基于深度學習的交通路口自動識別
2022-10-24 04:59:38胡蓉韓宇徐永許偉輝李誠
福州大學學報(自然科學版) 2022年5期
胡蓉,韓宇,徐永,許偉輝,李誠
(福建工程學院,福建省大數據挖掘與應用重點實驗室,福建 福州 350118)
0 引言
隨著互聯網和智能手機的快速發展,基于位置的服務(location-based services,LBS)已經成為人們日常生活中重要組成部分(如導航、 點外賣、 線上生活超市等),從而對電子路網地圖的實時更新產生了更高的需求.因此全自動道路檢測技術成為研究熱點,許多學者提出了基于遠程遙感圖像的方法[1-2],以及光探測和測距點(激光雷達)云數據[3]來提取路網信息.這兩種方式數據獲取成本高且提取的信息往往滯后于實際路網的改變[4].近年來,大多數車輛運營車輛(出租車、 公共汽車、 貨車)都裝有全球定位系統(GPS),這些設備能收集大量的位置信息,記錄了包括車輛經緯度、 速度、 時間戳、 航向角等信息,這些軌跡信息相互聯系代表了一定的交通模式,因此通過挖掘和分析車輛軌跡數據來更新數字地圖就成為一種新型低成本而實時有效的方式[5].交叉路口是路網的重要部分,能夠提供非常有用的信息,比如連通性、 拓撲,以及允許移動的方向.為了從大規模的網絡中自動產生完整的交通路口地理數據,許多研究者對此展開了研究,以實現讓車輛安全通過路口的目的[6-8].
目前已有的路口識別方法主要分為3種基本的類型: 一類是基于空間幾何特征和聚類的方法,如Wu等[9]通過聚類方法尋找停止點和轉彎點來識別路口; 一類是利用軌跡數據在路口呈現的空間幾何特征提取路口,如Xie等[10]通過在每一對軌跡中尋找共同子軌跡,并將其起始點作為采集的連接點,最后對連接點采用核密度估計方法檢測路口; 第三類是學習方法,如利用決策樹方法構建軌跡片段分類模型及軌跡線剖分模型建立交叉口區域變道軌跡片段提取方法,然后對這些片段進行聚類提取中心線獲取道路交叉口結構[11],以及通過深度學習產生地圖[12-13].
在軌跡數據來源上, 有研究者通過分析眾源GPS車輛軌跡數據來獲取道路地圖及交通路口信息,如Wang等[14]通過分析航向差從高采樣頻率GPS軌跡中提取轉彎曲線,將交叉路口建模成圓形區域,最后通過聚類的方法獲取路口的位置信息.Keler等[15]基于分析出租車軌跡數據,為每個實體創建單獨的軌跡作為多線段表示,然后從所有軌跡多線段中提取交叉點.為了提高交叉口的幾何識別精度,Li等[16]采用融合相似方向并保持沖突方向的獨立性方法,通過調整主要方向來提取路口從而減少位置偏移和道路變形帶來的識別誤差.為了識別路口的詳細結構,最近Chen等[17]提出擴展分類利用幾何特征道路交叉口,并獲得了較好的召回率和整體性能.Wang等[18]通過分析車輛運動方向熵來有效識別路口,采用統計模型評估上游車輛的停車位置并進而估計停車流的數量、 坐標和方向.
為避免受人工設置閾值的影響,本研究提出一種基于長短期記憶(long short time memory,LSTM)深度學習的方法對車輛在路口的轉彎軌跡模式進行建模學習,從而自動尋找路口轉彎軌跡點; 然后,針對路口轉彎軌跡點的稀疏性缺陷,提出一種基于計算補償點和轉彎角度變化幅度聯合確定路口候選點的方法,并通過基于密度聚類(density based spatial clustering of applications with noises,DBSCAN)方式對路口候選點自動提取路口中心位置.采用福州市鼓樓區出租車實際軌跡數據驗證該方法.實驗結果表明, 該方法能快速自動識別轉彎軌跡和交通路口,有助于該領域自動識別系統的研發.
1 研究方法
基于LSTM在處理時間序列數據方面的優勢,對具有時序特性的軌跡數據建模.首先,對浮動車軌跡段打上直行、 左轉、 右轉、 掉頭和小轉彎5類標簽,提取經度、 緯度和航向角作為輸入特征,然后通過建立LSTM模型識別軌跡類別; 其次,針對低頻軌跡導致路口轉彎點比較少這個缺陷,提出一種基于補償點計算和轉彎角度變化聯合確定路口中心候選點的方法; 最后,通過DBSCAN聚類自動識別出路口中心.
1.1 一種基于LSTM的浮動車轉彎軌跡自動提取方法
該方法分為兩個步驟.首先是構建軌跡特征向量,作為LSTM模型的輸入; 然后是基于LSTM轉彎軌跡的自動提取.
1.1.1 時空特征的軌跡段特征向量矩陣構建
軌跡數據是記錄車輛或行人的行駛軌跡序列,具有時間連續性及空間幾何特性,在行至路口時因航向改變而具有幾何特點.假設軌跡數據平均回傳率為1/20 Hz(每20 s傳回一次),空間上考慮每個樣本點間距為50 m,根據路口轉彎特點,考慮4個軌跡樣本點可描述路口轉彎特性,有如下定義.
定義1: 一個軌跡樣本點為xi(loni, lati,φi),其中lan, lat,φ分別是車輛行駛時實時傳回的經度、 緯度、 航向角.
定義2: 每天傳回軌跡數據的車輛集合為{id(i),i=1, 2, …,N}.
定義3: 所有車輛一天的行駛軌跡點的集合為T={T(id(i))},i∈1, 2, 3, …,N
定義4: 每臺車一天采集到的軌跡點的數量為n.
定義5: 將每輛車(id(i))的行駛軌跡集合定義為{Tr(id(i))=(x1,x2, …,xn)}.
定義6: 軌跡點按照時間順序每4個點構成一個子軌跡
定義7: 軌跡特征向量為一個4行3列矩陣,選取每個樣本點的3個特征,其中loni、 lati和φi分別為第i個軌跡點的經度、 緯度和航向角,形成一個子軌跡Tri矩陣列,每一個輸入矩陣都對應于一種軌跡類型: 直行、 左轉彎、 右轉彎、 掉頭或小轉彎,通過人工為每個子軌跡打上對應的標簽構成后續LSTM模型的訓練樣本數據集,如圖1所示.式(1)所示是一個獨立樣本的示例.

(1)
1.1.2 基于長短期記憶網絡(LSTM)深度學習自動提取路口轉彎軌跡點
深度學習領域中,循環神經網絡(recurrent neural network, RNN)被廣泛用來分析時間序列數據的結構,其中LSTM是一種可以通過門控機制控制輸入、 輸出和神經元記憶間的信息流,主要應用在語音識別、 圖像說明、 語言翻譯等,近來也被用來分析軌跡數據[19].
LSTM是一種循環神經網絡,與傳統的前饋神經網絡不同,它具有反饋機制,不僅可以用來處理單個的數據,也可以用來學習時間序列的數據.其特點是重復利用之前的隱藏層輸出,使得神經網絡可以重復學習前面學到的東西,并結合上下文的內容進行學習分析,從而對序列數據的處理有獨特的優勢.
通過LTSM模塊的特征提取學習,輸入子軌跡Tri=X, 如式(1)所示作為輸入向量,輸出為預測的軌跡類別.模型包含輸入、 4個隱藏層(每層神經元1 024個,激活函數sigmoid)、 一個dropout 層(隨機丟棄率設置為0.1、 全連接層,最后輸出預測結果,優化方法選擇Adam, 學習率設置0.001, 損失函數采用交叉熵,如下式所示.
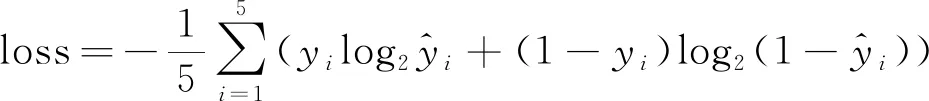
(2)
1.2 一種補償點計算和臨近入口點計算的路口候選點選取方法
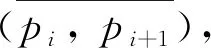
其中: (xi,yi)(i=1, 2, 3, 4)是轉彎軌跡點pi的經緯度.
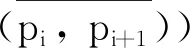
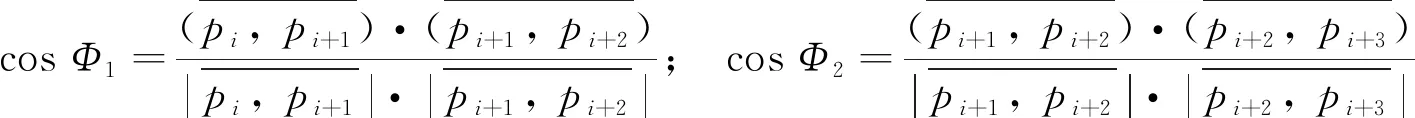
(4)
由圖3可知,如果Φ1角度大于Φ2,則pi+1離路口點更近,可作為路口中心候選點; 反之, 則pi+2離路口點更近而作為路口中心候選點.
為了確定補償點和候選點的距離是否超過路口的范圍,要根據路口覆蓋范圍確定一個距離閾值.如圖4所示,一個大型路口的覆蓋半徑一般為60 m左右,因此當補償點與最近路口點的距離超過了覆蓋范圍的直徑120 m即可判定補償點已經偏離路口,此時將以靠近路口點作為路口中心的候選點.
1.3 基于DBSCAN的路口識別
如節1.1和1.2方法獲得路口候選點后,采用DBSCAN對候選點進行聚類,類族族心就是路口位置.該算法能找到多維數據的內在特征關系,在聚類數目未知的情況下,可以發現任意形狀,任意大小的噪聲數據集的簇,并且支持空間數據.該算法需要用戶根據實際情況和經驗確定簇內最小數目MinPts及簇間最小距離ε,這兩個參數的選擇是影響結果的重要因素-輪廓系數來評價的.
通過實驗選取18<ε<30,MinPts取5~15,計算出當各個組合的輪廓系數最大,S(i)=0.760 593、 簇間最小距離ε=25 m、 簇內最小數目MinPts=10、 噪聲比為3.27%時,該聚類的結果是最合理,將采用DBSCAN對前面獲得的路口候選點進行聚類,聚類后的每個族代表一個路口,從而識別出路口的大致位置.
2 實驗結果與分析
采用福建省營運車軌跡數據,該數據是福建省交通廳對福州市內約15萬部營運車輛(主要是出租車)在道路運營行駛中進行實時采集而獲得,提取并預處理2018年5月3—5日的福州市鼓樓區的浮動車軌跡數據,得到12.5萬條軌跡數據,將5月4—5日的數據打上標簽作為訓練數據訓練模型.為了驗證模型的有效性,用5月3日的數據(模型沒用過的數據)作為輸入數據測試模型,輸出y為每一種軌跡類別的概率,選取概率最大的值作為軌跡類別的標簽.通過所得到的輸出,提取出左轉與右轉的軌跡數據,并基于計算補償點和臨近路口點方法選取路口候選點,最后通過DBSCAN聚類識別路口中心.首先,將2018年5月4—5日的軌跡數據分為3部分,70%為訓練數據構建模型,20%作為驗證數據用于檢驗和評估模型的準確率.為了輔助模型的構建,剩下的10%用來做交叉驗證數據.
2.1 數據描述
所選的福州市鼓樓區為福州市的經濟、 政治和文化交流中心,具有代表性,所用的出租車軌跡數據的經緯度范圍為: (119.286 7°, 26.065 6°)~(119.352 21°, 26.108 13°).該數據的平均采樣頻率為1/20 Hz,主要采樣屬性包括: 車輛ID、 經度、 緯度、 時間戳、 速度和航向角.
2.2 基于LSTM轉彎軌跡識別結果的分析
通過使用LSTM模型進行軌跡類別的識別,訓練初期,模型的訓練與測試的準確率提升較快速.
為了驗證模型的準確性,用2018年5月3日福州市鼓樓區內浮動車軌跡數據(模型未接觸過的數據)作為模型路口識別效果的測試數據.該數據作為訓練好的模型的輸入數據以自動獲取轉彎軌跡,分類結果如表1所示.

表1 測試分類結果
2.3 補償點與候選點相結合的路口中心提取結果與比較
如前所述有的路口點通過補償點計算存在軌跡點偏移情況,導致后續識別出的交叉口偏移正確位置.為此,在轉彎軌跡中計算靠近路口的中心點,然后結合二者確定路口候選點,以彌補補償點計算的不足,圖5給出轉彎補償點糾正前后的對比,可以看出路口候選點比較集中,較好地糾正補償點的不足.
2.4 路口的識別結果分析與討論
通過計算補償點和臨近點相結合的方法確定了候選路口點之后,采用DBSCAN聚類算法對路口候選點進行聚類,從而最終識別出路口中心.通過試錯找出輪廓系數選取簇間最小距離ε=25 m,簇內最小數目MinPts=10,對這些簇內的路口點求經緯度均值后,得到路口中心位置,如圖6所示,紅色的點為算法識別出的路口中心.從圖中可以看出,紅色點基本都是在路口中心處.
為量化評估所提出的路口識別方法的效果,通過計算查準率、 查全率和F-score等來實現.查準率表示正確識別的路口在算法所識別的路口中所占的比例; 查全率表示正確識別的路口在真實的路口中所占的比例; F-score綜合考慮兩者的影響.通過對比百度地圖進行人工核查,評估結果如表2所示.
表2中,TP指實際地圖上有路口被正確識別為路口,FP指實際地圖上有路口沒有被識別為路口,TN指地圖上沒有路口識別為非路口(本實驗只識別路口,非路口就是道路,不做識別),FN指地圖上實際沒有路口被錯誤識別為路口.在該數據覆蓋范圍內百度地圖上顯示一共有238個路口,通過方法識別路口214個,TP=207,FP=7,FN=24.查準率=0.967,查全率=0.896,F1-score=0.93,準確率=0.87%.

表2 路口識別率評估
路口識別錯誤的原因主要有3種: 一是兩個路口太靠近,導致算法得到的路口點很接近,識別成一個偏移實際位置的路口; 第二種情況是小區或者景區的入口,由于確實會有車輛在該處轉彎,導致誤判為路口; 第三種路口漏識別的主要原因是有的路口的交通流量特別大,導致轉彎軌跡及轉彎候選點較多,附近的小路口交通流量少且距離大路口過近,容易當成噪聲點.
傳統方法中通過軌跡數據中的航向角變化計算獲取轉彎軌跡點,然后采用聚類方法對轉彎軌跡點直接聚類提取路口信息(如Wu等[9]稱之為CHD(change of head direction).本研究提出的方法采用LSTM學習軌跡模式自動提取轉彎軌跡點,然后通過結合補償點計算和臨近路口點計算聯合確定路口候選點,最后通過聚類候選點獲取路口位置信息,稱之為LSTM+CCI (LSTM+compensation and closest to intersection).兩種方法的識別率比較如表3.從表中可以看出,本研究提出的方法明顯優于通過僅航向角來識別路口的方法,無論是識別率還是查全率、 查準率都高于CHD方法.

表3 不同算法下路口識別結果比較
綜上,提出了基于LSTM深度學習對浮動車軌跡模式建模,通過采用福州市出租車一天的軌跡數據驗證該方法可以快速(1 min之內,環境: Intel CoreTMi5-5200U CPU@ 2.20 GHz)自動從軌跡中識別出轉彎軌跡點.提出一種補償點計算和臨近路口點相結合的路口候選點確定方法; 通過補償點和臨近點計算兩種情況對比, 可以看出該方法能有效地解決因采樣或GPS質量影響帶來的路口識別困難; 最后通過DBSCAN聚類方法識別路口.通過對比百度地圖與識別結果進行人工核查,該方法能準確有效快速(僅一天的軌跡數據)識別道路交叉口,為快速持續更新電子地圖和基于位置的服務應用提供關鍵技術支持.
3 結語
電子地圖信息是地理位置信息的關鍵組成部分,是城市規劃、 智能交通、 位置服務等應用中的關鍵技術之一.GPS軌跡數據為產生電子地圖提供一種快速的方法,交通路口是電子地圖的重要組成部分,在已有的研究中還存在因軌跡數據采樣頻率和GPS信號質量等因素影響的挑戰.
本研究創新性地提出采用LSTM深度學習方法對車輛軌跡模式進行建模學習,不僅可實現對路口轉彎軌跡的自動提取,而且還能自動過濾掉不屬于路口的轉彎模式(如駛入停車場、 小區、 加油站等).提出一種補償點計算和臨近路口點計算的路口候選點選取方法,能有效解決受GPS軌跡采樣頻率和信號等影響帶來的識別精度不高的問題.通過采用福州市真實的軌跡數據驗證了本方法可以快速實時(一天的軌跡數據僅一分鐘內)地檢測出交通路口變化,為電子地圖的實時更新和自動駕駛導航等應用需求提供技術支持.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
