基于混合注意力機制的中文機器閱讀理解
2022-10-16 12:27:08劉高軍李亞欣段建勇
計算機工程 2022年10期
劉高軍,李亞欣,段建勇
(1.北方工業大學 信息學院,北京 100144;2.北方工業大學CNONIX 國家標準應用與推廣實驗室,北京 100144)
0 概述
機器閱讀理解是自然語言處理領域的一個極具挑戰性的任務,一直受到研究人員的關注。深度學習技術的成熟以及數據的多樣化推動了機器閱讀理解技術的快速發展,基于深度學習建立閱讀理解模型已成為目前普遍采用的方法。
機器閱讀理解是指讓機器通過閱讀文本回答相應的問題。機器閱讀理解技術通過訓練模型幫助用戶從大量的文本中快速、準確地找到答案。根據答案類型的不同,機器閱讀理解任務可分為4類[1]:完形填空式任務要求模型從候選答案集合中選擇一個正確的詞填至問題句,使文章變得完整;抽取式任務要求模型能根據提出的問題在文章中抽取一個連續片段作為答案,輸出答案在上下文中的起始位置和結束位置;多項選擇式任務需要從候選答案集合中挑選正確答案;在自由作答式任務中,答案的類型不受限制。其中,抽取式閱讀理解任務的形式相對靈活,能夠適用于現實中大部分場景,如搜索引擎、智能問答等。
預訓練語言模型BERT[2]的出現使得一些模型在閱讀理解任務上的表現接近甚至超過了人類,推動了機器閱讀理解的研究進入到新的階段。BERT 模型優秀的表現受到了眾多專家、學者的高度關注,近年涌現出了很多基于BERT 改進的模型,如ALBERT[3]、RoBERTa[4]等,使用預訓練模型已成為機器閱讀理解的發展趨勢。由于預訓練模型只能學習到文本的淺層語義匹配信息,目前大多數模型都采取了預訓練語言模型與注意力機制相結合的方式,即通過預訓練模型獲取相應表示,再使用注意力機制進行推理,從而捕捉文本的深層語義信息,預測出更加準確的答案。但原始的預訓練模型是針對英文語言設計的,無法有效處理中文文本。
本文提出一種基于混合注意力機制的中文機器閱讀理解模型。該模型使用混合注意力機制進行推理,并結合多重融合機制豐富序列信息,最終在CMRC2018 中文閱讀理解數據集上進行了實驗。
1 相關工作
1.1 結合注意力機制的機器閱讀理解
BAHDAUAU等[5]將注意力機制用于機器翻譯任務,這是注意力機制第一次應用于自然語言處理領域。引入注意力機制后,不同形式的注意力機制成為基于神經網絡模型在閱讀理解任務上取得好成績的一個關鍵因素。
2015年,HERMANN等[6]提出The Attentive Reader和The Impatient Reader 兩個基于神經網絡的模型,將注意力機制應用于機器閱讀理解的任務中,通過注意力機制得到問題和文章之間的交互信息。隨后提出的Attention Sum Reader 模型[7]以及The Stanford Attentive Reader 模型[8]均著重于提升注意力模型中問題和文章的相似度計算能力。
在前期模型中使用的注意力機制大多較為簡單,對文本理解能力不足,無法對文章和問題進行有效交互。針對這一問題,研究人員在深層注意力機制方面做了大量的研究。BiDAF 模型[9]同時計算文章到問題和問題到文章兩個方向的注意力信息,捕獲問題和文章更深層的交互信息。Document Reader 模型[10]將詞性等語法特征融入詞嵌入層,經過模型處理得到答案。R-Net 模型[11]在計算問題和文章的注意力之后加入自匹配注意力層,對文章進行自匹配,從而實現文章的有效編碼。FusionNet 模型[12]融合多個層次的特征向量作為輸入。
2017 年,谷歌的研究人員提出了Transformer 模型[13],該模型僅依靠自注意力機制在多個任務上取得了較好結果,證明注意力機制擁有較強的提取文本信息的能力。2018 年,谷歌團隊提出了基于雙向Transformer 的預訓練語言模型BERT。這種雙向的結構能夠結合上下文語境進行文本表征,增強了模型的學習能力。BERT 的出現刷新了11 個自然語言處理任務的最好結果,使得預訓練語言模型成為近年來的研究熱點。
1.2 中文機器閱讀理解
中文機器閱讀理解由于起步較晚,缺少優質中文數據集,發展相對緩慢。在近年來發布的各種中文機器閱讀理解數據集的影響下,越來越多的研究人員致力于中文領域的探索。
2016 年,CUI等[14]發布了大規模填空型中文機器閱讀理解數據集People Daily and Children’s Fairy Tale,填補了大規模中文閱讀理解數據集的空白。2017 年,CUI等[15]在此數據集的基礎上提出了CMRC2017 數據集,作為第一屆“訊飛杯”中文機器閱讀理解評測比賽的數據集。
2018 年,CUI等[16]發布了抽取型中文機器閱讀理解數據集CMRC2018,該數據集作為第二屆“訊飛杯”中文機器閱讀理解評測比賽使用的數據集,也是本文實驗使用的數據集。該數據集由近兩萬個人工標注的問題構成,同時發布了一個需要多句推理答案的挑戰集。
HE等[17]于2018 年提出DuReader 數據集,該數據集共包含20 萬個問題、100 萬篇文章和超過42 萬個人工總結的答案,數據來源更貼近實際,問題類型豐富,是目前最大的中文機器閱讀理解數據集。
徐麗麗等[18]搜集全國各省近10 年高考題及高考模擬題中的981 篇科技文章語料,構建了4 905 個問題,同時搜集5 萬篇新聞語料,構造10 萬個補寫句子類選擇題語料。SHAO等[19]提出了繁體中文機器閱讀理解數據集DRCD,該數據集包含從2 108 篇維基百科文章中摘取的10 014 篇段落以及超過3 萬個問題。中文機器閱讀理解領域受到研究人員越來越多的關注,不斷有優秀的方法與模型被提出,呈現較好的發展趨勢。
2 本文模型結構
為了提高模型對中文文本的理解能力,本文提出一種基于混合注意力機制的中文機器閱讀理解模型。首先經過編碼層得到序列表示,使用混合注意力機制提取文本中可能與答案有關的關鍵信息,然后結合多重融合機制融合多層次的序列信息,經過雙層BiLSTM建模后傳入輸出層,最終輸出正確答案所在位置。
本文模型包含編碼層、混合注意力層、融合層、建模層以及輸出層,其結構如圖1 所示。
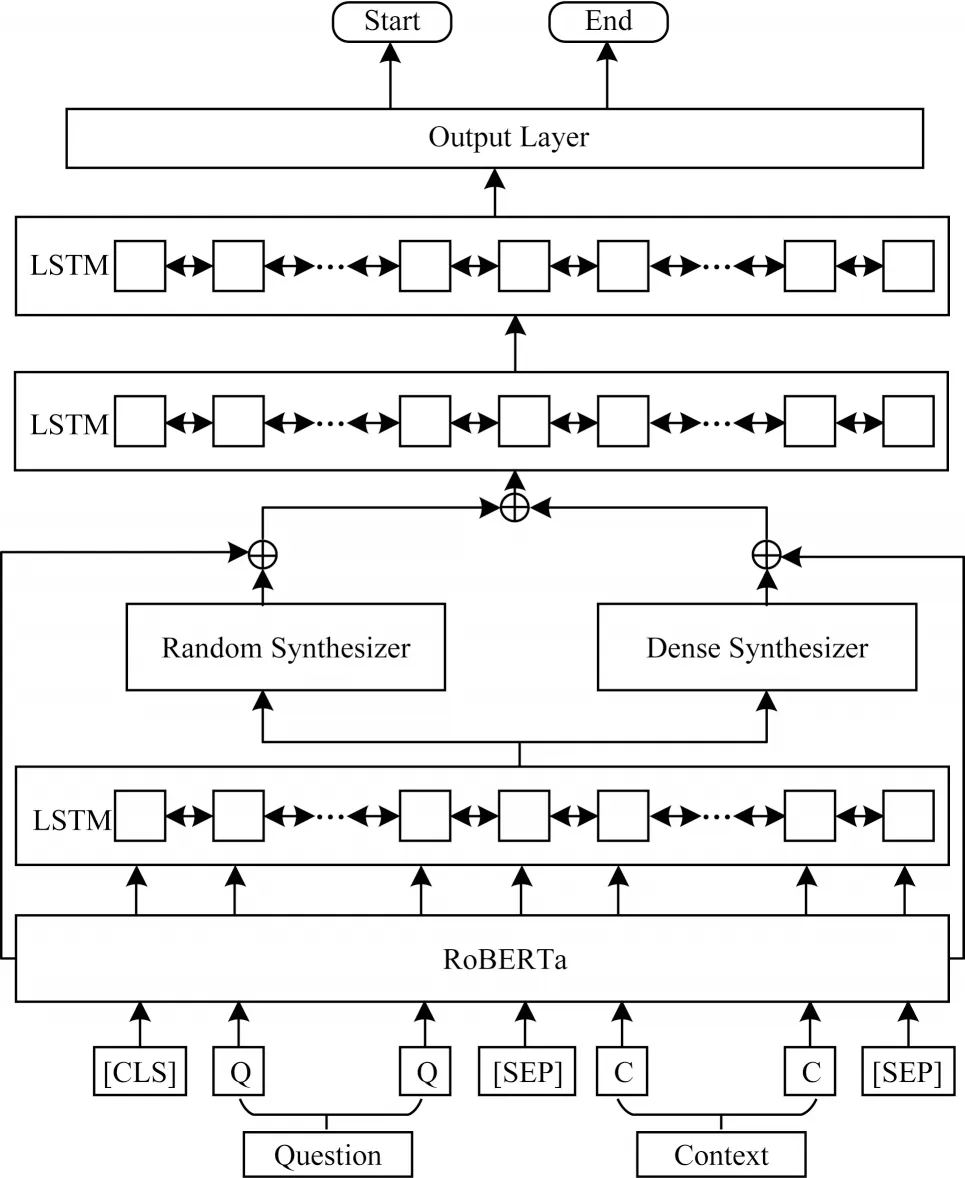
圖1 本文模型結構Fig.1 The structure of the proposed model
2.1 編碼層
編碼層通過中文預訓練語言模型RoBERTa[18]對問題和文章進行編碼。RoBERTa 模型仍使用BERT 的基本結構,在模型訓練時有以下4 個方面的差異:
1)使用動態掩碼機制。
2)移除BERT 中采用的下一句預測訓練任務。
3)使用更大Byte 級別的文本編碼方式。
4)使用更大批次以及更大規模的數據進行訓練。
可以看出,RoBERTa 模型在多個任務上的表現優于BERT。
編碼層將問題和文章拼接后的文本輸入到RoBERTa 模型中,經過分詞器處理后的每一個詞稱為token,最終RoBERTa 模型輸入的編碼向量為token 嵌入、位置特征嵌入以及用以區分問題和文章的分割特征嵌入之和。本文使用的RoBERTa 模型由12 層Transformer 編碼器組成,該模型取最后一層編碼輸出作為文本嵌入表示,得到的向量表示H如式(1)所示:

其中:hi為序列中第i個token 經過RoBERTa 編碼后的向量表示;N為序列長度。
利用BiLSTM 進一步加深文本的上下文交互,捕捉文本序列的局部關系,如式(2)所示:

2.2 混合注意力層
混合注意力層基于混合注意力機制處理編碼層得到的上下文向量Hl,進而學習文本中更深層次的語義信息,該層是模型的核心部分。該層的混合注意力機制由文獻[10]中提出的兩種自注意力機制的變體注意力Random Synthesizer 和Dense Synthesizer 組成。傳統的自注意力機制通過計算序列中每一個token 與序列中其他token 的相關度得到權重矩陣R,再將歸一化后的權重和相應的鍵值進行加權求和,得到最終的注意力表示。這里的相關度一般通過點積得分矩陣體現,點積自注意力的主要作用是學習自對齊信息,即token對的交互信息。自注意力機制通過比較序列本身捕捉序列和全局的聯系,獲取文本特征的內部相關性,其簡化結構如圖2 所示。
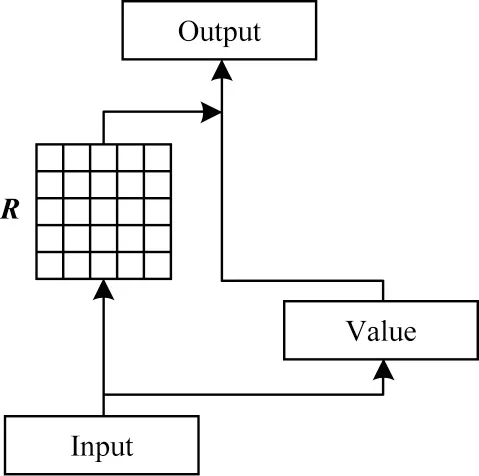
圖2 自注意力機制結構Fig.2 Structure of self-attention mechanism
這種從token-token 交互中學習到的注意力權重有一定的作用,但也存在缺點。傳統自注意力機制中的權重包含實例中token 對的交互信息,通過計算點積的方式得到每個token 與序列其他token 的相對重要度。這種方式過度依賴特定實例,僅通過token 對之間的相關度決定答案的概率是不穩定的,缺乏一致的上下文聯系,很大程度上會受不同實例影響,不能學習到更多的泛化特征。文獻[19]的實驗結果表明,與傳統自注意力機制相比,Synthesizer 注意力機制得到的權重曲線更加平滑。受其啟發,本文認為這種合成權重矩陣的自注意力機制不會從特定的token 中獲益,可以在提取序列關鍵信息的同時減小因不同實例產生的影響,因此該層使用這種合成注意力來提取文本深層信息。這種合成矩陣的注意力與點積注意力或考慮上下文的注意力不同,它不依賴于token-token 交互的方式生成權重矩陣,受特定樣本的影響較小,能夠學習到較為穩定的權重值。
1)Random Synthesizer 使用隨機值初始化權重矩陣R,并隨著模型一起訓練這些值。這種方式下所有實例均使用相同的對齊模式,不依賴輸入的token,不會因特定實例而影響權重矩陣,因此Random 關注的是全局的注意力權重。
2)Dense Synthesizer 通過對輸入序列進行線性變換得到權重矩陣R,序列中的每個token 為自己相應位置的token獨立預測權重,即按序列順序處理每個向量。Dense 學習的是局部的注意力權重,權重矩陣的生成需要依賴樣本的每一個token,因此它能關注到序列中每一個token 攜帶的信息。線性變換方式如式(3)所示:
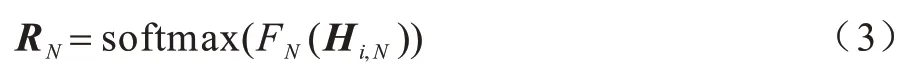
其中:參數化函數FN(·)由兩層前饋層和ReLU 激活函數組成;i為Hi,N的第i個token;N為序列長度。
這兩種自注意力使用不同方法合成權重矩陣,分別從不同角度提升獲得信息的質量。因此,該層采取兩種注意力混合使用的策略,能夠結合全局與局部注意力的優勢,不會過度依賴輸入樣本,既能從原始序列中獲取特征信息,又能減弱不同實例對模型的影響,可以更加有效地處理相關任務。
將上一層得到的向量Hl分別輸入到Random Synthesizer 和Dense Synthesizer 中,與權重矩陣R加權求和,得到兩組具有深層語義的向量表示和,如式(4)、式(5)所示:

其中:和分別為Random Synthesizer 和Dense Synthesizer 輸出的表示;和分別表示Random Synthesizer 和Dense Synthesizer 的權重矩陣;LN(·)為一層線性層;LN(HN)等同于注意力機制中的V矩陣。
2.3 融合層
為防止模型過于關注某一部分而過濾掉文本其他特征信息,融合層結合多重融合機制豐富序列表示。
首先,將上層得到的兩組注意力Hr和Hd分別與RoBERTa 模型得到的序列H進行融合,如式(6)、式(7)所示,實現在不丟失原始信息的基礎上更加關注關鍵信息。
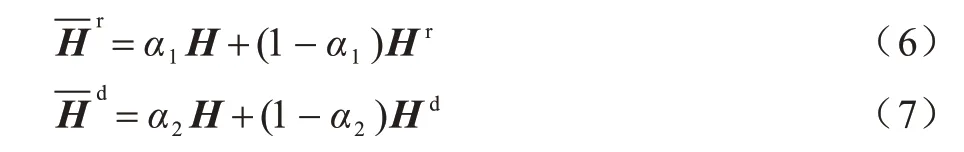
其次,對處理后的兩組序列進行融合,得到混合語義表示,如式(8)所示:

在式(6)~式(8)中:α1、α2、α3均為模型訓練參數;分別為兩組注意力與序列H融合后的表示;為最終融合后的輸出表示。
最后,輸出結合全局和局部的注意力信息,融入一定比例的全局上下文信息,能夠有效降低實例不同對信息造成的影響。以上3 次均融合采用同一種策略。
2.4 建模層

2.5 輸出層
輸出層將建模后的序列Hf輸入到線性層,得到針對答案開始位置和結束位置預測的兩個輸出,由softmax 函數計算概率得到最終預測答案在文章中的起止位置s和e,如式(11)所示:
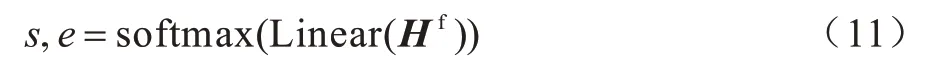
3 實驗結果與分析
3.1 數據集
本文使用CMRC2018 評測任務數據集以及DRCD數據集進行實驗。兩個數據集的格式相同,均用于抽取式閱讀理解任務。其中,CMRC2018 數據集為簡體中文數據集,DRCD 數據集為繁體中文數據集。除對比實驗外,其余幾組實驗均使用CMRC2018 數據集。以CMRC2018 數據集為例,數據集實例如下:
[Document]白蕩湖位于中國安徽樅陽縣境內,緊鄰長江北岸,系由長江古河床擺動廢棄的洼地積水而成。湖盆位置介于北緯30°47′~30°51′、東經117°19′~117°27′。白蕩湖原有面積近100 km2,經過近五十年的圍墾,目前面積縮小為39.67 km2,平均水深3.06 m,蓄水量1.21×109m3。通過白蕩閘與長江連通,是長江重要的蓄洪湖之一。湖水補給主要依賴降水與長江倒灌,入流的羅昌河、錢橋河等均為季節性溪流,入水量較小。白蕩湖是重要的水產養殖基地,盛產各種淡水魚類與水禽,其中以大閘蟹產量最大。每年冬季開啟白蕩閘排干湖水捕魚,次年5 月左右再引長江水倒灌,水位至7 月、8 月份達到最高。
[Question]白蕩湖是怎樣形成的?
CMRC2018 數據集和DRCD 數據集由幾萬個真實問題組成,篇章均來自中文維基百科,問題由人工編寫。兩個數據集規模分別如表1、表2 所示。
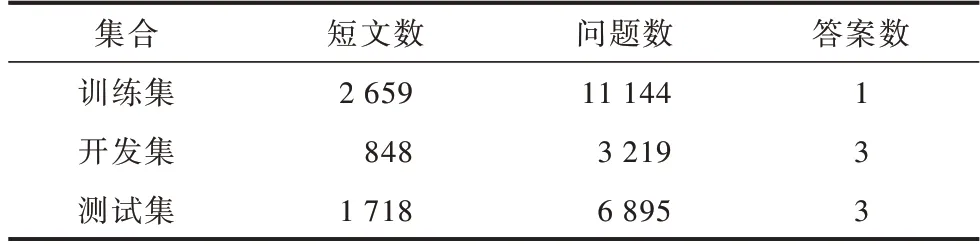
表1 CMRC2018 數據集規模Table 1 CMRC2018 dataset size
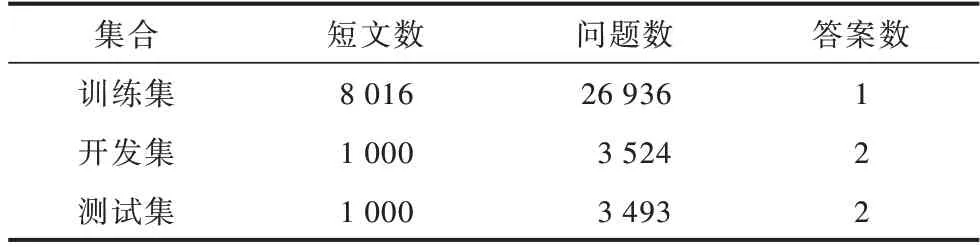
表2 DRCD 數據集規模Table 2 DRCD dataset size
3.2 實驗配置
本文實驗采用GPU 進行訓練,開發語言為Python,深度學習框架為Pytorch。由于本文模型加入注意力層以及BiLSTM,增加了序列之間的交互過程,因此相比基線模型,本文模型的訓練速度更加緩慢。實驗參數如表3 所示。
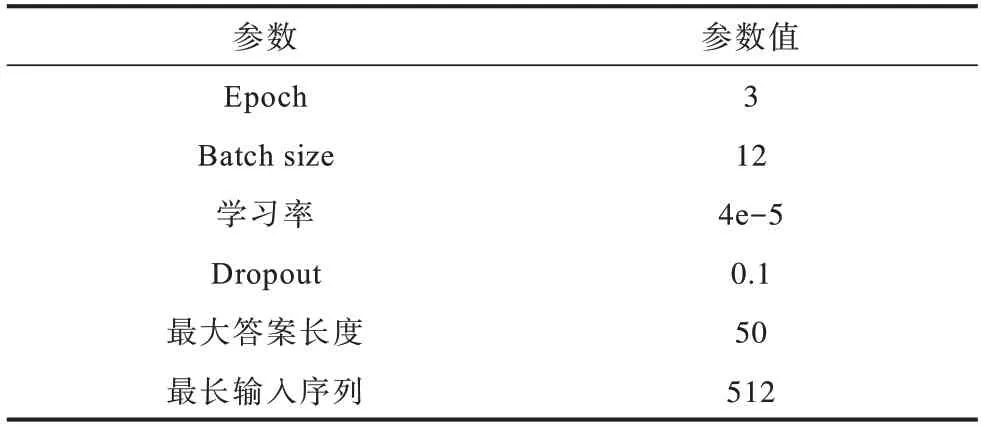
表3 實驗參數Table 3 Experimental parameters
3.3 評價指標
本文采用EM 值和F1 值作為評價指標。EM 值為精確匹配度,計算預測答案與真實答案是否完全匹配。F1 值為模糊匹配度,計算預測答案與標準答案之間的匹配程度。這兩個指標通常作為抽取式機器閱讀理解的評價指標。
3.4 結果分析
3.4.1 對比實驗
為驗證本文提出的模型在中文機器閱讀理解任務的有效性,將本文模型與以下模型進行實驗對比:
1)BERT-base(Chinese)和BERT-base(Multilingual)為CMRC2018 評測任務選用的基線模型。
播種兩周后,在田間按小區取水稻葉片混樣,并提取DNA。水稻基因組DNA的提取采用李進波等[5]改進的CTAB法。
2)RoBERTa-wwm-ext[21]為本文選取的基線模型,該模型針對中文改進預訓練模型中的全詞掩碼訓練方法。
3)MacBERT-base 為文獻[22]提出的預訓練模型,該模型主要針對mask 策略對RoBERTa 進行改進。
表4、表5所示為本文模型與其他模型在CMRC2018數據集與DRCD 數據集上的EM 值和F1 值。其中RoBERTa-wwm-ext(*)為本文復現的結果。
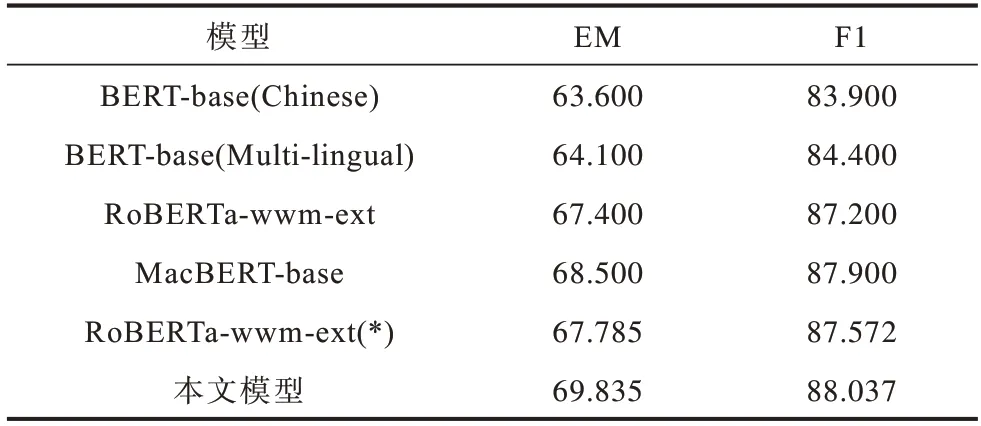
表4 不同模型在CMRC2018 數據集上的實驗結果Table 4 Experimental results of different models on the CMRC2018 dataset %
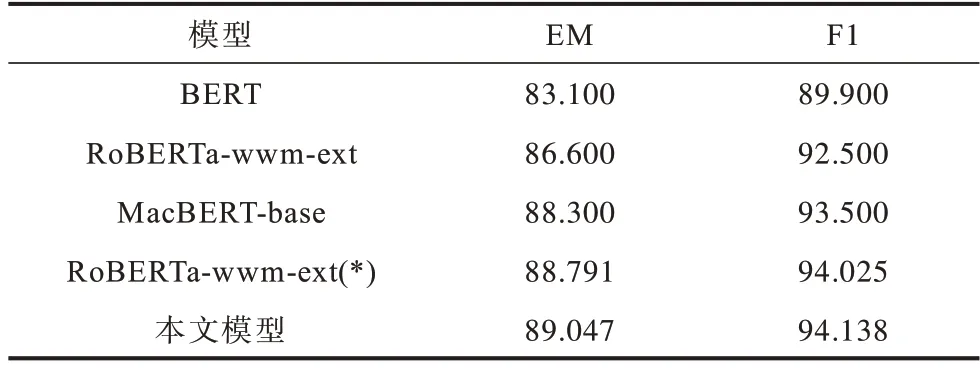
表5 不同模型在DRCD 數據集上的實驗結果Table 5 Experimental results of different models on the DRCD dataset %
本文模型在CMRC2018 數據集的EM 值和F1 值分別達到69.835%和88.037%,相比復現的基線模型分別提高了2.05 和0.465 個百分點,在DRCD 數據集上的EM 值和F1 值分別達到89.049%和94.138%,相比基線模型分別提高了0.256 和0.113 個百分點,在兩個數據集上的表現均優于其他對比模型。實驗結果表明,本文模型在性能上有顯著提升,能夠學習到文本的深層語義信息,有效改進了預訓練語言模型。
3.4.2 消融實驗
為研究混合注意力以及多重融合機制對模型的貢獻,設計消融實驗進一步分析本文模型。由于多重融合機制需要混合注意力的輸出信息,因此本節實驗考慮兩部分共同作用的影響,實驗結果如表6所示。
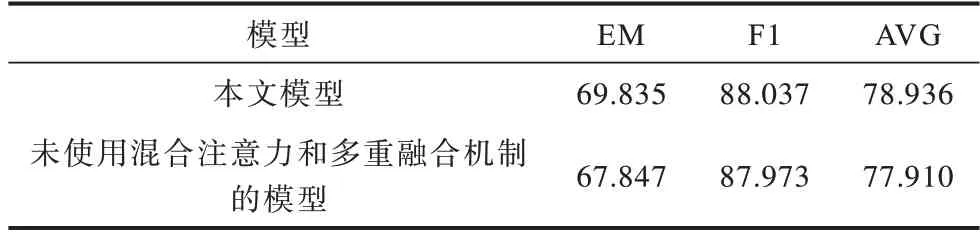
表6 消融實驗結果Table 6 Ablation experiment results %
從表6 可以看出,當模型未使用混合注意力和多重融合機制時,EM 值和F1 值分別下降了1.988 和0.064 個百分點。結果表明,使用混合注意力機制以及多重融合機制能夠加深對文本的理解,防止模型隨著訓練遺失原有信息,使模型更好地預測答案。
3.4.3 不同注意力策略實驗分析
為了驗證變體注意力以及混合策略對模型的影響,本文針對傳統自注意力機制以及單一注意力機制兩個方面設計對比實驗,結果如表7 所示。
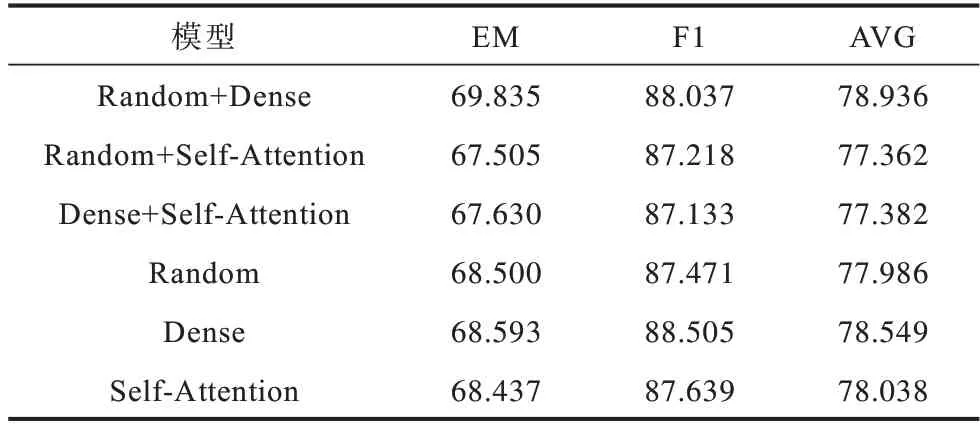
表7 不同注意力策略的實驗結果Table 7 Experiment results of different attention strategies %
表7 所示為使用不同注意力方法對模型的影響,其中,Random 和Dense分別表示Random Synthesizer注意力和Dense Synthesizer 注意力,“+”表示混合使用兩種注意力,Self-Attention表示使用傳統自注意力機制。實驗結果分析如下:
1)傳統自注意力的表現略低于Dense Synthesizer,證明以往利用token 對生成權重矩陣的方式并沒有合成矩陣有競爭力,使用合成注意力能夠降低過多關注局部注意力的影響,提升模型性能。
2)綜合比較EM 值和F1 值,混合使用Random Synthesizer 注意力和Dense Synthesizer 注意力的方法效果最好。Random Synthesizer 與Dense Synthesizer兩種注意力在合成權重矩陣時輸入的信息不同,因此聯合使用這兩種方法可以學習到綜合注意力權重,能夠進一步提升模型性能。對比結果發現,使用單一Dense Synthesizer 注意力的F1 值最高,混合注意力加入一定比例的全局注意力,減少樣本不同導致的權重波動,因此會在一定程度上影響個別樣本的準確度。
3.4.4 注意力層和融合層位置實驗分析
為了研究混合注意力層和融合層加入位置的不同對模型的影響,本文設置了注意力層和融合層位置對比實驗。RoBERTa+Att+BiLSTM 對應于將注意力層和融合層加在RoBERTa 模型之后,實驗結果如表8 所示。

表8 注意力層和融合層不同位置的實驗結果Table 8 Experiment results of different positions of attention layer and fusion layer %
通過實驗發現,混合注意力層和融合層的位置在第1 個BiLSTM 和序列建模層之間表現更好,表明對使用BiLSTM 建模后的序列進行自注意力處理,能較好地理解文章,更有效地預測答案。
4 結束語
本文對抽取式中文機器閱讀理解任務進行研究,提出一種基于混合注意力機制的閱讀理解模型。該模型使用兩種自注意力機制的變體模型對序列進行處理,加深對文本語義信息的理解,并對輸出的注意力進行多層次的融合,使得輸出的序列攜帶更加豐富的信息。實驗結果表明,本文方法提升了模型的理解能力,改進了模型對語義的獲取方法,同時保留了原序列的信息特征,提高了預測答案的準確率。目前的中文機器閱讀理解模型多數存在答案邊界不準確的問題,下一步通過使用分詞器優化模型輸入,將分詞結果作為輸入特征加入到序列中,從而優化答案邊界。此外,結合雙向注意力機制,融合文章到問題以及問題到文章雙向的注意力優化模型結構,加深對文本的理解。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
