LBSN中利用深度學習的POI推薦方法
2022-10-17 14:04:44吳安波李慧斌
計算機工程與設計 2022年10期
劉 旸,吳安波,李慧斌
(1.西安科技大學 管理學院,陜西 西安 710054; 2.西安交通大學 數學與統計學院信息科學系,陜西 西安 710048)
0 引 言
現如今,基于位置的社交網絡(location-based social network,LSBN)服務在人們的日常生活中起著越來越重要的作用[1-3]。由此,在對LBSN領域的研究過程中,感興趣的位置點(point of interest,POI)推薦成為了眾多研究學者的熱門關注話題[4-6]。因此,如何深入挖掘LBSN簽到數據中的深層次信息,提升POI推薦準確率,成為了當前研究的熱點。文獻[7]對社會和地理影響分別建模,并融合到矩陣分解框架中實現POI推薦。文獻[8]將POI內容上的用戶首選項與其本身用戶首選項區分開來,并對用戶POI的位置偏好進行位置感知建模,通過組合內容和POI位置預測進行最終的POI推薦。文獻[9]針對現有方法在POI推薦過程中融合個性化、情感傾向等方面的不足,提出了一種融合多因素的POI推薦模型,有效地融合地理相關、分類偏好以及社交情感分數,實現Top-N的POI推薦,但該方法對于冷啟動問題還有待進一步研究[10]。文獻[11]利用長短期記憶神經網絡對用戶的復雜過渡行為進行建模,很大程度上提升了POI推薦方法使用過程中的準確程度。文獻[12]提出了一種基于譜嵌入增強方式的POI推薦算法,具有較好的推薦性能,但該方法不能深度融合LBSN中簽到數據上下文的多維特性,難以準確獲得用戶最近鄰。文獻[13]提出了一種基于遞歸神經網絡的POI推薦方法,在考慮相似用戶的位置興趣和包括時間、位置以及朋友偏好等上下文信息的基礎上,形成了用戶興趣和上下文信息的網絡神經全特征表示方式。但該模型對特征向量的處理則忽視了用戶和POI之間的非線性關系,不能進一步提升推薦準確性[14]。
針對簽到數據多維度特性融合以及數據之間非線性聯系等問題,提出了一種LBSN中利用深度學習的POI推薦方法,其主要創新點總結如下:
(1)構建異構的LBSN圖,即UP2Vec模型,其能夠整合信息進行聯合建模,提高了信息的使用效率;
(2)為了準確預測用戶POI偏好,所提方法采用譜嵌入的方式增強神經網絡學習用戶與POI的非線性關系,提高了POI推薦的準確性。
1 問題描述
為了便于論述,需要定義使用的關鍵概念,以及闡述POI推薦研究中的主要問題。
定義1 POI:一個POI(p)被定義為其地理坐標可用的唯一地理實體(如飯店或者電影院),則LSBN中可用的POI集合表示為P。
定義2 Check-in:三元組c=(p,u,t) 表示一個簽到,即用戶u在時間節點t訪問POI(p)的簽到記為C,c∈C。
定義3 冷啟動POI:冷啟動POI定義為沒有簽到關聯的唯一地理實體,冷啟動POI的集合表示為Pc。
定義4 孤立冷啟動用戶:孤立的冷啟動用戶定義為唯一的LBSN用戶,其地理坐標可用,但是沒有遷入歷史紀錄,并且與其它LBSN用戶沒有任何聯系。孤立冷啟動用戶的集合表示為Uc。
定義5 用戶位置:給定用戶u,將用戶居住地表示為pu(xu,yu), 并且其位置來自用戶的簽到記錄。具體而言,將地理空間位置離散為25×25 km的單元,并將簽到次數最多的單元位置定義為用戶家庭位置,該集合表示為PU,pu∈PU。
給定一個LBSN,用戶之間的簽到(c)和社交關系(L)是可用的。非孤立的POI(P),其地理信息以及時間信息可以從簽到中獲得,而非孤立用戶(U)可以從用戶之間的社會關系中獲得。此外,還考慮了孤立冷啟動用戶(Uc)和冷啟動POI(Pc)。
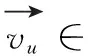
問題1:POI推薦:給定用戶在時間t之前的歷史紀錄,POI推薦的目標是推薦用戶在時間t時刻可能訪問的前k個POI。
問題2:冷啟動POI推薦:給定用戶直到t時刻的歷史記錄,冷啟動POI推薦的目標是推薦用戶未來可能會訪問的前k個冷啟動POI。
問題3:社交鏈接預測:鏈接預測是社交網絡分析中的一個常見問題,其目的是預測一對用戶之間是否存在社交關系。
2 方法框架
提出的利用深度學習的POI推薦方法的整體架構如圖1所示。利用設計的偏好增強譜聚類(preference enhanced spectral clustering,PSC)算法分析用戶的簽到信息、社交信息和時間信息,由此得出用戶的不同維度的多個數據的空間特征信息,同時使用偏好增強譜聚類算法對用戶進行精準分類。同時,利用改進神經網絡-多層感知器(improved multi-layer perceptron,IMLP)深度挖掘用戶與POI之間的非線性關聯。
深度學習的POI推薦方法由5部分組成,即神經網絡輸入層、神經網絡譜嵌入層、神經網絡拼接層、神經網絡隱含層以及神經網絡輸出層。把用戶群體中的用戶與POI標記對輸入譜嵌入層,經過兩者的二分圖譜構建潛在因子,以獲取兩者的譜特征集合描述。然后,拼接用戶與POI譜特征集合,從而構成拼接集合,將其輸入隱含層,同時,使用神經網絡多隱含層結構實現對用戶與深度學習的POI推薦方法間的深層次的關聯模仿。最后,利用神經網絡softmax層實現用戶對于深度學習的POI推薦方法的偏好的預估輸出。
2.1 LBSN數據分析
所提方法主要使用兩個公開數據集(Foursquare和Gowalla)進行論證,由于Gowalla和Foursquare數據集的分析結果類似,因此僅顯示在Foursquare數據集上的實驗結果。
2.1.1 簽到頻率分析
首先分析LBSN中用戶和POI的簽到頻率,結果如圖2所示。
從圖2中可以看出,只有少數POI和用戶主導了簽到活動,這意味著POI或用戶的簽到頻率遵循冪律分布。如果連通圖的度分布遵循冪律分布,那么短隨機游走中出現的節點頻率也將遵循冪律分布。因此利用Skip-gram模型構建圖嵌入模型進行表示學習,同時采用隨機游走將異質LBSN圖中的節點采樣為Node2Vec。
2.1.2 地理影響分析
用戶的簽到行為受到用戶地理位置因素的影響,用戶的地理位置因素也會對用戶在深度學習的POI推薦方法之間的轉換行為造成一定程度上的作用。在實際研究過程中,為深入探討用戶地理位置對用戶簽到行為的作用效果,對每個用戶的簽到時間進行排序,并計算兩個相鄰POI之間的距離。然后匯總所有用戶的結果,并計算相同地理距離的累計簽到頻率。兩個相鄰POI之間地理距離的分布如圖3所示。其中橫軸表示相鄰簽到之間的距離,縱軸表示相鄰簽到活動在此距離發生的概率,概率越大代表用戶更愿意訪問POI。
從圖3中可以看出,連續簽到之間的地理距離分布遵循冪律分布,這表明用戶更愿意訪問距訪問POI更近的POI。因此,采用冪律分布模擬地理位置對用戶的簽到行為和用戶在POI之間的遷移行為的影響。
2.1.3 時間影響分析

從圖4中可以看出,用戶的移動性行為在每24 h和每168 h(7天)左右呈現出較強的時間循環模式,分別顯示了日循環模式和周循環模式。所提方法中關注的是每日的周期性時間影響,因此,在日常基礎上對時間信息進行建模。
2.2 LBSN異構圖的構建
根據上述分析結果構建LBSN異構圖,具體來說,為了同時學習用戶和POI的表示,使用Ω表示LBSN異構圖
Ω=(V,E)
(1)
式中:V為LBSN異構圖的節點集合,將包含用戶集的U、POI的集合P、孤立冷啟動用戶集合Uc和冷啟動POI集合Pc等節點。E為異構圖的邊緣集,該邊緣集是基于簽到記錄、用戶之間的社交關系、地理影響和時間信息構建的。
2.2.1 簽到信息建模
簽到記錄直接表明用戶的歷史空間行為,因此,首先僅根據簽到信息構建LBSN異構圖,稱該基本模型為UP2Vec。在構建LBSN異構圖時,使用用戶集U、POI集合P、孤立冷啟動用戶集合Uc和冷啟動POI集合Pc構建節點集V。對于邊緣集E,如果用戶和POI之間發生簽到行為,則將其在LBSN異構圖中進行連接,這種邊緣集表示為Ep,u。 對于孤立冷啟動用戶,連接到LBSN異構圖中地理上最近的POI或用戶;對于冷啟動POI,同樣連接到地理上最近的POI或用戶。因此,UP2Vec中的LBSN異構圖表示為
Ω0=(V,E)V=U∪P∪Uc∪PcE=Ep,u∪Ep,p
(2)
為了更加清楚描述LBSN異構圖的構建過程,給出了一個由UP2Vec建立的LBSN異構圖的示例,如圖5所示。
圖5中,A、B、C、D、E是用戶節點,E是孤立冷啟動用戶,節點1至節點16是POI節點,節點17是冷啟動POI。孤立冷啟動用戶和冷啟動POI節點通過虛線節點連接到最近的鄰居節點[16]。
2.2.2 社交關系建模
在簽到信息的基礎上,進一步擴展UP2Vec,將用戶之間的社會關系信息納入到異構圖中,得到UP2Vec+。如果用戶之間存在社交關系,則連接相應的節點。將UP2Vec表示為Ω′0=(V′,E′), 其中V′定義為V,E′定義為
E′=Ep,u∪Ep,p∪Eu,u
(3)
式中:Eu,u為基于社交關系構建的邊緣集。UP2Vec+的模型結構,具有相同的V,但是社交關系已經添加,即用戶A分別和用戶B、用戶C相連。
2.2.3 時間信息建模
V″=U∪Pτ∪Uc∪Pc
(4)
2.3 PSC算法
PSC算法主要是通過簽到信息、社交信息和時間信息獲得偏好歸一化相似度集合φ,由此進一步得到歸一化的Laplacian集合φsym,根據φsym得到最小k個特征值對應的數據集合,以此完成聚類分析。
2.3.1 偏好提取歸一化相似度集合φ
所提方法同時考慮簽到與社交關系,利用偏好相似度?衡量兩個用戶間的邊權重,計算如下
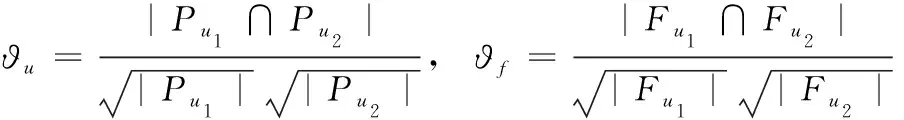
(5)
式中: |Pu1∩Pu2| 為u1與u2一起簽到的POI數量, ?u為兩個用戶之間的興趣偏好相似的程度, |Fu1∩Fu2| 為u1與u2的共有的好友數量, ?f為雙方友好聯系的程度。
同時,利用隨機游走方法把兩用戶間的相似度作歸一化處理,則歸一化后的相似度集合φ計算如下
(6)
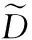
2.3.2 歸一化的Laplacian集合φsym
譜聚類算法把聚類問題當成圖像分解問題,聚類問題的尋優過程始終與 Laplacian的求解結果的特征集合的過程保持相同,因此,通過運算獲得用戶相似度的集合就能得出所對應的Laplacian矩陣[17,18]。則歸一化的Laplacian集合φsym計算如下
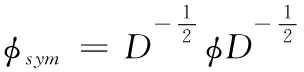
(7)
通過實踐研究可知,神經網絡的功能,是通過對用戶的處理信息進行檢索,并通過對用戶的推薦任務進行分析,從而獲得用戶與目標物品之間所存在的某些非線性的隱藏關聯信息[19]。由此,提出了創新性的譜嵌入增強的LMLP神經網絡,利用不同渠道和各種技術手段對用戶的各類信息進行分析,以完成下一個深度學習的POI推薦,其中IMLP包括了輸入層、譜嵌入層、拼接層、隱含層和輸出層。
3 IMLP神經網絡設計
現有的研究已經論證了神經網絡能夠有效處理信息檢索與推薦任務中獲取用戶與物品間非線性的隱藏關聯[19]。因此,所提方法設計了譜嵌入增強的神經網絡IMLP,通過分析用戶的各種信息完成用戶下一個POI的推薦,其中IMLP包括了輸入層、譜嵌入層、拼接層、隱含層和輸出層。
3.1 譜嵌入層
用戶與POI 間的簽到關聯能夠以二分圖的形式進行描述,其中包括了兩者許多連通的關聯信息,而非直接的隱藏連通程度對獲取用戶偏好具有非常重要的作用[20,21]。IMLP中的譜嵌入層即利用連通信息圖的譜完成對用戶與POI的譜映射,以得到兩者的譜嵌入量,計算如下
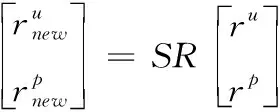
(8)

3.2 其它各層的設計
所提方法利用神經網絡模擬輸入用戶與POI關系對、輸出 POI推薦位置兩者間的聯系。其中選擇非線性激活函數,采用增加隱含層層數的方式使得IMLP能夠接近任何復雜函數,以更為精準地表述輸入和輸出之間的聯系,并且把神經元的輸出反映至存在邊界的區域內[22,23]。所以,IMLP各個層次的輸出值計算如下
x=h0=[ui,pj]Th1(x)=ReLU(ω1h0+b1)h2(x)=ReLU(ω2h1(x)+b2)hq(x)=ReLU(ωqhq-1(x)+bq)
(9)
式中:ωq,bq為第q層的參數,當q=0時,x便是用戶與POI對的拼接量。
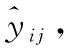
(10)
此外,選擇對數損失函數(llog)當作IMLP網絡的目標函數,計算如下
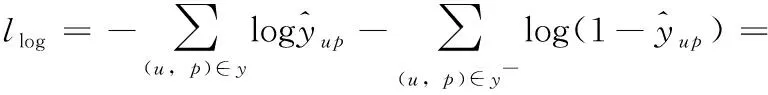
(11)
4 模型性能評估
實驗中使用兩個公開的真實數據集(Foursquare和Gowalla)對所提方法的性能進行評估。其中Foursquare數據集中包含2009年12月至2013年7月之間來自California用戶的483 813條簽到記錄,還包含32 512位用戶之間的社交數據。Gowalla數據集是在2010年8月公共收集的,其包含來自216 734位活躍用戶的12 846 151次簽到記錄,其中簽到記錄包含1 421 262個位置和736 778個社交關系。這兩個數據集中的每一個簽到記錄包含唯一的用戶ID、POI ID、POI類別、POI的描述信息、相應的經緯度坐標以及與此簽到相關的時間戳。為了測試UP2Vec的冷啟動POI推薦功能,從Foursquare和Gowalla數據集中選擇了2000個POI作為冷啟動的POI。
4.1 評估指標
POI推薦的任務從給定的測試用戶可能會訪問的POI集合中選擇POI,具體的說,給定用戶和候選POI集合,計算用戶表示和POI表示的內積,再按照降序對POI進行排序。之后,選擇前K個POI生成推薦列表。所提方法采用廣泛使用的基于排名的評價指標Acc@K進行評估。對每個測試樣本,若訪問的POI出現在前K個推薦列表中,則Acc@K為1,反之為0。總體Acc@K取所有測試樣本的平均值。
在現實條件下,對深度學習的POI推薦進行一系列實踐實驗,對所有的目標用戶,將所有用戶中前80%的用戶簽到數據作為POI推薦實驗的訓練集,將所有用戶中最新10%的用戶簽到數據作為POI推薦實驗的測試集,將所有用戶中最后所剩的10%的用戶數據作為POI推薦實驗的驗證集來對參數進行調整。
4.2 參數敏感度分析
在論證所提方法的推薦性能之前,需要對UP2Vec中的參數進行討論。參數的初始默認值分別為:維度d=256、 鄰域范圍ζ=10、 返回參數υ=1、 輸入-輸出參數v=1, LBSN異構圖中每個邊的轉移概率統一設置為1。為了研究特定參數對模型參數的影響,當分析某個特定參數時,該參數值在一定范圍內變化,其它參數仍取默認值。由于UP2Vec、UP2Vec+和UP2Vec++的表示無明顯差異,因此僅分析UP2Vec++在Fouresquare數據集上的推薦結果,如圖6所示。其中橫坐標表示參數值的變化,縱坐標表示在Acc@15下,POI的推薦性能。
從圖6中可以看出,當輸入-輸出參數v變大而返回參數υ變小時,Acc@15的值在不斷增大,表明UP2Vec++的性能在不斷提高。并且推薦精度隨著維度d的增加而增加,當d達到一定值時,性能達到峰值趨于飽和狀態。不過,當鄰域范圍大小ζ變大時,推薦精度Acc@15將會降低。
由于隨著v的增大和υ的減小,將對更多附近節點進行采樣,因此,更多的信息輸入推薦模型,以進行更有效的POI推薦。而鄰域范圍ζ越大,將會在學習特征量時引入噪聲數據,這會降低特征值的可靠性,因此POI推薦的準確性降低。因此,將UP2Vec的默認參數設置為d=256、ζ=8、υ=0.24、v=5, 模型在數據集Fouresquare和Gowalla上具有最好的推薦性能。綜上所述,針對地理影響、用戶社會關系和時間信息之類的語境因素共同建模,能為LBSN異構圖中的用戶和POI提供更好的表示學習。
4.3 與其它方法的對比分析
為了論證所提方法的POI推薦性能,將其與文獻[7]、文獻[11]、文獻[13]在POI推薦、POI冷啟動推薦、偏好預測等3個方面進行對比分析。其中文獻[7]針對社會和地理影響進行建模,并利用矩陣分解框架實現POI推薦。文獻[11]利用長短期記憶神經網絡對用戶的復雜過渡行為進行建模,以完成POI推薦。文獻[13]提出基于遞歸神經網絡的POI推薦方法,通過相似用戶的位置興趣和上下文信息的全特征表示提高POI推薦性能。
4.3.1 POI推薦
在Fouresquare和Gowalla數據集上,使用不同方法進行POI推薦的性能比較結果如圖7所示。
從圖7中可以看出,所提方法在數據集Fouresquare和Gowalla上的推薦性能明顯優于其它方法。由于所提方法采用PSC算法方法對簽到信息、社交信息和時間信息進行聚類分析,并利用IMLP網絡實現POI推薦,與文獻[13]相比,在兩個數據集上的Acc@N值分別提高了33.33%~47.06%、21.05%~43.75%,因此結合社交關系、時間信息和地理影響可以更好獲取用戶的POI訪問行為。文獻[11]利用長短期記憶神經網絡實現POI推薦,但單一模型在信息處理過程中仍不充分,因此性能不佳。由于文獻[7]中用戶POI矩陣的稀疏性以及缺少對時間信息和地理信息的使用,其推薦性能最差,在兩個數據集上的Acc@15均低于0.15。
4.3.2 POI冷啟動推薦
由于兩個數據集上冷啟動POI推薦實驗結果相似。因此,僅分析在Fouresquare數據集上的實驗結果,不同方法的冷啟動POI推薦對比結果如圖8所示。
從圖8中可以看出,不同的K值下,所提方法的冷啟動POI推薦性能優于其它對比方法,以Acc@10為例,所提方法分別高出其它3種方法0.03、0.02、0.07。此外,對比圖8與圖7(a),可以發現在POI冷啟動推薦中,各方法的推薦性能均明顯降低。當K=5時,所提方法的推薦精度降低20%,而其它3種方法分別下降了23.62%、25%、33.33%,因此所提方法在處理冷啟動時的推薦性能下降幅度相對較小,意味著其在處理POI冷啟動問題上有更強的魯棒性。由于所提方法考慮了地理特征、POI簽到序列和時間特征建模POI冷啟動推薦,并且采用了更細粒度的地理信息,而部分方法沒有考慮多種信息,或者采用的是粗粒度地理信息,因此冷啟動POI推薦性能不佳。
4.3.3 偏好預測
同樣的,不同方法在偏好預測方面的性能對比結果如圖9所示。
從圖9中可以看出,在準確率、召回率、F1值3個指標上,所提方法的預測性能均高于其它對比方法,以準確率為例,其在兩個數據集上分別為95%和91%,而其它方法均低于90%。主要是因為所提方法通過UP2Vec++學習用戶的表示形式,其中包含社交關系、POI和用戶的時空特征,并且利用IMLP進行偏好預測,進一步提升了POI推薦的準確率。文獻[13]利用遞歸神經網絡實現POI推薦,其中考慮了用戶的位置興趣和上下文信息,因此整體性能優于文獻[11],而文獻[11]僅利用長短期記憶神經網絡進行信息處理,各種用戶信息考慮得不夠全面。文獻[7]利用矩陣分解框架處理社會和地理影響,而缺乏用戶POI矩陣稀疏性的考慮,其推薦性能較差,推薦準確率大約為75%。
5 結束語
LBSN中含有豐富的語境信息,如簽到信息、時間信息、社交關系等,能夠更加全面地推薦用戶下一個POI,但各種語境信息存在異構性,POI推薦的性能也受到此影響。為此,提出了一種LBSN中利用深度學習的POI推薦方法。在UP2Vec模型中整合地理簽到信息、用戶社會關系和時間信息等語境,并利用PSC算法進行分析處理,以得到用戶群體分組。在此基礎上,結合POI信息,利用IMLP網絡深度挖掘用戶與POI 之間的非線性關聯,實現POI的準確推薦。基于Foursquare和Gowalla數據集對所提方法進行實驗論證,結果表明,將UP2Vec參數設置為d=256、ζ=8、υ=0.24、v=5時,模型性能最佳。此外,所提方法在POI推薦、POI冷啟動推薦和偏好預測3個方面的推薦性能均優于其它對比方法,其中,在POI推薦的Acc@N值較文獻[13]提高了21.05%~47.06%,在POI冷啟動推薦的Acc@10值分別高出0.03、0.02、0.07,并且推薦準確率分別為95%和91%。因此,通過該方法學習的用戶和POI表示可用于進一步提高LBSN任務中位置推薦和偏好預測的性能。
由于POI推薦過程中并沒有根據用戶偏好進行動態調整,在接下來的研究中,將重點關注注意力機制的引用,以便在LBSN中更好進行POI推薦和用戶表示學習。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
