基于自動機器學習的全球尺度滑坡災害易發性預測
2022-10-20 10:35:00唐貴希方志策李朋磊
資源環境與工程 2022年5期
王 毅, 陳 曦, 唐貴希, 方志策, 李朋磊
(1.中國地質大學(武漢),湖北 武漢 430074; 2.湖北省地質調查院,湖北 武漢 430034;3.湖北省地質局 遙感應用技術中心,湖北 武漢 430034)
滑坡是一種常見的地質災害,在全球范圍內分布廣、發生頻率高、災害破壞力強,對人類生命和財產構成巨大威脅[1]。滑坡災害易發性預測能夠預測研究區內發生滑坡的空間概率,從而為滑坡災害風險管理及監測提供可靠的科學依據。滑坡易發性預測方法主要分為兩大類:確定性預報方法和非確定性預報方法。前者主要針對單個滑坡預測,包括適用于短期和臨期滑坡預報的齋騰迪孝法[2]、適用于長期滑坡預報的有限元法[3]等,此類方法通常具有嚴格且確定的數學函數關系式,且每個參數均有明確的解釋,能夠反映滑坡發生的物理實質[4]。后者主要包含知識驅動型和數據驅動型兩大類,基于非確定性預報的滑坡易發性預測方法經歷了從定性到半定量、再到定量的發展過程[5],該方法不強調預報模型中函數式的各個參數的準確性,而是通過調查宏觀地形地貌等一系列滑坡內外在影響因子,對滑坡進行空間規劃,更適于滑坡災害風險管理的宏觀決策,如Saboya等[6]運用模糊邏輯法將專家選擇的滑坡誘因轉換為模糊數,在巴西里約熱內盧進行了滑坡易發性預測。知識驅動型方法很大程度上依賴于專家知識,但人為因素干擾較大,導致滑坡易發性預測結果的精度偏低。
隨著3S技術的飛速發展,多源對地觀測數據越來越豐富,使得近年來滑坡數據的精度和可靠性也越來越高。面對海量數據,數據驅動型方法已經展現出強大優勢,其應用也日漸成熟,主要包括信息量[7-8]、多元統計分析[9-10]、證據權[11]、樸素貝葉斯(Naive Bayes,NB)[12]、隨機森林(Random Forest,RF)[13]、邏輯回歸[14-15]、支持向量機[16-17]、決策樹[12-18]、人工神經網絡[19-20]等統計學和機器學習模型。然而,機器學習方法需要專業研究人員進行極其繁瑣的模型選擇和參數調整等操作,因此降低使用機器學習的時間和人工成本已逐漸成為當前研究熱點。自動機器學習作為新興的智能學習方法,能夠自動篩選特征、自動選擇模型和動態調整模型參數,因此被廣泛應用于醫學圖像識別[21-22]、物體檢測[23-24]、語義分割[25-26]、文本分類[27]、損失函數搜索[28-29]等領域。
在多源數據的支持下,全球滑坡易發性研究愈發受到研究人員的重視。然而,全球尺度的滑坡災害易發性預測面臨諸多挑戰。首先,全球滑坡編目數據獲取較難,眾多易發性預測研究所使用的數據并未公開,即使能獲取研究數據,當將其應用于全球滑坡易發性預測時,往往需要大量的人工成本進行鑒別和篩選。其次,全球滑坡災害易發性預測還存在模型選擇較為局限、無法確定最優模型等難點。最后,目前全球滑坡易發性制圖精度普遍偏小,幾十千米至幾弧度的精度并不能有效應用于滑坡災害風險管理中。鑒于自動機器學習模型對于滑坡災害易發性預測具有良好的針對性,因此基于自動機器學習的全球尺度滑坡災害易發性預測研究具有廣闊的應用前景。鑒于此,本文基于全球滑坡開放數據集,充分利用自動機器學習的特性,并最大程度地提升模型預測性能。具體而言,擬以Auto-PyTorch自動機器學習模型為基礎,構建全球尺度滑坡易發性預測框架,探究自動機器學習在全球尺度下滑坡易發性預測中的可行性,期望為全球性滑坡災害風險管理提供科學依據。
1 數據準備與分析
1.1 滑坡編目數據
滑坡編目數據對于易發性預測和后續驗證評價舉足輕重。然而,開展全球尺度下的滑坡易發性預測時,滑坡數據精度參差不齊,其完整性和精確性也難以保證。本次研究選用了全球開放在線滑坡存儲庫(Cooperative Open Online Landslide Repository,COOLR),該存儲庫是基于美國國家航空航天局啟動的全球滑坡目錄(Global Landslide Catalog,GLC)進行的深度開發產品[30],記錄了2007年以來山體滑坡的信息來源、源鏈接以及滑坡發生時間、發生位置、誘發原因、誘發事件的具體描述、滑坡規模、數據精度等。此外,本次研究還使用了全球致命滑坡數據庫(Global Fatal Landslide Database,GFLD),該數據庫記錄了2004—2017年間對人類造成生命威脅的山體滑坡的發生時間、發生位置、誘發原因、造成的人員傷亡情況、數據精度等[31]。
需特別指出的是全球尺度的滑坡數據庫存有量極其有限,即便已發布COOLR和GFLD,但仍無法滿足全球滑坡易發性制圖數據規模的要求。因此,研究中搜集了部分篩選的精確區域滑坡數據集對全球尺度的滑坡編目數據進行補充,如意大利國家滑坡數據庫(FraneItalia)記錄了2010—2019年間意大利發生的山體滑坡事件,根據滑坡數量、類別和人員的生命財產損失程度進行了分類,而滑坡數據精度運用確定、近似和市政提供的滑坡數據三個等級進行劃分[32];澳大利亞山體滑坡數據庫記錄了2008—2018年間澳大利亞的滑坡數據,根據數據來源的可信度,將滑坡劃分為GPS測量、GIS定位、地圖定位、衛星影像定位、本地報道、根據報告定位的滑坡以及未知等類別[33];新西蘭國家滑坡數據庫(New Zealand Landslide Database,NZLD)同樣是一個共享數據庫,但缺少數據精度的信息解釋[34];美國華盛頓州[35]和猶他州[36]的滑坡數據庫同樣根據精度信息對滑坡編目數據進行了分類。
滑坡編目數據精度對于易發性研究至關重要。由于不同滑坡數據庫的數據精度各不相同,為了增加全球尺度下滑坡易發性預測的可信度,需要對以上搜集的滑坡數據進行篩選。對于全球滑坡數據庫而言,選擇COOLR和GFLD兩個數據庫1 000 m以下的滑坡數據;對于局部區域滑坡數據庫而言,選擇FraneItalia中確定和近似兩個精度等級的滑坡數據,選擇澳大利亞山體滑坡數據庫GPS測量、GIS定位、地圖定位、衛星影像定位四種來源的滑坡數據,選擇NZLD中有具體時間記錄的滑坡數據,選擇美國華盛頓州和猶他州滑坡數據庫中精度等級為高的滑坡數據。最后,在表1中列出了各滑坡數據庫在90 m精度下的具體滑坡數據量等信息,重采樣至1 000 m后滑坡數據量為14 290個。
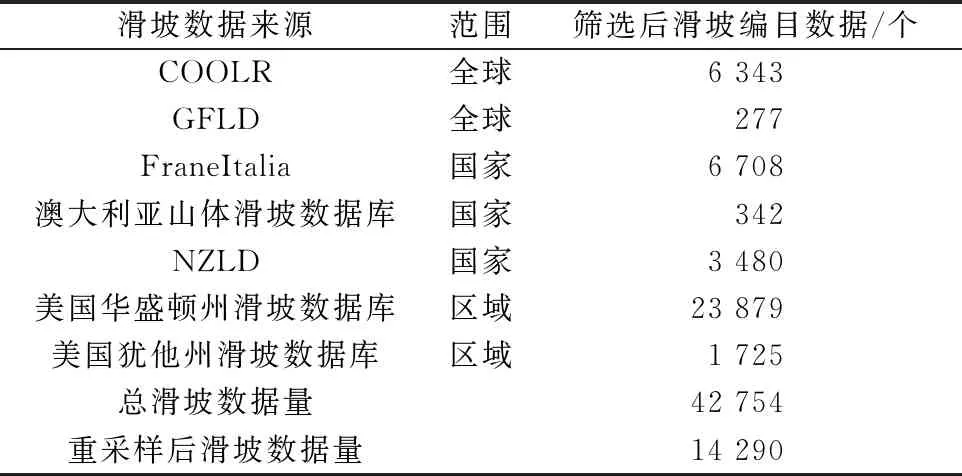
表1 滑坡數據來源
1.2 滑坡影響因子
研究區域為全球60°N-60°S緯度范圍內,其滑坡易發性預測是基于SRTM DEM 90 m數據的Version 4版本來完成[37],該數據是位于全球60°N-60°S緯度范圍內的高程數據集(圖1)。同時考慮了全球尺度滑坡樣本空間分辨率不夠精細的內因以及制圖時間效率偏低的外因,將SRTM DEM 90 m數據重采樣至1 000 m,并基于此精度開展全球滑坡易發性制圖研究(圖1-a)。具體地,滑坡易發性預測研究中所采用的坡度(圖1-b)、坡向(圖1-c)、平面曲率(圖1-d)和剖面曲率(圖1-e)等因子均基于重采樣的SRTM DEM數據進行提取。
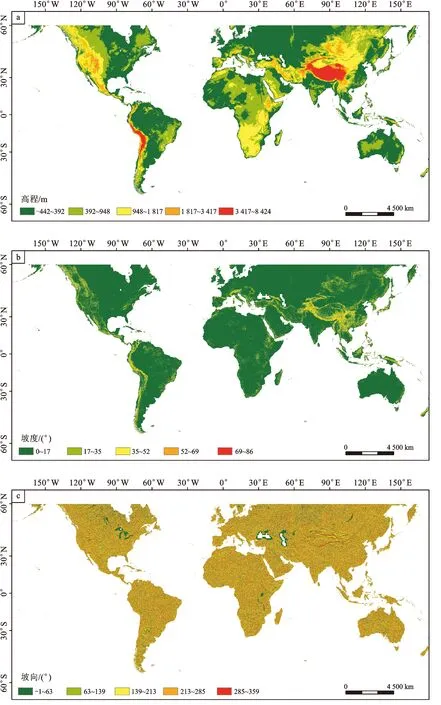
圖1 基于DEM的滑坡影響因子專題圖
巖性數據對于易發性預測至關重要。不同種類的巖石所能承受應力不同,在雨水、植被等作用下的內部應力變化也各不相同,然而大多精度更高的巖性數據庫無法有效支持在全球尺度下的易發性預測。本次研究所使用的巖性數據來自全球巖性數據庫(Global Lithological Map,GLiM),該數據庫是將全球范圍內多張區域可用最高分辨率的巖性數據圖組合而成,根據精細度、數據量及數據一致性等準則進行數據合并,共包含16種巖性[38](圖2)。
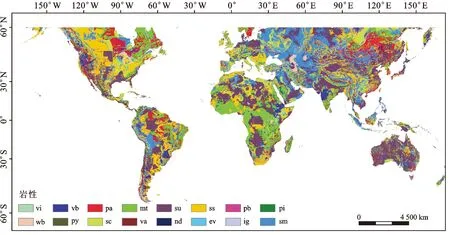
圖2 巖性因子專題圖
土地覆蓋狀況對于誘發滑坡同樣重要。土地覆蓋狀況相較于巖性數據在時間尺度上變化更頻繁,考慮到滑坡數據均為2010年左右采集,并綜合考慮數據量和土地覆蓋數據出圖時間,采用歐洲航天局于2009年發布的全球陸地覆蓋數據GlobCover(圖3)[39]。其空間分辨率為300 m,該數據運用Envisat衛星中MERIS(Medium Resolution Imaging Spectrometer)傳感器進行采集,土地覆蓋數據的地物類別詳見文獻[39]。
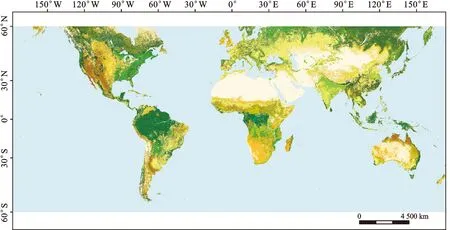
圖3 土地覆蓋因子專題圖
降雨是滑坡的另一大誘因。本次研究選取了東英吉利大學氣候研究部門發布的WorldClim 2數據集[40-41]。以2000—2018年的世界降雨量數據的平均值作為降雨量因子,空間分辨率為21 km(圖4)。
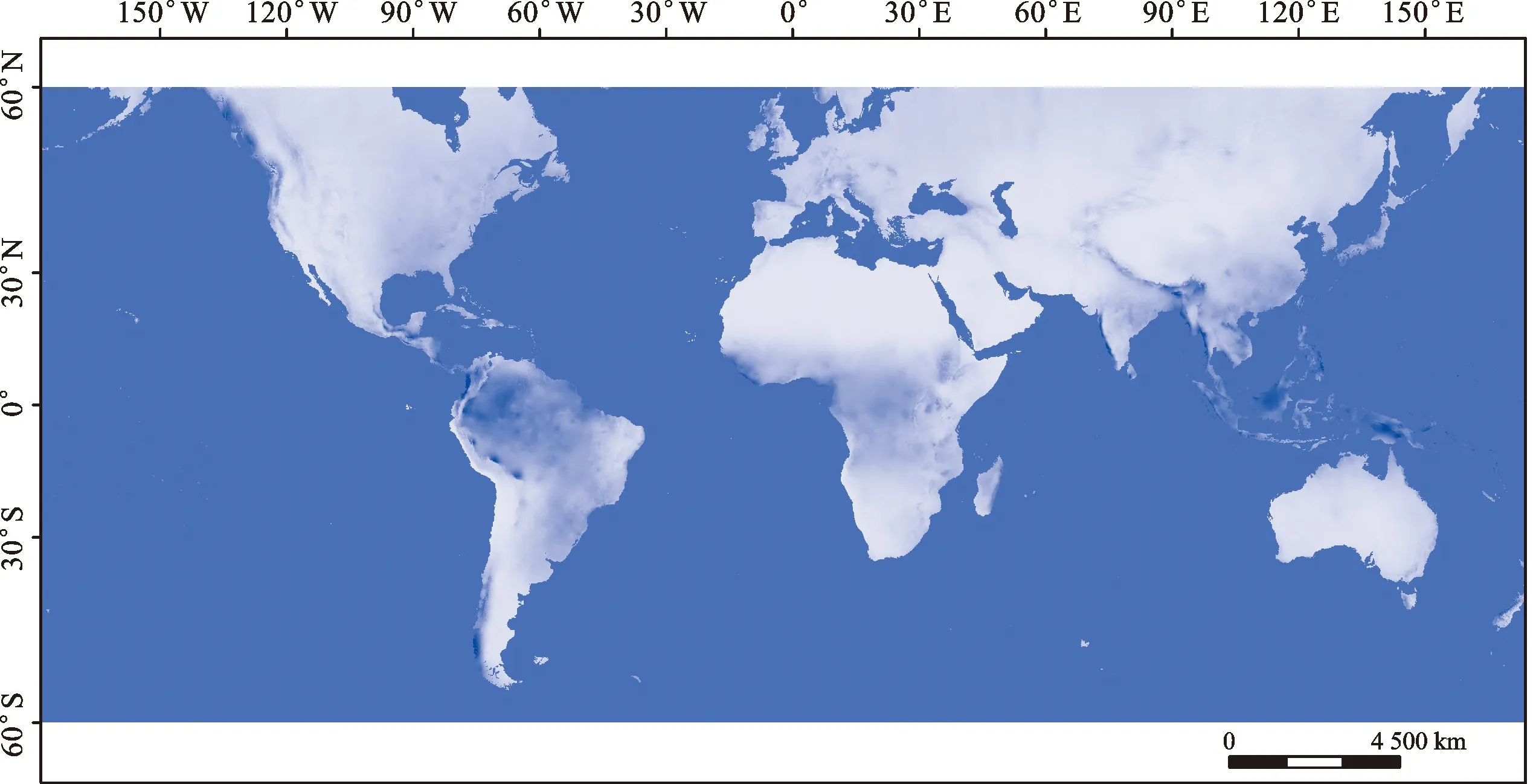
圖4 降雨量因子專題圖
地球上主要有三大地震帶:環太平洋火山地震帶、歐亞地震帶和洋脊地震帶。地震發生時能觸發大量滑坡,而震后由于改變斜坡受力結構,同樣會導致滑坡不斷發生。本次研究采用全球地震模型基金會(GEM)發布的全球主動斷層數據庫(GAF-DB)[42],將計算的距離斷層數據的歐式距離作為斷層距離因子數據(圖5)。
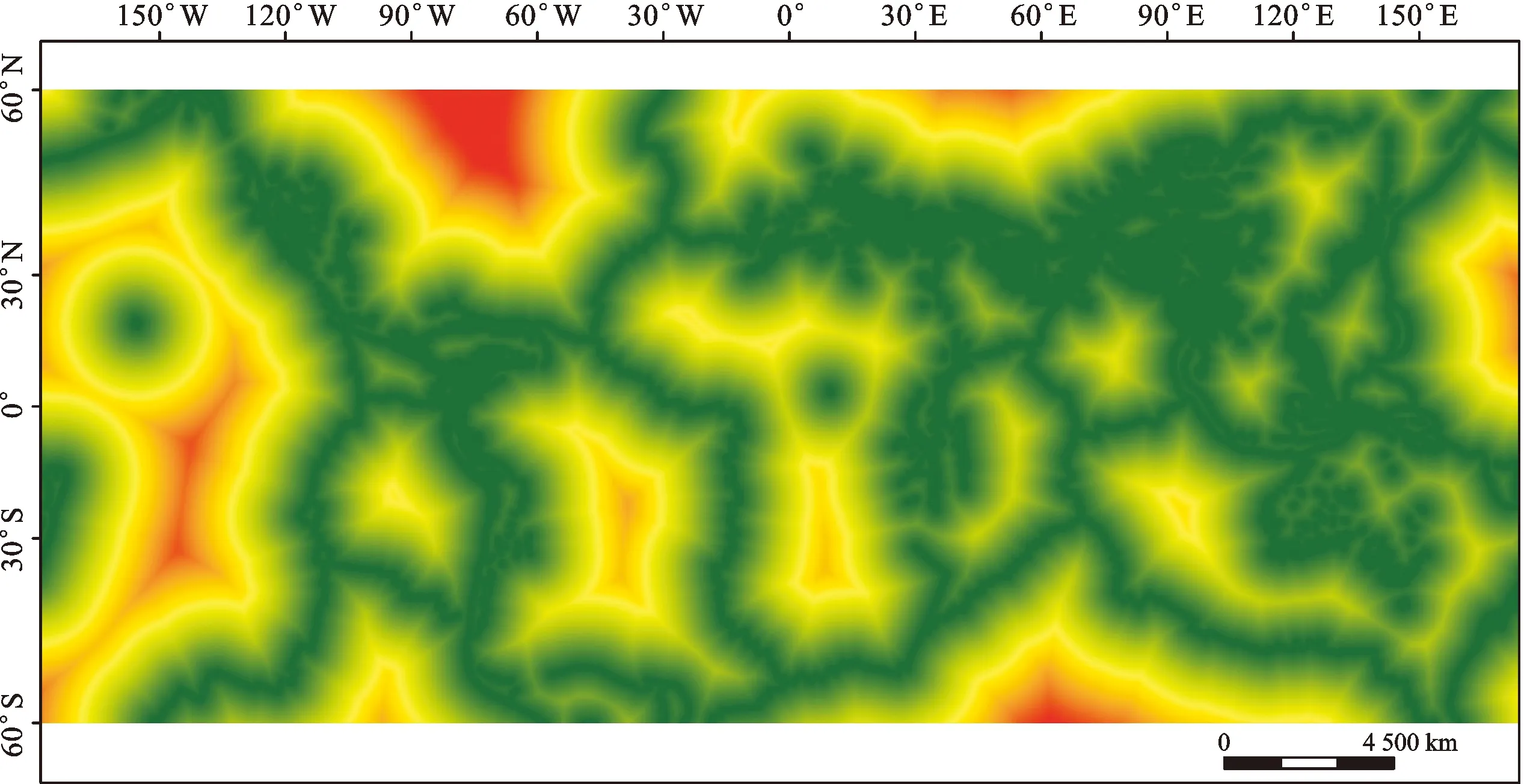
圖5 斷層距離因子專題圖
為了保持精度一致,以上所有因子均重采樣至1 000 m 的空間分辨率,并且所有數據集都保持在WGS84 CRS(EPSG:4326)坐標系下進行制圖,各因子的重分類則由自然斷點法來實現。
2 滑坡易發性評價模型
本次研究的主要目的是探究自動機器學習進行全球尺度滑坡易發性預測的可行性,其總體技術路線如圖6所示。首先,獲取全球滑坡多源數據,包括滑坡編目數據和影響因子數據。其次,將滑坡影響因子重采樣至相同空間分辨率,再將滑坡編目數據與滑坡影響因子進行疊置分析,將滑坡編目數據劃分為訓練數據和測試數據。然后,采用自動機器學習方法進行模型構建,此次采用了開源自動機器學習平臺Auto-PyTorch[43]。將自動機器學習方法與兩種傳統機器學習方法RF(也是經典集成學習模型)、NB進行對比。最后,選取三種方法中各項評價指標最優的模型進行最終全球尺度滑坡易發性預測制圖。

圖6 技術路線圖
2.1 自動機器學習模型
眾所周知,機器學習模型的選擇在實際應用中需耗費大量時間成本和技術成本,同時對于選定模型的參數確定還需要專業數據研究人員的不斷調試。在很多情況下,研究人員并不能找到最優參數,并且其調出的參數也不具有可解釋性。自動機器學習可以看作是對傳統機器學習一定意義上的顛覆性改進,它不僅能夠對參與訓練的特征進行自動篩選,還能自動選擇模型,并自動對模型參數進行動態調整,極大程度地減少模型應用的時間與技術成本。此外,它還能夠有效提升傳統機器學習模型的處理效果。
本次研究運用的Auto-PyTorch是開源的自動機器學習平臺,早期更關注于自動選擇和優化傳統機器學習模型,而在后續加入了依賴于PyTorch框架[43]的深度學習框架,該框架利用多保真度優化來對神經網絡架構及其中的超參數進行優化。Auto-PyTorch實現并自動調整完整的深度學習管道,包括數據預處理、神經架構、網絡訓練技術和正則化方法。此外,它還通過從產品組合中抽樣配置以及自動集成選擇來預啟動優化。其自動機器學習模型中也包括傳統的機器學習模型,例如輕量級梯度提升機器和支持向量機等,用于解決所提供數據集的回歸或分類任務。在使用傳統機器學習模型篩選時,引入了貝葉斯優化,輸出模型時采用了集成模型。充分利用了之前模型選擇和超參選擇時的探索結果。集成模型的使用使得之前的搜索結果沒有被浪費,進一步提高了模型的泛化性。
2.2 模型評價指標
為了客觀評價易發性預測模型的性能,本文采用了多個統計學評價指標,包括變動率指標(Price Rate of Change,ROC)曲線、ROC曲線下面積的值(Area Under Curve,AUC)、準確率(Accuracy,ACC)、均方根誤差(Root Mean Square Error,RMSE)和平均絕對誤差(Mean Absolute Error,MAE)。其中AUC和ACC的取值范圍為0~1之間,越接近1,表示該模型性能更優越;RMSE與MAE的取值范圍同樣為0~1,其值越接近0表示該模型性能更優。
ACC計算公式為:
(1)
式中:TP為正確識別正樣本的數量;TN為正確識別負樣本的數量;FP為被誤報的負樣本數量;FN為被漏報的正樣本數量。
RMSE和MAE的計算公式為:
(2)
(3)
式中:n為測量的次數;oi為真實數據;pi為預測數據。
3 實驗結果與分析
3.1 滑坡評價因子分析
本次研究使用了Python編程工具,并以Auto-PyTorch庫為基礎,對自動機器學習進行了建模。此外,利用Sklrearn庫作為傳統機器學習的模型基礎,構建了RF和NB兩種傳統機器學習模型。研究實驗環境包括:16核CPU、2塊GPU(NVIDIA GeForce RTX 3090,單個顯存為24 GB)和128 GB內存。
由表1可知,全球滑坡編目數據重采樣到1 000 m后,其滑坡數量為14 290個樣本,同樣在非滑坡區域隨機選擇14 290個非滑坡樣本。對全球滑坡數據和滑坡影響因子圖層進行疊加,并在疊加后對該多維矩陣數據按7∶3比例進行分割。其中,70%的樣本數據用于滑坡易發性自動機器學習模型構建,剩余30%的樣本數據用來驗證模型性能。
由于自動機器學習具有自動選擇特征,因此本研究無需因子篩選和重要性分析過程。首先,對自動機器學習模型進行訓練。為了兼具效率和性能,自動機器學習模型的學習時間設定為0.5 h,采用模型評價指標定量評估Auto-PyTorch、RF和NB的性能優劣。最后,選擇性能最優的自動機器學習模型進行后續建模和易發性制圖。
3.2 滑坡易發性預測圖
為了驗證基于自動機器學習的全球尺度滑坡易發性預測的可行性,將Auto-PyTorch自動機器學習模型分別與RF和NB兩種傳統機器學習模型進行了對比分析出圖。將研究區按滑坡的易發性大小分為五個等級:極低、低、中、高和極高易發區,易發性等級分區方法選擇自然斷點法[44]。Auto-PyTorch自動機器學習模型與RF、NB兩種傳統機器學習模型的全球尺度滑坡災害易發性預測結果分別如圖7-a、圖7-b、圖7-c所示,Auto-PyTorch模型易發性分區與滑坡點堆疊圖如圖7-d所示,可以看到三種模型的全球滑坡預測結果中高與極高易發性區域與滑坡編目數據非常吻合,自動機器學習模型尤其優秀,表明自動機器學習在全球尺度下進行滑坡易發性預測具有良好的可行性。
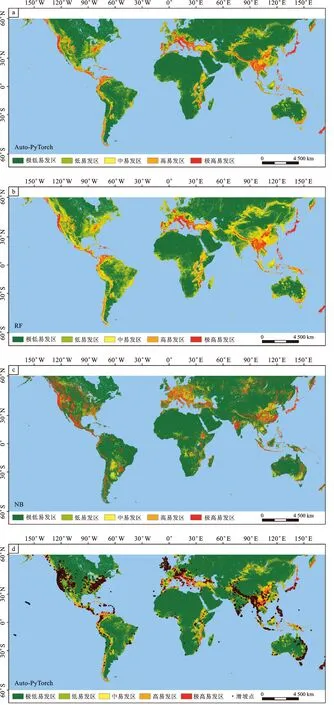
圖7 滑坡災害易發性分區圖
3.3 模型比較與驗證
表2給出了三種機器學習模型的評價結果。其中,Auto-PyTorch模型的各項指標均最優,ACC、AUC、RMSE和MAE分別為0.901 4、0.963 2、0.313 9和0.098 5;RF模型次之,其各項指標比Auto-PyTorch模型略低,ACC、AUC都略微下降0.004 7,RMSE與MAE分別增加0.007 3和0.004 7。雖然差距較小,但是僅訓練10 min的Auto-PyTorch模型的潛力還是優于RF模型。NB作為傳統機器學習模型,雖然AUC超過0.8(達到0.839 3),能算是優良的結果,但各項數值相比Auto-PyTorch模型和RF模型下降許多,較之最優秀的Auto-PyTorch模型,ACC、AUC分別下降0.154 9和0.123 9,RMSE與MAE分別增加0.189 5和0.154 9。結果表明,Auto-PyTorch模型能夠自動選擇模型和動態調整參數,在節約時間的同時還能提升精度。圖8給出了三種模型的ROC曲線,可看出Auto-PyTorch模型明顯優于傳統機器學習模型。以上實驗結果進一步驗證了自動機器學習的優勢,也證明了自動機器學習在全球尺度下滑坡易發性預測的應用價值。為了探究訓練時間的長短對于自動機器學習性能的影響,以Auto-PyTorch模型為例,分別設定10 min和30 min作為訓練時間進行模型性能比較。如表2所示,訓練30 min的ACC較訓練10 min的ACC增加0.001 4,由于模型是根據ACC高低進行篩選,AUC在其他指標增加的情況下略微下降0.000 8,而RMSE和MAE分別下降0.002 3和0.001 4。如圖8所示,自動機器學習模型較長的訓練時間能得到更優越和綜合提高的精度。
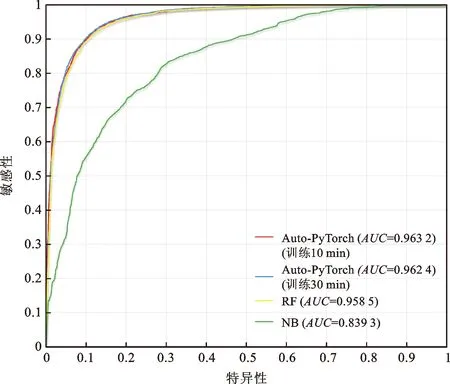
圖8 模型ROC曲線

表2 模型精度評價結果
4 結論
本文開展了基于自動機器學習的全球尺度滑坡災害易發性預測研究,以全球60°N-60°S緯度范圍作為研究區,采用坡度、坡向、平面曲率、剖面曲率、巖性、土地覆蓋、降雨量、斷層距離9個滑坡影響因子,運用Auto-PyTorch自動機器學習模型和RF、NB兩種傳統機器學習模型進行了滑坡易發性建模工作,旨在探討自動機器學習在全球尺度下滑坡易發性預測的可行性。研究結果表明,三種模型的全球滑坡易發性制圖結果與滑坡編目數據的趨勢非常吻合,Auto-PyTorch模型吻合程度格外優秀;提升訓練時間能夠在一定程度上提升模型預測性能。具體而言,在各模型中,NB模型的各項指標為最低,RF模型的各項指標略遜色于Auto-PyTorch模型。AUC最高的為訓練10 min的Auto-PyTorch模型,ACC、RMSE、MAE最佳的為訓練30 min的Auto-PyTorch模型;各項指標最優的Auto-PyTorch模型較NB模型而言,AUC、ACC分別增加0.123 9、0.156 3,RMSE和MAE分別下降0.191 8、0.156 3,證明了Auto-PyTorch模型的優越性能。此外,自動機器學習還存在不可解釋性,未來解決該問題能夠更加有效地提升自動機器學習在全球尺度滑坡災害易發性預測中的應用潛力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
核科學與工程(2015年4期)2015-09-26 11:59:03
