雙通道深度主題特征提取的文章推薦模型①
2022-11-07 09:08:18井明強房愛蓮
計算機系統應用 2022年10期
井明強,房愛蓮
(華東師范大學 計算機科學與技術學院,上海 200062)
現在在線文章的數量已經非常龐大,而且每年都在急劇增加,根據NCSES 的統計,Scopus S&E 出版物數據庫的數據,2020年的出版物產量達到290 萬篇.過去4年(2017-2020年)以每年6%的速度增長,如何向用戶推薦他們喜歡并且適合他們的文章成為數字圖書館服務提供商面臨的一個關鍵問題.許多學術搜索網站在某一特定領域的信息頁面上提供文章推薦來幫助用戶查找相關文章.然而,這些建議往往是基于關鍵字的推薦,如周興美[1]提出的論文檢索系統,通過將文章的段落、語句、常用詞、關鍵詞、結構框架內容等檢索篩選、做出對比來推薦文章,這并不能個性化地向用戶推薦文章.
通常,一篇文章會涵蓋多個不同的主題,例如本文中,如關鍵字所示,包含: 個性化推薦、主題模型、文本相似度.不同背景和興趣的用戶可能更喜歡與不同主題相關的文章.個性化推薦如果不考慮用戶的多樣性,也不能滿足多數用戶.良好的個性化對于一個進行文章推薦的網站來說是一個挑戰,很多用戶都是冷啟動用戶,他們的個人資料并不完善,不能提供很多有用的信息.典型的方法是基于用戶反饋,然而用戶反饋可能非常稀疏.對于新用戶,只有來自同一會話的隱式反饋可用.因此很難利用傳統的推薦方法,如基于內容的推薦[2]或協同過濾[3]等.
文本相似度衡量在推薦系統和信息檢索領域中起著非常關鍵的作用,也是一個挑戰.大多數傳統方法都是基于詞袋模型,丟失了有關詞語順序以及上下文的信息.因此這些方法無法捕捉到短語、句子或更高級別的文意信息.近年來,詞嵌入和神經網絡在各個領域都得到了廣泛的應用,在自然語言處理領域也提出了許多可以直接處理詞序列的神經相似度計算模型[4,5],但它們經常不加區分的處理文章中的所有單詞,因此它們無法將文章的重要部分與文章的一些固定化表達(比如“我們發現”“這說明了”)區分開來.
為了應對這些挑戰,本文提出一個基于雙通道深度主題特征提取的文章推薦模型,將相關主題模型CTM[6]與預訓練模型BERT[7]相結合,文章經過預處理后,分別輸入到獨立的子模塊中進行高維信息抽取并計算相似性得分,結合個性化得分給出最終推薦.我們發現,在BERT 中添加相關主題信息,在3 個數據集上均有明顯提升,尤其是在特定領域的數據集上有優秀的表現.本文的主要貢獻有:
(1)提出了基于雙通道深度主題特征提取的文本相似度計算模型ctBERT,融合了相關主題模型CTM 和深度預訓練模型BERT 作為文本語義相似度預測工具.
(2)我們在不同來源和尺度上的數據集上進行實驗.實驗結果表明,我們的模型相比于其他的基線模型能有效提高性能.
1 文章個性化推薦系統
1.1 個性化推薦
個性化推薦系統旨在為特定用戶在給定的上下文中提供最合適的推薦項目,基于內容的方法[1]將項目描述和用戶的畫像文件進行比較,以得到推薦內容.經典的協同過濾方法[8]利用當前用戶或者與當前用戶類似的其他用戶的歷史行為數據進行預測.混合推薦方法[9]則結合了上述兩種方法的優點以提高建模精度.
杜政曉等人[10]將個性化文章推薦問題定義如定義1.

定義1.個性化文章推薦問題輸入: 查詢文章 ,候選集,與用戶相關的支撐集.u k R(dq,S)?D dqD={d1,d2,···,dN}u S={(images/BZ_326_1353_903_1375_933.pngdi,images/BZ_326_1384_910_1406_941.pngyi)}T{i=1}輸出: 一個為用戶 生成的前個完全排序的集合,其中.|R|=k
1.2 文本相似度
文本相似度是指通過某種方法獲得一個值來描述文本對象之間的相似度,如單詞、句子、文檔等.衡量兩篇文檔之間的相似度的傳統方法如BM25[11]和TFIDF[12]都是基于詞袋模型,這些方法通常將兩篇文章中匹配單詞的權重之和作為相似度分數,忽略了語義信息,所以在衡量短語和句子的匹配程度方面表現不佳.
基于神經網絡的方法可以大致分為兩種類型: 基于表示的模型和基于交互的模型.基于表示的代表模型有DSSM,LSTM-RNN 以及MV-LSTM 等,他們的主要思想是使用神經網絡獲取文章的語義表示,然后將兩篇文章的表示之間的相似性(通常是余弦相似性)作為相似性分數.然而這些模型通常缺乏識別特定匹配信號的能力.基于交互的模型通常是依賴于詞嵌入,使用神經網絡來學習兩篇文章的單詞級交互模式,比如DRMM 在單詞相似直方圖上使用多層感知器來獲得兩篇文章的相似度分數,其他的代表模型有MatchPyramid 以及K-NRM 等.這些模型主要依賴于單詞的嵌入,忽略了文章中的潛在主題信息.
1.3 相關主題模型CTM
主題模型的核心思想是以文本中所有字符作為支撐集的概率分布,表示該字符在該主題中出現的頻繁程度,即與該主題關聯性高的字符有更大概率出現.在文本擁有多個主題時每個主題的概率分布都包括所有字符,但一個字符在不同主題的概率分布中的取值是不同的,它可以發現隱藏在大規模文檔集中的主題結構.
相關主題模型(CTM)[6]是建立在Blei 等人[13]的潛在狄利克雷(LDA)模型之上,LDA 假設每個文檔的單詞都來自不同的主題,其中每個主題都有一個固定的詞匯表,文檔集合中的所有文檔均共享這些主題,但是文檔之間的主題比例會有不同的差異,因為他們是從狄利克雷分布中隨機抽取的.LDA 模型是一個典型的詞袋模型,無法直接對主題之間的相關性進行建模.CTM 用更靈活的邏輯正態分布取代了狄利克雷,該正態分布在組件之間包含協方差結構,這給出了一個更現實的潛在主題結構模型,其中一個潛在主題可能與另一個潛在主題相關.
1.4 單樣本學習
單樣本學習可以將分類任務轉化為差異評估問題,當深度學習模型針對單樣本學習模型進行調整的時候,它會獲取兩個目標并返回一個值,這個值顯示兩個目標之間的相似性,如果兩個目標有包含相同的特征,神經網絡則返回一個小于特定閾值(例如0)的值,如果兩個目標差異較大,返回的值將會高于閾值.單樣本學習目前主要被應用于圖像任務中,用于少量樣本情況下的圖片分類任務.它可以將在其他類中學到的知識建模為與模型參數有關的先驗概率函數.當給出一個新類的示例時,它可以更新知識并生成一個后驗密度來識別新的實例.
2 方法
2.1 基于單樣本學習的推薦框架
為了得到有序集R,我們的模型為候選集D中的每篇文章di計算了一個分數s(di|dq,S),然后選取D中獲得最高分數的前k篇文章作為top-k 推薦.針對特定用戶u的推薦問題可以看作用戶u是否接受這篇文章,以此將問題轉化為二分類問題,即對于支撐集S中的是二進制的(1 表示用戶接受該文章,0表示不接受).可以將S視為分類的訓練集,其中是訓練實例,是相應的標簽,由于前期用戶的交互數據非常少,S的規模很小甚至為空,我們將單樣本學習與我們的問題類比.受文獻[14]的啟發,我們的模型計算s(di|dq,S)的方式如下:
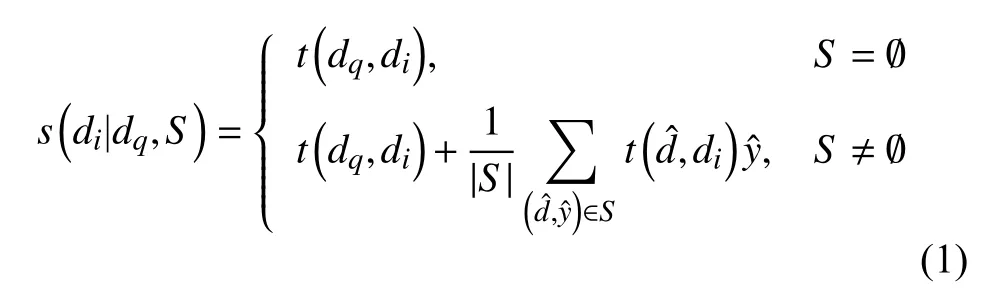
其中,t(·,·)是用于計算文本相似性的ctBERT 模型,將在下面的部分中討論.從式(1)中可以看出,s由兩部分組成,第1 部分是與查詢文章的相似度得分.第2 部分是個性化得分,是S中反饋的歸一化線性組合,以文本相似度為系數,S為空時等于0.整個推薦框架如圖1 所示.
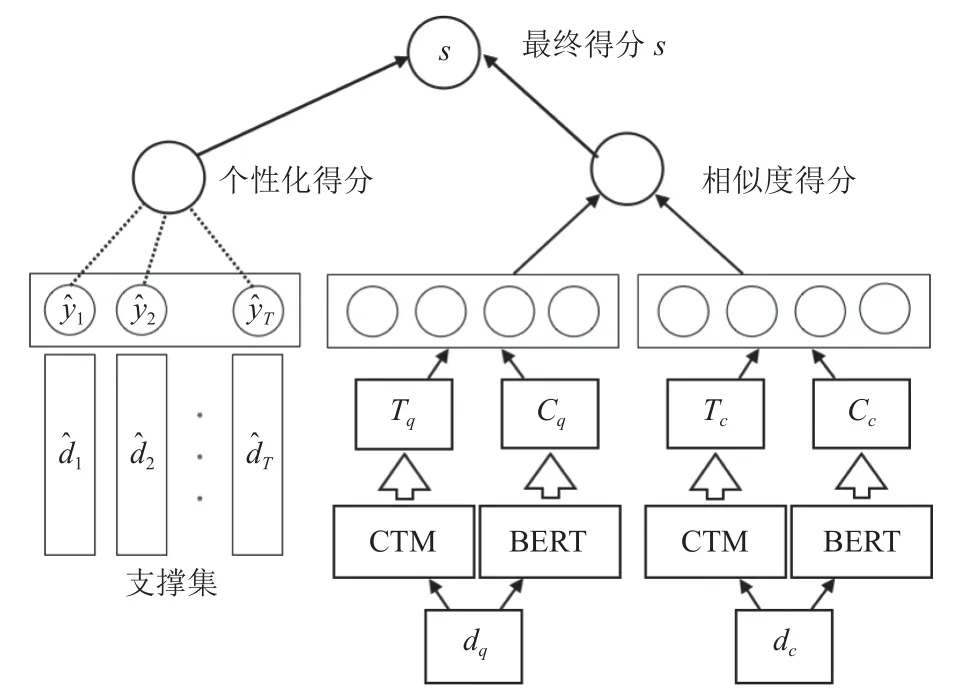
圖1 ctBERT 模型的整體架構
2.2 文本語義相似度得分計算
首先,需要對文章進行預處理,包括切詞、去除停用詞等.由于BERT 模型支持的最大輸入長度只有512,本文采用的方法是按固定長度進行截斷,即對于每篇文檔di,選取去除停用詞后的前512 個字作為輸入.為了提高性能和減少計算開銷,本文根據文獻[15]的啟發,采用了雙塔模型結構.通過獨立的子模塊進行高維信息抽取,再用抽取得到的特征向量的余弦距離來得到文本語義相似度得分.
對于查詢文檔dq和候選文檔dc,分別輸入BERT模型,這里的BERT 模型選用BERT-BASE,最終會得到BERT 最后一層[CLS]向量輸出,將其作為文檔的全局語義特征表示C,形式化如式(2):

關于主題模型部分,本文使用Bianchi 等人[16]的CTM 模型對文檔進行主題建模,使用Word2Vec 模型對詞向量進行訓練,其計算方式如式(3):

其中,x為所有詞匯的詞向量表征形式,v是詞匯字典中的詞匯總數,e(wi)為詞匯wi的詞向量表示形式.通過主題模型訓練結果,得到文檔d對應的主題分布,取概率最大的主題Tmax,在根據主題詞文件選擇主題Tmax下的前n個詞(t1,t2,···,tn)及其概率值(p1,p2,···,pn),將概率值歸一化處理作為n個詞語的權重信息,公式如式(4):

其中,qi表示pi歸一化后的值,(q1,q2,···,qn)即為前n個詞的權重大小.通過訓練好的Word2Vec 模型得到詞向量(e(t1),e(t2),···,e(tn)),再對其進行加權求和,得到主題擴展特征,公式如式(5):
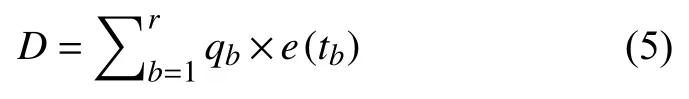
接下來,對全局語義特征表示C和主題擴展特征D進行組合以得到文檔向量與文檔主題表示相結合的表現形式:

對于查詢文檔和候選文檔的最終表示Fq和Fc,通過一個隱藏層統一長度,最后計算他們的余弦相似度得出相似度得分.
2.3 優化與訓練
整個模型在目標任務上進行端到端的訓練,我們將鉸鏈損失函數作為訓練的目標函數.給定三元組其中對于查詢文檔,的排名要高于,損失函數表達式為:t(dq,d)dqd

其中,表示查詢文章 和文章 的相似度得分.通過標準反向傳播和小批量隨機梯度下降法進行優化,同時采用隨機丟棄和早期停止策略避免過擬合.
3 實驗
在本節中,為了評估所提出的模型,我們在3 個數據集上對文章推薦問題進行了實驗,并與傳統方法和神經模型做了對比.
3.1 數據集
第1 個數據集是來自Aminer[17]的論文集,由188 篇查詢文檔組成,每個查詢文檔有10 篇候選論文,這些文檔均是計算機相關的專業論文.第2 個數據集是基于美國專利和商標局的專利文件(Patent),由67 個查詢組成,每個查詢有20 個候選文檔.第3 個數據集是來自Sowiport 的相關文章推薦數據集(RARD),這是一個社會科學文章的數字圖書館,向用戶提供相關文章.此數據集包含63 932 個帶有用戶點擊記錄的不同查詢.每篇查詢文章平均有9.1 篇文章顯示,我們選取了100 個點擊率最高的查詢進行測試,其他的查詢則用于訓練.
3.2 實驗對比方法
下面是本文中用來做對比的幾種方法,其中前兩種方法為傳統方法,后3 種方法為神經模型.
(1)TF-IDF[12]: 將查詢文檔和候選文檔中共同出現的詞語的權重相加來得到文檔之間的相似度得分.一個詞的權重是其詞頻和逆文檔頻率的乘積.
(2)Doc2Vec[18]: 通過段落向量模型得到每一篇文章的分布表示,然后通過計算他們之間的余弦相似性來得到文檔之間的相似度得分.
(3)MV-LSTM[5]: 由Bi-LSTM 生成的不同位置的句子表征形成了一個相似性矩陣,由這個矩陣來生成相似度得分.
(4)DRMM[19]: 基于查詢文檔和候選文檔的詞對向量構建局部交互矩陣,根據此矩陣轉化為固定長度的匹配直方圖,最后將直方圖發送到MLP 以獲得相似度得分.
(5)LTM-B[20]: 采用分層的思想將文檔切分成多個分段,使用BERT 將文本向量化,將得到的矩陣表示與BiLSTM 產生的位置矩陣求和之后輸入到Transformer中進行特征提取,最后將兩個文檔矩陣進行交互、池化拼接后經全連接層分類得到匹配分數.
3.3 實驗設計與結果分析
(1)實驗1: 與其他方法的對比實驗
表1 展示了不同方法在歸一化折損累計增益(NDCG)指標方面的排名精度.為了比較的公平性,所有模型都不涉及用戶反饋,這一點會在后面討論.
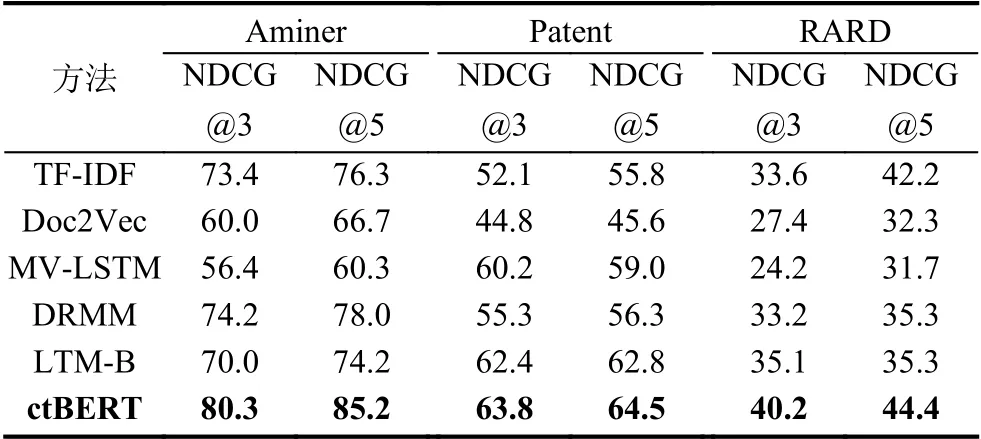
表1 不同方法在NDCG 指標方面的排名精度(%)
從表1 中的評估結果可以看出,我們提出的模型性能優于其他的方法,在NDCG@3 標準上優于對比方法3.6%-19.6%,在NDCG@5 標準優于對比方法2.2%-24.9%,在每個數據集上NDCG 平均提高分別為:14.6%、5.8%、9.8%.我們注意到,在Aminer 數據集中的提升效果要明顯優于其他兩個數據集,說明我們的模型在涉及特定專業領域的數據集上有更好的表現.
(2)實驗2: 消融實驗
為了探究主題模型和預訓練模型分別對ctBERT的性能影響,我們為消融實驗建立基線模型,分別是:
(1)ctBERT-ctm: 去掉主題模型,僅用預訓練模型BERT 對文章進行建模.
(2)ctBERT-BERT: 去掉預訓練模型,僅用主題模型CTM 對文章進行建模.
為了比較的公平性,本實驗均不涉及用戶反饋.它們與ctBERT 模型的性能比較如表2 所示.

表2 消融實驗結果對比(%)
實驗結果可以看出,僅用預訓練模型BERT 對文章進行建模的方法ctBERT-ctm 相比表1 中的Doc2Vec以及MV-LSTM 方法有部分性能提升,但是效果仍不如其他對比的基線模型,說明此種方式對文章語義信息的表示有限.去掉預訓練模型的ctBERT-BERT 模型僅用概率最大的主題詞詞向量作為文章表示,實驗結果表明此方法在3 個數據集上均無法達到很好的效果.
(3)實驗3: 單樣本學習對整個框架的影響
為了探究單樣本學習對整個框架的影響,我們設置了以下實驗,探究加入單樣本學習之后ctBERT 模型的表現.由于以上3 個數據集均沒有用戶個性化標簽,我們利用數據集中的數據模擬個性化問題.首先選擇有多個正面標記的候選項的查詢,對于每個查詢,我們將標記的候選項隨機分為兩部分.第1 部分用于支撐集,第2 部分用作將要推薦的候選集.然后我們將單樣本學習推薦框架(稱為ctBERT-os)與前面不涉及用戶反饋的最佳模型ctBERT 進行比較.結果如表3 所示.可以看到,通過加入支撐集,可以提高模型性能,平均而言,ctBERT-OS 模型的表現在NDCG@3 和NDCG@5標準上要比ctBERT 高出4%和3.9%.

表3 原始模型與加入單樣本學習后的實驗結果對比(%)
4 結論
本文研究了個性化文章推薦問題,在前人研究的基礎上提出了一個新的模型來解決它,相較于其他的特征工程語義相似性模型,創新性的加入主題信息,將主題信息與預先訓練好的上下文表示(BERT)相結合作為文本表示.實驗結果表明,該模型優于傳統的和最新的神經網絡模型基線,尤其是在特定專業領域(如計算機領域)的數據集上能顯著的提高性能.
本文提出的模型雖然有一定的效果提升,但也有一些局限,比如目前主題信息與文本表示的集合是在兩個模型外部進行的融合,對于模型的統一性而言還不夠高,未來的工作方向可能集中在如何不破壞預訓練信息的情況下直接將主題信息融合到BERT 內部中,從而指導文本語義相似度的計算.
由于本文中用到的數據集均沒有用戶個性化標簽,在一定程度上會影響單樣本學習框架的性能表現,未來的工作方向會將ctBERT 部署到線上環境,收集到足夠的用戶反饋數據,再根據訓練結果調整模型和超參數,從而更好地指導模型性能.
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
