基于層次狀態機的服務組合
2022-10-17 14:05:12朱雪峰
計算機工程與設計 2022年10期
張 颯,朱雪峰
(中國石油大學(北京) 石油數據挖掘北京市重點實驗室,北京 102249)
0 引 言
Web服務組合方案設計分為組合方案設計和組合方案優化兩個階段。如何將不同的服務有效地組合在一起,實現功能需求,繼而在優化階段,針對非功能性屬性對候選服務進行篩選,是web服務組合研究的重點。
文獻[1]采用擴展工作流模型,將抽象服務替換為實際的wsc(web service composition)方案。基于工作流模型研究的重點之一在于如何克服動態環境的影響。文獻[2]利用petri網建模,建立了服務組合描述與狀態圖的一一映射關系。但是petri不易理解,不能在網中體現數據流。文獻[3]的研究基于π演算是進程代數在wsc研究中應用的代表。根據文獻[4],局部優化方法從所有候選服務中,可以找到局部較優的服務方案,但是會忽略非功能屬性的需求;全局優化方法可以找到最優方案,但這個方法的時間花銷隨規模增大;運用啟發式算法的優化方法,可以以較小的開銷找到較優的結果,但沒有考慮到服務之間的邏輯關系。
通過對比web組合方案的研究現狀可以發現,對web服務組合設計建模,進行服務組合優化的研究存在以下問題:①已有的服務自動組合的研究工作主要集中在通過形式化描述、圖例方法得到服務的組合和執行順序,在這種情形下,由于空間有限和狀態過多就有可能造成狀態爆炸;②關于組合優化的研究,上述方法并沒有考慮到用戶對于服務提出的約束條件,忽略了服務之間的邏輯關系。
1 Web服務組合及相關技術
單一的web服務可以實現一定的功能,但是單一的服務所能起到的作用相對而言還是有限的。通過服務組合,可以構建出應用場景更加多樣,功能更加強大的服務系統。web服務組合方案設計分為組合方案設計和組合方案優化兩個階段。組合方案設計階段主要為業務流程建模,優化階段主要是基于QoS或者是用戶的其它非功能性需求進行研究分析。
組合優化階段,設計者主要針對用戶的非功能性需求進行優化,在衡量用戶的滿意程度上,除了主觀因素,QoS作為一種非功能性的標準,可以客觀的、量化的衡量滿意程度。QoS的屬性指標有各種各樣的,其中的內容也是多種多樣的。常用的QoS屬性可以分為兩類,一類是優勢屬性,另外一類是劣勢屬性。其中服務花費、響應時間等屬于劣勢屬性,它們的值越小越好;而服務安全、可靠性等屬于優勢屬性,它們的值越大越好。
用QoS對web服務組合模型進行評定時,可以選取的備選方案往往有多個。但是各個QoS屬性的取值單位和范圍是不統一的,舉例來說,服務花費的取值范圍是服務提供者提出的,取值單位是數值類型的;而可靠性的取值單位是比率類型的,取值范圍在[0,1]之間。因此如果想要進行web服務組合中QoS屬性的比較,首先要對各個QoS屬性進行歸一化處理,避免取值單位和取值范圍造成的影響。優勢屬性采用式(1)來計算
(1)
劣勢屬性采用式(2)計算
(2)
式(1)和式(2)中的m表示web服務未經處理的QoS屬性值,而m′代表著經過歸一化處理的QoS屬性值。經過歸一化處理后,原來的QoS屬性值的值域會一一映射到范圍[0,1]中去。
在web服務組合之中存在4種服務運行邏輯。在計算web服務組合的QoS屬性值時,要用不同的方法對4種運行邏輯的web服務組合進行不同的聚合。順序、循環、選擇和并行,這4種運行邏輯的計算公式見表1。
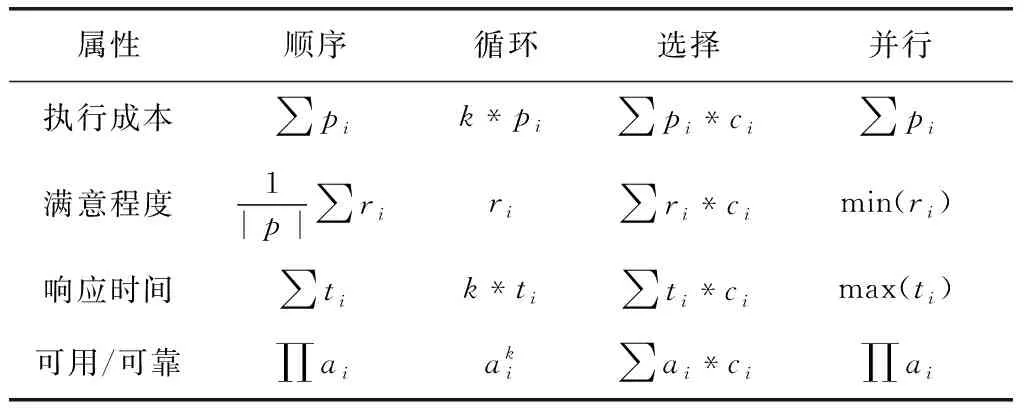
表1 服務組合QoS計算模型
2 狀態機與服務組合建模
2.1 服務狀態機
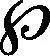
用簡單的服務狀態機互相組合最終形成的狀態圖可能存在狀態爆炸的情況,因此引入層次狀態機對服務進行組合。假設用戶的需求為輸入 {1,2,3}, 輸出為 {7,8,9,10}。 那么層次狀態機中的超狀態如圖1所示。其中矩形為層次狀態機中的超狀態, {A,B,C}、 {D,E} 是分別屬于兩個超狀態的服務。
2.2 基于狀態機的服務社區
存在很多接口參數相似、功能相似的服務,將他們組成一個服務社區。基于狀態機的服務社區為一個四元組 (ID,S,I,O) 其中:ID為服務社區的唯一標示,S為服務的集合,I=(Ipub,Ipri) 為輸入參數的結合,Ipub為公共參數即所有服務輸入參數的交集、Ipri為非公共參數即所有服務除公共參數的輸入參數。O=(Opub,Opri) 為輸出參數的結合,Opub為公共參數即所有服務輸出參數的交集、Opri為非公共參數即所有服務除公共參數的輸出參數。
3 基于層次狀態機的服務組合過程
通過用戶的輸入參數發現服務,得到的服務暫時作為層次狀態機的H0層。將H0層的輸出作為下一層的輸入參數,找到下一層的服務,有則選擇該服務,無則不能選擇。直到所有層的輸出參數的并集與用戶需求的輸出參數相吻合。
基于層次狀態機的服務組合定義如下
3.1 基于層次狀態機的服務發現
由于公共參數是一個服務社區所有服務都需要的輸入參數,所以先匹配每個服務社區的服務參數,再匹配非公共參數可以提高效率。
劃分超狀態的服務步驟如下:
步驟1 查找服務社區,如果輸入滿足服務社區的公共參數,下一步。
步驟2 進入這些服務社區,找到輸入滿足的服務集,獲得它們的輸出參數,如果滿足用戶需求,返回組合方案;不滿足,將該層的輸出與輸入并集作為下一次的輸入集。
步驟3 獲取已經匹配的服務社區的后續服務社區,循環步驟1~步驟2,直到滿足用戶需求,或者達到停止條件。
3.2 服務狀態機的組合
(1)QP(A,B)=QA∪QB∪s0P(A,B);
(2)EP(A,B)=EA∪EB∪ε;
(4)s0P(A,B)=s0P(A,B);
(5)FP(A,B)=FA∪FB;
3.3 服務組合的驗證
所有服務是否能正確且高效地組合成目標服務,需要對服務組合的存在性及等價性進行驗證。其中,存在性驗證實質上就是對服務的可達性進行驗證。
3.3.1 服務存在性驗證
由定義2可知,從最終狀態開始尋找前繼節點,再繼續尋找前繼節點的前繼節點,直到找到起始節點q0, 每個在路徑上的節點都是可達的。第4節中通過反向搜索保證了狀態圖的可達性。
3.3.2 服務等價性驗證
(1)q0=s0;
(3)qn∈F;
則服務狀態機接受t。如果L={t|m接受t}, 則稱服務狀態機m識別語言L,記為:L(F)。
由以上的定義,可以得到如下性質:
性質1 對于狀態節點,當且僅當q0*t→qi+1~q2*t→qi+1時,q1~q2。
性質2 終止狀態一定不等價于非終止狀態。
根據以上內容,結合第4節的構建過程,如果層次狀態機的所有終止狀態都可以在服務社區中找到對應的終止狀態,那么驗證目標服務與原服務是等價的。
4 服務優化過程
4.1 基于最優QoS優化過程
以時間花費屬性為例,采用正向執行順序,起始狀態看作一個只有輸出的虛擬服務,其QoS為0。對每一層的輸入參數I循環。在候選服務中選出QoS最小的服務s。根據2.1節的內容,由于服務都是并行的,s的前序服務的QoS為上一層所有輸入參數最小值中選出的最大值。將最大值與s的QoS相加,即得到選擇s服務的服務組合QoS最小值。直到最后的終止狀態。終止狀態可以看作是一個只有輸入的虛擬服務。虛擬服務的QoS即為服務組合的最終值。基于最優QoS優化過程如算法1所示。
算法1
輸入:候選服務s
輸出:候選服務的組合最優QoS表
(1)創建變量qosmax=0, 變量qosmin=極大值, map結構的QoS最優表map。
(2)循環s.I:
(3)創建隊列sersrc;
(4)sersrc.push(能輸出該參數的服務);
(5)循環sersrc{
(6)查QoS最優表中該元素的值, 若值為null或者值比qosmin小, 將值賦給qosmin;
}
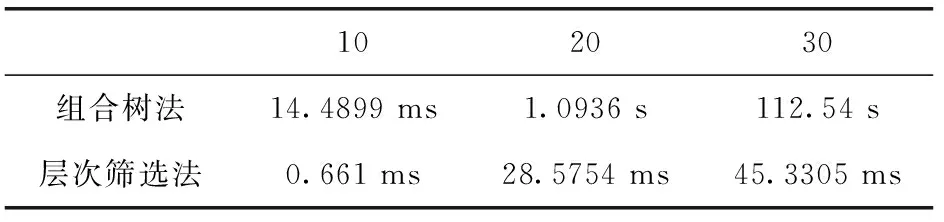
(7)if (qosmax (8)取s.qos中時間花費的屬性值與qosmax相加, 得到的值存入QoS最優表s鍵值對應的位置。 層次狀態機的終止狀態可以看作是一個只有輸入的虛擬服務,它的最優QoS值即為服務組合的最終QoS值。算法1不僅得到了服務組合的最終QoS值,選擇每個服務時的最優QoS值也在組合過程中記錄下來。 采用第3節中的超狀態構建過程,會導致組合服務中存在冗余服務。3種情況下會存在冗余服務:①k層的服務s,其輸出并沒有被后續服務利用;②k層存在被重復計入的服務;③k層的多個服務互相組合,輸出的參數對于后續服務的作用是相同的。 針對情況①,最終采取反向搜索排除無用服務。針對情況②、情況③采用算法2去除冗余服務。 為了減小運算規模,應對組合按照約束條件去除冗余服務。結合算法2,得到符合約束條件的服務組合最簡集。由于最終采取反向搜索,輸入應包含上一層的服務,算法開始時輸入的即為終止狀態的虛擬服務。 算法2 輸入:輸出一層參數的服務集集合sersrclist,上一層的服務組合方案slast 輸出:基于約束條件的去冗余服務方案集合 (1)循環sersrclist: (2)將服務集集合的元素兩兩對比{ (3)檢查是否存在元素A是元素B的子集; (4)若存在, 刪除規模大的集合; } (5)取sersrclist的隊頭元素s, 把s中的每個服務作為集合存入res; (6)forj=1循環sersrclist: (7)比較res中的每個元素和sersrclist[j], 存在交集的每一項移入resR并在res中刪除, 并把交集元素存入serU; (8)對serU的每個元素{ (9)if(map無這個元素)存入map,key值為serU[i],value為res中每一項與serU[i]組合的服務。 (10)elsevalue追加res中每一項與serU[i]組合的服務} (11)res中剩余沒有交集的元素sres: (12)判斷sersrclist[j]中的每個服務s: (13)從map中取key為s的值, 檢查其中的元素, 如果不存在sres的子集, 將sres與組合作為一個元素進入到resR中; (14)將resR的值賦給res; (15)循環res{ (16)取上一層服務的約束服務的集合slast.s.?; (17)對比元素留下符合約束要求的組合方案。} 將上述過程結合可得到基于層次狀態機的服務組合優化算法。算法1得到了各個服務在組合中的最優QoS值,取服務狀態機本身QoS的時間維度的值,用服務的最優QoS減去服務本身的值,得到前序服務組合的最優QoS值,來對所有前序候選服務進行篩選。 采用反向搜索,排除輸出參數無用的服務,也使層次狀態機是可達的。首選對終止狀態進行處理。把終止狀態看作是一個只有輸入參數的虛擬服務,輸入參數為用戶的目標輸出參數。將輸出這些參數的服務存入變量sersrc,利用算法1得到的最優QoS篩選服務。得到的參數服務候選集經過算法2,得到去冗余符合約束的服務組合方案存入listLeaf。循環服務組合方案集合:創建listTree隊列;list-Tree.push(服務方案);創建樹集合listTrees;listTrees.push(listTree)。以上流程如算法3所示。 算法3 輸入:listLeaf,listTrees,result 輸出:result (1)檢查listLeaf是不是只包含一個方案且方案中只有一個起始狀態的虛擬服務; (2)是的話將listTrees[0]加入result終止遞歸, 返回結果, 不是的話繼續; (3)循環listLeaf中的元素; (4)分別找到元素的輸入參數對應的前服務, 存入; (5)利用算法1得到的QoS篩選符合最優QoS的服務; (6)利用算法2對篩選后的各個參數的服務集去冗余組合, 得到元素的前序服務組合方案集合存入listTreenew; (7)循環listTreenew: { (8)創建listTree數組; (9)listTree.push(listTreenew元素); (10)listTree.push(listTrees[0]); (11)listTrees.push(listTree); (12)listLeaf.push(listTreenew元素); } (13)listLeaf隊頭元素出隊; (14)listTrees隊頭元素出隊; (15)繼續用新的listLeaf,listTrees,result調用本程序; 算法3是由終止狀態出發,以其為根結點,找到它的前序服務組合方案,然后再以前序服務為結點,不斷添加葉子結點,樹的每條路徑就是一個組合方案。算法3采用廣度優先,算法第(1)行~第(2)行是終止條件,即組合方案到達了起始狀態,滿足了用戶的輸入參數需求。算法第(3)行~第(6)行獲得它們符合約束的前序服務組合方案存入listTreenew。算法第(7)行~第(12)行把前序服務掛在相應的父節點下,將這條路徑保留在listTrees中,將新的需要找前序服務的服務進入隊列listLeaf。第(13)行~第(15)行將已有葉子節點的父節點出隊,繼續遞歸。 實驗主要驗證上述算法在尋找組合方案時的有效性,將其與傳統的枚舉組合樹法進行對比。采用選擇不同的服務社區數量和候選服務數量,比較兩種算法在此情況下運行時間的變化。本實驗采取的服務數據來自QWS數據集,但由于QWS數據集不存在約束條件以及服務參數的信息,因此采取隨機生成法為這些服務生成約束條件和服務參數。初始化服務數據的過程如下:首先設置模擬參數數據建立服務社區之間的參數依賴關系,再根據每個服務社區參數構造一批參數類似的服務,其中候選服務來自QWS數據集,每個服務的參數參考服務社區的參數隨機生成。為了模擬在組合過程中各個服務之間的約束邏輯,同樣采用隨機生成法,為這些服務生成一些隨機的約束邏輯和用戶請求。 表2、表3分別是兩種算法在候選服務保持10、20、30的狀態下,服務社區分別為3時、4時的時間花費情況。針對每種實驗參數設置,隨機生成不同的約束條件實驗50次,以50次實驗的平均運行時間作為結果進行對比。 由表2、表3可以看出,層次篩選法明顯優于傳統組合樹法,根據任務的增多,在表3中,20個任務時傳統方法已經達到秒級單位,層次篩選法時間增長的趨勢明顯低于傳統方法。 表2 3個服務社區下算法的時間花費/ms 表3 4個服務社區下算法的時間花費 選擇狀態機進行服務組合的情況下,當轉移過多、狀態爆炸時,可以進一步選用層次狀態機。提出描述服務狀態機和服務社區的概念,根據用戶的輸入以及目標輸出,提出方法不斷劃分超狀態,直至最后超狀態輸出的參數并集符合用戶的要求。在這個過程中,會產生冗余服務,而且也沒有考慮用戶的非功能性需求。與此同時考慮到服務之間的約束邏輯,基于這三方面對服務組合方法進行優化,構建過程中篩選符合要求的候選服務,最終得到符合約束條件的最優QoS組合方案。經過仿真實驗的對比,驗證該方法是行之有效的。 研究取得了一定的成果,但是工作仍然有待完善。研究主要在模擬好的服務社區數據的基礎上,基于層次狀態機對服務進行組合和優化,并沒有考慮到如何對相似的服務進行聚合形成服務社區。未來的研究工作中,應完善服務聚合的方法。4.2 基于約束條件的去冗余服務過程

4.3 服務方案選擇
4.4 仿真實驗與結果分析

5 結束語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
