移動應用眾包測試人員信譽度復合計算模型研究
2022-09-22 05:59:54譚頂梅
軟件導刊 2022年9期
關鍵詞:模型
譚頂梅,成 靜
(西安工業大學計算機科學與工程學院,陜西西安 710021)
0 引言
隨著互聯網平臺的快速發展,眾包技術被廣泛應用于解決各種工程任務,尤其是軟件測試[1]。眾包一詞是由Howe[2]于2006 年提出,其是一種分布式問題解決模式,即公司或組織通過一個開放網絡平臺,以自由和自愿的方式將以往由全職員工完成的工作任務外包給一群不特定的解決方案提供者[3]。眾包測試是依托新一代互聯網技術衍生出來的新興測試方法,其利用互聯網的即時性和共享性,采用分布、協作的方式組織生產,協同測試需求和測試資源,最終聚合形成規模效益[4]。
隨著新興移動應用數量的激增,移動應用測試中也引入了眾包測試形式。移動應用眾包測試任務的完成需要發包方、眾包平臺與眾包測試人員三者之間良好協作,典型的移動應用眾包測試模型如圖1 所示。與傳統測試相比,眾包測試可以輕松、廉價地獲得大量候選測試人員,他們可以在不同環境、平臺以及知識背景下進行測試,能快速且低成本地發現軟件缺陷[5],提高了測試效率,解決了企業人手與資金不足的問題。
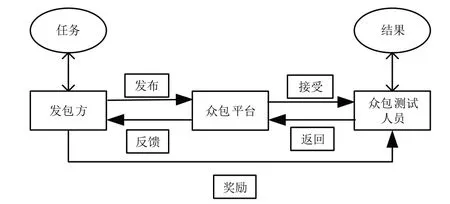
Fig.1 Typical mobile application crowdsourcing testing model圖1 典型移動應用眾包測試模型
雖然移動應用眾包測試有很多候選測試人員,但由于成本限制,不可能讓所有候選人員都執行測試任務。同時在眾包測試背景下,軟件測試成功與否很大程度取決于眾包測試人員的反饋。然而,由于眾包測試的匿名性與非契約性,眾包測試人員會產生懈怠、欺詐等行為,使測試結果質量得不到保證[6],因此如何選取眾包測試人員十分重要。為使發包方更加方便地選擇眾包測試人員,本文以數據化的方式對眾包測試人員信譽度進行研究與展現。
1 相關研究
國內外學者對眾包測試人員的信譽度進行了積極研究并取得了一定成果。例如,芮蘭蘭等[7]采用重復博弈方法計算測試人員信譽值并構建了激勵機制,同時設置了懲罰機制針對惡意工作者作出相應懲罰,有效激勵了理性工作者盡力工作;阮閃閃等[8]提出基于證據理論的信任評估模型實現眾包平臺的質量監控,通過計算眾包測試人員的直接信譽值和間接信譽值綜合評定其信譽值,模型中同時引入獎懲機制,用以激勵接包方參與眾包并提供高質量眾包,同時遏制惡意的接包方;嚴俊等[9]通過控制眾包交互過程中測試人員的積極性和任務完成質量構建眾包測試人員信譽模型,實現了眾包平臺的質量控制;肖江輝[10]提出一種基于可信度的眾包協同測試算法,即通過統計測試人員在測試過程中發現的bug數目和等級計算其客觀可信度,然后通過評估bug的可信程度給出主觀可信度,最后通過集成二者獲得測試人員的全局可信度;Lee 等[11]提出基于質量評估和用戶等級任務分配框架的眾包質量提升策略。然而,目前已有的信譽度計算方法均未考慮到眾包測試人員受到的主客觀因素影響。本文在前人研究的基礎上充分考慮影響眾包測試人員信譽度的主客觀因素,提出移動應用眾包測試人員信譽度復合計算模型,通過眾包測試人員主觀評分計算主觀信譽度,采用層次分析法計算其客觀信譽度,最后評估出眾包測試人員的綜合信譽度。
2 基于主客觀因素的眾包測試人員信譽度計算
2.1 主觀信譽度計算
采用評分算法選取用戶可靠評分并更新目前眾包測試人員的個人評分,在個人評分不斷更新的基礎上計算其主觀信譽度。目前,評分算法已被廣泛應用于各類場合,具有一定的有效性,可以很好地反映被評價方的任務完成度、信譽度以及滿意度,對其有一定的督促作用[12]。常用用戶評分機制包括2 分制、5 分制和10 分制。本文采用10分制對眾包測試人員信譽度進行評分,評分越高表示發包方對眾包測試人員越滿意。
發包方的評分范圍包括眾包平臺上給出的眾包測試人員各方面屬性,維度越多,眾包測試人員的個人信譽度越準確[13-14]。為方便計算,本文選取3 個維度,分別為測試人員可靠性、測試結果質量和測試結果數量。發包方對眾包測試人員的評價用V表示,V1、V2和V3分別表示發包方對眾包測試人員的可靠性、測試結果質量和測試結果數量評分。由于無法保證新發包方給眾包測試人員的評分全部真實可靠,本文通過研究評分的可靠置信區間計算偏離值,去除惡意評分,更新眾包測試人員的歷史評分,使評分更加真實有效。
2.1.1 評分可靠置信區間計算
為保證新發包方給出的評分具有可信度,本文根據新評分與眾包測試人員歷史評分之間的關系提出評分置信區間的概念,計算出新評分與樣本總體評分之間的偏差,偏差在可靠置信區間內即為有效評分[15-16]。當新發包方的評分明顯低于或高于該眾包測試人員歷史評分時,這個新評分便有可能是虛假評分,在更新用戶評分時不予采納。若新發包方的評分在給出的可靠置信區間內,說明該評分可信,則將新評分納入眾包測試人員歷史評分中進行評分更新。具體計算方法如下:
首先,計算第j個眾包測試人員的第k個屬性評分均值,公式為:

然后,計算新發包方對眾包測試人員評分向量相對于該人員歷史評分向量平均值的偏離大小,即新評分的可信度L,采用距離向量表示,距離越小,說明新發包方的評價與該人員的歷史評價越相似,評分信息也越可靠,反之則不可信。具體計算公式為:
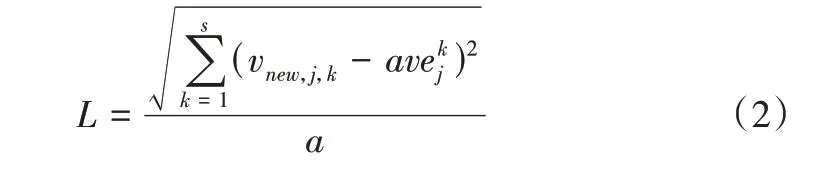
2.1.2 眾包測試人員主觀信譽度計算
對眾包測試人員信譽度的計算實際上是對其評分的不斷更新。在測試任務結束后,發包方對眾包測試人員進行評分,通過計算該評分與該用戶總體評分均值之間的偏離度來判斷新評分是否可用,偏離度越小說明新評分越可信,則將新評分代入該用戶歷史評分,計算出該人員新的綜合評分V,即為其主觀信譽度值。以下給出計算過程部分數據作為實例進行分析。
表1 給出了20 個發包方對眾包測試人員T1 的評價,具體計算方法為:
首先根據式(1)計算T1各維度評分的均值,分別為:

可以得出T1 的評分均值為(8.1,7.9,7.1)。由表1 可以看出,U6 對T1 的評分明顯偏離,即以該評分為例,根據式(2)計算出偏離大小,即為:

L=0.790>0.3,即該評分不可信,不予采納。若新用戶對T1 的評分為(9,9,7),根據式(2)可得L=0.142<0.3,說明新評分可信,則采納新評分并代入計算T1 的新評分,得到:=7.09,T1 的新主觀信譽度V=7.76。
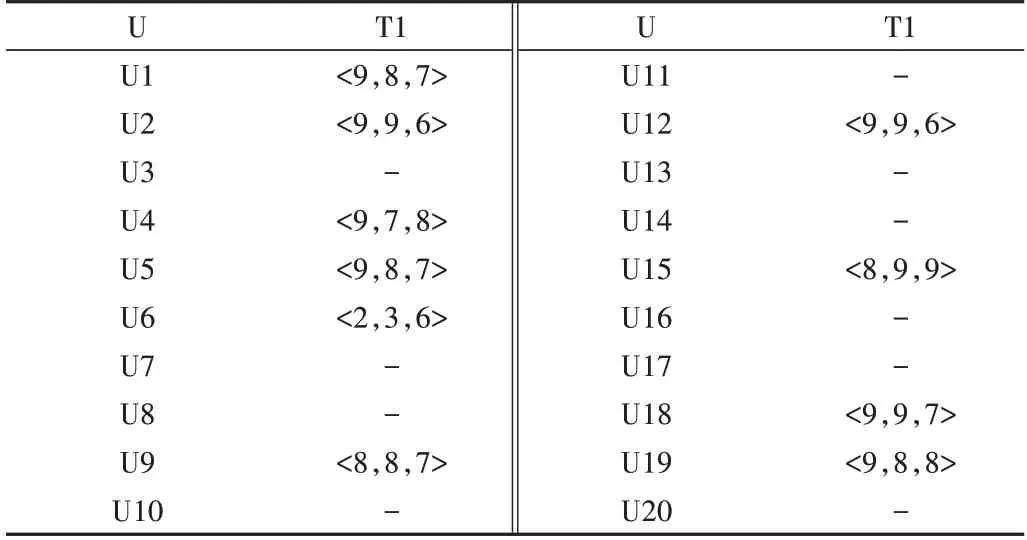
Table 1 Scoring table for crowdsourcing tester T1表1 眾包測試人員T1評分表
2.2 客觀信譽度計算
2.2.1 影響因素
選擇按時交稿任務數量、發現Bug 數量、有效Bug 數量以及測試人員等級4 個影響因素對測試人員客觀信譽度進行研究分析[17],具體如表2所示。
(1)按時交稿任務數量。眾包測試人員的按時反饋對于發包方錯誤的及時更正具有重要意義,基層嚴重Bug 的出現會導致整條生產線重新測試。同時按時交稿任務數量也體現了眾包測試人員的時間觀念,是影響眾包測試人員信譽度的重要因素。
(2)發現Bug 數量。發現Bug 數量多少是測試人員能力和工作積極性的一種體現,發現Bug 數量越多,眾包測試人員的信譽度也會有一定提高。
(3)有效Bug 數量。有效Bug 數量是相對于發現Bug數量來說的,有效Bug 越多,且在Bug 數量中占比越大,說明眾包測試人員測試質量越高,其信譽度也就越高。
(4)測試人員等級。眾包測試人員等級分為初級、中級、高級,等級劃分是對眾包測試人員能力的認定,其等級越高,信譽度也就越高。

Table 2 Influencing factors of tester's credibility表2 眾包測試人員信譽度影響因素
2.2.2 層次分析法
層次分析法是一種解決多目標復雜問題的定性與定量相結合的決策分析方法[18],其在對復雜決策問題的本質、影響因素及內在關系等進行深入研究的基礎上,利用較少的定量信息使決策思維過程數學化,從而為多目標、多準則或無結構特性的復雜問題提供簡便的決策方法[19]。本文采用層次分析法評估眾包測試人員信譽度的客觀評分,將影響眾包測試人員信譽度的客觀因素分為4 個層次,然后借助定性和定量分析得到評價指標的權重向量[20],依據權重計算出眾包測試人員的客觀信譽度。
層次分析法的具體步驟為:①建立層次結構模型。依據上述影響眾包測試人員客觀信譽度的目標因素構建出層次結構圖,將各因素分為不同層級,構建多層級多指標結構;②構造判斷矩陣。依據專家或相關資料對同一層的影響因子兩兩打分,比較確定影響因子的重要性,以此建立判斷矩陣U=(Aij)n×n,其中Aij為因素i相較于因素j的重要程度量化值,判斷矩陣中Aij的值越大,說明因素i相對于因素j 越重要,Aij取值范圍為1~9;③層次單排序及其一致性檢驗。計算上述判斷矩陣中最大特征根λmax的特征向量,經標準化處理后記為W。W 為同一層次因素對于上一層次因素相對重要性的排序權值,這一過程稱為層次單排序[21]。為檢驗判斷矩陣的一致性,需要計算一致性指標CI,公式為:

式中,λmax為矩陣的最大特征值,n 為矩陣階數。當CI=0 時,表示有完全的一致性,當CI接近于0 時,表示有滿意的一致性,CI越大,不一致性越高。
為降低主觀偏差,引入判斷矩陣的平均隨機一致性比率CR,計算公式為:

式中,RI為平均隨機一致性指標,對于低階矩陣可直接通過查表得到。當CR<0.1 時,則表明判斷矩陣U通過一致性檢驗,判別結果為可以接受,否則需要重新構造判別矩陣U,直至通過一致性檢驗。
2.2.3 判斷矩陣構造
如表3 所示,A表示眾包測試人員信譽度;B表示影響A的指標,其中B1為按時交稿任務數量,B2為發現Bug 數量,B3為有效Bug 數量,B4為測試人員等級。本文選取直接相關因素,僅構造了一層相關層次結構,因而計算較為簡單。根據Santy 的1-9 標度方法及相關資料數據[22],得出A 相對于B 的判斷矩陣U,表示為:

2.2.4 信譽度指標權重向量計算
為判斷層次分析法是否符合邏輯,需要對判斷矩陣U進行一致性檢驗。根據一致性檢驗步驟可以得出,U 的最大特征值λmax=4.223 0,將λmax代入式(3)可得CI=0.074 3,RI=0.90,將計算結果代入式(4)可得CR=0.082 6<0.1,說明U 具有滿意一致性,對應的特征向量即為其權重向量。U的最大特征值對應的特征向量W=[0.833 8 0.203 5 0.499 8 0.116 7],該向量經歸一化處理后可得=[0.504 2 0.123 0 0.302 2 0.070 6]。歸一化后的向量稱為權向量,可以看出在計算眾包測試人員信譽度時按時交稿任務數量最重要,其次為有效Bug 數量,再次為Bug 數量,最后為眾包測試人員等級,具體權重如表3所示。
根據權向量的計算結果可以得到眾包測試人員信譽度影響因素指標模型,表示為:

2.2.5 信譽度影響因素權重的應用
測試用戶信譽度N0可表示為:

Table 3 Credit impact indexes and their weight value表3 信譽度影響指標及其權重值

該式是對信譽度各影響因素的歸一化處理,其中N表示測試用戶當前指標值,Nmax為該指標的最大值,Nmin為該指標的最小值。
根據表3 中的權重構建眾包測試人員客觀信譽度計算模型,表示為:

式中,Ci為信譽度計算模型中第i 個影響指標的賦值,本文采用10 分制,則Ci=10 ×N0;Wi為第i 個影響指標的權重。將賦值分別乘以權重并求和,所得分數即為眾包測試人員客觀信譽度值。
2.3 復合信譽度計算模型
綜合分析主觀和客觀影響因素,眾包測試人員復合信譽度Z最終表示為:

式中,V表示眾包測試人員主觀信譽度值,A表示眾包測試人員客觀信譽度值;α、β 分別表示其對應權重,且α+β=1,其值可以根據用戶個人需要設定。
3 實驗方法與結果分析
數據提取自某開放式網絡授課系統的實驗結果[23],將學生在亞馬遜眾包平臺完成的1 000 道測試題得分作為初始信譽度評分,再通過發布新任務更新學生的信譽度。實驗在初始信譽度數據的基礎上進行相應擴展并模擬出眾包測試社區中3 種典型眾包測試人員TS1、TS2、TS3,其中TS1 為優秀型,TS2 為一般型,TS3 為惡意型。為驗證人為惡意評分對眾包測試人員信譽度的影響,實驗模擬了一批發包方對TS1 和TS2 進行惡意差評,對TS3 進行好評,評分為10 分制,模擬眾包測試人員數量為50 人,信譽值計算次數分別為10 次和20 次。在計算客觀信譽值時,參考眾包測試人員信譽度模擬相應數值,要求偏差不能過大。
為驗證本文模型的優越性,分別對基于發包方評分的模型和本文復合模型進行信譽度計算。其中基于發包方評分的模型信譽度計算以網絡授課系統實驗中學生的信譽度為基礎,僅根據新發包方的評分更新迭代眾包測試人員的信譽度。圖2 為僅基于發包方評分計算出的眾包測試人員信譽值,可以看出,惡意評分對眾包測試人員的信譽值影響較大。從圖2(a)可以看出,TS2 一般型人員在惡意差評下迭代10 次的信譽值與TS3 惡意型人員在故意好評下迭代10 次的用戶信譽度值重疊。由圖2(b)可以看出,當迭代20 次時,TS3 惡意型人員的信譽值甚至高過了TS1 優秀型人員,這明顯與實際情況不符。基于發包方評分的模型受惡意評價影響嚴重,評價結果不夠合理。

Fig.2 Credibility values of different types of personnel under the employer's scoring model圖2 不同類型人員在發包方評分模型下的信譽值
圖3 為基于本文復合模型計算出的眾包測試人員信譽值。在同樣的惡意評價下,可靠置信區間的計算排除了大部分惡意評價,只有一小部分與眾包測試人員歷史評分相近的評分被保留代入計算,因此對主觀信譽度值影響不大。由于客觀信譽度不受主觀評分影響,只與眾包測試人員本身的行為有關,使得綜合信譽度幾乎不受惡意評分的影響。由圖3 可以看出,無論是迭代10 次還是20 次,不同類型測試人員的信譽值均可以保持平穩,說明復合模型可根據測試人員實際行為對其信譽度作出有效評估。

Fig.3 Credibility values of different types of personnel under the compound models圖3 不同類型人員在復合模型下的信譽值
4 結語
本文提出一種基于將主客觀因素相結合的移動應用眾包測試人員信譽度復合計算模型,該模型通過發包方對測試人員的主觀評分以及評分可靠置信區間的計算迭代更新測試人員的主觀信譽度值,根據眾包測試人員行為計算其客觀信譽度值,最后將兩者結合,根據各自權重綜合計算出最終信譽度。該模型既排除了主觀因素的惡意評分,并對主觀信譽度進行實時更新,又考慮了眾包測試人員行為因素,使得評價結果合理性得以保證。
目前復合信譽度模型還存在一定缺陷。首先,評分可靠置信區間的計算會阻擋真實的跳崖式下降或上升的評分,影響眾包測試人員主觀信譽度的真實性;其次,目前考察的客觀信譽度影響因素不夠完善。下一步將結合發包方評分參考價值度增強眾包測試人員主觀信譽度的真實性,并進一步完善影響因素模型,對眾包測試人員信譽度進行擴展性研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
