FPGA在人工智能深度學習中的應(yīng)用
2022-10-26 08:52:52武漢工程大學郵電與信息工程學院周瑩
數(shù)字技術(shù)與應(yīng)用 2022年10期
關(guān)鍵詞:模型
武漢工程大學郵電與信息工程學院 周瑩
近年來,F(xiàn)PGA應(yīng)用的呼聲之高,發(fā)展之快令人振奮,從AI到VR,從語音識別,人臉識別到各種各樣的加速器。在人工智能興起和發(fā)展的時代,深度學習起到了中流砥柱的作用,然而深度學習仍然面臨著超大計算量的問題,GPU、ASIC、FPGA都是解決龐大計算量的有效方案。本文將以Lenet卷積神經(jīng)網(wǎng)絡(luò)模型為例,基于CNN網(wǎng)絡(luò)模型和硬件架構(gòu)實現(xiàn),對CNN網(wǎng)絡(luò)的后向訓(xùn)練過程進行Matlab定點仿真和FPGA實現(xiàn)以及Modelsim仿真驗證,最終綜合對比FPGA、GPU、CPU的性能。
人工智能是研究用于模擬和擴展人類行為的一門新型技術(shù)學科。對于人工智能,特別是基于深度學習的應(yīng)用來說,很多應(yīng)用場所都對實時性有著很高的要求[1]。面對這個新時代提出的新要求,F(xiàn)PGA利用其特點,發(fā)揮著它重要的作用[2]。下文以CNN網(wǎng)絡(luò)的后向訓(xùn)練過程為例說明FPGA的性能優(yōu)勢。
DNN(深層神經(jīng)網(wǎng)絡(luò))包含兩類核心算法:CNN(卷積神經(jīng)網(wǎng)絡(luò))和LSTM(長短期記憶網(wǎng)絡(luò)),都能在很大程度上受益于低精度的乘加運算[3]。CNN算法目前是最重要的深度學習方法之一,這種算法在圖像識別以及語音識別應(yīng)用中取得了突破性的成就,下面就以CNN算法的后向訓(xùn)練過程模型架構(gòu)及結(jié)果仿真為例,說明FPGA在深度學習算法加速上的優(yōu)勢。
1 CNN的網(wǎng)絡(luò)模型
下面以一種具體的Lenet卷積神經(jīng)網(wǎng)絡(luò)模型為例,給該CNN一個輸入,輸入名為MINST的一個數(shù)據(jù)集,也就是一張灰度圖像,其像素是(1,28,28),如圖1所示。
其conv1作為第一個卷積層,卷積核的大小是(4,1,5,5),其中的4代表有4個(1,5,5)的卷積;利用非全零的方法進行填充,步長取1,Relu作為其激活函數(shù),再依據(jù)(式1)和(式2)可得,輸出(4,24,24);第1個池化層是Pooling1,經(jīng)過這個池化層之后,再采用最大池化策略的方式,利用非全零的方法進行填充,步長取2,這時的輸出是(4,12,12);conv2作為第二個卷積層,它的conv2卷積核大小是(4,4,5,5,),其中的4是指有4個(4,5,5)卷積,利用非全零填充的方法進行填充,步長取1,Relu作為其激活函數(shù),根據(jù)(式1)和(式2)可得,經(jīng)過卷積后的輸出是(4,8,8);接著進入到第二個池化層pooling2,采用Max Pooling的方式且池化值為(2,2),最終的輸出為(4,4,4);經(jīng)過2層全連接層FC1和FC2,F(xiàn)C1的大小是(12,64),激活函數(shù)是Relu,F(xiàn)C2的大小是(10,12),激活函數(shù)是Softmax。
通過該模型的訓(xùn)練之后,可以得到如圖2所示的系統(tǒng)損失函數(shù)的變化曲線,隨著迭代次數(shù)的疊加,損失函數(shù)將會逐漸變小,在開始的四千次迭代中損失函數(shù)的變化是迅速變小,而之后的四千到八千次時,曲線已經(jīng)變得非常緩慢,直到最后趨于平穩(wěn)。
可以通過曲線圖發(fā)現(xiàn):隨著迭代次數(shù)的增加,損失函數(shù)逐漸減小,最終會趨向一個穩(wěn)定值;而準確率的曲線圖是會不斷增大,最終也趨向于一個穩(wěn)定值,準確率曲線圖此處略[4]。總之,這種模型的損失函數(shù)變化曲線和準確率變化曲線都符合要求,性能良好。下文以該模型為例,介紹硬件加速的實現(xiàn)。
2 CNN的硬件結(jié)構(gòu)
對于CNN的后向訓(xùn)練過程,包含全連接層、池化層傳遞過程以及卷積層誤差;同時也包括了權(quán)值的更新。CNN硬件框架是以后向訓(xùn)練過程的誤差傳遞過程為主,前向預(yù)測過程的輸出結(jié)果長度為10,作為結(jié)構(gòu)的輸入,通過和Label(正確標簽)相減取得差值之后,便得到了全連接層FullConnected2的誤差項,再經(jīng)過全連接層隱層的誤差傳遞,會得到全連接層FullConnected1的誤差項,最終得到有效長度是8的4路卷積層,最后經(jīng)過池化層的誤差項傳遞和卷積層誤差項傳遞,就會得到有效長度為24的4路卷積層[5]。參數(shù)更新模塊被進入的誤差項進行更新之后,權(quán)值和偏置項也會被更新。下面介紹利用FPGA實現(xiàn)全連接層后向過程的仿真驗證。
3 FPGA實現(xiàn)全連接層后向過程仿真驗證
3.1 Matlab定點仿真
(1)根據(jù)卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的算法理論,對上述Lenet卷積神經(jīng)網(wǎng)絡(luò)的后向訓(xùn)練過程進行Matlab的定點仿真。在Matlab中進行仿真,首先將數(shù)據(jù)集中的“mnist.train.images.txt”文件輸入,把“mnist.train.labels.txt”當做正確標志。均值設(shè)為0.1,初始化權(quán)值使用0,初始化方式采用標準差。
(2)向訓(xùn)練過程的定點方式采用1位符號位、5位整數(shù)位、12位小數(shù)位,即FI(1,18,12),采用這種方式后的輸出數(shù)據(jù)是卷積層為1的偏置b_conv1和權(quán)值w_conv1,卷積層為2的偏置b_conv2和權(quán)值w_conv2,全連接層為1的偏置b_full_connected1和權(quán)值w_full_connected1,全連接層為2的偏置b_full_connected2和權(quán)值w_full_connected2[6]。如圖3所示,訓(xùn)練的迭代次數(shù)是橫坐標,數(shù)據(jù)的最大相對誤差值是縱坐標,經(jīng)過分析訓(xùn)練過程中的相對誤差絕對值,可以得到相對誤差的最大值是10∧-2,顯然這個誤差結(jié)果是在期望值中的。
3.2 FPGA實現(xiàn)和結(jié)果驗證
Lenet卷積神經(jīng)網(wǎng)絡(luò)中全連接層隱層的誤差傳遞過程的Modelsim仿真結(jié)果如圖4所示,模塊是以10個連續(xù)誤差數(shù)據(jù)作為輸入,輸出是12路并行誤差數(shù)據(jù),該數(shù)據(jù)是由有效控制模塊和12個乘累加器得到的,利用Matlab仿真的結(jié)果與這個結(jié)果一樣,意味著模塊正確。
其中,全連接層隱層誤差傳遞模塊的端口信號定義如表1所示。
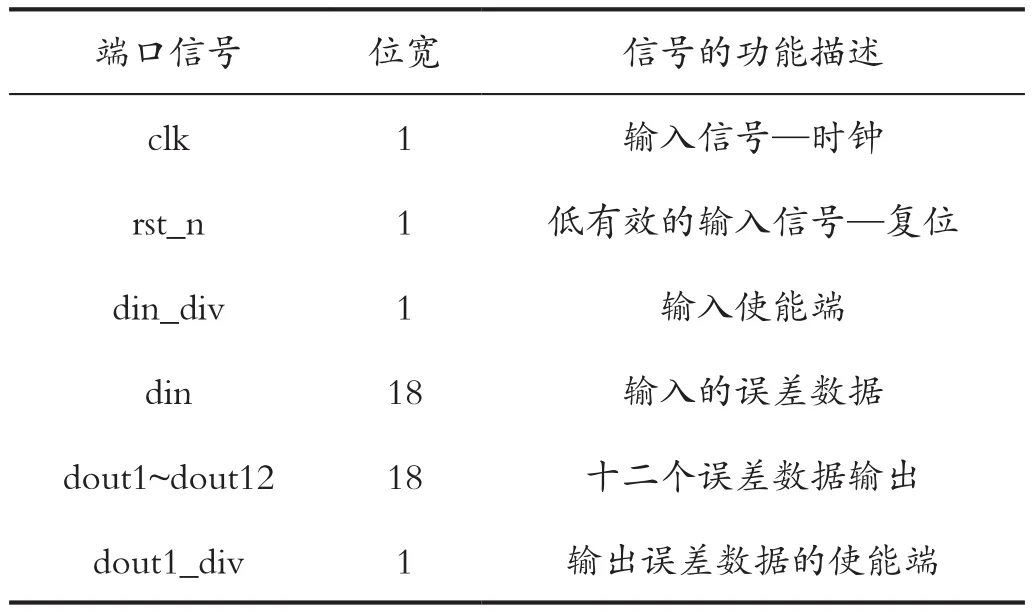
表1 模塊的端口信號說明-誤差傳遞Tab.1 Module's port signal description - error propagation
Lenet卷積神經(jīng)網(wǎng)絡(luò)中全連接層隱層的權(quán)值更新過程由第三方仿真工具Modelsim得出的時序結(jié)果如圖5所示,該模塊的輸入是單個的誤差數(shù)據(jù),輸出是64位的1路數(shù)據(jù),即64個權(quán)值。一個誤差更新64個權(quán)值,因此12個誤差更新了所有的768個權(quán)值[7]。Matlab仿真結(jié)果和FPGA經(jīng)過第三方仿真工具Modelsim的結(jié)果一樣,意味著模塊功能正確。
其中,全連接層隱層權(quán)值更新過程的端口信號定義如表2所示。
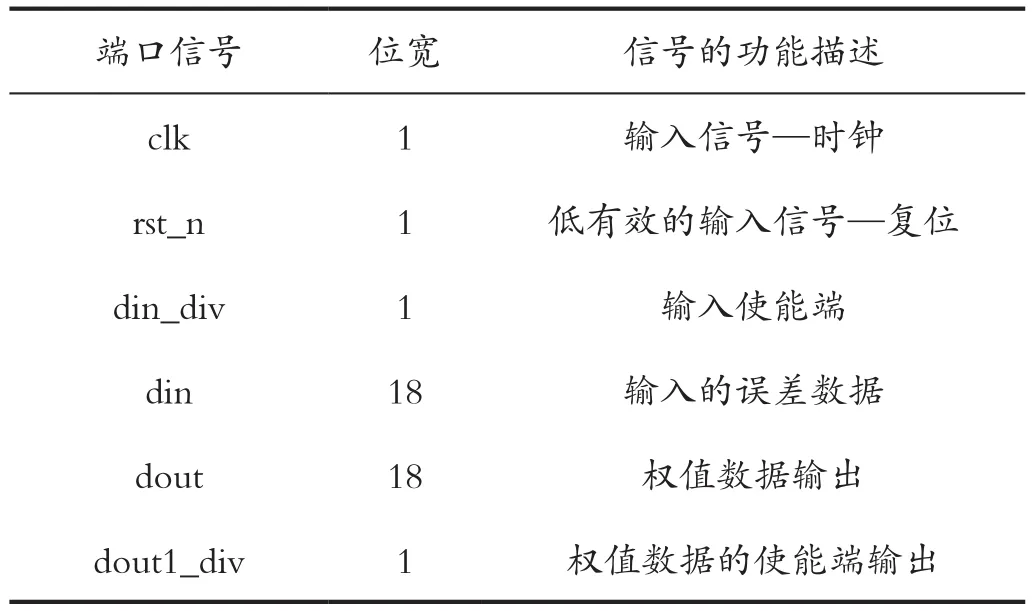
表2 端口信號說明-權(quán)值更新Tab.2 Port signal description - weight update
實現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)后向訓(xùn)練過程之后,經(jīng)過Modelsim仿真的波形圖如圖6所示。由時序圖可得,在FPGA中只要實現(xiàn)了一次后向訓(xùn)練,就需要821個時鐘信號,由于最大CLK頻率設(shè)定為200MHz,即5NS[8]。
通過分析后向訓(xùn)練在FPGA、GPU、CPU的性能,如表3所示。FPGA實現(xiàn)的后向訓(xùn)練過程對比CPU來說,處理速度提高了1.8倍,由于該結(jié)果受到訓(xùn)練過程中一系列外在因素的影響,例如權(quán)重相對正向過程需要轉(zhuǎn)置,就會浪費一定的處理時間[9]。雖然FPGA相對于GPU,處理速度稍有差距。但是FPGA功耗比GPU和CPU要小很多。

表3 后向訓(xùn)練過程FPGA、GPU、CPU性能對比Tab.3 Backward training process FPGA, GPU, CPU performance comparison
4 結(jié)語
目前深度學習的流行,其實仍然是得益于大數(shù)據(jù)和計算性能的提升。但是卻也遭受著計算能力和數(shù)據(jù)量限制的瓶頸。針對數(shù)據(jù)量的需求,還能夠利用調(diào)整或者變更模型來緩解,但面對計算力的挑戰(zhàn),卻沒有捷徑。FPGA解決了傳統(tǒng)PLD資源有限的劣勢,又克服了全定制的電路較死板的缺點[10]。隨著FPGA器件和云端部署等技術(shù)的發(fā)展,內(nèi)存帶寬已經(jīng)逐漸不再是DNN的算力瓶頸,取而代之的是單周期可以完成的乘加操作數(shù)量,這些都使得FPGA在未來的AI領(lǐng)域中,能夠發(fā)揮它最大的優(yōu)勢,推動科技的進步。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
