基于隨機森林-聚類混合方法的多分類入侵檢測研究
2022-10-14 08:53:50呂廣旭盧加奇魏先燕王小英
現(xiàn)代信息科技 2022年16期
呂廣旭,盧加奇,魏先燕,王小英
(防災(zāi)科技學院,河北 三河 065201)
0 引 言
隨著技術(shù)手段的不斷更新,傳統(tǒng)的防御模型已無法應(yīng)對當前復(fù)雜多變的網(wǎng)絡(luò)攻擊技術(shù),以防火墻為首的防御手段正在失去“防火墻”的作用,攻擊方逃逸率不斷增加,它們往往采取多種攻擊方式結(jié)合的手段進行,這使得精準防御逐漸變得力不從心。
隨著機器學習技術(shù)的不斷興起,防火墻防御技術(shù)、入侵檢測技術(shù)等有了較大進步,但仍有較大的提升空間,防御攻擊能力相對較弱。網(wǎng)絡(luò)攻擊的復(fù)雜多變成為新攻擊下網(wǎng)絡(luò)安全問題不斷嚴峻的新方向。一方面基于有監(jiān)督的入侵檢測方法嚴重依賴樣本數(shù)據(jù),樣本數(shù)據(jù)分布是否合理、數(shù)據(jù)的質(zhì)量成為有監(jiān)督入侵檢測方法應(yīng)用過程中的重要一環(huán)。在數(shù)據(jù)量巨大網(wǎng)絡(luò)環(huán)境中,數(shù)據(jù)良莠的認定成為制約有監(jiān)督學習的另一關(guān)鍵問題,對于數(shù)據(jù)的標簽處理各行業(yè)很難有統(tǒng)一的處理方式,導(dǎo)致效果未能滿足要求。為此,基于無監(jiān)督的入侵檢測方法應(yīng)運而生,無監(jiān)督檢測方法摒棄對樣本標簽數(shù)據(jù)的依賴,減少人力資源的消耗,提升了檢測手段的實用價值,成為解決入侵檢測重點問題的關(guān)鍵抓手。
1 研究概述
用于入侵檢測方面的無監(jiān)督方法獲得了大量的關(guān)注和研究,為后續(xù)研究提供大量的理論基礎(chǔ)。2018年,楊文君等人對于K-means聚類方法在密度、距離和閾值等方面進行了分類分析,對于各類應(yīng)用場景分別進行了詳細闡述。此外針對聚類方法容易陷入局部最優(yōu)等實質(zhì)性問題,邢瑞康等人使用數(shù)據(jù)密度等信息改進中心點依賴弊端,顯著提高檢測效果。入侵檢測的數(shù)據(jù)往往是高維且復(fù)雜的,應(yīng)對高緯度環(huán)境下壓縮降維難題對于傳統(tǒng)聚類方法難以保證檢測準確率。2020年,解濱等人結(jié)合三支決策思想對傳統(tǒng)聚類方法進行改進,消除K值對于聚類效果的限制影響,通過二次聚類手段重新劃分,此方法在多攻擊行為場景下表現(xiàn)優(yōu)異。董新玉等人引入多視角余弦相似度作為衡量手段使用主成分分析對數(shù)據(jù)進行降維處理,克服有監(jiān)督學習漏檢率高等難題。
目前入侵檢測方法存在以下關(guān)鍵問題:
一是傳統(tǒng)數(shù)據(jù)降維方式中涉及較多的方式為主成分分析和線性判別分析。無論是作為無監(jiān)督的主成分分析方法,還是相比較主成分分析具有較優(yōu)的降維效果的線性判別方法而言,都容易存在過擬合的缺點。但不論是降維還是特征選擇的方式,對原始數(shù)據(jù)的壓縮和特征減少會對原始數(shù)據(jù)的表示存在損耗。因此還會出現(xiàn)損耗過大的情況導(dǎo)致誤報率較高。
二是傳統(tǒng)聚類方法存在局部最優(yōu)、漏檢率高、難以應(yīng)對高維復(fù)雜攻擊數(shù)據(jù)等主要問題,聚類算法將直接影響聚類效果的好壞。
針對上述問題,適應(yīng)高維大數(shù)據(jù)檢測,本文使用隨機森林方法對于數(shù)據(jù)進行特征篩選以提供數(shù)據(jù)降維支撐,將特征篩選結(jié)果提供聚類方法實現(xiàn)多分類入侵檢測效果。將改進算法應(yīng)用于入侵檢測分析中,其顯著提升無監(jiān)督聚類條件下多維數(shù)據(jù)的聚類效果,提升檢測準確率。
2 隨機森林-聚類混合方法
本文使用隨機森林-聚類混合方法對于入侵檢測數(shù)據(jù)進行分析,該方法包括兩部分組成。
模型前半部分主要利用隨機森林方法對入侵檢測數(shù)據(jù)集進行特征篩選,對高維度數(shù)據(jù)進行降維,在盡可能最大化保留原始數(shù)據(jù)信息情況下,將數(shù)據(jù)維度降至最低。模型后半部分接受降維后的數(shù)據(jù)作為輸入,使用基于改進的Canopy+K-means混合聚類方法對于數(shù)據(jù)集進行多分類劃分研究。
2.1 隨機森林篩選特征
由于網(wǎng)絡(luò)流量數(shù)據(jù)的高維性,導(dǎo)致單獨聚類方法對于入侵檢測的分類效果不佳,模型的泛化能力較差。就需要前期對數(shù)據(jù)進行壓縮降維處理,使提取的特征數(shù)據(jù)能夠保留原始數(shù)據(jù)的大部分信息的前提下,對聚類效果進行一個更優(yōu)的表達。本文使用隨機森林方法對數(shù)據(jù)特征進行篩選。
隨機森林篩選特征結(jié)構(gòu)如圖1所示,該方法將多個有監(jiān)督學習模型通過一定的結(jié)合策略實現(xiàn)一個能力更加優(yōu)秀的學習器。隨機森林則是以決策樹為單元劃分多個單元模塊分別進行決策,通過投票選擇出最優(yōu)的分類組合。基于隨機森林的特征篩選過程則是利用隨機森林基于決策樹分析的這一核心思想,通過每個單元可以將特征在決策樹上進行劃分,對比特征對于每個樹的貢獻程度通常是以袋外數(shù)據(jù)錯誤率作為評價指標,對特征進行選取從而達到特征篩選的目的。隨機森林因為隨機選取初始特征性質(zhì)以及強大收斂性,相比較于單個決策時進行分析時,更加適應(yīng)高維數(shù)據(jù)的處理,很好避免過擬合現(xiàn)象發(fā)生。
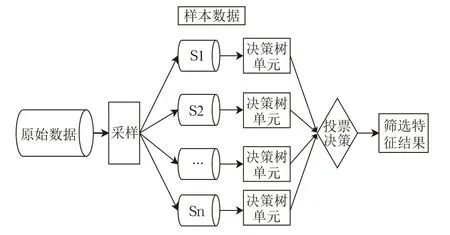
圖1 隨機森林篩選特征結(jié)構(gòu)圖
2.2 Canopy+K-means混合聚類算法
傳統(tǒng)的K-means聚類方法存在以下缺點:
(1)由于中心點的不確定性,導(dǎo)致簇內(nèi)聚合質(zhì)量較差,反映到入侵檢測方面產(chǎn)生的直接后果影響就是具有較大的錯誤分類數(shù),對于各攻擊的劃分非常不明確。
(2)另一方面由于聚類數(shù)據(jù)量較大,使用聚類方法計算迭代的次數(shù)也愈來愈大,導(dǎo)致分析時間延長。
由缺點進而演化出多種基于傳統(tǒng)K-means聚類方法的改進方法,從密度和距離計算方式等方面進行改進,極大提高了K-means聚類方法的效果。本文使用Canopy+K-means混合算法作為改進方法,為克服K值選取的困擾,可先用Canopy算法對所選數(shù)據(jù)進行一個初期的聚類研究,根據(jù)Canopy算法的結(jié)論然后對K-means算法中的K值進行一個選取,這樣既可以減少K值選取的極大不確定性,也可以減少開銷時間。Canopy算法原理如下:
(1)將原始數(shù)據(jù)轉(zhuǎn)換成列表形式作為樣本數(shù)據(jù),并設(shè)定初始閾值S1和S2且S1>S2。
(2)從列表數(shù)據(jù)中隨機選取樣本P,計算樣本數(shù)據(jù)到所有簇中心點的距離D。
(3)如果D>S1,則形成一個新簇,將P作為新簇中心點并將P從列表中刪除。
(4)如果S2<D<S1,則判斷該樣本屬于該簇并將其從列表中刪除。
(5)如果D<S2,則該點于該簇中心距離相當近屬于強相關(guān),并將其從列表中刪除。
(6)直至列表為空結(jié)束循環(huán)。
3 實驗分析
3.1 實驗環(huán)境和數(shù)據(jù)
為驗證隨機森林-聚類混合方法的多分類入侵檢測方法的應(yīng)用效果,本文采用數(shù)據(jù)為CSE-CIC-IDS2018流量數(shù)據(jù)集,該數(shù)據(jù)集主要用于評估和測試入侵檢測系統(tǒng),包括Bruteforce、Heartbleed、Botnet、DoS、DDoS等七種攻擊場景,由470臺計算機和30臺服務(wù)器組成的攻防網(wǎng)絡(luò)中。該流量數(shù)據(jù)集包含正向數(shù)據(jù)包總數(shù)、數(shù)據(jù)包平均大小、在向后方向傳輸?shù)臄?shù)據(jù)包中設(shè)置 URG 標志的次數(shù)(對于UDP為0)、數(shù)據(jù)流的平均長度等共80多個特征。
實驗環(huán)境為LINUX操作系統(tǒng),Intel CPU、RTX3090 GPU,64 GB內(nèi)存,運行環(huán)境為Python3.6。
為了驗證聚類方法在數(shù)據(jù)集上的實驗效果,本文采用調(diào)整互信息(AMI)、調(diào)整蘭德系數(shù)(ARI)和準確率三個做為聚類方法“外部”和“內(nèi)部”性能度量的評價指標。具體如下:
(1)調(diào)整互信息是基于互信息的優(yōu)化,用于評價隨機變量之間的關(guān)聯(lián)信息,調(diào)整互信息值越大則表明聚類結(jié)果和實際分類結(jié)果越相近。
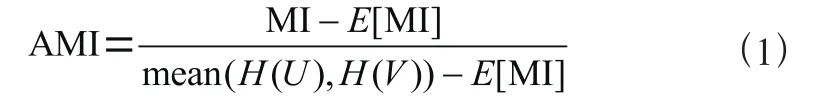
(2)ARI調(diào)蘭德系數(shù)是基于蘭德系數(shù)的優(yōu)化,評價隨機變量之間的劃分的重疊程度,結(jié)果越接近1,則聚類結(jié)果越優(yōu)秀。
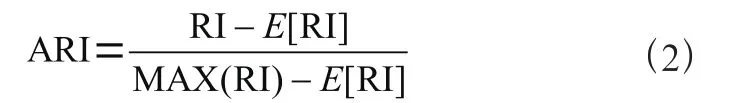
(3)準確率為正確聚類樣本數(shù)/入侵檢測樣本數(shù)。
3.2 實驗結(jié)果分析
使用數(shù)據(jù)集對于首先對于隨機森林-聚類混合方法進行分析,并對比單獨K-means方法、Agglomerative層次聚類、DBSCAN密度聚類方法進行對比實驗,對比不同方法期望驗證提出方法的有效性。首先用ids2018數(shù)據(jù)進行分析,用于隨機森林算法對于數(shù)據(jù)特征進行篩選,使用重采樣方法將數(shù)據(jù)進行劃分,對于特征重要性進行排序。
首先對數(shù)據(jù)集進行預(yù)處理,將無效數(shù)據(jù)和空數(shù)據(jù)進行替換和刪除,同時發(fā)現(xiàn)部分數(shù)據(jù)集的特征值全為零值,對聚類方法效果無影響,因此刪除這些特征。使用隨機森林作用于數(shù)據(jù)集進行特征篩選后的結(jié)果如表1所示,我們選取閾值大于0.02為有效特征,共計15個特征作為后續(xù)聚類分析的輸入。
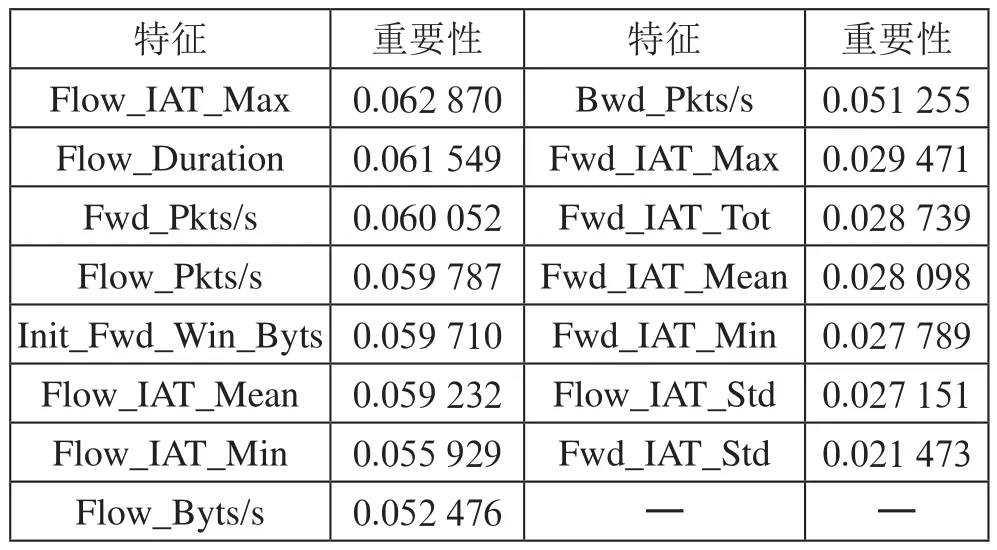
表1 有效特征及重要性
使用Canopy進行粗聚類研究,根據(jù)指標調(diào)蘭德系數(shù)分析,當聚類數(shù)在7~8之間時,系數(shù)值高于其他聚類數(shù),如圖2所示。與數(shù)據(jù)集描述七種攻擊場景和一種正常環(huán)境也相符合,因此選取初始值為8。
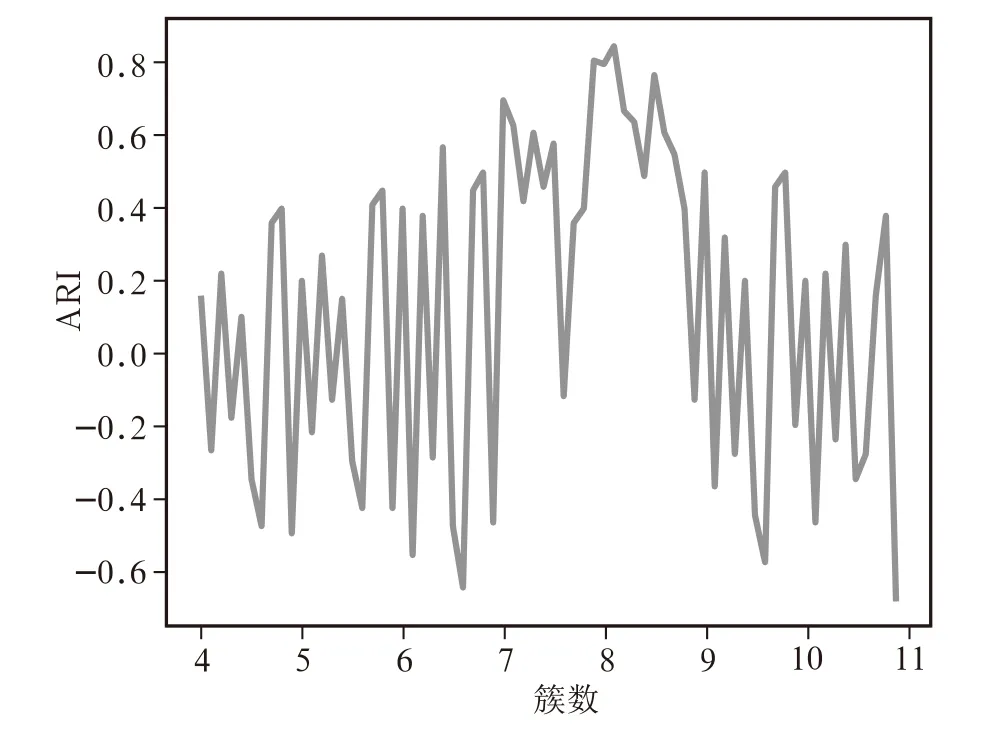
圖2 Canopy不同簇數(shù)下的ARI值
將聚類K值給定K-means聚類方法進行聚類分析,并對比不同聚類方法的實驗效果,實驗效果如表2所示。
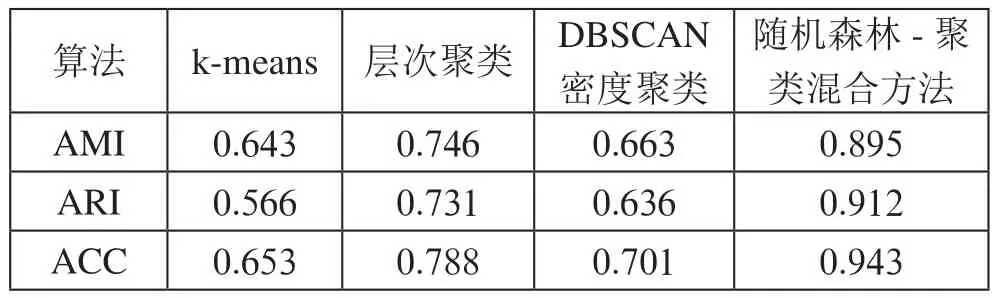
表2 不同算法在數(shù)據(jù)集上的實驗效果
實驗結(jié)果表明,傳統(tǒng)聚類方法在2018檢測數(shù)據(jù)集中檢測效果差距不大,其中層次聚類方法相較于K-means方法和DBSCAN檢測方法,在各項指標表現(xiàn)較優(yōu),改進后的隨機森林-聚類混合方法在入侵檢測數(shù)據(jù)集表現(xiàn)各項指標均優(yōu)于傳統(tǒng)聚類方法,相對于傳統(tǒng)方法中表現(xiàn)優(yōu)越的層次聚類方法,準確率提升了19.6%,同時AMI和ARI指標均大幅度改善,表明該方法簇內(nèi)和簇間的聚類劃分能力強,極大改善了傳統(tǒng)入侵檢測方法的檢測效果。
4 結(jié) 論
入侵檢測是防御網(wǎng)絡(luò)攻擊中重要一環(huán),為了解決傳統(tǒng)聚類檢測方法誤報率較高,難以應(yīng)對高維數(shù)據(jù)分析等關(guān)鍵難題,本文提出一種基于隨機森林-聚類混合方法的多分類入侵檢測方法,該方法基于CSE-CIC-IDS2018流量數(shù)據(jù)集,使用隨機森林進行特征篩選和組合,然后將篩選后的特征輸入聚類算法中,該聚類方法結(jié)合Canopy和K-means算法進行,可大幅度減少開銷時間,使K值確定更加準確,先用Canopy算法對于數(shù)據(jù)進行粗聚類為K值大小提供參考依據(jù),然后使用K-means聚類方法進行多聚類劃分。實驗結(jié)果表明,該方法能夠有效處理高維數(shù)據(jù)環(huán)境下入侵檢測數(shù)據(jù),相比較于傳統(tǒng)聚類方法,各項指標更高,檢測效果更加優(yōu)越。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年8期)2016-10-09 02:11:50
