基于CNN-LSTM的軸承剩余使用壽命預測
2022-10-21 07:17:36蔡薇薇徐彥偉頡潭成
機械傳動 2022年10期
蔡薇薇 徐彥偉,2 頡潭成,2
(1 河南科技大學 機電工程學院, 河南 洛陽 471003)
(2 智能數控裝備河南省工程實驗室, 河南 洛陽 471003)
0 引言
技術進步促進交通工具革新,現代鐵路,尤其是高速鐵路,扮演著舉足輕重的角色[1]。對鐵路軸承疲勞壽命進行準確預測,一直是鐵路學者們關心而又難以解決的課題[2]。當前,對機械設備中的關鍵部件采用剩余使用壽命(Remaining useful life,RUL)預測技術,來決定維修管理時機的方法得到越來越廣泛的重視[3]。RUL 綜合反映了機械設備關鍵部件的受損程度,通過對RUL 預測技術的研究,能提前發現機械設備中關鍵部件的異常,對其未來的性能退化趨勢進行研究,及時進行有效維護[4]。如果在軸承失效前可準確地預測出其剩余使用壽命,便可及時采取預防措施,從而避免造成重大的經濟損失。
滾動軸承剩余壽命預測方法大致可分為基于模型驅動和基于數據驅動兩大類[5]。丁鋒等[6]采用基于設備振動信號的均方根、峭度等統計特征,利用比例故障模型實現了對鐵路機車輪滾動軸承的可靠性評估。王奉濤等[7]將通過核主元分析降維后的核主元作為威布爾比例故障模型的協變量估計模型參數,對滾動軸承進行剩余壽命預測,取得了很高的準確度。王豪等[8]將多個特征組合為一個特征樹,將優化特征作為模型,對軸承剩余壽命進行了預測。這些基于模型驅動的方法能夠對滾動軸承剩余壽命進行比較準確的預測,但對于復雜的機械系統存在難建模、預測精度低等缺點。計算機技術的發展對研究數據驅動的機械設備剩余壽命預測方法有極大的推動。高斯博[9]利用線性Wiener 過程,陳法法等[10]使用小波支持向量機,李洪儒等[11]使用極限學習機進行了剩余壽命預測。但這些方法需要先進行人工構造特征,并且在模型復雜度和學習能力上與深度學習方法有一定差距。隨著現代計算能力的快速提升和計算效率的提高,深度學習方法因其在復雜系統中強大的學習能力,已成為預測領域的新興研究課題之一[12]。在大多數情況下,深度學習方法可利用振動信號來監測滾動軸承的健康狀況,因為信號中包含了故障發生的重要信息[13]。申彥斌等[14]提出了一種基于雙向長短時記憶網絡的循環神經網絡結構,利用其對處理時間序列數據的能力,對軸承在實際工作過程中的退化規律進行學習,實現了對軸承的剩余使用壽命預測。董紹江等[15]針對滾動軸承退化性能難以評估、壽命狀態難以識別的難題,基于卷積自編碼器與多維尺度分析算法構建軸承性能衰退指標,再根據構建指標和改進卷積神經網絡建立軸承壽命狀態識別模型,實現了軸承壽命狀態的識別。康守強等[16]針對稀疏自動編碼器采用Sigmoid 激活函數容易造成梯度消失的問題,提出了一種新的Tan函數替代原有的Sigmoid 激活函數,并采用Dropout 機制對網絡進行稀疏性約束,將提取出的深層特征作為滾動軸承的性能退化特征,實現了對滾動軸承的RUL 預測。這些研究都取得了很好的結果,但都是針對單工況數據進行的研究。
針對以上問題以及設備到達服役時間而依然健康所造成的浪費問題,本文中對完成服役時長仍健康的高鐵牽引電機軸承進行試驗,并使用深度學習方法建立剩余壽命預測模型,直接從原數據挖掘出有用的信息,對軸承的剩余使用壽命進行了預測。
1 高鐵牽引電機軸承試驗
1.1 高鐵牽引電機軸承試驗臺
高鐵牽引電機軸承剩余壽命試驗臺與信息采集系統由試驗主體、高鐵牽引電機軸承NU210、液壓加載系統、傳感器信息采集模塊、通風設置及計算機等組成,整體結構如圖1所示。試驗臺主軸轉速范圍為0~6 000 r/min,靠近試驗軸承箱處的風速為8~10 m/s。

圖1 高鐵牽引電機軸承試驗臺Fig.1 High speed railway traction motor bearing test bench
1.2 采集系統
如圖2 所示,采集系統由2 個振動傳感器(型號為LC0151T,靈敏度為150 mv/g,量程為33 g,分辨率為40 kHz,諧振頻率為0.000 2 kHz,頻率范圍為0.7~13 000 Hz)、1 個信號放大器、1 個信號調理器(型號為LC0201-5)、PCI采集卡(型號為PCI8510,8通道同步采樣,采樣頻率為500 kHz)和計算機組成。由振動傳感器采集的電流型信號經信號調理器處理為電壓型信號,再通過PCI采集卡存至計算機,最終由計算機實現對信號的分析及處理。
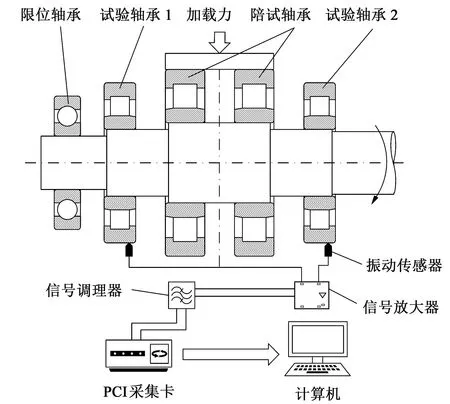
圖2 采集系統原理簡圖Fig.2 Schematic diagram of acquisition system
1.3 試驗參數及試驗方案
本次試驗是將已運行1.45×106km 里程數,完成其服役工作后仍健康的高鐵牽引電機軸承NU210再運行2.7×105km 的里程。根據實際工況,試驗過程中軸承所受徑向載荷為5 kN,由于高鐵實際運行中Vmax≥200 km/h,參 考TB/T 3017.2—2016[17]要 求,本文中采用4 h 循環試驗,即試驗主軸先正向轉動105 min,停止15 min,再反向轉動105 min,停止15 min,在停止期間不進行通風。
該高鐵線路單程里程數為968 km,1個往返循環的里程數為1 936 km,完成試驗需要進行140個循環。為更好地模擬高鐵牽引電機實際工作狀態,每天進行4 個循環(即7∶00~11∶00,11∶00~15∶00,15∶00~19∶00,19∶00~23∶00)。試驗安排如表1所示。

表1 試驗安排表Tab.1 Test schedule
2 CNN-LSTM 模型的建立
2.1 一維卷積神經網絡

對于傳感器數據在時間序列的分析,一維神經網絡有著較強的特征提取能力,可以被用于固定長度信號的分析[18]。其卷積層和池化層的數學模型分別為式中,W為池化區域的寬度;(t)為第l層中第i個特征矢量中的第t個神經元的值;t∈[(j-1)W+1,jW];P(j)為第l+1層中神經元對應的值。
2.2 長短時記憶網絡
長短時記憶網絡(LSTM)是循環神經網絡(RNN)的改進,具有長時間和短時間的序列記憶,可以學習到序列之間潛在的時間關系[19-20]。LSTM 原理的數學模型為:
(1)計算輸入門需要保存的信息
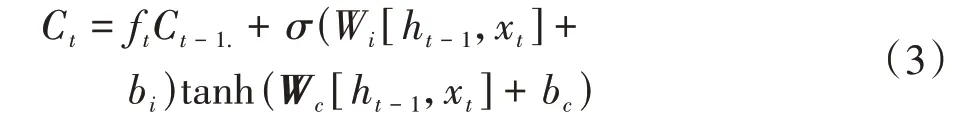
式中,Ct為LSTM 輸入門中的細胞狀態信息;Ct-1為上一個細胞狀態信息;Wc為權重矩陣;bc為偏置參數;tanh 為激活函數。
(2)計算遺忘門需要刪除的信息
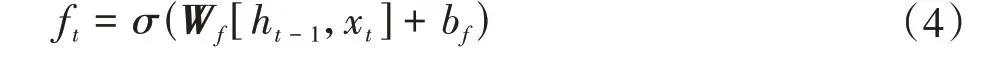
式中,xt為輸入的特征矢量;σ為sigmoid 激活函數;Wf為訓練的權重矩陣;ht-1為上一時刻的隱藏層信息;bf為偏置參數;ft為保留信息的權重。
(3)計算輸出門需要輸出的信息
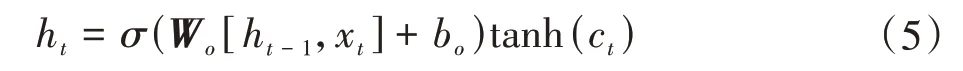
式中,ht為輸出門的輸出信息;Wo為訓練的權重矩陣;bo為偏置參數。
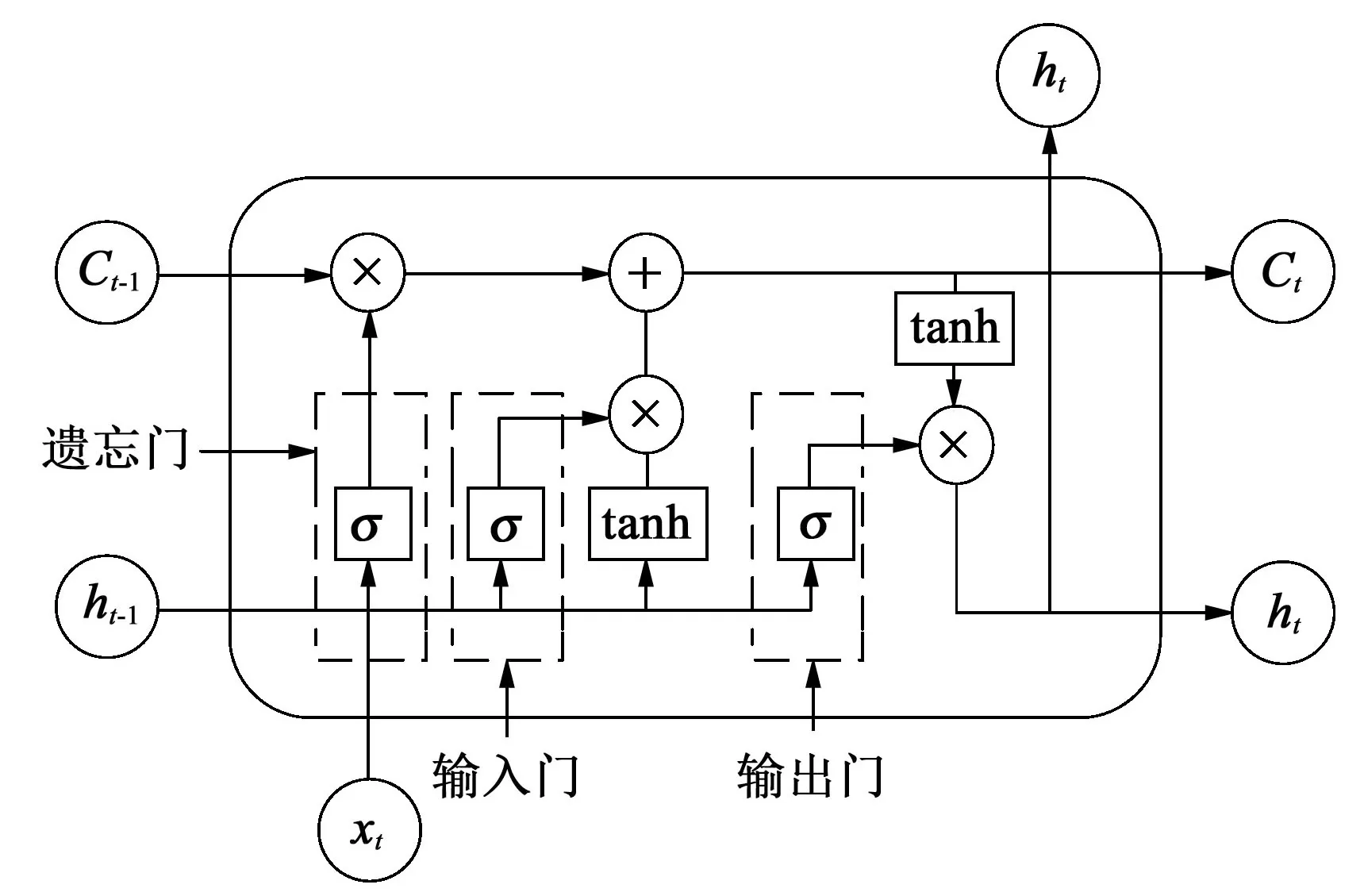
圖3 LSTM網絡結構圖Fig.3 LSTM network structure diagram
2.3 基于CNN-LSTM 的軸承剩余使用壽命預測方法
圖4所示為剩余使用壽命預測流程圖。其流程各模塊的功能為:
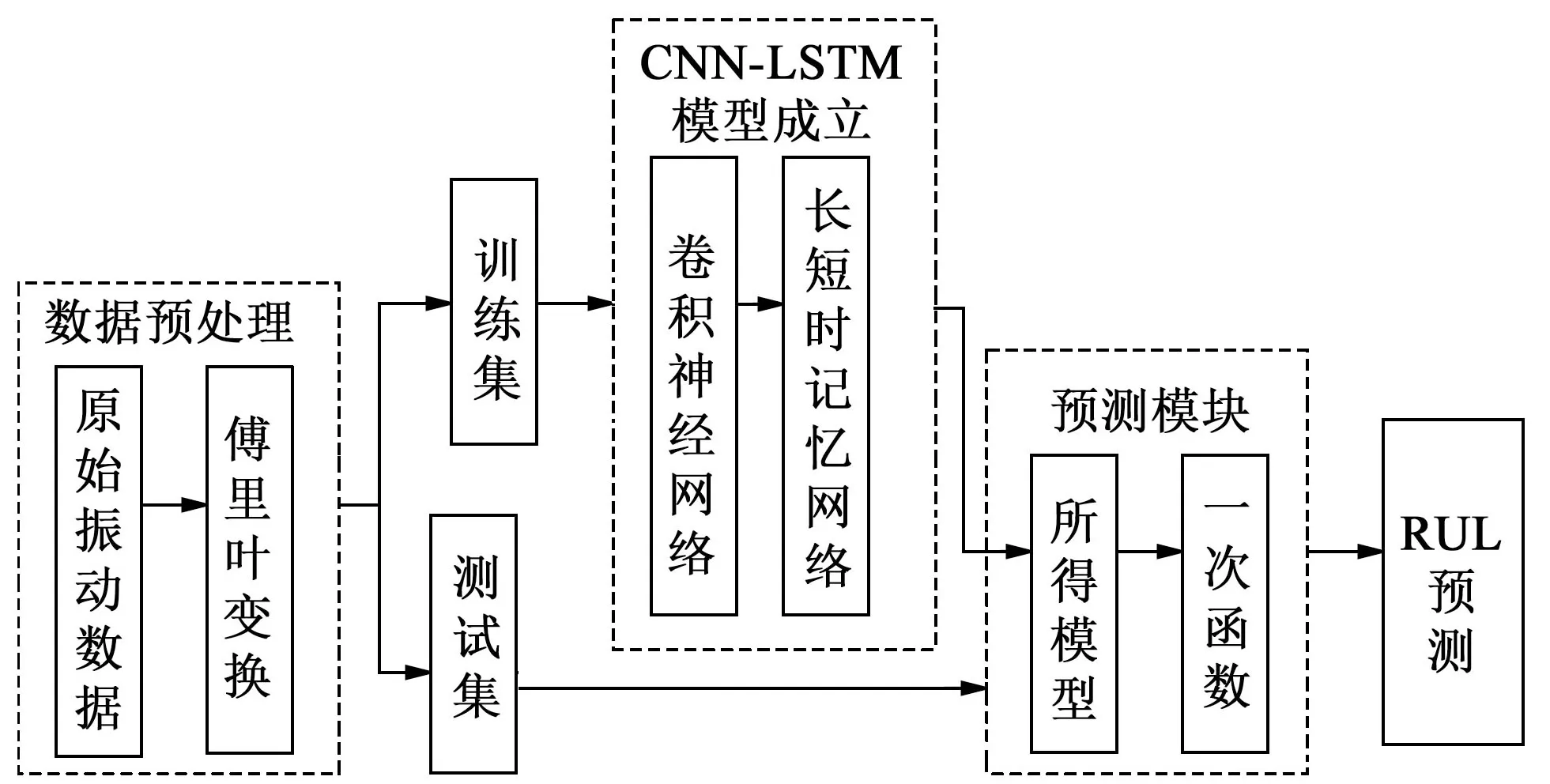
圖4 剩余使用壽命預測流程圖Fig.4 Flow chart of remaining service life prediction
數據預處理:把原始振動數據經過FFT 變換,轉化為頻域信號;把數據集劃分為測試集和訓練集。
CNN-LSTM 模型:輸入為頻域信號,CNN 學習振動信號不同頻帶的特征,再通過LSTM 學習序列數據潛在的時間關系,對其深層特征進行有效挖掘,進而輸出當前剩余使用壽命的狀態值。
預測模塊:測試集輸入建立的CNN-LSTM 模型中,輸出為當前狀態值C,再根據一次函數,輸出剩余使用時間。剩余使用時間Fc的表達式為

式中,Ctc為總特征值;Ccc為當前特征值。
3 滾動軸承RUL預測
本文中以50 kHz的采樣頻率,每5 min采集1次,每次采集時長為1 s 的方式對高鐵牽引電機軸承的振動信號進行采集。每次采集50 000個數據點,每個循環有42個采集點,試驗共有5 880個采集樣本。
根據香農采樣定理,選擇每2 275個數據為1組小樣本。本文中把每個采樣點分為前后兩部分,即45 450 個數據點和4 550個數據點。圖5所示為數據分段。將前半段的45 450個數據點采用重疊采樣的方法分成50組小樣本數據,作為訓練集,各組小樣本數據含有2 275個數據點;后半段數據不進行重疊采樣,直接截斷成2個數據長度均為2 275的小樣本作為測試集。
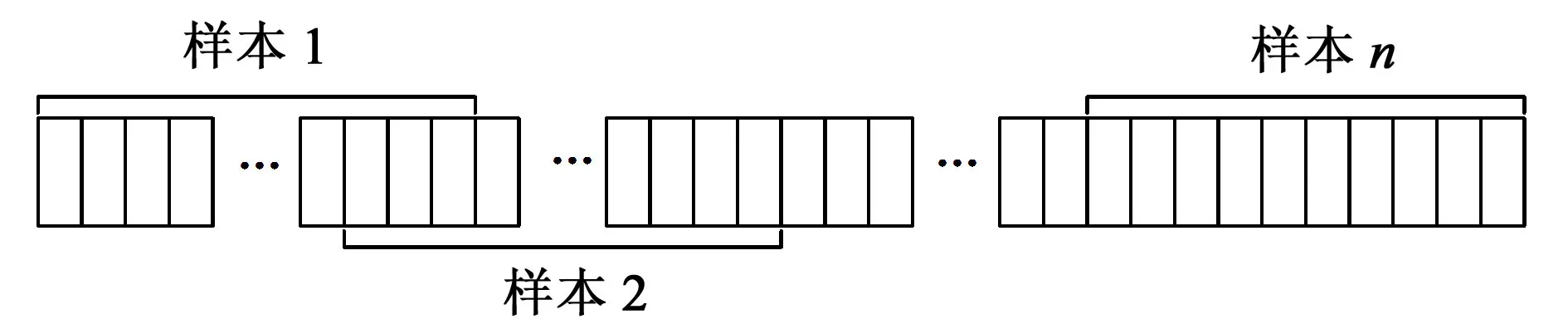
圖5 數據分段Fig.5 Data segmentation
本文中的數據分析均以試驗軸承2 為例。圖6、圖7所示分別為試驗軸承2在2 644 r/min和5 817 r/min時某樣本的時域及頻域信號圖。
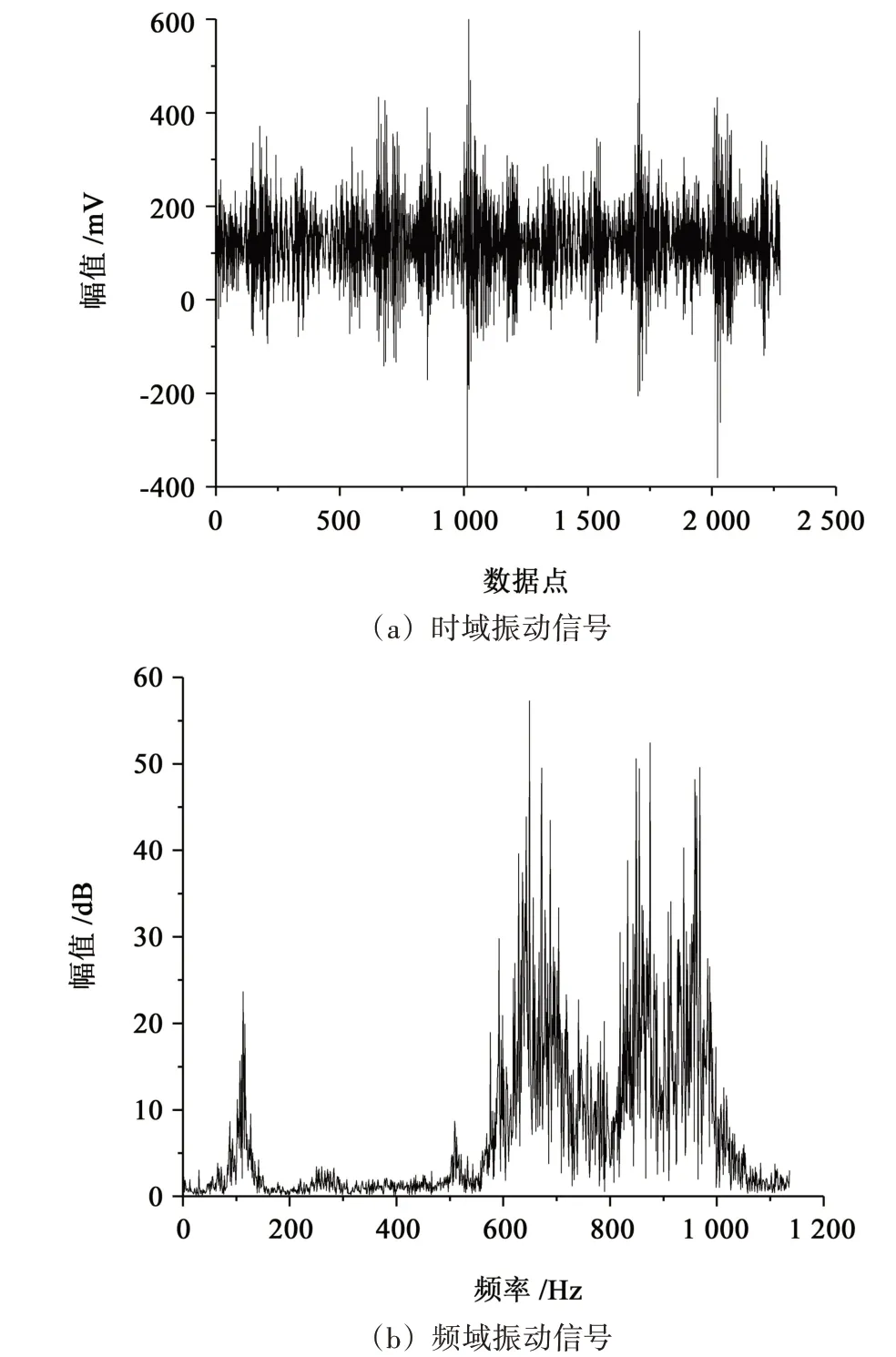
圖6 2 644 r/min時某樣本時域及頻域信號波形圖Fig.6 Time domain and frequency domain signal waveform of a sample at 2 644 r/min
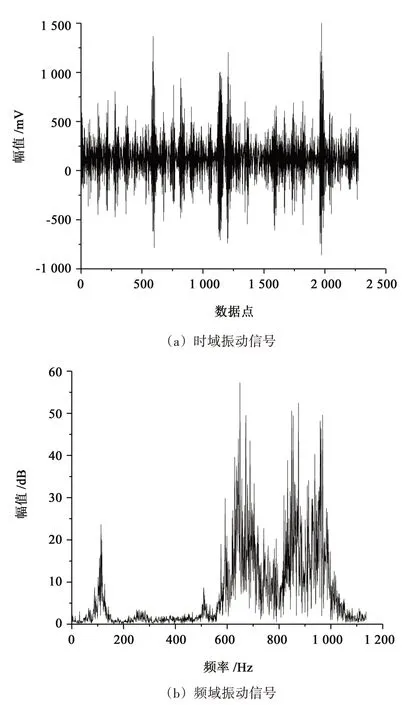
圖7 5 817 r/min時某樣本時域及頻域信號波形圖Fig.7 Time domain and frequency domain signal waveform of a sample at 5 817 r/min
根據單次循環轉速的變化,把試驗數據分為6部分。表2所示為各部分原數據按以上分段處理后得到的數據集。這6 部分都包含了140 種狀態值。其中,編號0、編號2、編號3、編號5 中的各狀態中包含7種特征點,編號1、編號4 的各狀態中包含6 種特征點。
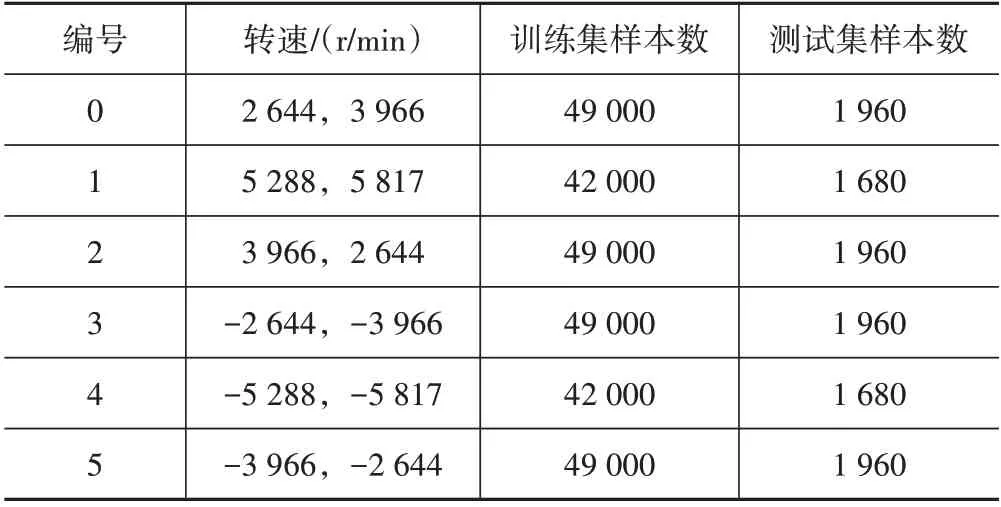
表2 試驗數據集描述Tab.2 Test data set description
經多次調試,最終確定CNN-LSTM 模型的組成部分為:2個卷積層、2個池化層、1個LSTM 層。在卷積層前添加了1 個BN 層。其中,卷積層激活函數選用Relu,LSTM 層激活函數選用Tanh。之后,添加1 個輸出維度為256 的全連接層;接著,添加1 個比率設置為0.2 的Dropout 層;最后,再添加1 個輸出維度為140 的softmax 分類器。該模型使用交叉熵損失函數作為其損失函數,選用Adam 優化器進行梯度優化,batch_size 為128,epoches 為35。得到6 部分數據集的預測準確率依次為97.72%、94.98%、96.96%、91.31%、94.06%和94.75%。
將各測試集輸入到訓練好的網絡模型中,得到預測的當前狀態值及當下特征點。以第二部分數據為例,其預測狀態值和實際狀態值如圖8所示。
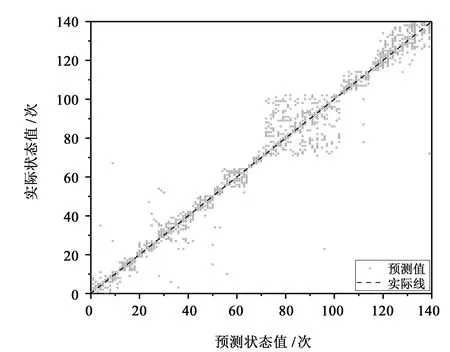
圖8 狀態值預測圖Fig.8 State value prediction diagram
對預測狀態值進行了6 種方法的擬合,即:線性擬合、2 階、5 階、9 階多項式擬合、以Boltzmann為模型和以Allometric1 為模型的非線性曲線擬合。表3 所示為擬合曲線參數表。線性擬合和以Allometric1 為模型的非線性曲線擬合的相關系數R2均為0.979 16;當階數為9 時,多項式擬合的相關系數最大,為0.981 10,比線性擬合的相關系數高0.001 94。
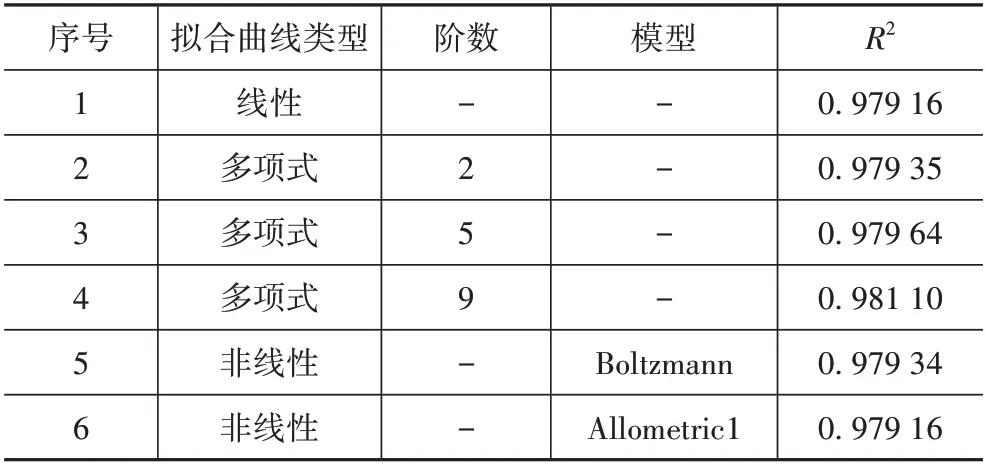
表3 擬合曲線參數表Tab.3 Fitting curve parameter table
綜合看來,這6 種擬合方法的相關系數差別不大。與其他5種相比較,線性擬合函數簡單,表示能力強。本文中選擇線性擬合作為擬合方法。
第二部分的線性擬合圖如圖9所示。
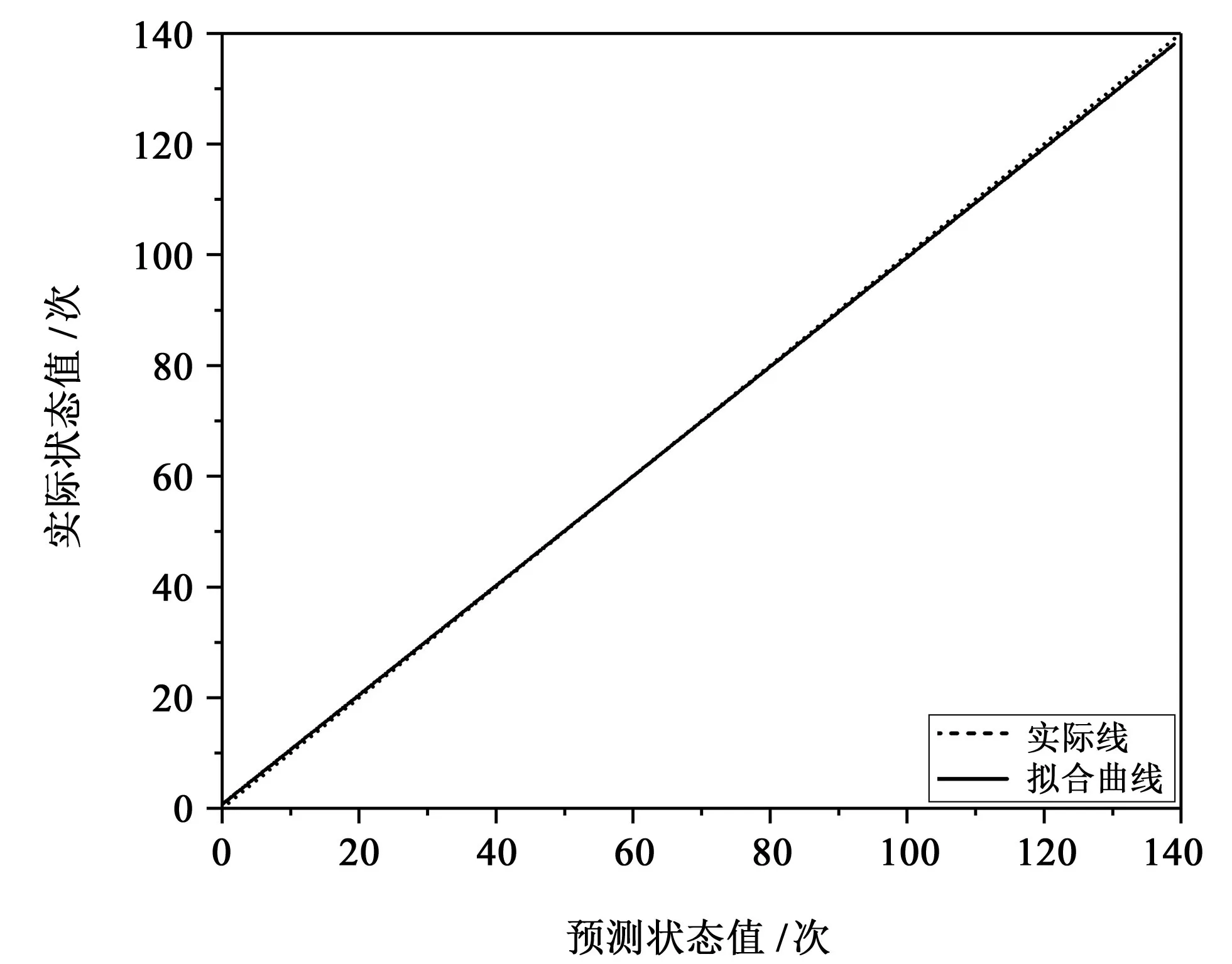
圖9 線性擬合圖Fig.9 Linear fitting diagram
表4所示為各部分預測結果的線性擬合參數。其中,a為斜率;b為截距;R2為相關系數。各參數取小數點后3位。
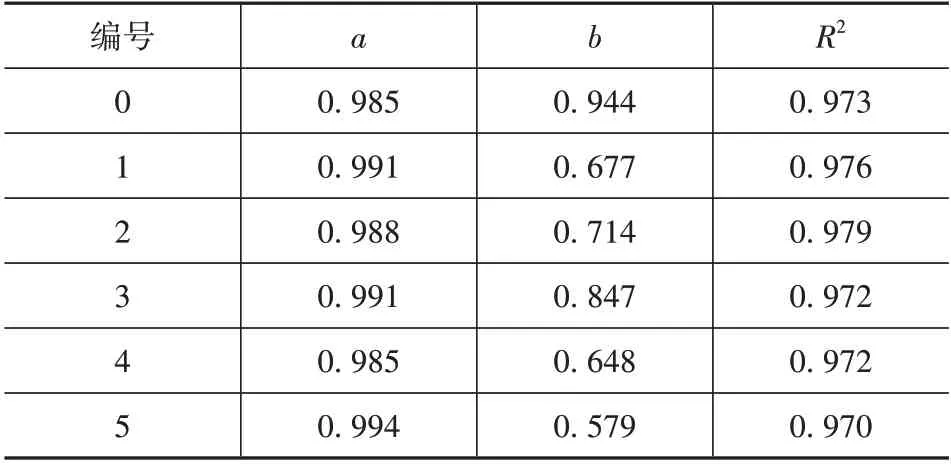
表4 線性擬合參數表Tab.4 Linear fitting parameter table
本文中試驗軸承2 的采樣數據共5 880 個,每個特征點表示的壽命是5 min。通過式(6)可計算出當前特征點的剩余使用壽命;之后,利用式(7)預測壽命百分比誤差Ec,評估模型性能的優劣,有
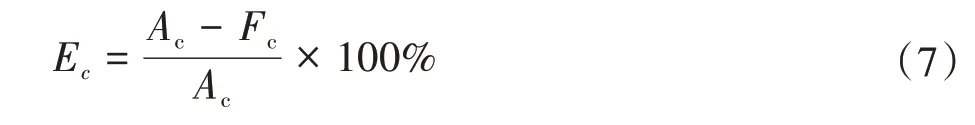
式中,Ac、Fc分別為當前特征點的實際剩余使用壽命和預測剩余壽命。
Ec>0 表明RUL 預測結果偏小;Ec<0 表明RUL 預測結果偏大;Ec=0表明RUL預測誤差為0。將采集的5 880 個數據點代表的壽命作為實際壽命,得到6 部分數據集的預測壽命百分比平均誤差分別為3.48%、9.59%、7.20%、8.09%、16.77%、7.42%。
表5 所示為部分RUL 預測結果。在各6 部分中隨機選擇5 個預測點,其中,Fc1是用預測的當前狀態值得到的剩余使用壽命;Fc2是預測的狀態值經過線性擬合后得到的剩余使用壽命。0-1 測試點處于第22 個循環的第1 個特征點,其當前特征值為22×42+1=925,實際RUL 為(5 880-925)×5=24 775 min,其特征點不發生改變,預測狀態值為23,得到Fc1為[5 880-(23×42+1)]×5=24 565 min,其預測誤差為(24 775-24 565)/24 775=0.85%,預測狀態值經過線性擬合后為23,得到的Fc2為24 565 min,Ec2為0.85%。由表5中可以看出,直接使用預測狀態值得到的預測結果較好。
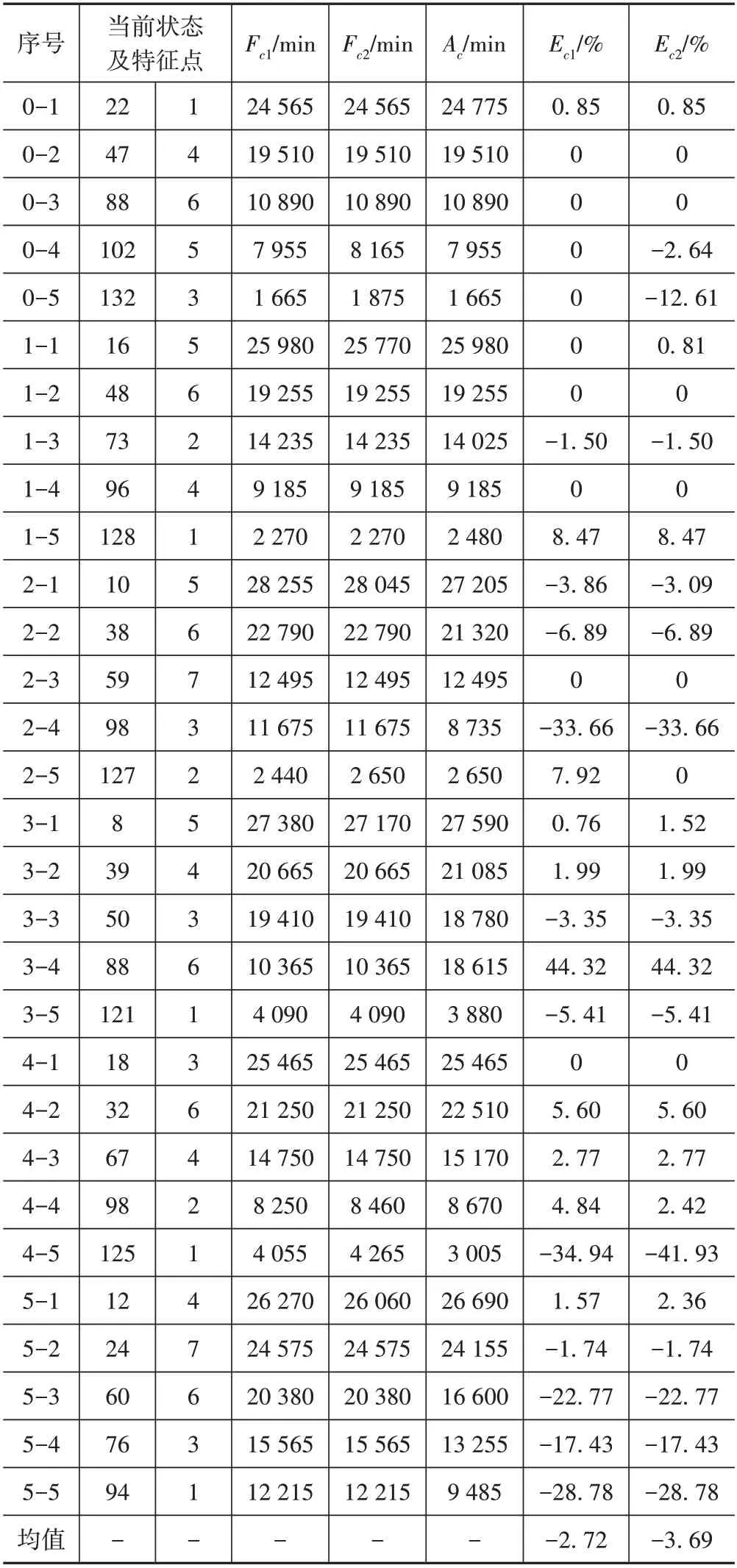
表5 部分RUL預測結果Tab.5 Partial RUL prediction results
4 結論
(1)建立了CNN-LSTM 網絡模型,對振動信號的深層特征進行了挖掘。試驗結果表明,本文中所提方法能夠很好反映軸承運行中的性能退化趨勢,預測值較接近真實值。
(2)對試驗軸承進行了工況下里程數為2.7×105km 的試驗。在后續的研究中可以對其進行更多里程數的試驗。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
