基于FPGA的量化推理CNN加速系統研究與設計
2022-09-29 08:12:24何家俊蘇成悅羅榮芳施振華陳堆鈺羅俊豐
計算機測量與控制 2022年9期
關鍵詞:深度
何家俊,蘇成悅,羅榮芳,施振華,陳堆鈺,羅俊豐
(廣東工業大學 物理與光電工程學院,廣州 510006)
0 引言
卷積神經網絡(CNN)在圖像處理分類、目標檢測等卷積神經網絡應用上有了較大的突破[1]。隨著多種深層次卷積神經網絡的提出[2],卷積神經網絡的網絡結構深度和網絡層中參數量以及計算量也隨之不斷提高。將CNN在有限資源的嵌入式設備中計算資源高效得部署成為非常有意義的研究。
許多研究人員在優化神經網絡中計算性能[3],提高外部內存訪問效率方面提出了很多CNN硬件加速的方案,在實現方面只是考慮到小型網絡的加速實現,對于大型網絡的實現都缺乏有效的方案[4-6]。且多數網絡加速只針對于卷積運算優化,少數網絡在加速網絡時針對網絡全連接的優化[7],全連接的優化對于網絡的參數影響[8]也占據著主要的位置。在推理方面提出了很多量化方案[9],采用的量化方案多數為定點數量化,在數據跨度比較大的情況下,采集的數據量不足導致損失率增加,降低算法識別率[10]。常用的動態量化推理INT8是通過人工設置值域范圍,不能有效地確定推理量化范圍[11]。取值范圍過大,會過度采集量化數據,不能有效地抵抗異常參數數據導致量化結果與原函數偏差過大。取值范圍過小,會導致數據采集不完整,也不能有效地量化擬合原始數據。
提出了一種結合DBSCAN密度聚類算法[12]的INT8動態量化推理算法,根據網絡結構特性實現網絡結構優化,設計一個基于多個CNN計算核心的硬件架構,優化加速器的內存訪問速率、資源使用以及卷積神經網絡計算效果,并以LetNet-5,VGG-16以及Resnet-50算法為例部署至FPGA平臺進行驗證。
1 算法分析
1.1 CNN網絡
CNN是由許多運算模塊層組成,有卷積運算的功能模塊層,激活數值功能模塊層,最大值池化數值功能模塊層和數據全連接運算功能模塊層。CNN會由輸入圖像數據到第一層功能模塊層開始,通過運算獲得新的多通道圖像特征數據并依次進行下一層功能模塊層的操作,每層的卷積層可以用下式表達:

(1)
其中:j表示輸入特征值,i表示輸出特征值,nin和nout分別表示輸入和輸出的數量,gi,j應用于第j輸入特征值和第i輸出特征值的卷積核。激活層是選取特征值中大于零的數值,每層的激活計算層可以用下式表達:
(2)
最大值池化層是選取一個區域內最大的值作為輸出特征值可以表示為:

(3)
其中:p是池化層內核的大小。這種非線性向下采樣不僅減少了特征數的數量大小和后續計算功能模塊的計算量,而且還可以提供一種形式的平移不變性,在不改變數據特性的情況下減少數據量。全連接層可以表示為:
fout=Wfin+b
(4)
其中:W是輸入輸出變化矩陣,b是偏移參數。在卷積運算后通常會使用激活運算層模塊和池化運算模塊層去除多余參數降低參數量。經過一次或多次的卷積激活、池化操作,數據以及降低并提取到一定的程度,接下來會使用全連接模塊功能層使得數據相互通過權重參數和偏移參數算得結果并將其求和。
上述算法可以看出,卷積神經網絡需要大量的乘法和加法運算。通過電路的形式并考慮FPGA可并行可串行的特性設計出算法需要做出相對應的分析,其中卷積運算需要考慮卷積核心的移動方法,以及不同深度神經網絡算法中有不同的卷積層數、不同的卷積核數、輸入通道數和輸出通道數。需要設計出合理的數據緩存區提前將數據保存起來再進行卷積操作。在池化層和激活層不需要用到乘法器和加法器,但是用到比較器,且比較的范圍不只是在同一行。
文中選用的3個網絡分別LetNet-5網絡兩個卷積網絡以及兩個全連接網絡的,略深層網絡的13層卷積網絡和3層全連接網絡的VGG-16,以及包含49層全連接網絡和1層全連接網絡的Resnet-50。
1.2 網絡參數與MACC計算量
由圖1可以看出LeNet-5無論是參數量還是計算量都是最少的,而其余兩個網絡,VGG-16和Resnet-50的MACC卷積計算量以及全連接計算量和網絡的卷積參數和全連接參數量都不小。圖1和圖2分別對網絡中主要算子的參數分布和網絡中主要的計算量分布進行了統計。
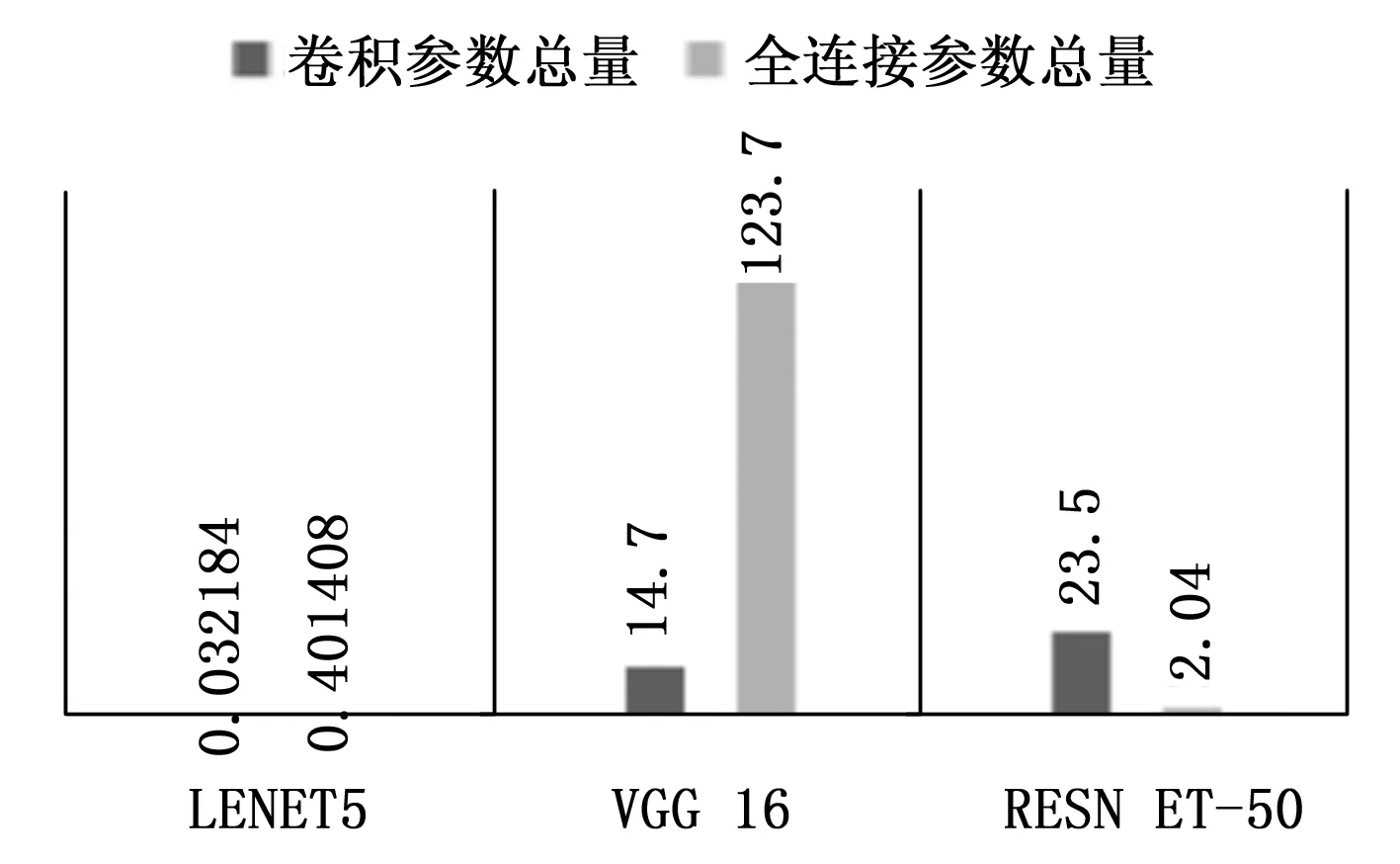
圖1 各網絡的參數總量(M)

圖2 各網絡參數的MACC計算總量(GFLOPs)
從圖1可以看出VGG-16卷積算子權重參數少于Resnet-50的權重參數 ,而在全連接計算算子參數的總量中,VGG-16的算子參數遠遠多于Resnet-50的全部算子參數的總和,而且LeNet-5和VGG-16網絡中全連接參數總量分別是卷積參數總量的12.5倍和8倍。
從圖2可以看出每個神經網絡的計算量都集中在卷積算子層,LeNet-5、VGG-16、Resnet-50中卷積計算分別為全連接計算的4.77倍,1.25倍和1 935倍,所有在卷積層中計算優化對整個CNN加速系統的影響占比更大。要做到優化好CNN加速系統模塊,需要結合優化VGG-16這種需要優化大量全連接計算和ResNet-50這種需要大量卷積計算的特性,將全連接層可以看作是一個特殊的點乘運算,根據不同神經網絡的特性設計一個專用的神經網絡加速器尤為重要。
1.3 網絡訓練推理流程分析
目前大部分CNN的研究部署和訓練都選擇了GPU平臺,平臺對FP32浮點型數據計算提供了很好的并行運算開發生態有利于做大數據的圖像識別訓練,但是GPU其高功耗的特性導致其不能成為便攜式移動設備的最優選擇平臺。FPGA同時擁有并行運算能力以及低功耗特性,并且具有靈活的結構為移動設備部署CNN提供了有效的解決方案[13]。CNN前推過程如圖3表示。

圖3 卷積神經網絡前推過程
卷積神經網絡需要大量的乘法和加法運算。通過電路的形式并融合FPGA擁有并行和串行的特性設計出算法需要做出相對應的分析,卷積運算需要考慮卷積核心的移動方法,以及考慮到不同的深度神經網絡算法不同的卷積層數中有不同的卷積核數、輸入通道數和輸出通道數。需要設計出合理的數據緩存區需要提前將數據保存起來再進行卷積操作。池化層和激活層由比較器組成為主,且比較的范圍不只是在同一行,如2×2的池化核需要第一行的圖像數據與第二行的圖像數據作對比,在電路設計上需要設計好緩沖區,保存第一行數據并且通過第二行數據輸入后作對比。全連接層則只需要在其他計算完成后得到的數據輸出的時候乘上權重和加上偏移值。訓練過程如圖4表示。
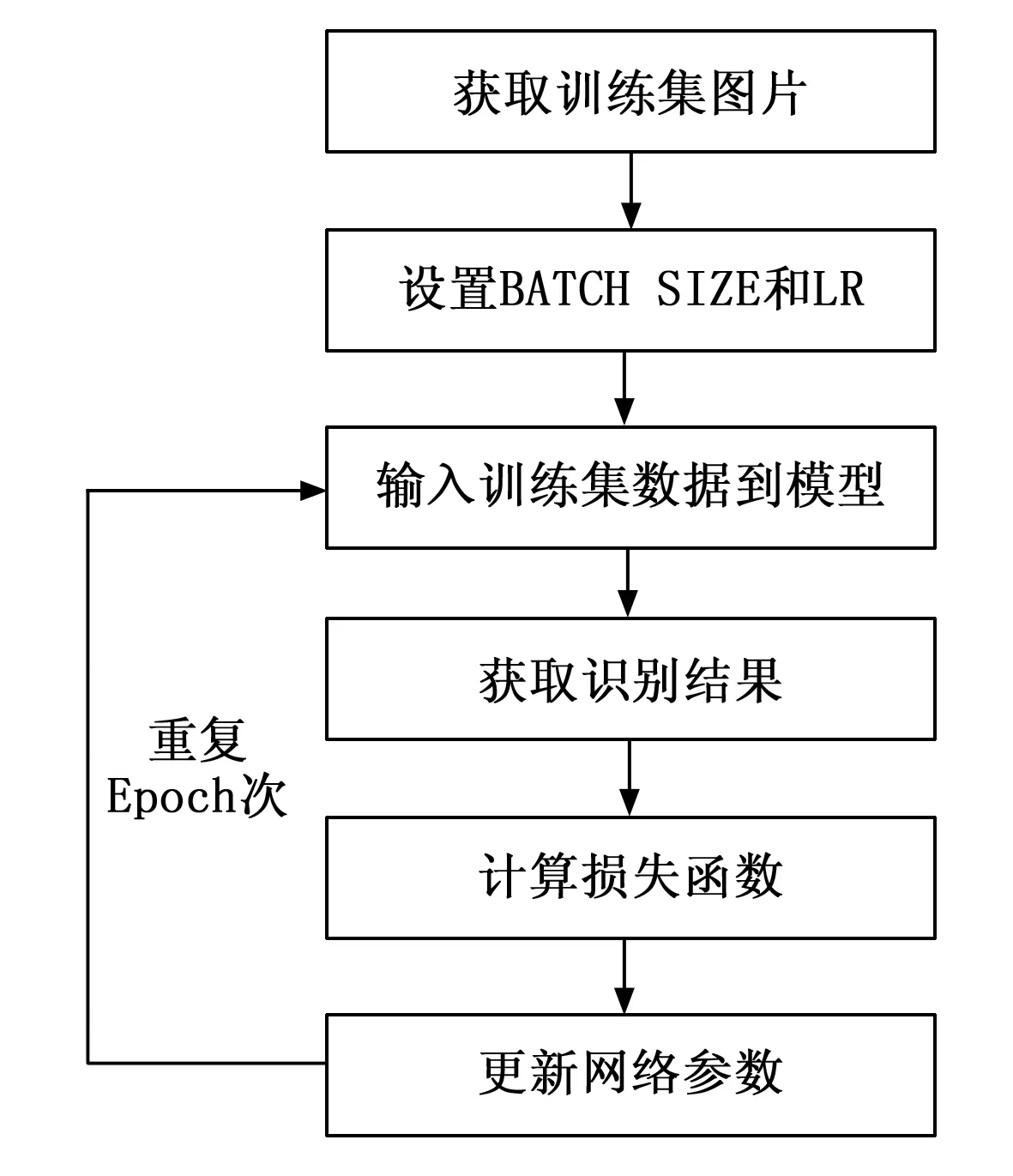
圖4 深度網絡訓練流程圖
深度神經網絡訓練需要構建訓練網絡,預設訓練次數(EPOCH),打亂數據集,劃分訓練集和驗證集。接下來設置每次訓練所抓取的數據樣本數量(BATCH SIZE)和學習率(LR),這兩個參數影響深度學習的速度和識別率。獲取訓練集中圖像數據,并使用歸一化處理。將數據傳入到構建好的訓練網絡,獲得識別結果。將結果通過與標識好的結果做一個損失函數計算,再更新網絡中的參數。重復第三步當經過EPOCH次訓練后得到訓練參數和識別率。
基于深度卷積神經網絡的訓練數據量龐大而且只需要訓練一次的原因,使用可以高速且具有豐富深度學習開發方案的GPU平臺成為首選。訓練不需要考慮功耗問題,通過GPU訓練出來的模型參數做處理后,部署到基于FPGA平臺的CNN加速器當中。
1.4 網絡優化分析
CNN加速研究中,常用的方法是通過壓縮神經網絡模型的方法達到縮小模型中數據體積大小和降低硬件的資源使用的效果,使得算法運算速率增加以及運行算法設備的功耗減少[14]。
通過將數據運算位數刪減降低數據精度,有效地提高運算速度和降低功耗。使用在大規模的圖像分類中,最為先進的CNN模型具有較深的網絡層數和大量的神經網絡權重參數和偏移參數。大量參數只能存儲在外部存儲器當中,運行算法時需要從外部參數讀取并使用計算,加速性能需要和存儲器讀寫的速度做匹配,在加速性能遠大于儲存器讀寫速率的情況下,存儲器的讀寫帶寬也就是儲存器每次讀寫數據量的大小以及讀寫速率成為了CNN加速的性能瓶頸[15]。
2 量化與優化
2.1 網絡量化
在FP32類型的數據下深度神經網絡的參數都會集中在一個值域區間[16],使得FP32大部分的數據段都是處于空閑狀態,這時可以通過有效截取數據段來使得參數數據壓縮,那么就可以得到一個量化的參數模型,如圖5是LeNet-5訓練后的參數分布數據圖。
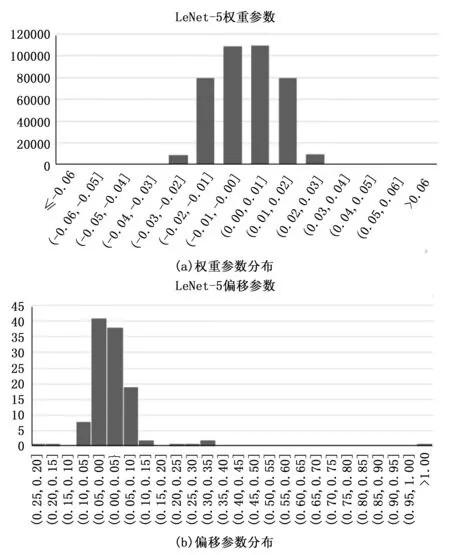
圖5 LeNet-5參數數據分布
從圖5(a)和圖5(b)可以得到神經網絡的權重參數主要分布和偏移量參數主要分布在一定范圍,我們可以合理地設置區間為這個綜合范圍的最大值和最小值映射到INT8類型數據的最大值和最小值,其中相差間隔很小的數據會合并映射到一個數值。
在FP32轉向INT8的過程中需要去除小數點后的數,需要在映射到8位數據后進行舍入的操作。當存在少量遠大于或小于大量數值參數的異常參數,則異常參數會影響整個量化過程,大量的正常參數才是在圖像識別運算中起著重要的權重作用,合并到同一數值當中,減少了兩個區域甚至多個區域中數據的可比性。合理選擇量化的值域顯得尤其重要。
2.1.1 量化FP32至INT8實現的計算公式
從輸入圖像數據轉換成量化圖像數據公式如下:
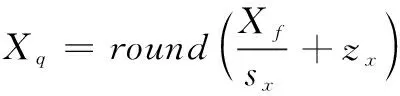
(5)
其中:Xf為輸入圖片特征數,Xq為Xf量化后的圖片特征數,Sx為圖片特征數量化放縮因子,Zx為圖片特征數量化偏移值。量化放縮因子是通過輸入數據的值域范圍和需要量化的范圍做一個比例計算,公式如下:
(6)
式(5)Zx是通過放縮因子,量化結果以及原數據做一個偏移計算獲取,公式如下:
(7)
同理權重的參數量化如同輸入圖像特征數的量化,給出的3個公式如下所示:
(8)
(9)
(10)
其中:Wf為輸入權重參數,Wq為Wf量化后的權重參數,Sw為權重參數量化放縮因子,Zw為權重參數量量化偏移值。量化計算使用在深度網絡訓練后得到參數進行量化推理調整。
2.1.2 量化中舍入公式:
量化中的舍入公式使用了隨機離散舍入函數方法[17],我們可以定義為:
(11)
在CNN量化中,使用四舍五入的round方法會產生一定的誤差,在大量的卷積運算會使得這種誤差放大,導致圖像識別的準確率降低。隨機離散舍入函數方法中,采用隨機因子,使得函數期望為x。有助于在量化過程中舍入后減少誤差,減少算法損失率。
2.1.3 DBSCAN聚類算法
DBSCAN是基于密度的分類算法。算法通過設置中心點直徑范圍,和中心直徑范圍內數據量遍歷出數據中心點的位置。將與中心相連的點位數據收集到同一數據集中,生成多個數據集。通過刪除含有數據少的中心數據團,獲取存在大量數據的中心數據團,從而確定量化參數大致分布區域,截取數據的值域區間,提高量化后與量化前的相似度。如圖6是LeNet-5的兩個卷積層量化前后對比圖。
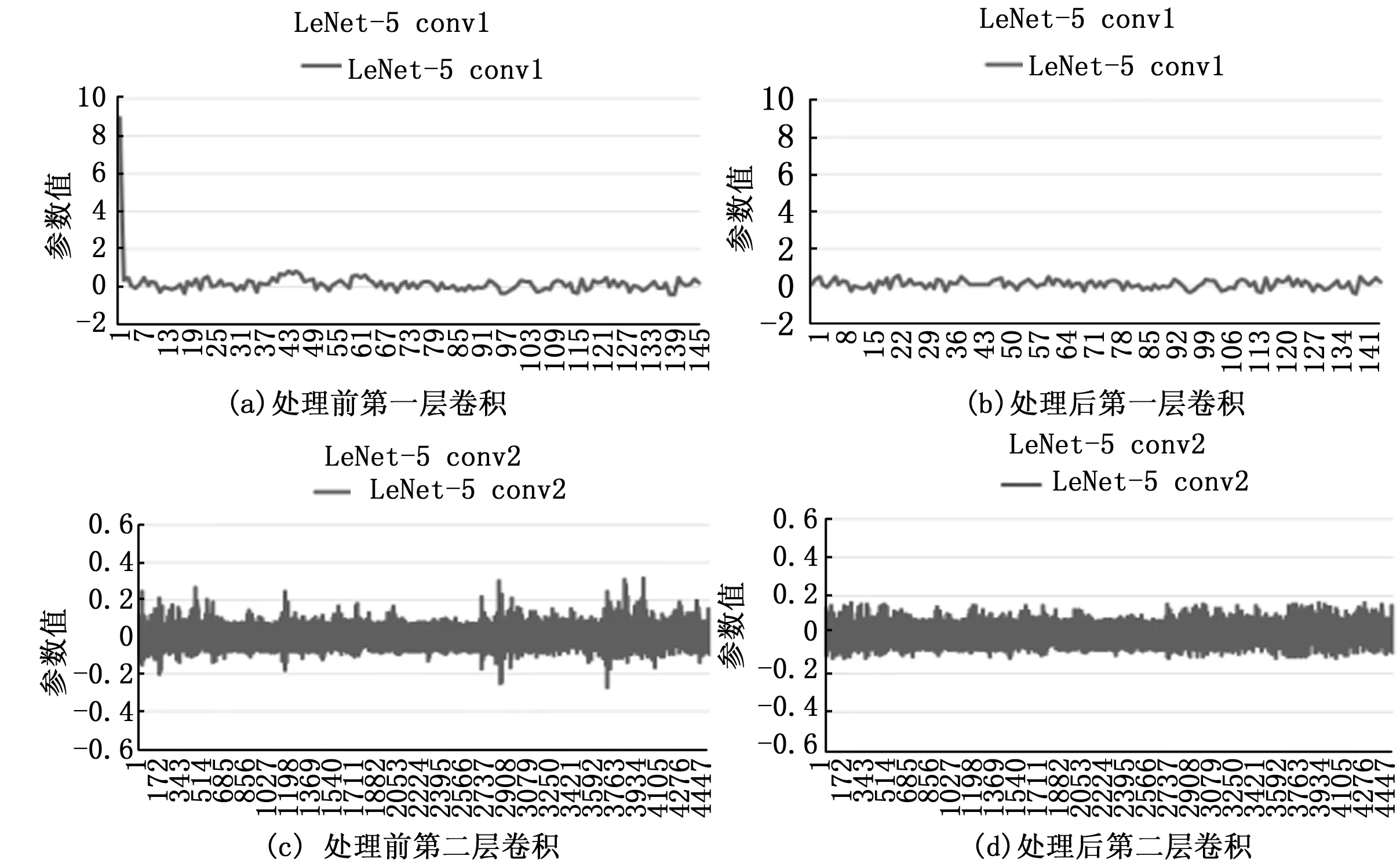
圖6 卷積參數DBSCAN聚類算法處理數據圖
從圖6(a)以及圖6(c)可以看出在訓練后的卷積參數會出現異常數據。異常數據會導致在設置INT8推理的閾值過大,大部分的參數分布在0.1與0.2之間,如圖4(a)出現了最大值9,若設置9為量化最大值則會出現0.2到9之間存在大部分不占據參數的空間稀釋原本參數分布區域的精度參數從而導致量化后結果與原函數的相似度降低。
從圖6(b)以及圖6(d)可以看出經過DBSCAN聚類算法處理后相對于處理前的數據減少了很多異常數據,顯示聚集密度大得數據集,可以直接截取數據集的最大值和最小值通過公式(6)計算出量化放縮因子,極大地去除異常數據,可以通過算法處理使得數據參數有效得并量化貼合,可以明顯有效得去除了數據毛刺,有助于數據量化。
2.2 全連接優化計算公式
LeNet-5和VGG-16等深度神經網絡中會存在多個全連接,全連接可以看作是兩個矩陣的相乘,將第一層全連接的權重參數等價于W,第一層偏移量等價于B得到公式如下:
(12)
第一層全連接層的結果等價于H可以得到:
H=[h1h2…hm]T=W*X+B
(13)
其中:n為全連接輸入數,m為輸出通道數,h為全連接結果,x為輸入特征值,w為權重參數,b為偏移參數。同理可將第二層全連接的權重參數等價于U,第二層全連接的偏移參數等價于D:
(14)
得到第二層全連接最后結果FC,公式如下:
FC=[fc1fc2…fck]T=U*H+D
(15)
其中:k為輸出通道數,fc為全連接結果。若用式(13)的全連接帶入到式(15)中的H中,可以將(13)、(15)兩式融合成一式:
FC=U*(W*X+B)+D
(16)
將(16)中括號拆開,使第二層全連接權重參數與第一層全連接權重參數結合成為總的全連接權重參數,使第二層全連接參數結合第一層全連接偏移參數再加上第二層全連接偏移參數得到總的全連接的偏移參數,新成立的全連接權重矩陣和偏移矩陣分別是:
Wn=U*W
(17)
Bn=U*B+D
(18)
融合后全連接可以簡單描述為:
F=Wn*X+Bn
(19)
選用LeNet-5和VGG-16全連接融合效果對比如表1所示。

表1 全連接層融合對比效果
可以看出LeNet-5 和 VGG-16在全連接融合后MACC計算總量的壓縮率分別為52.9%和3.3%,全連接參數總量的壓縮率分別為52.6%和3.3%。
擁有少量全連接參數和計算量的LeNet-5網絡擁有很好的壓縮效果。針對VGG-16全連接計算量占據大量參數和計算的特性,VGG-16在向前推算的參數量和計算量在全連接層融合壓縮起到了明顯的效果。
3 CNN推理加速器模塊設計
使用GPU平臺進行Fashion MNIST(FM)和CIFAR-10(CR)的數據集的訓練并獲取各網絡模型參數,將參數進行量化數據分析和融合全連接參數等操作得到最后使用到FPGA平臺上CNN加速系統中。
基于以上量化理論,CNN加速系統需要考慮CNN網絡在卷積運算的運算速率。CNN卷積網絡數據在并行運算中表現較好,在設計加速電路中需要運用并行的電路設計。
通過對網絡的分析,系統同時需要多個模塊組合并按順序執行計算。運用多個計算核心的方法組合加速系統,通過控制系統控制執行順序可以靈活地調用硬件資源完成CNN深度加速。FPGA設計的CNN推理加速器模塊設計如圖7所示。
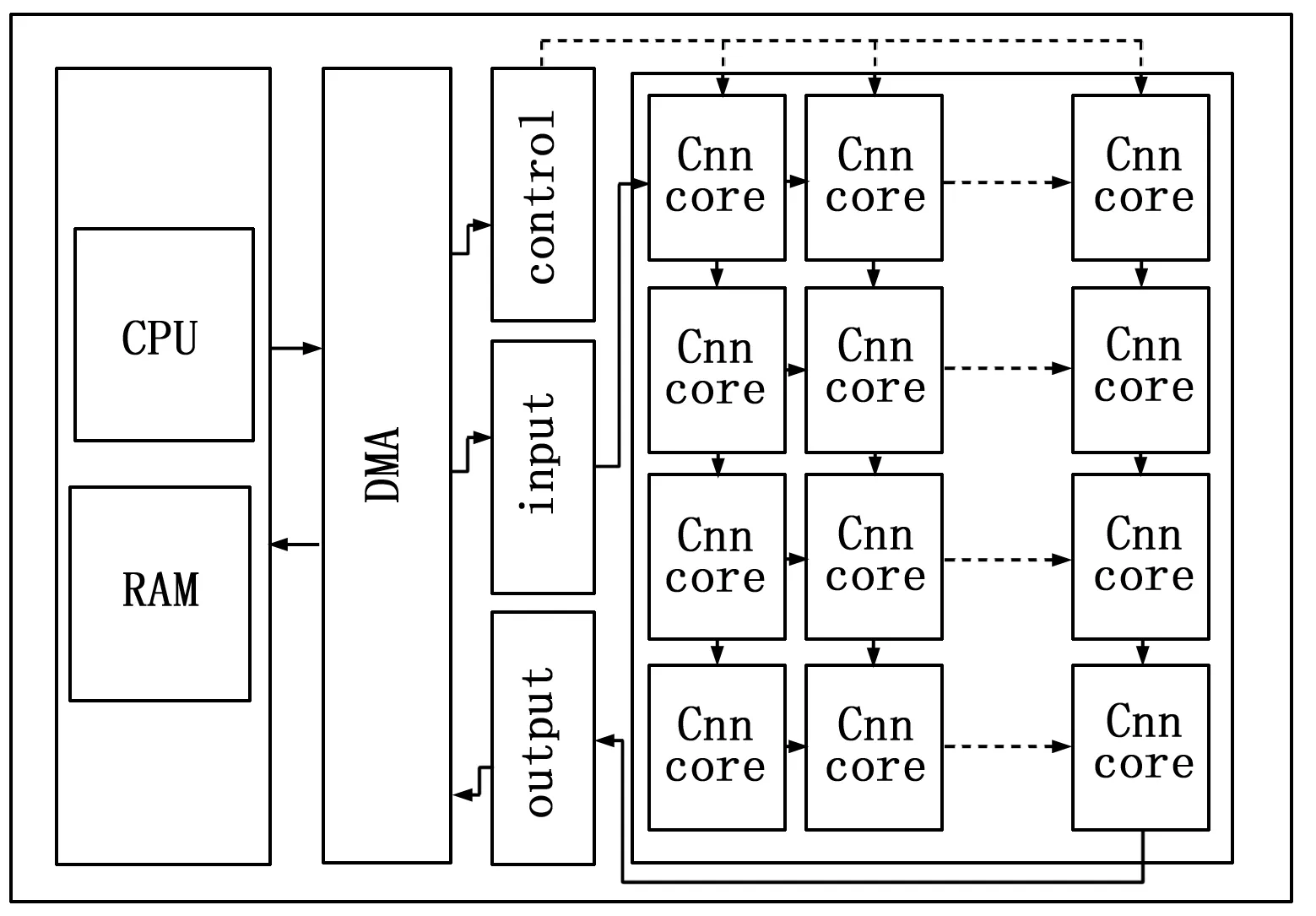
圖7 深度神經網絡推理加速器
加速器主要包含了片上系統控制中心模塊、內存緩存模塊、深度神經網絡計算單元核心模塊、單元核心控制仲裁模塊和輸入輸出模塊。使用C++代碼實現深度神經網絡的結構,通過系統控制中心模塊調度內存緩存模塊,將權重數據和偏移數據與圖像數據以及神經網絡單元核心的參數通過DMA傳輸進入深度神經網絡計算模塊中進行前推計算,最后輸出數據返回到系統控制中心,完成整個深度神經網絡加速過程。
3.1 內存緩存與數據傳輸
片上內存主要保存了當前神經網絡的權重數據和偏移數據,數據傳入神經網絡模塊傳輸設計如圖8所示。

圖8 神經網絡模塊傳輸圖
考慮到卷積操作多數是以3×3的卷積核結構對特征圖進行滑動操作,固神經網絡模塊數據首先讀取數據的前三行,新的數據行替換舊的數據行。第一次卷積需要等待三次數據的讀取,后續數據可以直接替換舊數據進行卷積,當此次卷積實現了輸入特征數據面積數且沒有新的數據輸入時完成卷積并輸出空閑狀態。
上述電路實現卷積的運算讀取內存中數據[18],每次時鐘只需要讀取一個數據量即可,并使用了流水線設計實現了加法樹和乘法的功能優化了內存讀寫效率和在很短的等待時間內執行多條運行命令,提高了卷積計算的速度。
3.2 深度神經網絡計算單元核心模塊
計算單元核心模塊是加速器的主要模塊,其中有量化模塊(Quantization)、控制模塊(CORE CONTORL)、深度神經網絡算子等計算模塊,其結構如圖9所示。
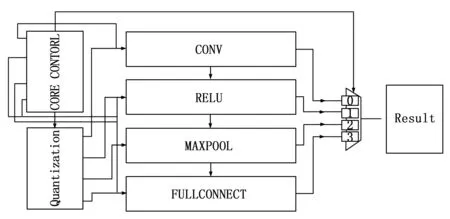
圖9 神經網絡計算單元核心模塊
量化模塊(Quantization)中隨機數使用的是LFSR隨機數產生電路生成隨機因子作用于離散舍入計算得到量化放縮因子。模塊輸入數據后經過量化處理,將FP32數據乘以量化放縮因子并加上量化偏移值,得到最后的INT8數據,在卷積和全連接的計算中使用INT8計算,不需要使用浮點型的運算電路,減少加速系統對DSP使用的同時減少運算數據的位數達到電路系統在運行時降低功耗降低計算量。
控制模塊(CORE CONTORL)通過代碼控制圖像數據輸入到指定算子開始執行運算,并通過指定算子運行結束后輸出結果,比如只需要數據從卷積計算到全連接,則控制使能卷積并輸入數據,控制選擇器將全連接的數據和計算完成標志輸出結果(Result)。深度神經網絡算子模塊中的算子由卷積到全連接串聯而成的計算模塊,順序是由卷積到全連接的計算順序,因為每個模塊之間都是通過先入先出隊列模塊FIFO(First Input First Output)做中間層銜接,每個模塊之間的輸入數據和輸出數據都是規定為一個有利于每個模塊間交叉銜接。
深度神經網絡算子模塊中的算子由卷積到全連接串聯而成的計算模塊,順序是由卷積到全連接的計算順序,因為每個模塊之間都是通過先入先出隊列模塊FIFO(First Input First Output)做中間層銜接,每個模塊之間的輸入數據和輸出數據都是規定為一個有利于每個模塊間交叉銜接。卷積計算模塊如圖10表示。

圖10 卷積模塊設計
卷積計算模塊的設計是由加法樹和9個乘法器組成,由數據輸入完成后將輸入數據用乘法器相乘得到第一層數據,再通過加法器將數據相加得到第二層數據,進而再進行三次相加和兩次數據平移,最后結果由最后兩個數據相加得到。
激活層是當卷積數據輸出時通過比較器與8位數據127值作對比,若比127大則可以認為在算法中大于0輸出原值,若小于127則在算法中認為小于0輸出數據0。
全連接層則是通過一個乘法器和一個加法器,實現單個數據通過FIFO輸入后進行全連接的運算后通過FIFO輸出。
3.3 單元核心控制仲裁多核加速
控制模塊里面包含了多個單元核心仲裁器,每個仲裁核心會將處理數據優先級通過優先分配算法分配給空閑的神經網絡運算單元核心進行卷積神經網絡的運算,結構如圖11所示。
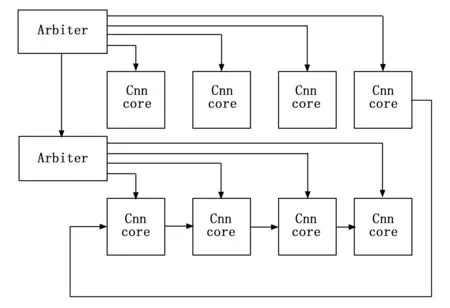
圖11 仲裁模塊結構
當數據傳入時,控制模塊會查看當前空閑的神經網絡單元核心算子,若當前仲裁卷積神經網絡算子都處于繁忙階段,則會將消息傳輸到下一個仲裁中,仲裁都處于繁忙階段的情況下,則當前計算直接跳過,當一個神經網絡算子完成當此計算,會將數據發到下一個神經網絡算子,且讓仲裁控制器控制當前數據是否要繼續計算或再傳送到下一個節點。通過將數據同時發送到多個子仲裁模塊,實現數據并行運算。卷積運算中需要運算多個輸出通道,可以按FPGA平臺性能合理執行單次最大并行運算核心或通過自定義計時器和有限狀態機FSM(Finite State Machine)控制數據的再傳輸和再計算實現單個計算核心組的多次使用。
4 實驗結果與分析
利用GPU平臺以及Pytorch軟件框架可以有效地對深度卷積神經網絡模型進行大規模的數據集訓練,其中數據集使用了Fashion MNIST(FM)和CIFAR-10(CR)為數據集 。
因為要計算在量化深度網絡結構在網絡計算量和網絡參數的壓縮率與識別效果,需要在平臺上記錄不同網絡、不同數據集、不同前推運算的條件下記錄相關參數。通過計算量化前LeNet-5、VGG-16和ResNet-50的網絡大小與量化后網絡的面積計算壓縮率,壓縮效果和量化網絡對數據集的識別效果見表2和表3。
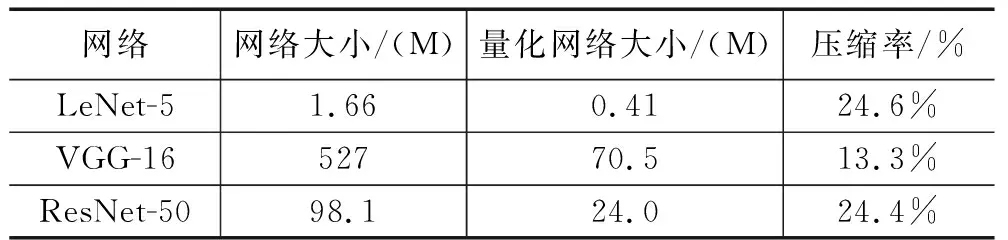
表2 量化面積

表3 量化精度
可以看到LeNet-5的網絡大小在量化前是1.66 M,量化網絡后大小變成了0.41,壓縮率為24.6%,因為LetNet-5網絡有兩層卷積層數和兩層全連接層,通過量化計算參數數據,壓縮卷積層中占大量計算的數據位數,由原來的FP32變成INT8在數據上減少了75%的位數據,在卷積層方面的壓縮效果明顯。通過融合全連接層,LetNet-5本來由原來的兩層全連接網絡,融合成一層全連接網絡,在計算全連接上不僅在量化中減少了大量的數據,在全連接上減少了實際運算次數,達到明顯的壓縮效果。
從表中得知VGG-16網絡的壓縮效果是最明顯的。由于VGG-16的全連接層的數據量大部分占據在全連接層,全連接層的層數是3個網絡中層數最多的,在全精度的情況下VGG-16的網絡大小是527 M而其中全連接的占比可以達到89%即469.3 M,全連接融合有效的將中間的全連接層數運算過程融合在了一起,將全連接的大小壓縮到了15.55 M。因為全連接層的數量對準確率有一定的影響,但是全連接層的融合是經過訓練后合并而成的,不會影響訓練后用于前推的神經網絡算法。
表中ResNet-50的壓縮效果與LeNet-5的壓縮效果相似。在ResNet-50中不只是在計算上,在層數上都是以卷積計算占據主要部分,并且全連接層只有一層,融合全連接的方法在ResNet-50中不起作用。ResNet-50中占據主要壓縮優化效果的是由量化參數起作用,可以將原來98.1 M的網絡大小壓縮到24 M,優化方案適應于ResNet-50。
從表3可以看到量化后的網絡在在識別準確率上都維持在1%以下的損失率。表明了在通過有效去除異常數據量化擬合和融合全連接層的方法可以有效地降低深度神經網絡的網絡大小而不會有過大的損失率,量化推理方案是有助于降低深度神經網絡的復雜性并有助于降低電路設計相關深度神經網絡算法電路的復雜性。
通過訓練后的網絡模型,在GPU平臺下運行FP32全精度的識別Fashion MNIST(FM)和CIFAR-10(CR)的驗證集測試并記錄準確率。獲取GPU平臺下,網絡訓練模型中的參數,使用C++語言搭建前推深度計算網絡模型,輸入驗證集。將編譯好的bitstream文件導入到FPGA開發板中,可以得到加速器利用資源情況見表4。
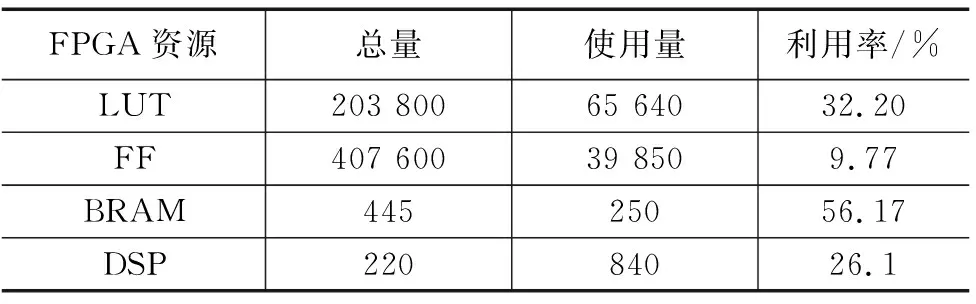
表4 加速器資源利用
本設計因為使用了多個深度神經網絡計算單元核心模塊,在一定程度上使用更多通道的并行運算上在,并且在經過推理量化后的計算不需要使用大量的DSP功能進行計算,本設計的CNN加速系統在計算性能上相比于其他同為8位計算的FPGA實現由較大的提升,其中峰值154.95 GOPS,性能提高了2倍,詳細對比見表5。

表5 加速器對比效果
5 結束語
為了提高硬件移動設備上實現卷積深度神經網絡(CNN)的運行性能和降低算法運算給設備帶來的功耗問題,通過對CNN的網絡結構以及計算流程特性,設計出使用DBSCAN聚類算法實現量化值域截取有效得截取INT8推理算法的閾值,改變閾值選取方法以及全連接融合減少具有大量全連接層的深度網絡數據量,并針對FPGA硬件和深度神經網絡運算特性,設計出多個深度神經網絡計算單元核心模塊加速器。在Fashion MNIST(FM)和CIFAR-10(CR)的驗證集上進行了性能測試。實驗結果表示,在量化后的神經網絡中,損失率在1%以內,LeNet-5、VGG-16和ResNet-50壓縮分別為原來的24.6%,13.3%和24.4%,設計的加速器最高性能可以達到154.95GOPS,提高了2倍。
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
