基于分數匹配生成模型的無透鏡成像方法
2022-10-27 04:54:22伍春花劉且根萬文博王玉皞
光學精密工程 2022年18期
伍春花,彭 鴻,劉且根,萬文博,王玉皞
(南昌大學 信息工程學院,江西 南昌 330031)
1 引 言
基于掩膜的無透鏡成像系統通過在圖像傳感器前幾毫米處放置一個薄掩膜來替代鏡頭組件,直接應用圖像傳感器(如CCD和CMOS)記錄場景信息,從而簡化光學硬件[1-3]。該成像方式打破了場景到圖像一一對應的采樣方式,將成像的重心由硬件轉移到計算上,使三維熒光顯微鏡、熱成像和重聚焦攝影等成像系統實現結構緊湊化、輕量化、低能耗和低成本成為可能。在過去幾年里,研究人員提出了各種各樣的基于無透鏡相干系統的成像技術,如,相干衍射成像[4-5]和片上顯微鏡[6-7]等。然而,這些成像技術對光的相干性要求很高,極大地限制了成像系統應用。
菲涅爾非相干全息術是新發展的一種非相干光成像技術。非相干光成像技術最早起源于20世 紀90年 代,Mertz和Young[8]提 出 了 用 菲 涅爾波帶片(Fresnel Zone Aperture,FZA)編碼全息成像的建議,將全息成像的概念和應用范圍拓展到了非相干光領域。與相干成像技術相比,非相干成像技術的照明光源獲取容易,且記錄過程不會產生類似于激光全息術中固有的散斑噪聲,可以有效提高再現圖像的質量。因此,非相干技術在熒光三維成像、非相干全息三維顯示、自適應光學、天文成像等領域具有獨特的應用優勢[9]。在無透鏡成像系統中,使用非相干光照明將場景中無數個點光源線透過FZA,這些點源投影在傳感器上非相干疊加后最后形成了編碼圖像。理論上,編碼圖像既包含物體振幅/透射率的信息,又包含相位延遲的信息。由于圖像傳感器只對入射光強度敏感,在圖像采集過程中只能采集圖像的強度信息而丟失了相位信息,這導致重建圖像中出現物體的孿生像[10-12]。孿生像是同軸全息中的固有問題,表現為重建圖像中會有物體的共軛像疊加在原始圖像上,從而導致重建圖像質量下降。
為克服無透鏡成像中的孿生像效應,通常采用四步相移法來去除孿生像。該方法需要采集經過四組不同相位波帶片的編碼圖像[13-14],在實際操作中,不僅需要更換波帶片,而且需要圖像間的配準,增加了實驗的復雜性。為了彌補這個缺點,可以采用單張FZA實現無透鏡成像系統的編碼,這樣既不需要波帶片和傳感器之間的校準,又能簡化實際操作。然而,使用單張FZA編碼方式并不能消除孿生像,因此需要通過重建算法消除孿生像的影響。
針對無透鏡成像過程因丟失相位信息導致重建圖像不唯一的問題,如何建立場景與圖像之間的聯系,并通過求解逆問題反演圖像是解決編碼成像問題的關鍵。傳統方法是直接通過使用反向傳播(Back Propagation,BP)算法對同軸全息圖進行重建,然而孿生像干擾嚴重影響了重建圖像。正則化技術,特別是壓縮感知(Compressive Sensing,CS)理論中提出的基于稀疏的全變分(Total Variation,TV)正則化方法是處理這種不適定問題的有效方式。2009年,Brady等[15]首次將壓縮感知理論應用于全息成像中,實現了單幅全息圖的深度重建和孿生像的去除。Wu等[16]根據孿生像和原始圖像在梯度域稀疏程度的不同提出一種基于CS的無透鏡成像方法,它通過在目標函數中加入TV正則化約束以改善問題的不適定性。在圖像處理和計算成像技術中,通過外加約束先驗的稀疏性在逆問題中可以增強圖像統計的先驗信息。雖然正則化先驗技術常被用于不適定問題的求解。然而這類人為選擇的正則化器存在校準誤差和手動調整參數等不定因素,并不能表示真正的數據。
近年來,基于分數匹配生成模型[17-19]和去噪擴散概率模型(DDPMs)[20-21]的新的生成模型[17-21]引起了人們的廣泛興趣,它在不需要對抗訓練的情況下能夠實現高質量的樣本。生成模型本質是用一個已知的概率模型來擬合所給的數據樣本。雖然神經網絡(Neural Networks)也能擬合任意函數,但是概率分布有“非負”和“歸一化”的要求,因此不能隨意擬合一個概率分布。近來,Song等人[22]提出了一個新的基于廣義離散分數匹配方法模型。該模型通過概率密度函數對觀察到的樣本進行數據建模,在利用已知輸入不變性建模數據分布方面表現出了出色的性能。生成模型在擬合參數學習的過程會盡可能地增加數據的相似度,因而可以學習良好的先驗信息。近年來,有不少該領域的研究工作聚焦于如何更好地利用算法提升來改善成像質量,尤其是針對深度重構的真實度。基于此,本文利用生成模型強大的先驗信息建模能力和成像的擬合約束相結合的方法,將生成模型引入到無透鏡成像逆問題求解。本文提出一種基于分數匹配生成模型的無透鏡方法(Lens-less imaging via Score-based Generative Model,LSGM)。具體而言,無透鏡成像系統在非相干照明下使用單張FZA實現點源編碼,無需精確校準和嚴格標定,具有更高的信噪比。然而,由于孿生像的偽影很容易導致重建質量差以及顏色重建不準確等問題。針對這個問題,本文提出一種新的LSGM算法對編碼圖像進行解碼重建。該模型通過利用梯度數據分布對圖像樣本進行建模,并從給定的觀測數據的條件分布中采樣數據,然后將采樣的數據作為先驗信息和成像的擬合約束相結合來求解無透鏡成像的逆問題。該方法模型訓練穩定、結構靈活,在數據分布建模方面表現出了強大的性能,并且能獲得豐富的先驗信息,可以有效地用于無透鏡成像中逆問題的求解,并有望擴展至其他計算成像領域。
2 基本原理及算法過程
2.1 無透鏡成像原理
如圖1所示,無透鏡成像的主要流程主要包含兩大部分:光學編碼和計算解碼。不同于傳統光學成像——“所見即所得”。無透鏡成像直接應用圖像傳感器記錄由編碼掩膜調制的場景信息,然后通過算法重建場景圖像。
若將FZA的透射率函數近似為理想波帶片,其振幅傳遞函數為:
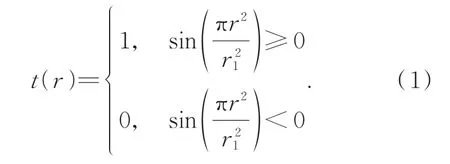
對式(1)作傅里葉展開為T(r)=[1+cos(πr2/r21)]/2。其中:r=(x,y);r1為常數,表示FZA最內側區域的半徑。然后根據歐拉公式轉化為:
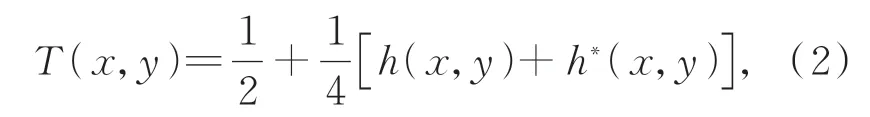
其中:h(x,y)=exp(i(π/r21)(x2+y2)),h*(x,y)是h(x,y)的共軛。當r21=λd時,h(x,y)與菲涅爾傳播核函數exp(i(π/λd)(x2+y2))相同。
目標物體被放置在離FZA一定距離處,在非相干光源照明下,經過FZA調制的所有點源疊加的集合被傳感器捕獲。其成像過程的表達式即為目標圖像與FZA函數的卷積:
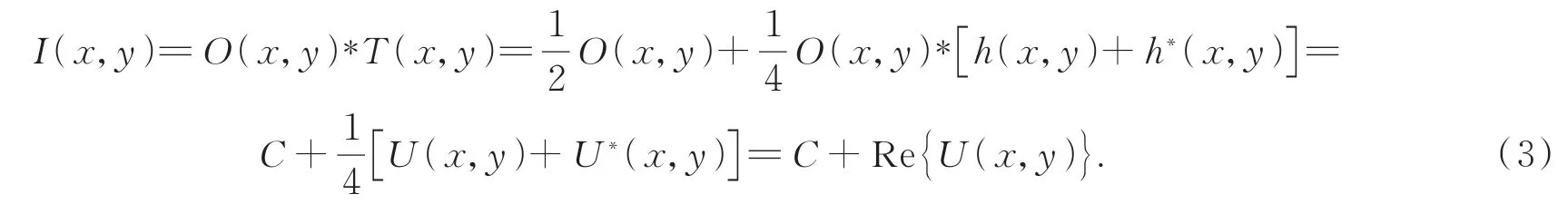
其 中:*表 示 卷 積;O(x,y)為 目 標 圖 像;U(x,y)=O(x,y)*h(x,y)可以看作是波長為λ的光波在距離d處傳播的衍射波前圖像;U*(x,y)與U(x,y)相互共軛,式(3)中U*(x,y)相關的項即為孿生像;C為常數,可直接通過直流濾波去除。將上式卷積計算轉換到傅里葉頻率域,計算公式表示為:

其中,I∈RNxy為傳感器測的圖像數據;O∈RNxy為目標圖像;F和F-1分別為傅里葉變換算子和逆傅里葉變換算子;H表示乘以傳遞函數H=i exp(-iπλz(u2+v2))的操作算子。由于O為實函數、H為中心對稱函數,則Re{H}=sin(πr21(u2+v2))是cos((π/λd)(x2+y2))的 歸一化傅里葉變換。假設系統轉換矩陣H=F*ΛF,其中F∈RNxy×Nxy為二維離散傅里葉變換矩陣,Λ為對角矩陣,其非零項為Re{H}的離散值。則用O表示I的相關函數即為正向轉換模型:

其中,H為系統測量矩陣或者傳遞函數矩陣。上述正向模型是一個典型的逆問題。在式(3)中,U(x,y)的虛部可以被任意賦值,使得求解不唯一,從而產生孿生像。孿生像的偽影很容易導致重建質量差以及顏色重建不準確等問題,引入合適的圖像先驗是解決該問題的關鍵。
傳統的方法包括變換域中圖像的稀疏性、圖像梯度的稀疏性、正則化先驗、低秩等。隨著生成模型的研究發展,圖像的生成式建模的進展已經遠遠超出傳統的基于先驗的算法。新的一類生成模型[22-24]被提出,它們提供了一種使用梯度數據分布對圖像進行建模的強大方法,利用學習的分數函數作為先驗,可以很容易地解決成像中的逆問題。近來,Song等人[22]提出使用隨機微分方程(Stochastic Differential Equation,SDE)緩慢地添加噪聲將復雜數據分布轉換為已知的先驗分布,并使用相應的反向SDE緩慢地去除噪聲將先驗分布轉換回數據分布。至關重要的是,反向SDE僅取決于擾動數據分布的時間相關梯度場[25],也稱為分數函數。為方便表述,本文將基于分數的SDE稱為基于分數匹配的生成模型。
2.2 基于分數匹配生成模型的無透鏡成像方法
如圖2所示,生成模型可以簡單地概括為用概率分布方式描述圖像的生成,通過對概率分布采樣產生數據。圖2右邊是一個訓練數據集,里面所有的數據都是從某個數據pdata中獨立同分布取出的隨機樣本。左邊是其生成模型(即概率分布),在這種概率分布中,找出一個分布pθ使得它離pdata的距離最近。接著在pθ上采新的樣本,可以獲得源源不斷的新數據。通常,使用分數函數(概率密度函數對數的導數)來表示概率分布,稱為分數匹配的生成模型。相比概率密度函數模型,它沒有歸一化的要求,因而模型選擇更加靈活。
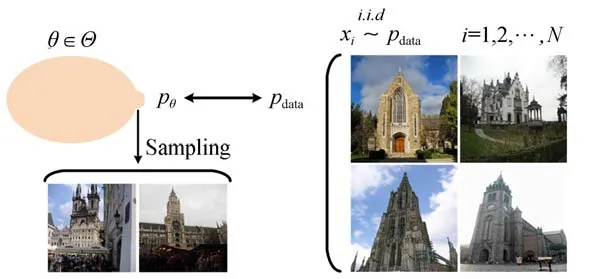
圖2 生成模型Fig.2 Generative model
基于分數匹配的生成模型是一種通過優化以θ參數化的分數網絡Sθ(x)來估計數據分布的分數函數的方法。用多個噪聲尺度對數據進行擾動是分數匹配生成模型方法成功的關鍵。它定義了一個正向擴散過程(即SDE),用于將數據轉換為噪聲并通過其逆向過程從噪聲中生成數據。如圖3所示,分數模型使用一個正向SDE通過添加高斯噪聲擾動數據分布,為了從數據分布中進行采樣,可以訓練一個神經網絡來估計對數數據分布的梯度(即?xlog pt(x)),并用它來數值求解逆時間SDE從噪聲中生成數據。
本文通過使用分數模型對目標圖像數據集進行訓練,將學習到的圖像先驗信息引入無透鏡成像逆問題,然后通過預測-校正采樣算法以實現高質量的無透鏡成像重建。
具體來說,訓練階段,通過將目標圖像數據集輸入基于分數匹配生成模型進行訓練。該模型使用SDE通過緩慢添加高斯噪聲擾動數據分布,然后使用方差爆炸(Variance Exploding,VE)-SDE的去噪分數匹配方法訓練了一個連續時間相關的分數函數Sθ(O)估計對數數據分布的梯度,即模型學習的梯度先驗?Olog pt(O),其中O為目標圖像數據集。測試階段,根據訓練的分數函數(即目標圖像先驗)和逆時間SDE數值求解器迭代更新重建目標圖像。在非相干光照明下由單張FZA調制的編碼圖像,通過訓練好的分數網絡先經過數值求解器SDE一次預測,再通過退火朗之萬方法在數值求解器SDE和數據保真項步驟之間輪換更新以實現編碼圖像的重建。基于分數匹配生成模型的無透鏡成像方法的訓練和重建算法將分別在2.3和2.4節展開介紹。

圖3 SDE的正向和反向過程Fig.3 Forward and reverse time process of SDE
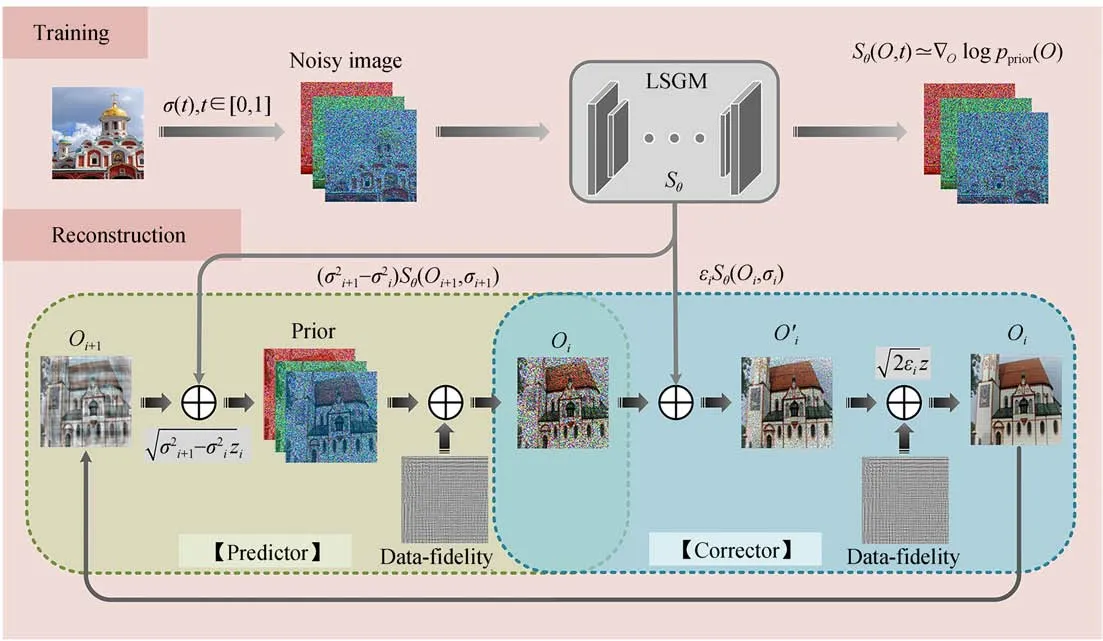
圖4 LSGM算法的訓練與重建流程圖Fig.4 Training and reconstruction flow chart of LSGM algorithm
2.3 基于分數匹配生成模型的訓練
圖4為LSGM算法的訓練與重建流程圖。本論文提出的LSGM方法的訓練過程如圖4上半部分所示。首先,模型構造了一個連續擴散過程其中,O(t)∈RNxy,t∈[0,T]是時間變量。正向過程是將數據分布O(0)通過隨機過程擾動得到含噪圖像O(T)。其中,O(0)~pdata,pdata表示目標圖像數據分布;O(T)~pT,pT表示先驗數據分布。那么,該隨機過程可以建模為求解以下SDE過程:
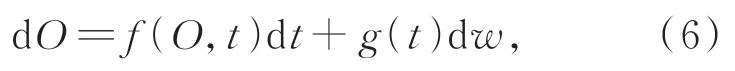
其中:f∈RNxy和g∈R分別是漂移系數和擴散系數,w∈RNxy是標準維納過程或稱布朗運動。
然后,通過求解逆時間SDE來重建編碼圖像。具體而言,從正向SDE訓練過程學習的目標相關的先驗信息O(T)~pT開始求解式(6)的逆向問題可以得到O(0)~pdata目標圖像,其中pT是一個包含pdata信息的非結構化先驗分布。那么,逆SDE過程為:
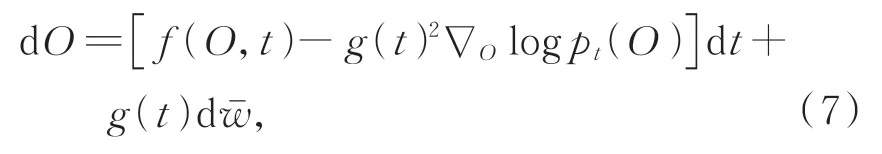
為了求解公式(7),需要已知所有t的分數函數?Olog pt(O(t))。通過訓練一個基于時間的評分網絡Sθ來匹配Sθ(O,t)??Olog pt(O(t))[26],然后將這個網絡函數替換式(7)中相應項。因此,通過對分數網絡的參數θ進行優化:
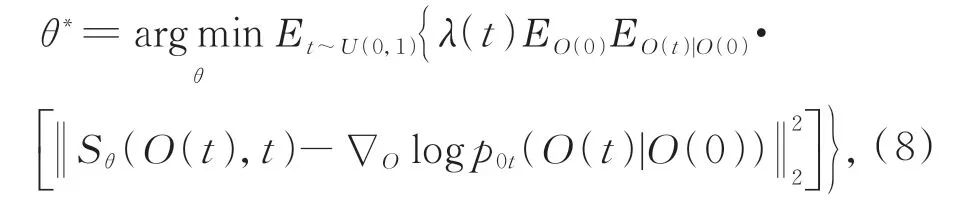
其中:E表示期 望,λ:[0,T]→R>0為正 權重函數,t在[0,T]上均勻采樣,p0t(O(t)|O(0))是以O(0)為中心的高斯擾動核,?Olog p0t(O(t)|O(0))表示擾動核的梯度,σ(t)是噪聲尺度的單調遞增函數。通過公式(8)訓練的網絡模型應當滿足Sθ(O,t)??Olog pt(O(t)), 這 意 味 著?Olog pt(O)對所有t都被訓練的Sθ(O,t)所知。因此,可以將其帶入逆時間SDE求解公式(7)并對其進行模擬以進行采樣。
2.4 基于分數匹配生成模型的重建
無透鏡成像問題歸結為求解方程(5),求解該逆問題的經典方法是轉化為優化以下約束問題:
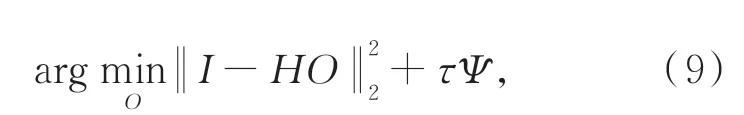
其中:Ψ是正則化項,τ是正則化系數。在求解上式時,通常使用變量分裂[27]或投影到凸集[28]等近似算法將先驗信息項和數據保項優化解耦,然后根據輪換求解思路在兩個子問題之間交替更新實現最優解:
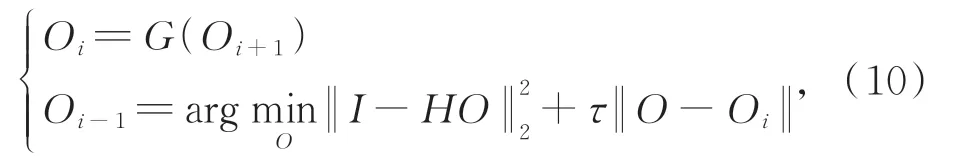
其中,第一個公式為生成;第二個公式的第一項是數據保真項,第二項是正則化項,τ是正則化系數。
根據貝葉斯最大后驗估計,如果生成模型能夠準確地從目標圖像數據集中估計復雜先驗數據分布,可以實現高質量的無透鏡成像重建。在2.3節中,詳細闡述了基于分數匹配生成模型的先驗學習過程。在上述訓練過程中,一旦訓練好分數網絡Sθ(O,t),并將其帶入公式(7)中,即可以求解逆時間VE-SDE,實現無透鏡編碼圖像重建:
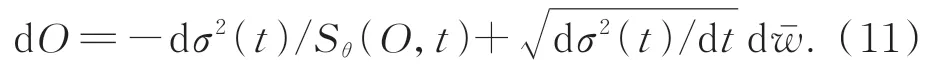
對于該過程的求解,可以使用歐拉離散化[22]求解VE-SDE的數值。為了校正離散化方向SDE演化中的錯誤,根據預測-校正的思想引入了一個預測-校正采樣器(Predictor-Corrector,PC)。基于分數匹配生成模型先通過數值求解逆時間VE-SDE從得到的目標圖像的先驗分布中獲得初步預測的重建圖像,然后通過使用退火朗之萬[29]作為校正器來校正這個初步預測結果。與此同時,在求解逆時間VE-SDE和退火朗之萬采樣時,每個無條件采樣更新步驟之后都需要進行一次保真。基于無透鏡成像的迭代重建算法如下:
預測:該預測器可以是逆時間VE-SDE的任意數值解算器,并具有固定的離散化策略。從目標圖像先驗分布中生成目標圖像可以通過求解由式(11)得到:
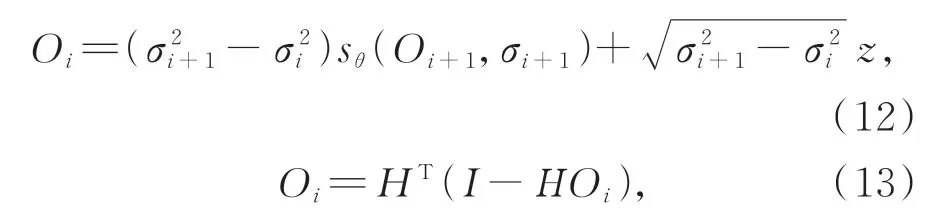
其中:σi噪聲尺度,i是總迭代次數,z是零均值的高斯白噪聲。式(13)稱為數據保真步驟,可以有效增強數據的一致性。式(12)和(13)即為該算法的預測過程。
校正:本文使用朗之萬馬可夫鏈[29]校正算法校正梯度上升方向,得到校正器步驟:
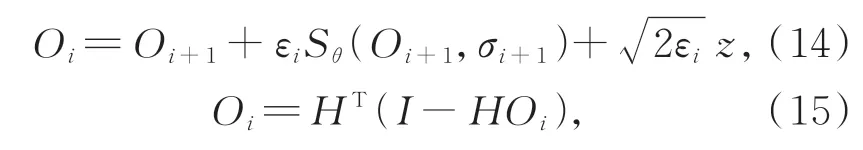
其中,εi是第i次迭代的步長。式(14)和(15)稱該算法的校正過程。
本文最終產生的LSGM的重建算法的偽代碼如算法1所示。LSGM重建過程包含兩層循環:(1)外層循環次數為逆時間VE-SDE的離散化步驟數,無透鏡編碼圖像輸入網絡先進行一次預測,再進入內層循環校正;(2)內層循環的校正過程是通過退火朗之萬迭代1 000次。整個循環迭代過程中,每一次循環均對預測和校正過程的數據先驗項和數據保真項進行更新,經過1 000次的迭代實現無透鏡成像重建。
圖4下半部分展示了本文提出的LSGM算法的重建流程圖。在訓練過程,利用生成模型對隨機樣本訓練估計數據分布的梯度先驗;在重建過程,先利用訓練的梯度先驗進行一次預測,然后再利用退火朗之萬方法迭代進行校正,并且在每一次迭代完成,都會在預測和校正步驟之后對數據保真項和先驗項進行更新,以保證實現最優求解。

Algorithm 1 LSGM Training Dataset:Object image dataset Output:Sθ(O,t)??O log pt(O)Reconstruction Setting:Score network Sθ,Noise iteration step{εi},Noise scale{σi},Number of discretization steps for the reverse-time SDE N,Number of corrector steps M 1:ON~N(0,σ2max I)2:For i=N-1 to 0 do(Outer loop)3:Update Oi via Eq.(12)and(13) 【Predictor】4:For j=1 to M do(Inner loop)5: Update Oi via Eq.(14)and(15)【Corrector】6:End for 7:End for 8:Return O0
3 實驗結果及分析
在本章節中,接下來的實驗將從定性和定量兩方面對本文提出的方法進行評估。
3.1 數據集和模型訓練
由于目前還沒有用于無透鏡編碼成像的公共數據集,本實驗所做的訓練和測試均在LSUN數據集上進行。LSUN數據集是一個大型的彩色圖像數據集,包含10個場景類別和20個對象類別,每個類別包含約100萬幅標記圖像。主要選取其中兩個子數據集:室內場景LSUN-bedroom和教堂LSUN-church數據集,分別觀察網絡模型在兩不同訓練集上的訓練和測試效果。
具體地說,使用LSUN官方網站給出的用于訓練的bedroom和church數據集分別訓練,圖像設置大小為256×256,其像素值均縮放至[0,1]之間。使用噪聲數值范圍為0.01~380的高斯噪聲擾動數據分布。同時,為規避數值問題,參數設置ε=10-5,信噪比為0.16。將梯度裁剪的最大值設為1.0,參數采用指數移動平均,流速為0.999,每種數據集訓練50萬次。此外,為了進一步驗證LSGM網絡的性能表現,在每個數據集中選取100張圖做測試。在PC采樣算法重建中的內外層循環迭代次數分別為N=1 000、M=1,每張圖迭代1 000次,取最大的峰值信噪比及其相應的結構相似性值,然后對這100對數據取平均。基于仿真實驗使用固定學習率0.000 01,優化采用自適應估計方法(Adaptive Moment Estimation,Adam),其中β1=0.9,β2=0.999。
3.2 評價方法
由于人眼的視覺特性,經常出現評價結果與人的主觀感覺不一致的情況。為有效定量評價本文的實驗,主要使用以下幾個指標來評估重建質量:
峰值信噪比(Peak Signal to Noise Ratio,PSNR,IPSNR)是基于對應像素點間的誤差,單位為dB。該指標是基于誤差敏感的圖像質量評價,數值越大表示失真越小。它是使用最為廣泛的一種圖像客觀評價指標,定義如下:
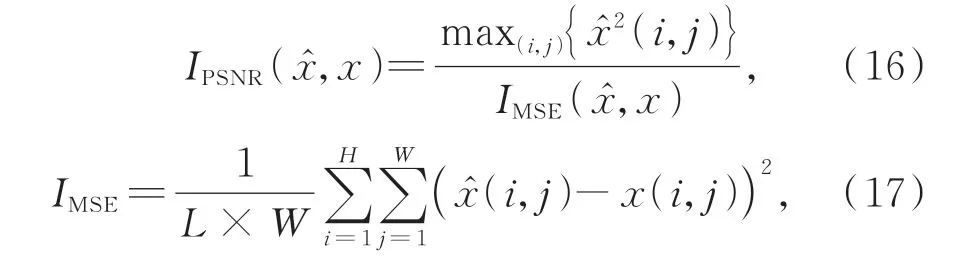
結構相似性(Structural SIMilarity,SSIM,ISSIM):是一種衡量兩幅圖像結構上相似程度的指標,它分別從寬度、對比度、結構三方面度量圖像之間的相似性:
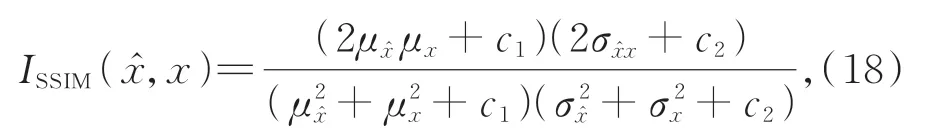
其中:μ和μx分別表示目標圖像和重建圖像的均值,σ和σx分別表示目標圖像和重建圖像的方差,σ表示圖像的協方差,c1和c2是用于保持穩定的常數。結構相似性的取值范圍是[0,1],其值越大,表示圖像失真越小,越能被人眼所接受。
3.3 實驗設置及環境
本實驗的模擬仿真實驗參數設置具體如下:FZA作為編碼掩膜放置在圖像傳感器3 mm處,目標大小為15 mm×15 mm,置于距離編碼掩膜20 mm處,掩膜板最內側區域半徑r1=0.23 mm。模擬傳感器的像素數為256×256,像素間距為0.014μm。傳感器上每個像素探測器記錄的是編碼掩膜上多個孔徑所成圖像的一個疊加,即來自場景中多個位置入射光場的疊加。
軟件仿真環境為:實驗使用基于PyTorch的深度學習框架,在一張2080 TI的GPU上進行LSGM算法的訓練和測試。為了更好地體現算法的可重復性,我們將代碼公開在網址:https://github.com/yqx7150/LSGM.

圖5 LSUN-bedroom數據集上重建圖像的視覺比較Fig.5 Visual comparison of reconstruction images on the LSUN-bedroom dataset
3.4 實驗結果
3.4.1 LSUN-bedroom數據集上的實驗結果及分析
近年來,隨著數據量的急劇增長和計算能力的不斷提高,基于分數匹配生成模型的成像方法已經被應用于磁共振成像[30]和CT成像重建[31],然而尚未應用于無透鏡成像。為證明本實驗的有效性,本實驗挑選了傳統的BP算法和目前實驗結果較好的CS算法[16]作為對比算法。
為從視覺上比較,圖5從LSUN-bedroom數據集中挑選出四組不同實驗結果進行展示,其中每組實驗結果包含原圖、編碼圖和BP、CS、LSGM算法重建的圖。可以很直觀地看出,BP算法實驗結果最差,可以觀察到很明顯的孿生像效應。其次,CS算法的重建結果與原圖對比,存在明顯的顏色差異,而且其圖片清晰度存在很大差距。例如,在第二行和第三行中CS重建結果與原始圖像有很明顯的顏色差距,中間有很明顯的顏色擴散以及圖片邊緣黑色區域變色現象。顯然,圖5中第五列的圖像質量明顯優于另外兩組結果,三種算法中LSGM的重建結果最優。
為進一步進行定量分析,三個算法的平均PSNR和SSIM值如表1所示。從表中分析可知,傳統的BP算法的平均PSNR值僅為7.78 dB。相比之下,其余兩種算法通過迭代的方式可以獲得更好的結果。對比表中數據,CS和LSGM的PSNR值分別比BP算法高10.69 dB、18.32 dB。本文提出的LSGM算法具有最優的成像質量,在迭代校正之后,其PSNR值 為26.10 dB、SSIM值 能 達 到0.64,比CS算法 的PSNR和SSIM分 別 高 出7.63 dB和0.33。
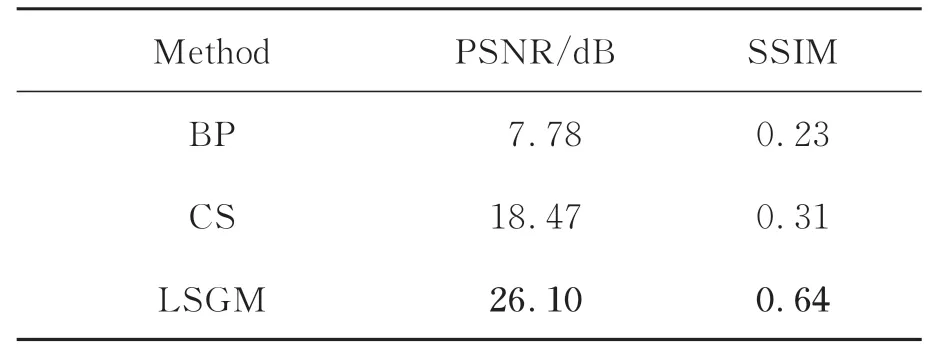
表1 LSUN-bedroom數據集上測試結果Tab.1 Test results on LSUN-bedroom dataset
3.4.2 LSUN-church數據集上的實驗結果及分析
為了更好地驗證LSGM方法的魯棒性,本實驗還選取了另一個圖像灰度、亮度和結構變化更豐富的LSUN-church(256×256)數據集進行實驗。在使用LSUN-church數據集對LSGM模型訓練完成之后,選取其中100張圖像作為測試輸入。
圖6展示了BP、CS和本文所提出的LSGM三種算法在LSUN-church數據集上重建圖像的視覺比較。和上小節實驗相同,本實驗展示了四組不同的重建圖像,每組包含原圖、編碼圖和BP、CS、LSGM算法重建結果。與在LSUN-bedroom數據集上的實驗結果相似,BP算法重建結果最差;CS算法重建的圖像上總是會有與圖片不相關的顏色出現。例如,圖6中第一、二和四行的CS重建結果中能觀察到明顯的紫色和綠色孿生像,尤其是圖片中間區域和邊緣黑色區域更為明顯。雖然CS算法重建結果并不影響圖像的辨識,但圖像質量仍然較模糊。對比圖6中第三行的CS和LSGM算法重建結果,可發現LSGM算法具有更高的清晰度。根據圖6中給出對應的PSNR和SSIM,LSGM算法重建的定量評價指標也是最高的,LSGM的PSNR和SSIM比CS算法分別提高6.68 dB和0.36。整體對比圖6中各組重建結果,最后一列圖像不論在圖像顏色、亮度和清晰度上都優于第三列和第四列。因此,LSGM算法是表現最好的,它在保證顏色的同時,還能清晰地重建出圖像細節,更加接近原始圖像。
定量對比表2中PSNR和SSIM兩項指標數據,在 三 個 算 法 中,LSGM的PSNR和SSIM值最高,在該實驗數據集上的平均PSNR值接近于LSUN-bedroom數據集上的結果。在更換成一個灰度、亮度和結構變化更為豐富的數據集后,BP算法重建記錄的評價指標幾乎不變。CS算法的PSNR值下降了0.68 dB,而SSIM值下降0.02。整體分析,本文提出的LSGM基算法在兩項指標上均表現得相對穩定且最好,PSNR值最高達到24.47 dB、SSIM值達到0.65。相對BP和CS算法,LSGM算法的平均PSNR值依舊分別提高16.66 dB和6.68 dB,平均SSIM值分別提高0.43和0.36。因此,本文提出的方法重建圖像最好,不僅能夠在保持顏色、亮度和清晰度的同時,還能顯著去除孿生像的偽影噪聲。
綜合上述兩組實驗結果可以得出結論,在不同數據集上,與BP算法、CS算法相比,LSGM方法都能達到更高的重建質量,模型性能更加穩定。
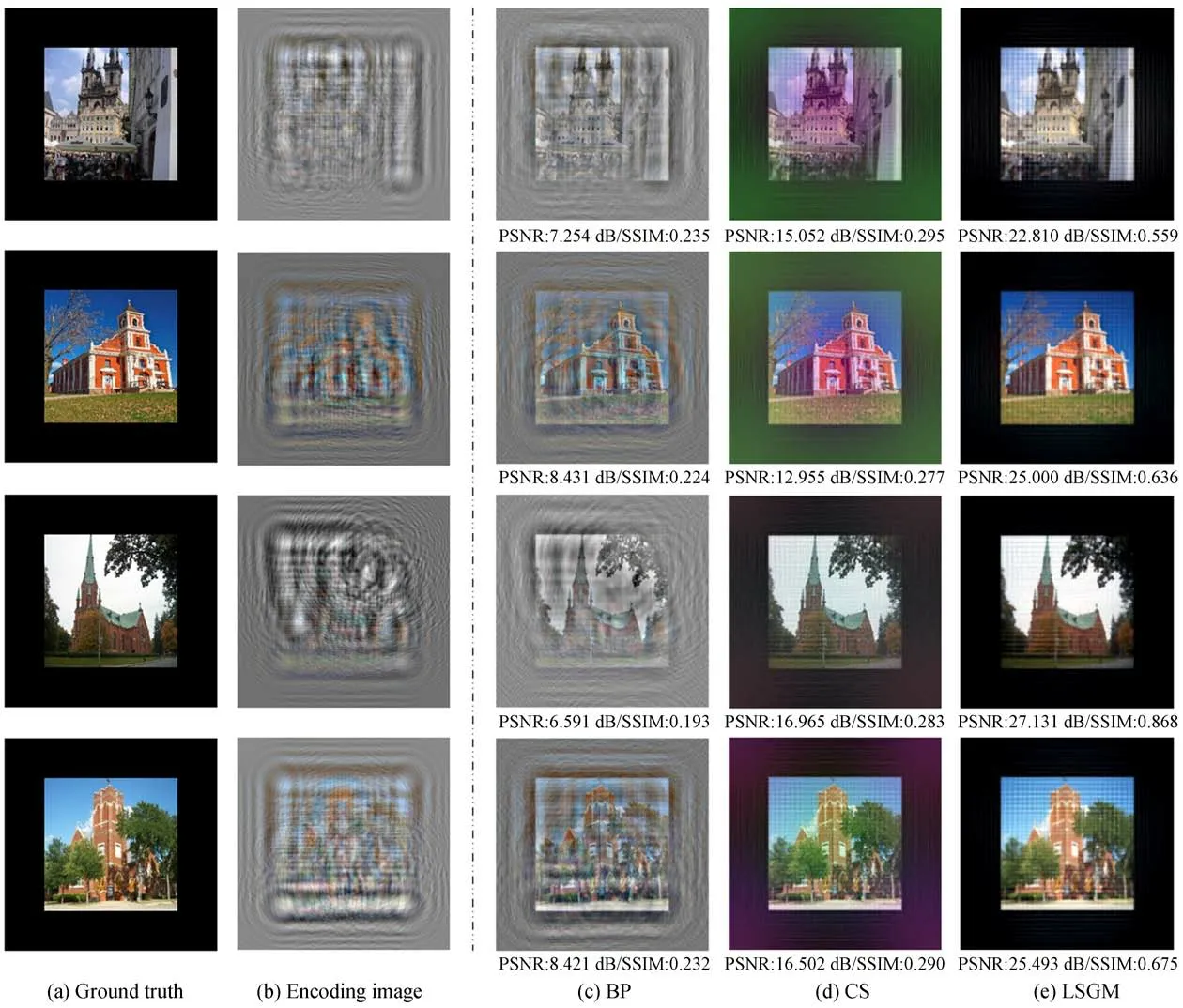
圖6 LSUN-church數據集上重建圖像的視覺比較Fig.6 Visual comparison of reconstruction images on the LSUN-church dataset
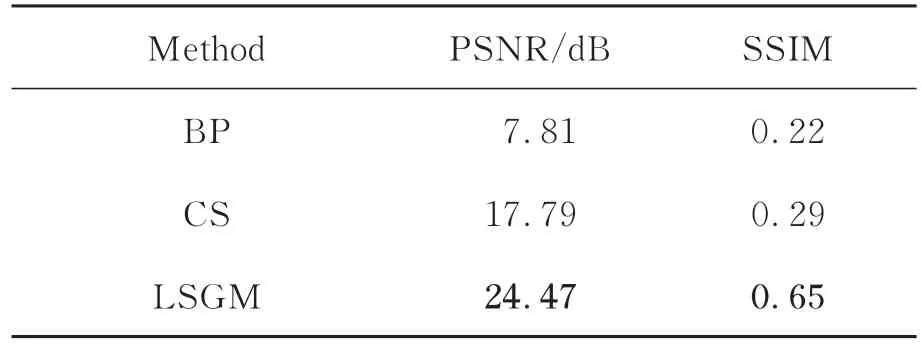
表2 LSUN-church數據集測試結果Tab.2 Test results on LSUN-church dataset
3.4.3 TV去網格效應
由于無透鏡成像本身特性,重建圖像存在很明顯的“網格”現象,重建圖像和原始圖像存在一定差距,在圖像紋理細節部分的恢復結果仍然不夠理想。為了解決這個問題,本文將基于變分理論的TV方法應用于重建過程。該方法是依靠梯度下降流對圖像進行平滑,希望在圖像內部盡可能對圖像進行平滑(相鄰像素的差值較小),而在圖像邊緣(圖像輪廓)盡可能不去平滑。前兩個實驗證明了本文提出的LSGM模型生成的先驗信息作為正則化項求解無透鏡成像逆問題,并取得了較好的數值結果。圖7展示了使用及不使用TV方法的LSGM算法的重建結果以及原始圖像。從圖7(c)可以看出,結合了TV方法的重建圖像中“網格”效應更為平滑,視覺效果更令人舒適,但其相應代價是失去了圖像中的部分高頻信息。由兩種方法重建結果的定量指標可以得出,提出的LSGM算法比不使用TV方法的LSGM算法的PSNR和SSIM值分別平均提高0.80 dB和0.10。

圖7 使用TV方法的LSGM算法對視覺效果的提升Fig.7 Improvement of visual effects by LSGM algorithm with TV method
4 討 論
4.1 消融實驗
上述實驗表明,本文提出的LSGM方法能夠實現高質量的無透鏡成像結果。然而,使用基于分數匹配生成模型進行圖像重建時,迭代式重建方法在耗時方面有著明顯的局限性。為了更好地驗證LSGM模型的性能,本實驗探究了在不同σmax下的圖像質量和離散化步驟數之間的關系。
如圖8所示,本實驗選取了LSUN-church數據集對測試需要的離散化步驟數與圖像質量之間的關系進行實驗驗證。當訓練階段使用N=1 000個離散化步驟來進行正向SDE,重建階段使用N=1 000個離散化步驟時,需要大約10 min的推理時間。從N=1到N=1 000每隔1個離散化步驟記錄重建圖像的PSNR以及SSIM。可以觀察到隨著離散化步驟的增加,重建圖像PSNR以及SSIM呈現一定的規律性。在N=700的情況下,可以實現高質量的重建圖像,PSNR以及SSIM達到最高值。當離散化步驟數逐漸增加,PSNR值趨于穩定,SSIM會下降。由于在不同σmax下,PSNR隨著離散步驟數增加,將趨向于穩定,并且穩定值在24 dB左右,而SSIM波動較大,所以本文選取當PSNR達到穩定值下的離散步驟數來進行所有實驗。在之后的工作中,我們將嘗試使用去噪擴散模型(DDPM)[32]來進一步減少離散化步驟數。
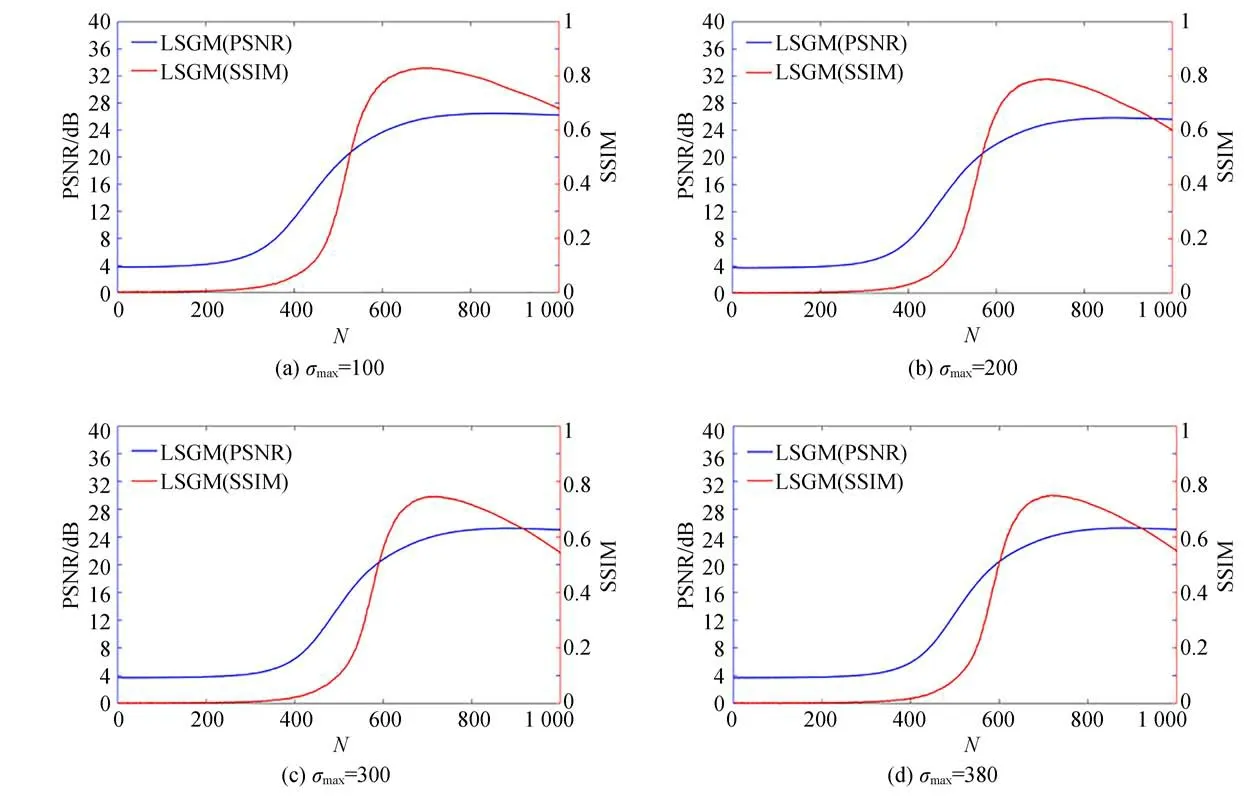
圖8 不同σmax下的圖像質量和離散化步驟數關系的消融實驗Fig.8 Ablation experiments on the relationship between image quality and discretization steps under differentσmax
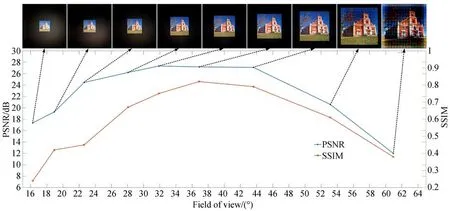
圖9 視場角測試實驗Fig.9 Experimental test of field of view
4.2 成像視場分析
如圖9所示,為測試視場角對本文提出算法的影響,進一步分析了不同視場角下重建圖像的PSNR和SSIM指 標。在 本 組 實 驗 中,FZA的 參數與前文一致,在保持目標尺寸不變的情況下,通過改變目標物與FZA掩膜間的距離來實現不同視場角。從圖9所示結果可以看出,隨著視場角的增大,PSNR的值先增大后減小,隨著目標圖像的增大,邊界處部分衍射信息丟失,造成圖像重建質量的惡化。當視場角在32°~46°范圍內,相應的PSNR的值可達到26~28 dB、SSIM的值為0.85~0.68,可以實現最好的成像效果。
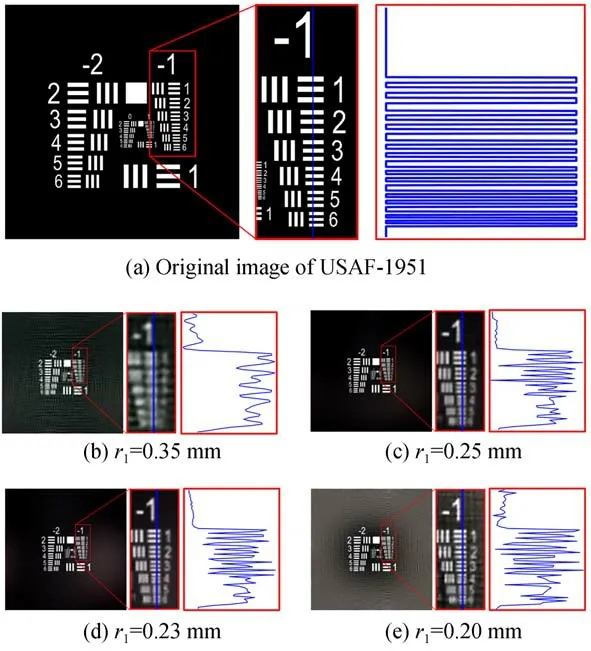
圖10 分辨率測試實驗Fig.10 Experimental test of the resolution
4.3 成像分辨率分析
受制于工藝制造水平,傳感器和FZA掩膜的像元尺寸不能無限小,系統重建的帶寬有限。為了驗證提出算法能實現的最小分辨率,本文采用一張尺寸為20 cm×20 cm、像素數為1 280×1 280的USAF-1951測試圖像進行測試,該成像目標與FZA距離為267 mm,成像視場角為41.11°。由于本文訓練模型中傳感器的像素數為256×256,為了適應本文算法,將USAF-1951原圖經過FZA調制后的結果進行像素歸并至像素數為256×256,以得到測量結果。
圖 像 重 建 結 果 如 圖10所 示,圖10(a)為USAF-1951測試卡原圖、-1組線對的細節以及相應的剖線。為了測試不同FZA參數r1對結果 的 影 響,本 文 在r1分 別 為0.35、0.25、0.23、0.20 mm時進行了重建。可以很明顯看出,r1=0.35 mm時,難以分辨-1組線對。隨著r1參數的減少,圖像分辨率得到有效提高,當r1減小到0.23 mm及0.20 mm時,能夠有效分辨出-1組4號 線 對。
5 結 論
本文提出了一種基于分數匹配生成模型框架的無透鏡成像方法,即LSGM。該模型利用數據分布梯度對圖像進行建模,并從給定的觀測數據的條件分布中采樣數據,然后將采樣的數據作為圖像先驗數據用于圖像重建。所提出的LSGM算法在計算重建過程中能夠有效消除無透鏡成像系統固有的病態性而帶來的孿生像偽影噪聲及其他影響成像的不良影響,使得成像質量大幅提高。在LSUN-bedroom和LSUNchurch數據集上測試結果表明,本文提出的方法和其他傳統算法相比,LSGM算法圖像重建的平均PSNR值和平均SSIM值分別達到25.23 dB和0.65,量化指標以及視覺質量均獲得了令人滿意的結果。本文提出的模型框架結構靈活,訓練穩定,在建模數據分布方面的性能表現出色,能夠獲得高質量樣本。本文通過大量的實驗驗證了該方法在質量和實用性方面的優越性,有望應用于其他計算成像領域。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
