輕量化雙通道圖像語(yǔ)義分割模型
2022-11-16 02:03:04姬壯偉
姬壯偉
(長(zhǎng)治學(xué)院計(jì)算機(jī)系,山西長(zhǎng)治 046011)
語(yǔ)義分割是當(dāng)下熱門研究領(lǐng)域,在如今智能化的社會(huì)中,多個(gè)領(lǐng)域都有廣泛的應(yīng)用,自動(dòng)駕駛中對(duì)路況的語(yǔ)義分析,地理信息中對(duì)不同地形的語(yǔ)義理解,醫(yī)學(xué)影像中對(duì)細(xì)胞和組織的語(yǔ)義分割等,這對(duì)分割模型的分割進(jìn)度和分割效率都有很高的要求[1-7]。
分割模型的設(shè)計(jì)起初使用了很多方法去提高分割的精度,F(xiàn)CN 首次像素級(jí)別端到端的對(duì)圖像進(jìn)行分割,并將底層特征和淺層特征融合上采樣提高分割效率;SegNet 引起嚴(yán)格對(duì)稱編解碼結(jié)構(gòu)模型的熱潮;DeepLab 提出多尺度特征融合和空洞卷積,將分割精度提至空前的高度。但同時(shí)模型的深度越來(lái)越深,復(fù)雜度越來(lái)越高,參數(shù)量越來(lái)越大,分割效率很低,難以應(yīng)用在諸多移動(dòng)設(shè)備的應(yīng)用環(huán)境中。
保證模型的分割精度需同時(shí)可以提取原圖的空間信息和上下文信息,空間信息在卷積網(wǎng)絡(luò)的淺層,能有效的對(duì)各分割對(duì)象進(jìn)行分割定位,但由于淺層網(wǎng)絡(luò)感受野小,上下文信息不全,難以準(zhǔn)確的對(duì)分割對(duì)象進(jìn)行分類,而對(duì)于卷積網(wǎng)絡(luò)的深層,通過(guò)多次下采樣獲得了對(duì)原圖像足夠大的感受野,提取了分割對(duì)象的語(yǔ)義,但相對(duì)的,同時(shí)丟失了分割對(duì)象的空間信息,難以定位分割對(duì)象邊界。模型對(duì)原圖像的特征提取分為兩條路徑,即空間特征提取路徑和上下文信息提取路徑,最后融合圖像的空間和上下文信息,上采樣完成端到端的圖像分割預(yù)測(cè)。同時(shí)為了減少模型的參數(shù)量,每次常規(guī)卷積之前,都使用1×1 卷積減少通道數(shù),并通過(guò)全局池化搭建殘差通達(dá),降低模型的過(guò)擬合。
使用camvid 數(shù)據(jù)集進(jìn)行測(cè)試,在驗(yàn)證集和測(cè)試集分別得到了59.3%和58.6%的MIOU,參數(shù)量?jī)H為5.8 M,F(xiàn)PS 可達(dá)到15.2,相比DeepLab 經(jīng)典分割模型,精度雖然降低了幾個(gè)百分點(diǎn),但參數(shù)量降低了94%。
1 數(shù)據(jù)集
Camvid 數(shù)據(jù)集是一個(gè)關(guān)于道路和駕駛場(chǎng)景的數(shù)據(jù)庫(kù),最初是通過(guò)安裝在汽車儀表板上的960×720 分辨率攝像頭捕獲的五個(gè)視頻序列,其中一個(gè)用1 fps 的速度,剩余四個(gè)用15 fps 的速度對(duì)序列采樣共701 幀。該數(shù)據(jù)集共32 個(gè)分割對(duì)象類別,依次用手動(dòng)注釋,如建筑物、墻壁、樹、人行道、標(biāo)志、行人、汽車等。
2 語(yǔ)義分割模型架構(gòu)
2.1 架構(gòu)
分割模型架構(gòu)如圖1所示,分兩條路徑對(duì)原圖像進(jìn)行特征提取。左邊為空間位置信息提取路徑,對(duì)原圖像進(jìn)行3 次2 倍下采樣,得到分割對(duì)象空間位置特征圖;右邊為上下文信息提取路徑,對(duì)原圖像進(jìn)行4 次4 倍快速下采樣,得到分割對(duì)象上下文語(yǔ)義信息分割圖,相比原圖像,特征圖縮小32 倍,保證了足夠的感受野大小,保留了分割對(duì)象的語(yǔ)義信息。在兩種不同特征圖融合階段,首先將語(yǔ)義信息特征圖進(jìn)行4倍上采樣至同樣尺寸大小,再和空間信息特征圖做相加融合,最后上采樣至原圖像大小進(jìn)行輸出測(cè)試分割效果圖。
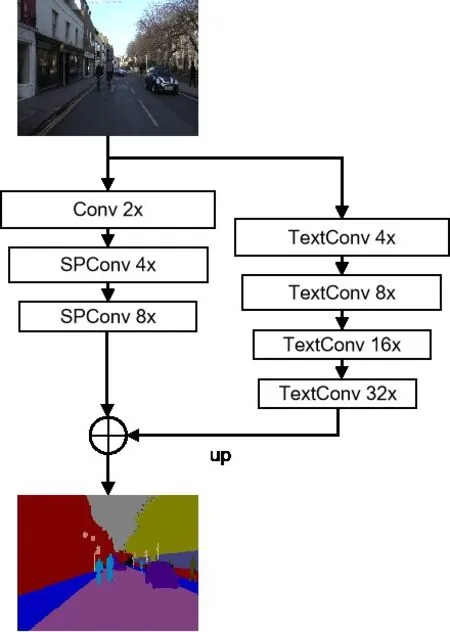
圖1 雙路徑模型架構(gòu)圖
語(yǔ)義分割需要模型完成兩個(gè)任務(wù),即分割對(duì)象的定位和分類。空間路徑主要為定位任務(wù),由于下采樣次數(shù)少,分割對(duì)象基本保留原有的空間位置信息,在上采樣還原時(shí)能確保分割對(duì)象的空間位置正確;上下文路徑主要為分類任務(wù),特征圖是經(jīng)過(guò)多次下采樣生成,對(duì)原圖像像素具有足夠大的感受野,各分割對(duì)象之間的聯(lián)系信息幫助判斷分割對(duì)象的所屬類別,保留了足夠多的分割對(duì)象語(yǔ)義信息幫助判斷類別。通過(guò)融合空間和上下文信息,提高模型的分割精度。
2.2 模型參數(shù)量?jī)?yōu)化
卷積操作的參數(shù)量取決與卷積核的大小,在卷積操作中,通常圖像尺寸縮小一倍,通道數(shù)便增加一倍,通道數(shù)的急劇增加將導(dǎo)致模型參數(shù)量劇增。因此專門設(shè)計(jì)空間和上下文路徑的卷積操作,如圖2 所示,SPConv 為空間路徑卷積模塊,可看出在真正卷積操作之前,首先使用1*1 卷積減少特征圖通道數(shù),卷積后再使用1*1 卷積恢復(fù)通道數(shù);除此之外,在卷積路徑外另加殘差路徑,殘差路徑僅使用最大值池化減低圖像分辨率,以此來(lái)防止模型的過(guò)擬合。TextConv 為上下文路徑卷積模塊,為了快速下采樣,每一個(gè)殘差路徑則對(duì)應(yīng)兩個(gè)連續(xù)的下采樣操作。
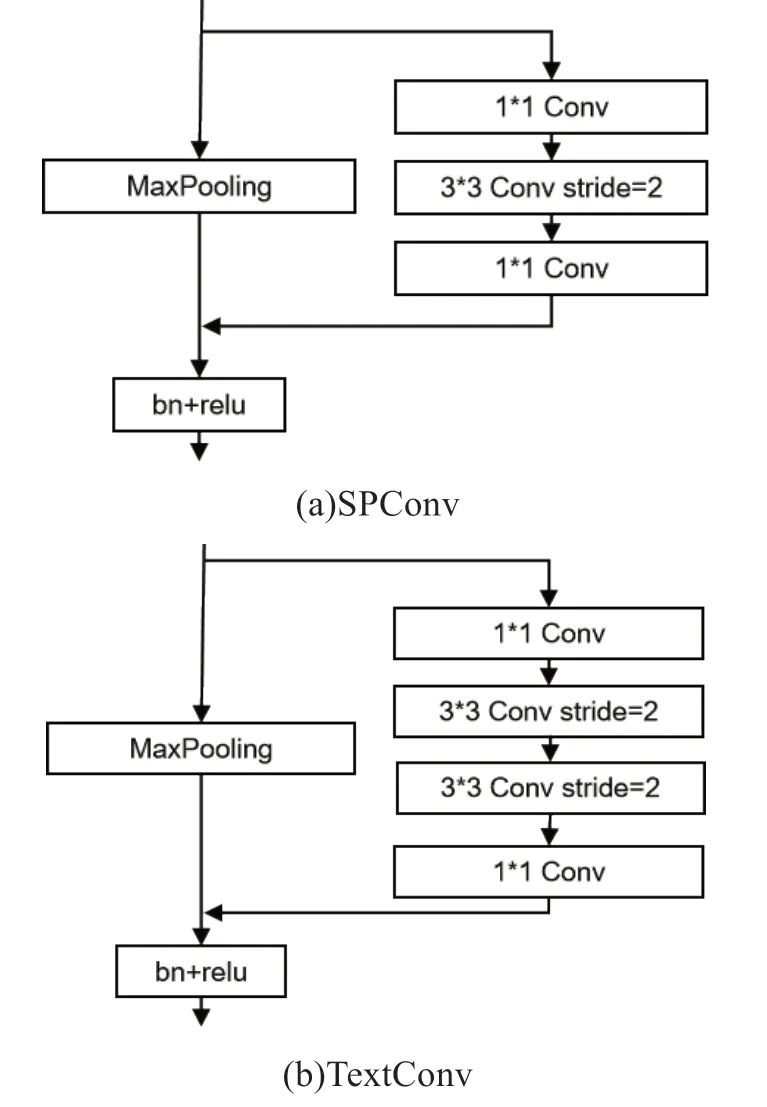
圖2 卷積模塊示意圖
3 實(shí)驗(yàn)論證
使用camvid 數(shù)據(jù)集分別訓(xùn)練單條路徑的編解碼模型和雙路徑模型,并分別使用驗(yàn)證集和測(cè)試集計(jì)算模型預(yù)測(cè)的MIOU,同時(shí)統(tǒng)計(jì)各模型的參數(shù)量等信息。兩種模型實(shí)驗(yàn)同時(shí)在RTX3080 設(shè)備上進(jìn)行,統(tǒng)計(jì)兩種模型的信息如表1 所示,從表中可以看出,雖然雙路徑模型的分割精度相比下降了將近5 個(gè)百分點(diǎn)左右,但參數(shù)量減少了94.8%,每秒分割圖像幀率也得到了顯著提高,足以應(yīng)用在很多移動(dòng)設(shè)備分割環(huán)境之中。
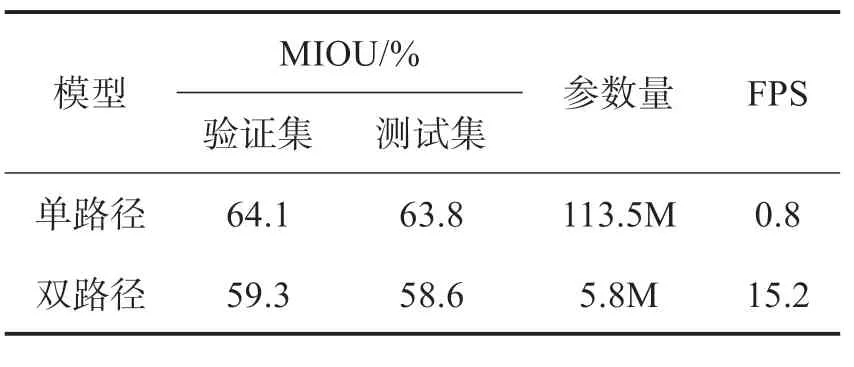
表1 單雙路徑模型對(duì)比表
4 結(jié)論
所提出的語(yǔ)義分割模型以輕量化為目的,使用單點(diǎn)卷積精簡(jiǎn)網(wǎng)絡(luò)模型參數(shù),同時(shí)為了應(yīng)對(duì)參數(shù)量下降帶來(lái)的分割精度降低的問(wèn)題,設(shè)計(jì)了兩條路徑分別提取分割對(duì)象的空間位置信息和語(yǔ)義信息,保證模型的分割精度在可接受范圍。通過(guò)實(shí)驗(yàn)證明所提模型可在保證精度的前提下,極大減少模型復(fù)雜度,提高分割效率。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
