鋼卷自動拆捆機器人捆帶定位系統研發與應用
2022-10-03 05:17:36王榮浩張文博盛博文王景云
制造業自動化 2022年9期
王榮浩,徐 斌,張文博,盛博文,王景云
(1.機科發展科技股份有限公司,北京 100044;2.中國國際工程咨詢有限公司,北京 100048)
0 引言
隨著我國冶金行業轉型升級進入關鍵時期,國內各大鋼廠均對產線的智能化改造提出了迫切的需求。鋼卷拆捆是硅鋼生產工藝中的重要環節。截至目前大多數鋼廠的鋼卷拆捆仍采取人工作業的形式進行,為了解決人工拆捆作業中存在的工作環境惡劣、拆捆斷帶傷人和斷帶落入運輸小車軌道威脅設備運行安全等一系列問題,同時提高拆捆作業的效率,部分龍頭鋼廠先后開始引入工業機器人系統進行自動拆捆作業[1~3]。機器人自動拆捆作業完全依賴于捆帶定位結果的引導,因此是否可以準確地定位捆帶的位置,直接決定了機器人能否實現自動拆捆功能。

圖1 鋼卷表面捆帶
目前已在鋼廠中投入使用的非接觸式捆帶檢測自動拆捆機器人大多采用以下兩種方式進行捆帶識別定位:一種是點激光掃描測距[4],另一種是機器視覺算法圖像處理[5~7]。點激光掃描測距法在機器人第六軸末端安裝點激光傳感器,工作時首先對鋼卷位置進行定位[8],使點激光垂直照射在鋼卷外表面,機器人帶動點激光從鋼卷的一個端面沿軸向掃描至另一端面,當點激光測距數值發生突變并持續一段距離時,認為發生突變的位置為捆帶所在的位置。這種方法原理簡單,易于實現,在不銹鋼冷軋、精整機組等鋼卷表面形貌較好的產線上使用捆帶檢出率可達90%以上,但這種檢測方法的缺點同樣明顯,在帶有氧化鎂涂層的硅鋼FCL機組等鋼卷表面平整度較差的工況下捆帶檢出率只有不足50%,且周圍電磁干擾嚴重時激光測距結果會出現無序跳動,嚴重影響檢測結果的獲取,顯然無法滿足生產需求。
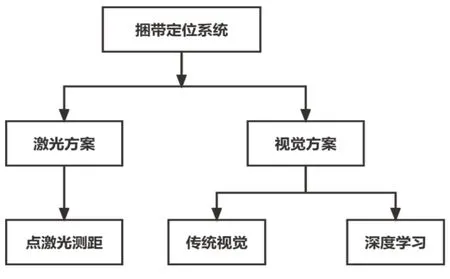
圖2 捆帶自動識別定位系統方案
針對以上現狀,重點分析復雜環境和背景條件下的捆帶識別定位的視覺解決方案,本文對比有限規則的傳統視覺捆帶識別算法及其運行結果,研發了一套基于深度學習目標檢測算法的捆帶視覺定位系統。深度學習強大的自主學習能力使其能夠適應更加復雜多變的目標檢測應用場景[9]。硅鋼FCL入口開卷機組自動拆捆機器人試運行結果表明基于深度學習目標檢測算法開發的捆帶識別定位系統能夠滿足冶金行業復雜環境條件下的捆帶定位需求,部署了該系統的自動拆捆機器人能夠節約人工成本,保障作業安全,提高生產效率。
1 捆帶視覺識別定位系統簡介
1.1 系統設備組成
捆帶視覺定位系統主要由六軸工業機器人、CCD相機、光源、光源控制器和工控機組成。工業機器人布置在安全圍欄內,相機固定安裝在機器人第六軸末端,拍攝圖像時始終保持相機光軸所在直線與鋼卷軸心所在直線垂直且相交。視覺光源安裝在相機下方,光源中心軸與相機主光軸重合。工控機和光源控制器安裝在圍欄外的操作柜中。
傳統視覺捆帶識別定位系統和深度學習捆帶識別定位系統均由上述硬件組成,兩者的差異僅體現在算法層面。

圖3 機器人末端視覺組件
1.2 系統軟件
基于Visual Studio平臺下的C#語言、halcon機器視覺算法庫和百度飛槳PaddleX平臺的深度學習目標檢測開發包,編寫了捆帶識別定位上位機軟件,使用WinForm設計了人機交互界面。軟件能夠控制CCD相機進行圖像采集,通過圖像處理獲得捆帶定位信息,并且能夠對檢測結果進行展示和保存,提高了生產過程的可追溯性。
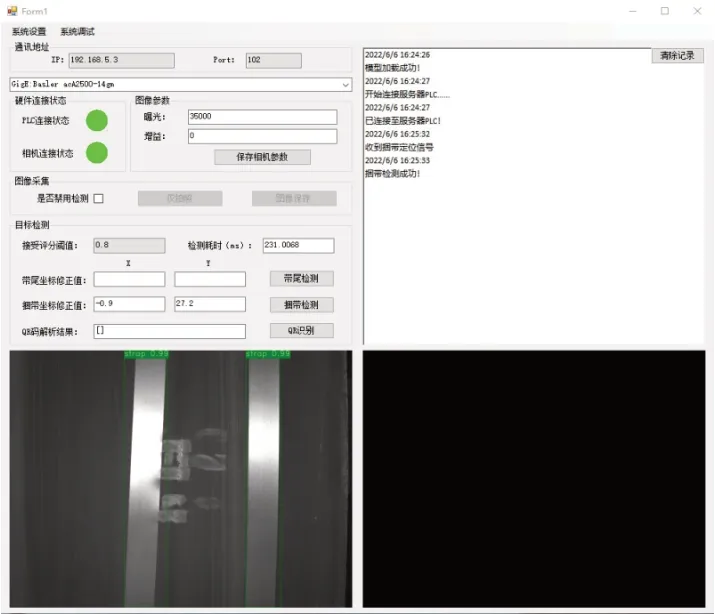
圖4 自動拆捆機器人系統上位機軟件界面
1.3 系統工作原理
鋼卷由運輸小車輸送至拆捆工位后,運載設備鎖定,PLC發出拆捆指令,機械人左右移動機頭,帶動末端CCD相機對鋼卷表面進行數據采集并進行視覺算法處理,通過事先計算出的標定矩陣將捆帶中心位置像素坐標轉化為世界坐標,引導機器人進行拆捆作業。捆帶識別定位的具體流程如圖5所示。
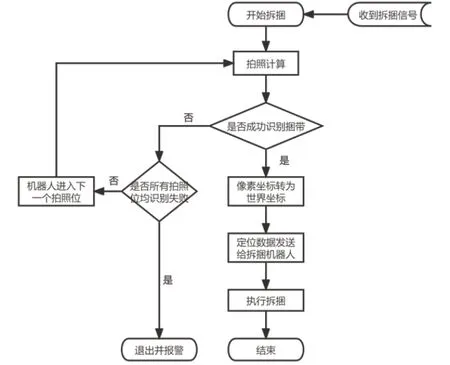
圖5 捆帶定位流程圖
2 傳統視覺捆帶定位
為了解決部分工況下激光檢測適用性較差的問題,引入視覺方案進行捆帶定位識別。在捆帶定位的需求中,待檢捆帶是寬度為32mm,厚度為1mm的均勻帶狀鋼材,且緊密環繞在鋼卷外表面。在不考慮鋼卷運輸過程中捆帶發生嚴重變形的情況下,捆帶自身的視覺特征一致性較好,基本滿足傳統視覺算法的使用條件。本系統傳統視覺研發過程中分別采用邊緣提取和模板匹配兩種算法對捆帶中心進行識別定位。
2.1 邊緣提取檢測算法
邊緣提取捆帶檢測算法提取圖象中捆帶邊緣的像素數據并加以分析判斷進而定位出捆帶所在的位置。該算法具體分為下幾個步驟:
1)圖像預處理,對捆帶圖像進行高斯濾波,消除部分噪聲干擾;
2)邊緣提取,利用canny算子對圖像中捆帶邊緣的像素數據進行提取;
3)特征選擇,設置邊緣長度閾值,當檢出的邊緣像素數組長度在設定的閾值區間時認為該邊緣為有效邊緣;
4)直線擬合,通過最小二乘法對所有有效邊緣像素坐標序列進行擬合[10];
由直線擬合的最小二乘法公式推導結果可知,離散點集(xi,yi)(i=0,1...m)的直線擬合結果為y=a*+b*x,其中:
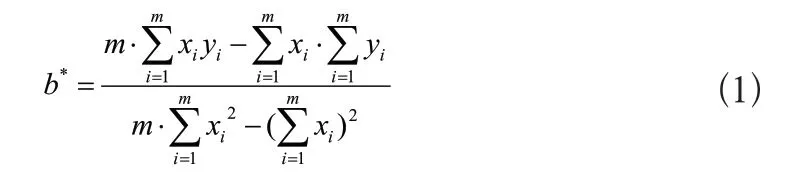
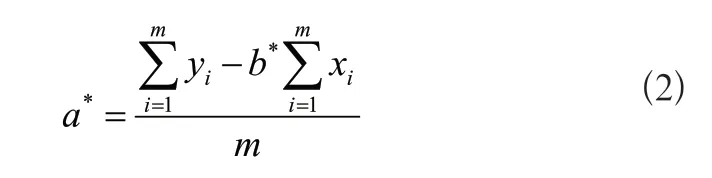
5)寬度計算,設置邊緣對寬度閾值,根據平面點到直線的距離公式為:
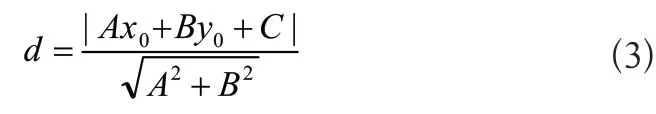
其中,A=b*,B=-1,C=a*
計算每條有效邊緣的中點到其他所有有效邊緣擬合直線之間的距離,作為有效邊緣對之間的等效距離,有效邊緣對之間的距離d在設定的閾值區間時認為該邊緣對為識別出的一條捆帶的兩條邊緣;
6)計算捆帶中心,在識別出的捆帶邊緣對中,取其中一條邊緣的中點像素坐標記為點M(xM,yM),點M到另一條邊緣的垂足記為點N,M、V連線的中點P(xP,yP)即為捆帶中心的定位點,其中:
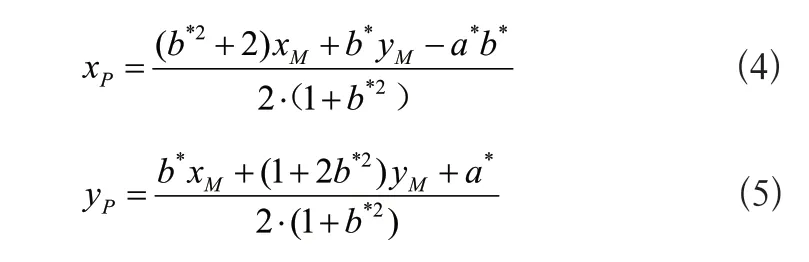
利用上速算法對捆帶進行識別定位的可視化過程如圖6所示。

圖6 邊緣提取捆帶識別
2.2 模板匹配檢測算法
模板匹配是一種用于在較大圖像中搜索和查找模板圖像位置的方法,主要分為基于灰度的匹配方法和基于特征的匹配方法。基于灰度的匹配方法通過待測圖像與模板圖像之間的相關性定位目標也稱為相關匹配算法,其工作原理是模板在原始圖像上從原點開始滑動,計算模板與圖像被模板覆蓋區域的差異,找到圖像中的與模板圖像中最相似的像素點,再根據模板的寬度和高度,標記出對應的區域范圍。基于特征的匹配方法主要通過提取待測圖像的顏色特征、紋理特征、形狀特征、空間關系特征與模板圖像進行匹配。
相較于捆帶材質不同和鋼卷長時間熱處理導致的圖像中捆帶部分像素灰度差異明顯這一問題,捆帶自身形狀一致性較好,邊緣特征明顯,相對更適合基于形狀特征的匹配算法進行模板匹配,選擇halcon提供的creat_shape_model算子創建捆帶模板圖像,使用find_shape_model算子進行模板圖像檢出,通過匹配結果評分閾值控制檢出目標的質量[11]。

圖7 模板匹配捆帶識別
2.3 傳統視覺算法檢測檢出率計算
通過準確率(accuracy)、誤檢率(false)和漏檢率(loss)三項量化指標評價傳統視覺算法的精度。將傳統視覺算法的檢出結果和人眼觀察結果進行對比,所有真實的捆帶實例記為p,正確地檢測為是捆帶個數記為tp,錯誤地檢測為是捆帶的個數記為fp,錯誤地檢測為不是捆帶的個數記為fn,則有:
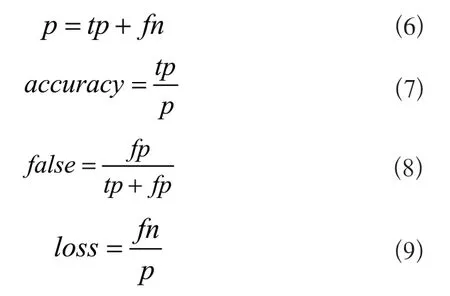
其中準確率作為算法的主要精度指標,誤檢率和漏檢率作為參考項。
3 深度學習捆帶定位
深度學習目標檢測算法與傳統視覺算法的特征提取方法有所不同,前者通過將大量待檢圖像數據輸入卷積神經網絡(CNN)進行自主學習的方式訓練出用于預測目標分類和識別定位信息的推理模型。值得一提的是,每當數據集擴增時,都可將原有推理模型作為預訓練模型和新的圖像數據一起輸入深度學習神經網絡再次學習,這使得深度學習目標檢測算法可以適應不斷變化的環境和規則,從而對目標物體進行更準確的分類識別和定位。
3.1 深度學習目標檢測算法
當前深度學習目標檢測算法主要分為Two-stage算法和One-stage算法兩類。Two-stage算法由兩步組成,第一步由選擇性搜索、邊界框等方法生成候選區域,第二步結合CNN提取特征并回歸分類。Two-stage算法檢測準確率高,但檢測速度較慢。典型的Two-stage算法有R-CNN、Fast R-CNN、Faster R-CNN以及Mask R-CNN等。One-stage算法則采用直接回歸的方式同時進行候選區域選擇和目標分類識別,這極大地提高了算法的運算速度但也導致了準確度有所下降。典型的Onestage算法有YOLO系列、SSD系列等[12~14]。本文系統研發過程中,分別選擇Two-stage算法中高檢測精度的Faster R-CNN算法,和One-stage算法中已在工業領域成熟應用的YOLOv3算法訓練模型進行捆帶檢測。
3.2 模型訓練
在硅鋼FCL入口機組生產現場,通過工業相機采集了1177張照片作為捆帶檢測的數據集,經過數據標注、轉換和切分后的VOC數據集包含訓練集照片825張,驗證集照片235張,測試集照片117張。通過PaddleX深度學習平臺自帶的訓練接口加載卷積神經網絡和訓練集數據進行模型訓練。訓練端服務器的CPU為Intel(R)Core(TM)i9-10920X,主頻3.50GHZ,GPU為NVIDIA GeForce RTX 3080,使用GPU進行深度學習訓練,并通過CUDA架構的cudnn深度神經網絡庫加速。訓練完成后對模型進行壓縮剪裁,提高模型的推理速度。
3.3 深度學習模型精度評估
訓練后對模型進行精度評估,評估過程中用到的指標主要有交并比(IoU)、精確率(Precision)、召回率(Recall)和平均精度(AP)。

圖8 深度學習捆帶識別
深度學習目標檢測的預測結果是一個包含檢測目標的預測框,將其記為PredictBox(PB),正確的標注框記為GroundTruth(GT),則IoU的計算公式如式(10)所示:
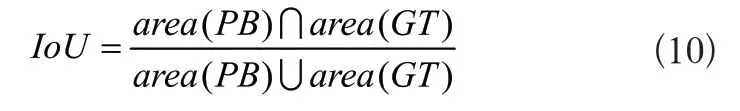
當IoU大于預設的IoU閾值時,認為目標檢測結果有效。
精確率和召回率的計算公式如式(11)、式(12)所示:
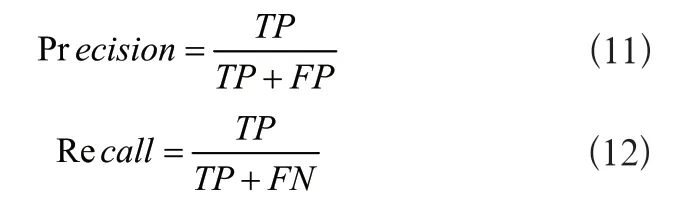
其中,TP為被正確地檢測為正實例的個數,FP為被錯誤地檢測為正實例的個數,FN為被錯誤地檢測為負實例的個數。
對于本系統單一的目標種類這種情況來說,可以使用AP來反映模型的整體精度[15],將不同閾值下精確率和召回率之間的映射記為P(r),則AP的計算公式為:

4 實驗與分析
為了驗證上述傳統視覺和深度學習捆帶識別定位算法的性能,在硅鋼FCL入口機組自動拆捆機器人系統調試過程中進行實驗,現場部署端選用win7系統普通工控機,CPU為Intel(R)Core(TM)i7-8700主頻3.20GHz,使用CPU進行深度學習預測。
將捆帶數據集照片分別輸入傳統視覺算法接口、Faster R-CNN目標檢測模型和YOLOv3目標檢測模型預測接口進行檢測,設置置信度閾值和IoU閾值均為0.8,分別計算傳統視覺檢測算法的準確率、誤檢率、漏檢率和深度學習目標檢測算法的精確率、召回率和AP,得到的測試結果如表1和表2所示:
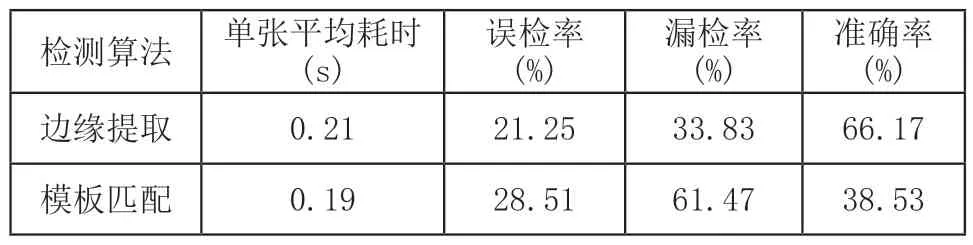
表1 傳統視覺捆帶識別結果
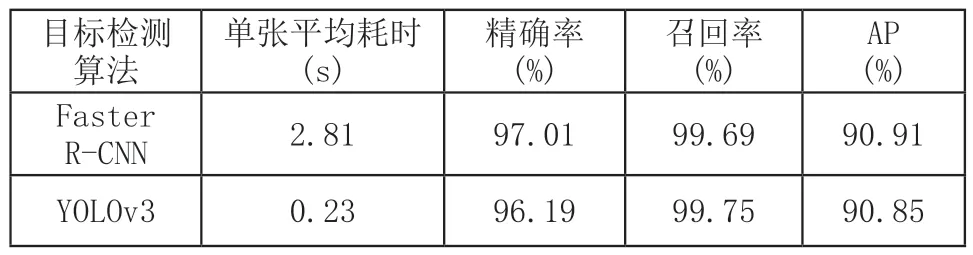
表2 深度學習捆帶識別結果
5 結語
1)傳統視覺邊緣提取和模板匹配算法在硅鋼FCL入口開卷機組這種環境光照變化劇烈、捆帶及背景鋼卷表面特征復雜多變的情況下檢測精度較低,無法滿足自動拆捆機器人捆帶識別定位的需求。
2)基于YOLOv3算法訓練的深度學習捆帶檢測模型整體檢測精度為90.85%,捆帶識別的平均速度為4fps,能夠滿足硅鋼FCL入口自動拆捆機器人的生產節拍和90%以上的拆捆率要求,經過優化后可以在性能較低的現場工控機上部署應用。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
