改進雙分支膠囊網絡的高光譜圖像分類
2022-10-16 05:51:22張海濤柴思敏
計算機與生活 2022年10期
張海濤,柴思敏
遼寧工程技術大學 軟件學院,遼寧 葫蘆島125105
高光譜遙感有效結合了成像技術和光譜技術,并成為一種流行的多維信息采集技術。和傳統遙感影像、自然圖像相比,高光譜圖像(hyperspectral image,HSI)憑借更加豐富的光譜和空間信息來描述目標表面。它通常由大量的光譜通道構成,并且被廣泛應用在礦物勘探、土壤測試和環境監測等領域。高光譜圖像分類旨在根據其空間-光譜信息自動將特定的語義標簽分配給每個像素。正是因為HSI比多光譜圖像能夠提供更多細節信息和光譜信息,所以更適合實現分類任務。盡管如此,由于HSI具有更高的結構復雜度,其質量受天氣、光照等因素影響,以及標記訓練樣本消耗大量時間并需要足夠的先驗知識,高光譜圖像分類任務仍然面臨極大的挑戰。
考慮到以上問題,研究者已經提出了許多新的方法來對高光譜圖像分類,包括基于光譜和基于光譜-空間的方法。先前,有傳統監督機器學習的支持向量機(support vector machine,SVM)、隨機森林(random forest,RF)、稀疏表示分類器和均值聚類算法(-means clustering,-means)的基于光譜信息的提取方法來對高光譜數據集分類,但這些方法存在可用標簽數據量過小以及對重要特征提取不充分的問題。
為了更加充分地提取圖像中的光譜空間聯合特征,研究者將深度學習技術應用到HSI 分類任務中。因為深度神經網絡由較多的網絡層構成,所以它擁有從低層到高層的強大特征提取能力,一定程度上解決了傳統機器學習方法提取特征不夠充分的問題。Chen等首次提出用于HSI 分類的深度學習方法,隨后提出基于深度信念網絡的方法進行高光譜數據分析。
1 網絡模型
1.1 相關卷積神經網絡方法
深度卷積神經網絡(convolutional neural networks,CNN)作為最具代表性的深度學習方法,被廣泛應用于提取HSI 的光譜空間聯合特征,主要包含3D CNN直接作用于HSI 和使用1D CNN 與2D CNN 分別提取光譜信息和空間信息兩種方式。Makantasis等使用CNN 對高光譜輸入圖像樣本點的光譜和空間信息進行編碼,最終使用多層感知機對其分類。CNN能夠得到良好的表現,很大程度上歸因于3D CNN能夠更加充分地提取高光譜數據中的光譜-空間信息。然而由于HSI 的結構復雜性,基于3D 卷積的方法極其依賴復雜的網絡結構,為模型的訓練帶來不可避免的壓力。針對維度災難現象,佘海龍等將HSI進行降維后使用優化的3D CNN 對其分類,降低了網絡的計算復雜度。復雜的數據往往包含著大量多尺度的信息,為有效利用這些信息并應用于HSI 領域,一些基于多尺度的并行多分支卷積神經網絡被提出。Xu等提出一個新穎的CNN 算法處理多源遙感圖像數據,用一個空間光譜特征提取器和一個空間提取器分別提取輸入圖像的信息,最終將多尺度特征融合得到分類結果。此外,與并行卷積不同,小規模樣本下的空-譜卷積稠密網絡算法(spectralspatial convolutional dense network,SSCDenseNet)采取空譜分離卷積的方式,將光譜一維卷積與空間二維卷積串聯來提取光譜-空間信息。這種提取多尺度特征來優化分類性能的方法取得了成功。然而,這種出色的處理特征方式仍然沒有從基礎架構上解決CNN 本身所存在的問題。一方面,由于卷積的參數共享和池化層的局部效應,CNN 具有平移不變性,這意味著在預測過程中,當同一實體發生位置、方向等變化,對原實體表現活躍的神經元將不會被激活。另一方面,池化層導致空間信息被大量破壞。雖然數據增強可以緩解上述問題,但大量的高光譜圖像數據對模型帶來更大的訓練壓力。顯然,在多分支卷積神經網絡的機制下,訓練過程將為大樣本數據集付出更高的代價。
針對之前所述的問題,一個新的網絡結構被Sabour等提出,即膠囊神經網絡(capsule neural network,CapsNet)。其主要貢獻是取代了CNN 的池化層,進而保留了輸入數據的空間信息,并且在MNIST數據集的測試錯誤率僅為0.25%。Jiang等結合多尺度提取特征與膠囊網絡結構,提出一個雙通道膠囊神經網絡(dual-channel capsule networks,DCCaps-Net)用于HSI 分類。隨后結合CapsNet 與MRF(Markov random field)提出Caps-MRF 方法。但由于膠囊網絡在實際訓練時動態路由產生大量參數,導致訓練時間過于緩慢。
1.2 本文提出的方法
基于此,本文提出1D 與2D 約束窗口(1D-Conv-Caps、2D-ConvCaps)來降低膠囊網絡的參數量,并分別用1D 卷積核與2D 卷積核來提取HSI 的光譜信息與空間信息且結合MRF 來計算細分標簽形成新的架構DuB-ConvCapsNet-MRF。對比兩個公開的HSI數據集的分類性能和評價指標并進行相應的消融實驗,所提出方法優于一些傳統方法和主流的深度學習方法,且參數優化效果在提取特征數較小的情況下更加明顯。
本文提出的網絡架構如圖1 所示。該架構使用兩條分支分別提取HSI 的空間信息和光譜信息。提取信息的方式為經典的膠囊神經網絡CapsNet。為防止數據集過大,實驗中為兩條分支做了相應的預處理。使用所提出的1D-ConvCaps、2D-ConvCaps 以及對應的1D 與2D 約束窗口得到更少的膠囊數來降低動態路由過程中的訓練壓力。最終通過級聯MRF來計算細分標簽。
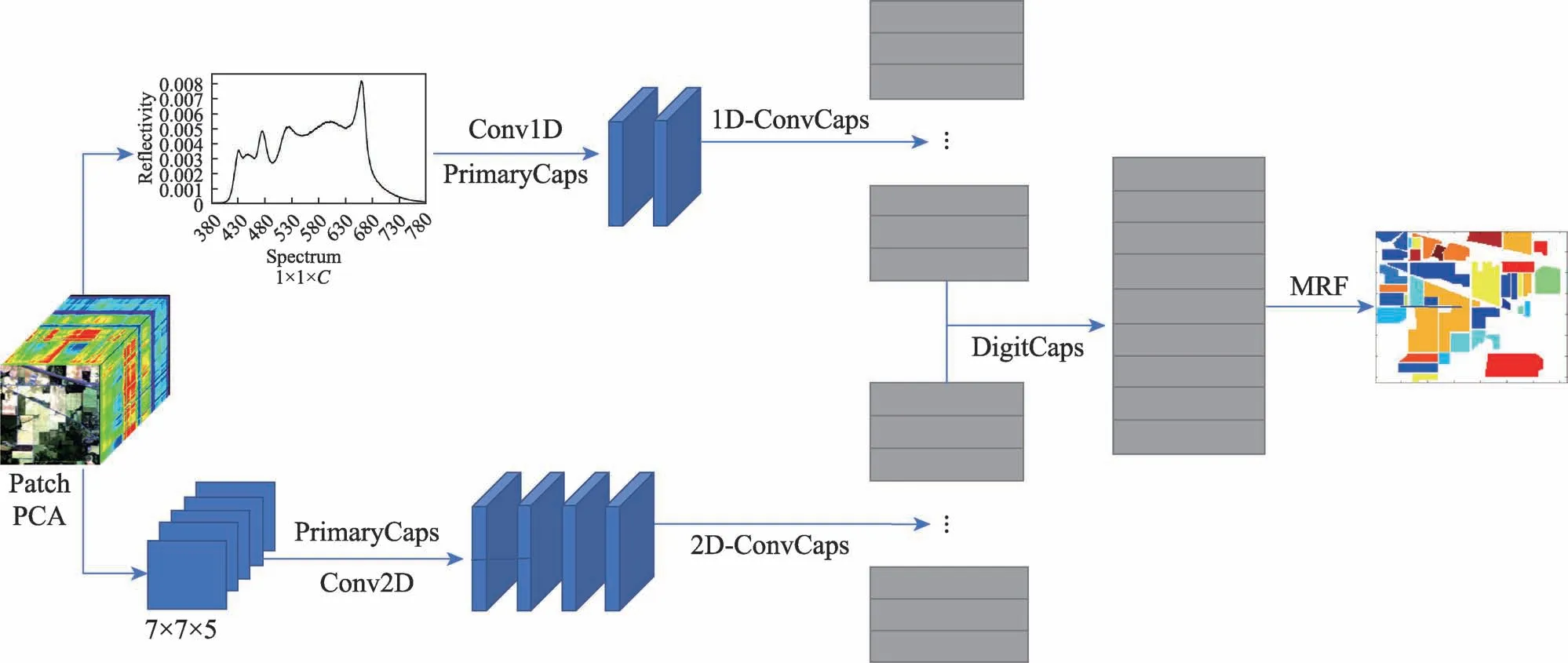
圖1 DuB-ConvCapsNet-MRF 網絡架構Fig.1 Network architecture of DuB-ConvCapsNet-MRF
2 所使用方法
2.1 膠囊神經網絡
capsule 的輸入輸出向量表示特定實體類型的實例化參數,向量的方向代表實體的某些屬性,向量的長度代表實體存在的概率。同一層的capsule 通過某變換矩陣對下一層的capsule 的實例化參數進行預測。此外,對預測有關鍵作用的動態路由會使該層的多個預測一致,下一層的capsule 將變得活躍。為了實現將向量的長度壓縮為0 到1 之間的概率值,進而保證capsule 層級的激活功能的完成,通常使用一個被稱為squashing 的非線性函數:

其中,v為capsule的輸出向量,s為上一層所有capsule 輸出到當前層的向量加權和,即capsule的輸入向量。該非線性函數既保留了向量的原始方向,即保持實例化參數的屬性不變,又將向量的長度壓縮到[0,1)區間內。輸入向量的計算分為兩個過程,即線性組合和Routing,可以表示為:


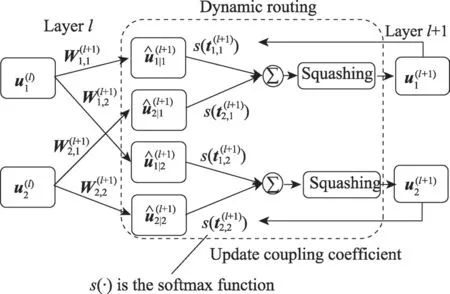
圖2 動態路由的執行過程Fig.2 Execution process of dynamic routing

2.2 預處理
以高光譜圖像立方體整體作為特征提取器的輸入的做法會為網絡帶來大量的參數進而導致過擬合,同時為訓練過程帶來極大的代價。為提出一個輕量級的高光譜圖像分類方法,實驗中對輸入數據進行了預處理。如圖1,記原始HSI 數據塊為∈R,其包含個大小為×的基于不同光譜的圖像,其中第行、第列的像素記為x。一方面,首先網絡中空間特征提取分支不需要關注圖像的光譜信息,故利用PCA 對數據塊進行降維處理,具體降維得到5 個通道數據,不僅降低了輸入數據的維數,而且避免了光譜特征的冗余。其次提取某一像素x周圍大小為7×7×5 的數據塊(patch),作為空間特征提取器的輸入。另一方面,提取同一像素x處大小為1×1×的光譜張量,這個1D 向量會被用來提取該像素處豐富的光譜信息。
2.3 2D-ConvCaps
為了減輕膠囊神經網絡的訓練壓力,提出了該自定義網絡層。CapsNet 使用動態路由來代替傳統卷積神經網絡的全連接層,這為網絡帶來了強大的解釋能力的同時,由于其本身屬于全連接層以及復雜的向量運算,為訓練過程帶來大量的參數和高額的運行時間成本。因此,降低網絡的參數量的關鍵在于降低全連接層的壓力,即在向量長度一定的情況下,減少該層輸入的向量的個數。針對以上問題,提出了2D 約束窗口,它在能夠適應所提出的新型網絡結構的前提下,運用一個局部信息提取的策略來減少輸入向量的數量,進而減少全連接層在動態路由過程中的壓力。2D-ConvCaps的結構如圖3。該結構接受一切封裝成向量數組的特征圖作為輸入,不僅可用于圖1 中2D 膠囊網絡分支的PrimaryCaps 層與DigitCaps 層的中間,也可用于任何被重構為×××大小的特征圖,其中為一個膠囊的長度,為膠囊向量組的個數,×為一個膠囊數組中向量的個數。
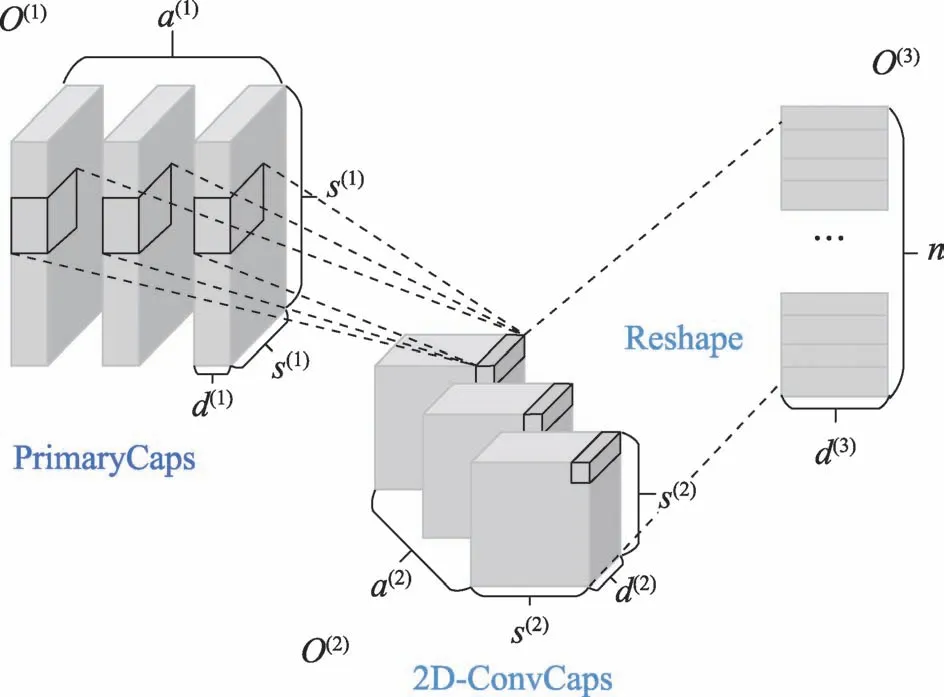
圖3 所提出的降低參數方法2D-ConvCapsFig.3 Proposed parameter reduction method,2D-ConvCaps


2.4 1D-ConvCaps
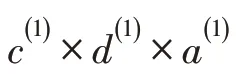
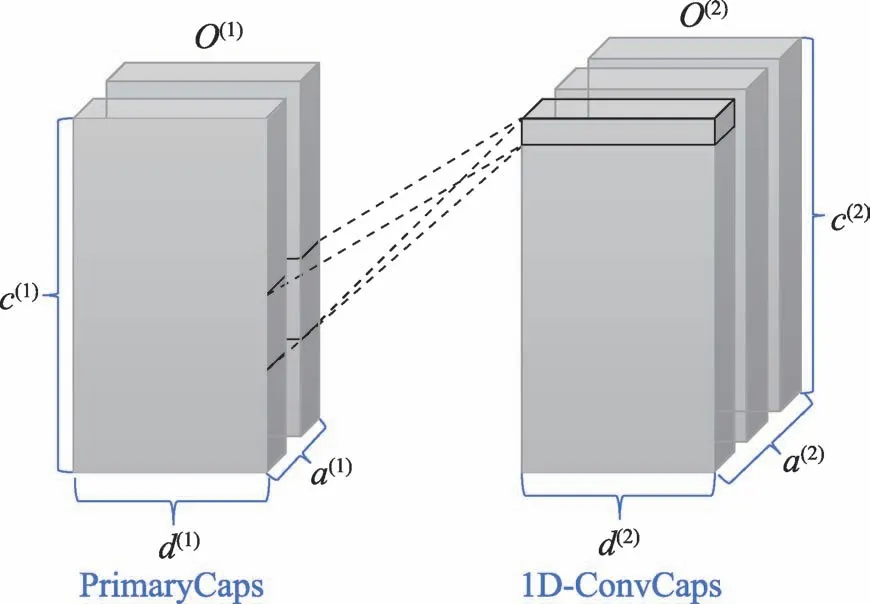
圖4 所提出的降低參數方法1D-ConvCapsFig.4 Proposed parameter reduction method,1D-ConvCaps

2.5 馬爾可夫隨機場
馬爾可夫隨機場(MRF)是具有無向圖描述的馬爾可夫性質的隨機變量集合,也是無向圖的概率表示。在計算機視覺任務中,它能夠解決標識標簽的問題,具有強大的空間約束性和更少參數量,因此MRF 更適合應用在HSI 分類任務中。此外,MRF 是事件的集合,在這個集合中任意一個事件的當前狀態只與它之前幾個狀態有關,而與其他狀態無關。對于高光譜圖像分類,圖像中每個像素的標簽僅與其所在鄰域標簽有關,與其他位置標簽無關。以上關系如式(6):
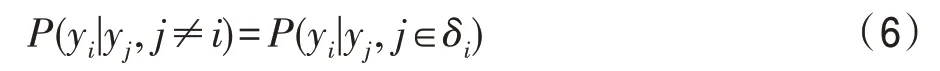
其中,y和y分別代表第個像素和第個像素所對應的標簽,δ代表第個像素鄰域的所有像素集合。MRF 對應一個無向圖,無向圖的節點代表任意一個HSI 像素,邊由像素與像素之間的相鄰關系決定。MRF 在本質上反映了哪些像素間有依賴關系需要被考慮。
2.6 損失函數
與卷積神經網絡不同,由于膠囊網絡輸出的概率值無法實現歸一,允許多個分類同時存在,所提出網絡無法直接使用傳統的多分類損失函數。在CapsNet中表現良好的margin loss定義如式(7):
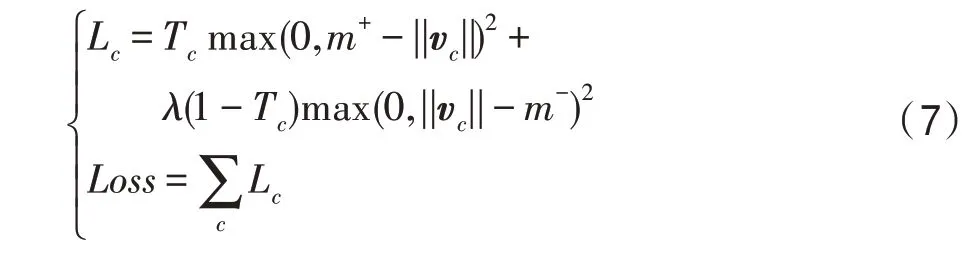
其中,T是分類的指示函數(當分類存在即為1,否則為0),||v||是輸出向量的模長,是上懲罰因子,懲罰未預測到存在的分類的情況,即對||v||大于的正確預測記為損失0;是下懲罰因子,懲罰預測到不存在的分類的情況,即對||v||小于的錯誤預測記為損失0;是比例系數,調節兩種情況的比重;Loss為所有分類對應的L的總和。
3 實驗與分析
3.1 實驗環境及數據準備
實驗主要基于python3.7.1 和keras2.2.4,在帶有CPU 型號為IntelCorei5-9300H 的Windows 10 操作系統上,為使反向傳播過程中的損失函數快速達到收斂效果,使用型號為NVIDIA GTX 1650 的圖形處理器(GPU)在系統內存為16 GB 環境下加速訓練過程。所采用的數據集為兩個經典高光譜圖像數據集,分別為IP(Indian Pines)數據集和UP(University of Pavia)數據集。IP 數據集包含145×145 個像素、200 個光譜帶以及20 m 的空間分辨率,由AVIRIS 傳感器在印第安納州拍攝,產生的波長范圍為400 nm到2 500 nm。如圖5 所示,其提供16 個互斥的真實標簽類,如街道、農田等數據。UP 數據集包含610 ×340 個像素和103 個光譜帶以及1.3 m 的空間分辨率,由ROSIS 在意大利北部的帕維亞大學拍攝,產生的波長范圍為0.43 μm 到0.86 μm。如圖6 所示,其提供9 個互斥的真實標簽類。
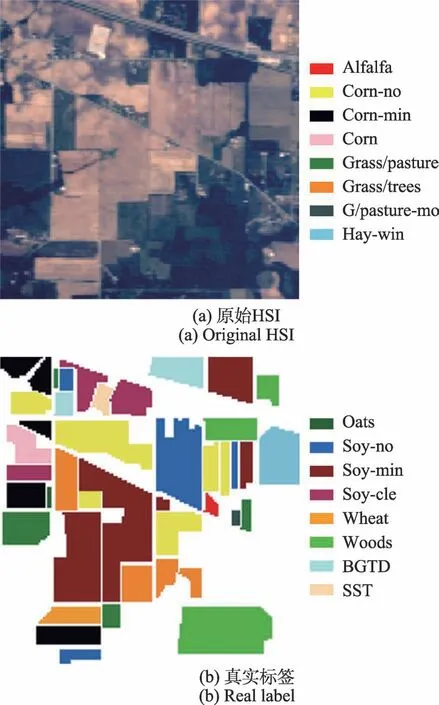
圖5 Indian Pines數據集Fig.5 Indian Pines datasets
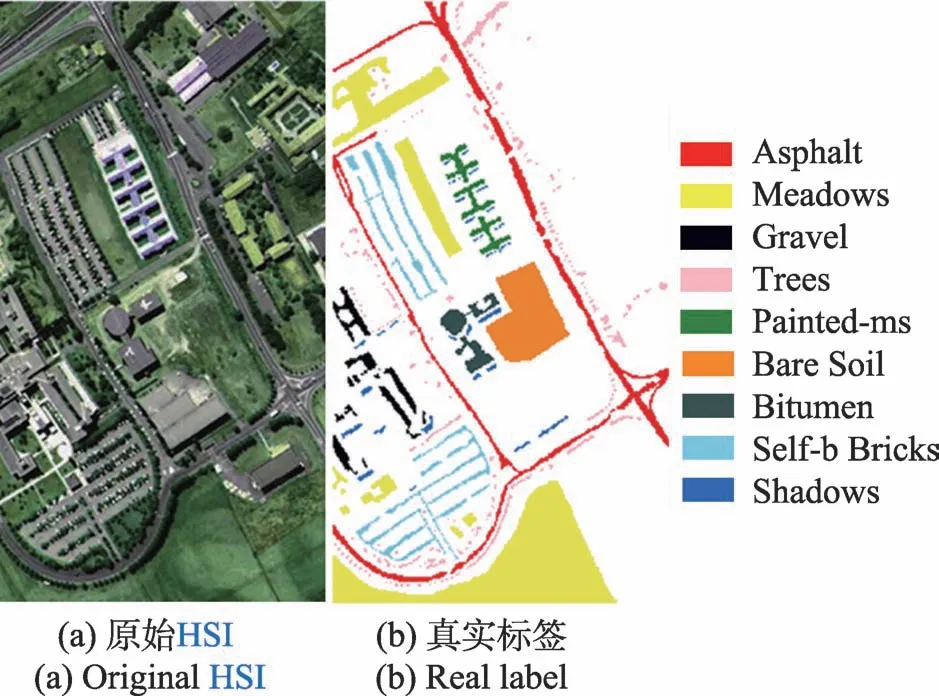
圖6 University of Pavia 數據集Fig.6 University of Pavia datasets
選用兩個標準高光譜數據集(Indian Pines 和University of Pavia)來驗證所提出網絡的分類性能,以下是選擇這兩個數據集的幾個重要原因:
(1)圖像信息覆蓋了多個不同性質的區域,為分類提供了更多的訓練和測試數據。
(2)二者的空間分辨率具有一定的差異,方便對模型的泛化性進行更嚴格的驗證。
(3)二者包含的光譜波段數不相同。
(4)兩個數據集圖像中不同類地物的樣本數量分布復雜,且不相同。
3.2 參數設置
為避免在實驗中訓練模型時發生梯度爆炸,在網絡層中增加批歸一化層和dropout層。此外批歸一化還能加大探索步長,加快收斂速度,破壞原來的數據分布并在一定程度上防止過擬合。同樣地,在每個訓練批次中,使用dropout 的層忽略一部分的特征檢測器,減少特征檢測器間的相互作用,可一定程度上防止過擬合。訓練所有方法的超參數均如表1所示。
用于訓練所提出的DuB-ConvCapsNet-MRF 的超參數見表1,指明了所使用的訓練優化器及初始學習率大小、學習衰減率、Dropout 系數、損失函數參數以及主成分分析(principal components analysis,PCA)降維保留的通道數。為分析PCA 降維對有效信息完整性影響,在Indian Pines 數據集上對不同降維程度進行測試。實際PCA 降維所保留的通道數對分類性能的影響如圖7。可以看出降維后保留5 個波段信息時的分類性能總體更優。
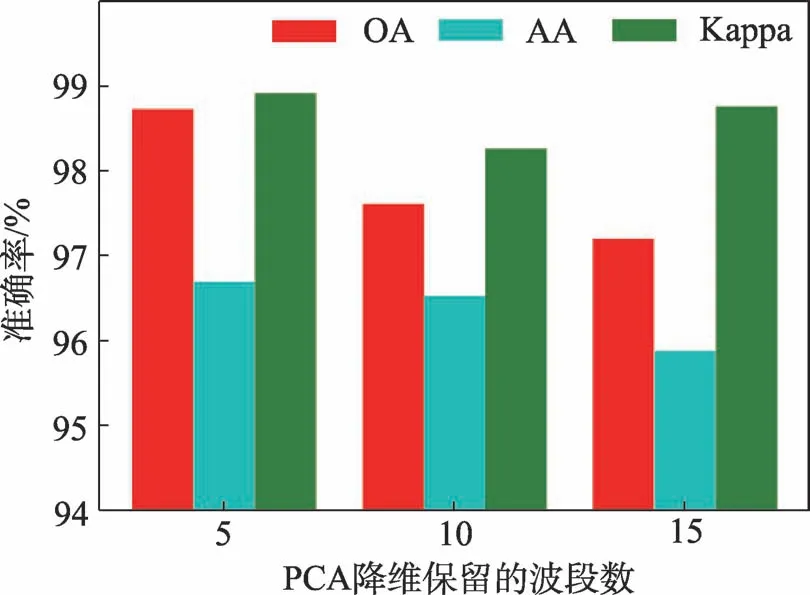
圖7 PCA 降維保留的通道數對分類性能的影響Fig.7 Impact of the number of channels reserved by PCA on classification performance
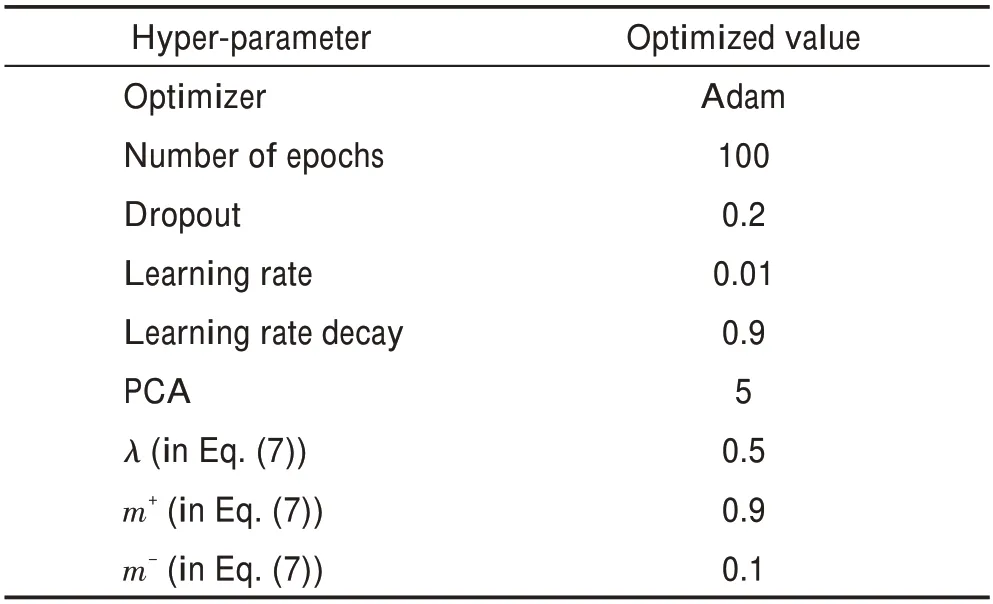
表1 用于訓練所提出的DuB-ConvCapsNet-MRF的超參數Table 1 Hyper-parameters used for training proposed DuB-ConvCapsNet-MRF
3.3 實驗結果與分析
為保證分類的準確性,將采樣得到的20%獲得標簽的像素作為訓練集,10%獲得標簽的像素作為驗證集,70%作為測試集。實驗也對數據集中每一類別數據的訓練集所占比率對分類性能的影響進行比較。此外,為得出降參優化效果與所提出約束窗口提取的特征通道數間的關系,以所提出結構較復雜的2D-ConvCaps 所包含的參數量為評價指標進行分析。
實驗對一些相關主流的算法進行測試評估并進行對比,包括SVM、2D-CNN、3D-CNN、DCDCNN、CNN-MRF、Caps-MRF。
采用總體分類精度(overall accuracy,OA)、平均分類精度(average accuracy,AA)和Kappa 系數對高光譜分類準確性進行評估。其中,OA 代表正確分類的像素個數與所有類別總像素個數的比率;AA 代表計算每個類別分類準確率后得到的平均準確度;Kappa 系數用來衡量模型預測結果與實際標簽的一致性,其取值范圍為[-1,1],通常大于0。所有評估結果越接近1,表明模型的分類性能越高。
相關的方法在IP 數據集上的分類準確率、OA、AA、Kappa 系數結果如表2 所示。從表2 可看出,基于機器學習的SVM 在評估準確率方面表現最差,但所需時間最少。所提出方法在OA 精度上比未級聯MRF的2D-CNN和DCD-CNN分別高出3.79%、0.38%,比3D-CNN 僅高出0.29%,但由于3D 卷積核帶來的參數過多,導致其所需訓練時間最高,訓練代價最大。同樣級聯了MRF 的方法中,所提出方法在OA精度上比CNN-MRF 和Caps-MRF 分別高出1.64%、0.21%,且在所需訓練時間上比Caps-MRF 減少了38.77%,在各方面精度和訓練代價上都優于其他方法。為判斷所使用的MRF 后處理方法、所提出的降參優化方法和PCA 降維的有效性,進行針對這些單元的消融實驗得到的分類準確性見表3,可看出結合了所有單元的方法得到的分類準確率更高。
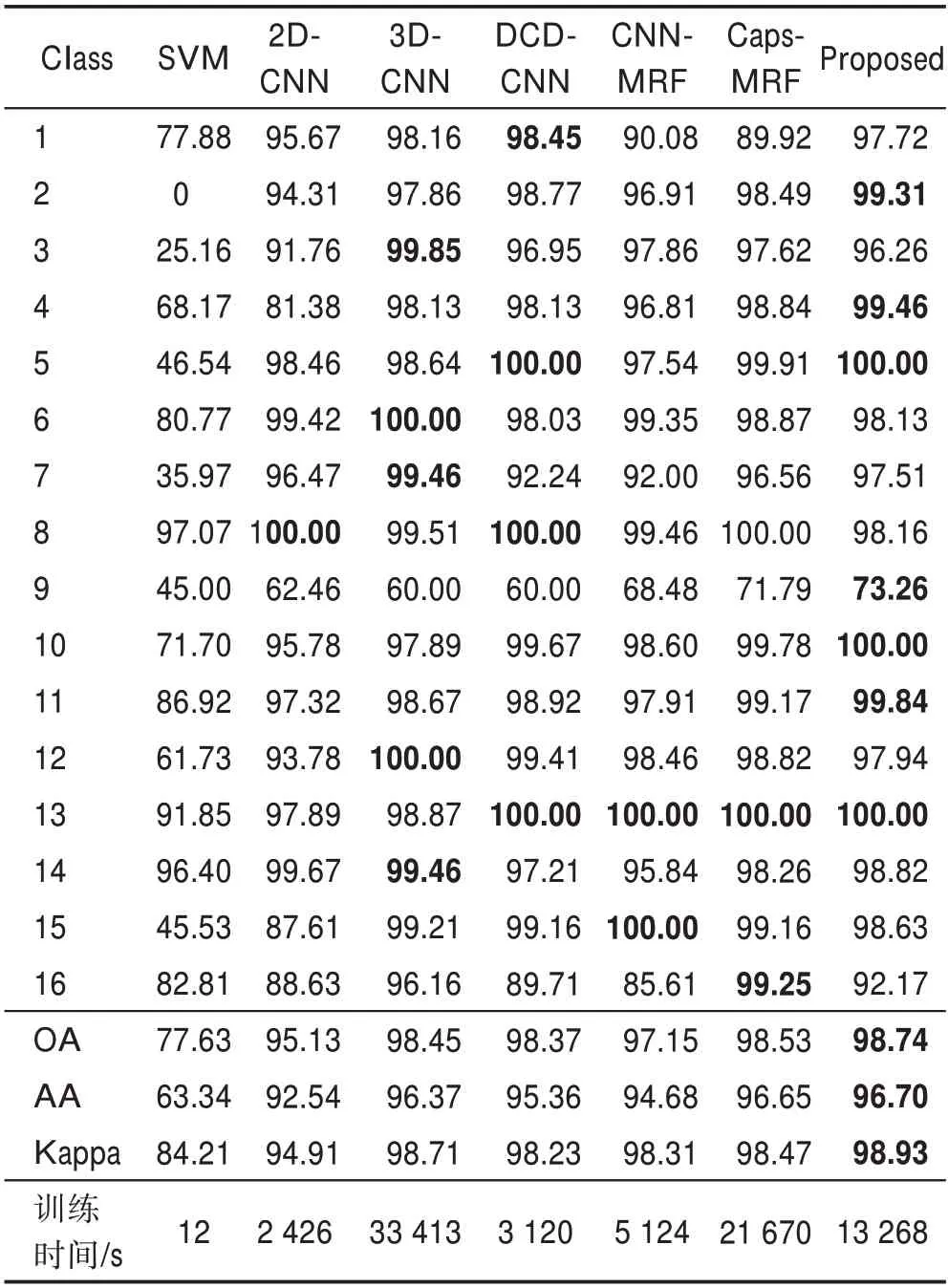
表2 不同方法在IP 數據集上的分類結果Table 2 Classification results of different methods on IP dataset 單位:%
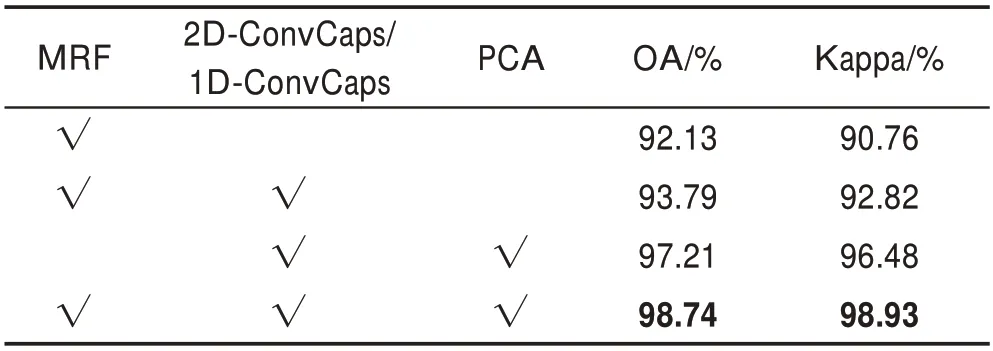
表3 不同情況下的模型在IP 數據集的分類準確性Table 3 Classification accuracy of models in different situations on IP dataset
IP 數據集中每一類別數據的不同比率訓練集得到的分類準確性如圖8,因此所提出方法取每一類別樣本的20%左右作為訓練集可以得到最理想的分類性能。
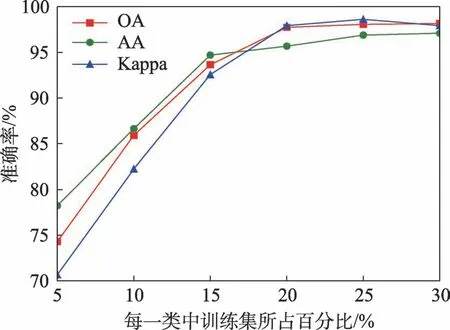
圖8 IP 數據集中不同比率訓練樣本的分類準確性Fig.8 Classification accuracy of different ratios of training samples in IP dataset
圖9 從視覺角度來比較不同方法的分類準確性。基于降參優化后的雙分支膠囊神經網絡結合MRF 的方法的結果圖明顯更接近真實圖。此外,直接比較基于MRF 的方法和非基于MRF 的方法發現,所提出方法和Caps-MRF 的分類表現高于3D-CNN、DCD-CNN,且CNN-MRF 的分類表現高于2D-CNN。可以得出結論,MRF 提高了所提出雙分支膠囊神經網絡的分類表現。
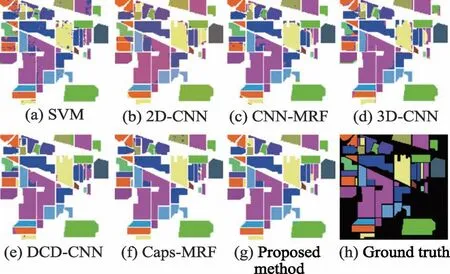
圖9 不同方法在IP 數據集的分類圖Fig.9 Classification maps of different methods on IP dataset
不同情況下的模型在UP 數據集的分類準確性見表4,主要對模型中的MRF 結構、降參優化網絡層(2D-ConvCaps/1D-ConvCaps)以及PCA 降維的有效性進行驗證。UP 數據集中每一類別數據的不同比率訓練集得到的分類準確性如圖10。相關的方法在UP 數據集上的分類準確率、OA、AA、Kappa 系數結果如表5 所示。所提出方法在OA 精度上比未級聯MRF的2D-CNN、DCD-CNN 分別高出13.89%、0.04%,比3D-CNN 僅高出0.71%,同樣由于3D 卷積核產生的參數過大,導致其所需訓練時間最高。對比基于MRF 的方法,所提出方法在OA 精度上比CNN-MRF和Caps-MRF 分別高出3.59%、0.37%,且在所需訓練時間上比Caps-MRF 減少了37.53%,在各方面精度和訓練代價上都優于其他方法。
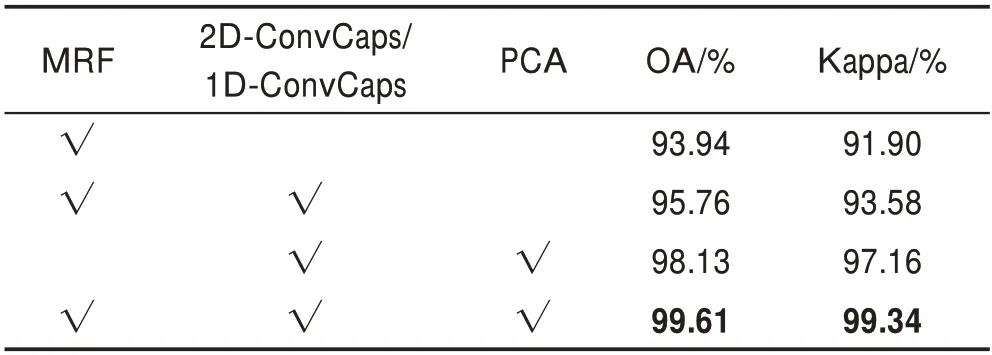
表4 不同情況下的模型在UP 數據集的分類準確性Table 4 Classification accuracy of models in different situations on UP dataset
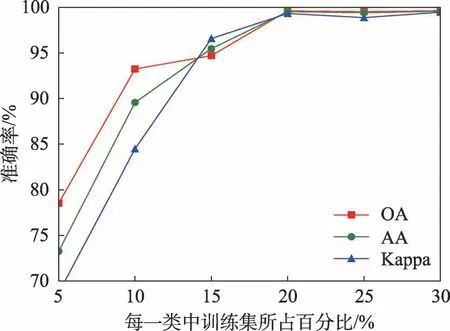
圖10 UP 數據集中不同比率訓練樣本的分類準確性Fig.10 Classification accuracy of different ratios of training samples in UP dataset
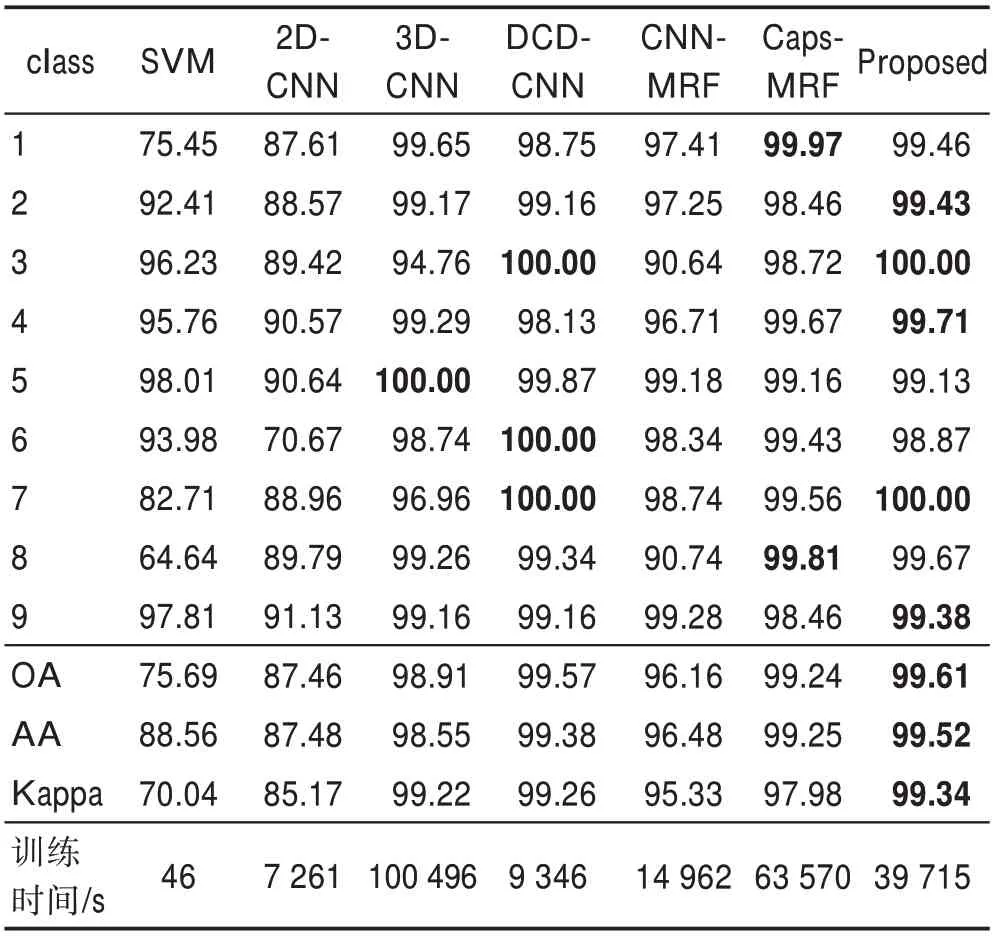
表5 不同方法在UP 數據集上的分類結果Table 5 Classification results of different methods on UP dataset 單位:%
所提出的2D-ConvCaps 取不同輸入向量組個數(如圖3的)與該層提取特征向量組個數(如圖3的)來比較優化效果。不同輸入通道數和特征提取通道數對應的2D-ConvCaps 層與動態路由包含的可訓練總參數量見表6。可看出當所提出的降參網絡層提取特征通道數過大時,總參數量反而高于未降參優化時的動態路由參數量。因此,在實際工程應用時,所提出方法提取特征通道數量不應大于輸入特征圖的通道數量。為同時保證分類性能,建議選取為輸入通道數的1/2 或1/4,也可以根據實際需要疊加使用兩層2D-ConvCaps 層來降低動態路由過程的壓力,同時能夠增加模型的非線性擬合能力。所提出的1D-ConvCaps 的使用建議與2D-Conv-Caps層類似。
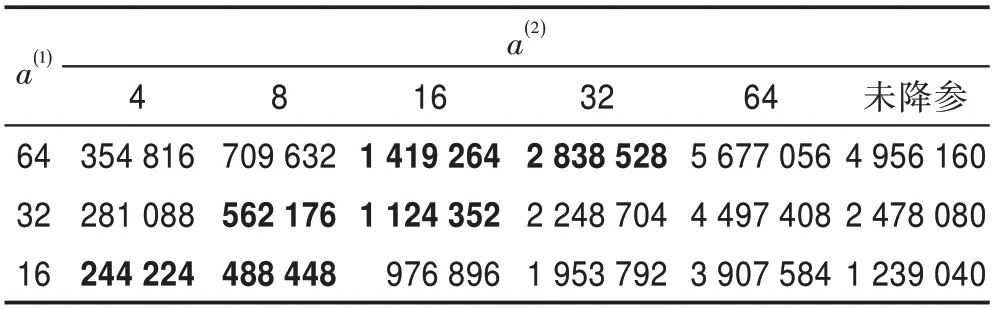
表6 輸入和特征提取的不同向量組個數帶來的參數量Table 6 Amount of parameters brought by different number of vector groups for input and feature extraction
4 結束語
為進一步提升高光譜圖像分類性能以及彌補膠囊網絡參數量過大的缺陷,利用雙分支膠囊神經網絡能夠同時提取圖像的光譜特征和空間特征的優勢,對其進行參數優化并結合MRF,首次使用新的架構(DuB-ConvCapsNet-MRF)對HSI 圖像進行精確細分。從實驗結果來看,通過所提出的方法得到的精確細分結果優于傳統的雙分支卷積神經網絡、單一分支的CNN、單一分支的capsule 網絡以及未優化的雙分支膠囊神經網絡。實驗表明網絡提取的特征通道數越少,1D 和2D 約束窗口降低參數的效果越明顯,這是運用該方法的一個技巧。但圖像預處理中對HSI 進行大量采樣,導致訓練數據比原數據量更大,對訓練過程帶來了額外的壓力。因此在今后的工作中,將基于現有工作更加注重模型輸出的表達,真正實現具有更優效果的“端到端”模型。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
