異構分支關聯特征融合的行人重識別
2022-11-15 16:17:50陳璠,彭力
計算機與生活 2022年11期
陳 璠,彭 力
物聯網技術應用教育部工程研究中心(江南大學 物聯網工程學院),江蘇 無錫214122
行人重識別(person re-identification,Person Re-ID)是計算機視覺中的一項重要任務,其目的是從多臺攝像機捕捉的一組行人圖像中檢索出一個特定的人。
早期的Person Re-ID 技術對整幅圖像提取全局特征進行圖像檢索,但是由于真實場景下的行人圖像存在光照差異大、拍攝視角不統一、物體遮擋等問題,從圖像整體提取的全局特征易受無關因素的干擾,識別精度不高[1]。基于局部特征的方法因此被提出,通過挖掘人體部位[2-5]、行人姿態[6-9]等關鍵信息,可加強模型對人體關鍵區域的學習,降低無關因素的干擾。
基于特征空間分割的方法在空間尺度上將特征劃分為多個局部顯著性區域,讓模型在訓練過程中學習不同區域的差異性,并強制每個區域滿足獨立的ID 預測損失。Zheng 等人通過將卷積網絡輸出的特征圖均分為6塊,考慮了全局特征和局部特征之間的漸變關系,金字塔模型包括6 層共計21 塊不同尺度區域,再將最后一層的特征串聯起來以使模型能夠提取到具有較強上下文聯系的特征[4]。PAR(partaligned representations)模型將人體分割成若干個可區分的區域,再將每個區域的特征向量連接起來,得到最終的特征向量表示[5]。上述基于空間分割的方法能夠簡單直觀地細化特征,加強特征的魯棒性。另外,該方法考慮到圖像間行人粗糙的幾何對應關系,將所有局部特征以特定順序進行連接以得到行人的結構化特征。雖然此類方法在一定程度上能夠解決幾何變化和遮擋等問題,但沒有顧及身體局部區域之間的關系,可能降低具有相似屬性的不同行人在對應部位的區分度。
為了進一步提升采用特征空間分割方法的模型的重識別性能,有研究者構建具有多個分支的網絡模型,例如全局特征分支和局部特征分支。Yao等人提出的零件損失網絡(part loss networks,PL-Net)通過引入零件損失自動檢測人體部位,并計算每個零件的分類損失,以影響全局分支的特征表達[10]。Wang等人設計了一種整合全局特征和局部特征的多粒度模型(multiple granularity network,MGN),包括一個全局分支和兩個局部分支,MGN 通過將特征圖劃分成多個條紋特征圖,并且改變不同分支的條紋數量來獲得多粒度局部特征表示[3]。對于采用多個分支的模型,全局特征增強了模型對背景信息的學習,而局部特征可融合人體關鍵特征。但這些模型的每個分支均使用同構特征,即這些特征均復制自全局分支的高層,使模型缺乏結構多樣的差異特征。
針對上述問題,本文提出一種異構分支關聯特征融合的行人重識別算法。將OSNet(omni-scale network)與注意力機制相結合作為主干共享卷積網絡,以學習到具有更強顯著性和區分性的行人關鍵特征;將分支網絡輸出的行人特征進行水平均等分割,再提取關聯條紋特征,從而全面利用位于條紋間的綜合信息;設計異構特征提取模塊,以增加模型學習差異特征所需的結構多樣性。
1 異構分支關聯特征融合的行人重識別
1.1 網絡結構
本文所提模型結構如圖1 所示,包括3 個分支,分別為全局分支(v1)、條紋特征關聯分支(v2)和異構特征提取分支(v3),圖中D表示特征向量的維數。骨架網絡選用的是OSNet[11],由5個卷積塊Convi組成,其中i=1,2,3,4,5。OSNet 是支持全尺度特征學習的輕量級網絡,保證較高的特征提取效率,并且能夠有效地捕獲不同感受野范圍下的尺度特征。為了學習圖像中更值得關注的關鍵信息,在OSNet 的Conv2和Conv3層分別添加空間注意力模塊(spatial attention module,SAM)和通道注意力模塊(channel attention module,CAM)。全局分支由OSNet的Conv5組成,且僅使用全局最大值池化(global max pooling,GMP),GMP 可以促使網絡識別相對較弱的顯著特征,以保證全局分支與其他分支之間的功能多樣性。條紋特征關聯分支通過條紋特征關聯模塊將不同的條紋特征進行關聯計算,以加強條紋間信息的相關性,進而最優地學習并整合局部特征信息。異構特征提取分支將OSNet 的Conv5替換為網絡Res-Net50 的Conv2、Conv3和Conv4,以學習更具結構多樣性的特征。共享卷積網絡輸出的特征圖經過全局分支,獲得1 個512D 的特征向量g1;經過條紋特征關聯分支和平均池化(average pooling,AP),獲得8個256D的關聯特征向量fi(i=1,2,…,8),再串聯為特征向量g2;經過異構特征提取分支和降維操作,獲得1個512D的特征向量g3。
訓練階段,對3個特征向量gj(j=1,2,3)分別使用ID 預測損失函數、中心損失函數和三元組損失函數進行監督優化。測試階段,將特征向量gj(j=1,2,3)串聯為特征描述符G,并使用特征描述符G進行相似性判斷。
1.2 注意力模塊
在深度學習領域中,注意力機制的使用普遍且廣泛[12-15],類似于人類觀察物體時將視線聚焦于小部分重要區域,它可以幫助卷積神經網絡(convolutional neural networks,CNN)將關注的重點放在目標的細節信息并抑制無用信息,尋找對特征圖影響較大的區域,增強模型對重要局部區域的關注度[1],進而使CNN 網絡對信息進行快速篩選,從中總結出高價值信息,提高信息處理與提取的效率和準確度。卷積網絡中低層網絡提取到的更多是圖像中的細節特征,如行人的邊緣輪廓特征,高層網絡提取的是全局的語義信息。由于低層特征圖對高層特征圖的生成至關重要,后者依賴于前者,只有低層網絡的卷積核提取到行人更多的邊緣特征,高層網絡才能將該行人進行最佳的抽象映射。
本文在骨架網絡OSNet中加入注意力模塊SAM和CAM。SAM 可以突出卷積網絡的有效部分并抑制像素級背景雜波的干擾,在空間域中捕獲并聚合語義相關的像素點。如圖2所示,為了降低計算復雜度,本文使用1×1 的卷積核,將輸入圖像的通道數由c減少至c/r。但單獨使用SAM 的模型會過度集中于圖像前景,而忽視低相關特征,因此加入CAM 模塊。CAM旨在將每個通道的權重壓縮到一個特征向量中[16],并將具有相同語義信息的通道進行組合,最后與原始特征融合使模型能夠學習關鍵通道的特征,如圖3 所示。首先在式(1)中用全局平均池化對每個通道中的特征值相加后平均,以將每個通道的特征壓縮到一個1×1 的二維矩陣中,最終特征通道上所響應的全局分布均由二維矩陣z表征。
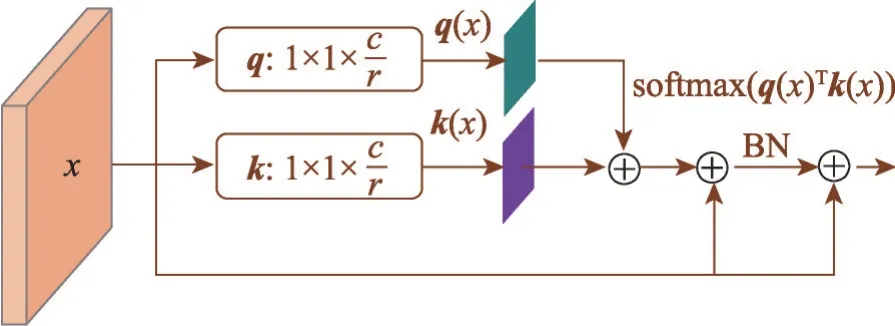
圖2 SAM模塊Fig.2 Structure of SAM
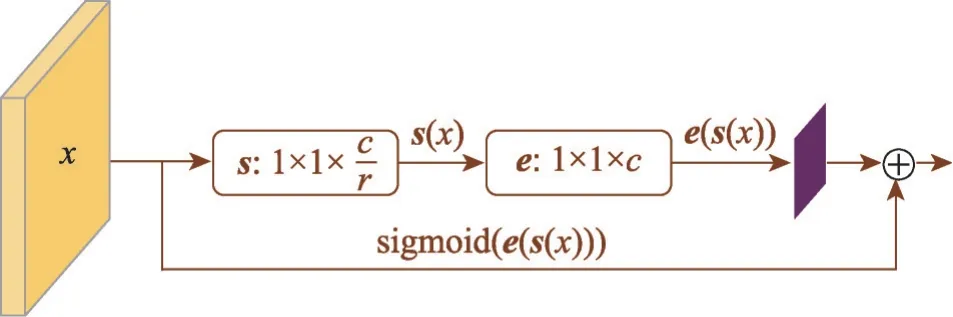
圖3 CAM模塊Fig.3 Structure of CAM
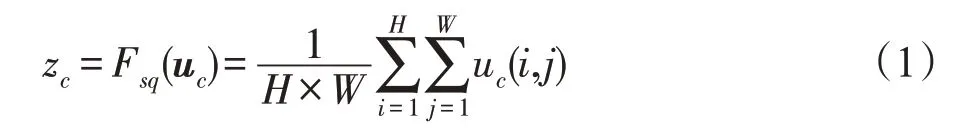
式中,uc、zc分別表示輸入特征u和輸出特征z的第c個通道,H、W分別表示輸入特征u的高和寬。
然后根據式(2),使用激活函數ReLU和Sigmoid激勵通道特征圖。特征圖先經過兩層全連接層,之后利用激活函數強化通道特征的非線性響應,從而得到最終的通道注意力圖s。
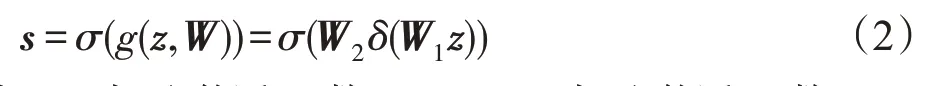
式中,δ表示激活函數ReLU,σ表示激活函數Sigmoid,W1和W2分別為兩層全連接層的權重矩陣,s為輸出的特征注意力圖。
最后利用式(3)融合原始特征u與通道注意力圖s,從而重新分配原始特征圖中的各個通道的權重。

1.3 條紋特征關聯模塊
局部特征的使用降低了數據集中行人樣本復雜化的影響,且這些關鍵的局部特征更具代表性,更有助于網絡模型區分不同的行人。
本文算法根據人體的結構特征,將分支網絡v2輸出的特征圖進行水平均等分割,由于分割后的條紋相互獨立,且每個條紋僅包含自身的信息,當每個條紋不與其余條紋進行通信時,如果直接將這些局部特征單獨用于行人檢索,會混淆具有相似屬性的不同行人在相應部位的區分度。因此提出條紋特征關聯模塊,該模塊解釋了行人身體各個部位與其他部位之間的關系,使每個條紋特征都包含了對應部位本身和其他部位的綜合信息,從而更具鑒別力。如圖1所示,條紋特征關聯模塊接收來自所在網絡分支提取的特征圖,將最后一個卷積塊Conv5的輸出特征圖在豎直方向上水平分割為均等的8塊,通過條紋間的關聯計算依次將每個條紋與其他條紋進行通信,從而獲得8 個關聯條紋特征向量,并將平均值池化(AP)作用在所得的關聯條紋特征上。
如圖4 所示,首先選中其中一個條紋特征向量fi(i=1,2,…,8),尺寸為1×1×C,將平均池化AP作用于其余7 個條紋特征向量fj(j≠i),以獲取包含其余條紋綜合信息的向量gl(l=j)。然后將1×1 的卷積層用于向量fi和gl,以減小通道數至c,并產生尺寸為1×1×c的向量。條紋特征關聯模塊連接特征,并且為每個fi輸出一個關聯特征向量qi。此時每個特征qi(i=1,2,…,8)均包含了行人的全部信息。關聯計算過程為:
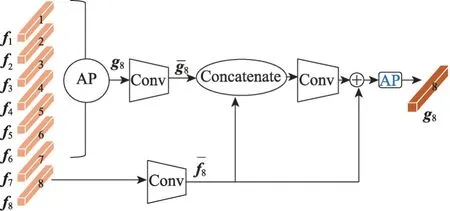
圖4 條紋特征關聯模塊Fig.4 Stripe feature correlation module

其中,i=1,2,…,8 且j≠i,l≠i。Bp是一個子網絡,包含1×1的卷積層、BN層和ReLU層;C表示特征的串聯。能夠使局部的條紋特征對遮擋與幾何變化更具辨別性和魯棒性。特征關聯模塊通過線性方式計算特征qi,計算成本低的同時保持了特征表示的緊湊性。
1.4 異構特征提取模塊
在行人重識別任務中,結合全局特征和局部特征的多分支網絡可以同時關注行人的輪廓信息和細節信息,但目前很多網絡的不同分支使用的均是同構特征,致使模型缺乏結構多樣的差異特征。
針對上述問題,本文通過增加異構特征提取分支,增強網絡模型學習差異特征的能力,同時使其更具有判別力。具體為:異構特征提取分支將OSNet的Conv5替換為ResNet50[17]的Conv2,3,4,如圖5(a)所示,ResNet50 的每個卷積塊Conv 均由不同數量的卷積和恒等連接的殘差塊構成,殘差塊使用3 個卷積層(1×1,3×3,1×1)堆疊而成,其中兩個1×1 的卷積負責調整維數,3×3 的卷積對圖像進行下采樣。通過對殘差塊中卷積參數的設置,使殘差塊的輸入和輸出特征圖尺寸一致,從而進行線性操作,保證將網絡深層的梯度值有效地傳遞至網絡淺層,以避免深度網絡的退化和梯度彌散問題。對于輸入張量X∈RH×W×C,經殘差塊后對應的輸出Y為:

圖5 異構特征提取模塊Fig.5 Structure of heterogeneous feature extraction module

異構特征提取分支v3的特征提取過程如圖5(b)所示,v3 分支接收來自OSNet 骨架網絡輸出的特征圖,并將其送入ResNet50 網絡的Conv2,3,4層,再經過全局最大池化GMP 和全局平均池化(global average pooling,GAP)后得到一個2 048D的特征向量。為了提高計算效率,使用1×1 的卷積將得到的特征向量降維至512D。對于輸入張量X∈RH×W×C,經v3 后對應的輸出Fo為:
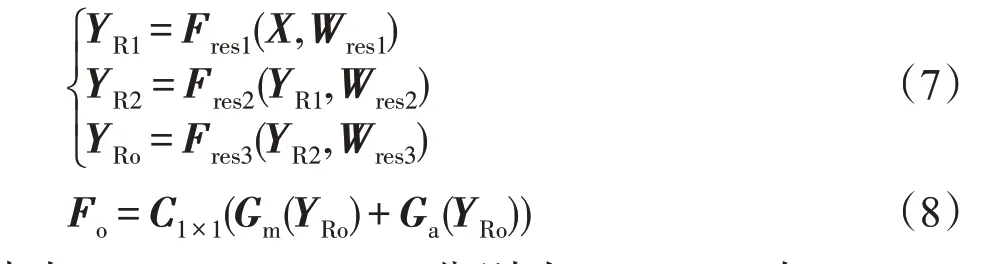
其中,Fres1、Fres2、Fres3分別為ResNet50 中Conv2,3,4層的網絡表示;Wres1、Wres2、Wres3分別為每層網絡對應的權重;YR1、YR2、YRo分別為ResNet50中Conv2,3,4層的輸出;Gm表示全局最大值池化GMP;Ga表示全局平均值池化GAP;C1×1表示1×1卷積操作。
1.5 損失函數
聯合多種損失函數,可以幫助網絡模型學習到區分度更高、魯棒性更強的行人特征。在訓練階段,組合三種不同的損失函數,包括ID 預測損失(softmax loss)、中心損失(center loss)[18]以及三元組損失(triplet loss)[19]。通過最小化組合后的損失函數來優化網絡模型,總損失函數為:

其中,Ls-id為單一ID損失,α、β分別是中心損失和三元組損失所占的權重。
在基于特征空間分割的行人重識別研究中,大多數方法采用多重ID 損失函數對行人身份進行預測。如圖6 所示,輸入的行人圖像通過骨架網絡進行特征提取得到張量T,在特征空間中T被均勻劃分為n條水平條紋,再經過平均值池化和降維等操作生成n個特征向量gi(i=1,2,…,n),最后使用n個分類器以產生n個ID 預測損失值。多重損失函數Lm-id為:

通過多重ID損失函數來監督每個條紋特征向量gi(i=1,2,…,n),模型可以將局部區域的特征學習到最優以區分不同的人。然而如圖6所示,許多條紋特征可能無法捕捉到不同行人的具有明顯區分性的信息,因此降低對行人整體的預測準確率。
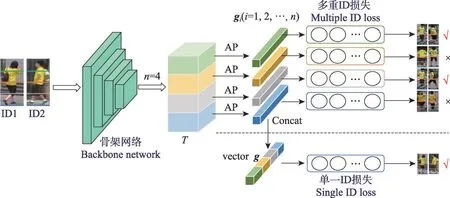
圖6 單一ID損失與多重ID損失Fig.6 Single ID loss vs multiple ID loss
為了更高效地利用模型學習到的局部顯著性區域的判別特征,本文將n個條紋特征向量串聯成一個列向量g用于產生單一的ID 預測損失值。單一ID損失函數Ls-id為:
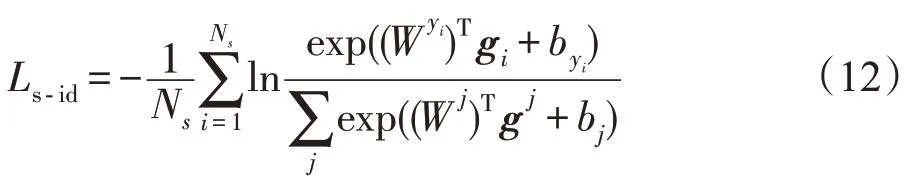

其中,W是特征向量g對應分類器的權重矩陣,Wj和是權重矩陣W的第j列和第yi列,Ns為樣本數目。
由于向量g包含輸入圖像中行人的完整信息,使用單一ID損失函數可以驅動g學習并整合局部顯著性區域中足夠多的判別信息。
2 實驗結果與分析
2.1 實驗配置與數據集
本文采用Pytorch-1.0.1 深度學習框架,Ubuntu 16.04 操作系統,編程語言為Python3.6。硬件采用顯卡內存為8 GB的NVIDIA GTX 1070 GPU,CUDA版本為10.1。實驗階段,將所提算法在Market-1501[20]和DukeMTMC-reID[21]數據集上進行實驗驗證,并將其與目前較新的幾種行人重識別算法進行比較。
Market1501[20]數據集分為訓練集和測試集兩部分。訓練集包括12 963 張圖像對應751 個行人。測試集包括3 368 張查詢圖像和19 732 張圖庫圖像共對應750 個行人。DukeMTMC-reID[21]數據集同樣分為訓練集和測試集兩部分。訓練集包括16 522張圖像對應702個行人。測試集包括2 228張查詢圖像和17 661張圖庫圖像共對應702個行人。
訓練階段,輸入圖像的分辨率大小調整為256×128,batchsize選擇為64,包括16個不同行人且每人4張圖像。通過隨機水平翻轉、隨機擦除和歸一化策略進行數據增強。骨架網絡OSNet通過ImageNet數據集預先訓練的模型參數進行初始化。max_epoch(訓練總輪數)設置為150。使用Adam 優化本文模型,基礎學習速率初始化為3.5E-5。使用warmup策略預熱學習率激活網絡[22],初始學習率為0.000 3,為了保持損失的穩定下降,分別在epoch=60 和epoch=90 兩個階段設置學習率衰減點以實現指數衰減,衰減系數為gamma=0.1。
2.2 多分支聯合學習實驗結果
為了測試多分支聯合學習的有效性,本文分別在Market-1501 數據集和DukeMTMC-reID 數據集上進行了實驗驗證,結果分別如表1和表2所示。

表1 Market-1501數據集上不同分支的實驗結果Table 1 Experimental results with different branches on Market-1501 dataset 單位:%
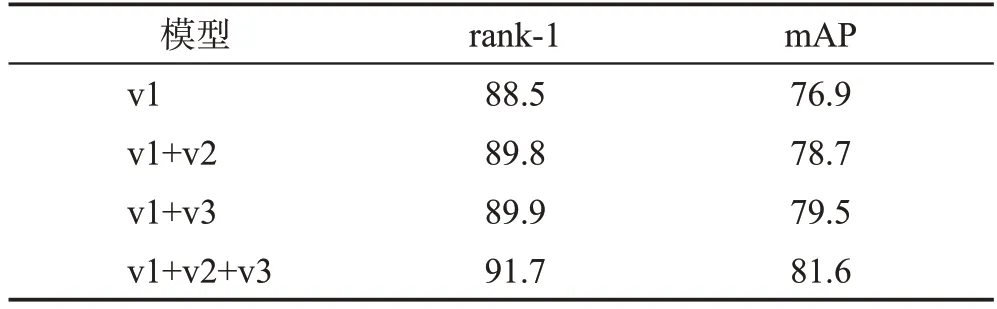
表2 DukeMTMC-reID數據集上不同分支的實驗結果Table 2 Experimental results with different branches on DukeMTMC-reID dataset 單位:%
對于Market-1501 數據集,對比兩分支聯合學習的模型,三分支聯合學習模型的rank-1精度分別提高2.3個百分點和1.1個百分點,mAP分別提高了1.8個百分點和0.6 個百分點。其中,兩分支(v1+v2)聯合學習的模型在加入異構特征提取模塊后,模型的rank-1 精度提高了2.3 個百分點,mAP 提高了1.8 個百分點。本文所提三分支模型相對全局單分支模型在rank-1精度上提升了3.3個百分點,在mAP上提升了3.6個百分點。
對于DukeMTMC-reID數據集,本文所提三分支模型對比兩分支聯合學習的模型,rank-1精度分別提升了1.9 個百分點和1.8 個百分點,mAP 分別提升了2.9 個百分點和2.1 個百分點。其中,兩分支(v1+v2)聯合學習的模型在加入異構特征提取模塊后,模型的rank-1 精度提高了1.9 個百分點,mAP 提高了2.9個百分點。相對全局單分支在rank-1 精度上提升了3.2個百分點,在mAP上提升了4.7個百分點。
結果表明,多分支聯合學習可以使模型學習到魯棒性更強的特征,異構特征提取模塊對于提取更加多樣化的特征效果明顯。
2.3 注意力機制的影響
本文將主流的注意力模塊添加到共享卷積網絡中,以使模型更專注于顯著性較強的特征,實驗結果如表3和表4所示。從表中數據可以得出,注意力模塊對模型性能的提升做出了貢獻,在Market-1501 數據集上rank-1精度提高了0.6個百分點,mAP提高了0.5個百分點;在DukeMTMC-reID數據集上rank-1精度提高了0.7個百分點,mAP提高了0.3個百分點。

表3 Market-1501數據集上注意力機制的實驗結果Table 3 Experimental results of attention modules on Market-1501 dataset 單位:%

表4 DukeMTMC-reID數據集上注意力機制的實驗結果Table 4 Experimental results of attention modules on DukeMTMC-reID dataset 單位:%
2.4 不同種類ID損失函數下的實驗結果
與PCB(part-based Conv baseline)[2]及其變體采用多重ID 損失不同的是,本文通過將多個關聯條紋特征向量串聯為一個新的特征向量,并用單一ID 損失函數進行監督優化。多重ID損失的利用使模型中ID 損失的數量等于分割條紋的數量,好處在于可能迫使每個條紋特征向量使用帶有身份標簽的數據集在每個指定的局部區域學習特征,但缺點在于某些條紋特征向量可能無法產生可靠的ID預測。
以Market-1501數據集上三分支聯合學習模型為例,如表5所示,單一ID損失下的模型相比多重ID損失下的模型在rank-1 精度上提升了1.9 個百分點,在mAP 上提升了3.6 個百分點。同理在DukeMTMCreID數據集上,如表6所示,單一ID損失下的模型相比多重ID 損失下的模型在rank-1 精度上提升了1.8個百分點,在mAP上提升了3.8個百分點。實驗結果表明,單一ID損失函數在本文所提模型中的表現更好。

表5 Market-1501數據集上不同損失函數實驗結果Table 5 Experimental results with different losses on Market-1501 dataset 單位:%

表6 DukeMTMC-reID數據集上不同損失函數實驗結果Table 6 Experimental results with different losses on DukeMTMC-reID dataset 單位:%
2.5 與現有方法的比較
表7和表8所示為本文網絡模型與其他一些網絡模型的性能比較,包括MGN[3]、OSNet[11]、SONA(secondorder non-local attention networks)[23]、Auto-ReID[24]、Bag Of Tricks[25]、St-ReID(spatial temporal ReID)[26]、MHN(mixed high-order attention network)[27]、CAMA(class activation maps augmentation network)[28]和IAN(interaction and aggregation network)[29]。所有結果中St-ReID 模型表現最好,但是該算法需要獲取行人圖像的時間和空間信息,而行人數據集包含的時空信息量巨大,訓練過程占用較多的資源且花費時間較長,使得計算效率較低。本文方法在兩個公開數據集上展示了較強的魯棒性和判別力。在Market-1501數據集上得到的rank-1 精度和mAP 分別為96.7%和89.5%;在DukeMTMC-reID 數據集上得到的rank-1精度和mAP分別為91.7%和81.6%,顯著優于其他方法。結果表明,本文構建的模型不僅繼承了OSNet的輕量級特性,而且顯著提升了重識別的精度。圖7展示了本文方法在Market-1501測試集上的部分測試結果,并與OSNet 模型的測試結果進行了比較,實驗結果表明本文模型具有較好的特征映射性能。
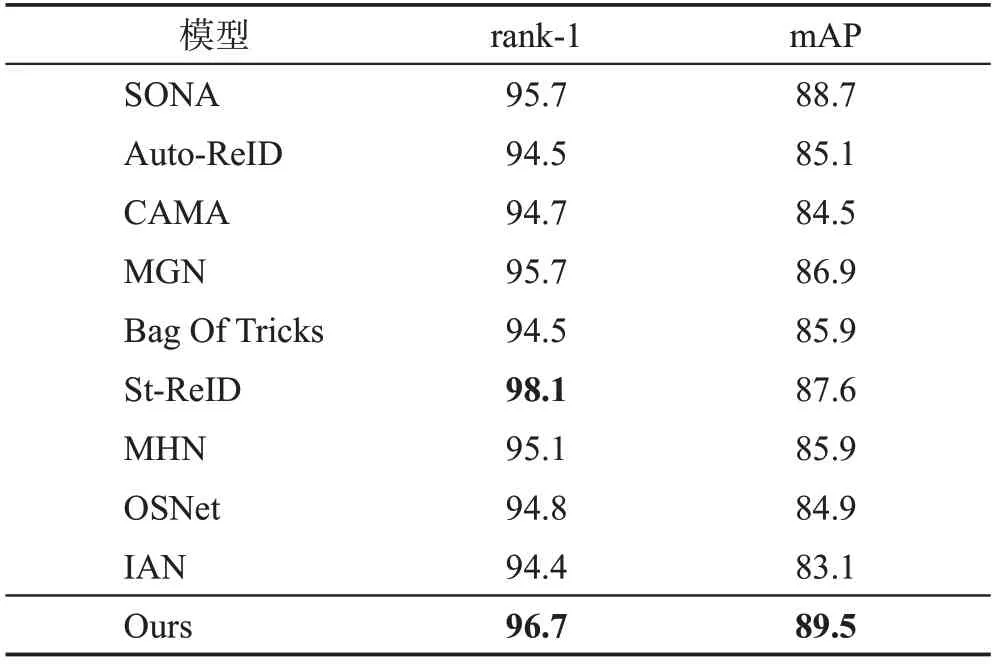
表7 在Market-1501數據集上與主流算法的比較Table 7 Comparison with mainstream algorithms on Market-1501 dataset 單位:%

表8 在DukeMTMC-reID數據集上與主流算法的比較Table 8 Comparison with mainstream algorithms on DukeMTMC-reID dataset 單位:%
3 結束語
本文提出了一種基于異構分支關聯特征融合的行人重識別算法。使用條紋特征關聯模塊,綜合了位于條紋間的關聯信息;加入異構特征提取分支,增加了網絡模型學習差異特征所需的結構多樣性;結合注意力機制,使網絡模型學習顯著性和區分性更強的行人關鍵特征;采用單一ID 損失函數對條紋特征關聯模塊進行監督,避免特征的錯誤學習,并提高預測的可靠性。本文將該算法分別在Market-1501和DukeMTMC-reID 數據集上進行有效性實驗驗證。實驗結果表明,該算法能夠有效提高行人重識別的準確度。
實驗過程中,全局分支對整幅圖像提取特征時會受到復雜背景的影響以及前景遮擋的干擾。在今后的研究過程中,將考慮結合人體骨骼姿態圖以進一步提升模型的行人重識別能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
