基于法條知識的刑事類案推薦模型
2022-10-18 09:48:29吳歡棟
電腦知識與技術 2022年25期
吳歡棟

摘要:當前中國裁判文書網很難滿足用戶自定義案情推薦的需求,類案推薦又區別于傳統的文本相似性研究,因為裁判文書具有法律專業性強、文本長度較長等特性,傳統文本相似性的研究方法在法律領域的可解釋性和效果通常都不盡如人意。為此,該文提出了一個基于法條知識的刑事類案推薦模型,使用預訓練BERT對文書的文本序列進行編碼,同時利用BiLSTM提取其上下文的法條知識特征,演化為多標簽分類任務,最終輸出對應的法條向量,然后通過與本地的法條向量庫進行余弦相似度匹配,挑選與輸出向量最相似向量對應的裁判文書作為模型的推薦結果。
關鍵詞:裁判文書;法條知識;類案推薦;BERT-BiLSTM模型
中圖分類號:TP311? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)25-0079-03
開放科學(資源服務) 標識碼(OSID) :
由于存在判決年份、地域、法院層級與執法水平等諸多差異因素,導致社會上“類案不同判”的現象時有發生。為此,司法部也在逐步推進“數字法治,智慧司法”建設,上線了以中國裁判文書網為代表的一系列司法網站,急劇增長的司法案件數量導致文書網數據庫的規模劇增,而文書網自帶的檢索系統只能提供關鍵字檢索服務,當司法工作者或者普通用戶需要搜索相似案情的判例做參考時,仍需進一步自行篩選相似文書,專業性的篩選給用戶帶來了極大的不便。
刑事類案推薦即從已有的裁判文書中找出與輸入案情在司法角度最相似的文書,屬于文本相似度的研究范疇。對于普通文本相似度的數據集,一般的深度學習模型都能有效應對,但是裁判文書有別于普通文本的相似研究,裁判文書存在著文本較長、法律屬性強等特點,傳統的文本相似度匹配模型在法律領域的效果并不理想。
近些年來,得益于自然語言處理領域中預訓練模型的迅速發展,越來越多的文本匹配研究都選擇BERT[1]等預訓練模型作為詞嵌入層。基于此,本文提出一種基于法條語義信息的類案推薦模型,面向特定刑事文書,構建法條屬性數據集,模型采用BERT+BiLSTM網絡,用于學習用戶自定義輸入案情對應的法條屬性從而來得到法條向量,再利用法條向量與已有的法條向量數據庫進行向量匹配,進而給用戶推薦相似案例,通過自動理解用戶輸入案情的法條知識來進行案例推薦,從而降低裁判文書的人工篩選成本。
1 相關研究
類案推薦作為智慧司法的重要研究方向之一,一直受到國內外研究學者的關注。在以判例法為代表的英美等海洋法系國家中,法官主要依據過去的判例對當前案件進行判決,在判決文書中申明對以往判例的引用,自動形成了一個案例引用網絡。Dhanani等人[2]提出了一種基于圖聚類的法律文件檢索系統,在引文網絡中找到語義相關的判例,利用社區發現算法來聚類引文網絡和利用Doc2Vec 來捕獲集群內判例之間的語義相關性。
但是,在成文法為代表的中國構建大規模的引文網絡存在一定難度,在詞嵌入研究之前,主要以研究詞頻特征和LDA(Latent Dirichlet Allocation)為主。向李興[3]通過提取關鍵詞來計算詞頻,結合TF-IDF和余弦相似性進行相似案件推薦。李銳等人[4]使用SimHash算法利用相似哈希模型查找出同類型判決書中相似度最高的判決書推薦給用戶。呂賓等人[5]提出基于LDA主題模型的案例檢索算法,挖掘文本隱含語義信息,并采用多粒度特征來表征文本。
隨著神經網絡的普及和詞嵌入模型的逐漸出現,類案推薦也逐漸與深度學習相結合。陳志奎等人[6]構建一個多模態特征融合網絡,將Skip-Gram模型與Elmo模型分別產生的詞向量構建融合特征向量,再利用核密度估計的方法進行案例聚類檢索。許梓濤[7]提出了一種上下文感知類案的推薦方法,其以BERT作為詞嵌入層,利用CNN獲取上下文的語義信息,得到文本向量再進行類案匹配。但是,裁判文書作為專業屬性極強的法律文本,案例相似性和判決結果都直接取決于文本中涉及的法條知識,因此,如果忽略法條知識只關注于文本本身的相似性研究,其法律的可解釋性和判決結果的準確性都會存在問題,因此從法條知識的角度來解決類案推薦是非常有必要的。
2 數據集制作
2.1 裁判文書爬取
在我國,司法文書的下載網站包括中國裁判文書網、OpenLaw等,后者的文書數量遠少于前者,而裁判文書網存在下載量上限、滑塊校驗等反爬限制,本文通過IP代理池使用Selenium框架爬取文書網近5年的盜竊罪文書共計4300份,利用docx庫進行數據清洗并轉成csv格式,每個案例對應表中的一行,包含案件序號和案情描述等列。
2.2 法條知識標注
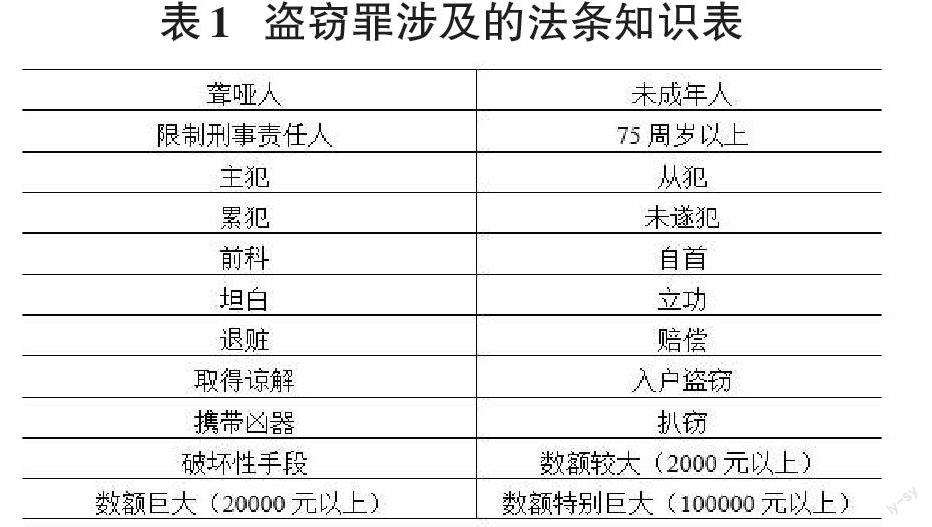
在我國,每種刑事犯罪的判決都是依據《中華人民共和國刑法》法條而定,而每條法條包含的知識要點與輸入案情之間的關聯程度直接決定了判決結果,因此,為了更好地表征輸入案情涉及的法條知識,我們需要在爬取的案情中標注出其中涉及的法條知識用于后續訓練。在我國,刑法犯罪的量刑都有相應的建議性指導文件,在參考《關于常見犯罪的量刑指導意見(試行) 2021年》和總結盜竊罪涉及的刑法條文之后,可以得出下列一些相關的法條知識,如表1所示,共計22種。
雖然裁判文書屬于非結構性數據,但是通常其格式和措辭都具有固定形式,因此可以利用正則庫re,對案情描述文本進行標注,例如通過re.compile(“供述”||“供認不諱”||“坦白”||“交代”)便可以得到“坦白”對應的標簽,然后依次類似操作后,每個裁判文書可以得出一個1[×]22大小的法條標簽,從而得到對應數據集。
3 刑事類案推薦模型
3.1 詞嵌入層
詞嵌入層主要功能是將輸入文本轉化為文本向量,常用的文本編碼技術包含one-hot、Word2vec和BERT等,one-hot生成的向量會存在高維度性、稀疏性、無法體現詞語的順序性等缺點,Word2vec相比one-hot可以獲得低維稠密的詞向量表征,但該種方案屬于靜態生成,無法適用于多義詞的場景。
因此,目前詞嵌入層通常是采用BERT模型,其是由Google AI研究院在2018年10月提出的一種預訓練模型,完美地解決一詞多義的問題。BERT的主體是基于Transformer架構的雙向編碼網絡,采用了前者的編碼器部分,通過掩碼語言模型和下文預測兩個任務進行預訓練。BERT由通用語料庫訓練而來,因此,只需要微調輸出層的參數便可用來提取每個案情序列對應的詞向量。
3.2 特征提取網絡
在自然語言處理領域,常用于特征提取的網絡包括CNN模型、RNN模型及上述兩類的有關演化變種,例如TextCNN、LSTM、BiLSTM、GRU和BiGRU等。TextCNN由輸入層、卷積層、池化層和輸出層組成,它比傳統CNN更加簡單,卷積層和池化層的層數更少,前一層的輸出作為當前層的輸入,但是經過卷積和池化操作后容易丟失詞匯順序等;RNN作為早期的時序神經網絡,主要應用于自然語言處理領域,在RNN的反向傳播過程中,隨著序列過長和網絡層數的增加,容易出現梯度爆炸和梯度消失的情況。因此,便逐漸出現LSTM、GRU等一系列RNN的演化網絡。
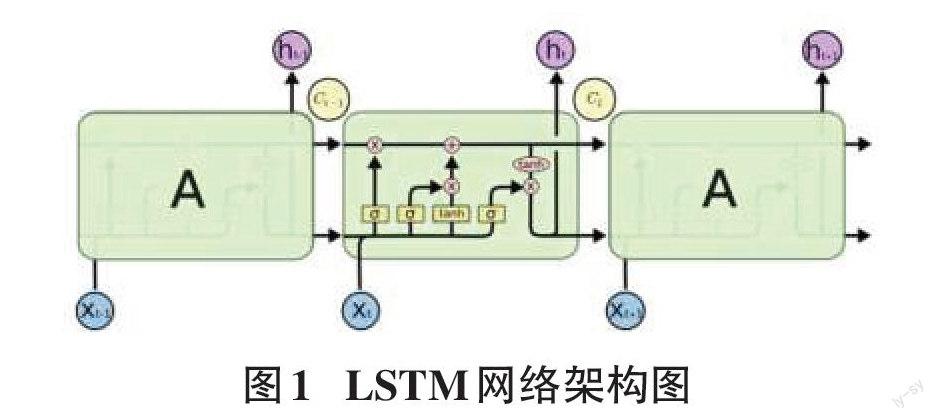
LSTM是RNN的一種變種,能夠學習長距離依賴關系,主要由輸入門、遺忘門和輸出門三部分組成,結構如圖1所示,隨著單元狀態在時間序列上的傳遞,通過門控機制來決定信息的丟棄或保留,三個門控單元都有各自的權重矩陣,從而實現對不同信息的選擇。但是,單向LSTM無法編碼從后向前的信息,很多場景又需要后向語義,因此出現了由一個前向的LSTM和一個后向的LSTM組成的BiLSTM網絡,其兼顧雙向語義,特征提取效果往往優于單向的LSTM。
GRU(Gated Recurrent Unit) 是RNN的另一種變種,GRU主要包含重置門和更新門兩部分,更新門類似于LSTM中的遺忘門和輸入門的結合,前者決定要丟棄的信息,后者決定需要向下傳遞的信息,由于它的張量操作和相關參數矩陣更少,在同等情況下,該模型的訓練難度比LSTM小,通常也會與LSTM一起進行性能比較。BiGRU與BiLSTM類似,是一個雙向的GRU組合網絡,效果也一般優于單向的GRU。
3.3 全連接層
在經過特征提取層之后,詞向量需要全連接層進行輸出,常用的激活函數包含Softmax和Sigmod等,前者適用于二分類、多分類,后者適用于多標簽分類;由于22項法條知識中的大部分知識在一個判例中是可以同時存在的,比如被告人既是累犯、又有立功情節且自首,于是法條知識的表征問題便可以演化為一個多標簽文本分類問題,因此選用Sigmod作為全連接層的激活函數,其對應的交叉熵損失函數L的計算公式如下所示。
[p=Sigmodz=11+e-z]
[L=-zlogp+1-zlog (1-p)]
3.4 網絡架構
本類案推薦模型主要由輸入層、詞嵌入層、特征提取層、全連接層和輸出層等五層組成,輸入層為用戶自定義輸入的案情文本,刪除停用詞;詞嵌入層選用的BERT_BASE模型,模型輸出的詞向量為768維;詞向量序列經過特征提取層和全連接層處理后,輸出22維向量,便可與法條向量庫中的向量進行余弦相似度匹配,然后再推薦出與輸入案情最相似的判例。
4 實驗模塊
4.1 評價標準與模型比較
由于爬取的文書數據集的規模相對較小,共計4300份裁判文書,因此設置訓練集與測試集的比例為7:3。模型的評價標準采用機器學習中常見的準確率P、召回率R和F1值,其定義分別如下:
[P=TpTp+Fp×100%]
[R=TpTp+Fn×100%]
[F1=2PRP+R×100%]
為了挑選出最佳模型組合,總共設計了5組對照實驗,分別為BERT-TextCNN、BERT-LSTM、BERT-BiLSTM、BERT-GRU和BERT-BiGRU;由于BERT最多只能接受510個token的輸入,而文書的平均長度在832字,采用頭尾截斷的方法進行處理。最終,各模型的實驗結果如表2所示:
從上述的實驗結果可以看出,TextCNN的效果不如循環神經網絡,BiLSTM的模擬效果最佳,可能與其兼顧雙向語義的特性有關,而LSTM與BiGRU的效果基本相近,因此最終選用F1值最高的BERT-BiLSTM模型作為特征提取網絡。
4.2 類案推薦模塊
由于此時BERT-BiLSTM模型已經具有表征盜竊罪文書相關法條的能力,當用戶向模型中輸入盜竊類案情時,模型通過識別其中的法條知識,輸出一個22維的法條向量X,即[x1,x2,…,x22 T],然后將X與本地已存在的4300條法條向量集合Y中的第i條向量Yi,即[yi_1,yi_2,…,yi_22 T],進行特征向量相似度的度量就可以進行判例相似比較,常見的相似度度量方法包括杰卡德相似系數、余弦相似度和歐氏距離等。此處,選擇余弦相似度作為評判標準,最終,從4300條法條向量中挑選出與X之間的余弦相似度取得最大值的向量Yi,其對應的裁判文書i作為推薦系統的推薦結果。
5 結束語
本文提出了一種基于法條知識的形式類案推薦算法模型,首先使用BERT模型將頭尾截斷的文本序列轉化為詞向量,詞向量輸入至BiLSTM網絡來學習其上下文信息,根據對應的法條知識標簽來訓練BiLSTM的參數矩陣,最后輸出對應的法條向量。然后通過向量的余弦相似度,從本地的法條向量庫中選取相似度最大的判例文書作為最終模型的推薦結果。由于本模型只針對盜竊類的刑事案件,如果要擴展到通用的單人單罪的類案推薦任務,可以先進行罪名預測任務得到罪名,然后根據量刑文件總結該罪名的法條知識,后續的訓練和預測流程則與本文基本一致。
參考文獻:
[1] Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[EB/OL]. 2018:arXiv:1810.04805.https://arxiv.org/abs/1810.04805
[2] Dhanani J,Mehta R,Rana D.Legal document recommendation system:a cluster based pairwise similarity computation[J].Journal of Intelligent & Fuzzy Systems,2021,41(5):5497-5509.
[3] 向李興.基于自然語義處理的裁判文書推薦系統設計與實現[D].南京:南京大學,2015.
[4] 李銳,游景揚,劉穩,等.基于SimHash算法的案件輔助判決系統研究[J].湖北工業大學學報,2017,32(5):67-72.
[5] 呂賓,侯偉亮.基于主題模型的法院文本典型案例推薦[J].微電子學與計算機,2018,35(2):128-132.
[6] 陳志奎,劉振嬌,原旭,等.基于深度多模態與核密度估計的法律文書推薦模型[J].西北師范大學學報(自然科學版),2021,57(1):31-37.
[7] 許梓濤,黃炳森,潘微科,等.一個新的上下文感知類案匹配與推薦方法[J].太原理工大學學報,2022,53(1):80-88.
【通聯編輯:光文玲】
