)習(xí)范式進(jìn)行視頻異常檢測(cè)通常需要提供充足的正常視頻數(shù)據(jù)。
(3)弱監(jiān)督學(xué)習(xí):基于弱監(jiān)督學(xué)習(xí)的視頻異常檢測(cè)是指僅依賴視頻級(jí)標(biāo)注信息進(jìn)行建模,在測(cè)試時(shí)可進(jìn)行逐幀或視頻片段的異常檢測(cè)。基于弱監(jiān)督學(xué)習(xí)的視頻異常檢測(cè)方法對(duì)于數(shù)據(jù)的標(biāo)簽依賴大幅降低,不再依賴逐幀標(biāo)簽,很大程度上降低了數(shù)據(jù)的標(biāo)注工作量,方便使用大規(guī)模數(shù)據(jù)集,進(jìn)而可增強(qiáng)檢測(cè)方法對(duì)不同場(chǎng)景的適應(yīng)能力,以及對(duì)不同異常類型的檢測(cè)性能。
(4)自監(jiān)督學(xué)習(xí):基于自監(jiān)督學(xué)習(xí)的視頻異常檢測(cè)是指模型直接從無(wú)標(biāo)簽數(shù)據(jù)中自行學(xué)習(xí),無(wú)需標(biāo)注數(shù)據(jù)。自監(jiān)督學(xué)習(xí)不再依賴標(biāo)注,而是通過(guò)學(xué)習(xí)數(shù)據(jù)各部分之間的聯(lián)系,從大規(guī)模的無(wú)標(biāo)簽數(shù)據(jù)中挖掘自身的監(jiān)督信息生成的標(biāo)簽,用于指導(dǎo)自身進(jìn)行訓(xùn)練。自監(jiān)督視頻異常檢測(cè)方法通常考慮的是一種更具有挑戰(zhàn)的實(shí)驗(yàn)設(shè)置,即不依賴任何訓(xùn)練數(shù)據(jù)。
2.3 視頻異常檢測(cè)的評(píng)價(jià)方式
視頻異常檢測(cè)主要有2種評(píng)價(jià)方式,分別為精度優(yōu)先和效率優(yōu)先。
(1)精度優(yōu)先:精度優(yōu)先的視頻異常檢測(cè)方法要求對(duì)異常的檢測(cè)和定位有較高的精度和較低的虛警率。該類方法的目的是通過(guò)使用所有可用的訓(xùn)練數(shù)據(jù)集視頻、固定的模型參數(shù)和預(yù)定義或微調(diào)的異常閾值來(lái)保證高精度,但很難保證模型的實(shí)時(shí)性。
(2)效率優(yōu)先:效率優(yōu)先的視頻異常檢測(cè)方法旨在以最快的幀處理速度獲得具有競(jìng)爭(zhēng)力的精度來(lái)檢測(cè)和定位視頻異常。該類方法的目的是使視頻異常檢測(cè)方法能夠具有較快的實(shí)時(shí)處理速度,滿足在線檢測(cè)的需求,因而更適合實(shí)際應(yīng)用。
3 基于深度學(xué)習(xí)的視頻異常檢測(cè)方法
不同于大多基于學(xué)習(xí)范式和建模流程的分類策略,本文從區(qū)分正常視頻和異常視頻的基本原理出發(fā),將基于深度學(xué)習(xí)的視頻異常檢測(cè)方法分為基于重構(gòu)的方法、基于預(yù)測(cè)的方法、基于分類的方法和基于回歸的方法。
3.1 基于重構(gòu)的方法
基于重構(gòu)的視頻異常檢測(cè)方法的核心思想是通過(guò)訓(xùn)練正常視頻數(shù)據(jù)來(lái)獲得正常數(shù)據(jù)的分布表示。在測(cè)試過(guò)程中,正常測(cè)試樣本會(huì)具有較小的重構(gòu)誤差,而異常樣本的重構(gòu)誤差則較大,從而實(shí)現(xiàn)視頻的異常檢測(cè)。若令x代表一個(gè)視頻片段或視頻幀,g代表重構(gòu)x的神經(jīng)網(wǎng)絡(luò),f()代表計(jì)算x與g(x)之間重構(gòu)誤差的函數(shù),ε代表重構(gòu)誤差,基于重構(gòu)的深度學(xué)習(xí)方法可以看作是在極小化式(1)中的重構(gòu)誤差。
ε=f(x,g(x))
(1)
一種常用的重構(gòu)方法為自編碼器。Xu等人[11]提出了一種外觀運(yùn)動(dòng)深度網(wǎng)絡(luò)AMDN(Appearance and Motion Deep Net),能夠同時(shí)提取視頻的外觀和運(yùn)動(dòng)信息,并使用多個(gè)單類支持向量機(jī)SVM(Support Vector Machine)預(yù)測(cè)每個(gè)輸入的異常得分,最后集成分?jǐn)?shù)用于最終的異常檢測(cè)。Hasan等人[12]提出了2種基于自編碼器的方法,首先利用傳統(tǒng)手工方法提取時(shí)空特征,并在其上學(xué)習(xí)一個(gè)全連接的自編碼器;其次建立一個(gè)全卷積前饋?zhàn)跃幋a器學(xué)習(xí)局部特征和分類器作為端到端的學(xué)習(xí)框架,使其能夠在很少或者無(wú)監(jiān)督的情況下進(jìn)行視頻異常檢測(cè)。但是,由于深度神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力較強(qiáng),導(dǎo)致自編碼器有時(shí)不僅能將正常樣本重構(gòu)得較好,同時(shí)也使得異常樣本具有較小的重構(gòu)誤差。針對(duì)這一問(wèn)題,Gong等人[13]提出了一種改進(jìn)的自編碼器,稱為記憶增強(qiáng)自編碼器MemAE(Memory-augmented AutoEncoder)。當(dāng)給定輸入時(shí),該方法首先從編碼器獲取編碼,然后使用它作為查詢檢索最相關(guān)的記憶項(xiàng)進(jìn)行重構(gòu)。Park等人[14]在Gong等人[13]的研究工作基礎(chǔ)上,使用一個(gè)具有更新方案的記憶模塊,使得記錄數(shù)據(jù)原型模式的項(xiàng)可以不斷更新,以更好地記住正常樣本,并在公開基準(zhǔn)數(shù)據(jù)集上取得了可以媲美當(dāng)時(shí)最先進(jìn)方法的異常檢測(cè)效果。
基于重構(gòu)的視頻異常檢測(cè)的另一種常用方法為稀疏編碼,其思想主要是通過(guò)構(gòu)造一組能夠表達(dá)正常視頻的字典,使得正常視頻能夠通過(guò)該字典很好地重構(gòu)出來(lái),而異常的視頻則會(huì)變得模糊甚至無(wú)法重構(gòu)。假設(shè)輸入的視頻特征X=[x1,x2,…,xk],其中每個(gè)xi代表正常的視頻幀特征,基于稀疏編碼方法的目標(biāo)是找到一個(gè)最優(yōu)字典D,從而能夠通過(guò)稀疏系數(shù)α=[α1,α2,…,αk]將X重構(gòu)出來(lái),其中D和α通過(guò)交替迭代優(yōu)化獲得。其目標(biāo)函數(shù)如式(2)所示:
(2)
Zhao等人[15]早在2011年提出了一種無(wú)監(jiān)督的動(dòng)態(tài)稀疏編碼方法檢測(cè)視頻中的異常事件,該方法首先對(duì)輸入視頻序列提取時(shí)空興趣點(diǎn),并依據(jù)上下文視頻數(shù)據(jù)學(xué)習(xí)字典,在測(cè)試過(guò)程中依據(jù)字典基底能否重構(gòu)出查詢事件來(lái)判定異常。考慮到字典的大小會(huì)影響模型的計(jì)算復(fù)雜度,Cong等人[16]設(shè)計(jì)了一種具有稀疏一致性約束的字典選擇方法,通過(guò)引入稀疏重構(gòu)代價(jià)SRC(Sparse Reconstruction Cost)達(dá)到壓縮字典的目的。此外,Luo等人[17]指出基于字典學(xué)習(xí)的異常檢測(cè)方法在稀疏系數(shù)迭代優(yōu)化過(guò)程中非常耗時(shí),于是提出一種時(shí)間相干稀疏編碼TSC(Temporally-coherent Sparse Coding)網(wǎng)絡(luò),用于約束相鄰幀以相似的重構(gòu)系數(shù)進(jìn)行編碼,并使用一種特殊類型的堆疊遞歸神經(jīng)網(wǎng)絡(luò)sRNN(stacked Recurrent Neural Network)映射TSC,從而實(shí)現(xiàn)參數(shù)的加速優(yōu)化。Luo等人[18]在文獻(xiàn)[17]的基礎(chǔ)上對(duì)TSC進(jìn)行了改進(jìn),在TSC的sRNN上再疊加一層,以減少優(yōu)化過(guò)程中字典和稀疏系數(shù)交替更新計(jì)算成本。考慮到視頻異常檢測(cè)實(shí)時(shí)性的重要性,Wu等人[19]提出一種雙流神經(jīng)網(wǎng)絡(luò)提取隱藏層的時(shí)空融合特征STFF(Spatial-Temporal Fusion Features),并對(duì)STFF使用快速稀疏編碼網(wǎng)絡(luò)FSCN(Fast Sparse Coding Network)來(lái)構(gòu)建一個(gè)字典,F(xiàn)SCN與傳統(tǒng)網(wǎng)絡(luò)相比,不僅測(cè)試速度快了數(shù)百倍,而且精度也達(dá)到了先進(jìn)水平。
3.2 基于預(yù)測(cè)的方法
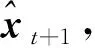
(3)
Liu等人[20]提出了一種基于預(yù)測(cè)模型進(jìn)行視頻異常檢測(cè)的框架,使用U-Net(U-shaped Network)作為生成器用于生成未來(lái)幀,并使用強(qiáng)度損失、梯度損失和光流損失共同約束生成的未來(lái)幀質(zhì)量,再通過(guò)判別器判斷生成幀的真假,以強(qiáng)化預(yù)測(cè)模型的預(yù)測(cè)能力。受LSTM(Long Short-Term Memory)處理時(shí)序數(shù)據(jù)的啟發(fā),Medel等人[21]提出了一種復(fù)合的Conv-LSTM(Convolutional LSTM),對(duì)視頻序列進(jìn)行建模,通過(guò)對(duì)解碼過(guò)程進(jìn)行約束,能夠重構(gòu)過(guò)去幀和預(yù)測(cè)未來(lái)幀,進(jìn)而實(shí)現(xiàn)視頻的異常檢測(cè)。Lu等人[22]將VAE(Variational AutoEncoder)與Conv-LSTM相結(jié)合,提出Conv-VRNN(Convolutional Variational Recurrent Neural Network)網(wǎng)絡(luò)結(jié)構(gòu),用于生成視頻未來(lái)幀。考慮到預(yù)測(cè)過(guò)程中均方差損失函數(shù)可能造成的未來(lái)幀模糊現(xiàn)象,Mathieu等人[23]使用一種卷積網(wǎng)絡(luò),通過(guò)交替卷積和矯正線性單元ReLU(Rectified Linear Unit)生成未來(lái)幀,并提出將多尺度結(jié)構(gòu)、對(duì)抗訓(xùn)練和圖像梯度差異3種不同的特征學(xué)習(xí)策略進(jìn)行融合的方法來(lái)生成清晰的未來(lái)幀。此外,Ye等人[24]提出了一種深度預(yù)測(cè)編碼網(wǎng)絡(luò)AnoPCN(A novel deep Predictive Coding Network)來(lái)解決異常檢測(cè)問(wèn)題,該網(wǎng)絡(luò)由預(yù)測(cè)編碼模塊PCM(Predictive Coding Module)和誤差細(xì)化模塊ERM(Error Refinement Module)組成,將PCM設(shè)計(jì)成Conv-LSTM網(wǎng)絡(luò)結(jié)構(gòu)用于生成未來(lái)幀,引入ERM重構(gòu)預(yù)測(cè)誤差,通過(guò)將重構(gòu)和預(yù)測(cè)方法統(tǒng)一到端到端的框架中實(shí)現(xiàn)異常檢測(cè)。
3.3 基于分類的方法
雖然目前主流模型主要依賴基于重構(gòu)和未來(lái)幀的預(yù)測(cè)方法,但仍然有一些研究工作將該問(wèn)題看作是分類問(wèn)題。這種分類方法可以用一個(gè)通用的公式描述:令x代表輸入視頻幀或視頻片段,h()代表通過(guò)網(wǎng)絡(luò)訓(xùn)練得到的映射函數(shù),y表示相應(yīng)的所屬類別,公式如式(4)所示:
y=h(x),y∈R
(4)
基于分類的視頻異常檢測(cè)方法主要分為單分類和多分類2種。基于單分類方法的視頻異常檢測(cè)的主要思想是通過(guò)正常視頻數(shù)據(jù)訓(xùn)練一個(gè)單類分類器,在測(cè)試過(guò)程中分類器只需要判別給定數(shù)據(jù)是否屬于該類即可。Sabokrou等人[25]受GAN(Generative Adversarial Network)在無(wú)監(jiān)督和半監(jiān)督環(huán)境中訓(xùn)練深度模型的啟發(fā),提出了一種基于單分類的視頻異常檢測(cè)方法。在此基礎(chǔ)上,Wu等人[26]提出了一種深度單分類神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),使用堆疊的卷積編碼器生成低維的高級(jí)表示信息,并通過(guò)結(jié)合對(duì)抗機(jī)制與解碼器,能夠在僅給定正常樣本的前提下訓(xùn)練得到緊湊的單類分類器,進(jìn)而實(shí)現(xiàn)異常檢測(cè)。對(duì)于多分類的視頻異常檢測(cè)方法,Narasimhan等人[27]提出了一種利用局部特征和全局特征的方法,對(duì)于局部特征,在視頻立方體塊上使用圖像相似度來(lái)表示時(shí)間和空間特征,使用訓(xùn)練后的自編碼器的特征向量來(lái)表示全局特征,再將特征送入高斯分類器進(jìn)行二分類異常檢測(cè)。Ionescu等人[28]將異常檢測(cè)問(wèn)題轉(zhuǎn)化為一個(gè)單對(duì)剩余類的二分類問(wèn)題,在卷積自編碼器生成的特征上使用聚類,訓(xùn)練一個(gè)單對(duì)剩余類分類器來(lái)區(qū)分聚類。在測(cè)試過(guò)程中若通過(guò)分類器得到的最高分類分?jǐn)?shù)為負(fù)數(shù),則表明該樣本不屬于任何聚類,即將其標(biāo)記為異常。除二分類外,Xu等人[29]提出一種自適應(yīng)幀內(nèi)分類網(wǎng)絡(luò)AICN(Adaptive Intra-frame Classification Network),將視頻異常檢測(cè)任務(wù)轉(zhuǎn)化為多分類問(wèn)題。該網(wǎng)絡(luò)接受原始輸入,將提取的運(yùn)動(dòng)和外觀特征分為若干個(gè)子區(qū)域,并對(duì)每一個(gè)子區(qū)域進(jìn)行分類。在測(cè)試過(guò)程中若該子區(qū)域的測(cè)試分類結(jié)果與真實(shí)分類不同,則被視為異常。
3.4 基于回歸的方法
除了上述提到的基于重構(gòu)、基于預(yù)測(cè)和基于分類的方法以外,一些研究人員也將該問(wèn)題定義為回歸問(wèn)題。其主要思想是將異常得分作為評(píng)估指標(biāo),設(shè)置適當(dāng)?shù)拈撝担舢惓5梅指哂陂撝担瑒t將其視作異常,否則便為正常。令x代表輸入的視頻幀,k()代表輸入x的函數(shù),實(shí)數(shù)z表示輸出的異常分?jǐn)?shù),如式(5)所示:
z=k(x),z∈R
(5)
Sultani等人[30]提出了一種主要在弱監(jiān)督條件下訓(xùn)練的多示例學(xué)習(xí)方法,首先將每一個(gè)訓(xùn)練視頻分成數(shù)量相等的片段,分別構(gòu)成正例包(只包含正常視頻幀)和負(fù)例包(至少包含一幀異常視頻幀),使用C3D(Convolutional 3D)對(duì)每個(gè)視頻片段提取時(shí)空特征;再將特征輸入神經(jīng)網(wǎng)絡(luò)進(jìn)行打分,從正例包和負(fù)例包中分別挑出得分最高的片段用于訓(xùn)練模型參數(shù);最后通過(guò)鉸鏈損失使得模型對(duì)異常樣本輸出高分,而對(duì)正常樣本輸出低分,在測(cè)試時(shí)依據(jù)模型輸出的異常得分進(jìn)行判定。在此基礎(chǔ)上,Kamoona等人[31]指出文獻(xiàn)[30]使用的鉸鏈損失函數(shù)是不光滑的,在優(yōu)化過(guò)程中可能會(huì)面臨梯度消失的風(fēng)險(xiǎn),提出了一種新的損失函數(shù),從而使得模型對(duì)輸出異常得分具有魯棒性。由于提取視頻特征對(duì)于輸出異常得分至關(guān)重要,Zhu等人[32]放棄使用C3D,改為計(jì)算光流信息,再將計(jì)算得到的光流信息輸入到時(shí)間增強(qiáng)網(wǎng)絡(luò)輸出異常得分。這一方法顯著提高了異常檢測(cè)的性能。考慮到手工標(biāo)注正常/異常視頻數(shù)據(jù)的復(fù)雜性,Pang等人[33]設(shè)計(jì)了一種端到端可訓(xùn)練的視頻異常檢測(cè)方法,該方法可以在無(wú)需手工標(biāo)記正常/異常數(shù)據(jù)的基礎(chǔ)上進(jìn)行表示學(xué)習(xí)并輸出異常得分,進(jìn)而實(shí)現(xiàn)視頻的異常檢測(cè)。
3.5 小結(jié)
本節(jié)主要從區(qū)分正常視頻和異常視頻的基本原理出發(fā),將基于深度學(xué)習(xí)的視頻異常檢測(cè)方法分為基于重構(gòu)、基于預(yù)測(cè)、基于分類及基于回歸4類方法。這4類方法的對(duì)比、歸納和總結(jié)如表1所示。

Table 1 Comparison and summary of different kinds of methods
基于重構(gòu)和基于預(yù)測(cè)的方法對(duì)提取的視頻幀特征依賴性很高,具有較高的空間復(fù)雜度和時(shí)間復(fù)雜度,對(duì)異常較少的視頻數(shù)據(jù)檢測(cè)效果較好,適用于視頻數(shù)量較少的數(shù)據(jù)集,能夠?qū)?jí)別的異常進(jìn)行有效的時(shí)空檢測(cè)與定位。基于分類的方法適用于具有充足正常視頻的數(shù)據(jù)集,從而有利于更好地學(xué)習(xí)到正常視頻模式的分布,但也需要更多的訓(xùn)練時(shí)間,能夠檢測(cè)并定位到視頻幀級(jí)別的異常。上述基于重構(gòu)、基于預(yù)測(cè)和基于分類的方法通常采用無(wú)監(jiān)督的學(xué)習(xí)范式,適用于對(duì)視頻進(jìn)行幀級(jí)別的檢測(cè)定位。作為對(duì)比,基于回歸的方法通常與弱監(jiān)督學(xué)習(xí)方法相結(jié)合,適用于視頻數(shù)量較多的大型數(shù)據(jù)集,主要對(duì)視頻級(jí)別或視頻片段級(jí)別進(jìn)行異常檢測(cè),能夠檢測(cè)定位到視頻中的視頻片段是否包含異常。
4 視頻異常檢測(cè)數(shù)據(jù)集
表2列出了目前常用的6個(gè)單場(chǎng)景異常檢測(cè)數(shù)據(jù)集的具體信息。
(1)UMN數(shù)據(jù)集。
UMN數(shù)據(jù)集[34]共有11個(gè)視頻,包含校園草坪、室內(nèi)和廣場(chǎng)3個(gè)不同場(chǎng)景。該數(shù)據(jù)集屬于全局異常行為的數(shù)據(jù)集。由于此數(shù)據(jù)集包含的視頻數(shù)量較少,使用重構(gòu)方法能夠充分捕捉到全局特征并進(jìn)行幀級(jí)檢測(cè)定位。目前基于深度學(xué)習(xí)方法在該數(shù)據(jù)上的異常檢測(cè)準(zhǔn)確率已經(jīng)達(dá)到99.7%,研究人員逐漸不再使用此數(shù)據(jù)集。
(2)Subway數(shù)據(jù)集。
Subway數(shù)據(jù)集[35]包含地鐵入口處(Entrance)和出口處(Exit)2類視頻。該數(shù)據(jù)集包含的視頻數(shù)量較少,使用重構(gòu)的方法能充分捕捉到視頻中的位置異常,進(jìn)而進(jìn)行幀級(jí)別的異常檢測(cè)定位。由于該數(shù)據(jù)集包含的異常數(shù)量較少且異常種類相對(duì)單一,可泛化性相對(duì)較差,因此現(xiàn)階段的研究人員較少使用。
(3)UCSD Pedestrain數(shù)據(jù)集。
UCSD行人數(shù)據(jù)集[36]的拍攝場(chǎng)景為某大學(xué)校園人行道。該數(shù)據(jù)集屬于局部異常行為數(shù)據(jù)集,數(shù)據(jù)集中視頻數(shù)量相對(duì)充足,適合基于重構(gòu)、基于預(yù)測(cè)和基于分類等方法。目前在UCSD Ped1和UCSD Ped2數(shù)據(jù)集上達(dá)到的幀級(jí)別異常檢測(cè)準(zhǔn)確率分別為97.4%和97.8%。雖然準(zhǔn)確率相對(duì)較高,但由于該數(shù)據(jù)集異常數(shù)量和異常種類相對(duì)充分,其目前仍是較受歡迎的幾個(gè)基準(zhǔn)數(shù)據(jù)集之一。
(4)CUHK Avenue數(shù)據(jù)集。
CUHK Avenue數(shù)據(jù)集[37]的拍攝場(chǎng)景為某大學(xué)校園主干道路。該數(shù)據(jù)集包含的視頻數(shù)量適中,適于基于重構(gòu)、基于預(yù)測(cè)和基于分類等方法。目前在CUHK Avenue數(shù)據(jù)集上達(dá)到的幀級(jí)別異常檢測(cè)準(zhǔn)確率為90.4%,還具有很大的提升空間,是目前使用較多的幾個(gè)基準(zhǔn)數(shù)據(jù)集之一。
(5)Street Scene數(shù)據(jù)集。
Street Scene數(shù)據(jù)集[38]的拍攝場(chǎng)景為某城市街道。該數(shù)據(jù)集是于2020年提出的,具有相對(duì)充足的視頻數(shù)量,適合基于重構(gòu)、基于預(yù)測(cè)和基于分類等方法。目前使用此數(shù)據(jù)集的論文較少,但考慮到其包含的異常數(shù)量和異常類型的多樣性,在實(shí)際城市街道中會(huì)具有較好的泛化性能,后續(xù)應(yīng)該會(huì)被眾多研究人員使用。
(6)IITB Corridor數(shù)據(jù)集。
IITB-Corridor數(shù)據(jù)集[39]是Rodrigues等人在2020年創(chuàng)建的大型數(shù)據(jù)集。該數(shù)據(jù)集適合采用回歸的方法,結(jié)合弱監(jiān)督學(xué)習(xí)范式,進(jìn)行視頻級(jí)別或視頻片段級(jí)別的異常檢測(cè)定位。雖然目前使用較少,但考慮到該數(shù)據(jù)集包含充足的異常數(shù)量和異常種類,在實(shí)際人類活動(dòng)中具有很好的泛化能力,后續(xù)應(yīng)該會(huì)被眾多研究人員使用。

Table 2 Commonly used single-scene anomaly datasets
5 視頻異常檢測(cè)性能評(píng)估
5.1 方法性能評(píng)價(jià)
(1)混淆矩陣。
當(dāng)異常樣本被預(yù)測(cè)為異常時(shí),稱為真陽(yáng)性TP(True Positive);當(dāng)正常樣本被預(yù)測(cè)為正常時(shí),稱為真陰性TN(True Negative);當(dāng)正常樣本被預(yù)測(cè)為異常時(shí),稱為假陽(yáng)性FP(False Positive);當(dāng)異常樣本被預(yù)測(cè)為正常時(shí),稱為假陰性FN(False Negative)。綜合上述4個(gè)指標(biāo)可以評(píng)價(jià)分類方法性能,即為混淆矩陣。
(2)ROC曲線。
ROC(Receiver Operating Characteristic)曲線是基于真陽(yáng)率TPR(True Positive Rate)和假陽(yáng)率FPR(False Positive Rate)繪制的曲線,ROC曲線包含的面積AUC(Area Under Curve)通常用于評(píng)價(jià)方法的性能。
(3)等錯(cuò)誤率。
等錯(cuò)誤率EER(Equal Error Rate)定義為當(dāng)真陽(yáng)率TPR與假陽(yáng)率FPR相等時(shí),錯(cuò)誤分類視頻幀所占的百分比。EER值越小,表明異常檢測(cè)方法性能越好。
5.2 方法性能比較
表3展示了近5年來(lái)基于深度學(xué)習(xí)的視頻異常檢測(cè)方法在UCSD、CUHK Avenue和Subway 3個(gè)代表性單場(chǎng)景數(shù)據(jù)集上的性能。由表3可知:
(1)從整體上看,基于重構(gòu)的方法在UCSD Ped1數(shù)據(jù)集上的異常檢測(cè)效果最好。基于預(yù)測(cè)和分類的方法在UCSD Ped2數(shù)據(jù)集上總體表現(xiàn)較好,使用持續(xù)學(xué)習(xí)的回歸類方法在該數(shù)據(jù)集上獲得了最高檢測(cè)精度。相比之下,現(xiàn)有方法在CUHK Avenue數(shù)據(jù)集上的AUC普遍較低,基于卷積自編碼器的分類方法的檢測(cè)精度最高。而Subway Entrance和Subway Exit數(shù)據(jù)集相對(duì)使用較少。

Table 3 Performance comparison of video anomaly detection methods based on deep learning
(2)基于自編碼器的深度學(xué)習(xí)模型在基于重構(gòu)、基于預(yù)測(cè)、基于分類和基于回歸4類方法中均被廣泛采用。其原因在于大多視頻異常檢測(cè)方法均采用無(wú)監(jiān)督學(xué)習(xí)范式訓(xùn)練模型。而基于編碼-解碼表示學(xué)習(xí)的自編碼器在無(wú)監(jiān)督學(xué)習(xí)范式下可有效學(xué)習(xí)高維數(shù)據(jù)的低維表示。
(3)由于表中單場(chǎng)景視頻異常檢測(cè)數(shù)據(jù)集UCSD、Subway和CUHK Avenue的訓(xùn)練集均為正常視頻,且視頻中背景相對(duì)固定不變,只有前景發(fā)生變化,因此適合采用無(wú)監(jiān)督的視頻異常檢測(cè)方法,通過(guò)學(xué)習(xí)正常視頻的分布表示可獲得較高的檢測(cè)精度。
6 挑戰(zhàn)與展望
6.1 挑戰(zhàn)
目前基于深度學(xué)習(xí)方法的視頻異常檢測(cè)研究主要面臨著以下挑戰(zhàn)和問(wèn)題:(1)正常視頻和異常視頻之間的數(shù)據(jù)不平衡性。(2)缺乏異常視頻的注釋,對(duì)異常定義模糊。隨著現(xiàn)實(shí)生活中使用端到端的深度學(xué)習(xí)方法進(jìn)行異常檢測(cè)的部署,一些舊的數(shù)據(jù)集(如UMN、Subway或UCSD等)已經(jīng)無(wú)法滿足深度學(xué)習(xí)對(duì)于訓(xùn)練數(shù)據(jù)的需求,從而嚴(yán)重阻礙了端到端可訓(xùn)練深度學(xué)習(xí)模型的發(fā)展[56]。(3)基于深度學(xué)習(xí)方法進(jìn)行視頻異常檢測(cè)的計(jì)算成本較高。(4)深度學(xué)習(xí)模型對(duì)于視頻異常檢測(cè)尚不具有普適性。
6.2 展望
基于上述視頻異常檢測(cè)研究面臨的挑戰(zhàn)和問(wèn)題,本文對(duì)其未來(lái)的研究方向提出了以下展望。
6.2.1 構(gòu)建更多的數(shù)據(jù)集
考慮到視頻異常檢測(cè)在實(shí)際生活中的應(yīng)用,從泛化角度出發(fā),未來(lái)應(yīng)該構(gòu)建更多大規(guī)模的、具有豐富異常數(shù)量和異常種類并且?guī)в性敿?xì)異常標(biāo)簽的數(shù)據(jù)集。現(xiàn)有的視頻異常檢測(cè)數(shù)據(jù)集大多為單場(chǎng)景數(shù)據(jù)集,雖然無(wú)監(jiān)督方法在其上取得了較高的異常檢測(cè)準(zhǔn)確率,但是在實(shí)際應(yīng)用中的泛化性還遠(yuǎn)遠(yuǎn)不夠。例如,對(duì)于城市交通監(jiān)控視頻,期望異常檢測(cè)方法能夠?qū)Τ鞘袃?nèi)所有交通道路的監(jiān)控視頻進(jìn)行異常檢測(cè)而不局限于某一固定街區(qū)的道路監(jiān)控視頻。近年來(lái),多場(chǎng)景視頻異常檢測(cè)問(wèn)題逐漸受到關(guān)注,現(xiàn)已發(fā)布了UCF Crime[30]、Shanghaitech[57]和XD Violence[58]等包含多個(gè)場(chǎng)景的數(shù)據(jù)集。但是,對(duì)于未來(lái)的發(fā)展,仍需要包含更多異常種類和異常數(shù)量的大型數(shù)據(jù)集。
6.2.2 設(shè)計(jì)更好的方法
雖然許多先進(jìn)的深度學(xué)習(xí)方法都沒(méi)有對(duì)處理速度進(jìn)行說(shuō)明,但通過(guò)調(diào)查發(fā)現(xiàn),盡管目前大多數(shù)的方法都能夠取得較高的異常檢測(cè)準(zhǔn)確率,但大多數(shù)都還不能夠?qū)崟r(shí)性部署,其中一個(gè)關(guān)鍵原因在于深度學(xué)習(xí)方法提取視頻有效特征的時(shí)間成本過(guò)高。從實(shí)際應(yīng)用的角度考慮,及時(shí)準(zhǔn)確地發(fā)現(xiàn)異常能夠有效降低異常事件造成的損失,所以未來(lái)需要設(shè)計(jì)新的方法進(jìn)行高效的視頻數(shù)據(jù)預(yù)處理和特征提取,進(jìn)而突破處理速度的限制,使得這些系統(tǒng)能夠用于實(shí)時(shí)的檢測(cè)場(chǎng)景。
6.2.3 提出更可靠的評(píng)估指標(biāo)
目前絕大多數(shù)研究對(duì)于視頻異常檢測(cè)的評(píng)估均使用幀級(jí)別的異常檢測(cè)評(píng)估指標(biāo)。但是,從實(shí)際的應(yīng)用角度考慮,視頻異常檢測(cè)更應(yīng)該確定到幀內(nèi)的異常區(qū)域。一些研究人員嘗試使用像素級(jí)指標(biāo),但其使用的像素級(jí)指標(biāo)仍在計(jì)數(shù)真陽(yáng)性幀和假陽(yáng)性幀,而不是真陽(yáng)性異常區(qū)域和假陽(yáng)性異常區(qū)域。現(xiàn)有的像素級(jí)評(píng)估指標(biāo)將檢測(cè)到的異常區(qū)域與真實(shí)的異常區(qū)域重合度超過(guò)40%的視為真陽(yáng)性幀,將檢測(cè)到至少包含1個(gè)像素的異常區(qū)域與真實(shí)標(biāo)簽為不存在異常區(qū)域的現(xiàn)象視為假陽(yáng)性幀[38]。但這種評(píng)估指標(biāo)既不會(huì)獎(jiǎng)勵(lì)局部異常區(qū)域的緊湊性,也不會(huì)懲罰局部異常區(qū)域的松散性。因此,未來(lái)需要提出更可靠的評(píng)估指標(biāo),以評(píng)估精準(zhǔn)檢測(cè)到的局部異常區(qū)域。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
人大建設(shè)(2020年4期)2020-09-21 03:39:12
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
人大建設(shè)(2017年2期)2017-07-21 10:59:25
