基于目標函數優化的無向加權圖粗糙模糊聚類算法
2022-10-26 13:45:34何文倩劉士虎楊昔陽
云南民族大學學報(自然科學版) 2022年5期
何文倩, 劉士虎,宋 敏, 楊昔陽
(1.云南民族大學 數學與計算機科學學院,云南 昆明 650504;2.泉州師范學院 數學與計算機科學學院,福建 泉州 362000)
隨著數據庫技術的快速發展和數據庫管理系統的廣泛應用,積累數據和掌控技術的用戶越來越多[1].數據爆炸的背后隱藏著重要信息,人們希望通過更高層次的分析來更好地利用數據[2].圖是一種重要的數據結構,可用于描述復雜網絡的拓撲結構,如社交網絡[2]、疫情傳播網絡[3],傳感器網絡和蛋白質網絡[4]等.圖數據聚類可以幫助檢測出含有重要信息的類結構,此外,還可以幫助研究者更好地理解圖數據的特征和功能[5].
圖數據聚類是根據圖的拓撲信息和屬性信息將一個大圖劃分為若干個子圖的過程,使得同子圖內的頂點連接緊密而不同子圖內的頂點連接稀疏,并且相似頂點應劃分到相同子圖內,不相似頂點應劃分到不同子圖內[4-5].研究者已經提出許多相關算法,并成功地應用于各種圖數據中.比如,基于結構相似性的圖數據聚類算法利用結構相似性來發現圖數據中無重疊的子圖類[5].Walktrap算法利用隨機游走技術檢測復雜圖數據中的類[6].此外一些算法還使用歸一化割方法、最小割方法和最大流最小割方法來進行圖數據聚類反演.這些算法均基于邊連接權值對圖數據進行聚類,但它們需要從所有頂點中選擇權值最小的邊,這是一個較難的問題.還存在一些算法,要么需要預先輸入少量信息,要么只考慮圖數據的拓撲信息和屬性信息中的一個.針對這些問題,Tian等[7]提出了一種基于屬性信息的關系對圖數據進行聚類的算法,它將同一維度的屬性分組到同一個類中.不幸的是,該算法忽略了聚類內的拓撲結構.Zhou等[8]提出了一種圖數據中統一的距離度量方法,該方法通過在原始圖中添加帶屬性的頂點來生成屬性增廣圖,然后使用隨機游走方法計算頂點之間的距離.該算法得到的屬性增廣圖中頂點數大于原始圖中的頂點數,但是算法運行時間不盡人意[9],并且當屬性較多時,算法的時間復雜度會很高[10].Javed等[11]提出了一種綜合考慮拓撲和屬性的圖數據聚類算法,這種算法被廣泛應用并且是一種基于描述驅動思想的聚類方法,目標是簡單地聚類社交圖數據,其中每個頂點都用附加信息進行注釋.
目前,眾多模糊聚類算法也已被提出來處理圖數據聚類問題.模糊C均值聚類是最常用的模糊聚類技術[12],由于模糊C均值在某些方面的不足,許多改進算法也已經被提出.在文獻[13]中,Naderipour引入了一種基于鄰近性的兩階段圖數據模糊聚類方法.隨后,一種基于抑制性因子的模糊聚類算法[14]被提出,在保證聚類效果的前提下,利用抑制因子提高算法收斂速度.此外,為了處理模糊C均值聚類算法的噪聲和較低收斂速度問題,文獻[14]提出了一種基于粗糙集思想的改進聚類算法版本,由此可知粗糙集思想已經不斷被廣泛應用于圖數據的模糊聚類中[15].在目前的研究中,基于圖數據結構信息和屬性信息的相似性度量來聚類是一項基礎任務[16].圖數據的多樣性,如其形狀、大小、密度以及噪聲的存在,這些都使得對圖數據的聚類更加困難[17].因此,研究這樣1種全面的聚類方法具有重要意義.在面對任何圖數據時,如果直接對圖數據進行處理以確定聚類方向,則必須將圖數據中所有信息都考慮在內,以達到類內高相似性和類間低相似性的理想目標[18].
通過對以上問題進行分析,本文在前人研究基礎上,提出了一種基于目標函數優化的無向加權圖粗糙模糊聚類算法.論文基于頂點的綜合結構相似性和屬性相似性建立無向加權圖數據的聚類算法模型.引入粗糙集的上下近似集思想分別設計了類的上近似集和下近似集的模糊中心,并以此建立目標函數迭代優化機制,使得算法能夠處理一定的噪聲問題,拓寬算法的應用范圍,還可以通過選擇實驗有效性指標的最小值,確定聚類的最佳個數.
1 預備知識
為了行文簡潔及后文敘述的需要,這里簡單闡述與文中相關的一些基本概念,如無向加權圖數據、粗糙集和模糊C均值聚類算法.更詳細的描述參考文獻[9,12,15].
一般地,一個無向加權圖數據G可以表示為一個三元組G=(X,E,W),其中非空有限集合X={x1,x2,…,xn}表示所有頂點的集合.如果每個頂點被m個屬性所刻畫,那么對應地可表示為xi=(xi1,xi2,…,xim).從矩陣的角度而言,此時X可以采用如下表示
(1)
在無向加權圖數據中,E={(xi,xj)|xi,xj∈X}表示邊集合,其中(xi,xj)表示圖數據中任意2個頂點xi,xj之間的邊.W={wij|i,j=1,2,…,n}表示圖數據邊的權重集合,其中wij為任意兩個頂點xi,xj之間邊的權重,如果邊(xi,xj)?E,那么wij=0.
粗糙集作為一種處理不精確性和不確定性的軟計算工具,其數學描述可以用一對所謂的下近似集和上近似集來表示.給定一個知識庫K=(U,R),其中U表示論域,R表示U上的等價關系.對于任意有限集合X?U,{Xi|i=1,2,…,c}是由模糊聚類過程中產生的聚類結果構成的劃分,所有類中心的集合為{vi|i=1,2,…,c},且類中心vi與類Xi是一一對應的,則類Xi關于R的下近似集、上近似集和邊界域為
(2)
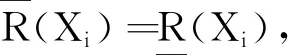
X的每個類Xi關于等價關系R的近似分類精度aR和粗糙度rR為
(3)
一個集合的不精確性是由其邊界域的存在而引起的,并且邊界域越大集合的精確性就越低.
進一步,類劃分{Xi|i=1,2,…,c}關于R的近似分類精度AR和質量QR為
(4)
近似分類精度描述的是當使用等價關系R聚類時,所有可能的類中被正確聚類的數據所占的百分比,即所有類的下近似集數據在上近似集中的百分比.分類質量表示的是應用R能被確切地分于{Xi|i=1,2,…,c}中類的數據在論域中所占百分比,即所有類的下近似集中數據占論域的百分比,由此分析確定在論文中將近似分類精度和分類質量分別作為下近似集和邊界域的計算權重.
模糊C均值聚類算法是數據分析的有用工具,該算法將聚類問題轉化成帶約束的目標函數最優化問題,因此可借助數學領域中的非線性規劃理論進行求解.此算法的目標函數為
(5)
其約束條件為
(6)
公式(5)所描述目標函數的優化過程具體是通過更新以下形式的uij和vi
(7)
(8)
其中uij表示xj關于第i個類的模糊隸屬度.m表示模糊因子,用于調整模糊隸屬矩陣的模糊程度.‖xj-vi‖2表示xj與第i個類中心vi之間的歐氏距離.
2 基于目標函數優化的粗糙模糊聚類算法
針對無向加權圖數據聚類問題,本文從拓撲信息和屬性信息角度出發,利用粗糙集思想構建了基于目標函數優化的模糊聚類算法.該算法從以下2個步驟對圖數據進行相似性度量和模糊聚類.首先基于共享鄰居的結構相似性和邊權重貢獻構造了無向加權圖數據中頂點的綜合結構相似性,通過論域上的等價關系R設計出頂點的屬性相似性度量方法.其次,通過引入粗糙集思想分別提出模糊類的上近似集和下近似集的類中心表示,并以此為基礎建立聚類算法的隸屬函數和目標函數優化機制.算法執行過程是基于目標函數優化機制對無向加權圖數據進行模糊聚類.
2.1 權重歸一化處理
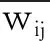
(9)
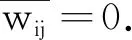
2.2 綜合結構相似性度量
在一個無向加權圖數據G=(X,E,W)中,將與頂點xi之間直接由邊連接的頂點稱為xi的一階鄰居,由所有一階鄰居組成的集合叫作xi的結構鄰域,并表示為N[xi],其集合表達形式為N[xi]={xj∈X|(xi,xj)∈E}.此外,頂點xi的度數記作d[xi]=|N[xi]|,即為一階鄰域中元素的個數.
對于無向加權圖數據G=(X,E,W)中任意2個頂點xi和xj,定義其結構相似性為2個頂點的結構鄰域N[xi]和N[xj]中共同頂點的數量與它們度數的幾何平均數的比值,即
(10)
對于任意2個頂點,如果其結構鄰域中的共同頂點越多,則它們之間的結構相似性就越大.以圖1中的頂點x1和x2為例不難發現,這2個頂點的共同鄰居為x3、x4、x5和x7,即共同鄰居的個數為4,由此可計算得2個頂點的度數分別為d[x1]=5,d[x2]=5,進而可根據公式(10)計算頂點x1和x2的結構相似性為S12=0.8.
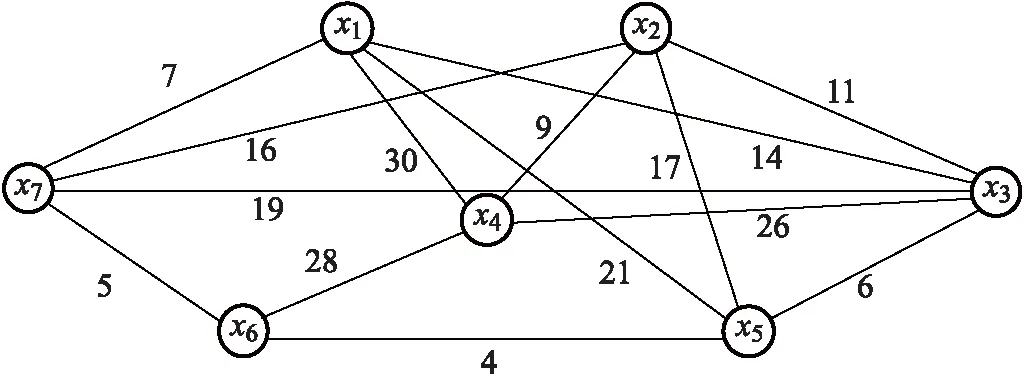
圖1 無向加權圖數據
一般地,對于大多數真實無向加權圖數據來說,除了具有重要價值的拓撲和屬性信息被考慮之外,各個邊上帶有的權重也不容忽略.權重是對任意2個頂點之間的關聯性重要程度的定量分配,對于圖數據的聚類仍然具有較大參考價值[19].基于以上對無向加權圖數據中頂點的結構相似性討論,為了發現潛在的具有高相似性的類,下面綜合考慮頂點的結構相似性和經過歸一化處理后的邊權重信息,統一計算兩者對無向加權圖數據聚類的貢獻.
給定G=(X,E,W),為了有效均衡頂點的結構相似性和邊權重的貢獻,引入一個均衡參數α∈(0,1),在實驗中取α=0.6.則任意2個頂點xi和xj之間基于結構相似性和邊權重的綜合結構相似性為
(11)
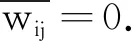
算法通過綜合考慮無向加權圖數據的拓撲結構和邊的權重,使類內頂點連接緊密的同時使具有較大權重的頂點被劃分到一類,而類間頂點之間連接稀疏.這樣,既保證具有較大權重邊連接的頂點不被分開,同時使類內頂點間連接緊密.
2.3 目標函數優化機制建立
在傳統的數據聚類中,頂點只能屬于某個特定的類.在模糊聚類中,頂點可以按照一定的隸屬程度屬于多個類.模糊聚類所獲得的聚類結果具有不確定性和模糊化,這種模糊程度由隸屬度函數來決定.
給定圖數據G=(X,E,W),其中頂點集為X={xj|j=1,2,…,n}.假設X中頂點被劃分到c個類,c個類中心為{vi|i=1,2,…,c},其類中心與類一一對應.則定義頂點xj關于第i個類的隸屬度函數uij為
(12)
基于模糊C均值聚類的類中心更新公式(8),對于任意X?U,{Xi|i=1,2,…,c}是模糊聚類結果構成的一個劃分,類中心集合為{vi|i=1,2,…,c},且每一個類中心vi對應一個類Xi.定義無向加權圖數據每個類的類中心計算方式為
(13)
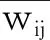
由于頂點隸屬度的存在導致每個類表示缺乏確定性,因此引入粗糙集思想使得類可用其一對下近似集和上近似集來表示,針對上近似集和下近似集自然會產生一個表示中心.接下來分別建立類的上下近似集的模糊中心表示.給定知識庫K=(U,R),對于任意X?U,對應為G=(X,E,W)中的頂點集X={xj|j=1,2,…,n},{Xi|i=1,2,…,c}是由模糊聚類過程中產生的聚類結果構成的劃分.建立每個劃分類的下近似集的模糊中心表示vl和上近似集的模糊中心表示vu.
(14)
其中,vl為劃分類Xi下近似集的模糊中心,vu是Xi上近似集的模糊中心.aR和rR為上面已定義的近似精度和粗糙度,AR和QR為近似分類精度和質量.在這里aR代表下近似集的權重并且rR代表上近似集的權重,且有aR+rR=1,aR≥rR.類劃分{Xi|i=1,2,…,c}關于R的屬性相似性為
(15)
在模糊聚類中,當隸屬度約束條件放松時,頂點的隸屬度可能大于1.那么每個類中頂點的隸屬度就大不相同.換句話說,一些頂點對于每個類可能具有較高隸屬度,而其它頂點對于每個類可能具有較低隸屬度.如果頂點在一個類中具有較高隸屬度,則最終類可能只包含這一個頂點[14],也就是說,噪聲會被聚到單個類,會導致聚類結果不理想.在我們的聚類算法設計中,給出一個可在uij基礎上快速提高的隸屬度函數
(16)
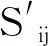
基于對類上下近似集中心表示和隸屬度函數的論述,對給定的圖數據G=(X,E,W),本文嘗試構建基于目標函數的模糊聚類方法.其模型的目標函數為
(17)
其中,d(vl,vu,xj)表示圖數據中基于類的上近似集和下近似集的模糊中心與所有頂點之間的距離度量,其基于粗糙集思想的數學定義為
(18)
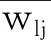
在傳統模糊聚類算法中,用一般歐式距離作為頂點之間的相似性或距離度量,且每個類皆用單個類中心來表示.在本文算法中,首先通過引入聚類基于上下近似集的粗糙表示,產生關于上下近似集的模糊中心表示,然后針對這3種模糊中心的表示提出一種特殊的距離度量方式,確定3種模糊類中心vl、vu和vi.
3 算法
算法通過引入粗糙集中上下近似集的思想,分別設計了相應的類上下近似集的模糊中心表示.針對無向加權圖數據,算法綜合考慮其拓撲結構信息和邊權重得到一種綜合結構相似性度量方法.在聚類過程中,以初始化的模糊隸屬度矩陣出發,算法通過不斷對類中心和模糊隸屬度矩陣進行更新迭代,直到目標函數達到穩定值或滿足停止閾值,此時便可獲得最終的模糊聚類結果.參考算法最終輸出的模糊隸屬度矩陣,對頂點依據每個類的隸屬度進行劃分.具體步驟可參考算法 1.
眾所周知,模糊聚類算法對初始化聚類中心較敏感,往往會得到顯著誤差.我們在算法中通過尋找最小指標值對應的類數來確定最優聚類數,以確定類中心.
算法1基于目標函數優化的無向加權圖粗糙模糊聚類算法
輸入: 無向加權圖數據G(X,E,W).
輸出: 隸屬度矩陣U和類中心V.
過程:
第一步 根據公式(9)歸一化處理圖數據中邊權重.
第二步 初始化算法相關參數:類數c、m=2、ε=0.001、T=0、α=0.6、U0.
第三步 根據公式(11)計算頂點的綜合結構相似性.
第四步 根據公式(15)計算頂點的屬性相似性.
第五步 根據公式(13)和(14)分別計算類中心vi,上近似集模糊中心vu和下近似集模糊中心vl.
第七步 如果|J(T+1)-J(T)|≤ε,則轉到步驟7,否則轉到步驟5.
第八步 根據步驟4和步驟5得到U和V,計算算法各項指標值.
第九步 求有效性指標的最小值,選擇對應的c作為最佳聚類數.
4 實驗分析
針對無向加權圖數據,本文結合了基于頂點拓撲信息與邊權重貢獻的綜合結構相似性和基于等價關系R的屬性相似性度量,提出一種基于目標函數優化的粗糙模糊聚類算法,并且算法通過隸屬度函數和類中心的不斷更新迭代來記錄目標函數的變化趨勢.
為了測試算法的聚類性能,實驗使用了UCI數據庫中的真實數據集,將我們的聚類算法與4種經典聚類算法進行對比.實驗環境均為Win10 64位操作系統、Matlab軟件、8G內存、Intel(R) Core(TM) i5-10210U CPU.
4.1 實驗數據集
本實驗將論文提出的聚類算法與其它4種經典的聚類算法分別在4種無向加權圖數據集進行比較分析,對比算法分別為近鄰傳播算法(AP)、近似模糊C均值聚類(AFCM)、基于核的改進模糊C均值聚類(KFCM)和模糊C均值聚類(FCM).表1列出圖數據信息并且已進行了標準化處理.

表1 數據集
4.2 評價指標
為驗證論文所提出算法模型的有效性,實驗共采用了10種常見聚類有效性指標,除了表2已列出的5種指標外還有聚類準確率、召回率、標準化互信息、聚類模塊度和運行時間效率.
聚類有效性指標需要突出反映類內緊密度和類之間的分離度[8].劃分系數(PC)[3]和劃分熵(CE)[3]是聚類模糊性的一種度量指標.PC值越大,CE值越小,表明聚類越明顯,算法效果越好.劃分指數(SC)[8]是類內緊致性與類間分離度的比值,Davies-Bouldin指數(DBI)[16]和分離指數(S)[16]是類間分離度與類內緊致性的比值.因此,SC值越大表明算法的聚類性能越好;對于DBI和S來說,情況正好相反.表2為5個聚類有效性指標的簡要描述.

表2 有效性指標描述
此外,準確率(Acc)和召回率(Re)的具體公式為
(19)
(20)
其中,ai表示正確劃分到類bi的頂點數,bi表示本該屬于類bi但被錯誤劃分到其它類的頂點數.
標準化互信息(NMI)的計算方式為
(21)
其中,I(X,Y)為劃分類X和Y之間的互信息,H(X)是X的熵,具有如下的表示形式
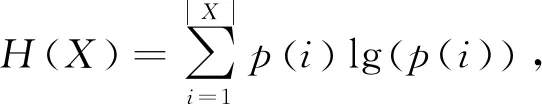
(22)
其中,H(Y)的計算類似于H(X),p(i)表示從X中隨機選取的頂點在類Xi的概率.
GAO提出評價重疊聚類結果質量的模塊度函數(Q)[5]
(23)
其中,kj表示頂點xj的度數,Aij表示圖數據的鄰接矩陣,m表示圖中邊個數.
4.3 實驗結果
本次實驗通過不斷增加聚類數和迭代嘗試,記錄實驗所得數據對比結果.下面將5種算法分別在4個圖數據上的各類指標對比結果進行展示和分析.
圖2展示了所有對比算法分別在4個數據集上的收斂性曲線及對比結果.從整體可以看出,所提出的算法(紅色曲線表示)在4個圖數據集上都表現出明顯的收斂性.隨著迭代次數的不斷增加,對應的目標函數值都逐漸減小并最終趨于一個穩定的常數值,且收斂于穩定狀態經過了較少的迭代次數,這也表明了算法花費較少的運行時間.從單個圖數據集上來看,論文提出算法的目標函數趨于穩定過程中的速度基本快于其它對比算法,但因受到不同數據集本身差異的影響,算法在個別迭代次數時的收斂性出現輕微波動,表現為曲線下降的不光滑現象.總體來說,依然可表明我們算法的良好收斂性且較優于其它算法.
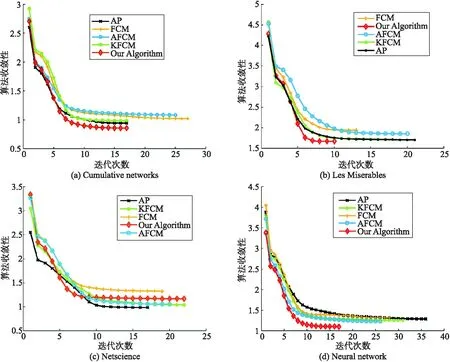
圖2 算法的收斂性對比
圖3分別給出了4個圖數據上5種算法聚類結果的指標(僅表2所示指標)對比結果,其中5種顏色分別代表5種指標,橫坐標表示5種算法.從圖3整體看出,文中算法聚類結果的PC、SC 值較其它算法大,同時CE、S、DBI值較其它算法更小,說明算法整體上具有更明顯的正向算法優勢.依據指標評價標準,論文提出算法在Cumulative networks數據集上具有更好表現.

表5 算法NMI %
從單個圖數據來看,文中的算法在Cumulative networks數據集(圖3(a))上相對于其它圖數據集獲得較小的S值為0.21、 最大的PC值為1.82和最大的SC值為1.51.已知SC是類內緊致性與類間分離度的比值,PC是聚類模糊性的一種度量指標,S是類間分離度與類內緊致性的比值.因此,SC和PC值最大意味著算法聚類性能最好,S值越小聚類越明顯,算法效果越好.從3個指標值對比可知,文中算法在Cumulative networks數據集上的聚類效率都明顯優于在其它圖數據上.
在Les Miserables數據集(圖3(b))上,論文所提出算法的最終聚類結果獲得了最低的DBI值為0.03、最小的CE值0.2.已知CE是聚類模糊性的一種重要度量指標,DBI是類間分離度與類內緊致性的比值.故由最小的CE和DBI值可以說明所得聚類劃分結果越明顯,類的模糊性就越低,類間的分離度越大,類內頂點間更緊致,表明算法聚類效果越好.
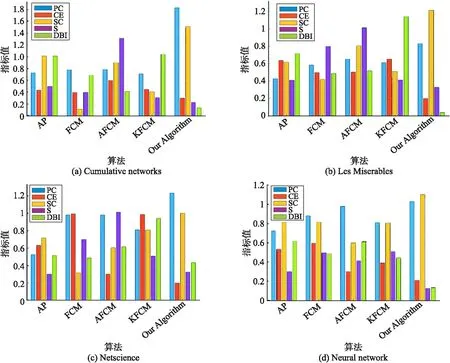
圖3 單個數據集上的PC、CE、SC、S、DBI指標對比
在Netscience數據集(圖3(c))上本文算法較其它圖數據獲得最小CE值為0.2,獲得S值為0.32且明顯大于算法在Cumulative networks數據集上的結果.S是類間分離度與類內緊致性的比值.因此,S值較小表現出較強聚類性能且聚類越明顯.所以僅在Netscience數據集上,算法的S指標值結果不是理想的較小或最小值,說明算法在此數據集上基于S指標表現不明顯,而基于CE指標的結果較好.除此之外,指標PC、SC和DBI在此數據集上的數值變化處于中等偏上水平,總體可認為算法在Netscience數據集上基于指標的聚類效果略優于其它圖數據,但是相差不大.
在Neural network數據集(圖3(d))上,本文算法獲得CE值為0.21,較Les Miserables和數據集Netscience僅大0.01.算法獲得了最小的S值為0.13,這與Les Miserables數據集上獲得的指標值之間的最大差值為0.19.已知S是類間分離度與類內緊致性的一個平衡指標.因此,最小的S值意味著算法聚類結果具有較高類間分離度和類內緊致性.基于算法效率而言,這體現出較其它算法最強的聚類性能和最佳的聚類結果.另外,算法的PC和DBI在此圖數據集上的表現不具有很明顯的優勢.各項聚類效率指標值的對比分析表明我們的算法在單個Neural network數據集相對于其它算法和圖數據表現穩定,具有較好聚類性能.
為了更直觀地比較算法的優劣,圖4分別展示了各個算法分別在4個圖數據上聚類結果的Acc、Re、NMI和Q對比情況.相應地,表3~5分別給出Acc、Re和NMI的具體數值.
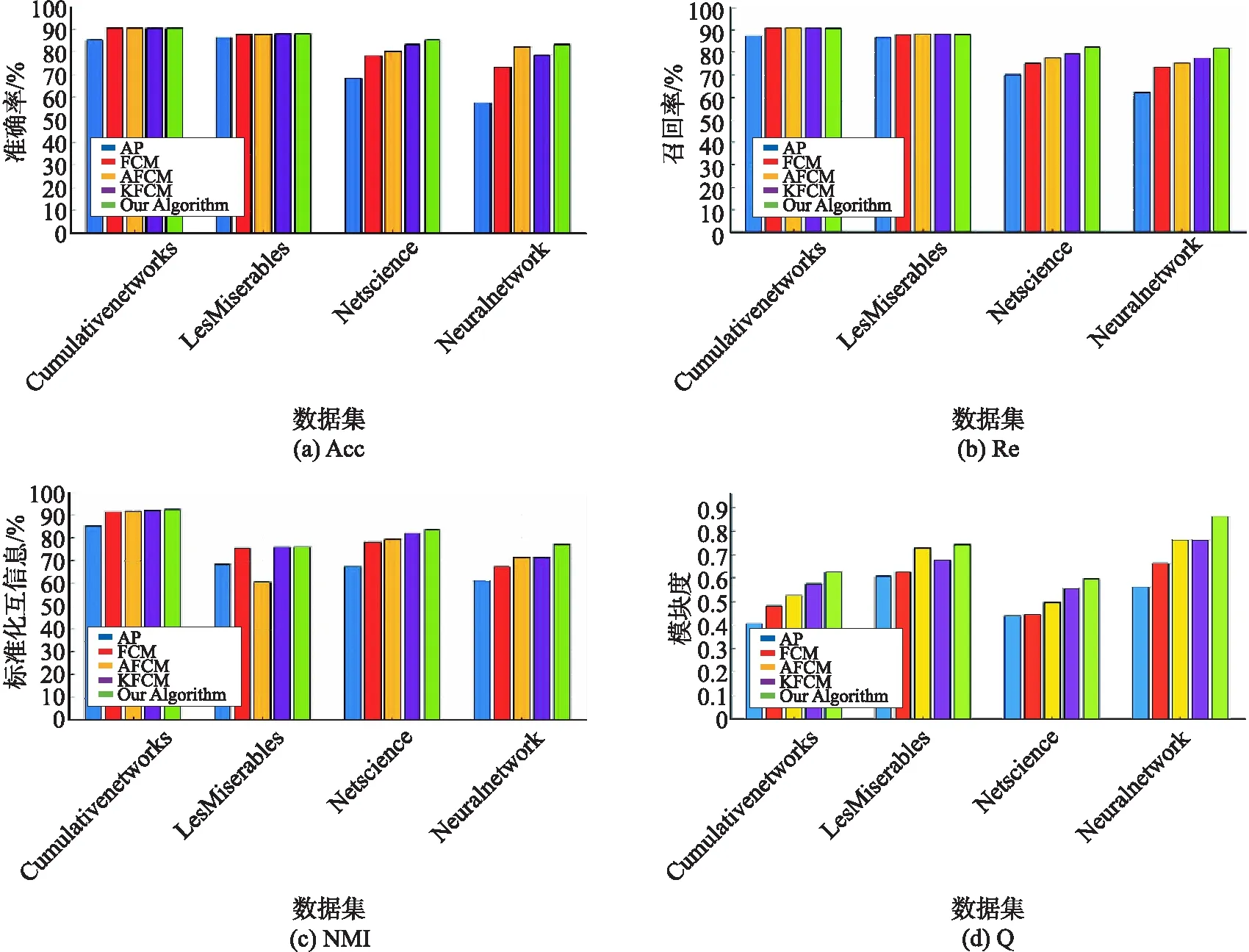
圖4 算法Acc、Re、NMI、Q對比

表3 算法Acc %
從圖4(a)和表3來看,本文算法獲得最高的Acc值,比其它算法都具有明顯地提高.但是AP算法在4個數據集上均獲得最低Acc值,這是由于當AP聚類算法被應用于一個圖數據時,如果歸屬同類的頂點相似性很高而不同類的頂點相似度很小,那么這類算法不具有優勢.但對于類與類間邊界不清晰的圖數據來說,我們的算法則更加適用.從單個數據集觀察來看,AP算法在Cumulative networks數據集上的聚類結果依然表現最差,而算法與其余3種算法獲得了相同且最高的Acc值為90.60%.在Les Miserables數據集上,算法僅與KFCM算法獲得相同最高的Acc值,表明2個算法的最高聚類效率.在其余2個圖數據上,算法均取得了最高的Acc值,更加說明了我們算法的聚類效果.
通過觀察圖4(b)和表4發現,本文提出算法依然獲得最高Re值,而AP算法獲得最低值.從單個圖數據來看,算法與對比算法AFCM和KFCM在Cumulative networks數據集上的聚類結果最佳,Re達到最高值90.70%,但是AP算法對于Cumulative networks數據集的Re最低,聚類結果仍然最差.在Les Miserables數據集上,本文算法與KFCM算法取得相同最高Re值為88.00%,而在另外2個圖數據上,算法均獲得最高值說明了算法在此圖數據上的聚類效果最好.

表4 算法Re %
從圖4(c)和表5的NMI來看,本文算法依然在單個圖數據上均獲得最高值.NMI用來衡量2個變量之間的相關性,是一種常見的評價聚類指標.實驗中用指標NMI來衡量頂點的實際類別與實驗結果是否一致,而最高的值直接說明了算法聚類效率很大程度符合實際結果.從單個圖數據來看,算法對于Cumulative networks數據集的聚類結果最佳,標準化互信息達到92.30%,而AP算法獲得最低值,算法較之明顯提高了7.20%.但在圖數據集Les Miserables上,本文算法與KFCM取得相同最高NMI為76.00%.綜上分析得本文算法的聚類效率具有明顯的優勢.同時可通過選擇最小指標值找到正確合理的聚類數.
為了進一步證明算法效率,對比算法聚類結果的Q值.已知Q大小取決于聚類情況,其值越接近1表示類結構強度越強,聚類質量越好.圖4(d)給出對比結果,從圖整體發現,論文提出算法(綠色柱狀)在生成高質量聚類的Q值明顯大于等于其它算法.在第一個圖數據集上,算法同FCM、AFCM和KFCM獲得相同且最高的Q為90.70%.在單個的數據集Les Miserables上,算法同KFCM算法獲得相同且較高Q值為88.00%,但僅較對比算法AFCM高0.02%,在其余圖數據上僅我們的算法獲得最高Q值.綜上分析表明,本文方法的類識別能力較好.基于獲得Q值可以通過選擇最高模塊度值確定算法的最佳聚類結果.
圖5為所有對比算法分別在4個圖數據集上的運行時間對比情況,結果同樣可證明算法的有效性.從單個數據集來看,在Cumulative networks數據集上,算法較其它算法的運行時間最短,且較KFAM算法運行時間短 0.018 s.在其它數據集上我們算法的運行時間依然是最短的.特別地,在Neural network數據集上,AP、FCM和AFCM算法的運行時間較我們算法更久.從實驗結果得出,論文提出的算法繼承了模糊C均值算法的時間優勢,運行時間比其它算法花費更少,因此在運行時間和內存消耗上都具有優勢.這是因為算法不但考慮了圖的結構相似性和屬性相似性,還考慮了頂點之間邊的權重貢獻,在聚類數量增多時,頂點間的權重也會增大,此時算法聚類效果更明顯.

圖5 算法時間效率對比
5 結語
針對無向加權圖數據聚類問題,本文提出了一種考慮圖數據屬性信息和拓撲信息的粗糙模糊聚類算法.提出一種結合拓撲信息與邊權重的綜合結構相似性度量方法和一種由等價關系R誘導的屬性相似性,并通過結合這2種相似性構建了算法聚類具有快速提高性質的隸屬度函數.算法進一步引入粗糙集思想,建立了聚類的上下近似集的模糊中心表示,并以此為基礎構建了參與算法迭代的目標函數.實驗結果表明,本文提出的算法具有更高效的聚類性能.
