特征混合增強與多損失融合的顯著性目標檢測
2022-10-16 05:51:18李春標謝林柏彭力
計算機與生活 2022年10期
李春標,謝林柏,彭力
物聯網技術應用教育部工程研究中心(江南大學 物聯網工程學院),江蘇 無錫214122
顯著性目標檢測旨在從輸入圖像上識別出最引人注目的對象。出于降低計算復雜度的目的,顯著性目標檢測已經被廣泛應用于語義分割、圖像檢索、目標識別、場景分類等領域。
圖像顯著性目標的特征包括低層級基本特征與高層級語義特征,低層級基本特征主要包括紋理、顏色、對比度等,高層級特征則揭示目標與背景之間內在的語義信息。許多傳統的顯著性目標檢測方法依賴于手工制作的特征和預定義的先驗知識。這些方法利用圖像的低層級信息以自底向上的方式進行檢測。然而,由于這些先驗信息在復雜的自然場景中往往是不準確的,導致了較差的檢測結果。
最近,基于卷積神經網絡的算法通過利用高層級語義信息,已經取得了更優越的檢測結果。Liu等使用膠囊網絡進行顯著性目標檢測,在模型中加入了部分物體關系,采用雙流策略來實現膠囊網絡,有效降低了噪聲分配的可能性。Kuen等提出了一個循環注意卷積-反卷積網絡,利用空間變壓器和循環網絡單元,實現了顯著圖的逐步細化。Zhang等提出了Amulet 網絡,首先將多層級特征整合到多個分辨率下,然后在每個分辨率下進行特征整合,最后進行顯著性融合獲得最終的顯著圖。Luo等提出了一種非局部深度特征網絡,使用多分辨率網格結構將局部信息與全局信息結合起來進行顯著性目標檢測,并且實現了一個邊緣感知的損失函數。
由于深度學習的快速發展,這一領域已經取得了很大的成功,但是復雜場景下的顯著性目標檢測仍有以下挑戰:(1)一方面由于顯著性是基于圖像全局定義的,算法必須整合全局信息;另一方面,精細的顯著性目標檢測,又要考慮局部、邊緣等細節。當前的顯著性目標檢測方法并不能對這兩方面進行有效的權衡。(2)當前許多顯著性目標檢測方法使用二進制交叉熵(binary cross-entropy,BCE)作為損失函數。但是交叉熵損失函數是像素級的,它不考慮鄰域的像素值,因此不能有效地處理全局信息。這導致了區域一致性差和特征缺失的問題。
為了應對以上挑戰,本文提出了一種特征混合增強與多損失融合的顯著性目標檢測算法。首先設計上下文感知預測模塊(context-aware prediction module,CAPM),它由多組編碼器-解碼器組成,并且為了有效提取全局信息嵌入了空間感知模塊(spatial-aware module,SAM)。然后設計特征混合增強模塊(feature hybrid enhancement module,FHEM),對預測模塊產生的全局特征信息和細節特征信息進行有效的整合,并利用特征聚合模塊(feature aggregation module,FAM)對整合的信息進行特征增強。最后提出了區域增強損失函數(regional augmentation,RA),通過結合二進制交叉熵損失函數和結構化相似度損失函數(structural similarity,SSIM),監督網絡保持前景區域的完整性,增強區域像素一致性。
1 方法概述
本文提出區域增強網絡,包含上下文感知預測模塊和特征混合增強模塊。上下文感知預測模塊能夠有效地提取全局信息和細節信息,獲得初步的顯著性特征圖。特征混合增強模塊可以將解碼器得到的全局信息和細節信息進行充分的篩選提取,最終獲得結構更加完整清晰的顯著圖。此外,網絡中使用的混合損失函數可以引導網絡學習更多前景細節信息,緩解特征缺失和增強區域像素的一致性。
1.1 上下文感知預測模塊
上下文感知預測模塊被設計成U 型結構,U型結構可以有效地獲取低層和高層的信息。對于主干網絡提取的多尺度信息,U 型結構使用自頂向下的方式分為多個層級進行逐級融合。其中逐級融合的方法保證了上采樣恢復出來的特征更精細,能更好地保留低層細節信息,多層級特征的融合保證了可以匯集多尺度信息,能更好地保留高層全局信息。網絡結構圖如圖1 所示。
圖1 中,六對編碼器和解碼器分別被記作和(∈{1,2,3,4,5,6})。
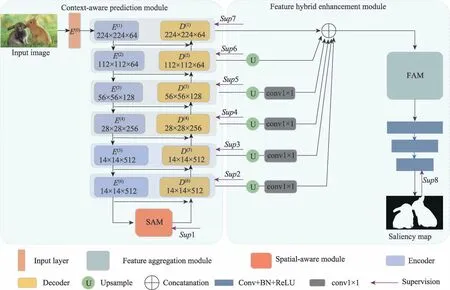
圖1 顯著性目標檢測網絡框架Fig.1 Framework of salient object detection network
采用ResNet-34 作為主干網絡,去除其最后兩個全連接層和最后一個池化層,并對輸入層進行修改。ResNet 模型首先用于圖像分類任務,由于其優異的性能,廣泛應用于各種計算機視覺任務中。由于ResNet 的輸入層使用的卷積核大小為7×7,stride被設置為2,這引入了過多的參數,損失了圖像的細節信息。因此使用64 個大小為3×3 的卷積核重新構造輸入層。在ResNet-34 這4 組卷積塊后進行池化操作pool4,此時特征圖大小為14×14。此外,通過加入兩組卷積塊(、),提高模型容量以充分提取高層級語義信息,這兩組卷積塊由3 個擁有512 個卷積核的普通殘差塊組成。為了提高顯著圖的清晰度,不再使用池化模塊,保持特征圖大小不再變化。
編碼器與解碼器連接處增加一個空間感知模塊以進一步捕獲全局語義信息,見圖2。它包含3 個膨脹率不同的3×3 卷積層和一個1×1 卷積層,在經過這些卷積層后產生4 個大小相同的特征圖,將其拼接,經過批歸一化和ReLU 激活函數后,得到和輸入大小相同的特征圖。
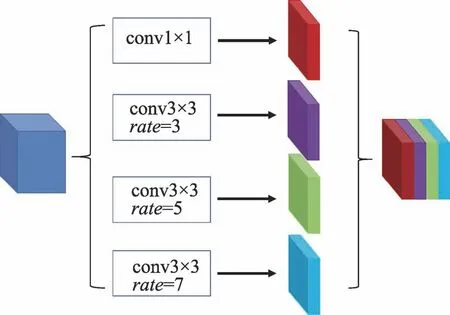
圖2 空間感知模塊Fig.2 Spatial-aware module
預測模塊的解碼器和編碼器幾乎完全對稱,共有6 個解碼器(~)。每個解碼器由3 個卷積塊組成,其中每個卷積塊依次由卷積層、批歸一化層、激活函數層組成。每個解碼器的輸入由前一個階段的解碼器的輸出與對應的編碼器拼接產生。如果特征圖大小不匹配,則對解碼器產生的特征圖進行上采樣,使其大小一致。預測模塊的編碼器與解碼器關系見式(1)。
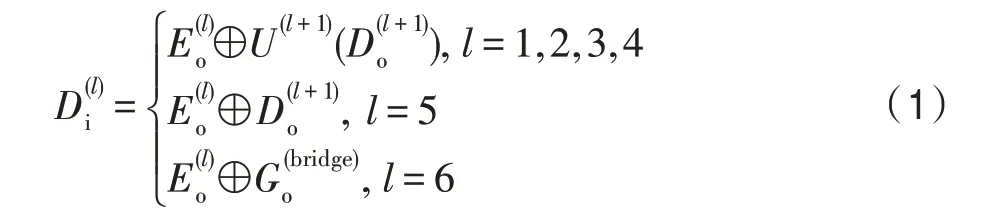
1.2 特征混合增強模塊
為了對預測模塊輸出特征圖的細節信息與全局信息進行充分的挖掘與整合,得到細節清晰、結構完整的顯著圖。在預測模塊的解碼器端引入特征混合增強模塊(FHEM),利用特征聚合模塊(FAM)充分聚合多尺度信息,并對得到的信息進行有效的整合,生成最終的顯著圖。
注意力機制是一種增強深度卷積神經網絡性能的手段,一些研究已經驗證了注意力機制對顯著性目標檢測任務的有效性。但是他們所使用的是通道注意力(channel attention,CA)模塊,激勵函數使用的是全連接神經網絡,這使得模型容易發生過擬合,影響模型的泛化性能,并且為了減少參數量進行了通道降維,這對于特征的深層次融合和細節保留是致命的。最近Wang等提出了高效通道注意力(efficient channel attention,ECA)模塊,使用一維卷積作為激勵函數,極大地緩解了以上問題。因此使用ECA 模塊構建了特征聚合模塊。
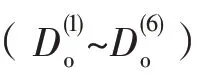
如圖3所示,將展開為[,,…,x],其中x∈R是的第層(-th)特征圖,是通道總數。首先,對每個x使用全局平均池化得到通道級特征向量∈R。之后,使用卷積核大小為的一維卷積來捕獲通道級依賴,的取值見式(2)。
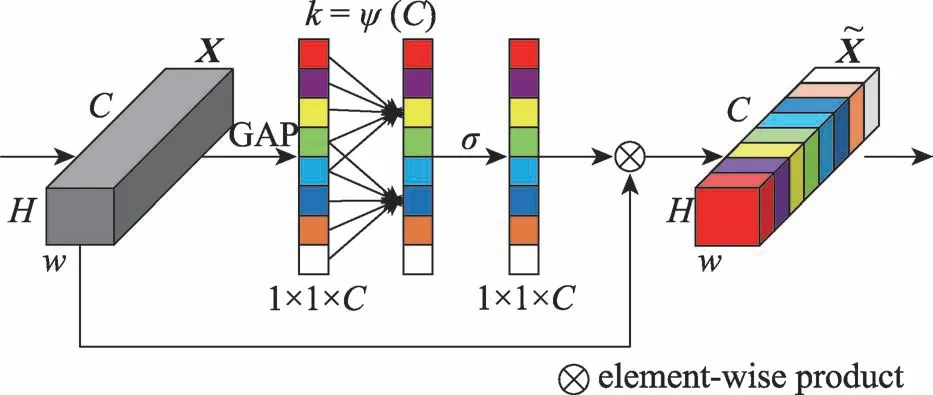
圖3 高效通道注意力模塊Fig.3 Efficient channel attention module

其中,||表示距離最近的奇數,設置和分別為2 和1。通過非線性映射,高維通道具有更大范圍的相互作用,而低維通道具有更小范圍的相互作用。
然后通過使用Sigmoid 運算,對經過編碼的通道級特征向量進行歸一化操作,將其映射到[0,1]。

其中,指的是注意力模塊的參數;指的是一維卷積運算;指的是Sigmoid 運算。
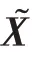

然后對得到的融合增強特征進行3 組卷積操作得到最終的顯著預測圖,卷積核個數分別為256、64、32,每組卷積同樣依次由卷積層、批歸一化層、激活函數層組成。
CA 模塊所使用的激勵函數為全連接網絡。
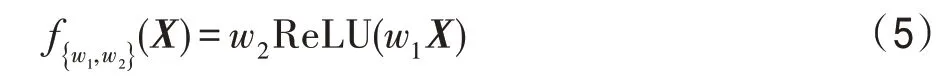
1.3 損失函數
整體損失函數被定義為:

其中,?指的是第層的輸出,指的是總輸出的個數,α指的是每個損失的權值,全部設置為1。該模型有8 個輸出,即=8,包括7 個預測模塊輸出和1 個增強模塊輸出。
定義?為混合損失:
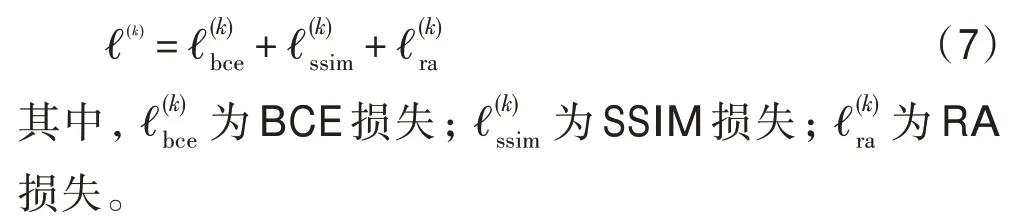
BCE 損失是二值分類和分割中使用最廣泛的損失:
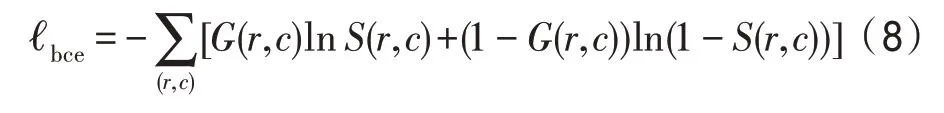
其中,(,)∈{0,1}是像素(,) 真實圖中的像素值,(,)∈[0,1]是顯著性目標像素的預測概率。
SSIM 損失起初是針對圖像質量評價提出的方法,它可以捕捉到圖像的結構信息,因此現在已經被整合到訓練損失中去學習圖像真實圖中的結構信息。
定義={x:=1,2,…,},={y:=1,2,…,}分別為顯著性預測圖和二進制真實圖裁剪出的大小為×的圖片的像素值。
SSIM 損失被定義為:
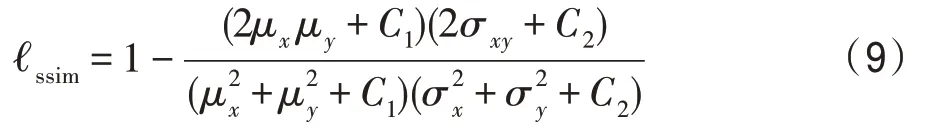
其中,μ、μ和σ、σ分別是、的均值和標準差,σ是它們的協方差,為了防止分母為0,設置=0.01和=0.03。
BCE 損失函數是像素級的損失函數,不考慮鄰域的像素值,對所有像素的權重相等,有助于在所有像素上收斂,但是容易導致特征缺失和區域一致性差的問題。IOU 損失函數是區域級的損失函數,考慮的是各個區域的像素值,因此可以增強各個區域的像素一致性,但是IOU 損失函數對前景和背景區域的權重相同,同樣容易導致特征缺失問題。因此,為了增強區域內像素的一致性,緩解特征缺失,基于IOU 損失函數,本文提出一種新的損失函數——區域增強損失(RA):
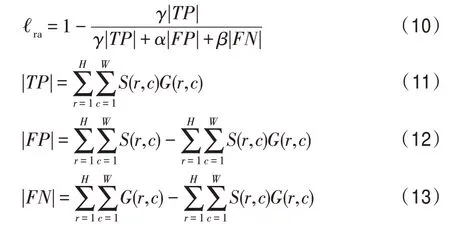
其中,||、||、||分別表示真陽性、假陽性和假陰性區域像素值的和,、和分別用于控制||、||和||的懲罰程度,+=1。(,)∈{0,1}是像素值(,)的真實圖標簽,(,)∈[0,1]是顯著性目標的預測概率。當===1,該損失退化為IOU 損失。通過增大,調整大于,RA 損失函數可以控制不同區域的懲罰程度,減少顯著圖的前景缺失。
2 實驗與分析
2.1 數據集
為了評估本文算法的有效性,在5 個數據集ECSSD、DUT-OMRON、HKU-IS、DUTS、SOD 上評估了本文的算法。ECSSD 包含1 000 張有著不同尺寸目標的復雜圖片。DUT-OMRON 是一個包含5 168張圖片的有挑戰性的數據集,每張圖片中有一個或兩個對象,大多數前景對象在結構上很復雜。HKUIS 包含4 447 張圖片,每張圖片包含多個顯著性物體,這些物體的色彩對比度低且與圖像邊界存在重疊現象。DUTS 是目前最大的顯著性檢測基準數據集,它包含10 553 張訓練圖片(DUTS-TR)和5 019 張測試圖片(DUTS-TE)。SOD 包含300 張圖片,最初用于分割領域,這些圖片大多數包含多個顯著性對象。
2.2 實現細節
本文選擇Pytorch0.4.0 深度學習框架來實現顯著性目標檢測網絡。全部輸入圖片的大小被調整為256×256,然后隨機裁剪為224×224。為了提高模型的泛化性能,使用的數據增強手段有:隨機裁剪、水平翻轉。使用ResNet-34 初始化部分網絡參數,其余參數使用Xavier 方法初始化。使用Adam 優化器來訓練網絡,超參數設置使用默認值,其中批次大小為16,學習率為0.001,為0.9,為0.999,正則化系數為0。在不使用驗證集的情況下訓練網絡,訓練損失函數在500 次迭代后收斂。在測試過程中,輸入圖像的大小將調整為256 × 256 獲得其顯著圖。然后,將其調整為輸入的原始大小輸出。訓練該網絡使用的設備為E5-2678v3 和NVIDIA GTX 1080Ti GPU×4。
2.3 評價指標
本文使用三種最常用的指標來評價本文算法:準確率-召回率曲線(precision-recall curve,PR)、MAE(mean absolute error)、F-measure(F)。
準確率-召回率曲線:首先二值化固定閾值的灰度預測圖,然后生成的二值圖和真實圖用于計算準確率和召回率,準確率與召回率計算方式為:

其中,、和分別代表真陽性、假陽性和假陰性。準確率-召回率曲線通過一組成對的準確率、召回率按照閾值從0~255 繪制生成,準確率-召回率曲線與坐標軸圍成的面積越大,性能越好。
F-measure:F由準確率和召回率加權平均生成。
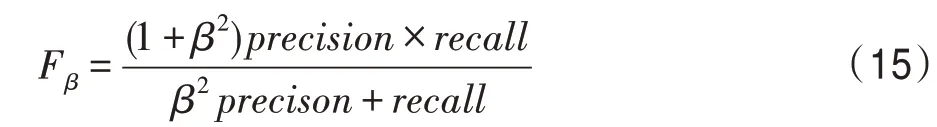
為了強調準確率的重要性,其中通常被設置為0.3。
MAE:計算歸一化的顯著圖和真實圖之間的平均絕對誤差。
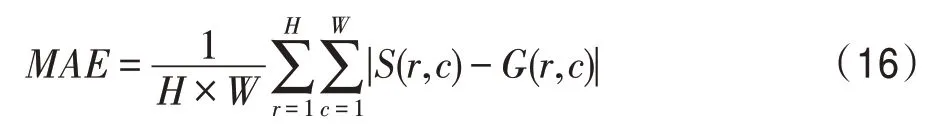
其中,和分別指的是顯著圖和對應的真實圖,和分別表示顯著圖的高和寬,(,)指的是對應的像素值。
2.4 消融實驗
本節逐步分解所提出的方法來揭示每個組件對顯著圖的貢獻。本節所有實驗均在DUT-OMRON 數據集上進行。
為了驗證本文提出的區域增強網絡的有效性,本文進行了相關的結構消融實驗,表1 列出了基線網絡U-Net、預測模塊和增強模塊的定量比較結果。如表1 所示,本文提出的預測模塊在max F(數值越大越好)和MAE(數值越小越好)這兩個指標上分別比基線網絡提升0.042、0.021。本文提出的區域增強網絡,在max F和MAE 這兩個指標上與預測模塊相比分別提升了0.019、0.011。為了展現添加不同模塊產生的實際效果,本文進行了更精細的視覺比較。如圖4 所示,未加入SAM 模塊的預測模塊產生的顯著圖部分與整體存在割裂,加入了SAM 的預測模塊能夠初步進行空間上下文整合,但是仍然存在特征缺失,當加入增強模塊對預測模塊產生的特征圖進行增強后,整個顯著圖變得完整。此外,實驗過程中嘗試使用CA 模塊搭建增強模塊,沒有成功。如表1所示,ECA 模塊在使用較少參數量的情況下取得的結果優于CA 模塊。
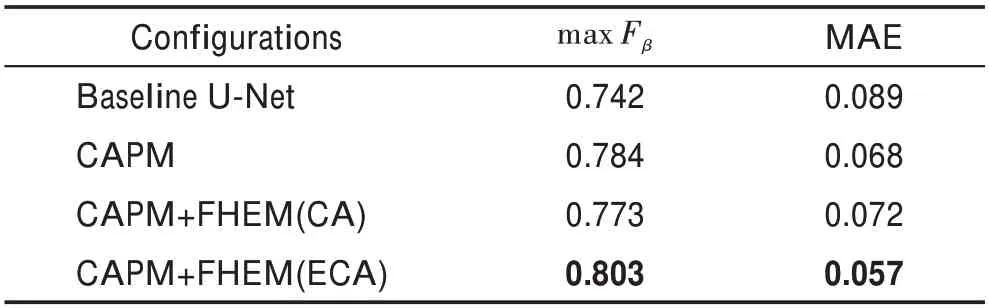
表1 算法使用不同模塊性能比較Table 1 Performance comparison of different modules in algorithm
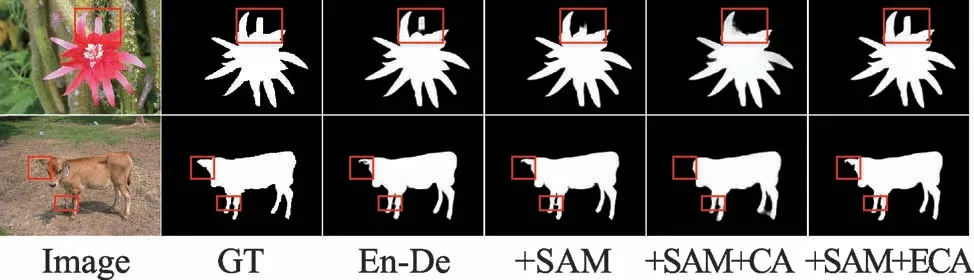
圖4 不同模塊顯著性檢測結果比較Fig.4 Comparison of saliency detection results of different modules
為了證明混合損失的有效性,基于區域增強網絡,對不同的損失進行了消融實驗。表2 中的結果表明,使用混合損失?的網絡在max F和MAE 這兩個指標上與使用?損失相比分別提升了0.014、0.012。如圖5 所示,與使用?損失相比,使用?損失有助于約束前景和背景的像素值,產生的顯著圖不易出現大面積的模糊現象。相比使用?損失,使用?損失產生的顯著圖更完整,區域一致性更好。
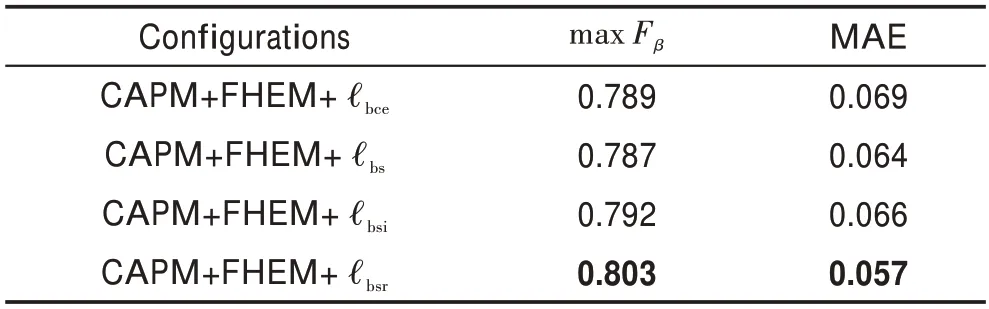
表2 算法使用不同損失的性能比較Table 2 Performance comparison of different losses in algorithm
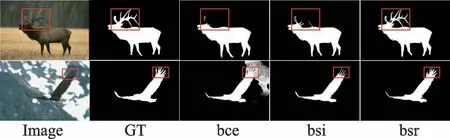
圖5 不同損失顯著性檢測結果比較Fig.5 Comparison of saliency detection results of different losses
為了確定RA 損失的最佳參數選擇,基于區域增強網絡,采用不同的系數進行了實驗。如表3 所示,當=0.3,=0.7,=2.0 時,max F與MAE 取得優值,相較于IOU 損失(=1.0,=1.0,=1.0)分別提升1.1%、0.9%。
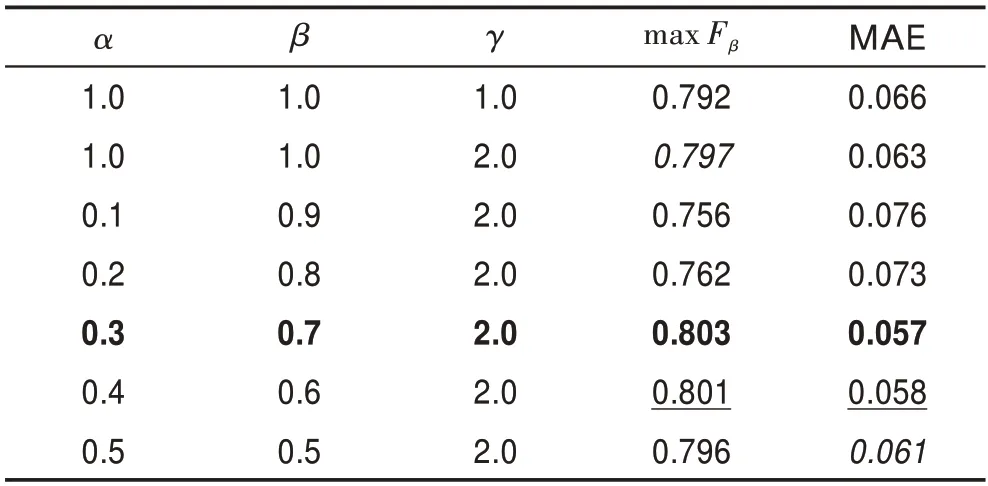
表3 算法使用不同系數RA 損失的性能比較Table 3 Performance comparison of RA loss with different coefficients in algorithm
2.5 性能比較
實驗過程中與其他9 種先進算法CapsNet、RAS、Amulet、NLDF、UCF、RFCN、ELD、DCL、LEGS進行比較。為了體現公平性,評測結果來自原始論文或者原作者提供的顯著圖。
圖6 為本文算法與其他顯著性目標檢測算法在PR 曲線與F-measure 曲線上的比較結果。表4 列出了本文算法與其他9 種先進算法的max F和MAE 性能指標比較結果。
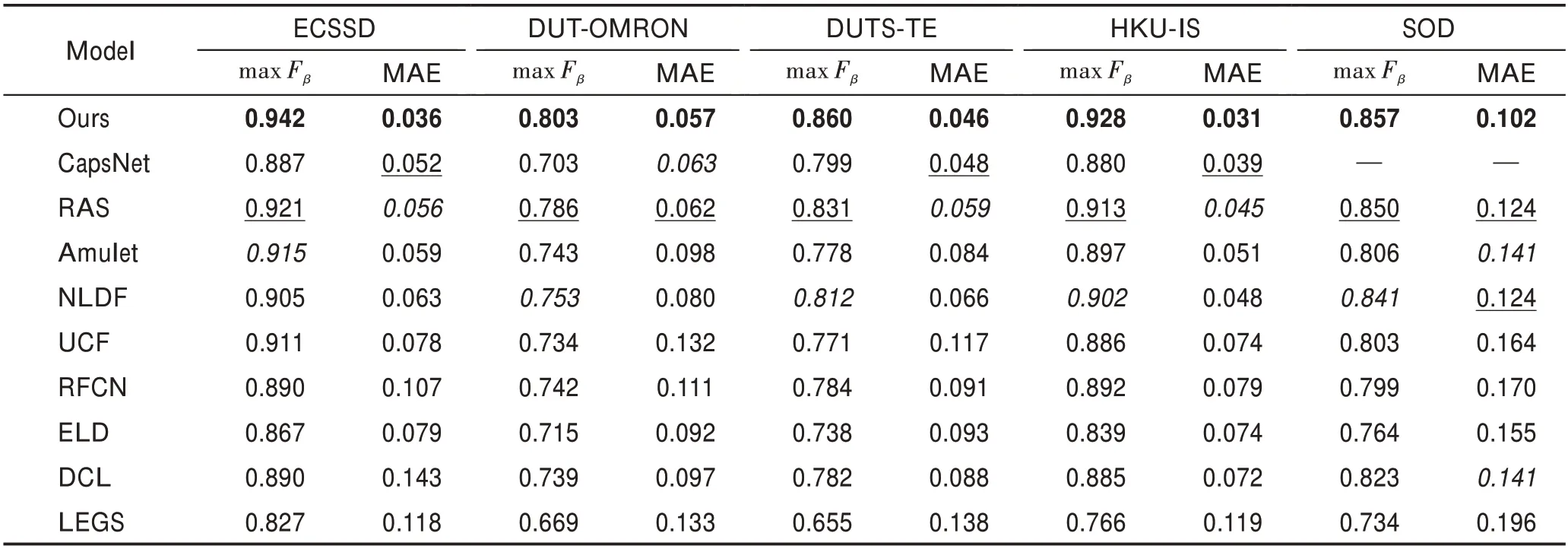
表4 在5 個數據集上不同算法性能比較Table 4 Performance comparison of different algorithms on 5 datasets
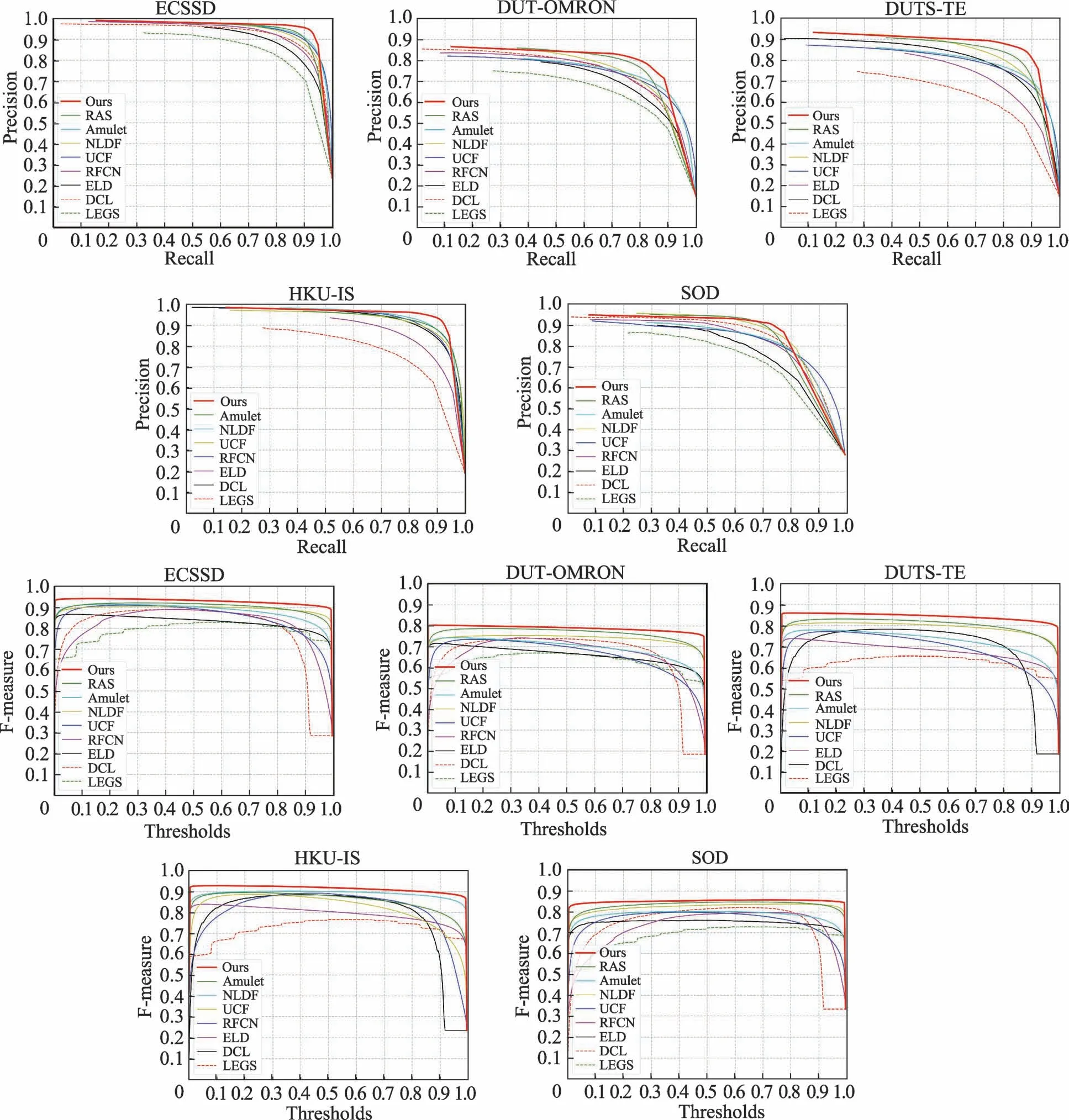
圖6 不同算法的PR 曲線與F-measure曲線比較Fig.6 Comparison of PR curves and F-measure curves of different algorithms
從結果可以看出,本文算法顯著優于其他算法。具體的,對于評價指標max F,本文算法比CapsNet、RAS 和Amulet 在5 個數據集上平均分別提高了0.066 0、0.017 8、0.050 2。對于評價指標MAE,本文算法比CapsNet、RAS 和Amulet 在5 個數據集上平均分別降低了0.008 0、0.014 8、0.032 2。
顯著性目標檢測的研究來源于對人類視覺系統的模擬,檢測結果的優劣依賴于視覺觀感。因此為了進一步闡述本文算法的優越性,圖7 展示了本文算法與5 種先進算法的定性比較結果。
圖7 第一行具有小目標的自然圖像檢測結果顯示,本文算法能夠完整地分割出圖像中的小目標,并且相比其他算法背景的像素更一致;第二、三行具有大目標的圖像檢測結果顯示本文算法能更加完備地檢測出航母艦島和城堡頂部的細節;第四行低對比度圖像檢測結果顯示本文算法能夠更好地整合圖像全局信息,不會漏檢顯著性物體;第五行具有復雜邊緣的圖像檢測結果顯示本文算法能夠更好地提取圖像細節信息,產生的顯著圖邊緣細節更豐富;第六、七行具有多目標粘連的圖像檢測結果顯示本文算法能夠更好地凸出前景和增強區域一致性。

圖7 不同算法的顯著性目標檢測結果對比Fig.7 Comparison of saliency detection results of different algorithms
綜合來看,本文算法能夠充分凸顯前景并且抑制背景。通過本文算法可以保持前景的區域像素一致,其內部不會有較大的灰色區域,與顯著性物體相似的背景被充分抑制,顯著性物體的邊緣不會出現大量的模糊現象。
3 結論
本文針對顯著性目標檢測中的特征缺失和區域一致性差的問題,基于全卷積神經網絡提出一種特征混合增強與多損失融合的顯著性目標檢測算法。通過使用編碼器-解碼器網絡初步捕獲高層全局信息和低層細節信息,然后使用空間感知模塊進一步捕獲全局語義信息,最后使用特征混合增強模塊將預測模塊提取的特征信息做增強處理。同時提出了區域增強損失函數,通過結合二進制交叉熵損失函數和結構化相似度損失函數,以多損失融合的方式監督網絡保持前景區域的完整性以及增強區域像素一致性。與其他的基于深度學習的顯著性目標檢測算法相比,顯著目標的邊界細節、前景完整度和區域一致性有明顯的改善,各項指標有較大的提升。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
