局部-整體雙向推理的文物無監督表征學習
2022-10-27 04:53:44耿國華劉陽洋周明全
光學精密工程 2022年18期
劉 杰,耿國華*,田 煜,王 毅,劉陽洋,周明全
(1.西北大學 文化遺產數字化國家地方聯合工程研究中心,陜西 西安 710127;2.西北大學 信息科學與技術學院,陜西 西安 710127)
1 引 言
隨著傳統博物館向數字博物館的轉變,文物的展示方式突破了藏品展陳的時空限制,變得豐富多樣,同時稀缺文物也可以得到很好地交流與共享。作為考古史上的重大發現之一,由于自然環境和人為因素的影響,兵馬俑大多以碎片的形式出土。因此,兵馬俑的修復工作亟待解決。傳統的人工修復方法不僅費時耗力,同時會對文物造成二次傷害。隨著激光掃描儀技術的飛速發展,文物虛擬修復技術成為研究熱點。作為文物修復的關鍵步驟,強大的碎片特征表示可大大提高碎片分類、匹配和拼接等工作的效率,對文物保護起著不可或缺的作用。
文物表征學習方法通常分為傳統機器學習方法和基于深度學習的算法。傳統方法一般采用專家設計的特征描述算子。Rasheed等[1]提出了依賴于RGB顏色特征和紋理特征、文物碎片之間以及基于灰度共生矩陣(Gray Level Cooccurrence Matrix,GLCM)從碎片中提取紋理特征的算法。路正杰等[2]提出了一種點云局部信息與顯著性多特征描述子,并結合旋轉投影特征,解決文物破損嚴重時分類效果差的問題。上述算法依賴于專家的先驗知識,需花費大量時間,且手工設計提取特征的方法表達能力較弱,使得分類模型的泛化能力不強。近年來,隨著深度學習的快速發展,一些學者將深度學習理論應用于自動駕駛[3-4]、遙感[5]、文化遺產保護[6-10]等領域,其中文物修復包括文物模型簡化[6],文物碎片分類、分割[7-9]和文物碎片拼接[10]等。隨著激光雷達傳感器和深度傳感器等三維數據采集設備的普及,點云已成為一種常見的三維模型數據,其結構簡單且描述的形狀信息豐富。如何將點云數據應用于上述領域,已經成為深度學習計算機視覺領域新的熱點。由于點云是無序的且分布稀疏,使得將二維卷積直接應用在點云上是困難的。Charles等[11]提 出的PointNet是利用 深度網絡 直接處理點云的開創性工作,并取得了較好的效果,但該模型沒有考慮局部特征。許多后續工作通過設計能夠更好地獲取點云的局部特征的卷積來擴展這個方向[12-17]。PointNet++[12]通過將點云劃分為小的子集,構建了通過層級結構學習局部區域特征的網絡。Yang等[7]提出一種基于雙模態神經網絡,能夠較好地同時提取兵馬俑碎片的空間特征和圖像紋理特征。Liu等[17]提出一種基于多尺度和自注意力機制的深度神經網絡,可以較好地提取兵馬俑碎片點云的局部特征和全局特征。
上述有監督學習方法雖然取得一定的成績,但往往需要大量的人工標記數據做訓練,人工標注工作費時耗力[18],尤其是對于真實場景數據集。因此,無監督特征表示方法的研究具有一定的現實意義。從無標簽的數據中學習有用的表征是點云分析中一個具有挑戰性的問題。現有方法大多數主要是基于生成或重建任務提供的自我監督信號,包括自我重建[19-21]和局部到整體重建[22]。Achlioptas等[19]通過多層感知器(Multi-Layer Perceptrons,MLPs)從特征表示中生成與原模型相似的結構,即Auto-Encoder(AE)結構。但該AE模型生成的點云模型較稀疏、粗糙。Yang等[20]提出一個通過深度網格變形的點云自編碼器(FoldingNet),以此來得到可以表示高維嵌入點云的特征表示,并以基于折疊的解碼器替換原有的全連接解碼器。Li等[21]將已有的生成對抗網絡框架(Generative Adversarial Networks,GAN)擴展到處理三維點云數據,提出一個用于點云分層采樣和推理網絡的深度生成對抗網絡(Point Cloud-GAN,PC-GAN)。該網絡通過使用層次貝葉斯建模和隱性生成模型的思想來學習生成點云。Liu等[22]通過局部到整體重建方法L2G Auto-Encoder同時學習點云的局部和全局結構。Hassani等[23]利用聚類、自動編碼和自監督分類這三個無監督任務來學習點云上的點和形狀特征并取得較好結果,但網絡架構復雜。上述無監督學習方法在提取點云低層次結構信息時是有效的,但通常不能或難以從點云中學習高層次的語義信息。
針對上述問題,本文通過不同抽象層次的局部表征與文物碎片對象的全局表征之間的雙向推理,提出一種能夠同時學習點云的結構和語義信息的無監督點云表征學習。該局部-整體雙向推理模型由兩部分組成:(1)局部到整體推理:首先定義預測網絡,將局部特征和全局特征映射到一個共享的特征空間內,然后衡量由局部特征得到的全局特征與直接提取的全局特征之間差異,進行反復學習,使其局部特征向全局特征靠攏;(2)整體到局部推理:為保證全局特征的質量,利用自重建任務學習文物碎片對象必要結構信息的全局特征。本文算法在兵馬俑數據集和Modelnet40公開數據集上的準確率分別達到93.33%和92.02%。其中在兵馬俑數據集上,該算法優于除有監督模型AMS-Net(較AMS-Net準確率低2.35%)之外的所有方法。實驗結果表明,本文無監督方法的點云表征在下游分類任務中比部分有監督表征更有鑒別力,同時縮小了無監督和監督學習方法之間的差距。作為將無監督表示學習應用于3D兵馬俑數據集的一次新的嘗試,該方法減少了文物數據集在收集和注釋過程中所花費的大量成本,對文物虛擬修復提供一種可行的方法,具有一定意義。

圖1 兵馬俑碎片數據集示例Fig.1 Examples of the Terracotta Warriors fragments datasets
2 兵馬俑數據集制作
本實驗所使用的兵馬俑碎片數據集是由西北大學文化遺產數字化國家地方聯合工程研究中心可視化研究所的學生使用Creaform VIU718手持式3D掃描儀采集得到的,共來自3 250塊兵馬俑碎片,并根據每個碎片所屬部位的不同,將其分為手臂(800塊)、身體(810塊)、頭部(810塊)和腿(830塊)四類。兵馬俑碎片數據集示例如圖1所示。對掃描得到的點云進行去噪聲和下采樣等一系列預處理操作。首先,使用Geomagic軟件獲得如圖2(a)所示的原始稠密點云。其次,為減少網絡的過擬合,同時提高網絡預測的魯棒性,需對稠密點云按一定比例進行下采樣。使用隨機采樣方法,將一個碎片點云重新采樣為四個不完全重疊的點云,且保證每個點云包含固定的點個數(1 024點),如圖2(b)所示。圖2(c)表明上述四個點云集合不完全重合。通過上述一些列操作,最終得到包含11 996塊碎片的擴增數據集,將其劃分為訓練集和測試集兩部分。其中,訓 練 集 包 含10 144塊 碎 片(Arm:2 656,Body:2 720,Head:2 272,Leg:2 496),測試集包含1 852塊碎片(testArm:476,testBody:504,testHead:428,testLeg:444)。

圖2 擴展數據集制作流程Fig.2 Approach of the extend dataset
3 基于局部-整體雙向推理無監督表征學習方法
利用三維模型的底層語義信息和結構信息融合在對象的整體結構中這一獨特屬性,使得三維模型可以由單個部分推理整個對象。如圖3所示,通過給定兔子耳部的點云,可推斷出相應整體對象;整個兔子的表示也包含所有必要的細節來推斷該兔子的局部結構。受上述啟發,本文通過局部-整體之間的雙向推理問題來實現點云表征學習。
本文提出的局部-整體雙向推理無監督表征學習整體網絡框架圖如圖4所示。首先,將點云P輸入至由兩個多尺度殼模塊組成的分層結構。編碼器通過構建分層結構的點分組,逐步擴大感受野,最終得到第l層局部特征Fl和維度為512的全局特征G。為保證全局特征G能夠獲得更豐富的點云表示,本文建立由局部到整體推理模塊,從而使得全局特征包含更多的結構信息和語義信息。為保證全局表征不偏離原始點云,再次提出從整體到局部的推理模塊,利用折疊解碼器(Folding-based Decoder)將學習到的全局特征G重新解碼為3D坐標,使得全局特征G能夠捕捉到更多的點云結構信息。接下來將詳細介紹每個模塊的組成部分。
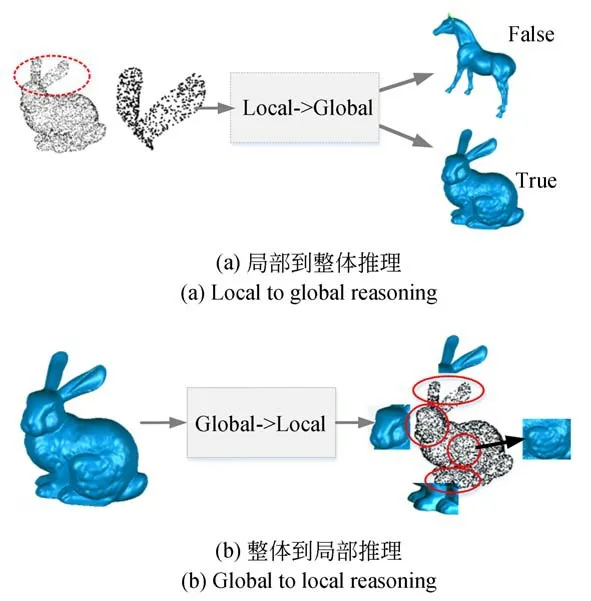
圖3 局部-整體雙向推理Fig.3 Local-global bidirectional reasoning
3.1 多尺度殼卷積層級結構特征提取
多尺度殼卷積模塊如圖5所示。本節將從多尺度局部區域的構造、單尺度特征提取和多尺度特征融合三部分分別予以介紹。
3.1.1 多尺度局部區域的構造
與PointNet++[12]和ShellNet[13]類 似,該 模型的多尺度局部區域構造分別由采樣層、搜索層和分組層組成。首先,采樣層利用最遠點采樣算法(Farthest Point Sampling,FPS)從輸入點云P中選擇M個點作為局部區域的質心,即PMc=在每個局部區域中,搜索層通過最近鄰搜索算法(K-Nearest Neighbors algorithm,KNN)尋找質心點的ki(i=1,2,3)個最近鄰點,并返回對應的點索引。其中,ki為各個局部區域每個尺度包含點云數目,本文使用三個不同大小的尺度,故i取值為3。最后分組層將點云集分成多組具有不同尺度大小的局部點集,其大小為M×ki×3。
3.1.2 單尺度特征提取
為便于理解,接下來先介紹單尺度模塊結構及特征提取,如圖5(b)所示。
本文提出一種鄰域的劃分方法。對于每個采樣點,將其鄰域劃分為一組同心球體,兩個同心球體之間的空隙定義為同心球殼。對于任意采樣點,殼卷積算子計算局部特征的算法如下:
輸 入:采 樣 點pi∈P,i=1,2…N,鄰 點pj,?pj∈Bp,鄰 域Bp,以 及 前 一 層 特 征F()l-1(pj)(上標l表示第l層)。
輸出:采樣點pi經過殼卷積的輸出特征Fp。
Step1:通過KNN搜索采樣點pi的鄰點pj,并將鄰點特征維度提高到F()l(pj)。
Step2:若已存在前層特征F()l-1(pj),則將F()l-1(pj)與F()l(pj)拼接在一起作為該點提取得到的特征F(l-1)(pj)。
Step3:根據鄰點pj到采樣點pi的距離確定pj屬于哪個殼,同一個殼內的點用X表示。
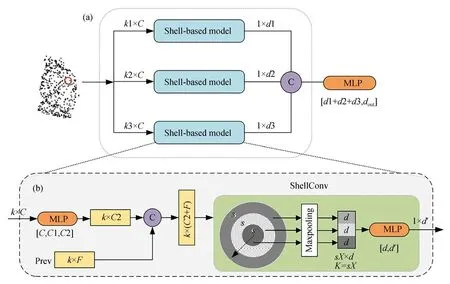
圖5 多尺度殼卷積模塊Fig.5 Multi-scale shell convolution block
Step4:通過最大池化操作獲取每個殼的局部特征。
Step5:按照從內到外的順序對所有殼的局部特征執行一維卷積,得到輸出特征Fp。
對于任意采樣點pi來說,pi點上傳統的卷積為:
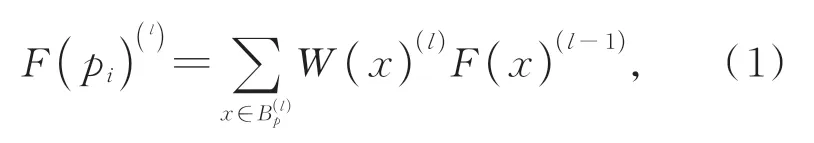
其中:F(·)表示輸入點的特征,W表示卷積的權重。每個點均需一個與之對應的權重,但點云是無序的,為每個鄰點pj都分配卷積權重W(pj)是不切實際的。為解決該問題,本文將劃分為同一殼內的點的特征分配相同的卷積權重。如圖5所示。規定每個殼中的點個數是固定的,確保每個殼中包含的點數達到閾值s后,向外擴展,直到下一個殼內點個數也達到s,依此類推。假設該采樣點的鄰域由X個殼組成,則鄰域數k為sX,那么采樣點的鄰域可表示為M×k×3。改進后的卷積可定義為:
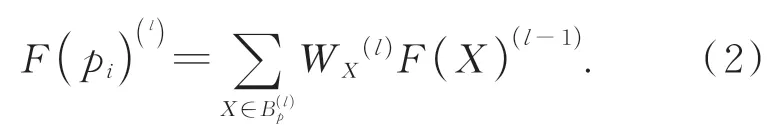
按照由內到外的順序對殼進行排序,每個殼的權重為WX。但每個殼中的點仍然是無序的,為了產生對輸入順序不敏感的輸出,通過最大池化來聚合同一個殼內的點,并使用一維卷積整合所有殼的特征以獲得采樣點的融合特征Fp:
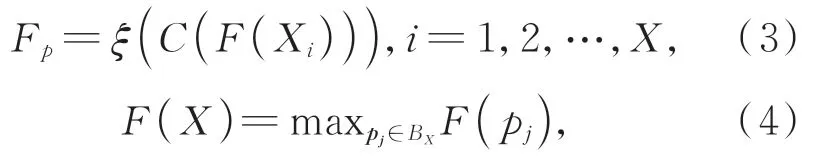
其中:C(·)為拼接操作,ξ(·)為一維卷積操作。
3.1.3 多尺度特征融合
受文獻[13]啟發,本文提出一種基于多尺度殼卷積點云特征提取方法,其結構如圖5所示。
每個單尺度模塊輸出的特征在進入下一個多尺度殼模塊之前還將進行特征聚合,以形成包含不同尺度局部信息的全局特征。其中,三個不同尺度的特征分別記為Fpk1,Fpk2,Fpk3,融合后的多尺度特征記為Fmulti:
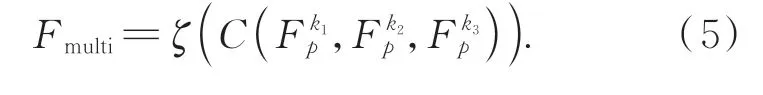
3.2 局部到整體推理模塊
本文利用局部和整體形狀之間的關系作為監督信號,用于訓練豐富的表征進一步理解點云。由于全局表征通常比局部表征能更好地捕捉對象的語義信息,所以局部到目標的推理是通過預測局部的全局表征來進行的。為了評估預測結果,本文將預測視為自監督度量學習問題,并使用改進多類N對損失(N-pair loss)來監督預測任務。
首先,簡單回顧三元組損失函數[24](Triplet loss)。三元組{pa,pp,pn}由錨點pa,正樣本pp和負樣本pn組成。映射函數fω(·)可以將點pi映射到嵌入特征fω(pi)∈Rd。為方便表示,令χa=fω(pa),χp=fω(pp),χn=fω(pn)。Triplet loss的目標是使同類樣本的特征在空間位置上盡量靠近,不同類樣本位置盡量遠離,并要求pa到負樣本pn的距離與pa到正樣本pp的距離之差至少大于閾值η,圖6為Triplet loss與N-pair loss示意圖,其中,“+”代表正樣本,“-”代表負樣本。Triplet loss表示形式如式6所示:
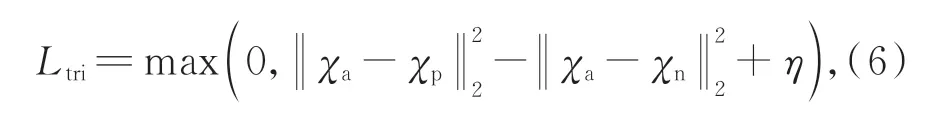
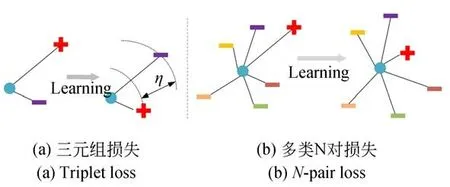
圖6 Triplet loss與N-pair loss示意圖Fig.6 Illustration of Triplet loss and N-pair loss
Triplet loss在學習參數的更新過程中,只比較了一個負樣本,而忽略了其他類的負樣本,故Triplet loss收斂速度慢。針對上述情況,N-pair loss[25]被提出,它是由多個負樣本對組成,即一對正樣本對,選取其他所有不同類別的樣本作為負樣本與其組合得到負樣本對。如果數據集中有C類別,則每個正樣本都對應了N-1個負樣本對。通過圖6中兩者比較,Triplet loss可看作是N-pair loss的一 個 特 例(N=2)。N-pair loss的 形式如式(7)所示:
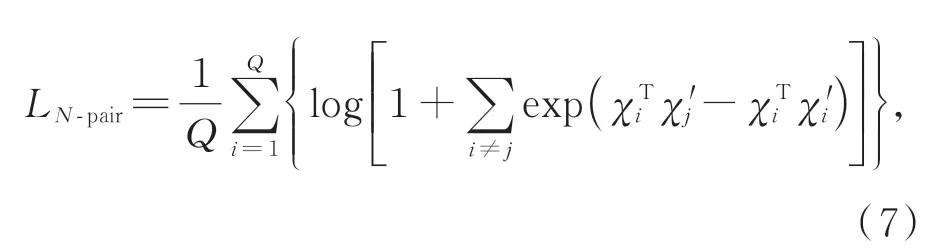
其中,χi=fω(pi)和{pi,p1′,p2′,…,pQ′}為來自Q個不同類別的樣本對。為學習每個對象的不同語義信息,將當前對象的全局表示作為正樣本,將其他類對象的全局表示作為負樣本。由于局部特征Fpi(l)和全局特征G的維度不同,無法直接衡量它們之間的相似度。故先使用Γ(l)(·)和B(·)將它們分別嵌入到一個共享的特征空間中。
優化預測的一種直接方法是最小化Γ(l)(Fpi(l)),B(G)之間的整體差異,即最小化然而,該目標可能會導致將所有輸入映射到一個常數。本文使用自監督度量學習任務來監督預測的好壞。對于每個嵌入的局部表示Fpi()l,強制其特征比任何其他類別對象更接近同一對象的全局表示,故本文使用的改進N-pair loss表示為:
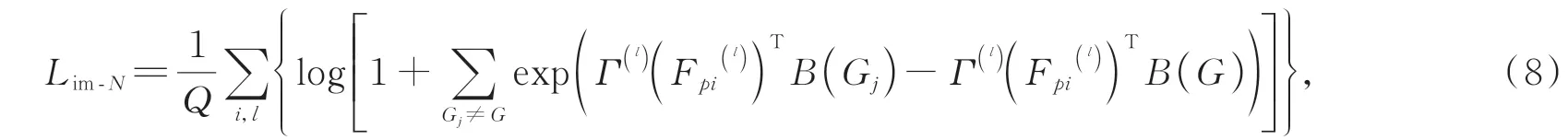
其中:{Gj}qj=1是批量大小為q的批量中不同點集的全局表示,M是局部特征的數量。
3.3 整體到局部推理模塊
局部到整體的推理只能監督局部表征接近全局表征,全局表征的好壞至關重要。若全局表征效果好,則會對局部表征提供較好的監督,從而為局部和全局特征的學習創造一個良性循環。反之,會導致網絡學習到不可預知的結果。為避免該問題的產生,本節提出自重建輔助任務來監督網絡共同學習有用的表征。自重建模塊采用3.1節提出的基于多尺度殼卷積層級編碼器,解碼器結構圖如圖4中Decoder所示。首先,將編碼器所得到的全局特征G∈R1×512復制m次,可得FG∈Rm×512。其次,將大小為m×512的特征矩陣FG與包含m×2網格矩陣拼接得到Fnew∈Rm×514,其中m×2矩陣包含以原點為中心的正方形上的m個網格點。然后,將Fnew送入MLPs得到粗輸出Fcoarse,其特征矩陣大小為m×3。為得到更好的重建點云,最后將m×512矩陣FG與粗輸出Fcoarse拼接,再經過MLPs,得到最終重建點云。其中,網格大小m2是根據輸入點云大小設置的,且需滿足m2≥N。本實驗m=32,N=1 024。
在給定輸入點云P時,重建點云是由基于折疊解碼器D將規范的2D網格變形到以全局表示G為條件的點云的3D坐標上,記為J(G),其中J(G)∈RN×3。重建誤差Lrec定義為P和J(G)之間的倒角距離,故其損失函數定義為:
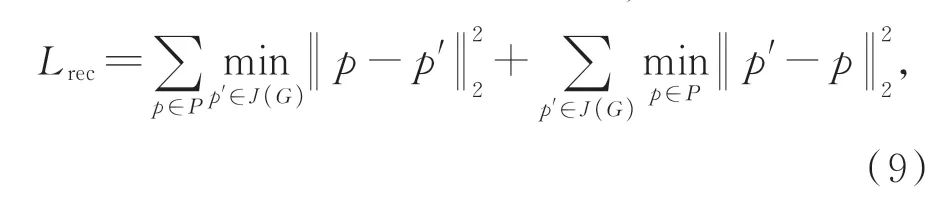
其中:P為輸入點云,p為輸入點云中的點,J(G)代表重建點云,p′是重建點云中的點。
4 實驗結果及分析
4.1 實驗數據集
本文分別選用兵馬俑數據集和公開數據集ModelNet40作為基準數據集并完成對該模型的測試,將其實驗結果與其他方法進行比較。其中,兵馬俑數據集已在第2節介紹。ModelNet40包含來自40個類別的12 311個CAD模型,其中包含9 843個訓練樣本和2 468個測試樣本。本實驗中所有數據只使用點云的坐標特征(x,y,z)。
4.2 實驗設置
編碼器網絡結構包含兩層多尺度殼卷積模塊,每個模塊均包含三個不同尺度的殼卷積算子。其中,參數Mj、sj和Xi(i=0,1;j=0,1,2)分別表示每層的采樣點的個數、每層殼的大小和不同尺度中殼的數量。因此,每個采樣點的鄰域個數為sj×Xi。具體參數取值如表1所示。對于第一層模塊來說,三個尺度鄰點個數分別等于32,64,128.同理可得,第二層模塊中不同尺度的鄰點個數為16,32,64。
本文使用Lim-N和Lrec聯合損失為損失函數,并使用Adam優化網絡,初始學習率為0.001,動量為0.9,批量大小為22。同時使用Lambda學習率調度器,每20輪將學習率衰減0.5。
實驗硬件環境為Intel Core i7處理器、16 G內存、2 T硬盤、顯卡NVIDIA GTX 1080Ti;軟件環境為Ubuntu16.04 x64+CUDA9.0+cuDNN 7.0+PyTorch1.2+Python3.7.
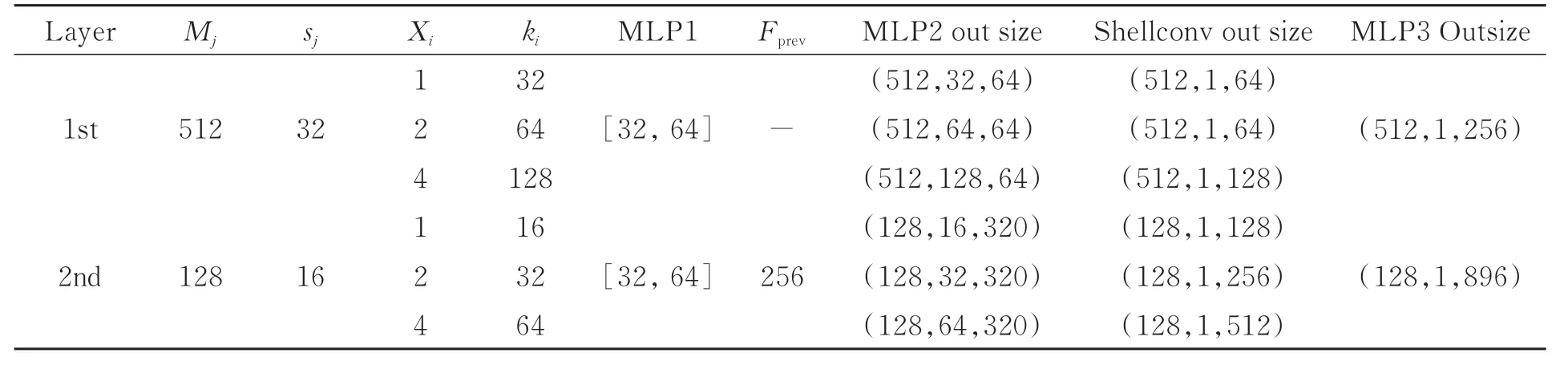
表1 編碼器網絡參數Tab.1 Encoder network parameters
4.3 不同方法實驗對比分析
為驗證本文方法的有效性,選取一種傳統點云分類方法和五種深度學習點云分類方法與之比較。目前基于兵馬俑點云集的無監督表征學習方法研究甚少,上述對比方法只有Foldingnet[20]為 無 監 督 方 法,其 余 方 法 均 為 有 監 督方法。
從表2可以看出,除AMS-Net方法之外(準確率比本文方法高2.35%),本文方法在兵馬俑數據集上取得了93.33%的最高分類準確率。表中輸入數據類型字段中“P”代表點云,“G”代表圖像。基于模板的兵馬俑碎片傳統分類算法[26]將分類問題轉化為形狀匹配問題,分類準確率為表2所 列 出 方 法 中 最 低。PointNet[11]缺 乏 局 部 特征的提取,易造成細節特征的丟失,故分類精度僅為88.93%。文獻[7]在PointNet基礎上結合圖像輪廓特征,提出一種融合點云和圖像輪廓的雙模態網絡,相比于單獨使用PointNet網絡,正確率提升了2.48%。然而本文提出的無監督方法比文獻[7]提高了1.92%,并遠超于無監督方法Foldingnet(提高了11.42%)。另外,本文所提出模型的編碼部分是在ShellNet的基礎上結合了多尺度策略,最終分類準確率高于ShellNet方法0.89%。但在ModelNet40數據集上,ShellNet高于該無監督方法1.08%(見表10),由此可以表明,該方法能夠針對兵馬俑碎塊數據集進行較好的特征表示,為兵馬俑碎塊分類任務提供了更加可靠的信息。
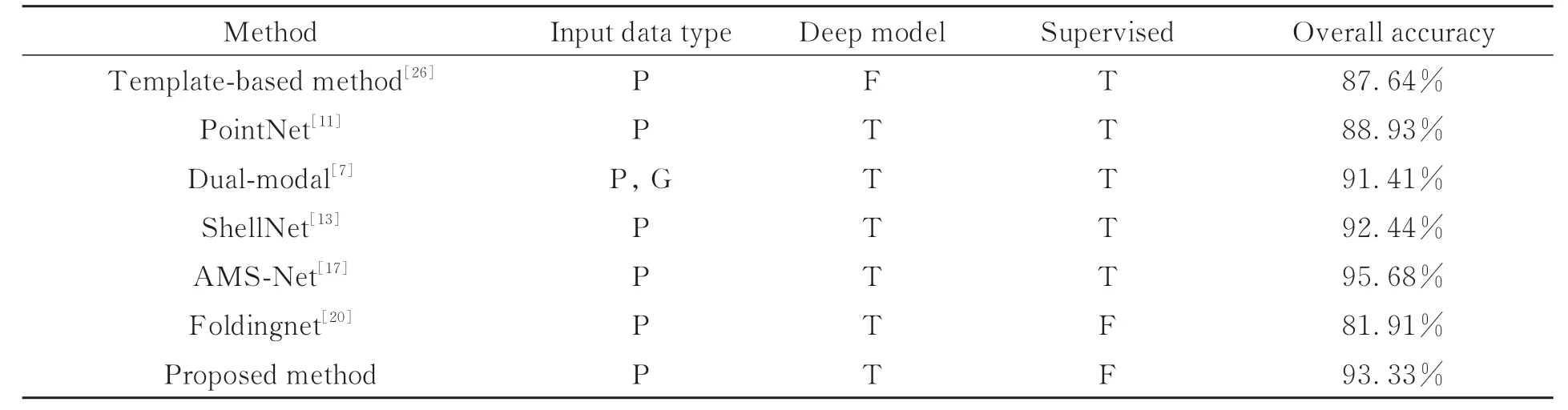
表2 兵馬俑數據集上不同方法的分類準確率Tab.2 Classification accuracies of different methods on Terracotta Warrior fragments dataset.
為了更科學地評估本文算法的分類效果,引入精確率(IPrecision)、召回率(IRecall)和F1值(IF1)作為評價指標。由于數據集包含多個類別,故文本采用平均精確率(P)、平均召回率(R)、平均F1值(F)作為整體的評價指標,三者分別為所有類對應值的算術平均值,其計算公式如式(10)~(12)。其中,NTP為正確判斷的正樣本數,NFN為誤判的正樣本數,NFP為誤判的負樣本數,類別個數為T。本組實驗僅對表2代碼公開的方法進行對比。從表3可以看出,本文算法在上述三個評價指標的結果與準確率保持一致,進一步說明該無監督方法在文物分類任務上具有一定的穩定性。
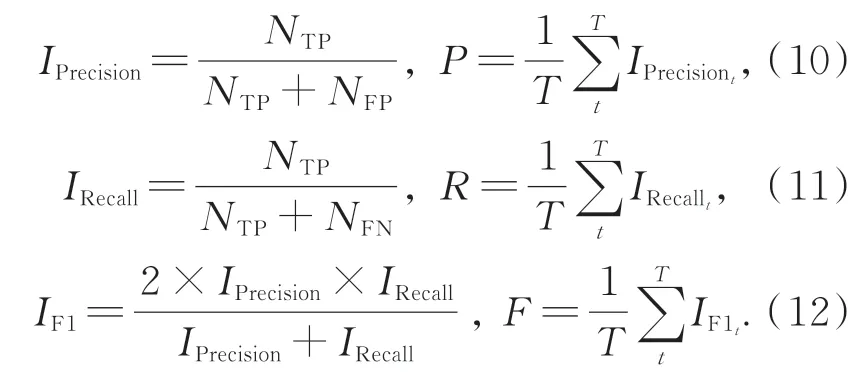
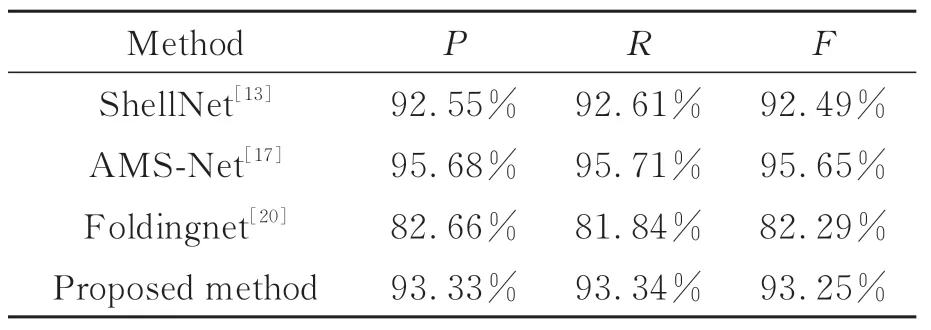
表3 不同模型的分類性能Tab.3 Classification performance of different models
從表4可以看出,表中的所有方法身體和頭部兩個類別的準確率要高于胳膊類和腿類。身體類的準確率最高,胳膊類的準確率最低。主要原因是身體大部分部位是衣服或盔甲,褶皺較多,特征較為明顯(見圖1)。部分胳膊類的特性與腿較為相似,容易被誤分類。整體上本文方法相較于文獻[7]都有很大的提升。
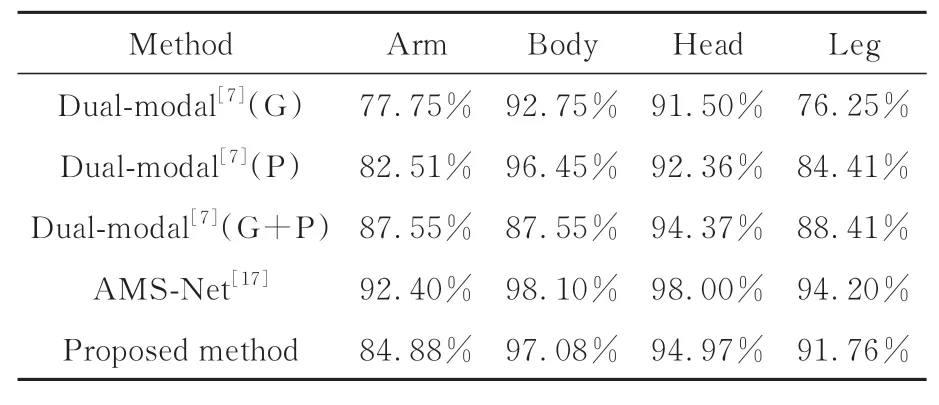
表4 4個類別中的分類精確度Tab.4 Classification accuracies of the four classes
4.4 消融實驗分析
為進一步評估該網絡模型中每個組成模塊對網絡性能的影響,在兵馬俑數據集分別進行三組對比實驗。
(1)編碼器結構:單尺度與多尺度對比。從表5可以看出,多尺度模型比單尺度模型準確率高2.40%,這表明該模型編碼器可以有效地提取多個尺度的細節特征。

表5 編碼器對分類精度的影響Tab.5 Effect of the encoder on classification accuracies
(2)解碼器結構:MLPs與Folding-based進行對比,其中,MLPs輸出通道數為[512,256,3]。從表6可以看出,本文采用的折疊解碼器比直接經過簡單的MLPs準確率提升1.88%。為進一步證明該模型的有效性,將兩個網絡的收斂性進行了比較,結果如圖7所示。該網絡在訓練25輪后逐漸變得平穩,且損失值低于MLPs解碼器。損失函數值越小,表明解碼生成的點云與輸入點云越相近。

表6 解碼器對分類精度的影響Tab.6 Effect of the decoder on classification accuracies
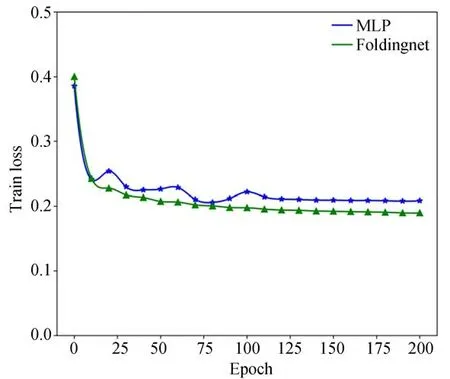
圖7 不同解碼器訓練損失曲線Fig.7 Training loss curves for different decoders
(3)損失函數:Lrec與Lim-N+Lrec進行對比。從表7可以看出,僅通過自重建損失進行訓練,得到89.47%的低分類準確率。當使用本文提出的聯合損失時,準確率可提升3.86%。結果表明通過度量每層局部特征與編碼獲取的全局特征,可以使網絡進一步捕獲兵馬俑碎片的潛在語義特征,從而提高分類準確率。

表7 損失函數對分類精度的影響Tab.7 Effectofthelossfunctiononclassificationaccuracies
4.5 魯棒性
為進一步驗證該模型的魯棒性,將大小在[-1.0,1.0]的隨機噪聲添加到輸入點云中,當一個點替換為噪聲點(nn=1)時,該模型的準確率為92.13%,其中nn為噪聲點數量。從表8可以看出,當噪聲數量高達100時,該模型仍然有很好的分類結果。表明該方法更適合真實場景數據集。

表8 不同噪聲點的結果Tab.8 Results for different noise points
4.6 在Modelnet40公共數據集的結果分析
為評估該方法在點云表征學習方面的性能,接下來在Modelnet40公共數據集上對其進行實驗測試。首先從上述預訓練模型中提取Model-Net40數據集的全局特征;然后將其放入線性分類器進行訓練,無需任何微調,得出分類結果。將本文方法與已有無監督表征學習方法進行比較,實驗結果如表9所示,其中,l-GAN的實驗結果為文獻[22]的復現結果。本文方法只使用ModelNet40作 為 訓練數據,而l-GAN[19]和FoldingNet[20]的 訓 練 數 據 是 包 含 超 過57 000個3D對象的ShapeNet數據集。盡管如此,本文方法仍比它們分別提高4.75%和3.62%。從定量結果可以看出,本文方法取得較好的分類性能,準確率為92.02%,分別比L2G和Multi-Task方法高1.38%和2.92%。
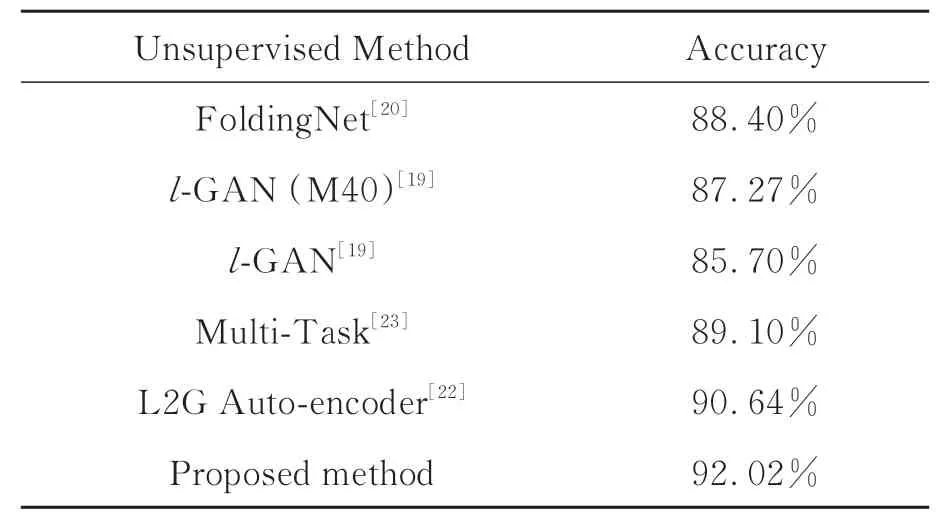
表9 與已有無監督方法在ModelNet40上的對比結果Tab.9 Comparisons of the classification accuracy of our method against the unsupervised learning methods on ModelNet40
從表10中可以看出,本文方法分類準確率分別 比PointNet和PointNet++提 高2.82%和1.32%。即使SO-Net輸入點云個數為2 048,本文方法仍相比提高1.12%。結果表明本文方法獲取的特征表示比一些監督表示更具辨別力。
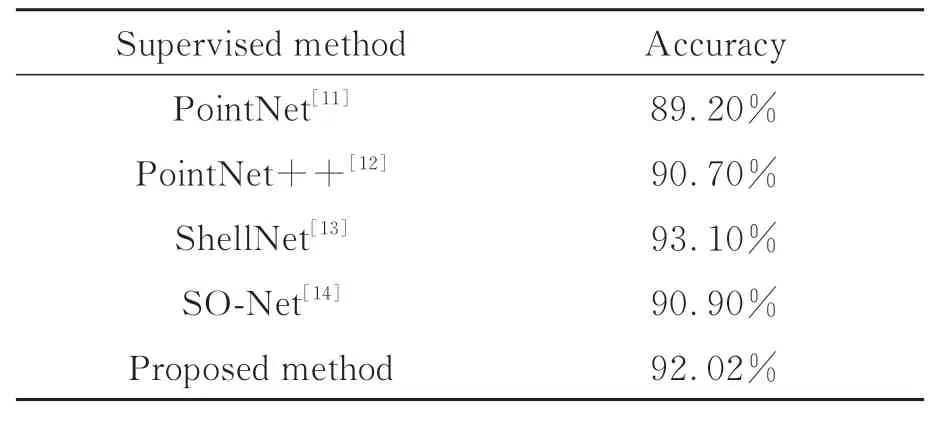
表10 與已有監督方法在ModelNet40上的對比結果Tab.10 Comparisons of the classification accuracy of our method against the supervised learning methods on ModelNet40
5 結 論
本文提出一種無監督表征學習網絡,應用于3D文物碎片分類的下游任務。首先通過層級結構的多尺度殼卷積編碼器來學習點云模型不同區域之間的相關性。其次通過各層局部特征和全局特征之間的相似性度量以捕獲模型的結構和語義信息。最后將學習到的點云表征應用于點云分類下游任務。實驗結果表明,本文算法在兵馬俑數據集和ModelNet40數據集的分類準確率分別為93.33%和92.02%。在ModelNet40數據集上,ShellNet比該無監督方法高1.08%;而在兵馬俑碎塊數據集上,該方法比ShellNet高0.89%。結果表明該方法更適合于兵馬俑碎塊分類,同時縮小了下游分類任務中無監督和有監督學習方法之間的差距。本文嘗試將點云無監督表征學習網絡應用于兵馬俑碎片數據集,結果也驗證了該方法的有效性。接下來將繼續該方法擴展到更多的文物點云分析場景中。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
