基于融合CNN 和MPA-SVM 的滾動軸承故障診斷
2022-11-08 07:14:36林珍莉曾憲文
上海電機學(xué)院學(xué)報 2022年5期
林珍莉, 曾憲文
(上海電機學(xué)院 電子信息學(xué)院, 上海 201306)
滾動軸承如果在機械運行[1]的時候發(fā)生故障,將嚴(yán)重影響正常的工作。因此,發(fā)現(xiàn)故障的原因,不僅是提高軸承穩(wěn)健性的重要措施[2],也是保證工業(yè)機械設(shè)備正常運行的關(guān)鍵[3]。在滾動軸承的使用壽命中,其發(fā)生故障的原因多種多樣,定時的檢查和維修是非常耗費人力的。對于具有重要作用的軸承,定時維修是非常不科學(xué)的。因此,軸承檢測和故障診斷技術(shù)[4]的研究和應(yīng)用,受到研究學(xué)者越來越多的關(guān)注,成為故障診斷領(lǐng)域的研究熱點,也是保障電機良好運行狀況的重要措施[5]。
以往的軸承故障診斷多利用數(shù)據(jù)驅(qū)動的特征提取方式,需要提前對信號進行快速傅里葉變換、小波變換[6]、S變換[7]和經(jīng)驗?zāi)J椒纸鈁8]等處理,但會丟失重要的時域特征。常見的模式分類算法有支持向量機(Support Vector Machine,SVM)[9]、貝葉斯分類器以及最近鄰分類器等。傳統(tǒng)的故障診斷具有準(zhǔn)確率不高、抗噪健壯性不強和難以解釋等問題,被基于數(shù)據(jù)驅(qū)動和深度學(xué)習(xí)的故障診斷相結(jié)合的方法所取代[10]。在深度學(xué)習(xí)的基礎(chǔ)上,吳春志等[11]提出了改進一維卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)的方法進行齒輪箱故障診斷,通過實驗得出1維CNN 模型高于傳統(tǒng)診斷模型。曲建嶺等[12]提出了改進CNN 的滾動軸承自適應(yīng)故障診斷算法,進一步提高了1維CNN 的準(zhǔn)確率和泛化性。張弛[13]提出一種基于CNN 和SVM 的軸承故障診斷模型,該模型以原始振動信號為故障診斷的輸入數(shù)據(jù),準(zhǔn)確率為96.7%。宮文峰等[14]為解決模型訓(xùn)練參數(shù)過多的問題,提出了一種在全連接層進行改進的CNN。
上述文獻均是對CNN 網(wǎng)絡(luò)結(jié)構(gòu)進行優(yōu)化。這些模型作為特征提取方法的參考,提高了一定的準(zhǔn)確度,但泛化能力不高[15]。針對泛化能力不高等問題,本文提出了一種基于融合CNN 和海洋捕食者(Marine Predators Algorithm,MPA)優(yōu)化SVM 的滾動軸承故障診斷方法。該方法只需輸入原始數(shù)據(jù),即可準(zhǔn)確識別滾動軸承的故障種類,不需要復(fù)雜的模型和先驗知識,具有更好的泛化能力和更高的準(zhǔn)確率。
1 基本原理
本文提出的融合CNN 模型的結(jié)構(gòu)由一維CNN特征提取子網(wǎng)絡(luò)、二維CNN 特征提取子網(wǎng)絡(luò)、特征匯聚層、2層全連接層和SVM 分類層構(gòu)成。一維CNN 特征提取子網(wǎng)絡(luò)包括第1輸入層、第1卷積層、第1池化層、第2卷積層和第2池化層;二維CNN 特征提取子網(wǎng)絡(luò)包括第2輸入層、第3卷積層、第3池化層、第4卷積層和第4池化層;特征匯聚層分別與第2池化層和第4池化層連接,將池化層輸出的特征進行融合后再輸入到全連接層中,之后把特征信號輸入SVM 中進行分類。融合CNN和MPA-SVM 的故障診斷模型結(jié)構(gòu)如圖1所示。

圖1 融合CNN和MPA-SVM 的模型結(jié)構(gòu)
在CNN前向傳播中,為了減少參數(shù)和過擬合問題,選擇用最大池化層來降低特征數(shù)據(jù)的維數(shù),然后使用全連接層對特征進行擬合。在反向傳播階段,通過Adam 訓(xùn)練算法更新權(quán)重,獲得全局最優(yōu)解,從而使誤差損失函數(shù)最小化。為了提高分類準(zhǔn)確性,分別利用MPA、粒子群算法(Particle Swarm Optimization,PSO)和麻雀搜索算法(Sparrow Search Algorithm,SSA)對SVM 的核參數(shù)和懲罰因子進行優(yōu)化。通過訓(xùn)練此模型,讓核參數(shù)和懲罰因子達到最優(yōu)值,經(jīng)過對比找到最優(yōu)算法。
2 基于融合CNN和SVM 的軸承故障診斷模型
相較于傳統(tǒng)人為設(shè)計的特征提取方法,CNN可以提取軸承故障振動信號的更深層特征,一維卷積是滑動窗口在寬或高方向上的相乘、求和,常用于序列模型。二維卷積是在高和寬2個維度上同時進行,常用來處理圖像數(shù)據(jù)。結(jié)合兩者的優(yōu)點,本文融合了1D-CNN 和2D-CNN,采用不同尺度的卷積核,對不同維數(shù)的輸入信號進行卷積,卷積過程數(shù)學(xué)表達式為

式中:max[]為最大值函數(shù)。
池化層是一種降采樣過程,主要過濾掉冗余的信息,減小參數(shù)數(shù)量;同時加快計算速度,防止過度擬合。由于軸承振動信號易受噪聲干擾,本文選取最大池化作為池化層,可表示為
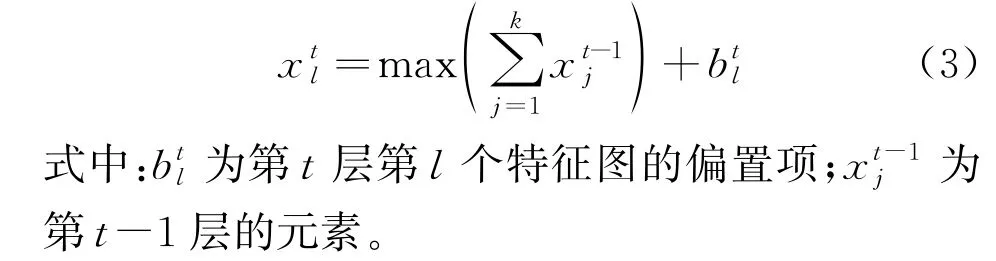
特征圖經(jīng)過池化層的壓縮、簡化后,在匯聚層將兩者池化層的輸出連接成1個向量后,輸入全連接層。全連接層主要用于對獲取到的特征進行擬合,同時為了防止過擬合采用Dropout方法,減少中間特征的數(shù)量,增加每層各個特征的正交性。融合CNN的模型參數(shù)見表1。

表1 融合CNN模型結(jié)構(gòu)參數(shù)
3 基于MPA-SVM 的參數(shù)優(yōu)化
SVM 是一種二分類模型,是特征空間中最大化間隔的線性分類器,在分類超平面的正負(fù)兩邊,各找到一個離分類超平面最近的點,使這2個點距離分類超平面的距離和最大。這些點離分界線越遠(yuǎn)越能更準(zhǔn)確地對新數(shù)據(jù)進行分類,分類器更穩(wěn)健。在SVM 中核參數(shù)的選取影響SVM 的性能,懲罰因子是分類準(zhǔn)確性和模型復(fù)雜度之間的權(quán)衡,而核參數(shù)和懲罰因子的選取都是人工選取,帶有一定的隨機性和不精確性。MPA 是由Faramarzi等[16]在2020年提出來的,其靈感來源于MPA 覓食策略。MPA具有很強的尋優(yōu)能力,相較于其他傳統(tǒng)智能優(yōu)化算法,MPA 的計算速度和精確度更高。為了提高分類的嚴(yán)謹(jǐn)性和精確度,本文選取MPA對SVM 的核參數(shù)與懲罰因子進行優(yōu)化,從而對故障類型進行識別。
MPA優(yōu)化過程分為3個主要階段,考慮不同的速度比,同時模擬捕食者和獵物的整個生命周期。
(1) 發(fā)生在優(yōu)化的迭代初期,此時全局搜索非常重要。此階段捕食者采取的最佳策略就是維持當(dāng)前位置,即
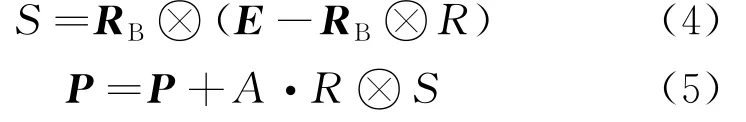
式中:S為此階段的移動步長;RB為呈正態(tài)分布的布朗游走隨機向量,維度是d;?為逐項乘法運算符,模擬了獵物的運動;A為常數(shù),通常取為0.5;R為[0,1]內(nèi)的隨機均勻分布值;E為由頂級捕食者組成的精英矩陣;P為獵物矩陣。
(2) 此時獵物與捕食者都在尋找獵物,該策略發(fā)生在迭代中期,種群被分為2部分,其中獵物做萊維運動,負(fù)責(zé)算法在搜索空間內(nèi)開發(fā),捕食者做布朗運動,負(fù)責(zé)算法在搜索空間內(nèi)探索。
前半部分種群跟新規(guī)則如下:

式中:RL由萊維分布組成,為萊維運動的隨機向量;CF為捕食者移動步長的自適應(yīng)參數(shù)。
(3) 發(fā)生在迭代后期,主要提高算法的局部開發(fā),此時捕食者的最佳策略為萊維運動,即
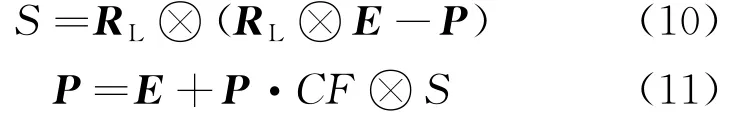
在式(11)中,RL和E矩陣的點乘模擬了捕食者的萊維運動,因此捕食者的運動又被模擬為獵物位置的更新。其中利用MPA優(yōu)化SVM 參數(shù)的步驟說明如下:
步驟1 設(shè)置海洋捕食者參數(shù),初始化種群;
步驟2 設(shè)置SVM 需要優(yōu)化的參數(shù)的取值范圍,計算獵物矩陣適應(yīng)度值,記錄最優(yōu)位置,計算出精英矩陣;
步驟3 捕食者根據(jù)迭代階段,利用式(4)~式(11)選擇對應(yīng)的更新方式,更新捕食者位置。將訓(xùn)練SVM 得到的測試集和訓(xùn)練集的錯誤率值作為MPA的適應(yīng)度值,計算適應(yīng)度值,更新最優(yōu)位置。若訓(xùn)練達到精度要求,將所得的參數(shù)作為SVM 的最優(yōu)結(jié)構(gòu)參數(shù),否則返回到步驟3。采用最優(yōu)參數(shù)測試SVM,得到軸承故障診斷的分類結(jié)果。
4 實驗結(jié)果與分析
4.1 實驗數(shù)據(jù)介紹
本文選用美國凱斯西儲大學(xué)電氣工程實驗室的滾動軸承數(shù)據(jù)集,實驗數(shù)據(jù)選取OHP下,采樣頻率為48 k Hz的驅(qū)動端數(shù)據(jù),驅(qū)動端的尺寸又分為3類,即7、14、21μm,相對應(yīng)每種尺寸下又可分為內(nèi)圈、外圈和滾動體故障。再加上正常狀態(tài)的軸承數(shù)據(jù),本文可分為10種故障類型,故障類型見表2。
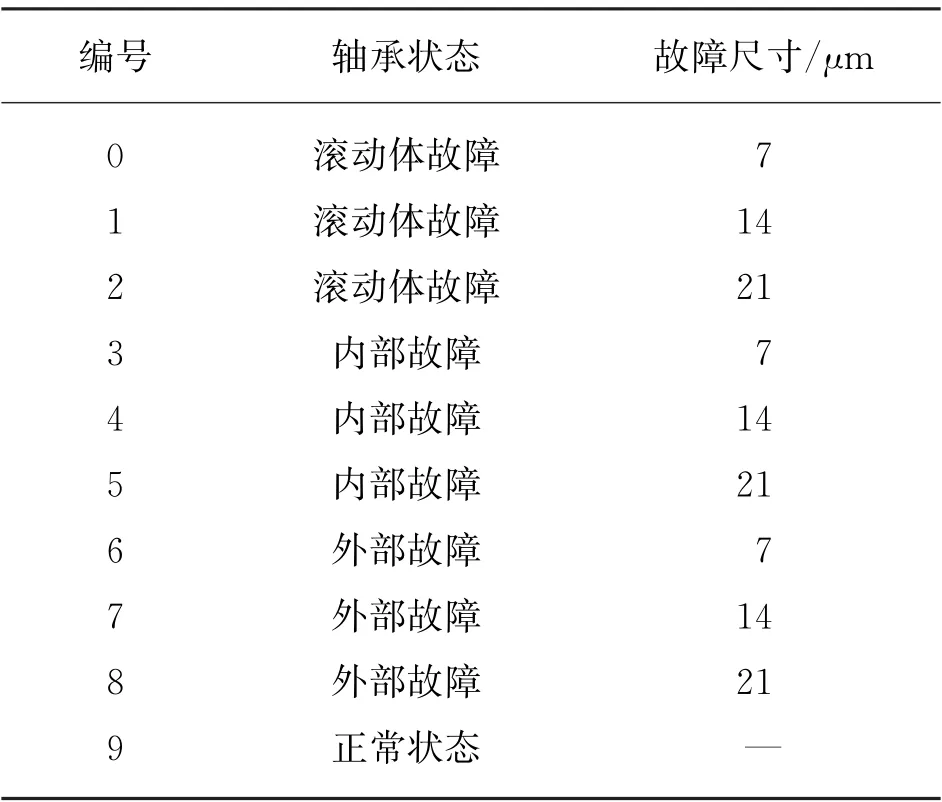
表2 實驗樣本數(shù)據(jù)集
本文選取1 024個采樣點作為一組訓(xùn)練樣本序列,每種類型選取1 000組訓(xùn)練樣本,則共能得到10 000個樣本。為了增加數(shù)據(jù)集的數(shù)量,增強模型的可行性,對原始數(shù)據(jù)進行重疊采樣和刪除冗余的數(shù)據(jù),然后按8∶1∶1劃分訓(xùn)練集、驗證集和測試集。
4.2 特征提取可視化
利用融合CNN 提取每個故障樣本的自適應(yīng)故障特征。由于CNN 比較復(fù)雜無法可視化,為了展示模型的性能,使效果更加直觀,本文采用TSNE技術(shù)對特征提取結(jié)果進行三維可視化。原始樣本的分布如圖2所示。通過融合CNN 提取特征后的10種樣本有規(guī)律的聚在一起,如圖3所示。通過對比,說明本文提出的模型效果更好。
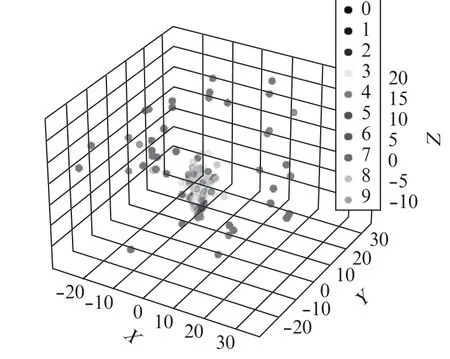
圖2 原始數(shù)據(jù)可視化結(jié)果

圖3 融合CNN提取特征可視化結(jié)果
4.3 算法訓(xùn)練與評估
本文選擇Google公司的Tensorflow 深度學(xué)習(xí)框架,搭建融合CNN和MPA-SVM 模型。對數(shù)據(jù)集進行訓(xùn)練,訓(xùn)練時的dropout為0.6,測試時為1.0。通過融合CNN,取FC層的輸出作為故障特征信號,最后采用優(yōu)化后的SVM 對采集到的特征進行分類。訓(xùn)練集和驗證集輸入融合CNN+MPA-SVM 模型,經(jīng)100次迭代得到分類準(zhǔn)確率和損失率曲線,結(jié)果如圖4和圖5所示。
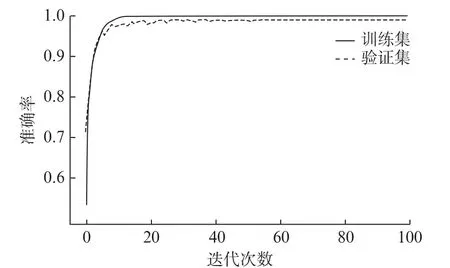
圖4 融合CNN+MPA-SVM 分類準(zhǔn)確率曲線
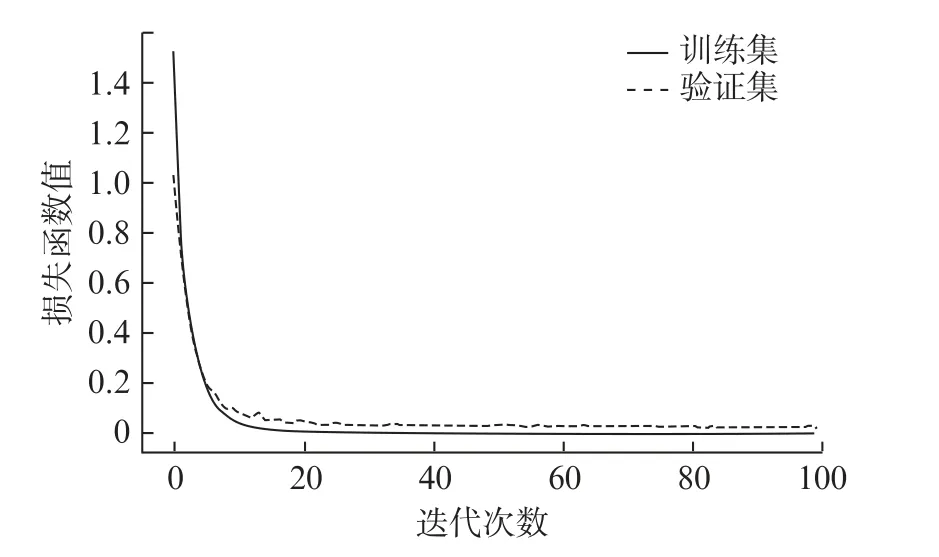
圖5 融合CNN+MPA-SVM 損失率曲線
由圖4和圖5可知,經(jīng)過20次迭代之后,模型驗證集的識別準(zhǔn)確率變換已經(jīng)平穩(wěn)且接近100%,損失函數(shù)接近于0。該模型識別結(jié)果的混淆矩陣如圖6所示,對角線對應(yīng)預(yù)測結(jié)果的精確度,顏色越黃說明預(yù)測分類的精確度越好。因此,本模型對軸承故障診斷具有很好的效果且精確度高。
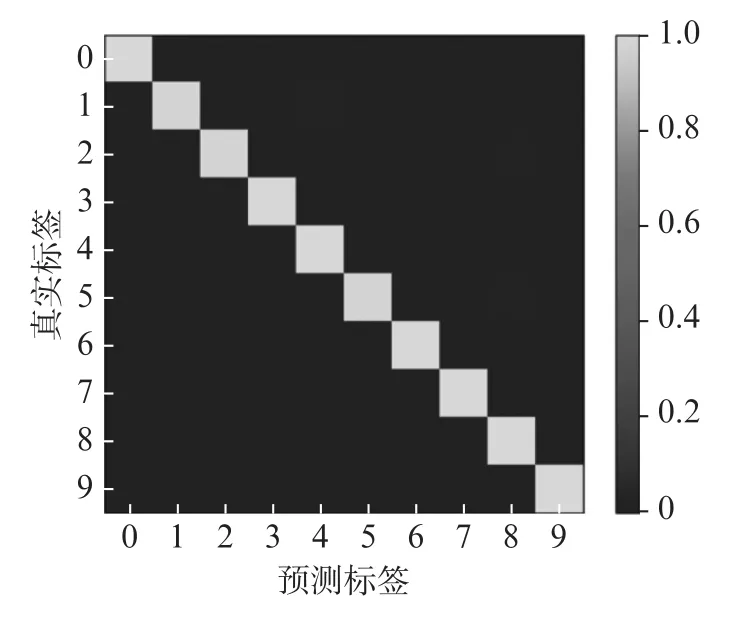
圖6 融合CNN和MPA-SVM 模型分類結(jié)果混淆矩陣
4.4 故障診斷能力對比
對上述融合CNN 采集的特征進行分類,并以驗證集的分類精度作為準(zhǔn)確率函數(shù),對4種分類方法進行比較,如圖7所示。
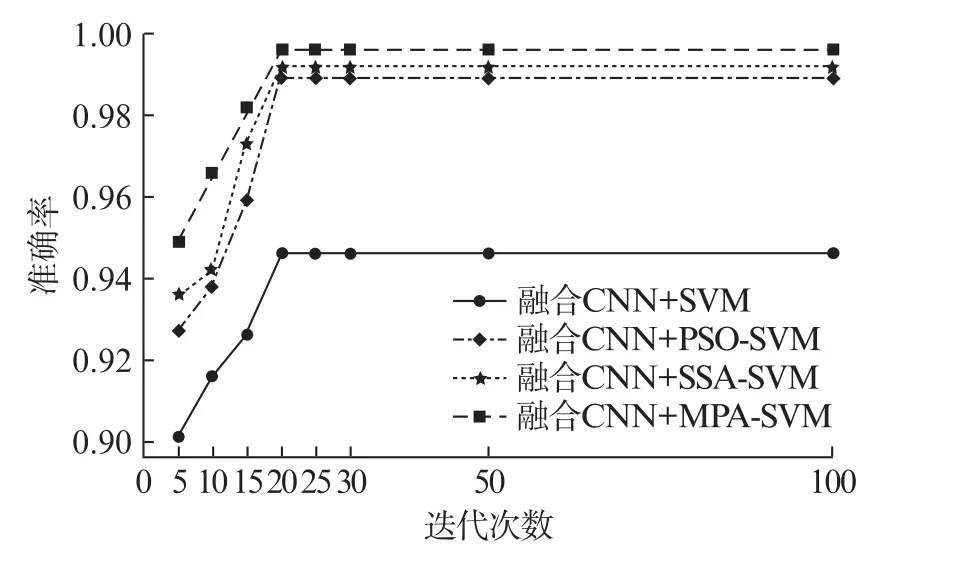
圖7 模型測試集故障分類準(zhǔn)確率對比
由圖7可知,當(dāng)?shù)螖?shù)在20次左右時準(zhǔn)確率趨于穩(wěn)定,而融合CNN+SVM 的準(zhǔn)確率最低。對比其他3種算法模型,融合CNN 和MPA-SVM的準(zhǔn)確率和效果最好,此時驗證集的準(zhǔn)確率為99.6%,優(yōu)化后的懲罰參數(shù)為107.999,核參數(shù)為0.121。說明優(yōu)化SVM 的算法中MPA最好,證明了本文模型的優(yōu)越性。
5 結(jié) 論
針對軸承故障診斷模型中細(xì)微故障特征提取困難、信息冗余、泛化效果不好和分類準(zhǔn)確率低等問題,提出了一種基于融合CNN與MPA-SVM 的滾動軸承故障診斷方法,并通過仿真驗證了其有效性,得到以下結(jié)論:
(1) 利用一維CNN 和二維CNN 各自的特點融合在一起,對滾動軸承振動信號進行特征提取,并利用SVM 進行分類,能夠使模型發(fā)揮更大的識別價值;
(2) 新型MPA算法優(yōu)化SVM 的核參數(shù)和懲罰因子,可以避免訓(xùn)練時間過長或參數(shù)不合適而提高了分類準(zhǔn)確率;
(3) 本文所構(gòu)建的融合CNN 和MPA-SVM軸承故障診斷模型相較于其他3種,方法識別率最高。同時也發(fā)現(xiàn)CNN 模型訓(xùn)練參數(shù)多,數(shù)據(jù)質(zhì)量不好。接下來可以在優(yōu)化和減少參數(shù)量上對CNN進行研究,使診斷模型更加完美。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
電子制作(2019年15期)2019-08-27 01:12:00
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫(yī)學(xué)工程學(xué)報(2017年6期)2017-02-10 05:11:45
重慶工商大學(xué)學(xué)報(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
