基于項目特征與用戶興趣模糊性的推薦算法
2022-09-22 05:59:40黃向春趙芬霞安建業
軟件導刊 2022年9期
關鍵詞:用戶
黃向春,趙芬霞,安建業
(天津商業大學理學院 天津 300134)
0 引言
隨著大數據時代到來,各種數據信息快速增長。在面臨海量數據時,用戶通常需要花費大量時間尋找感興趣的信息,信息過載已成為互聯網發展不得不面對的挑戰。
為此,推薦系統應運而生。該系統通過收集用戶歷史信息或行為數據建立用戶或項目特征模型,預測用戶感興趣的信息然后推薦給用戶。如果電商網站能將用戶感興趣的產品準確推薦給用戶,不僅能夠增加電商網站的銷量,還能提升用戶對網站設計的滿意度,產生巨大的商業價值[1]。
根據推薦策略不同,推薦系統可分為基于內容的推薦、基于知識的推薦、基于規則的推薦、協同過濾的推薦、混合推薦等。其中,協同過濾推薦是目前發展最成熟、應用最廣泛的個性化推薦技術[2-6]。該類系統通過尋找與目標用戶興趣相似的“鄰居”,給目標用戶推薦可能感興趣的信息,系統整體設計較為簡單,僅基于統計的機器學習算法就能夠取得較好推薦效果。
然而,協同過濾推薦算法的推薦效果嚴重依賴于用戶的歷史偏好信息,當該類信息無法被收集或信息量過少時,會造成數據稀疏程度較高。此時,項目評價信息的真實性和有效性將無法得到保證[7],協同過濾算法的推薦效果也會相應降低。
1 相關研究
目前,為解決項目評分矩陣稀疏性問題的方法種類較多。例如,Ma[8]首先提出將SVD 矩陣分解應用于協同過濾推薦,在Netflix Prize 數據集上的實驗結果表明,該算法推薦準確率相較于基準算法具有一定的提升,且推薦結果穩定性較強。Goldberg 等[9]利用主成分分析降維技術構建推薦算法,并將其成功應用于“笑話”推薦上,實踐結果表明算法效果較好。李紅梅等[10]提出一種改進LSH 的協同過濾算法,該算法有效克服評分數據的高維稀疏問題。然而,上述算法并未考慮項目特征或用戶偏好的模糊性問題。
為此,Zhang 等[11]使用三角模糊數描述用戶對項目的綜合評價,根據三角形面積和中點衡量三角模糊數的相似度,確定用戶相似度,提升相似度計算的準確率。然而,三角模糊數中隸屬度的最大值只對應一個點,靈活性低于梯形模糊數,可擴展性較差。吳毅濤等[12]借鑒年齡模糊模型,將滿意度映射到原始評分上,通過梯形模糊相似度計算策略衡量用戶相似度提升推薦效果[13-15],同時證明模糊相似度是余弦相似度在模糊域上的擴展,實驗結果表明該算法的預測精度優于基于三角模糊數的協同過濾算法。然而,該模型的結構相對固定,無法隨數據集和用戶的改變自動調整。Wu等[16]在文獻[9]的基礎上,根據評分分布情況自動生成個性化梯形模糊評分模型,基于模糊相似度和模糊評分預測評分提升推薦質量,實驗結果表明該算法的預測誤差更低。王森等[17]構建一種新的梯形模糊評分模型,通過融合基于模糊評分的項目相似度和基于標簽隸屬度的項目相似度形成新的項目相似度,進一步提升了推薦準確率。
然而,項目特征和用戶興趣均具有一定程度的模糊性。例如,對電影《戰狼1》進行項目特征劃分時,它的所屬類別并非是絕對的、唯一的,多數觀眾認為它屬于動作類、軍事類、戰爭題材的電影,但也有一部分觀眾認為它是愛情類電影。為了綜合所有觀眾的評價,設定《戰狼1》隸屬于動作類電影的程度為80%;隸屬于軍事類電影的程度為85%;隸屬于愛情類電影的程度為20%。同理,用戶對電影的喜愛程度也可按照此情況進行劃分。通過綜合考慮用戶興趣和項目相似度來計算推薦信任分,據此給出更為準確的推薦結果。
2 算法描述
2.1 模糊集和隸屬函數
設在論域X上給定集值映射μA:X→[0,1],記作μA(x),即μA確定了X上的一個模糊集,記為A,μA(x)為x對A的隸屬度,記為:A={(x,μA(x))|x∈X}。在模糊理論中,常見模糊集包括矩陣型、三角形、梯形、K 次拋物線型、高斯型、柯西型等。
2.2 項目特征隸屬度矩陣
隸屬度可用來描述項目對于不同類別的所屬程度。例如,對項目Ij(j=1,2,…,N)而言,將項目所屬類別定義在空間X={x1,x2,…,xK}中,Ij的隸屬度函數可表示為μk(Ij)[18]。本文采用類高斯隸屬函數[19]描述項目的特征模糊性。計算公式如式(1)所示:
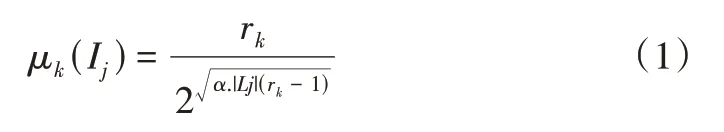
其中,N=|Lj|為項目Ij所對應項目特征屬性的個數,rk(1 ≤rk≤|Lj|)為項目Ij屬于第k個類別的秩,α一般設置為1.2[20],μk(Ij)是關于rk的遞減函數,以電影數據集為例,排序靠前的類別可賦予高的隸屬度,與電影無關的類別其隸屬度可賦予0。
然而,不同電影之間相同的所屬類別,由于所在位序存在不同,對應的隸屬度也會不同[21]。例如,電影Toy Story(選自MovieLens 100K 數據集),類別有Adventure、Animation、Children′s,所屬類別的秩依次為rk=1、2、3,這3 個類別在所有類別中的序號依次為3、4、5。根據式(1)計算電影Toy Story 對應類別的隸屬程度分別為:μ3(Ij)=1、μ4(Ij)=0.536、μ5(Ij)=0.467、μk(Ij)=0,(k=1,2,6,7,···,19),k表示電影的類別序號,即電影Toy Story 屬于Adventure、Animation、Children′s的隸屬程度分別為1、0.536、0.467。
本文從MovieLens 100k 電影數據集中,選取用戶5 的觀影記錄,觀影記錄所屬類別的隸屬度如表1所示。
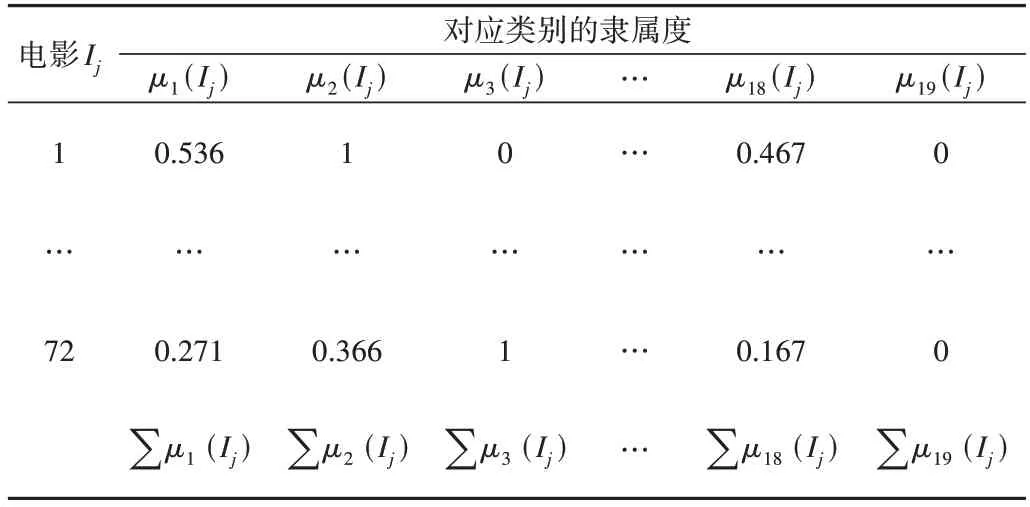
Table 1 Film category membership表1 電影類別隸屬度
2.3 用戶類別偏好矩陣
利用類高斯隸屬度函數可構建項目特征隸屬度矩陣UN×K,N、K分別表示項目總數和項目特征個數。將單個用戶的項目特征隸屬度矩陣按列相加,結果表示用戶訪問項目類別隸屬程度的總和,總和越大表示用戶對該類別項目的喜歡程度越高。基于此,生成該用戶的類別偏好向量s[15]。s=(p1,p2,…,p19),將s歸一化為s′=(s1,s2,…,s19),其中sk為:

最后,將所有用戶的類別偏好向量作為行,構造用戶類別偏好矩陣SM×K。其中,M表示用戶個數,K為項目類別個數。
2.4 用戶興趣模型
由于用戶對項目的評分受用戶類別偏好的影響,因此對于兩種不同類別的項目,相同的項目評分可能代表著不同的喜好程度。為此,通過用戶類別偏好矩陣SM×K對用戶評分矩陣RM×N進行修正。計算公式如下:
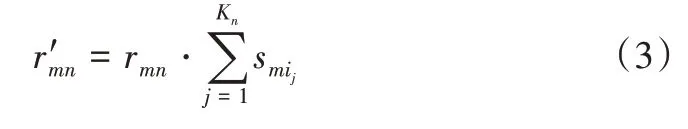
其中,r′mn為第m個用戶對第n個項目修正后的評分,rmn為第m個用戶對第n個項目的原始分,Kn為第n個項目所屬項目類別的總數,設其所對應的類別序號依次為為第m個用戶對第n個項目所屬第ij類型的偏好程度,修正后的用戶項目評分矩陣記為。通過用戶類別偏好矩陣修正后的用戶項目評分數據更離散化,能準確代表用戶對項目的喜好程度。
然后,利用修正后的用戶項目評分矩陣構建項目Ij的用戶興趣模型。在構造用戶興趣模型時,將用戶對電影的興趣分為非常喜歡、喜歡、不喜歡和非常不喜歡,由于要將修正后的評分均值作為用戶喜歡和不喜歡的臨界點,在多次實驗測試后,選擇將0.75 為臨界點,構建的梯形隸屬度函數如下:
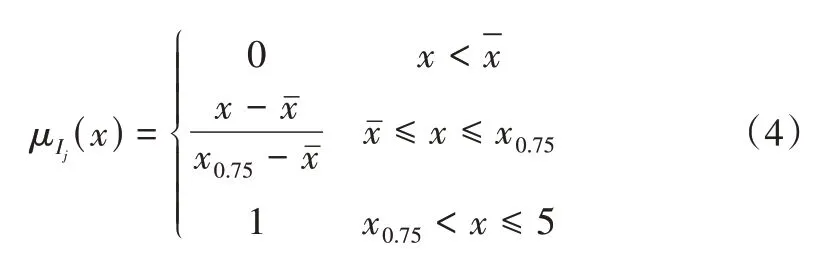
其中,x為用戶u對項目的修正評分值,為用戶u修正評分的均值,x0.75為用戶u修正評分的0.75 分位數。電影數據用戶的評分最高為5,因此x的上限設定為5,并定義用戶喜歡的項目集合為
2.5 推薦信任分
經過多次實驗比較后,本文選用cosine 余弦計算項目之間的相似度,即項目Ii和Ij的相似度計算公式為:
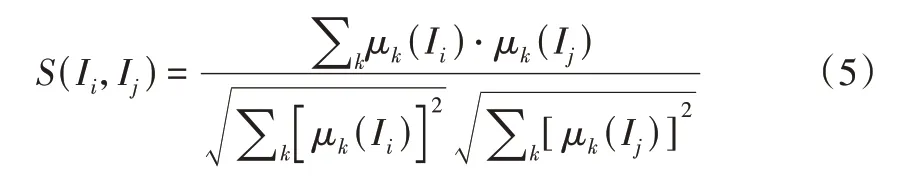
接下來,綜合用戶的興趣和項目間的相似度計算推薦信任分,計算公式如式(6)所示:
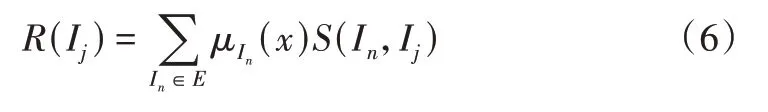
其中,μIn(x)為用戶對項目In的喜歡程度,S(In,Ij)為In與要推薦項目Ij之間的相似度,推薦信任分R(Ij)表示用戶喜好程度與相似程度的加權和,數值越高表示推薦信任分越高。
最后,根據R(Ij)大小產生Top -N 進行推薦。
3 實驗結果與分析
3.1 數據集
MovieLens 100k 數據集包括943 個用戶對1 682 部電影的10 萬條評分數據,電影類別總共有19 種,分別為動作、冒險、動畫等。每名用戶至少對20 部、至多對737 部電影進行評分,評分為1-5的整數。
實驗采用準確率(Precision)和召回率(Recall)作為系統評價指標,計算公式如式(7)、式(8)所示:

其中,用戶u推薦的P個物品記為R(u),用戶u在測試集上喜歡的物品集合為T(u)。
3.2 實驗步驟
本文實驗具體步驟如下:
步驟1:調用MovieLens 100k 數據集中的u.data 文件(用戶電影評分數據),生成用戶電影評分矩陣。
步驟2:輸入數據集中的u.Item 文件(電影所屬類別數據),根據公式(1)生成電影所屬類別的隸屬度矩陣。
步驟3:根據電影所屬類別和用戶的觀影記錄,根據公式(2)構建用戶—電影類別偏好矩陣。
步驟4:通過用戶—電影類別偏好矩陣,根據公式(3)對用戶電影評分矩陣進行評分修正。
步驟5:基于修正后的評分,根據公式(4)獲得用戶喜歡的項目集合E。
步驟6:從數據集中隨機抽取100 個用戶作為樣本,將單個用戶修正后的電影評分劃分為訓練集和測試集,訓練集的大小依次為5、15、25、35、45、55,剩余樣本作為測試集。
步驟7:通過用戶興趣模型確定每個用戶感興趣的項目個數,并通過式(5)、式(6)計算測試集的電影推薦信任分。
步驟8:根據推薦信任分產生Top -N,計算推薦的準確率(Precision)及召回率(Recall)。
3.3 實驗結果
本文提出的基于項目特征與用戶興趣模糊性的推薦算法(Based on the fuzziness of item features and user interest method,FIUM)分別選擇了5、15、25、35、45、55 的訓練集個數,推薦Top-5的準確率如圖1所示。
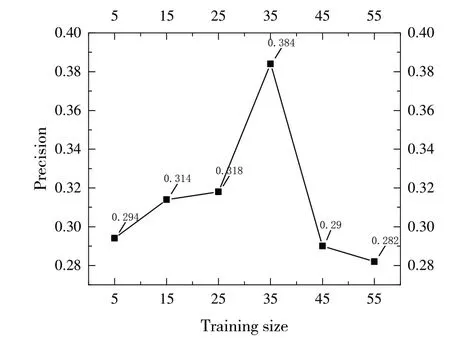
Fig.1 Accuracy of FIUM algorithm圖1 FIUM算法準確率
由圖1 可見,隨著訓練集數目增加,推薦準確率先增加再減少,最后趨于穩定,表明一旦訓練集的數目足夠代表用戶興趣時,增加訓練集的個數將不再提高推薦準確率。
接下來,將FIUM 與基于用戶的協同過濾推薦算法(User-based-CF,UCF)和基于項目的協同過濾推薦算法(Item-based-CF,ICF)進行比較。設定UCF 的鄰居個數與ICF 相似項目個數K為9,FIUM 的訓練集個數同樣設置為9,N取1-300,算法的Top -N 推薦準確率及召回率分別如圖2、圖3所示。

Fig.2 Comparison of accuracy between FIUM and UCF and ICF圖2 FIUM與UCF和ICF準確率比較
實驗結果表明,隨著推薦數目增多,相較于UCF 和ICF,FIUM 算法平均準確率分別提高39.66%和5.74%;平均召回率分別提高36.68%和158.76%。當推薦數目大于10 時,FIUM 的準確率明顯高于UCF 算法;當推薦數目大于100時,FIUM 算法召回率明顯高于ICF 算法的召回率。
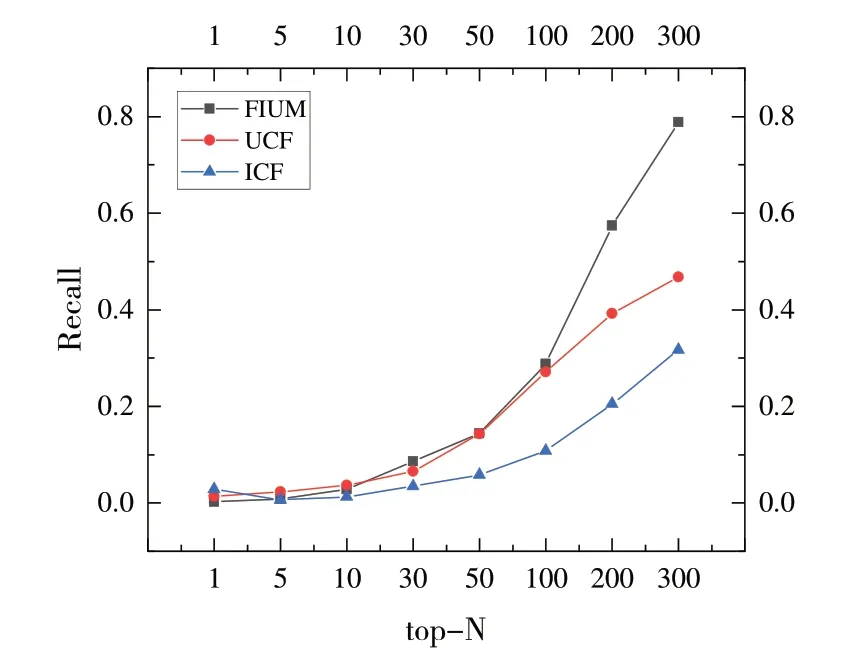
Fig.3 Comparison of recall between FIUM and UCF and ICF圖3 FIUM與UCF和ICF召回率比較
4 結語
本文提出了基于項目特征和用戶興趣模糊性的推薦算法,并與基于用戶和基于項目的協同過濾算法進行比較。實驗結果表明,該算法的召回率和推薦準確率相較于比較模型均有所提升。
然而,該算法需要計算用戶感興趣的項目與各個項目之間的相似度,在面對海量項目推薦時,計算量較大,會導致系統推薦效率降低。并且,MovieLens 觀影數據除了以上常規數據外,還含有導演信息、演員信息、時間等信息,現階段還未將其充分利用。下一步,將嘗試對此類信息進行模糊化或直接加入用戶興趣模型中來提高推薦準確率及召回率。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
