機器學習下隨機森林算法在電網故障分析指揮系統中的應用
2022-10-06 04:18:46湯衛東肖大軍談林濤于文娟
計算技術與自動化 2022年3期
湯衛東,肖大軍,談林濤,于文娟
(國家電網有限公司華中分部,湖北 武漢 430077)
隨著互聯網和信息技術的不斷進步,以大數據為依托的機器學習和人工智能成為熱門的發展方向,面對大量的數據和信息,對其進行快速的分類并從中找出潛在的規律是機器學習的主要目的,目前,數據挖掘對分類技術的研究已經取得了非常重要的進步,以決策樹和深度學習為代表的數據分析模型不僅操作簡單而且效果顯著。
隨著人們的生活質量不斷提高,對于數據處理的需求也越來越高。由于神經網絡在連續處理大量數據的過程中容易產生過度擬合的問題,同時對于數據樣本的要求也比較高,所以在許多領域都有非常廣泛的應用。但程中還存在局限性。在這樣的背景下,以決策樹為核心的多分類隨機森林算法(Random Forest Algorithm, RFA) 得到了研究學者的關注,作為一種典型的多分類器算法,隨機森林可以很好地對數據進行集成學習,同時根據數據的多樣性進行分類處理,避免了神經網絡對數據的過度擬合,因此隨機森林算法擁有非常強大的適用性,可以在許多領域進行廣泛應用,特別是針對一些非線性高維數據,隨機森林算法也可以很快地進行處理,此外,隨機森林算法對噪聲和隨機誤差的防控非常到位,可以極大地減少因數據產生的誤差,從而降低了數據處理難度,節約了大量的人力物力,幫助數據得到快速、準確的分析。
基于大數據時代背景,通過閱讀和查找大量的相關文獻和資料對電網系統的故障分析進行評級,然后利用隨機森林算法的決策樹分類模型對電網系統的故障進行預測分析,將隨機森林算法與其他應用較廣泛的算法的預測準確率進行對比驗證隨機森林算法的實用性和優越性,然后在Weka平臺上利用當地電力局的數據樣本進行仿真模擬,對電網故障的預測準確率結果進行分析,驗證故障分析模型的科學性和準確性。對于電網系統的故障預測具有非常重要的指導意義。
1 機器學習下的電網故障分析
1.1 電網故障分析原理簡述
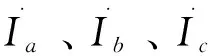
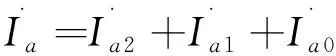
(1)
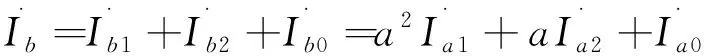
(2)
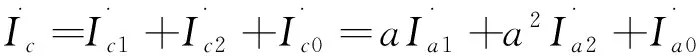
(3)
解方程(1)-(3)可得:
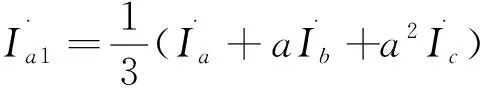
(4)
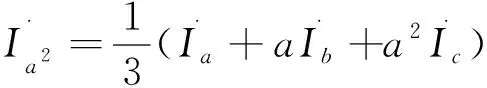
(5)
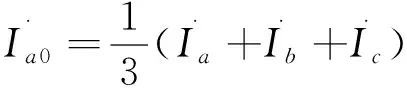
(6)
將其表示為矩陣的形式:
=
(7)
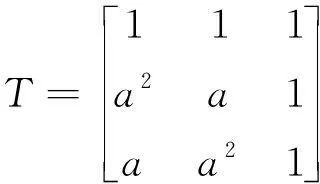
(8)
最后對電壓進行變換:
=
(9)
此外,對稱電路故障主要是根據電源三相系統進行分析,因為發生短路前后,電源的電壓和頻率不會發生變化,所以設短路前的電壓和電流分別為、:
=sin(+)
(10)
=sin(+-)
(11)
其中相電流的有效值為:

(12)

(13)
其中,和分別為每相電路的電阻和電感,當電路發生短路后,a相的電流表達式可表示為:
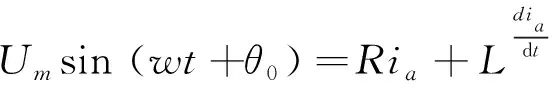
(14)
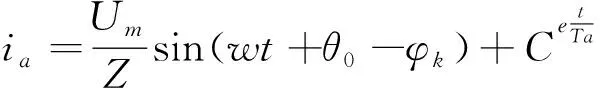
(15)
當電網系統發生故障時,工作人員必須及時對故障進行排查,確定故障來源和故障所在區域,利用對稱故障和非對稱故障法可以快速地實現對故障的定性處理,通過電壓、電流及其他參數的變化來確定故障類型,從而幫助電網系統解決故障,恢復電路正常運行,保障居民的用電需求。
1.2 機器學習和隨機森林算法
機器學習(Machine Learning)是利用計算機模擬人類大腦學習過程的一種多學科交叉理論,信息時代,對數據信息進行篩選和處理,是當下研究的熱點話題。機器學習領域廣泛,可以完成大量數據的快速分類和處理,實現數據預測和分析。
隨機森林算法是機器學習領域中一種普適性良好的數據挖掘方法。其運行原理是在決策樹算法的理論之上結合 boot strap 重采樣方法,集合多個單樹型分類器,最后結果通過投票的策略進行分類和預測。隨機森林算法具有多重優點,調整參數較少,抗噪聲能力強,最重要的是在實際的應用中分類性高,不容易發生過擬合等。但也有其缺點,隨機森林算法的特征選擇具有隨意性,導致忽略特征對類別的重要性以及特征與特征之間的相關性,采用重抽樣技術通過隨機抽取樣本形成新的訓練集,然后利用自主數據集進行決策樹建模,并組成隨機森林,分類結果進行投票決策。隨機森林的數學定義如下:首先設置一系列的決策()、()、…,()構建森林,同時隨機取兩個向量、,則邊緣函數為:
(,)=((()=)-
max((()=)
(16)
=,((,)<0)
(17)
其中為正確的分類分量,為錯誤的分類向量,表示取平均值,表示泛化誤差,邊緣函數的值越大,說明該模型的可信度越高。而隨機森林的邊緣函數為:
(,)=(()=)-
max(()=)
(18)
其中,(()=)表示判斷正確的分類概率,(()=)為判斷錯誤的分類概率。
隨機森林算法主要運用于數據分類和預測中,根據數據集中元素的特點可以分為正類和負類,和分別表示正確分類中正類和負類的樣本數量,而和分別表示錯誤分類中正類和負類的樣本數量,則隨機森林算法的分類精確度為:

(19)
精確度越高說明其分類效果越好,此外,靈敏度和特異度的定義分別為:
=+
(20)
=+
(21)
其中靈敏度表示隨機森林對正類數據的分類精度,特異度表示對負類數據法分類精度。隨機森林的設計總原則是要保證靈敏度和特異度的平衡性,也就是兩者總體均值的最大化,評價指標為幾何均值-:
-=

(22)
最后,負類數據對應的三個評價指標為查全率和查準率以及負類檢驗值:
=+
(23)
=+
(24)
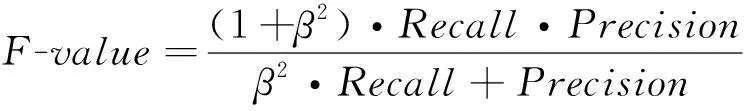
(25)
其中,查全率表示正確分類中的負類樣本在全部負樣本中的比例,查準率表示正確分類的負類樣本在所有預測為負類樣本中的比例,而負類檢驗值-是隨機森林算法中一個綜合的評價指標。隨機森林算法的示意圖如圖1所示:

圖1 隨機森林算法示意圖
2 基于隨機森林算法的電網故障分析模型
實驗對象:當地電力局的供電系統,以輸電網絡為主要分析對象,利用數據挖掘技術查找近三年的電網故障發生的時間和故障原因,并進行收集整理。
實驗數據來源:采取數據挖掘技術對當地電力局近三年的輸電數據進行收集,以2019年到2020年的數據作為訓練樣本,以2021年1月的數據作為測試樣本數據,2-3月的數據作為預測樣本。其中按照每個月的輸電故障為標準,每個月的故障次數在2次及以內為正常,評級為1;故障次數在3-6次評評級2,故障次數在7以上為故障高峰,評級為3。
實驗環境:隨機森林算法使用randomForest4.6語言軟件來實現,主要參數設置為:決策樹的數量為1000,隨機屬性的個數為3。在Weka數據挖掘平臺上建立電網故障分析模型,對比不同算法對電網故障的分析效果和精確度。
3 實驗結果分析
3.1 不同算法的對比分析
引入決策樹(decision tree)算法的一種(C4.5)、神經網絡算法(Neural Network Algorithm, NNA)以及支持向量機(Support Vector Machines)算法和隨機森林算法(RFA)進行對比,預測準確率和統計值指標如圖2所示。
由圖2可知,隨機森林算法的預測準確率和統計值指標要明顯高于其他三種算法,準確率高達93%,而其他三種算法的準確率均在90%以下,隨機森林算法的優越性得到了驗證。隨機森林算法決策樹的隨機性使數據多樣性得到提高,使環境和人為因素引入的誤差相對降低,避免了數據過度擬合的問題,增強模型的普適性。
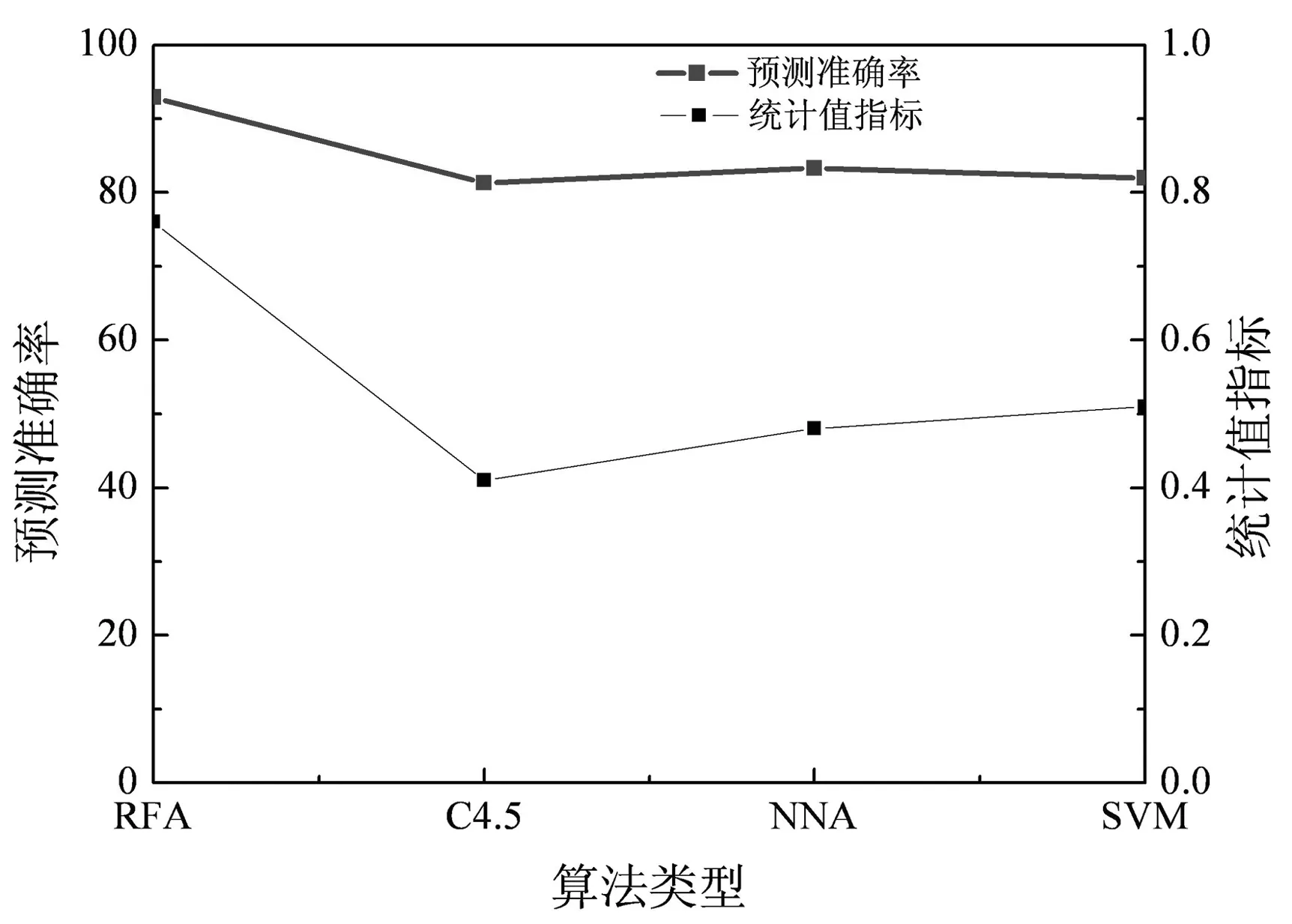
圖2 不同算法下電網故障的預測準確率與統計指標
3.2 電網故障的預測分析
利用隨機森林算法的電網故障分析模型進行檢測,不同故障等級的樣本數量對比如圖3所示。
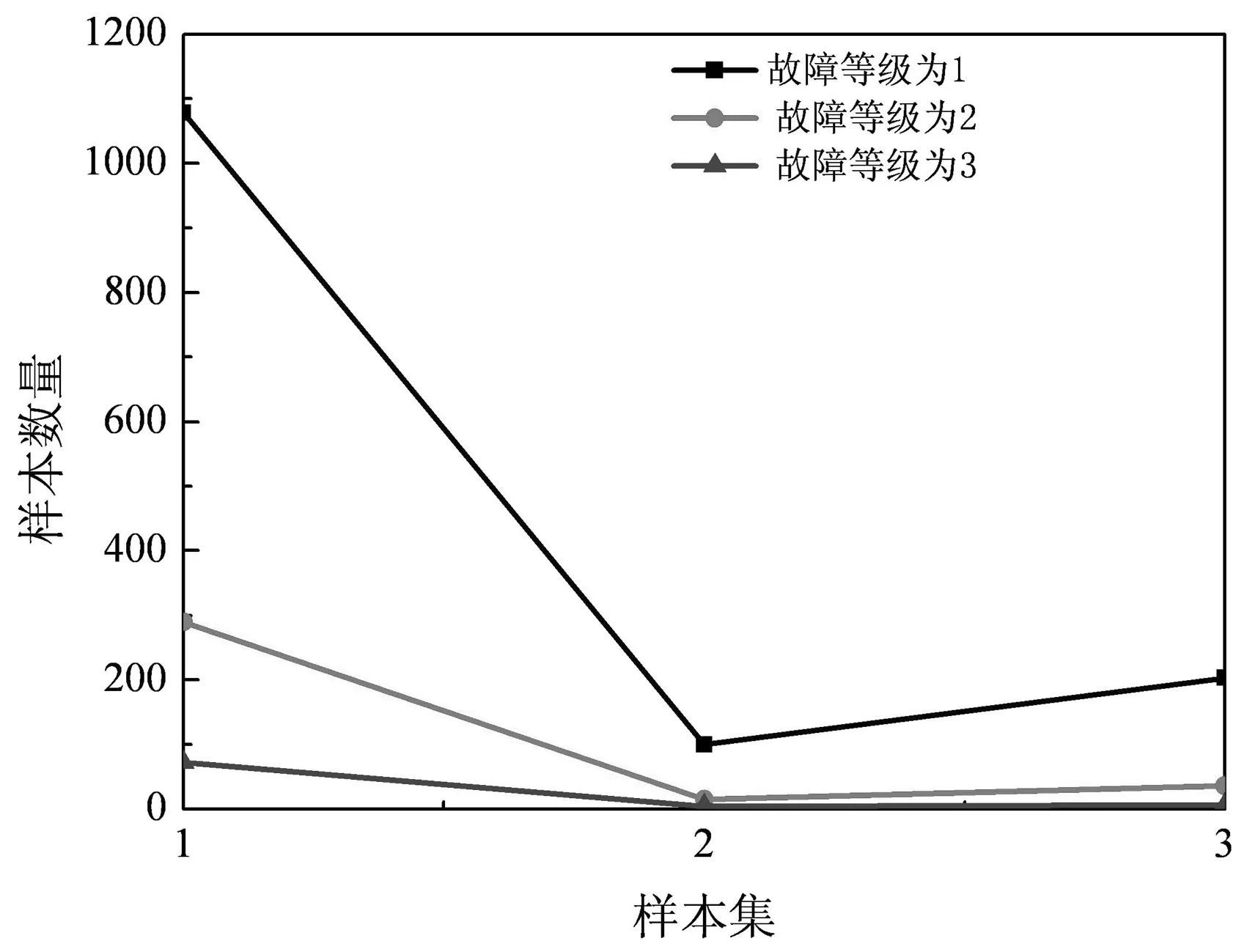
圖3 不同故障等級的樣本數量(橫坐標1-3分別表示訓練樣本、測試樣本、預測樣本)
由圖3可知,訓練樣本的數量要遠遠高于測試樣本和預測樣本的數量,同時故障等級為1的樣本數量遠遠超過其他兩個,說明該電力局的電網系統相對比較安全,故障發生的概率較低。
根據預測樣本的故障等級和實際故障對比,電網故障的預測結果如圖4所示。
由圖4所示,電網故障分析模型在2月和3月的預測中,總的預測準確率分別為95%和96.8%,其中等級為1的故障準確率均在95%以上,而故障等級為2的準確率為70%和89%,等級為3的預測準確率為66%和100%,這是由于樣本數量較少,容易出現隨機誤差從而導致準確率降低。整體而言,故障等級越高其預測難度越大,相對準確率也較不穩定,而故障等級越低,預測準確率越高。
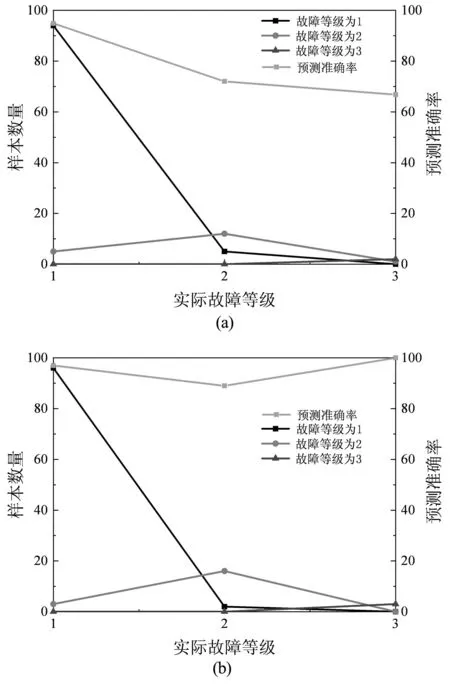
圖4 電網故障的預測結果
4 結 論
基于機器學習背景,首先對電網故障的原理展開分析,介紹了機器學習和隨機森林算法,根據電網故障的特點利用隨機森林算法對電網故障的等級進行分析預測。并引入決策樹算法(C4.5)、NNA神經網絡和SVM算法作為對照組檢驗隨機森林算法的預測性能,并利用隨機森林算法在Weka平臺軟件上對當地電力局近期的電力故障進行預測。結果表明,隨機森林算法的預測準確率和統計值指標要明顯高于其他三種算法,準確率高達93%。故障等級為1的預測準確率在95%以上,等級為3故障的預測準確率不穩定,最低僅為66%,相對準確率也較不穩定,故障等級越低,預測難度越低,準確率越高。由于受到客觀因素的限制,本研究存在一些局限,在收集數據時未進行預處理,可能存在虛假數據和無效數據,對實驗的準確性造成影響。在后續的研究過程中需要對數據進行預處理,提高研究結果的說服力。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
汽車維修與保養(2019年7期)2020-01-06 03:30:42
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
汽車維護與修理(2016年10期)2016-07-10 08:17:41
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
