注意力金字塔卷積殘差網絡的表情識別
2022-11-20 13:57:12陳加敏
計算機工程與應用 2022年22期
關鍵詞:特征
陳加敏,徐 楊,2
1.貴州大學 大數據與信息工程學院,貴陽 550025
2.貴陽鋁鎂設計研究院有限公司,貴陽 550009
近年來人臉表情識別在情感分析方面的研究取得了較大的進步,成為情感分析的關鍵技術之一。面部表情中含有豐富的特征信息,Mehrabian等人[1]的研究表明,在人類的日常溝通與交流中,表情所占有的信息高達55%,而語言所占有的信息僅含7%。因此,高效地提取表情特征更有利于人機交互過程。面部表情是指通過臉部肌肉塊的變化而表現出來的情緒,不同運動單元的變化產生了不同的情緒。Ekman等人[2]將表情分為憤怒、厭惡、驚訝、高興、悲傷、恐懼。在其研究基礎上,基于運動單元的面部動作編碼系統(facial action coding system,FACS)被提出,FACS主要通過分析運動單元的運動特征來說明與之聯系的相關表情。
人臉表情識別的關鍵步驟可分為圖像獲取、人臉檢測、特征提取、特征分類。其中特征提取是人臉表情識別中最為關鍵的一步,直接影響表情識別的效果。Gu等人[3]提出了全局特征與局部特征相結合提高整體特征表現力的表情識別方法。Yan等人[4]將原始人臉圖像與LBP圖像結合,將其輸入連續卷積提取高級語義特征,并將提取的特征進行下采樣處理提高表情識別準確率。Zeng等人[5]建立了深度稀疏自編碼(deep sparse autoencoder,DSAE),通過學習魯棒性和判別性特征,實現了對人臉表情的高精度識別。亢潔等人[6]將特征分組并建立空間增強注意力機制,突出表情特征重點區域。柳璇等人[7]將灰度圖、局部二值模式特征、Sobel特征進行融合提高特征表現力。由此可見,現有的深度學習模型大多從特征提取維度進行改進來提高表情識別準確率。
近年來,隨著深度學習的不斷發展,卷積神經網絡在圖像特征提取方面展現了顯著的優勢,可通過增加網絡的深度或者寬度來提取更為高級的語義特征。Wang等人[8]通過增加卷積神經網絡的深度和寬度來增強特征提取能力,將高層次與低層次的特征行融合,取得了較好的表情識別效果。不同的表情之間具有細微的差異信息,若模型只關注人臉表情的少數特征,就很可能預測出錯誤的類別。因此,融合多尺度特征尤為重要。具有競爭力的多尺度特征融合方法如下:早期的網絡架構AlexNet[9]和VGGNet[10]通過堆疊卷積運算符,但是過度地堆疊網絡的層數會出現梯度消失以及梯度爆炸[11-12]等問題;InceptionNets[13]通過使用不同內核大小的卷積,增加網絡的寬度,提高多尺度特征提取的能力,增加寬度能在一定程度上提高效率,但是仍存在局限性,過度增加寬度會出現過擬合等問題;ResNet[14]通過使用殘差模塊的跨層連接有效地解決了網絡梯度消失和梯度爆炸的問題,使得網絡的層數可以達到上千層;金字塔卷積(pyramidal convolution,PyConv)[15]通過堆疊不同大小的卷積核擴大感受野,具備細化特征的優勢,在圖像分類、目標檢測等圖像識別的基本任務中都取得了顯著的優勢。注意力機制將關鍵部分分配較高的權重,SENET[16]作為最后一屆ImageNet分類比賽的冠軍,只是在通道維度上標注注意力權重;卷積塊注意模塊(convolutional block attention module,CBAM)[17]是一種從通道和空間維度進行雙重特征權重標定的卷積注意力機制模塊,其依據多方向的特征增強改善網絡識別效果。
為了更好地提取面部表情中眼、眉、口等部位的局部變換特征,本文以殘差網絡為主要框架,融合金字塔卷積模塊和CBAM模塊中的通道注意力(channel attention,CA)以及空間注意力(spatial attention,SA),提出一種注意力金字塔卷積殘差網絡(attention PyConv ResNet,APRNET)。該網絡分為兩個子模塊,分別是PyConv-CAblock和PyConv-CSneck模塊,在網絡中將PyConv-CAblock替換殘差網絡中的基礎模塊(basicblock),將PyConv-CSneck替換殘差網絡的瓶頸模塊(bottleneck)。該網絡將金字塔卷積、通道注意力和空間注意力融合在一起,在提取多尺度全局信息的同時有效地突出重點區域。實驗證明該模型有效地提高了表情識別的性能,在CK+[18]和FER2013[19]數據集上準確率可達94.949%和73.001%,相比于現在的表情識別方法具有較大的優勢。本文的主要貢獻如下:
(1)在表情識別中,結合金字塔卷積的不同大小和深度的卷積核獲取具有細節信息的全局特征,捕獲面部表情圖像的細微差異。
(2)嵌入通道注意力以及空間注意力機制模塊來學習具有判別性的局部特征,突出了表情識別的重點特征區域。模型在公共數據集CK+和FER2013上進行實驗,驗證注意力金字塔殘差網絡的競爭性。
1 金字塔卷積
金字塔卷積(PyConv)包含不同大小和深度的卷積核,可提取多尺度信息。如圖1所示,從Level 1到Leveln卷積核大小依次增大,深度依次減小,為了能夠在PyConv的每個級別上使用不同深度的內核,借鑒分組卷積,如圖2所示,將輸入特性映射分成不同的組,并為每個輸入特性映射組獨立地應用內核。與標準卷積圖3相比,標準卷積僅包含單一的核,卷積核的空間分辨率為K21,而深度則等于輸入特征通道數FMi。那么執行FMo個相同分辨率與深度卷積核,得到FMo個輸出特征。因此,標準卷積的參數量與計算量分別為:
金字塔卷積將輸入的特征劃分為不同的組獨立地進行卷積計算。假設金字塔卷積的輸入包含FMi個通道,PyConv每一層卷積核尺寸為K21,K22,…,K2n,深度為FMi,FMi/(K22/K21),…,FMi/(K2n/K21),對應的輸出特征維度為FMo1,FMo2,…,FMon基于上述的描述,可以得出,金字塔卷積的參數量和計算量分別為:
FMo1+FMo2+…+FMon=FMo時,式(3)中每一行表示PyConv中某個Level的參數量和計算成本,如果每個Level輸出相同參數量的特征映射,則PyConv的參數數量和計算代價沿每一級金字塔均勻分布。在這個公式中,無論PyConv的Level有多少,無論核空間大小K21持續增加到K2n,其計算代價和參數數量都與單個核大小K21的標準卷積相似。
2 本文方法
本文以ResNet網絡作為基礎網絡,將通道注意力和空間注意力融入金字塔卷積模塊,得到注意力的金字塔卷積殘差網絡。受文獻[12]的啟發,本文在PyConv之后依次加入通道注意力和空間注意力構成PyConv-CSblock和PyConv-CSneck模塊,PyConv-CSblock由一個金字塔卷積、通道注意力、空間注意力以及1×1卷積構成,PyConv-CSneck由一個金字塔卷積、通道注意力、空間注意力以及兩個1×1卷積組成,如圖4所示。
在本文中,模型的框架分為4個Layer,每個Layer由不同參數的PyConv連接構成,根據參數的不同將其分為PyConv18和PyConv50,具體參數情況如表1所示。
若金字塔卷積提取的特征為F∈RH×W×C(H為高度,W為寬度,C為通道數),對其在通道和空間上分配注意力權重,使得所提取的人臉表情特征能夠聚集于眼睛、眉毛、嘴巴等人臉表情的關鍵部位,提升表情識別的特征提取能力,從而提高表情識別的準確率。將模型APRNET應用于表情識別具體結構如圖5所示(以APRNET50為例)。首先,使用一個7×7的卷積提取圖像的特征信息。其次,參照ResNet的網絡結構,用PyConv-CSblock替換ResNet中的basicblock,用PyConv-CSneck替換殘差網絡中的bottleneck,PyConv-CSblock和PyConv-CSneck中的PyConv提取多尺度特征信息,CA和SA分別在通道維度與空間維度分配注意力權重,獲取具有判別性的局部細節信息,突出人臉表情關鍵部位的特征表現力。分別通過4個不同的Layer堆疊構成APRNET18和APRNET50,不同Layer的PyConv由不同尺度的卷積核堆疊而成,具體參數如表1所示,最后使用一個全連接層作為分類器進行表情識別。

表1 金字塔卷積模塊參數Table 1 Pyramid convolution module parameters
2.1 融入通道注意力
在人臉表情識別中,表情與特定區域的特征有較大的相關性。金字塔卷積可以很好地將人臉表情圖像中的特征提取出來,注意力模型可以提高特定區域特征的表征能力,聚焦重要的特征,抑制不必要的特征。為進一步提高表情識別準確率,本文將通道注意力融入金字塔卷積之后,將金字塔卷積所提取的特征在通道維度標注權重,提高了通道維度具有判別性的局部特征的表現力,通道注意力模塊如圖6所示。假設金字塔卷積提取的特征為F∈RH×W×C,首先將金字塔卷積特征經過最大池化以及平均池化后得到兩個不同的空間描述特征Fcmax和Fcavg,然后將兩個空間描述特征經過一個共享網絡后將其相加得到通道注意力權重系數Mc∈RC×1×1,共享網絡由包含一個隱層神經元的三層感知機組成,然后將Mc與F相乘得到通道注意力圖。
其中,F為金字塔卷積輸出的特征,σ為sigmoid操作,Mc為通道注意力權重。
2.2 融入空間注意力
空間注意力是對通道注意力的一個補充,利用特征間的空間關系生成空間注意圖,如圖7所示。首先利用池化操作的聚合功能在通道軸上應用最大池化和平均池化各生成一個有效的特征描述符,分別為F′max和F′avg,然后使用torch中的cat函數將兩者進行橫向拼接后將其放入7×7的卷積降為一個通道,在經過sigmoid生成空間注意力權重Ms∈RC×1×1,再將Ms與F′相乘得到F′。
其中,Ms為空間注意力權重,F′是經過通道注意力模塊后的特征輸出,F′是經過空間注意力模塊后的特征輸出圖。
將空間注意力模塊嵌入通道注意力之后,該方法可將金字塔卷積提取的特征依次在通道和空間維度推斷注意力圖,增強表情中具有判別性的局部特征的通道維度信息和空間維度信息,從而提高表情識別準確率。
3 實驗結果及分析
本文對所提方法進行了對比實驗驗證,實驗平臺是Ubuntu16.04 LTS系統,實驗環境python3.5,在深度學習框架PyTorch1.0上使用具有11 GB顯存的NVIDIA GeForce GTX 1080Ti實現。本文在FER2013和CK+公開人臉表情數據集上對所提模型進行實驗,并與之前的工作進行對比分析。
3.1 數據集與實驗設置
本文選擇FER2013、CK+數據集。FER2013數據集是由International Conference on Machine Learning(ICML)2013挑戰產生,是目前較大規模的表情識別數據集,包含28 709張圖片,7種表情分類標簽,其中測試集分為公有測試集和私有測試集,數量均為3 589。CK+數據集包含從123個對象中提取的593視頻序列,這些序列持續時間從10幀到60幀不等,展示了從中性臉表情到高峰表情的轉變,選擇帶有標記的327個序列的最后3幀共981張圖片。FER2013、CK+的像素值均為48×48,它們的數據分布圖分別如圖8所示。
3.2 模型性能分析
表2為本文所提方法在FER2013公有數據集(Public)和私有測試集(Private)上的實驗結果。在訓練過程中,數據的擴充采取隨機裁剪以及水平翻轉操作,其中裁剪大小為44×44,權重更新使用隨機梯度下降,動量設置為0.9,初始學習率為0.1,從迭代50次開始每增加5次學習率以0.9的速率下降,總迭代次數為250。

表2 FER2013實驗結果Table 2 FER2013 experimental result
PyConv18是將金字塔卷積模塊融入ResNet18,PyConv18+CA是在PyConv18的基礎上嵌入通道注意力,PyConv18+SA是在PyConv18的基礎上嵌入空間注意力,APRNET18是在PyConv18的基礎上同時嵌入通道注意力和空間注意力。
PyConv50是將金字塔卷積模塊融入ResNet50,PyConv50+CA是在PyConv50的基礎上嵌入通道注意力,PyConv50+SA是在PyConv50的基礎上嵌入空間注意力,APRNET50是在PyConv50的基礎上同時嵌入通道注意力和空間注意力。
將APRNET18、APRNET50在私有數據集測試結果用混淆矩陣表示,如圖9所示。
從表2可以看出:APRNET18在私有測試數據集上表情識別準確率相比于PyConv18增加了2.953個百分點,相比于PyConv18+CA和PyConv18+SA分別增加了2.229個百分點和2.730個百分點。APRNET50在私有測試數據集上表情識別準確率相比于PyConv50增加了2.062個百分點,相比于PyConv50+CA和PyConv50+SA分別增加了1.198個百分點和0.139個百分點。本文所提出的APRNET50獲得了較好的表情分類結果,達到73.001%。由此可見,本文選取金字塔卷積作為特征提取部分,能夠獲得較好的分類結果。這是由于金字塔卷積能夠提取多尺度的細節特征信息,注意力模塊能夠提取具有判別性的局部特征,殘差結構能夠將層間的相關性很好地結合起來。
從圖9可以看出,高興和驚訝的表情識別結果明顯高于其他,而悲傷、害怕、厭惡、生氣的準確率較低,因為這四者在一定程度上存在相似的特征,在生活中,人眼也很難區分。其中害怕的準確率最低,出現這個問題的原因可能是數據集的分布不均勻,從數據分布圖來看,害怕類的數據明顯低于其他。
為驗證本文所提網絡模型的有效性,將FER2013私有測試集中訓練的模型保存,并在網上隨機選取圖像運用該模型進行人臉表情識別,識別結果如圖10所示。
3.3 對比實驗
為證明本文所提方法的有效性,將本文所提模型應用于CK+數據集,結果如表3所示。在訓練過程中,數據的擴充采取隨機裁剪以及水平翻轉操作,其中裁剪大小為44×44,權重更新使用隨機梯度下降,動量設置為0.9,初始學習率為0.1,從迭代20次開始每增加5次學習率以0.9的速率下降,總迭代次數為100。

表3 CK+實驗結果Table 3 CK+experimental result
從表3可以得出,APRNET18相比于PyConv18的識別準確率提高了3.535個百分點,APRNET50相比于PyConv50的識別準確率提高了5.050個百分點。
為進一步說明本文所提方法的有效性,選取了近幾年最新的表情識別算法在FER2013上進行對比分析,這些方法包括SHCNN[20]、Zhou[21]、Gan[22]、Parallel CNN[23]、CNN[24]、Liang[25]。文獻[20]通過一個含有三個卷積層的淺層網絡來抑制過擬合以及梯度爆炸等問題,在訓練FER2013數據集時采用0.001的學習率;文獻[21]通過對Softmax函數的改進來提取更加具有區分力的特征,在訓練過程中動量設置為0.9,權值衰減為0.000 5,批處理大小為512,初始學習率設置為0.1;文獻[22]在卷積層嵌入注意力模塊進行識別;文獻[23]設計兩個并行卷積池化結構,并行提取三種不同圖像特征;文獻[24]在VGG的基礎上卷積核的大小從3改為8,一種卷積核的數量設置為固定值32,另一種卷積核的數量設置為變量,分別為32、16、8,通過對卷積核大小和數量的更改提出了兩種網絡結構;文獻[25]將深度可分離卷積和壓縮激發模塊相結合,提出了一種輕量型的卷積神經網絡結構提取特征,在訓練過程中批處理大小為32,初始學習率為0.1。將文獻[26-28]的結果與本文所提方法在CK+數據集進行對比。文獻[26]提出了一種新的人臉表情識別方法,該方法利用圖像預處理技術去除不必要的背景信息,并將深度神經網絡ResNet50與傳統的支持向量機多類模型相結合進行人臉表情識別;文獻[27]提出一個重點發現感興趣區域的表情識別框架;文獻[28]提出一個新的DNN模型識別表情。對比結果如表4所示。
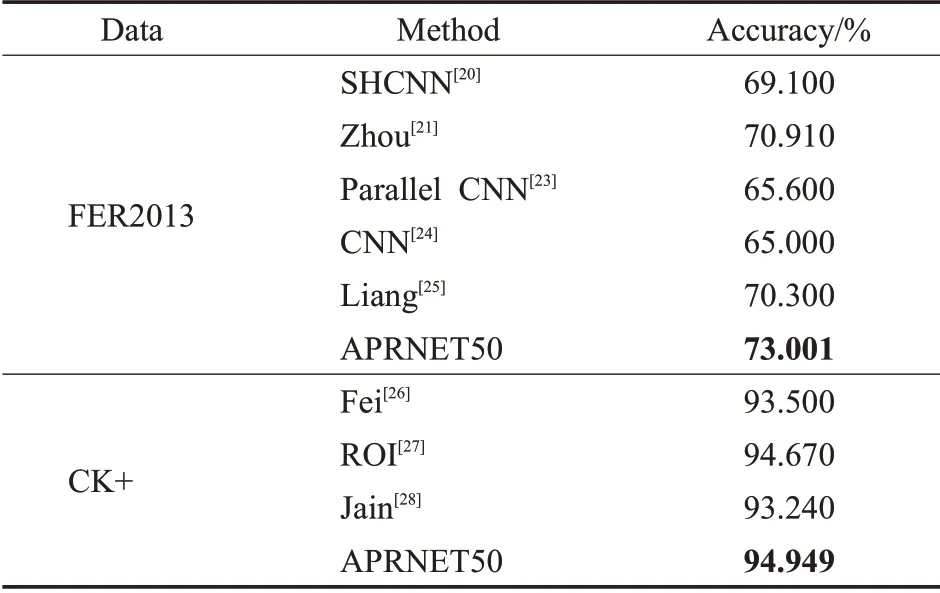
表4 對比結果Table 4 Comparison result
從表4可以看出,本文所提的方法在FER2013數據集上比CNN方法提高了8.001個百分點,比Zhou等人所提的方法也高出了2.091個百分點,在CK+上識別準確率相比于Fei提高了1.499個百分點,相比于ROI提高了0.279個百分點,相比于Jain提高了1.709個百分點。可見本文方法的識別準確率具有競爭性的優勢。
4 結束語
本文提出了一種新的網絡模型APRNET50用于人臉表情識別,該方法可以實現多尺度特征融合以及定位人臉表情的關鍵部位。其中金字塔卷積可以很好地提取多尺度特征信息,注意力模塊可以定位人臉的關鍵部位,充分地利用關鍵部位的詳細信息對于人臉表情識別來說尤為重要。以端到端的方式在公開人臉表情數據集FER2013以及CK+上設計了對比實驗來評估本文模型,結果表明,本文方法有效地提高了表情識別的效率。
接下來,將考慮如何將特征深入地進行融合,以及對表情識別進行深入的研究,將本文方法應用到現實場景中進行表情識別,以提高表情識別的利用率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
