基于深度學習模型的以圖搜圖技術在新華社供稿服務中的創新應用
2022-11-01 04:55:24熊立波
中國傳媒科技 2022年10期
熊立波
(新華通訊社技術局,北京 100083)
1.背景
新興媒體時代將成為受眾與用戶“按需消費”的時代,只要用戶提需求,媒體就應想盡辦法回應和滿足。[1]新華全媒新聞服務平臺作為新華社供稿平臺為全球新聞機構提供新華社全媒體內容供稿服務。
不少圖片用戶是在互聯網上看到圖片后再從新華全媒體平臺搜索并下載授權的高清圖片,但往往由于文字又不能準確表述而無法快速搜索到所需的圖片,用戶對用圖片直接搜索圖片的需求很大。如何為用戶提供方便準確的圖片搜索服務是一個需要不斷研究的課題。
2.“新華全媒”新聞服務平臺
“新華全媒”新聞服務平臺項目是新華社供稿線路優化調整的重要工程,基于云計算、互聯網統一技術架構,重構新華社轉型發展時期供稿技術體系,建成了包括所有新華社文字、圖片、圖表、視頻、新媒體、多媒體、歷史資料和第三方產品的全媒體供稿平臺,著力提升新興媒體供稿能力,整合傳統供稿線路資源,提升用戶使用體驗,滿足用戶需求。
3.以圖搜圖技術路線
以圖搜圖,是通過搜索圖像文本或者視覺特征,為用戶提供相關圖形圖像資料檢索服務的專業搜索引擎系統[2],是搜索引擎的一種細分,目前主要有如下2種實現方式。
(1)通過提取的圖片描述信息。使用程序直接提取描述圖片的關鍵字,使用關鍵字來進行檢索。
(2)通過識別輸入的圖片的特征。提取圖片的特征值,使用特征值進行相似圖片的檢索。
提取圖片的信息主要有以下3類。
(1)圖片內嵌描述信息。提取圖片內嵌的EXIF[3]或IPTC[4]等信息進行檢索,這是目前圖像搜索引擎采用最多的方法,但是搜索準確性比較低。
(2)圖片內容特征信息。人工對圖像的內容(如物體、背景、顏色特征等)進行描述并分類,給出描述詞。檢索時,將主要在這些描述詞中搜索檢索詞。這種查詢方式一般來講可以獲得較好的查準率。但需人工直接參與,勞動強度比較大,限制了可處理的圖像數量,而且需要預先指定規范和標準,搜索的準確率很大部分取決于人工描述的精確度和一致性。
(3)圖片屬性特征信息。通過算法自動抽取圖像的顏色、形狀、紋理等屬性特征,建立特征索引庫。優點是算法簡單,可以使用機器批量處理大量圖片,搜索原圖比較準確,能較快地應用到實際項目中,但是由于圖片屬性相似的圖片內容不一定相似,所以對“相似”圖片的檢索結果不理想。
基于圖形內嵌描述信息的方法從本質還是文字搜索,如果用戶提交的圖片是截圖等經過處理的圖片,本身就沒有內嵌的描述信息,將無法搜索到結果。
基于圖像色度、亮度等物理屬性特征比對圖片的相似度,算法意義上的相似度很高的圖片但是在內容上確可能沒有任何業務的“相似性”。
基于圖像內容特征描述搜索效果雖然好但是需要依賴大量的人工預標注。新華全媒平臺有超過千萬張歷史圖片,并且圖片每時每刻都在新增,如果要對每張圖片都進行人工標注是不現實的。隨著人工智能技術的不斷進步,基于深度學習算法可以從數據中自動挖掘統計規律,學出計算模型。[5]可以使用人工智能算法學習出計算模型,對圖片進行自動分類而代替人工標注,達到更好的圖片搜索準確度。
4.以圖搜圖算法的實現
為了對比搜索的準確性,本文構建了基于離散余弦變換(DCT,Discrete Cosine Transform)和基于深度學習算法2種搜圖方案進行對比測試。
4.1 基于離散余弦算法的實現
對比物品與物品之間的相似性所應用的方法通常為余弦相似性等方法。[6]離散余弦變換(DCT,Discrete Cosine Transform),是一種圖像壓縮算法,使用離散余弦變換來獲取圖片中的低頻成分[7],它將圖像從像素域變換到頻率域。可以利用這一點,將圖片進行頻域化后再進行相似性搜索,實現基于圖像屬性特征抽取的搜索。
4.2 基于深度學習算法的實現

圖1 VGG16學習模型[8]
VGG-16 是視覺幾何組(Visual Geometry Group)開發的卷積神經網絡結構,該深度學習神經網絡贏得了ILSVR(ImageNet)2014的定位任務冠軍[9],時至今日,VGG仍是一個經典和杰出的視覺模型。該結構有13個卷積層,3個全鏈接層,一共有16層。
ImageNet 超過1400萬的圖像被ImageNet手動注釋[10],包含2萬多個類別[11],,每個類別包含數百張圖片。[12]本文使用ImageNet的vggVGG-信息,實現圖像內容特征提取的以圖搜圖。
本文基于Keras[13]深度學習框架,使用Python,keras,TensorFlow,Flask構建以圖搜圖服務。
Python中有很多應用于科學計算、數據可視化、機器學習的擴展庫,例如NumPy,keras等,涉及的領域包括數值計算、符號計算、二維圖表、三維數據可視化、數據分析建模等。
Keras是用Python開發的崇尚極簡高度模塊化的神經網絡庫,優點是可以同時運行在TensorFlow和Theano這2個主流的深度機器學習庫上,同時可以方便的在CPU和GPU之間切換。為以圖搜圖提供調度深度學習算法。
TensorFlow是Google開發的深度機器學習庫,核心代碼是C++編輯,同時提供Python,Go,Java等接口。為以圖搜圖提供深度學習支持。
Flask是Python開發的微服務框架,依賴Jinja2模板引擎和Werkzeug WSGI服務。為以圖搜圖提供http的查詢和檢索服務。
4.3 流程設計

圖2 搜圖算法設計
圖片內容特征預提取。圖片通過使用ImageNet的VGG16預訓練模型,提取圖片的特征向量值并存儲到特征向量數組中。
用戶上傳圖片的特征提取。接收用戶上傳的圖片,圖片通過使用ImageNet的VGG16預訓練模型,提取圖片的特征向量值。
特征向量比較搜索。將用戶上傳圖片提取的特征向量和特征數組中所有圖片的特征向量進行逐一比較,返回距離(歐式距離,Euclidean distance[14])最小前N張圖片。
4.4 性能測試
經測試,以圖搜圖服務部署在單臺PC服務器(2c,16GB)對100萬張圖片進行并發搜索,可以提供可靠的以圖搜圖查詢服務,支持20個并發用戶訪問不報錯,200個并發用戶訪問不down機,并支持分布式部署和線性擴展。
4.5 搜索結果準確性測試
4.5.1 搜索對比測試
為了測試搜索結果的準確性,本文隨機從新華全媒平臺歷史圖片庫中挑選了3萬張歷史新聞圖片,對2種算法的實現進行搜索測試。選取了“人物”,“動物”,“植物”等不同場景的圖片,并對測試圖片進行“亮度增強”“灰度”“添加水印”等變形操作,每次提交圖片搜索返回前30張圖片結果。
圖3 和 圖4分 別 是ImageNet VGG-16和DCT實 現的以圖搜圖返回的結果,從搜索結果可以看出,2個搜索結果都能搜索到原圖(左上角第一個圖片),ImageNetVGG-16方案返回的結果中,除了原圖,其他的圖片也是和油菜花或者黃色的花有關的圖片,但是DCT方案返回的其他圖片和原圖基本沒有業務相關性。

圖3 ImageNet_VGG16返回結果

圖4 DCT返回結果
4.5.2 評分設計
“原圖”:搜索到原圖打100分,未搜索到給0分;
“相關圖”:搜索到的除“原圖”圖片外的其他圖片和被搜索圖片相似度,每一張相似圖片滿分給3.3分。
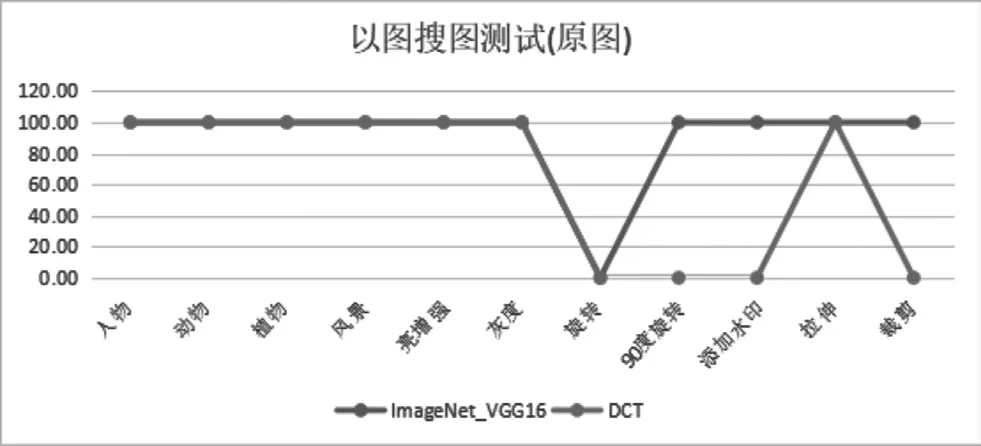
圖5 兩種搜索算法搜圖原圖準確性
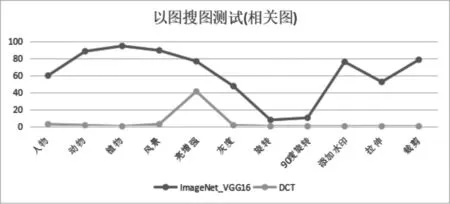
圖6 兩種搜索算法搜圖相關圖準確性
從上圖測試結果來看,基于深度學習算法的ImageNet VGG-16在原圖搜索中,除了對圖片旋轉后的由于圖片內容識別上存在誤差,導致沒有搜索到原圖,其他組都拿到了100分滿分。在相關圖片推薦測試中,同樣對旋轉后的圖片識別率較低,其他組的搜索得分都比較高。
對基于DCT算法的測試結果可以看到,DCT對原圖的搜索結果還是讓人滿意的,同樣對應旋轉后的圖片無法搜索到,但是對相關圖片搜索效果比較差,說明搜索到的圖片除了原圖,其他搜索到的圖片都是與被搜索圖片無關的圖片。
從上面的測試可以得出:基于深度學習方案實現的搜圖方案準確性要明顯好于基于離散余弦算法實現的搜圖方案。
5.以圖搜圖服務在新華全媒新聞服務平臺上的實現
5.1 需求分析和設計
5.1.1 用戶上傳圖片
需求點:為用戶提供圖片上傳的功能。
設計:以圖搜圖作為一個獨立功能模塊和新華全媒新聞服務平臺進行集成,用戶在系統中提交需要搜索的圖片,以圖搜圖系統獲取圖片,對已經索引的歷史圖片進行搜索和比對,返回搜索到圖片的結果,并將結果提交進行展示。
5.1.2 返回搜索結果
需求點:通過列表或網格的方式為用戶展現搜索結果。
設計:由于所有稿件都有唯一稿號,以圖搜圖系統將搜索到的稿件以稿號列表形式返回,新華全媒新聞服務平臺對所有稿件進行列表展示。
5.1.3 數據庫及數據存儲需求分析和設計
需求點:可以搜索到6個月圖片稿件的搜索功能。
設計:以圖搜圖模塊只需要返回搜索到的稿號,所以僅僅需要存儲每個圖片的索引結果,每個圖片無論大小,索引文件大小為固定為17K,半年的圖片50萬張,額外的所需空間約為9GB。
5.2 系統架構設計
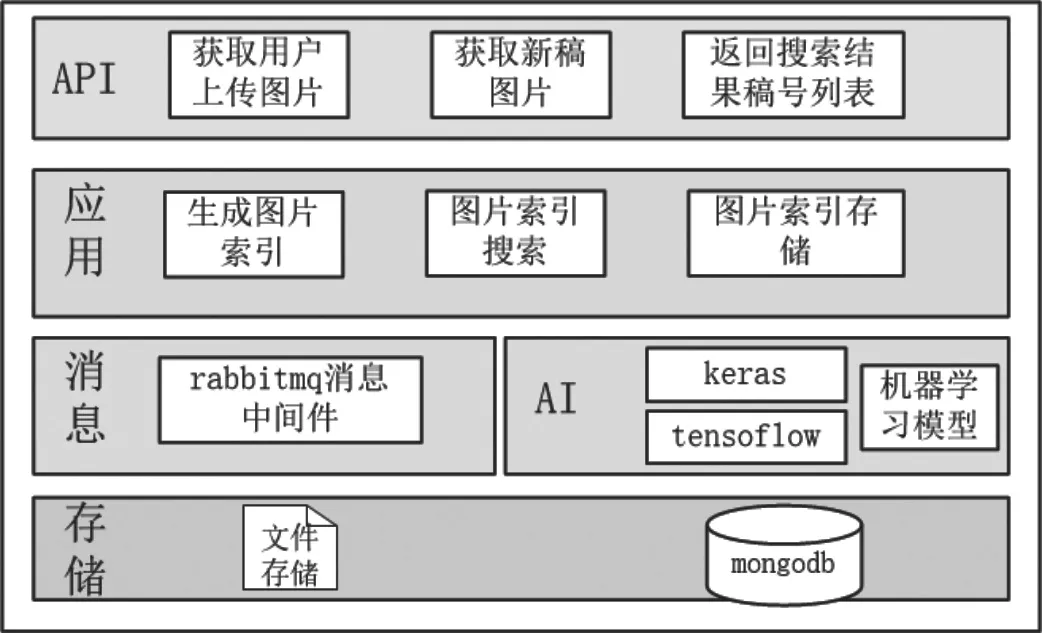
圖7 搜圖算法設計
5.2.1 API服務層
以圖搜圖對外提供基于http協議的微服務的接口層,主要包括獲取用戶上傳的圖片和返回搜索結果。
5.2.2 應用層
主要包括基于AI機器學習框架,生成圖片索引和進行相似圖片搜索,存儲生成的圖片索引。
5.2.3 消息層
為以圖搜圖提供統一消息路由服務。需要將所有的圖片通過消息層推送給圖片特征提取服務。
5.2.4 AI層
為以圖搜圖提供統一的機器學習模型服務。
5.2.5 存儲層
存儲中間數據和索引文件。
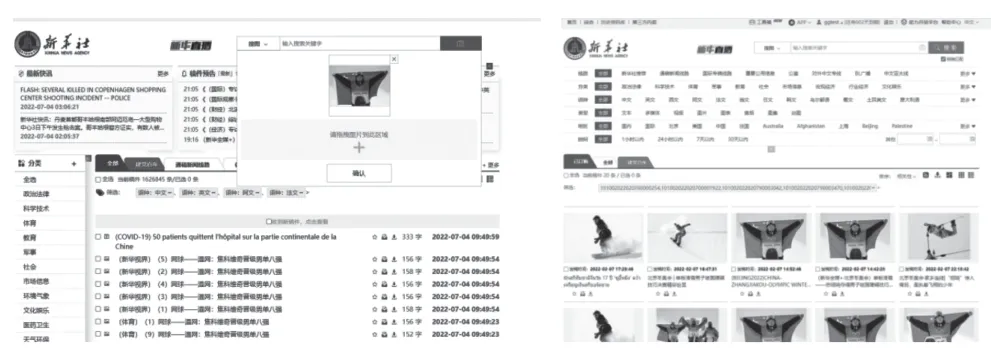
圖8 以圖搜圖服務在新華全媒平臺上的應用
基于深度學習模型的以圖搜圖服務在新華全媒新聞服務平臺上線后,為用戶提供了精準的圖片搜索服務,搜索到的其他圖片相似度也更高,是新華社供稿平臺首次為用戶提供以圖搜圖服務,受到了用戶的一致好評。
結語
通過對基于離散余弦算法DCT和基于深度學習VGG-16模型的以圖搜圖實現進行對比測試,得出基于深度學習模型的算法更優的結論。通過創新性應用到新華全媒新聞服務平臺的搜圖服務中,為用戶提供了更加精準的圖片搜索服務,得到了用戶的一致好評。下一步將繼續探索研究使用其他深度學習模型在以圖搜圖應用中的差異,以進一步提高圖片搜索的準確性。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
今日農業(2019年12期)2019-08-15 00:56:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
