基于無人機多光譜遙感的冬小麥葉片含水量反演
2022-10-19 08:16:24芮婷婷徐云飛馮志軍張世文
麥類作物學報 2022年10期
關鍵詞:模型
芮婷婷,徐云飛,程 琦,楊 斌,馮志軍,周 濤,張世文
(1.安徽理工大學空間信息與測繪工程學院,安徽淮南 232001;2.安徽理工大學礦山采動災害空天地協同監測與預警安徽普通高校重點實驗室,安徽淮南 232001;3.安徽理工大學礦區環境與災害協同監測煤炭行業工程研究中心,安徽淮南 232001;4.安徽理工大學地球與環境學院,安徽淮南 232001)
冬小麥在我國是人們日常生活中主要的糧食作物,快速、準確地獲取冬小麥水分含量對農田灌溉管理、旱情狀況監測、作物長勢監測等具有重要的科學意義。含水量影響著作物的生理特征和健康狀況,在缺水時作物葉片顏色、紋理特征和形態結構等會發生變化,如葉片出現蜷縮、枯黃和色斑等,進而影響作物的生長和產量。作物水分含量可以由根、枝、葉、冠層的生理特性來反映,其中作物葉片的新陳代謝最旺盛,生理特性最敏感,可以通過監測作物葉片水分含量來評估作物整體水分狀況。
近年來,國內外學者基于遙感技術對作物水分含量的快速監測進行了廣泛探討和深入研究。遙感技術主要分為衛星遙感、地物光譜儀和無人機遙感。大多數研究結合衛星遙感影像監測作物水分含量,但是衛星運行時會受到云層的影響,使得利用衛星遙感監測精度受限。利用地物光譜儀可以獲取作物的冠層光譜信息,但所得信息是點狀的,難以用于區域性水分含量的動態監測。而無人機遙感平臺具有移動性強、運營成本低、獲取影像分辨率高、作業周期短等優點,可快速地獲取農田高精度影像,更好地滿足農田尺度上精準監測的要求。胡珍珠等篩選了與葉片含水量相關的光譜水分指數,構建了核桃果實不同生育時期的葉片含水量反演模型。吾木提·艾山江等通過灰色關聯度分析,選擇與葉片含水量關聯度較高的5種植被指數,構建了春小麥葉片含水量的偏最小二乘模型和BP神經網絡反演模型。彭要奇等采用改進的神經網絡模型對玉米葉片含水量進行反演。陳秀青等在葉片和冠層兩個尺度上,采用兩波段植被指數,構建冬小麥葉片含水量的偏最小二乘回歸和競爭自適應重加權采樣-偏最小二乘回歸模型。Wang等分析了不同水分脅迫條件下春小麥冠層反射率與冠層含水量的關系。Chen等利用無人機數據,構建了植被補給水指數,篩選出棉花不同部位的敏感波段。以上研究大多基于單一的敏感波段或高光譜植被指數監測作物含水量,而將無人機多光譜數據與敏感波段、植被指數結合反演作物葉片含水量的研究尚未見報道。
本研究利用無人機獲得多光譜影像,同步采集了冬小麥葉片含水量數據,分析了葉片含水量與光譜反射率和植被指數之間的相關性,進而篩選出與葉片含水量相關的敏感波段組及植被指數組,再利用得到的敏感波段組和植被指數組分別構建了冬小麥葉片含水量的PLS、ELM和PSO-ELM預測模型,通過選定模型評價指標比較3種模型的預測精度,最后將最優反演模型應用于研究區,獲得研究區冬小麥葉片含水量的空間分布圖,以期為作物葉片水分含量的快速監測和田間管理提供科學依據和理論支持。
1 材料與方法
1.1 研究區概況
研究區位于安徽省淮北市杜集區和烈山區的交界區域(116.85°E,33.97°N),地處中緯度地區,屬于暖溫帶半濕潤季風氣候,全年平均溫度為17 ℃,平均降水量為849.6 mm,日照時數為 4 430.2 h,雨水多集中于6-8月,土壤類型為壤土。研究區采取冬小麥和夏玉米輪作的種植方式,灌溉方式為雨養。供試小麥品種為淮麥22,小麥實行機播,行距15 cm,播種密度約為每公頃100萬株。研究區位置和采樣點分布情況如圖1所示。

圖1 研究區位置和采樣點分布圖
1.2 數據采集
1.2.1 無人機多光譜數據
本研究使用的無人機為大疆精靈4多光譜版植保無人機,其光譜相機配備6個1/2.9英寸CMOS影像傳感器,其中1個彩色傳感器用于常規可見光(RGB)成像,5個單色傳感器用于包含藍光波段(中心波長450 nm,帶寬32 nm)、綠光波段(中心波長560 nm,帶寬32 nm)、紅光波段(中心波長650 nm,帶寬32 nm)、紅邊波段(中心波長730 nm,帶寬32 nm)和近紅外波段(中心波長840 nm,帶寬52 nm)的多光譜成像。
無人機多光譜影像的采集時間為2021年1月7日,冬小麥處于越冬期,飛行時間為11:00-14:00,飛行時天空晴朗無云,風力較小。起飛前手動控制無人機飛行至校準白板的正上方約1 m處,采用相機單攝模式來拍攝標準白板。本次飛行設置航線為S型,飛行高度為100 m,航向和旁向重疊度分別設置為70%和60%,相機鏡頭與地面呈90°,拍照模式為等時間間隔。
1.2.2 地面實測數據
根據研究區范圍及冬小麥種植面積,利用均勻布點原則布設采樣點,并利用GPS記錄每個采樣點的位置信息。冬小麥葉片樣品均采用五點法混合采集,然后用密封袋對冬小麥葉片樣品進行密封保存并放置于陰涼處,以此來保證葉片水分不受到損失。實驗室處理時,冬小麥葉片含水量的測定采用烘干法,將冬小麥植株的葉片和莖分離后稱取每一個樣品的葉片鮮重,然后將所有樣品放入烘箱中,在105 ℃下殺青30 min,再在 80 ℃下烘干至恒重,稱取葉片干重。冬小麥葉片含水量(LWC)按公式“LWC=(鮮重-干重)/鮮重×100%”進行計算。
1.3 多光譜影像處理
利用Pix4Dmapper軟件對無人機獲取的多光譜影像進行拼接處理。拼接后多光譜影像的主要預處理包括幾何校正和輻射校正。結合ArcMap 10.6軟件,以無人機高清數碼正射影像為參考影像,分別在5個單波段影像上均勻選取30個參考點進行幾何校正,幾何校正誤差在0.5個像元之內。在多光譜影像中計算標準白板在各波段的DN值,利用公式“=DN/DN×”進行多光譜影像的輻射校正,其中為目標地物的反射率,DN為目標地物的DN均值,DN為標準白板的DN均值,為標準白板的反射率值。
2) 當不確定加箱或減箱事件發生時見圖2b),進入下一階段t=t+1,更新集裝箱序列和船舶貝內箱位序列,減箱事件對應的集裝箱c4和箱位p6從序列中被刪除,加箱事件對應的集裝箱c7被添加到集裝箱序列。
將預處理后的無人機多光譜影像及采樣點的GPS點位信息導入到ENVI 5.3軟件中。以地面實測取樣點為中心,在圖像上裁剪出200×200(像素)的光譜影像,將感興趣區域(ROI)范圍內冬小麥葉片樣本的平均反射光譜作為該取樣點的光譜反射率,獲得不同波段的光譜反射率數據。
1.4 植被指數選取
作物因其內在生化參數存在差異而表現出不同的光譜反射率。在可見光波段內,健康綠色作物的主要吸收峰在紅光波段和藍光波段的附近形成,主要反射峰在綠光波段形成;而在近紅外波段,作物的光譜特征為高反射率和低吸收率;在紅邊波段,作物的光譜反射率增長較快。將這些特征波段范圍內的光譜反射率通過線性或非線性的組合構成植被指數,可用來診斷作物生長狀態以及反演各種作物參數。通過以上對植被光譜特征的分析,本研究獲取的多光譜影像波段特征,從現有的多光譜植被指數中選取了20個多光譜植被指數用于模型構建(表1)。

表1 植被指數及其相關計算公式Table 1 Vegetation index and its related calculation formula
1.5 模型的構建
偏最小二乘模型是一種具有廣泛適用性的線性多元統計數據分析方法,具有主成分分析、典型相關分析和多元線性回歸分析的特點,可以有效地解決變量之間存在多重共線性或者樣本量較少的問題。因此,其在處理因變量較多或者因變量內部信息高度線性相關,而樣本量較少的數據時具有明顯的優勢,具有簡化數據結構、降低數據維度、減少噪聲干擾等特點。
極限學習機是一種針對單隱含層前饋神經網絡的學習算法。該算法隨機產生輸入層與隱含層的連接權值和隱含層神經元的閾值,且在訓練過程中無需調整,只需要設置隱含層神經元個數,便可以得到全局最優解。與傳統的訓練方法相比,極限學習機具有學習速度快和訓練誤差小等優點。ELM模型的主要步驟為:①確定樣本集;②確定隱含層神經元個數,隨機生成輸入層與隱含層的連接權值和隱含層神經元閾值;③確定隱含層神經元的激活函數,計算隱含層輸出矩陣和輸出層權值矩陣,根據權值矩陣和激活函數,最終計算極限學習機模型的預測值。
粒子群算法是模擬群體智能所建立的一種優化算法,是基于鳥類的覓食行為而提出的全局尋優的一種方法。粒子群算法具有收斂速度快、可調參數少等優點,廣泛應用于神經網絡的優化。為了提高模型的預測精度,可用粒子群算法優化極限學習機的初始輸入權值和閾值,其優化流程如圖2所示。

圖2 PSO-ELM算法流程圖
1.6 模型的驗證
采用決定系數()和均方根誤差(RMSE)兩個指標來評價模型的精度。表示了預測值與實測值的擬合程度,其值越接近1,表明該模型的擬合效果越高;RMSE反映了預測值與實測值的偏離程度,其值越小,表明該模型的預測精度 越高。
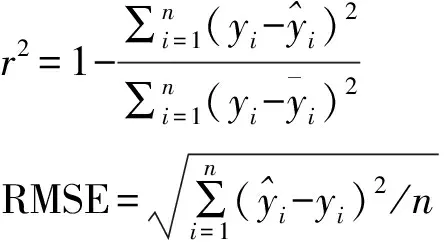

2 結果與分析
2.1 光譜反射率與葉片含水量的相關性
2.2 植被指數與葉片含水量的相關性
經皮爾遜相關性分析,選取的20個植被指數與冬小麥葉片含水量之間的相關程度不同,其中GNDVI、EVI、NRBDI與葉片水分含量的相關性達到顯著水平 (<0.05),其余植被指數與葉片水分含量的相關性達到極顯著水平(<0.01)(表2)。根據植被指數與葉片水分含量相關的顯著性原則,同時考慮模型的簡潔性,選取EXG、EXR、NGRDI、GI和TVI等5個相關性較高的植被指數作為模型的輸入變量。

表2 植被指數與葉片含水量的相關性Table 2 Correlation between vegetation index and leaf water content
*:<0.05; **:<0.01.
2.3 冬小麥葉片含水量的反演模型
為方便模型分析,將選取的紅、藍和近紅外波段作為第1組的模型輸入變量,記為敏感波段組;將選取的EXG、EXR、NGRDI、GI和TVI5個相關性較高的植被指數作為第2組的模型輸入變量,記為植被指數組。利用IBM SPSS Statistics 26軟件進行隨機抽樣,將獲得的46個樣本數據分為建模集和驗證集,70%的樣本數據(33個)用于建模,30%的樣本數據(13個)用于驗證,以此來構建冬小麥葉片含水量估算模型。
2.3.1 偏最小二乘(PLS)模型
采用敏感波段組和植被指數組通Origin 2021分析軟件分別建立的冬小麥葉片水分含量PLS模型的分別為0.65和0.80,RMSE分別為1.11%和0.82%(圖3),說明采用植被指數組所建的PLS模型的預測精度高。

圖3 冬小麥葉片水分含量的PLS預測結果
2.3.2 極限學習機(ELM)模型
通過MatlabR2020b編程軟件,利用兩組輸入變量分別建立基于ELM的冬小麥葉片水分含量反演模型,并對模型進行精度驗證。通過“試湊法”逐一實驗,最終確定隱含層神經元的個數為7,隱含層激活函數為“sigmoidal”函數。從圖4可以看出,采用敏感波段組和植被指數組建立的ELM模型的分別為0.79和0.84,RMSE分別為0.84%和0.74%,說明采用植被指數組所建模型的預測精度也較高。
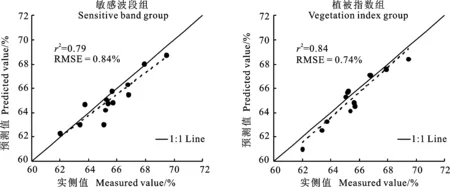
圖4 冬小麥葉片水分含量的ELM預測結果
2.3.3 粒子群優化極限學習機(PSO-ELM) 模型
通過MatlabR2020b編程軟件,用兩組輸入變量分別構建冬小麥葉片水分含量的PSO-ELM模型。為使得模型結果具有可比性,PSO-ELM模型的隱含層節點數與ELM模型保持一致。經過反復測試確定粒子群算法的參數:最大迭代次數為100次,種群規模為20,學習因子和均為1.494 45,粒子速度范圍為[-1,1]。采用敏感波段組和植被指數組建立的PSO-ELM模型的分別為0.92和0.98,RMSE分別為0.53%和0.26%(圖5),說明采用植被指數組建立的PSO-ELM模型的預測精度更高。
綜合來看,以上所有模型的均大于0.60,RMSE都小于1.12%,模型均能在一定程度上反映冬小麥農田光譜數據與實測葉片含水量之間的關系,且基于植被指數組構建的葉片水分含量預測模型的反演精度均高于基于敏感波段組構建的預測模型,其中基于植被指數組的PSO-ELM模型精度最高。

圖5 冬小麥葉片水分含量的PSO-ELM預測結果
2.4 研究區冬小麥葉片含水量的空間分布特征
為獲得整個研究區內冬小麥葉片含水量分布信息,將最優反演模型應用于研究區,繪制了研究區冬小麥葉片含水量的空間分布圖(圖6)。由圖6可知,研究區冬小麥葉片水分含量分布范圍為45%~75%,平均值為64.57%;地面實測冬小麥葉片水分含量分布范圍為50%~72%,平均值為64.55%。因此,基于無人機多光譜影像反演冬小麥葉片含水量的分布范圍與地面實際情況較為相符,研究結果可為農田尺度上冬小麥葉片含水量的空間反演和精準灌溉提供科學依據和技術 支持。

圖6 基于PSO-ELM模型的冬小麥葉片水分含量空間分布圖
3 討 論
作物水分含量的快速監測對于旱情監測和灌溉管理具有重要的現實意義。波段的光譜反射率和構建的植被指數均能與地面實測的葉片含水量有較好的相關性,因此基于多光譜各波段光譜反射率和植被指數構建的模型均可定量估算作物的葉片含水量。針對無人機多光譜數據估算冬小麥葉片含水量,本研究選取了20個植被指數和5個波段反射率,分別作為植被指數組和敏感波段組分析其與冬小麥葉片含水量的相關關系,確定的敏感波段為紅光波段、藍光波段和近紅外波段,這與Chen等的研究結果一致。本研究篩選的植被指數組為綠度指數、過紅指數、歸一化綠紅差值指數、三角形植被指數和過綠指數。同時發現,相關性較高的植被指數主要是紅波段、藍波段和近紅外波段的組合,這與相關性分析選取的敏感波段結果基本一致,并且與單波段相比,植被指數的相關系數有所提高。
作物冠層反射率主要受土壤背景、作物成分(如葉片含水量)和冠層結構(如葉傾角)三大因素影響。在不同的環境條件下,作物冠層結構也有所不同,從而引起波段或者植被指數對作物葉片含水量的敏感程度存在一定的差異,使得作物葉片含水量預測模型的普適性和估算精度降低。本研究對植被指數組和敏感波段組的建模預測效果進行對比發現,利用植被指數組構建的模型的精度和穩定性均優于敏感波段組。這主要是因為冬小麥在越冬期的田間覆蓋度較低,光譜反射率容易受到土壤等背景因素的影響,導致冠層光譜反射率噪音比較大,而植被指數具有較多的波段光譜信息,考慮了多光譜數據的敏感波段又剔除了信息冗余,能夠去除或者降低土壤背景等對植被光譜信息的影響,增強植被指數與葉片含水量之間的敏感性,以此提高了葉片含水量的估算精度。
本研究基于PLS、ELM和PSO-ELM的3種建模方法建立冬小麥葉片水分含量反演模型。PSO-ELM模型和ELM模型的反演精度均優于PLS模型,原因在于線性關系描述葉片含水量與植被光譜信息存在一些欠缺,難以精準解釋植被光譜構建葉片含水量之間的相關性;而PSO-ELM模型和 ELM 模型均用非線性函數來輸入輸出數據進行神經網絡的訓練,使訓練后的網絡能夠預測非線性函數輸出,可以有效解釋非線性的問題。PSO-ELM 模型的反演精度優于ELM模型,是因為ELM的初始輸入權值和閾值是隨機產生的,所以初始值會影響模型的訓練效果,導致基本粒子群陷入局部最優;而PSO算法優化了ELM的輸入權值和閾值,提高了模型的反演精度和穩定性。將構建的最優冬小麥葉片含水量模型應用于整個研究區后,預測結果較為準確,但本研究僅以越冬期冬小麥為研究對象,從敏感波段和植被指數出發構建了葉片含水量模型,未來需要結合冬小麥多個生育時期建立冬小麥葉片水分含量模型。
4 結 論
通過對5個多光譜波段和20個多光譜植被指數分別與地面實測冬小麥葉片含水量進行相關性分析,最終確定敏感波段為紅光、藍光和近紅外波段,敏感植被指數為EXG、EXR、NGRDI、GI和TVI。利用所選敏感波段、植被指數,建立冬小麥葉片含水量的 PLS、ELM、PSO-ELM模型并進行驗證,基于植被指數組構建的三種模型預測精度和穩定性均優于敏感波段組,其中基于植被指數組的PSO-ELM模型精度最高,其和RMSE分別為0.98和0.26%。利用植被指數組構建的PSO-ELM模型繪制冬小麥葉片含水量的分布圖,得到研究區冬小麥葉片水分含量與地面實測值較相符。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
