COVID-19 疫情下基于YOLOv4 的安全社交距離風險評估
2022-10-16 12:27:00郭克友賀成博王凱迪王蘇東李雪張沫
計算機工程 2022年10期
關鍵詞:檢測
郭克友,賀成博,王凱迪,王蘇東,李雪,張沫
(1.北京工商大學 人工智能學院,北京 100048;2.交通運輸部公路科學研究院,北京 100088)
0 概述
新型冠狀病毒肺炎(Corona Virus Disease 2019,COVID-19)是由SARS-CoV-2 病毒引起的急性呼吸道傳染病,自2019 年12 月起,許多國家和地區受到了COVID-19 的侵襲[1]。2020 年5 月,世界衛生組織(World Health Organization,WHO)認定COVID-19為“大流行病”[2]。WTO 于2021 年11 月18 日發布的統計數據證實了200 個國家中有2 億感染者,死亡人數高達500 萬人。目前,仍沒有明確的方案或方法消滅新型冠狀病毒,全世界都采取了預防措施以限制該病毒的傳播[3-4]。由于安全的社交距離是公共預防傳染病毒的途徑之一,因此在人群密集的區域進行社交距離的安全評估十分重要。
社交距離的測量旨在通過保持個體之間的物理距離和減少相互接觸的人群來減緩或阻止病毒傳播,在抗擊病毒和預防大流感中發揮重要作用[5],但時刻保持安全距離具有一定的難度,特別是在校園、工廠等場所。在這種情況下,將人工智能、深度學習技術集成至安全攝像頭,開發智能攝像頭技術對行人進行社交距離評估尤為關鍵。針對疫情防范的要求,現階段主要采用人工干預和計算機處理技術。人工干預存在人力資源要求高、風險大、時間成本高等缺點,而在計算機處理技術中,引入人工智能對社交安全距離進行安全評估具有良好的效果。吉林大學齊春陽提出基于單目視覺夜間前方車輛檢測與距離研究[6],采用two-stage 的檢測方式和注意力機制對車輛距離進行安全評估,但該方法的檢測率和速度仍有較大的提升空間。BIAN 等提出一種基于可穿戴磁場的接近傳感系統用于檢測社交距離[7],該系統可達到近100%的準確率,但由于需要極大的資金成本,因此不能很好地進行實際應用。PUNN 等基于微調的YOLOv3 和DeepSort 技術,通過人員檢測和跟蹤來測控COVID-19 社交距離[8],但由于網絡自身具有滯后性,因此該方法存在檢測精度低、網絡模型冗余等缺點。SATHYAMOORTHY 等提出COVID-Robot[9],在擁擠的場景中利用移動機器人監控社交距離限制,該方法在室內場景下起到了良好的監控作用,但鑒于機器人自身的因素限制,通過地平面的角度圖不能及時監控被遮擋的行人。
上述研究致力于結合人工智能對抗COVID-19疫情,這對于改善和促進民眾生活質量具有重要意義[10-11]。本文利用微調的YOLOv4 和DeepSort 算法對行人質點進行提取與跟蹤。在此基礎上,提出行人質點的運動矢量分析算法搜尋長時間未處于安全社交距離的行人,通過鳥瞰視角計算行人個體之間的距離,從而實現安全社交距離檢測。
1 安全社交距離評估模型
1.1 總體框架
面向公眾對于安全社交距離的實際要求,本文以公開數據集——牛津城市中心的數據集作為研究對象,基于YOLOv4 網絡框架對目標行人進行檢測,并提出運動矢量分析算法追溯長時間未處于安全社交距離的行人群體,利用鳥瞰圖對違反社交距離的個體進行連線標定。本文模型的總體框架如圖1所示。
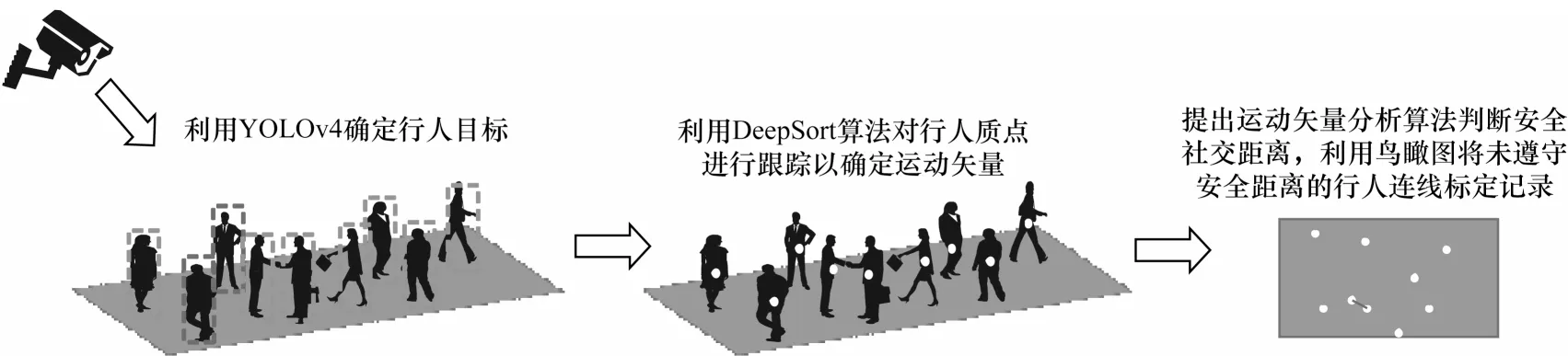
圖1 本文安全社交距離評估模型的總體框架Fig.1 Overall framework of the proposed safety social distance assessment model
1.2 基于YOLOv4 的行人檢測
YOLOv4[12]使用卷積網絡CSPDarknet53 進行特征提取,網絡結構模型如圖2 所示。在每個Darknet53的殘塊行加上跨階段局部結構(Cross-Stage Partial,CSP)[13],將基礎層劃分為兩部分,再通過跨層次結構的特征融合進行合并[14]。同時,采用特征圖金字塔網絡(Feature Pyramid Network,FPN)[15],通過不同層特征的高分辨率來提取不同尺度特征圖進行對象檢測。最終網絡輸出3 個不同尺度的特征圖,在3 個不同尺度特征圖上分別使用3 個不同的先驗框進行預測識別,使得遠近大小目標均能被準確檢測[16]。
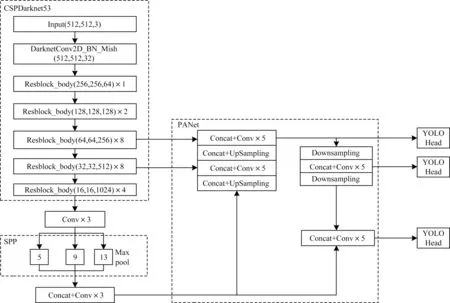
圖2 YOLOv4 網絡結構模型Fig.2 YOLOv4 network structure model
YOLOv4 的先驗框尺寸是考慮PASCALL_VOC、COCO 數據集包含的復雜種類而生成的,并不一定完全適合行人。由于本文旨在研究行人之間的社交距離,因此針對行人目標檢測,利用聚類算法對YOLOv4 的先驗框進行微調[17]。
首先,將行人數據集F依據相似性分為i個對象,即F={f1,f2,…,fi},其中每個對象都具有m個維度的屬性。聚類算法的目的是將i個對象依據相似性聚集到指定的j個類簇,每個對象屬于且僅屬于一個距離最近的類簇中心。初始化j個聚類中心C={c1,c2,…,cj},計算每個對象到每個聚類中心的歐式距離,如式(1)所示:
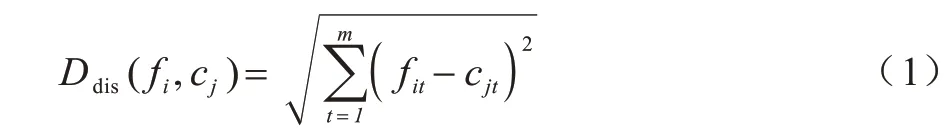
其中:fi表示第i個對象;cj表示第j個聚類中心;fit表示第i個對象的第t個屬性;cjt表示第j個聚類中心的第t個屬性。
然后,依次比較每個對象到每個聚類中心的距離,將對象分配至距離最近的簇類中心的類簇中,得到l個類簇S={s1,s2,…,sl}。聚類算法中定義了類簇的原型,類簇中心就是類簇內所有對象在各個維度的均值,計算公式如式(2)所示:

其中:sl表示第l個類簇中的對象個數。
本文針對先驗框的微調通過Python 語言實現,微調后的先驗框更注重對行人的檢測。
1.3 基于DeepSort 算法的行人跟蹤
YOLOv4 完成行人目標檢測后生成邊界框(Bounding box,Bbox),Bbox 含有包含最小化行人邊框矩形的坐標信息。本文引入DeepSort 算法[18]完成對行人的質點跟蹤,目的是為了在運動矢量分析時計算行人的安全社交距離。
首先,對行人進行質點化計算。質點位置計算公式如式(3)所示:

其中:xcenter、ycenter分別為質點的橫縱坐標;xtop_left、ytop_left分別表示邊界框左上角的橫縱坐標;xlower_right、ylower_right分別表示界框右下角的橫縱坐標。
在確定行人質點位置后,利用DeepSort 算法實現對多個目標的精確定位與跟蹤,核心算法流程如圖3 所示。
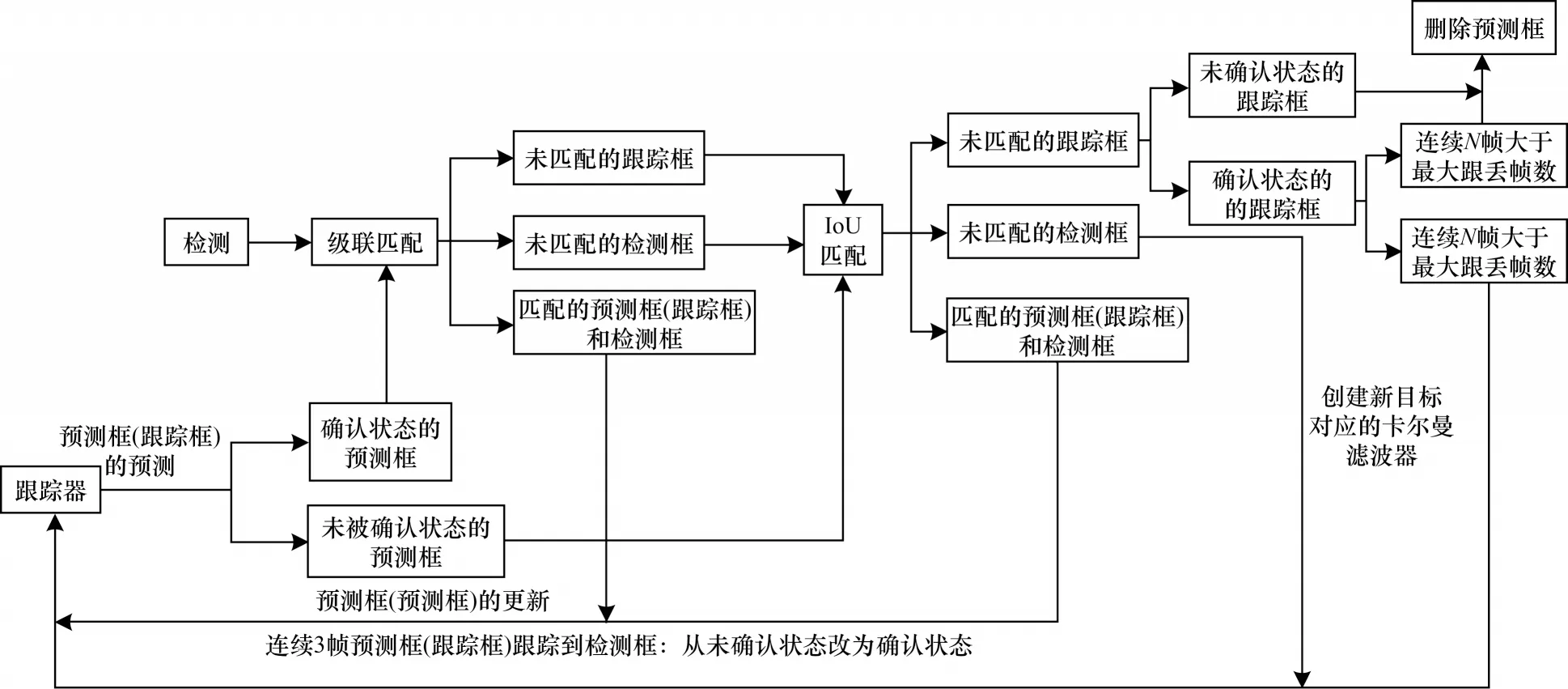
圖3 DeepSort 核心算法流程Fig.3 Procedure of DeepSort core algorithm
DeepSort 算法在Sort 算法[19]的基礎上增加了級聯匹配和新軌跡的確認步驟。首先利用卡爾曼濾波器算法[20]預測行人軌跡Tracks,然后使用匈牙利算法將預測得到的行人軌跡Tracks 和當前幀中檢測到的行人進行匹配(級聯匹配和IoU 匹配),最后通過卡爾曼濾波進行更新。具體計算公式如下:
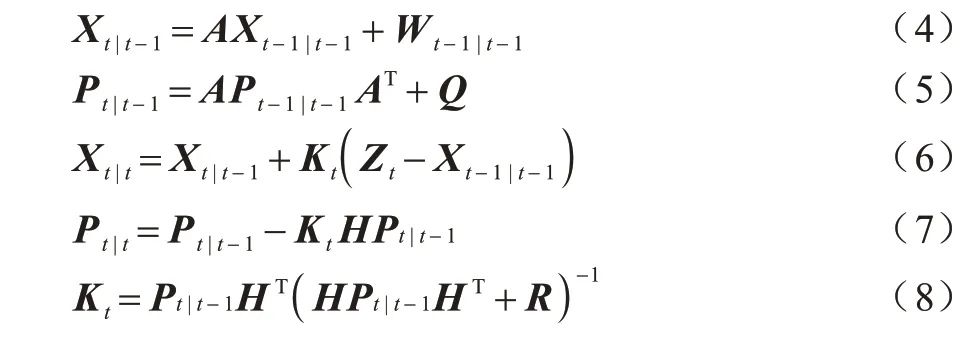
其中:行人質點坐標(x,y)表示為當前狀態Xt|t;Xt-1|t-1為上一時刻目標狀態;Xt|t-1為上一時刻預測出當前時刻的目標狀態;實際檢測到的行人質心坐標表示為觀測狀態Zt;Pt|t-1為當前時刻估計誤差協方差;Pt-1|t-1為上一時刻估計誤差協方差;Pt|t-1為上一時刻預測出當前時刻的估計誤差協方差;A為狀態轉移矩陣;H為觀測矩陣;Kt為卡爾曼濾波的增益矩陣;Wt-1|t-1為上一時刻的激勵噪聲;Q、R分別為激勵噪聲和觀測聲的協方差矩陣。
至此,完成了對行人目標的檢測和跟蹤。在此基礎上,本文按照目前國內疫情情況和政策指導[21]提出運動矢量分析算法,目的在于針對同向行人監控安全距離,避免行人長時間處于非安全的社交距離。
1.4 運動矢量分析算法
三維世界投影至二維透視平面導致對象之間的距離存在不切實際的像素距離,即透視效應。在三維空間中,原始的三個參數(x,y,z)在相機的接收圖像中壓縮為二維(x,y),深度參數(z)不可用,而在低維空間中,使用歐幾里得距離的計算準則進行行人距離估計是錯誤的。為了應用校準的逆透視變換(Inverse Perspective Mapping,IPM),首先需要設置z=0 來進行相機校準以消除透視效應,此外,需要知道相機的位置、高度、視角以及光學規格[22],以最終確定鳥瞰圖下行人的坐標信息[23],從而進一步執行矢量分析算法確定安全距離。可通過OpenCV 庫中的“getPerspectiveTransform”方法計算變換矩陣[24]。通過應用IPM,使世界坐標點(XW,YW,ZW)映射為二維像素點(u,v),計算公式如式(9)所示:
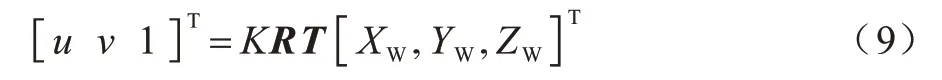
其中:K為相機的固有參數;R為旋轉矩陣;T為平移矩陣。
使用齊次坐標,考慮到相機圖像平面垂直于世界坐標系中的Z通道(即Z=0),三維點與投影結果圖像之間的關系可以表示為:

其中:ni j∈N(N∈R3×4)是變換矩陣,其通過固有矩陣K、旋轉矩陣R和平移矩陣T提供。
最終,從透視空間轉移到反向透視空間也可以用以下標量形式表示以確定二維坐標:
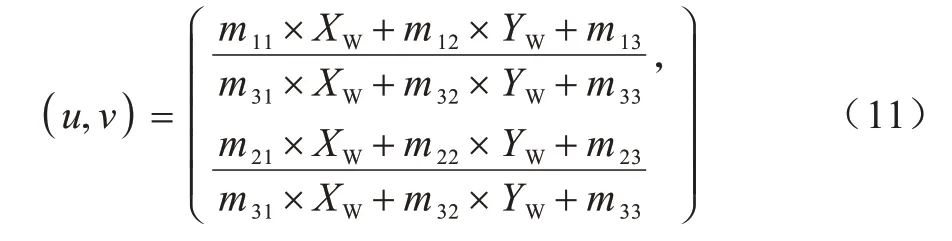
本文提出行人運動矢量分析算法旨在檢測同向行人的安全距離。經計算機視覺處理后,依據相機信息得到行人在鳥瞰圖下的坐標信息lk=(uk,vk),同理可得行人在k-1 時刻的全局位置坐標lk-1=(uk-1,vk-1)。定義行人的運動矢量為MP,如式(12)所示:
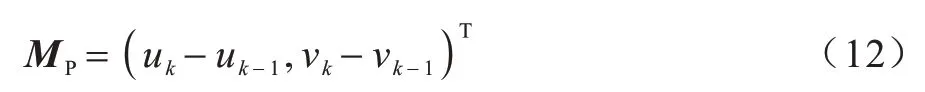
為了獲取當前時刻的運動矢量,設當前時刻的行人位置為lk-1,下一幀行人預測區域的中心位置為lk,由此得到的行人運動矢量如圖4 所示。
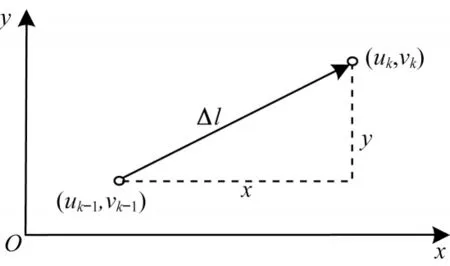
圖4 行人運動矢量Fig.4 Pedestrian motion vector
在圖4 中,Δl的大小即為向量MP的模,物理意義為行人在兩個時刻間的移動距離。由于連續兩幀圖像間的時間間隔很短,因此本文將行人移動的平均移動速率作為當前時刻的行人運動速率vP,其方向即為沿著Δl的方向,夾角θ表示行人相對于自身當前位置的移動方向,由此可以得到速率vP在x軸和y軸方向的投影值,分別為vxk和vyk。至此,可以連續得到行人在當前時刻的移動速率大小以及行人相對于當前位置的移動方向,可用語言描述為行人在(uk,vK)位置以速率vP沿著與x軸呈θ角的射線方向移動。
設定一個行人間安全社交距離的閾值dP,對于安全社交距離的識別,判斷公式如下:

其中:i、j為整數;Vpipj為行人i與行人j之間的位置向量;參數dP取值為1,小于閾值表示行人間距離小于1 m,為非安全社交距離。在安全社交距離風險評估算法中,對每個行人,以當前的空間位置坐標為圓心、dP為半徑的范圍內進行搜索,其運算復雜度與for 的循環控制變量呈一次線性關系,即O(n)。如果含有行人,則再對行人的運動矢量進行分析。成群行走的行人通常具有相似的移動方向和相近的移動速率,運動矢量判斷的計算公式如下:
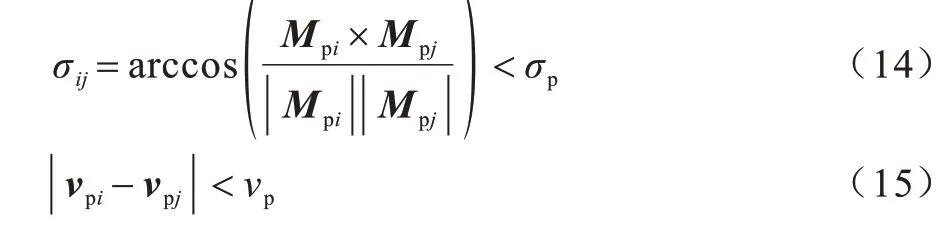
其中:i、j為整數;σij為行人i與行人j運動矢量的夾角;設定一個閾值σp為π18,小于閾值表示行人間具有相同的移動方向。
2 實驗結果及分析
本文實驗的軟件環境使用Ubuntu 16.04 LTS 操作系統及Pytorch 深度學習框架。在硬件配置中,CPU 使用英特爾酷睿i7-7900X,GPU 使用英偉達GTX Titan X 16 GB 顯存。
2.1 實驗數據集
實驗使用Caltech 行人數據庫[25]和戴姆勒行人檢測標準數據庫[26]這兩個采用車載攝像頭的公開數據集,將“person”子集作為YOLOv4 行人檢測模型的訓練集,在標準通用測試集Oxford Town Centre Dataset 上進行驗證檢測。
Caltech行人數據庫是目前規模較大的行人數據庫,包含10 h 左右的視頻,視頻的分辨率為640×480 像素,30 frame/s。標注約250 000 幀,總計時長約為137 min,對350 000 個矩形框和2 300 個行人進行標注,此外,還對矩形框之間的時間對應關系及遮擋的情況進行標注。Caltech 數據庫圖像示例如圖5 所示。

圖5 Caltech 行人數據庫圖像示例Fig.5 Example of image in Caltech pedestrian database
戴姆勒行人檢測標準數據庫分為檢測和分類兩個數據集。其中:正樣本包含18×36 像素和48×96 像素的圖片15 560 張,行人的最小高度為72 個像素;負樣本共計6 744 張,分辯率為640×480 像素或者360×288 像素。測試集為一段27 min 左右的視頻,分辨率為640×480 像素,共計21 790 張圖片,包含56 492 個行人。分類數據庫有3 個訓練集和2 個測試集,每個數據集有4 800 張行人圖片和5 000 張非行人圖片,另外還有3 個輔助的非行人圖片集,各有1 200 張圖片。戴姆勒行人檢測標準數據庫圖像示例如圖6 所示。

圖6 戴姆勒行人檢測標準數據庫圖像示例Fig.6 Example of image in Daimler pedestrian detection standard database
2.2 檢測跟蹤實驗
重新設計錨點框,采用K-means 聚類算法對數據集進行維度聚類,得到大、中、小3種尺度共計9個錨框,大小分別為(320,180)、(200,136)、(155,81)、(103,55)、(69,44)、(63,140)、(46,33)、(28,26)、(25,63)。依次分配大、中、小的檢測單元,之后對網絡進行訓練,采用SGD 優化器,初始學習率0.000 1,衰竭系數0.000 5,批大小設置為16,其余參數為默認參數,經過2 500 次迭代后進行測試,丟失率接近10%。對YOLOv4 模型進行微調后,在NVIDIA Geforce GTX TITAN 上分別運行微調后YOLOv4 算法和原YOLOv4 算法,檢測結果如圖7 和圖8 所示。

圖7 微調后YOLOv4 算法的行人檢測結果Fig.7 Pedestrian detection result of fine-tuned YOLOv4 algorithm

圖8 原YOLOv4 算法的行人檢測結果Fig.8 Pedestrian detection result of original YOLOv4 algorithm
在圖7、圖8 中,行人年齡分布方面包含小孩、年輕人和老人,狀態方面包括騎自行車的人、被部分建筑物遮擋的人、推嬰兒車的人等各類行人。YOLOv4 在檢測嬰兒以及被遮擋的行人方面效果不佳,如圖8 中被遮擋的行人、嬰兒和特征相似的行人存在較高的漏檢率。但是微調后的YOLOv4 算法在檢測遮擋的行人以及嬰兒等目標時可獲得良好的效果,并且有較強的置信度,同時誤檢和漏檢情況較少。
為檢驗微調后YOLOv4 在檢測數據集上的檢測效果,將其與Fast R-CNN、Faster R-CNN、SDD、YOLOv3等算法進行對比,以平均精度均值(mean Average Precision,mAP)和幀率(FPS)作為評價指標。mAP 的值越高,說明算法對目標的檢測效果越好;FPS 越高,代表每秒輸出的畫面越多,說明實時檢測效果越好。實驗結果如表1 所示,從中可以看出:微調后YOLOv4相較于其他算法mAP 值和FPS 有所提高,為之后的社交距離風險評估提供了保障;由于本文采用是YOLO系列算法,參數量和FLOPS 均大幅降低,因此提升了速度。
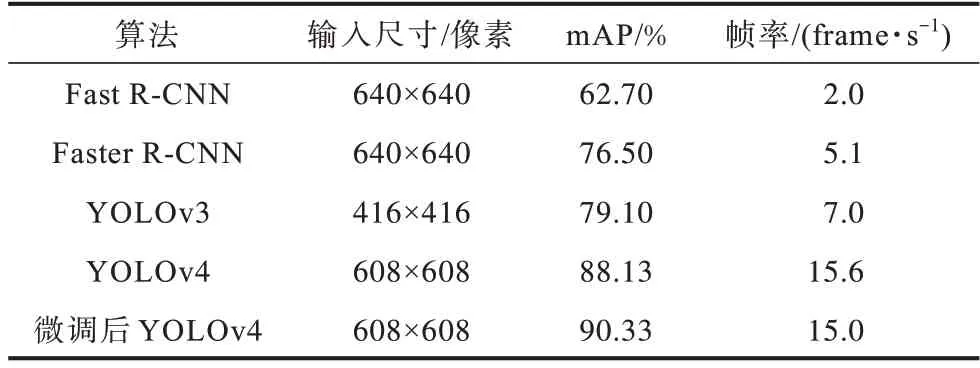
表1 微調后YOLOv4 算法與其他算法的性能對比Table 1 Performance comparison of fine-tuned YOLOv4 algorithm with other algorithms
在完成對視域內行人的檢測后,通過篩選出特征點將人抽象為質點,利用DeepSort算法中的卡爾曼濾波和匈牙利算法即可得到該行人的移動路徑。微調后YOLOv4 與原YOLOv4 算法的行人跟蹤結果分別如圖9 和圖10 所示。實驗結果表明,原YOLOv4算法對于行人的跟蹤有較強的魯棒性,但是對嬰兒等小目標的識別存在一定的漏檢率,而微調后YOLOv4 算法在小目標識別方面性能得到了大幅提升,提高了小目標的檢測效果。

圖9 微調后YOLOv4 算法的行人目標跟蹤結果Fig.9 Pedestrian target tracking result of fine-tuned YOLOv4 algorithm

圖10 原YOLOv4 算法的行人目標跟蹤結果Fig.10 Pedestrian target tracking result of original YOLOv4 algorithm
2.3 運動矢量分析及安全距離評估
在逆變換空間,利用線性距離表示每個人的位置,依據視域內各行人運動矢量間的關系對行人進行安全距離評估,最終算法結果如圖11 所示,嵌入式系統將識別出違反安全社交距離的行人并用直線進行連接以作警示。

圖11 安全距離檢測評估結果Fig.11 Safety distance detection and evaluation result
針對圖11 中標記部分,在不同時間段內對兩人至多人的行人行走狀態進行判斷分析。可以看出:在行人密度正常的情況下,本文算法具有一定的可行性。圖11(a)、圖11(b)結果表明,兩人安全距離檢測評估判斷具有較高的準確性;圖11(c)結果表明,由于行人群體在前幾秒有相似的位移和速度,因此將其歸為違反安全社交距離人群的一部分,在之后的判斷中根據算法結果將其排出被選范圍;圖11(d)結果表明,在長椅的遮擋下,本文算法在噪音處理后以及背景與行人較為相似的狀態下存在漏檢,但對于其他情況具有一定的可實施性。最終利用OpenCV繪制成鳥瞰圖,如圖12所示,在虛線框圖中,利用鳥瞰圖對行人質點進行連線警示。

圖12 測試集的鳥瞰圖Fig.12 Aerial view of the test set
采用人工安全社交距離標定,將違反安全距離規定的人群視為“群組”,統計前1 000 幀的行人總數、實際群組和判斷群組繪出三維統計圖,如圖13所示。可以看出,本文算法的“群組”識別準確率達到88.23%,視頻的幀率為15 frame/s,可滿足校園、工廠等封閉環境的防疫需求。
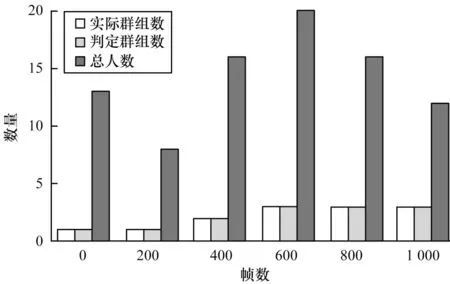
圖13 每幀的總人數及群組的判斷Fig.13 Judgment of total number of people and groups per frame
3 結束語
本文結合目前COVID-19 疫情狀態,在文獻[8]方法的基礎上進行改進,利用鳥瞰視角開發一個基于CNN 的深度社交距離監控模型,結合CSPDarknet53主干網絡、SPP 空間金字塔池化層以及PANet 頸部、Mish 激活函數和聚類算法構建行人檢測網絡框架,基于DeepSort 算法進行行人跟蹤,最后提出運動矢量算法并利用OpenCV 庫函數構建鳥瞰圖。實驗結果表明,該算法能夠實現對社交距離風險的有效評估,可滿足校園、廣場、工廠等環境的防疫需求。后續將對YOLOv4 在智能移動平臺上的部署做進一步優化,提高圖像的像素大小、mAP 和幀率,同時減少視頻流傳輸過程中的視頻幀損失。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
