基于深度學習的雙目立體匹配方法綜述
2022-10-16 12:26:54尹晨陽職恒輝李慧斌
計算機工程 2022年10期
關鍵詞:方法
尹晨陽,職恒輝,李慧斌
(西安交通大學 數學與統計學院,西安 710049)
0 概述
雙目立體視覺是機器視覺的一種重要形式,其基于視差原理來獲取被測物體的三維幾何信息,在自動駕駛[1]、機器人[2]、工業檢測[3]、遙感[4]以及三維重建[5]等諸多方面得到廣泛應用,是計算機視覺領域的研究熱點之一。立體匹配作為雙目立體視覺的關鍵步驟[6],其匹配精度和匹配效率直接影響整個雙目立體視覺系統的性能。
立體匹配是指從圖像對中尋找具有同名特征的像素間對應關系的過程,通常可分為稀疏匹配和稠密匹配,本文主要關注稠密匹配。傳統立體匹配方法通常包含匹配代價計算、代價聚合、視差計算和視差優化4 個步驟(或其中部分步驟的組合)[7]。傳統立體匹配方法依據是否含有代價聚合步驟可分為局部匹配方法[8-9]、全局匹配方法[10-11]以及介于兩者之間的半全局匹配方法[12-13]。
局部匹配方法也稱為基于滑動窗口的匹配方法,通常包含立體匹配方法中的所有步驟。在代價計算步驟中,局部匹配方法采用像素灰度差絕對值AD(Absolute intensity Differences)、CT(Census Transform)[14]和歸一化互相關(Normalized Cross-Correlation,NCC)[15]等度量函數計算匹配代價。在代價聚合步驟中,局部匹配方法采用的具體方法通常是:對于左右視圖中的2 個像素,分別以這2 個像素為中心取相同大小的窗口(稱為聚合窗口),逐個計算2 個窗口內同位置的像素之間的匹配代價并將其累加作為最終的聚合匹配代價。對于視差計算步驟,局部匹配方法常采用贏家通吃算法(Winner Takes All,WTA)直接進行視差搜索。對于視差優化步驟,一般采用左右一致性檢查(Left-Right Check)算法剔除錯誤視差,并用中值濾波或雙邊濾波等平滑算法對初始視差圖進行平滑,從而提高視差精度。
與局部匹配方法不同,全局匹配方法不包含代價聚合步驟,其認為視差圖在全局范圍內是平滑的,對于相鄰像素視差值相差較大的情況需要加以懲罰,據此構造全局能量函數來代替局部匹配方法中的代價聚合步驟。在全局匹配方法中,整個圖像的所有像素同時進行視差值求解,其能量函數通常包含數據約束項和平滑約束項。
半全局立體匹配方法(Semi-Global Matching,SGM)[12]也采用最小化能量函數的思想,但與全局匹配方法不同,SGM 將二維圖像的優化問題轉化為多條路徑的一維優化(即掃描線優化)問題,聚合來自多個方向的路徑代價,并利用WTA 算法計算視差,在匹配精度和計算開銷之間取得了較好的平衡。
近年來,隨著深度學習技術的發展,傳統立體匹配方法中的代價計算、代價聚合、視差計算和視差優化等步驟均可被整合至深度神經網絡框架中,并表現出了更優的性能。立體匹配技術的研究趨勢逐漸從傳統方法轉向深度學習方法,并產生了一系列頗具代表性的研究成果。通常可將基于深度學習的立體匹配方法分為非端到端和端到端兩類,其中,非端到端方法的共同特點是嘗試利用深度神經網絡取代傳統立體匹配方法中的某一步驟,而端到端方法則以左右視圖作為輸入,直接輸出視差圖,利用深度神經網絡直接學習原始數據到期望輸出的映射。本文總結近年來所出現的基于深度學習的立體匹配方法,將其歸納為非端到端立體匹配方法和端到端立體匹配方法,對不同類方法的性能和特點進行比較與分析,歸納立體匹配方法當前所面臨的挑戰,并展望該領域未來的發展方向。
1 基于深度學習的非端到端立體匹配方法
早期基于深度學習的立體匹配方法較關注對傳統匹配方法4 個步驟中的某一個或某幾個單獨進行設計優化。對于代價計算,非端到端立體匹配方法采用學習的特征替換手工設計的特征,然后使用相似性度量(如L1損失函數、L2損失函數,或通過神經網絡學習得到的度量函數)得到代價體。對于代價聚合,非端到端方法通常采用學習的方式優化SGM[12]代價聚合步驟中人工設計的懲罰項,從而提升聚合效果。對于視差優化,基于深度學習的非端到端方法一般采用多階段策略或引入殘差信息來優化視差計算步驟得到的初始視差圖。本文將分別從以上3 個角度介紹基于深度學習的非端到端立體匹配方法。
1.1 基于代價計算網絡的非端到端方法
尋找可靠且穩健的代價計算函數是保證匹配正確率的首要步驟,因此,對于匹配代價計算步驟,基于深度學習的非端到端方法試圖通過設計不同結構的卷積網絡來學習更有效的特征和度量函數,將其用于代價計算從而提高立體匹配方法的精度。
文獻[16]提出的MC-CNN 首次嘗試將深度學習引入立體匹配任務。考慮到人工設計的代價函數魯棒性不高,在反光、弱紋理等病態區域表現不佳,該文設計MC-CNN-acrt和MC-CNN-fst這2種網絡結構,如圖1所示,主要思想是通過深度神經網絡學習圖像塊特征的相似性度量。在MC-CNN 網絡的訓練過程中,該文構建一個二分類數據集(相似的圖像塊對和不相似的圖像塊對),以有監督的方式進行訓練。在MC-CNNacrt框架中,利用孿生網絡(Siamese Network)對圖像塊進行特征提取,然后經過數個全連接層來計算輸入的2 張圖像塊中心像素的相似性分數,以網絡學習的隱式度量代替手工設計的顯式度量函數。MC-CNN-fst 架構則采用顯式的相似性度量(以向量內積取代MC-CNNacrt的全連接層),從而降低時間成本,但是其匹配精度略有下降。
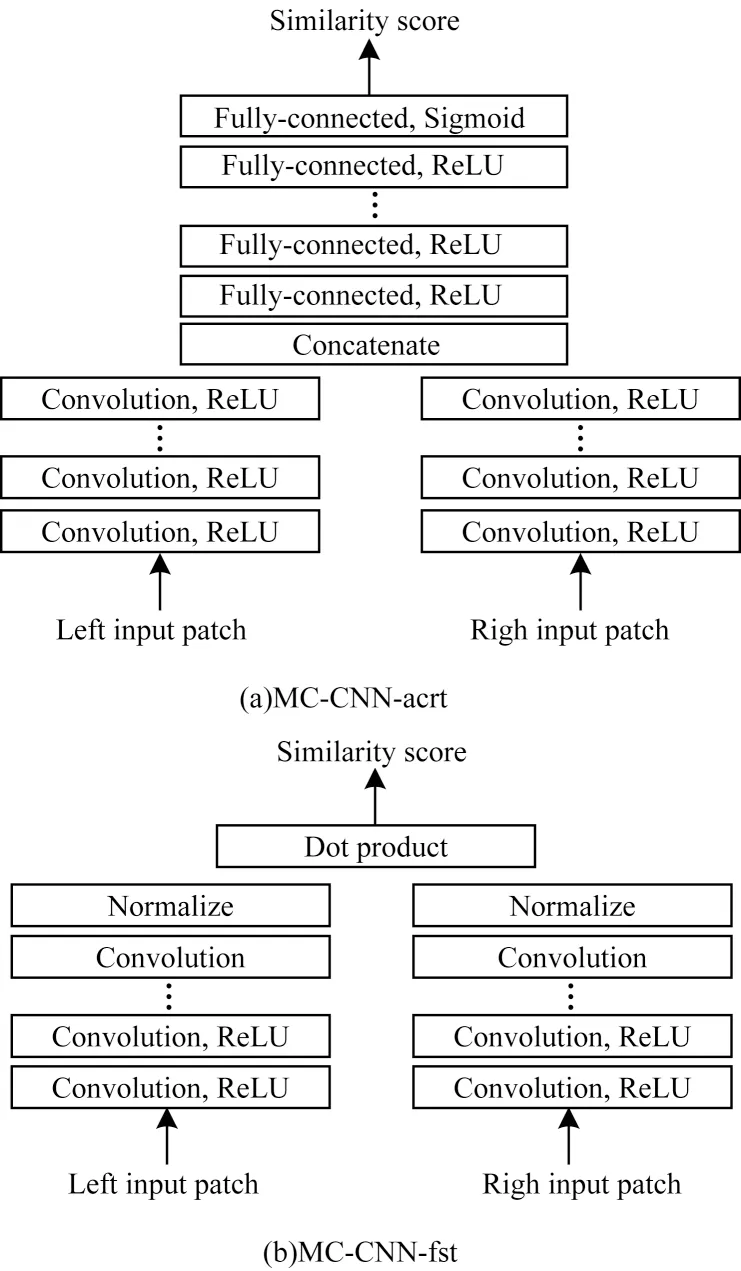
圖1 MC-CNN 網絡架構Fig.1 The network architecture of MC-CNN
在MC-CNN 之后,很多研究人員延續了其孿生網絡基本架構,并專注于改進特征提取方式從而提高匹配精度。文獻[17]提出的MatchNet 采用更多的卷積層來提取特征,并引入池化層以減小特征尺寸。文獻[18]提出的Deep Embedding 通過在2 個并行的子網絡中使用不同大小的卷積核進行多尺度特征提取,然后融合不同尺度特征并由匹配代價決策層處理得到匹配代價。文獻[19]提出的Content CNN 不再采用MC-CNN[16]中的二分類訓練方式,而是將立體匹配看作以視差作為類別的多分類問題,從而訓練網絡。文獻[20]在最終的匹配代價決策層之前插入4P(Per-Pixel Pyramid Pooling)層,使用4 個不同窗口大小的池化操作將輸出相連接以創建新特征,由于其生成的特征包含從粗到細的信息,使得網絡在擴大感受野的同時不會丟失圖像細節。文獻[21]指出文獻[20]中的金字塔池化層需要重新計算每個可能的視差,為此引入多尺度且步長為1 的池化模塊,并將其位置由全連接層末端移至全連接層之前,在保證匹配精度的同時提高了計算效率。文獻[22]提出的SDC(Stacked Dilated Convolution)模塊利用4 個不同擴張率的并行空洞卷積來增加網絡感受野,從而提取到更加有效的特征。文獻[23]引入一致性和獨特性2 個原則改進特征提取效果。文獻[24]提出的合并雙向匹配代價體(Coalesced Bidirectional Matching Volume,CBMV)網絡架構,在訓練時使用隨機森林分類器將由神經網絡學習的隱式代價函數與手工設計的顯式代價函數相結合,使學習到的匹配代價函數在跨域遷移時泛化性更強。
上述基于代價計算網絡的非端到端方法,其匹配效果表現證明了基于CNN 提取的特征相較手工特征更加準確有效,且用于特征提取的網絡越復雜或訓練數據集越大,提取的特征在匹配時性能表現越優。此類方法(如MC-CNN 等)盡管在KITTI等數據集上取得了遠超傳統方法的精度,但是由于它們大都采用孿生網絡結構,然后通過數個全連接層(DNN)對提取的特征進行串聯和進一步計算以獲得最終的匹配代價,因此此類方法普遍存在時耗較高的問題。例如,假定圖像大小為M×N,最大視差預設為D,孿生網絡一次前向傳播的時間為T,則代價體的構建就需耗時M×N×(D+1)×T。如果T值較大,此類方法將具有較低的時間效率,以MC-CNN 為例,其生成單張KITTI 數據集中的圖像(1 226×370 像素)視差圖就需耗時67 s,因此,此類方法大多因為時間復雜度較高而無法滿足實際需求。
1.2 基于代價聚合網絡的非端到端方法
代價聚合步驟的輸入是由代價計算步驟得到的初始代價體,輸出是優化后的代價體。在代價聚合步驟中,像素在不同視差下的匹配代價值會根據其鄰域像素的代價值來重新計算,以此鄰接像素間的聯系,從而降低異常點的影響,提高信噪比。目前,傳統方法中采用最廣泛的代價聚合方法是由SGM[12]提出的基于掃描線優化的代價聚合方法,但SGM[12]中代價聚合的依據準則較為依賴先驗知識,例如平滑項中不同懲罰參數的設置。SGM-Net[25]等基于深度學習的非端到端方法試圖利用置信度學習和左右一致性原則來設計代價聚合網絡以解決此問題。
文獻[26]指出SGM 的代價聚合步驟中并非所有的像素都應具有相同的懲罰項,為此根據左右一致性原則用CNN 處理初始左右視差圖,以得到每個像素的置信度,并在之后的代價聚合步驟中減小對高置信度像素的懲罰。在文獻[26]工作的基礎上,文獻[25]針對SGM 需要人工調整懲罰參數的問題,提出SGM-Net,利用CNN 自動學習懲罰參數。如圖2 所示,SGM-Net 的輸入是小圖像塊和其歸一化的位置參數,輸出對3D 物體結構的懲罰項。在SGM-Net 的訓練過程中,作者設計了一個包含路徑代價和鄰域代價的損失函數:路徑代價考慮掃描線上的像素點視差與實際視差之間的路徑成本,鄰域代價則關注相鄰像素視差之間的過渡成本。除此之外,SGM-Net 根據物體之間不同的遮擋關系,將沿掃描線的視差過渡分為正視差過渡和負視差過渡,保證其在病態區域也能有較好的視差預測效果。然而,由于SGM 中懲罰項無法被準確標記,因此網絡必須在訓練過程中設計包含3 個步驟的策略以生成懲罰項的弱標簽,這就使得整個方法在訓練過程中變得復雜且耗時。
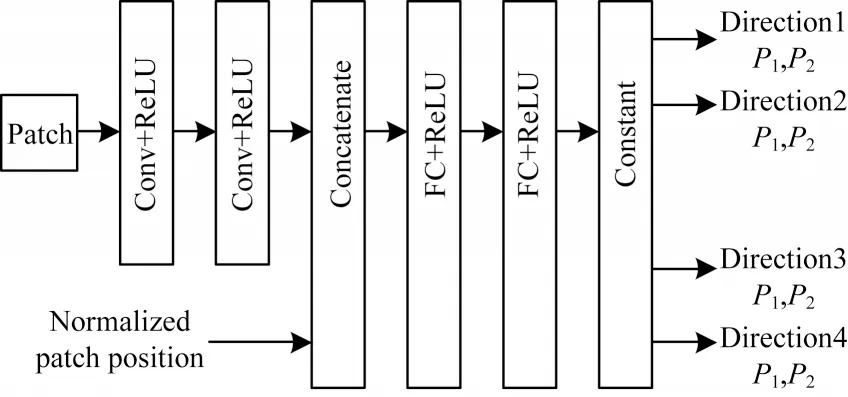
圖2 SGM-Net 網絡架構Fig.2 The network architecture of SGM-Net
文獻[27]指出SGM[12]采取的掃描線優化方法會導致視差圖出現條紋現象,其提出基于置信度的智能聚合策略,使用相應的置信度得分對每個獨立路徑計算的匹配成本進行加權求和。與此類似,文獻[28]提出的SGM-Forest 也不再使用SGM[12]中原始的聚合方式來簡單組合來自多個一維掃描線的匹配成本,而是訓練隨機森林分類器來融合多個方向的一維掃描線優化成本,針對圖像中的每個位置都選擇效果最優的掃描線路徑。
1.3 基于視差優化網絡的非端到端方法
視差優化是傳統立體匹配方法流程中的最后一步,目的是剔除初始視差圖中的錯誤視差,并得到優化后高質量的視差圖。在深度學習興起后,LRCR等[29]嘗試利用基于置信度學習、逐步調優以及殘差校正等思想設計深度神經網絡,從而進行視差優化。
文獻[30]提出名為λ-ResMatch 的多階段框架,該框架利用深度殘差網絡學習匹配代價的度量,并采用SGM[12]中的代價聚合步驟處理代價體,再利用全局視差網絡(Global Disparity Network,GDN)取代贏家通吃(WTA)算法計算得到視差圖和置信度,而后利用置信度得分修正視差圖,完成視差優化。文獻[31]將視差優化分解為3 個子步驟:檢測不正確的視差;用新視差替換不正確的視差;利用殘差校正的思想對輸出視差進行改善。該文將上述3 個子步驟嵌入在一個統一的卷積網絡框架中,稱為DRR(Detect、Replace、Refine)。由于DRR的輸入是初始視差圖,因此允許多次使用DRR反復優化視差圖,使匹配精度進一步提升。然而,在用新視差替代不可靠視差時會造成計算資源浪費,增加了計算負擔。文獻[21]將視差優化分解為4 個子步驟:利用卷積網絡對初始最優視差圖和次優視差圖進行融合;將融合后的視差圖和原始圖像作為輸入,依次進行錯誤視差檢測、并行視差替換和殘差優化,與文獻[31]不同,在并行視差替換的步驟中,并行的2 個沙漏狀結構的子網絡分別用來處理圖像中的平滑區域和細節區域,進一步提高了視差預測的準確性。受殘差網絡思想的影響,文獻[32]提出遞歸殘差網絡RecResNet(Recurrent Residual CNN),通過估計在多個分辨率下計算的殘差組合來糾正不同類型的視差錯誤,最終生成優化后的視差圖。該網絡可用于優化由未知黑盒算法生成的視差圖,并能周期性地應用于其自身的輸出以進行進一步改進。與上述完全基于CNN 的視差優化方法不同,文獻[29]按照RNN 模式搭建左右比較遞歸模型LRCR(Left-Right Comparative Recurrent),該模型可以同步執行視差估計與左右一致性檢測,在每次重復的步驟中,模型會為左右視圖同時生成視差圖并進行左右一致性檢測,以識別可能出現視差錯誤的區域。此外,LRCR 框架中引入了柔性注意力機制,用學習到的誤差圖引導模型在下個重復步驟中有選擇性地關注不可靠區域的視差,從而逐步改善視差圖的質量。值得注意的是,所有這些基于視差優化網絡的非端到端方法都能取得出色的匹配精度,但是它們會受到高計算負擔的影響,以最具代表性的LRCR[29]為例,其在當時的KITTI 數據榜單上取得了最好的結果,但處理一張圖片的時間高達49.2 s。
2 基于深度學習的端到端立體匹配方法
上述基于深度學習的非端到端立體匹配方法本質上并未脫離傳統方法的框架,一般仍需添加手工設計的正則化函數或視差后處理步驟,這意味著非端到端立體匹配方法具有計算量大和時間效率低的缺點,同時也未解決傳統立體匹配方法中感受野有限、圖像上下文信息缺乏的問題。隨著MAYER等[33]首次成功地將端到端網絡結構引入立體匹配任務并取得良好效果,設計更有效的端到端立體匹配網絡逐漸成為立體匹配的研究趨勢。從各立體匹配數據集的公開排行榜上可以發現,端到端方法在立體匹配任務中已然占據了主導地位。
如圖3 所示,當前基于深度學習的端到端立體匹配網絡以左右視圖作為輸入,經參數共享的卷積模塊提取特征后按相關性操作(Correlation)或拼接操作(Concat)構建代價體,最后根據代價體的維度進行不同的卷積操作以回歸出視差圖。根據代價體維度的不同,端到端立體匹配網絡可分為基于3D 代價體和基于4D 代價體的2 種方法,而具有級聯視差優化效果的2D 編碼器-解碼器和由3D 卷積組成的正則化模塊是當下分別用來處理3D 和4D 代價體的2 種結構。2D 編碼器-解碼器由一系列堆疊的2D CNN 組成,并帶有跳躍連接,加入殘差信息以提高視差預測效果。而3D 正則化模塊的關鍵點則是在構建代價體時將提取的左右圖特征沿視差維度進行拼接以得到一個4D 的代價體,而后使用3D CNN 處理4D 代價體,以充分利用視差維度信息。

圖3 用于端到端立體匹配的2 種主流架構Fig.3 Two mainstream architectures for end-to-end stereo matching
2.1 基于3D 代價體的端到端立體匹配網絡
基于3D 代價體的端到端立體匹配網絡接近于傳統密集回歸問題(如語義分割、光流估計等)的神經網絡模型。如圖3(a)所示,受U-Net[34]模型的啟發,該類型端到端網絡的設計中部署了編碼器-解碼器結構,以減少內存需求并增加網絡的感受野,從而更好地利用圖像的上下文信息。具體而言,一些研究為提升網絡的視差預測精度,采用多階段學習和多網絡框架或多任務學習的思想設計立體匹配網絡,而另外一些研究則著眼于減少網絡計算負擔,采用從粗到精的策略設計更高效的結構。
文獻[33]首次引入端到端視差回歸網絡Disp-Net,其包含快速框架Disp-NetS 和精確框架Disp-NetC。Disp-NetS 借鑒U-Net[34]的框架設計一種用于視差回歸的編碼器-解碼器結構。Disp-NetC 則類似于光流估計中的FlowNetCorr[35]網絡結構(如圖4 所示),首先利用孿生網絡提取輸入的左右視圖特征,然后對提取的左右特征塊進行1D 的相關性(Correlation)操作,得到3D 代價體(尺寸與特征圖大小相同,通道數為Dmax,Dmax是預設的最大視差值)。Disp-NetC 網絡的后續部分則利用2D 編碼器-解碼器處理3D 代價體并回歸出最終的視差圖。與非端到端方法特征提取模塊常采用孿生網絡相比,由于Disp-Net 將整個圖像作為輸入,因此其具有更高的時間效率,處理KITTI 數據集中一張圖片僅需0.06 s,時間效率是MC-CNN 的1 000 倍,但在圖像的病態區域,如遮擋、重復或無紋理區域,Disp-Net 仍然較難找到正確的對應關系。
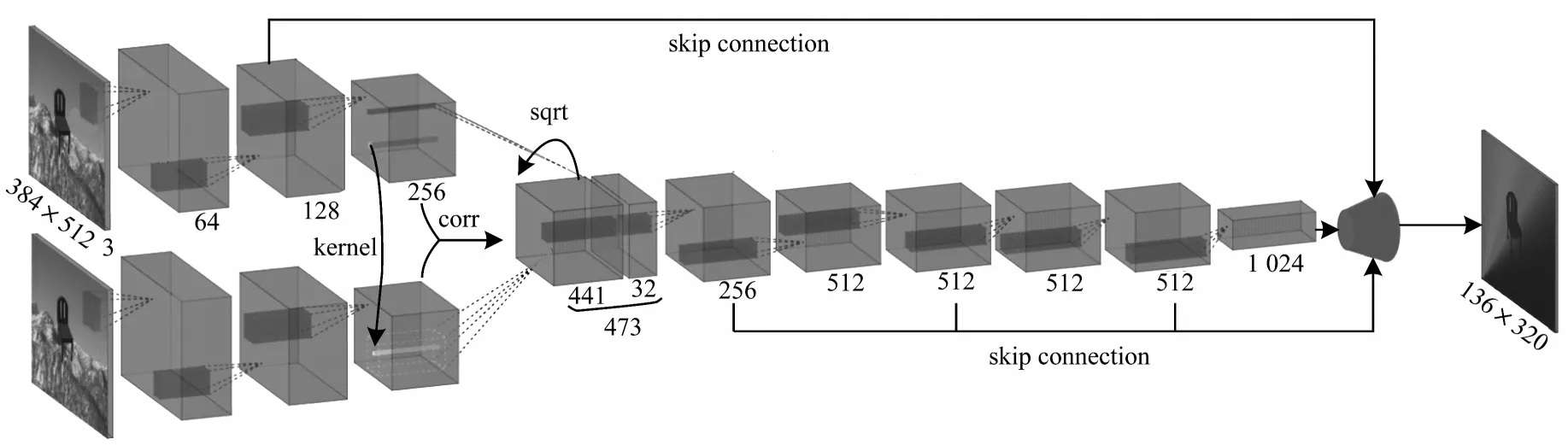
圖4 FlowNetCorr 網絡架構Fig.4 The network architecture of FlowNetCorr
考慮到Disp-Net[33]網絡結構配置的確定過程經過了多次手工設計和調整,而且無法確認是否為最佳配置,為此,文獻[36]引入自動機器學習(AutoML)的思路。該文利用基于梯度的神經架構搜索和貝葉斯優化來進行超參數搜索,尋找Disp-Net的最佳配置,并提出AutoDispNet-CSS 網絡結構。文獻[37]為了解決Disp-Net[33]網絡對遮擋區域預測效果不佳的問題,提出DispNet-CSS 框架,其包含多個基于FlowNet[35]的編碼器-解碼器結構和基于FlowNet 2.0[38]的堆棧結構,通過反復估計遮擋區域和運動邊界來改善視差估計效果。
秉承多階段網絡的思想,文獻[39]提出二級級聯殘差學習網絡CRL(Cascade Residual Learning)。如圖5 所示,CRL 的第一階段結構DispFulNet 由Disp-NetC 網絡添加額外的反卷積模塊得到,能生成包含細紋理的初始視差圖;第二階段結構DispResNet利用多尺度殘差信號修正初始視差圖,采用殘差學習的思想實現更有效的視差精細化。CRL 在所有立體匹配方法中達到了當時最高的匹配精度,但復雜的結構意味著較高的計算負擔,因此,其時間效率比Disp-Net 慢80%。
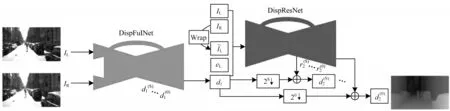
圖5 CRL 多階段網絡架構Fig.5 Multi-stage network architecture of CRL
文獻[40]認為CRL 網絡的第二階段中采用光度誤差(即色彩空間層次的重構誤差)對視差進行調優,魯棒性不足。為此,該文提出iResNet 網絡,在特征空間層面計算重構誤差,組合特征空間中的重構誤差與特征相關(feature correlation)作為特征恒量,并在最后的視差優化模塊輸入級聯的特征恒量和左圖特征,從而輸出調優殘差。這種網絡設計允許反復使用視差優化模塊對視差圖進行調優,以網絡的匹配速度換取匹配精度。事實上,iResNet 和CRL 具有類似的思想,但iResNet 在提升匹配精度的同時也實現了更好的時間效率,其匹配效率相較CRL 提升了4 倍。從網絡不同階段間的信息交互情況來看,CRL[39]方法只有第一階段網絡結構預測的視差信息會傳遞到第二階段網絡結構,而iResNet則在網絡的前后兩階段結構間共享更多的信息,這也是CRL[39]采用更復雜的網絡架構但預測效果仍不如iResNet 的主要原因。
盡管采用多階段的網絡設計策略在很大程度上提高了匹配精度,但更復雜的網絡意味著更高的計算負擔。因此,文獻[41]采用從粗到精的金字塔策略,提出首個無監督的實時域自適應立體匹配網絡MADNet。為了提升在線自適應效率,MADNet在反向傳播時不對網絡的全部參數進行更新,而是采用啟發式的獎勵-懲罰機制來動態選擇每次更新的參數。同樣,為減少計算成本,文獻[42]利用從粗到精的策略,提出分層離散分布分解立體匹配網絡HD3(Hierarchical Discrete Distribution Decomposition),將立體匹配視為像素對應的概率問題,以考慮立體匹配中固有的不確定度估計。HD3將估計視差等價轉化為估計離散匹配分布問題,并將圖像分層分解為從粗到細的多個尺度,在利用網絡預測出不同尺度上的離散匹配分布后,對由網絡計算得到的不確定度進行加權組合,以得到圖像整體的離散匹配分布。
弱紋理、反射、物體邊緣等病態區域會嚴重影響立體匹配網絡的匹配精度,通過融合不同模型的優點或采用多任務學習的方式能有效緩解此問題。文獻[43]提出由CNN 和條件隨機場(CRF)組成的混合模型,利用CNN 學習提取的特征,從而計算CRF 的一元和二元代價,并將CRF 公式化為最大余量馬爾可夫網絡,實現CNN+CRF 的聯合訓練。文獻[44-45]提出一種由預測視差的主干網絡和提取邊緣的子網絡共同組成的多任務學習網絡EdgeStereo。如圖6 所示,該模型在視差主網中共享子網提取的邊緣特征,并在損失函數中加入具有邊緣感知的平滑正則化項,從而將邊緣信息整合到視差主干網絡中,達成邊緣檢測與視差學習相互促進的目的。由于加入了邊緣信息,EdgeStereo 在細薄結構區域以及物體邊緣處表現較為優越,立體匹配方法固有的邊緣肥大缺陷有所緩解,但其仍舊存在訓練方式復雜以及對距離相機較遠的物體結構匹配精度不高的問題。
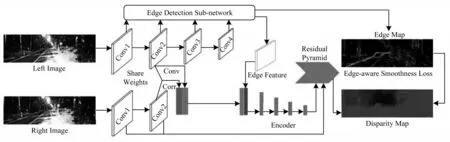
圖6 EdgeStereo 多任務網絡框架Fig.6 Multi-tasking network framework of EdgeStereo
文獻[46]構建的網絡模型SegStereo 用語義信息來指導病態區域的視差學習,該模型包含視差主干網絡和語義分支網絡。SegStereo 在視差主干網絡中融合來自語義分支的語義特征,并在網絡訓練的損失函數中引入語義損失項,利用語義信息指導視差估計,提高了反光、遮擋、重復紋理以及弱紋理等病態區域的匹配精度。與文獻[46]中使用2 個獨立的編碼模塊來分別提取語義和視差特征不同,文獻[47]提出的DSNet 是一種輕量級網絡架構,在特征提取時語義分割分支網絡與視差估計共享相同的主干網絡,此外,該文不再直接將語義分支網絡的特征進行拼接,而是設計一種具有注意力機制的匹配模塊提取融合特征從而進行視差估計。與加入邊緣信息的EdgeStereo[44-45]相比,加入語義信息的SegStereo[46]和DSNet[47]在病態區域的匹配精度提升效果較為明顯,但它們在細薄結構和物體邊緣區域的匹配精度則顯著低于EdgeStereo[44-45]。
2.2 基于4D 代價體的端到端立體匹配網絡
與受傳統神經網絡模型啟發的架構不同,基于4D代價體的端到端立體匹配網絡架構是專門為立體匹配任務而設計的,這一架構下的網絡不再對特征進行降維操作,從而使代價體能保留更多的圖像幾何和上下文信息,因此,基于4D 代價體的端到端立體匹配網絡視差預測效果一般優于基于3D 代價體的端到端網絡,但是這種精度上的提升需要消耗更多的計算時間和存儲資源。從基于4D 代價體的端到端網絡的初始設計理念(盡可能降低圖像信息損失)出發,文獻[48-53]致力于讓網絡在學習過程中考慮更多的圖像上下文信息。而為了緩解該種網絡架構普遍存在的高計算負擔問題,文獻[54-58]嘗試從壓縮4D 代價體大小、減少3D 卷積數量等不同角度提高網絡效率。
文獻[59]提出一種新型深度視差學習網絡GCNet,其創造性地引入4D 代價體,并在正則化模塊中首次利用3D 卷積來融合4D 代價體的上下文信息,開創了專門用于立體匹配的3D 網絡結構。如圖7所示,GC-Net 包含4 個步驟:
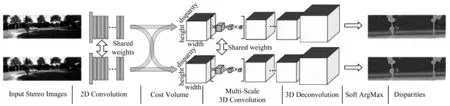
圖7 GC-Net 網絡框架Fig.7 Network framework of GC-Net
1)利用權值共享的2D 卷積層分別提取左、右圖像的高維特征,并在此階段進行下采樣將原始分辨率減半以減少內存需求。
2)將左特征圖和對應通道的右特征圖沿視差維度逐像素錯位串聯得到4D 代價體,大小為,其中,H、W分別為圖像的高和寬,Dmax為最大視差,C為特征通道數。
3)利用由多尺度的3D 卷積和反卷積組成的編碼-解碼模塊對代價體進行正則化操作,得到大小為H×W×Dmax×1 的代價體張量。
4)對代價體應用可微的Soft ArgMax 操作回歸得到視差圖。
GC-Net 取得了當時KITTI 基準下最高的匹配精度,原因是其構建的代價體包含高度、寬度、視差和特征通道4 個維度,從而保留了圖像更多的立體幾何信息。但是值得注意的是,由于網絡中大量使用3D 卷積,因此GC-Net 會存在計算時間方面的局限性,其處理一張分辨率為1 216×352 像素的圖像需要0.9 s,耗時約為基于3D 代價體的端到端立體匹配網絡DispNet 的15 倍。
與基于3D 代價體的端到端立體匹配網絡類似,在基于4D 代價體的網絡學習過程中加入更多的信息也能提升視差預測精度。文獻[48]提出的金字塔立體匹配網絡PSMNet,主要由空間金字塔池化(Spatial Pyramid Pooling,SPP)模塊和堆疊的沙漏狀3D CNN模塊組成,其中,金字塔池化模塊提取多尺度特征以充分利用全局環境信息,堆疊的沙漏狀3D 編碼器-解碼器結構對4D 代價體進行正則化處理以提供視差預測。但是,由于SPP 模塊中不同尺度的池化操作固有的信息損失,導致PSMNet 在如物體邊緣等包含大量細節信息的圖像區域的匹配精度較差。在PSMNet 的基礎上,文獻[49]將卷積空間傳播網絡(Convolutional Spatial Propagation Network,CSPN)模塊擴展到3D 情形以處理4D 代價體,使3D 正則化模塊可以從空間維度和視差維度上對4D 代價體進行信息聚合。文獻[50]則針對PSMNet 網絡前端的代價計算部分進行改進,提出多級上下文超聚合(Multi-level Context Ultra-Aggregation,MCUA)的二級特征描述方法,通過將層次內和層次間的特征組合(即將淺層、低級特征與深層、高級語義特征相結合),將所有卷積特征封裝成更具區分性的表示形式,在沒有顯著增加網絡參數量的前提下提升了網絡的匹配性能。受半全局匹配(SGM)的啟發,文獻[51]引入指導代價聚合的顯式代價聚合(Explicit Cost Aggregation Sub-Architecture,ECA)模塊。ECA模塊由雙流束網絡(two-stream network)組成:第一個流通過卷積操作沿著代價體的高度、寬度、視差3 個維度結合空間和深度信息,生成3 個潛在的代價聚合方式;第二個流評估潛在的聚合方式并選出其中最佳的一種,選擇標準由輕量卷積網絡獲得的低階結構信息所確定。GWC-Net[52]通過組相關策略保留基于3D 代價體的端到端網絡中代價體構建方式(相關性操作)的優點,考慮不同特征通道的關聯性從而得到更好的代價體表示,使網絡能夠推斷出更準確的視差圖。根據多任務學習的思想,DispSegNet[53]通過分割的方式利用語義信息指導深度估計,提高了網絡在病態區域的匹配精度。
盡管上述基于4D 代價體的端到端網絡取得了良好的匹配效果,但由于3D 卷積結構本身的計算復雜度,導致網絡在存儲資源和計算時間上成本高昂。以GCNet[59]為例,其處理分辨率為1 216×352 像素的圖像對大約需要10.4 GB GPU 內存[54]。為了解決此問題,壓縮代價體[54-55]、構建更低分辨率的代價體[56-57]或減少3D卷積層個數[58]等多種思路被提出。文獻[55]設計的網絡PDS(Practical Deep Stereo)引入一個瓶頸匹配模塊,通過將來自左、右圖像的級聯特征壓縮為更緊湊的匹配表示形式來壓縮4D 代價體,從而減少內存占用量。文獻[54]提出基于GC-Net[59]的稀疏代價體網絡(Sparse Cost Volume Net,SCV-Net),在由左、右圖像特征生成4D 代價體的步驟中引入步幅參數使代價體更緊湊,在不影響性能的情況下大幅減少了內存使用量。文獻[56]采用從粗到細的策略,提出一個三階段視差估計網絡AnyNet:首先以低分辨率特征圖作為輸入,構建低分辨率4D 代價體;其次使用3D 卷積在較小的視差范圍內進行搜索得到低分辨率視差圖;最后對低分辨率視差圖上采樣得到高分辨率視差圖。該方法是漸進式的,允許隨時停止來獲得較粗的視差圖,以匹配精度換取匹配速度。文獻[57]提出實時輕量立體匹配網絡StereoNet,在得到低分辨率的視差圖后通過2D 卷積網絡進行上采樣和視差優化,以降低網絡的復雜性,但與采用高分辨率4D 代價體的方法相比,StereoNet在物體邊緣區域的匹配精度有所下降。文獻[58]設計GA-Net,其采用半全局聚合(Semi-Global Aggregation,SGA)層和局部引導聚合(Local Guided Aggregation,LGA)層替換正則化模塊中的大量3D卷積層,其中:SGA是SGM中代價聚合方法的可微近似,并且懲罰系數不再由先驗知識確定,而是由網絡學習得到,因此,對于圖像的不同區域具有較好的適應性和靈活性;局部引導聚合層LGA 則附加在網絡末尾以聚合局部代價,旨在細化薄結構和物體邊緣的視差。
如上所述,許多研究人員嘗試從優化4D 代價體大小和減少3D 卷積個數等不同角度設計網絡結構,使網絡在時間效率上得到改進。但是,綜合匹配精度和匹配效率可以看出,如何設計更加高效實用的網絡結構仍需進一步探索。
3 方法性能比較
3.1 數據集
表1 給出了4 個常用數據集的介紹與比較。KITTI 2012[60]是用于立體匹配的第一個大型駕駛場景數據集,包括靜態場景的室外圖像,該數據集由389 個灰度圖像對組成,分為194個訓練圖像對和195個測試圖像對,數據集的GT(Ground Truth)由LIDIA 測量獲得,GT 是半密集的,覆蓋了圖像約1/3 的像素點,并經過手工矯正后將其轉換為視差。KITTI 2012 數據集提供了在線排行榜,可對全部區域像素和去除遮擋區域像素分別進行評估。KITTI 2015[1]數據集采集于動態場景,圖像內容包含行駛中的汽車,該數據集共包含400 對彩色雙目圖像,訓練集和測試集各200 對。KITTI 2015 數據集的數據采集方式與KITTI 2012 相似,評價指標也為誤匹配率,分為前景(移動的目標)、背景和全部區域3 種情形。Middlebury 2014[61]數據集由33 個亞像素級別的室內靜態場景組成,分為訓練集(13 對)、附加集(10 對)和測試集(10 對),圖像和GT 提供了全分辨率、半分辨率和1/4 分辨率3 種版本,該數據集視差范圍在200~800 像素之間,與KITTI 數據集相比,Middlebury 2014最大的一個差異是圖像分辨率非常高,達到了600萬像素。Freiburg SceneFlow[33]數據集包含約39 000 對大小為540×960 像素的虛擬圖像,根據場景類型又分為FlyingThings3D、Monkaa 和Driving 這3個子集。FlyingThings3D 數據完全由渲染生成,共包含22 872 個圖像對,其中,4 370 個圖像對作為驗證集;Monkaa 數據從動畫片中生成,共包含8 591 對雙目圖像;Driving的數據生成方式與Monkaa相同,提供駕駛場景的數據,共包含4 392 對圖像。

表1 立體匹配任務常用數據集Table 1 Common datasets of stereo-matching tasks
綜合近些年的研究結果來看,KITTI 數據集和Middlebury 數據集被廣泛應用于訓練和測試基于圖像塊的CNN 網絡架構(如MC-CNN 等),這是因為單個訓練圖像對可以產生數千對不同的圖像塊。而在端到端架構中,由于其需要大量數據集進行有效訓練,且這種情況下一個圖像對僅對應一個樣本,因此大多數端到端立體匹配網絡在遷移到如KITTI 和Middlebury 等真實數據集前,通常選擇在Freiburg SceneFlow 數據集上進行預訓練。
3.2 評估指標
立體匹配方法的評估指標有匹配精度與時間復雜度。匹配精度的衡量標準有平均絕對誤差、均方根誤差與誤匹配率,計算公式分別如下:
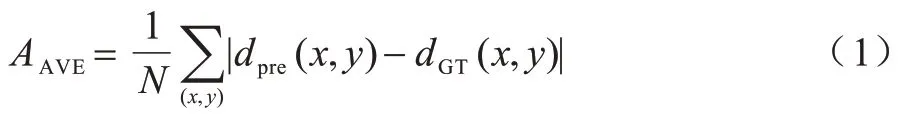
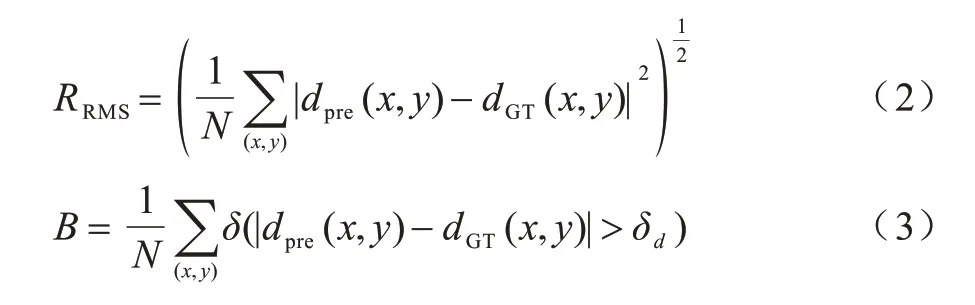
其中:dpre(x,y)與dGT(x,y)分別為預測視差和真實視差;δ為指示函數,當差值大于設置的閾值δd時其取值為1,否則為0;N為參與計算的像素點總數。
3.3 性能分析比較
本文從KITTI 2015 和Middlebury 2014 網站上選取部分方法的量化評價結果,以對基于深度學習的非端到端和端到端立體匹配方法進行定量比較。
表2 和表3 分別給出各立體匹配方法在所有區域(All pixels)和非遮擋區域(Non-occluded pixels)2 種情形下的誤匹配率,并在表4 中給出不同種類立體匹配方法的定性分析結果。
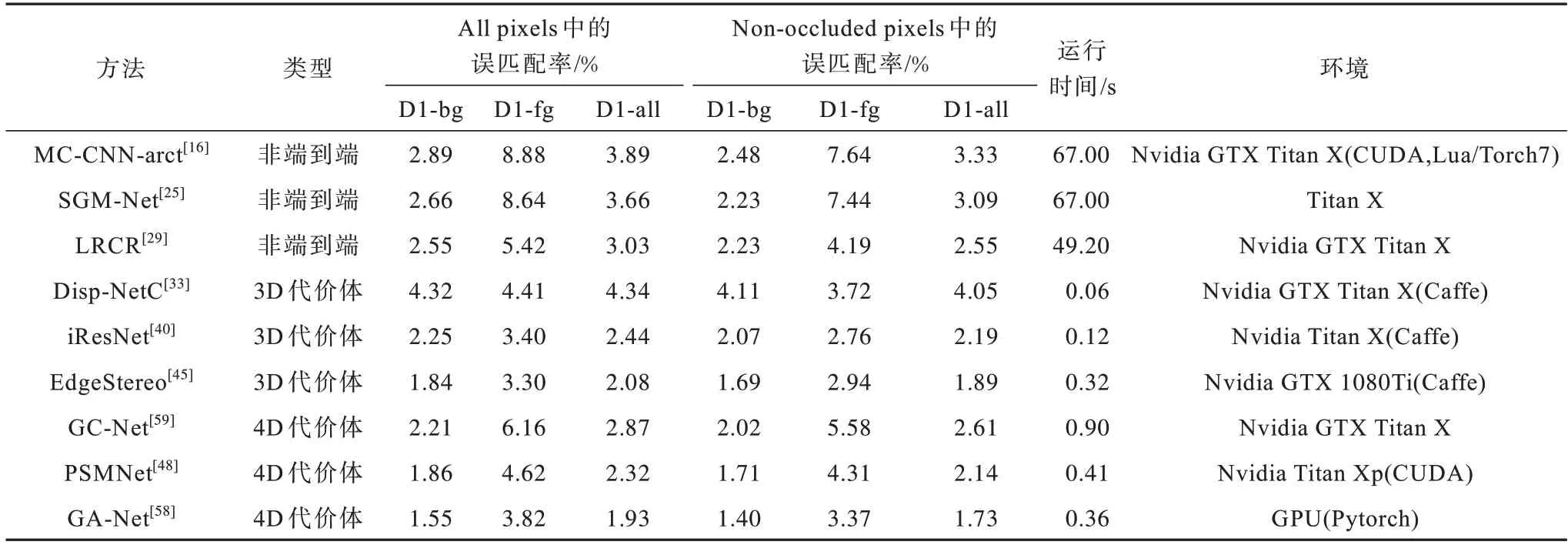
表2 KITTI 2015 數據集上不同立體匹配方法的性能比較結果Table 2 Performance comparison results of different stereo-matching methods on KITTI 2015 dataset

表3 Middlebury 2014 數據集上不同立體匹配方法的性能比較結果Table 3 Performance comparison results of different stereo-matching methods on Middlebury 2014 dataset

表4 不同立體匹配方法的特點比較Table 4 Comparison of characteristics of different stereo-matching methods
在表2 中,誤匹配率的誤差閾值限定為3 個像素,且D1-bg、D1-fg、D1-all 分別代表背景區域、前景區域和所有區域。在表3 中,誤差閾值限定為2 個像素,F、H、Q 分別代表全分辨率、半分辨率和1/4 分辨率,AVE 代表像素點的平均絕對誤差。
從表2 和表3 可以看出:在KITTI 數據集中,相比于深度學習與傳統方法相結合的非端到端方法,早期基于深度學習的端到端方法計算效率明顯提高,但匹配效果并不理想,隨著后期研究的深入,端到端方法(尤其是基于4D 代價體的端到端方法)的匹配精度要明顯優于非端到端方法;在Middlebury 2014 數據集中,大部分基于3D 代價體的端到端方法的誤匹配率高于非端到端方法,原因是端到端立體匹配網絡的學習效果較為依賴訓練集中圖像場景的類型。端到端立體匹配網絡通常在Freiburg SceneFlow數據集中進行預訓練,而Middlebury 2014 數據集中的圖像與Freiburg SceneFlow 中的圖像在情景內容上差距較大,導致網絡遷移到Middlebury 2014 數據集上時表現較差。而對于基于4D 代價體的端到端方法,除受到跨域遷移的影響之外,還因對于高分辨率圖像處理能力不足,導致其不僅在Middlebury 2014 數據集排行榜中排名靠前的算法數量較少,而且匹配精度也低于基于3D 代價體的端到端立體匹配方法。
4 未來展望
基于深度學習的立體匹配方法已經取得了顯著成果,然而,綜合匹配精度和時間效率來看,目前的研究工作仍處于起步階段。該領域未來的發展方向主要在以下幾個方面:
1)魯棒性。基于深度學習的立體匹配方法在精度上較傳統方法有很大提升,但在弱紋理、重復紋理、遮擋、透明、鏡面反射、光學失真等病態區域的誤匹配率依舊很高,而這些場景在實際應用中真實存在且不可避免,因此,設計新的立體匹配方法以降低這些區域的誤匹配率依然會是未來的研究重點。從文獻[44-47,53]等研究結果來看,將高級視覺任務中的目標識別、場景理解與低級視覺特征學習相結合是解決該問題的一種有效途徑。
2)實時性。大多數端到端方法在構建3D 或4D代價體后分別使用2D 和3D 卷積進行正則化處理,這導致它們普遍具有高昂的時間成本和計算資源開銷,嚴重阻礙了此類方法在嵌入式設備中的實際應用。因此,開發精度與速度并存的輕量級端到端網絡是未來的一個重要研究方向。
3)跨域遷移性。深度神經網絡在很大程度上依賴于訓練圖像的可用性,其方法性能和泛化能力會受到訓練集較大的影響,且容易出現模型對特定領域過擬合的風險。針對立體匹配問題,大多數端到端網絡框架一般都會選擇在合成數據集Freiburg SceneFlow 上進行預訓練,而這導致了訓練后的模型在遷移到真實數據集上時效果明顯下降。因此,開發泛化性較強的立體匹配方法,使其在跨域遷移時能適應新的情景環境也是需要解決的一大難題。在其他視覺任務中,常通過設計特定的損失函數或使用領域自適應和遷移學習策略來緩解此問題,這2 種思路也是緩解立體匹配網絡泛化性問題的潛在對策。
4)對高分辨率圖像的處理能力。當前大多數基于深度學習的立體匹配方法不能很好地處理高分辨率輸入圖像,通常會生成低分辨率的深度圖,導致這些方法無法有效重建如植被、細桿等細薄結構以及距離相機較遠的結構。對于高分辨率圖像,當下一種有效的思路是采用分層技術,即利用深層、低分辨率的特征信息生成低分辨率深度圖,而后結合淺層、保留較多空間位置信息的特征生成高分辨率深度圖。但在這種基于由粗到精的策略中,低分辨率深度圖可以實時生成,而生成高分辨率深度圖則需要較長時間。因此,對高分辨率圖像實時生成精確的深度圖仍是未來研究的一大趨勢。
5)學習范式。對訓練圖像進行逐像素標簽標注是一項耗時耗力的工作,已經有許多研究人員嘗試采用無監督方法來緩解標注負擔。而相比于監督學習方法,現有的無監督方法匹配精度較低,因此,設計效果優良的無監督訓練算法也具有重要的研究意義。
6)網絡架構搜索。目前基于深度學習的立體匹配方法研究大都集中在設計新的網絡結構和訓練方法,僅有較少的研究人員關注自動學習最佳架構問題,如AutoDispNet[36]。使用神經進化理論從數據中自動學習網絡架構、激活函數,可以釋放對人工網絡設計的需求。因此,對自動學習復雜視差估計網絡架構進行研究也具有較大的發展前景。
7)不同類型網絡的應用。目前基于深度學習的立體匹配方法大都基于卷積神經網絡,結合其他類型網絡(如循環神經網絡、生成對抗網絡等)的優勢來進一步提高立體匹配的效果,也是一個潛在的研究方向。
5 結束語
本文對基于深度學習的立體匹配方法進行分類和總結。基于深度學習的非端到端方法取得了優于傳統方法的性能表現,并且相較端到端方法,非端到端方法對訓練數據樣本量的要求較低,同時具有較強的泛化性和跨域遷移性,但是該類方法存在計算時間長、感受野有限、缺乏上下文信息、匹配精度不高等問題。基于深度學習的端到端方法具有匹配精度高、網絡結構易于設計、實時性高等優點,但是該類方法訓練數據量較少、計算資源成本較高且跨域遷移性較弱。設計同時滿足匹配精度、實時性、魯棒性、跨域遷移性等要求的立體匹配方法,將是下一步的研究方向。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
