基于XGBoost模型的新型冠狀病毒(COVID-19)疫情分析與預測
2022-10-15 13:17:10孫許可
現代信息科技 2022年14期
孫許可
(中國人民武裝警察部隊士官學校,浙江 杭州 311400)
0 引 言
新冠肺炎(COVID-19)疫情已成為國際關注的突發公共衛生事件,COVID-19 呼吸系統疾病的病毒株是一種名為嚴重急性呼吸系統綜合征冠狀病毒2(又稱SARS-CoV-2)引起的。這種冠狀病毒病具有極強的傳染性。自最初確認以來,盡管受到嚴格控制,但仍已成為全球流行病,對世界衛生和經濟發展構成了巨大的威脅和挑戰。目前,該疾病已蔓延至全球100 多個國家。
至2020年6月16日,全球共報告8 044 683 例COVID-19 病例,死亡437 131 例,治愈3 883 243 例,總病死率為5.43%,其中,美國、巴西、俄羅斯、印度和英國是世界上感染人數最多的5 個國家。COVID-19 表現出非線性和復雜的性質,除了涉及傳播的眾多已知和未知變量外,不同地緣政治區域的人口行為的復雜性和遏制策略的差異極大地增加了模型的不確定性。
因此,建立基于XGBoost 的疫情預測模型,使用Jupyter 軟件進行學習和訓練,對2020年1月23日到3月1日全國和湖北的累積確診病例數、累積死亡病例數、累積治愈病例數、累積正在治療病例數進行分析、建模,進一步洞悉新冠肺炎疫情發展規律,為防控新冠疫情提供參考。
1 模型與方法
1.1 XGBoost 概述
該算法的建模思路:給出一個泛化的目標函數的定義,在每一輪的迭代中找到一個合適的回歸樹去擬合上次預測的殘差,最小化目標函數,使估算值逼近真實值,如圖1所示。
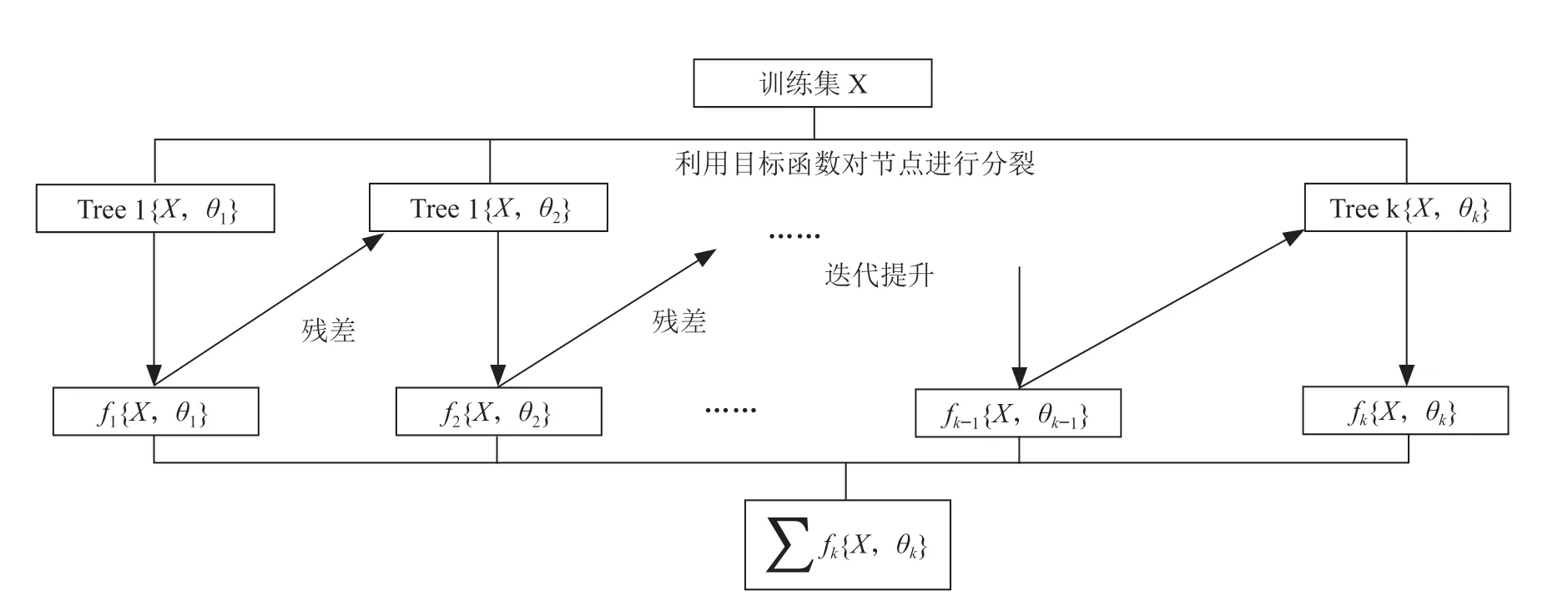
圖1 XGBoost 原理
例如,數據([Δ,Δ,],SOH),([Δ,Δ,],SOH)…([Δ UΔ T,],SOH),=1,2,…,。其中Δ U,Δ T,,SOH分別表示第i 組數據對應的電壓差、溫度差、平均電壓以及健康狀態。
在本文中,我們定義樹f(x)如下:
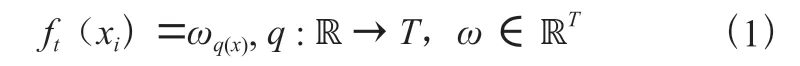
其中,表示每棵樹的結構,它將使葉子節點與每個樣本一一對應,是樹中葉子節點的個數。每個f對應于一個獨立的樹結構和葉子權重。
將樹的復雜度(f)定義為:
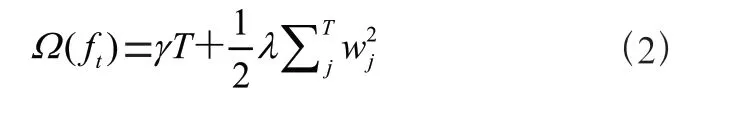
為葉子個數,w表示第個葉子的權重。
將目標函數定義為:


將目標函數進行展開,為:
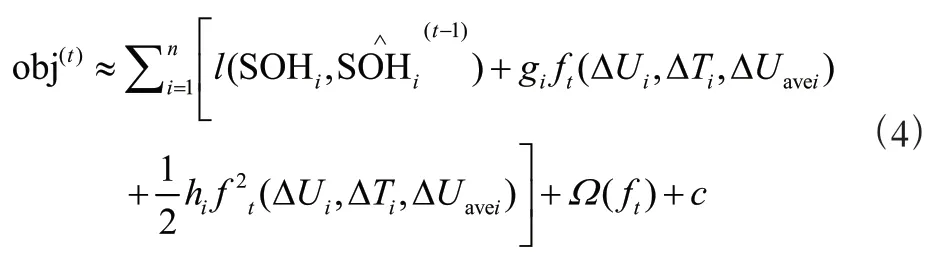
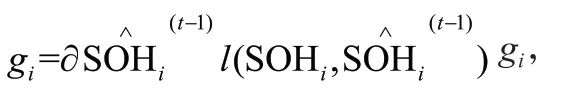
新的目標函數可以定義為:
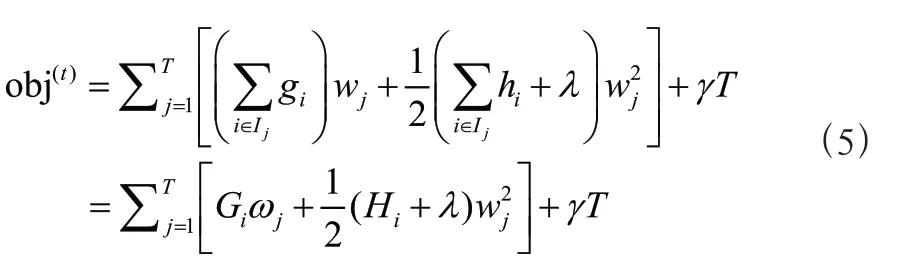
定義每棵樹的分裂節點的候選特征集合為I,I={|(Δ U,Δ T,Δ)=}。
計算出最優權重 和最佳的目標函數解obj:
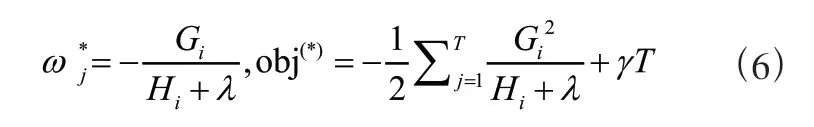
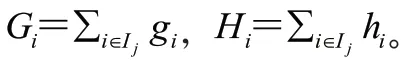
1.2 XGBoost 建模
如圖2所示,本文所提出的方法主要分為兩個部分:特征選擇、XGBoost 估算。首先,從數據集里面提取特征輸入,將累積治愈病例數、累積死亡病例數、累積正在治愈病例數作為特征輸入,然后,利用XGBoost 算法實現對累積確診病例數的估算,進一步提高累積確診病例數的估算精度。
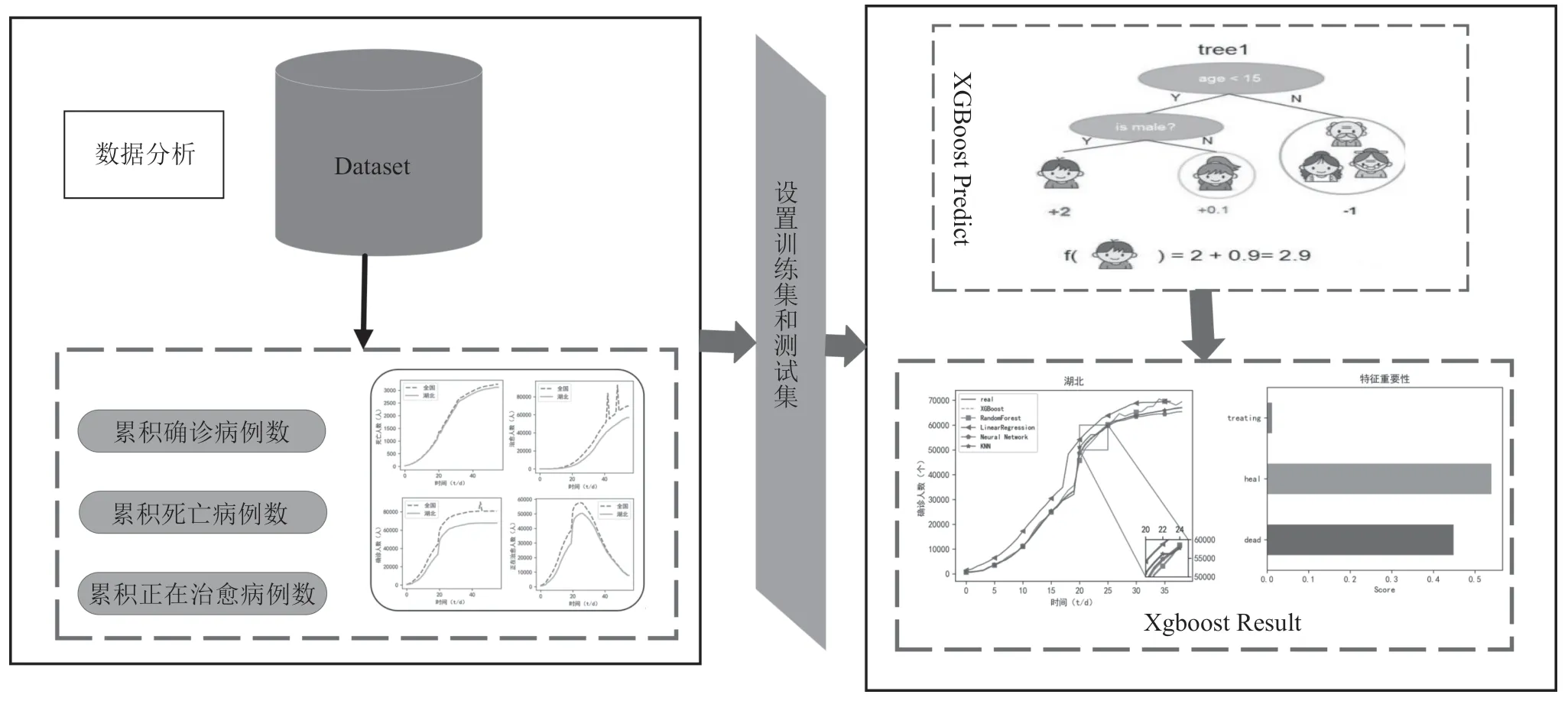
圖2 XGBoost 模型構建
2 模型評估與預測
2.1 實驗數據
本次實驗所使用的數據是該網站數據是從國家衛生健康委員會網站整理成CSV 格式得到,該網站為:http://www.nhc.gov.cn/xcs/yqtb/list_gzbd.shtml。該數據包括2020年1月23日到3月1日國家衛生健健委員會公布的全國和湖北的累積確診病例數、累積死亡病例數、累積治愈病例數、累積正在治愈病例數,該數據無缺失值。
全國和湖北的累積確診病例數、累積死亡病例數、累積治愈病例數、累積正在治愈病例數,如圖3所示。
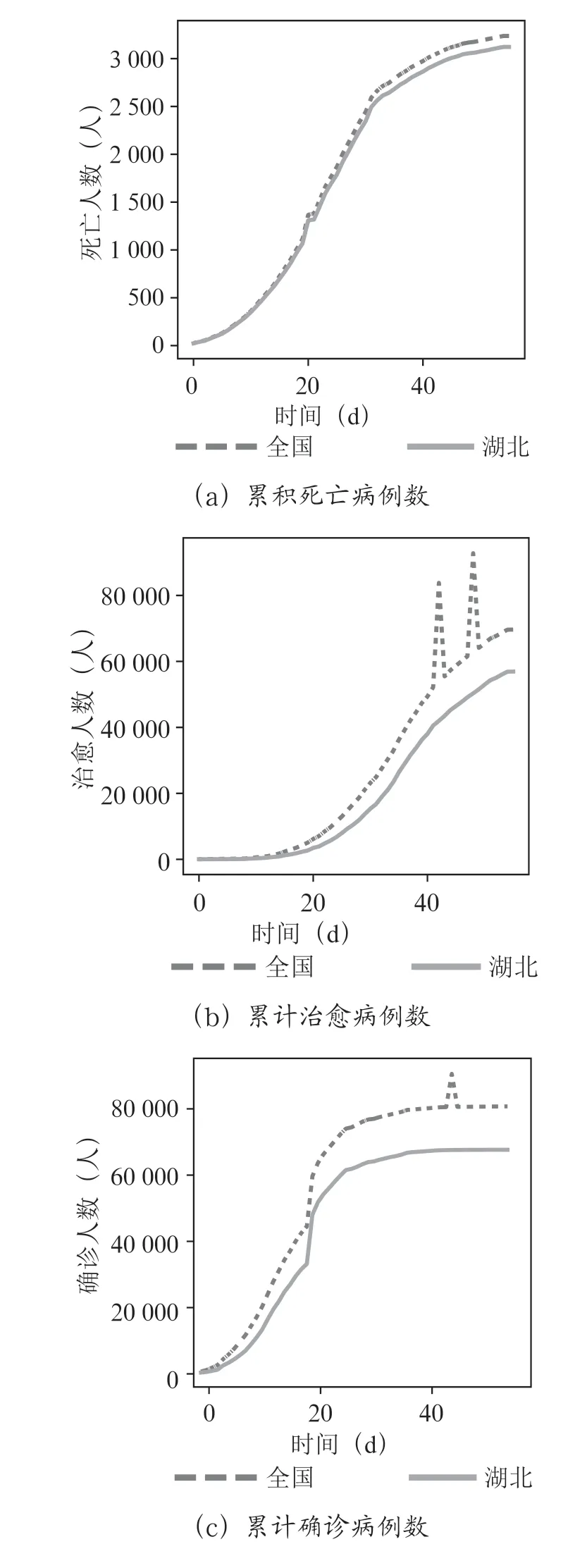
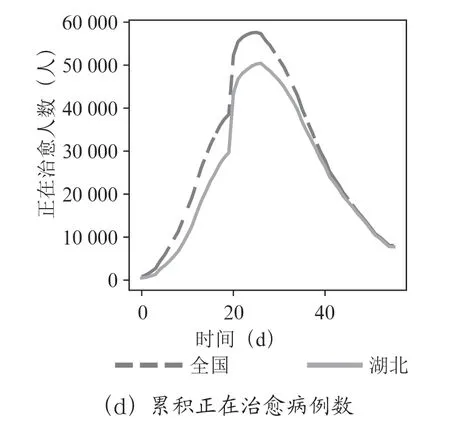
圖3 數據分析
為了驗證XGBoost 算法在COVID-19 估算上的普遍性,將學習率設置為0.2,最小葉子權重設置為1,樹的深度設置為3(實驗結果表明該模型收斂),并進行了兩組實驗:一組是將全國疫情數據作為模型的訓練集,用于模型的訓練,將湖北疫情數據作為測試集,用于測試模型的性能;另一組將湖北疫情數據作為模型的訓練集,用于模型的訓練,并將湖北疫情數據作為測試集,用于測試模型的性能。
2.2 實驗評估標準
(1)平均絕對誤差(MAE)
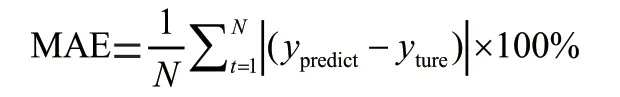
(2)均方根百分比誤差(RMSE)
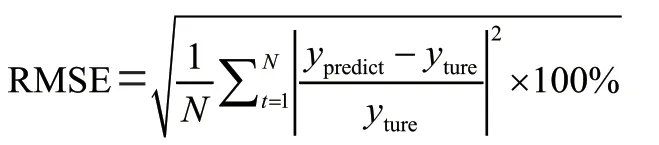
(3)最大估算誤差(Maximum Error)
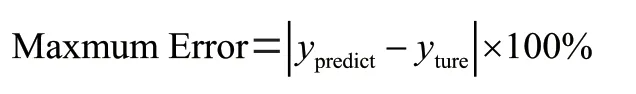
三項技術指標(MAE、RMSE、Maximum Error)的值越低,證明模型擬合的結果越好。
2.3 實驗結果分析
為了驗證基于XGBoost 算法的COVID-19 估算方法的準確性,將預測結果與隨機森林、線性回歸、KNN、SVM的預測結果進行比較。圖4和圖5顯示了在全國疫情數據和湖北疫情數據上的累積確診病例的預測結果和預測誤差。
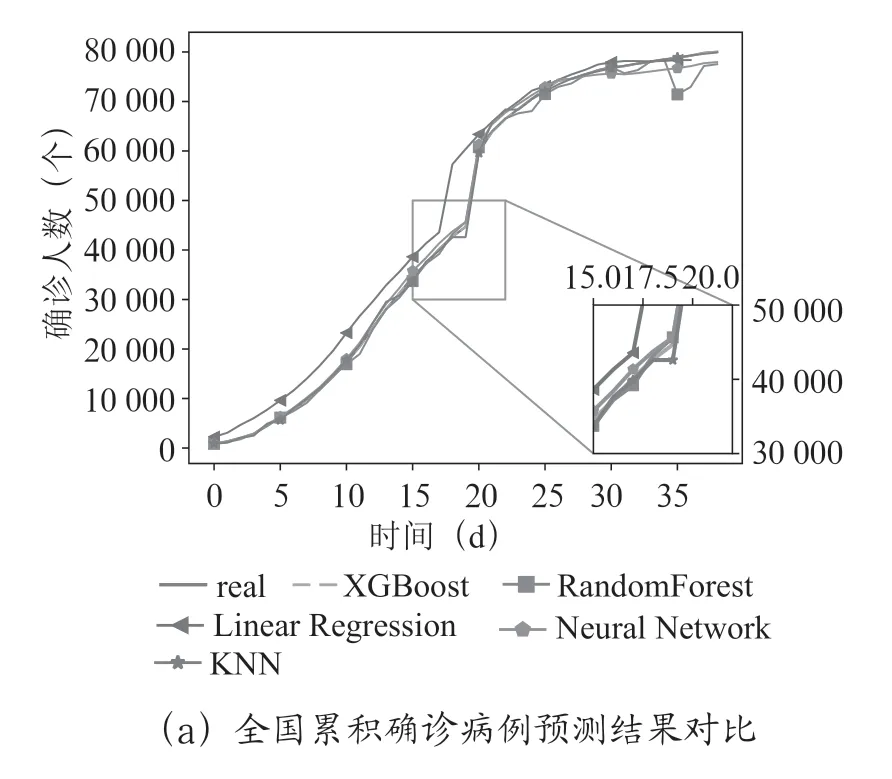
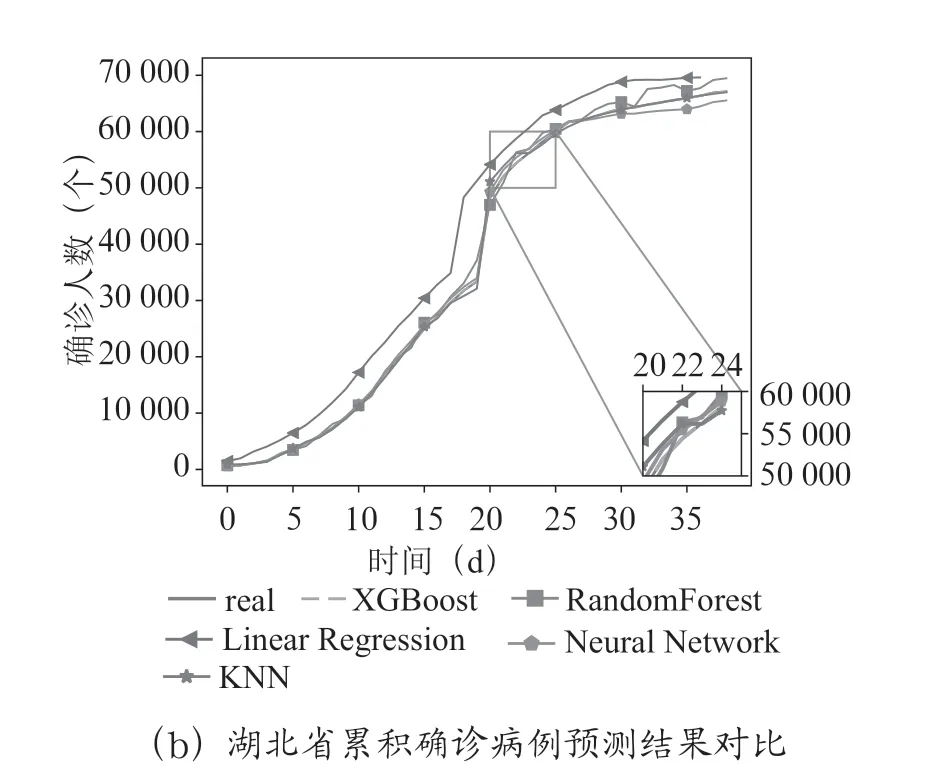
圖4 預測結果對比

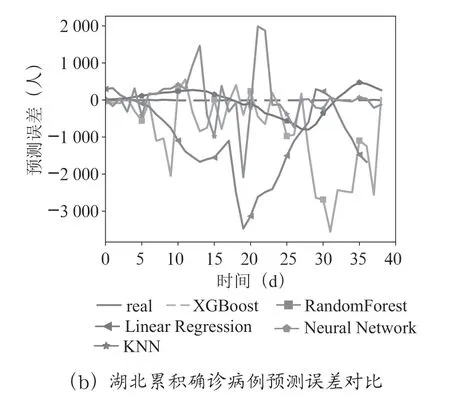
圖5 預測誤差對比
如圖4所示,從預測結果上看:無論是在全國疫情數據上還是在湖北疫情數據上,XGBoost 比其他四種回歸算法在估算值上更加接近真實值,估算精度更高。
如圖5所示,從產生的殘差上看:無論是在全國疫情數據上還是在湖北疫情數據上,其他四種回歸算法所產生的殘差曲線波動范圍較大,而XGBoost 的殘差曲線在0 附近上下波動。
從表1中可以看出,在全國疫情數據或湖北疫情數據上,三個技術指標中的XGBoost 值均低于其他四種算法的值,XGBoost 的性能均優于其他四種算法。
可視化表1中的MAE、RMSE、Maximum Error 數據,如圖6所示。總之,無論在全國疫情數據還是湖北疫情數據上,XGBoost 具有更高的估算精度,在三個技術指標中,XGBoost 均優于其他四種算法。

表1 全國疫情、湖北疫情數據集預測誤差對比
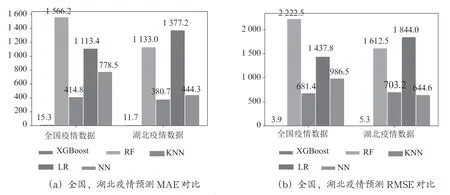
圖6 誤差可視化對比
特征重要性分析如圖7所示。其中,貢獻最大是累積治愈病例數,其次是累積死亡病例數,而累積正在治愈病例數最小。因此,在估算過程中,可以根據特征重要性等級,增加或減少某個特征比重,提高特征數據準確性,來進一步提高估算精度。
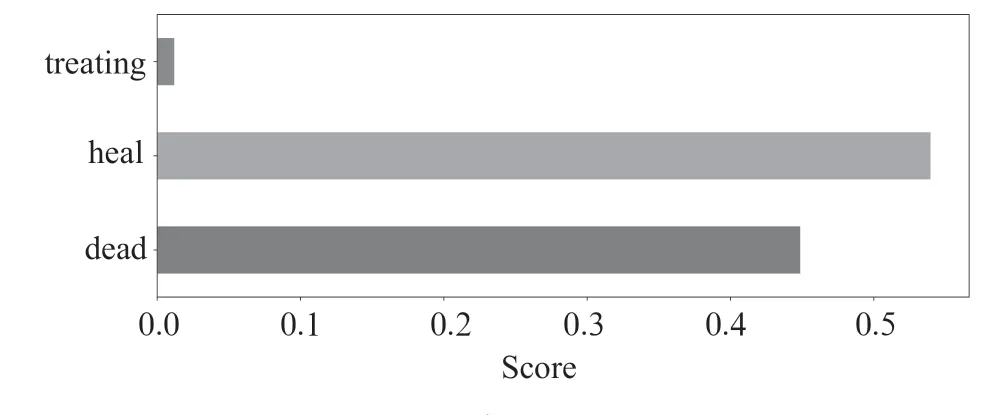
圖7 特征重要性
3 結 論
利用Jupyter 軟件對歷史數據進行學習和訓練,建立新冠肺炎病例XGBoost 預測模型,將累積治愈病例數、累積死亡病例數、累積正在治愈病例數作為特征輸入,對2020年1月23日到3月1日全國和湖北的累積確診病例數進行預測,將其預測結果與其他4 種預測模型進行比較,實驗結果表明:與線性回歸模型、隨機森林模型、支持向量機模型、KNN 模型等四種預測模型相比,采用XGBoost 預測模型預測的累積確診病例數更接近實際值,其平均絕對誤差和均方根誤差以及最大誤差這三項技術指標均最小,預測精度最高,并且分析得出特征重要性等級,其中,貢獻最大是累積治愈病例數,這為后期進一步提高估算精度指明方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂天地(音樂創作版)(2022年1期)2022-04-26 13:51:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
數學物理學報(2020年2期)2020-06-02 11:29:24
37°女人(2020年5期)2020-05-11 05:58:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
