基于非負矩陣分解的修正模糊聚類算法
2022-11-20 13:25:24李向利范學珍逯喜燕
吉林大學學報(理學版) 2022年6期
關鍵詞:實驗
李向利, 范學珍, 逯喜燕
(桂林電子科技大學 數(shù)學與計算科學學院, 廣西 桂林 541004)
聚類算法主要包括層次化聚類算法、 劃分式聚類算法、 基于密度的聚類算法和基于網(wǎng)絡的聚類算法[1-2]. 基于劃分聚類算法的模糊聚類由于引入了模糊概念并擴展了硬聚類隸屬度的取值范圍[3-5], 有更好的聚類效果與數(shù)據(jù)表達能力, 因此已成為目前聚類分析中的研究熱點[6-8].
由于傳統(tǒng)的模糊C-均值[9](fuzzyC-means, FCM)算法存在對初始值敏感及收斂速度慢等缺點, 因此已提出了許多FCM改進算法. Hung等[10]通過對FCM算法的初始值進行細化, 提出了一種高效聚類的psFCM算法; 文獻[11]提出了一種基于梯度的模糊C-均值(gradient-based fuzzyC-means, GBFCM)算法, 該算法利用梯度下降提高收斂速度和穩(wěn)定性; 針對非常大的數(shù)據(jù), Havens等[12]提出了LFCM和rseFCM算法, 通過核技巧的非線性聚類和放松收斂條件減少聚類復雜度; Krinidis 等[13]將局部空間信息和灰度信息以一種新的模糊方式相融合, 提出了模糊局部信息C-均值算法(fuzzy local informationC-means algorithm, FLICM); Zhou等[14]結合三角不等式, 提出了一種新的隸屬度模糊C-均值聚類算法(new membership fuzzyC-means clustering algorithm, MSFCM), 減少了運算時間, 但該算法并不適用于高維度數(shù)據(jù). 上述算法在解決復雜結構的高維度數(shù)據(jù)聚類問題時會出現(xiàn)大規(guī)模計算量導致聚類效果下降. 基于此, 本文提出一種基于非負矩陣分解(NMF)的修正模糊聚類(MFCM)算法(modified fuzzy clustering algorithm based on non-negative matrix factorization, MFCM-NMF), 該算法利用NMF進行降維, 并通過NMF提取數(shù)據(jù)的本質特征, 保留作為模糊聚類的聚類中心, 將NMF與MFCM相結合提出了新的目標函數(shù), 并采用交替迭代算法進行求解, 且在迭代過程中基于三角不等式過濾出在下一次迭代中不改變其最近聚類中心的樣本, 采用新的隸屬度更新公式, 減少計算量, 提高聚類性能.
1 預備知識
1.1 非負矩陣分解
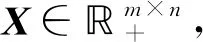
目前, 常用的重構誤差構造主要使用歐氏距離和KL(Kullback-Leibler)散度.一般情況下, 采用基于歐氏距離的目標函數(shù):
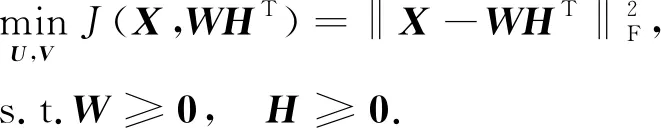
(1)
同時求解U和V時, 上述兩種目標函數(shù)下的優(yōu)化問題是非凸的, 但單獨針對U或V求解時, 該問題即為凸的.采用乘性迭代規(guī)則可解決該問題并證明其收斂性, 通過固定U或V使用乘性迭代規(guī)則的方法交替更新, 其更新迭代公式為
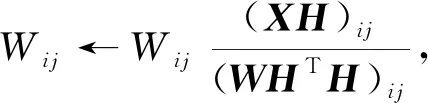
(2)
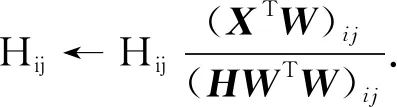
(3)
1.2 模糊C-均值聚類算法
模糊C-均值聚類算法[9]是一種基于劃分的聚類算法, 其基本思想是使被劃分到同一簇的對象之間相似度最大, 而不同簇之間的相似度最小. 模糊C-均值將n個樣本xi(i=1,2,…,n)分到c個簇中, 每個簇的聚類中心為wi(i=1,2,…,c), 而uik∈[0,1]表示對象xk屬于i類別的權重, 即可能性.利用隸屬度將目標函數(shù)描述為如下形式:
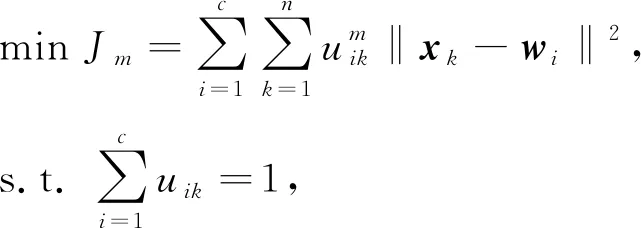
(4)
其中m為模糊加權指數(shù).迭代公式為
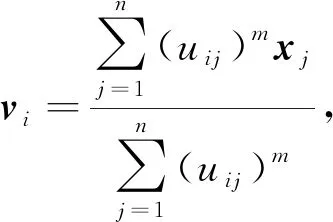
(5)
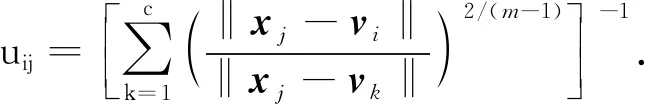
(6)
文獻[14]在FCM的基礎上引入了聚類中的三角不等式, 并給出了新的幾何解釋, 提出了一種新的隸屬度縮放方法, 其基本思想是利用三角不等式過濾出在下一次迭代中不改變其最近聚類的樣本, 根據(jù)一個放縮方案使簇內樣本的聯(lián)系增強, 簇外樣本的聯(lián)系減弱, 改進了傳統(tǒng)FCM算法計算量大、 收斂慢等缺點.
2 算法設計
2.1 目標函數(shù)
在較小矩陣上運行NMF算法可節(jié)省更多的時間和存儲空間, 但也可能破壞數(shù)據(jù)樣本間的本質結構, 影響聚類效果. 為減少負面影響, 本文希望在NMF壓縮樣本數(shù)據(jù)的過程中進行模糊聚類. 對于高維數(shù)據(jù), 通過NMF提取樣本的本質特征, 保留作為MFCM的聚類中心. 將NMF分解對原始數(shù)據(jù)樣本的影響加入到FCM的目標函數(shù)中. 最小化代價函數(shù)為
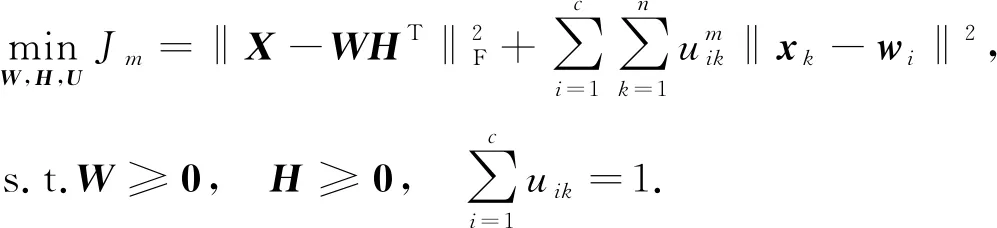
(7)
其中:m≥1;xk為矩陣X的第k列;uik∈[0,1]為隸屬度矩陣U第i行、 第k列對應的元素, 表示第k個樣本屬于第i個簇的可能程度;wi為矩陣W的第i列.
2.2 目標函數(shù)優(yōu)化求解
目標函數(shù)(7)中的第一項表示利用NMF算法處理原始數(shù)據(jù)的過程對聚類的影響程度, 第二項表示模糊C-均值對聚類的影響程度, 顯然目標函數(shù)是非凸的, 求出其全局最優(yōu)解不實際.因此, 利用交替迭代法則求解非凸函數(shù)的局部最優(yōu)解, 通過迭代下列步驟解決優(yōu)化問題, 直到收斂.
1) 若固定W和H, 通過uij最優(yōu)化J, 則uij的更新準則為
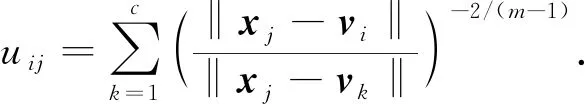
(8)
2) 若固定W和U, 通過H最優(yōu)化J, 則H的更新準則為
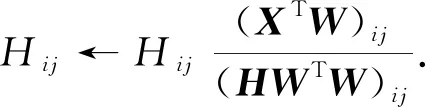
(9)
3) 若固定H和U, 通過W最優(yōu)化J, 則可將目標函數(shù)(7)改寫為
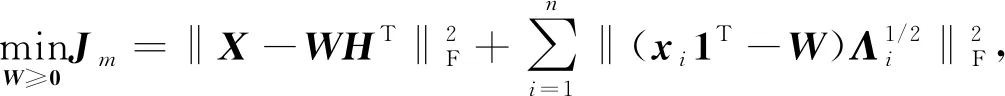
(10)
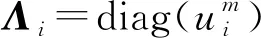
令φik為約束條件wik≥0的Lagrange乘子, 則目標函數(shù)(10)對應的Lagrange函數(shù)為
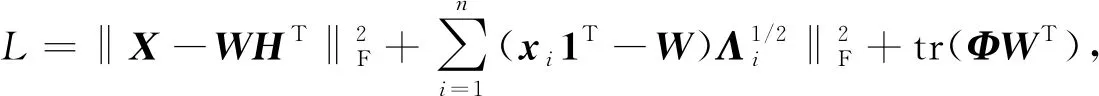
(11)
對W求偏導, 得
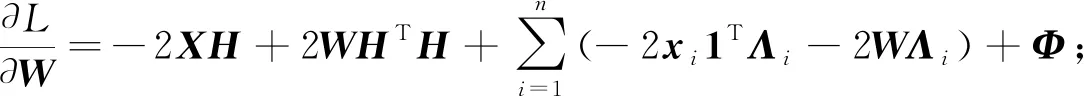
(12)
利用KKT(Karush-Kuhn-Tucker)條件φjkwjk=0(j=1,2,…,p,k=1,2,…,c), 可得
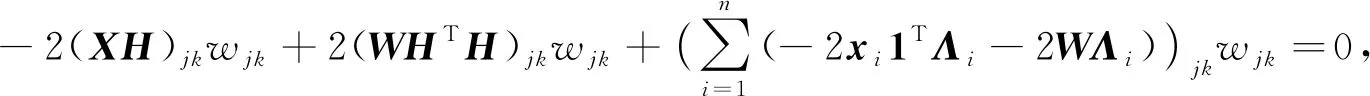
(13)
從而可得W的更新規(guī)則為
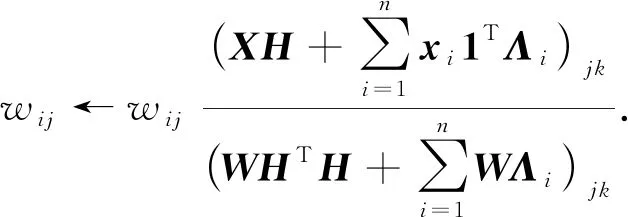
(14)
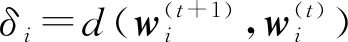
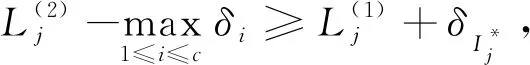
(15)
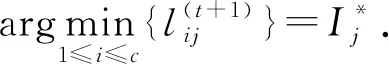
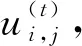
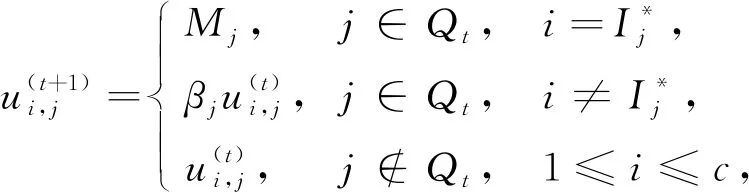
(16)
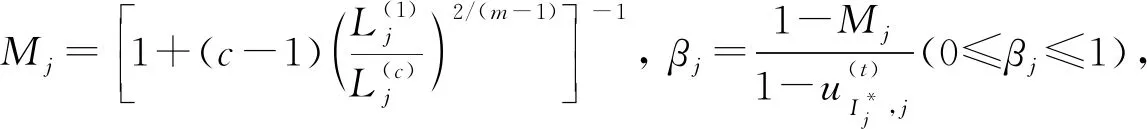
算法1MFCM-NMF算法.
輸入: 原始非負矩陣X, 模糊系數(shù)m, 聚類個數(shù)c;
輸出:U=U(t+1),V=V(t+1);
步驟1) 隨機初始化U(0),W(0),H(0), 并根據(jù)式(14)計算出W(1), 令t=1;
步驟3) 利用式(8)計算U(t);
步驟4) 利用式(9)計算H(t);
步驟7) 根據(jù)式(15)過濾樣本;
步驟8) 根據(jù)式(16)更新U(t+1);
步驟9) 根據(jù)式(16)更新H(t+1);
步驟10) 利用式(14)計算W(t+1);
步驟11) 若‖W(t+1)-W(t)‖≥ε, 則t=t+1, 返回步驟2), 否則停止.
3 實 驗
本文不僅在數(shù)據(jù)集UCI上進行實驗, 也在兩個圖像數(shù)據(jù)集和一個圖片數(shù)據(jù)集上進行實驗, 其中數(shù)據(jù)集UCI-satimage和UCI-wine來自于UCI機器學習數(shù)據(jù)庫(https://archive.ics.uci.edu/ml/index.php). 本文選擇幾種經(jīng)典的FCM算法作為對比算法: 傳統(tǒng)FCM算法[9]、 LFCM算法[12]、 MSFCM算法[14]和MFCM-NMF算法, 在5個數(shù)據(jù)集上進行實驗. 為避免初始值的影響, 每次實驗FCM算法、 LFCM算法、 MSFCM算法和MFCM-NMF算法均采用相同的初始值, 且對比實驗算法均取最優(yōu)的模糊參數(shù)m值. 此外, 為避免隨機性的影響, 每個實驗均重復20次取平均值. 實驗所用數(shù)據(jù)集的信息列于表1.

表1 數(shù)據(jù)集信息
為評估不同聚類算法的性能, 本文使用F-measure(F*)、 標準互信息(NMI)、 調整蘭德指數(shù)(ARI)[17-18]3個外部指標進行聚類效果的評定, 這3個指標都是用于衡量真實分類與算法聚類結果的一致性, 其值越大聚類效果越好.
3.1 模糊參數(shù)的選擇
模糊加權指數(shù)m是影響模糊聚類的重要參數(shù)[19-20]. 本文實驗旨在說明聚類的性能波動受模糊加權指數(shù)m的影響. 在5個數(shù)據(jù)集上對MSFCM和MFCM-NMF算法進行對比實驗, 結果如圖1~圖3所示. 其中: 參數(shù)m在[1.2,3.2]內的調節(jié)間隔為0.2, 帶有相同顏色的虛線和實線是在同一數(shù)據(jù)集上分別利用MSFCM和MFCM-NMF算法獲得的.
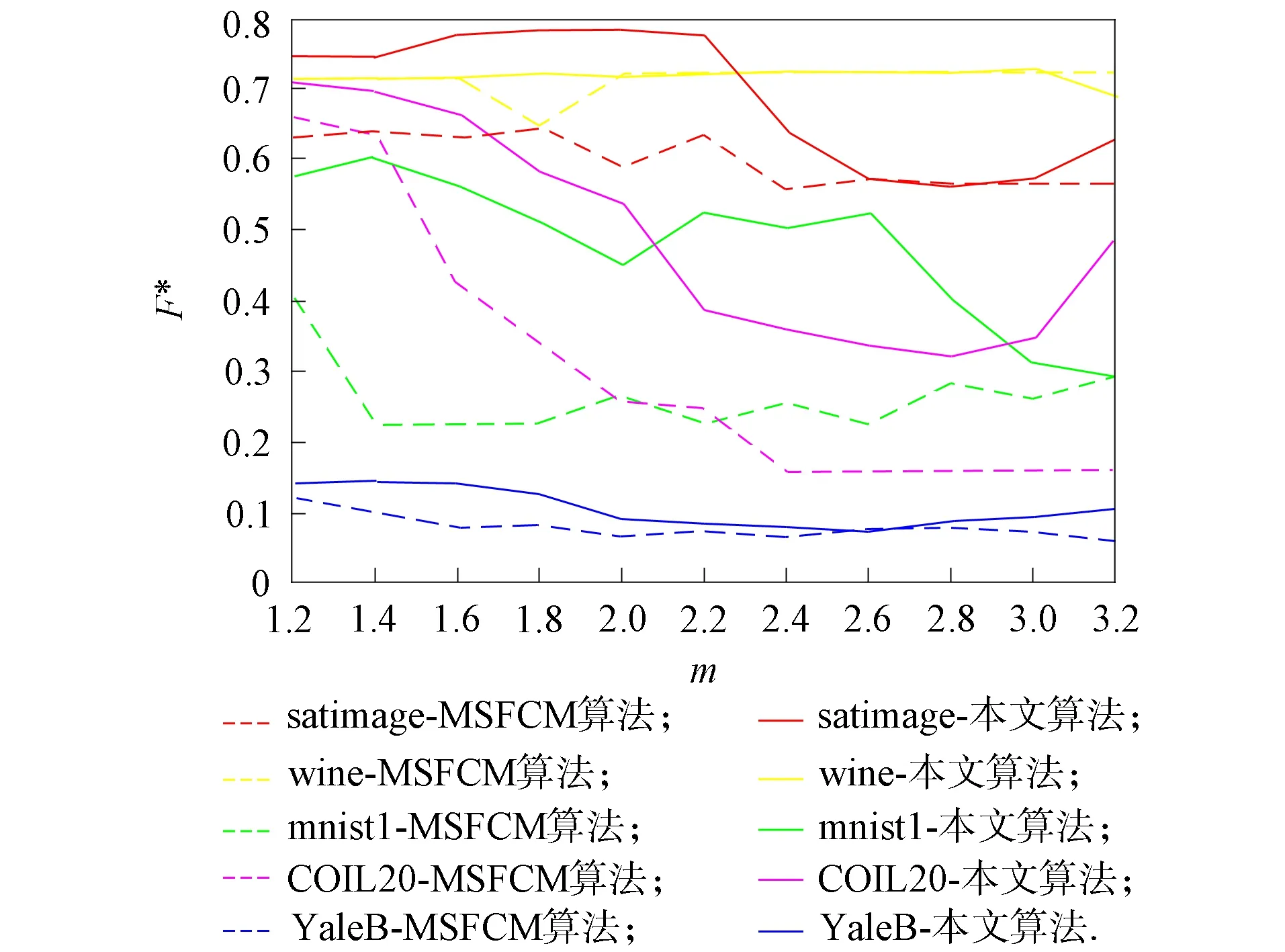
圖1 F*隨m的變化曲線
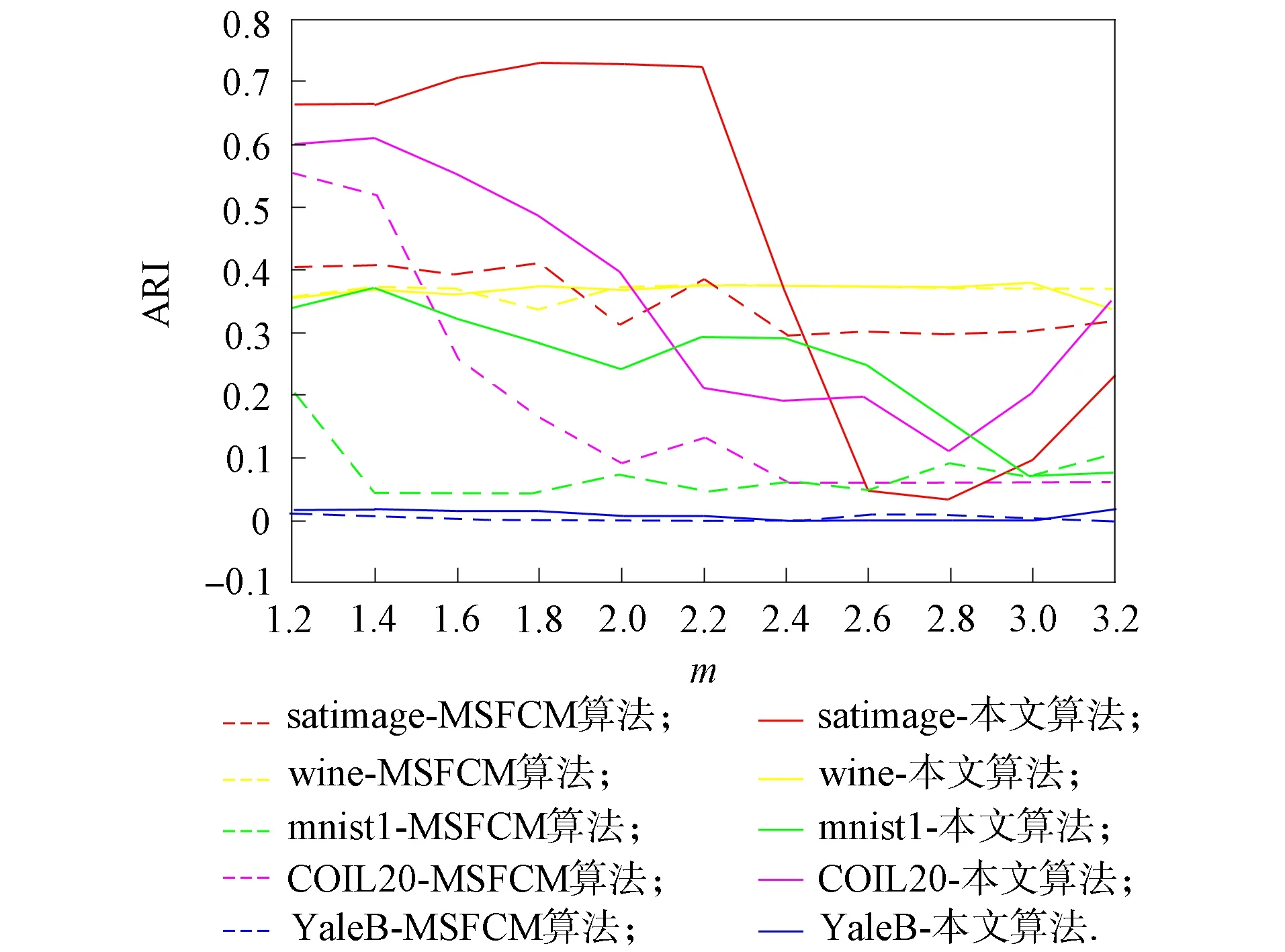
圖2 ARI隨m的變化曲線
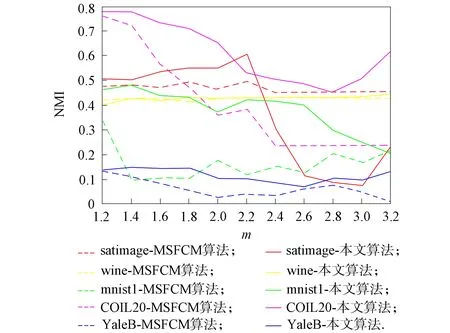
圖3 NMI隨m的變化曲線
由圖1~圖3可見: 1) MSFCM和MFCM-NMF算法的3個評價指標值均隨m的改變而變動, 因此, 不同數(shù)據(jù)集所需的模糊指數(shù)m需要調整; 2) 圖中的虛線為MSFCM算法得到的值, 實線為MFCM-NMF算法得到的值, 觀察可見多數(shù)情況下實線位于虛線的上方, 表明MFCM-NMF算法優(yōu)于MSFCM算法的聚類效果.
在數(shù)據(jù)集UCI-wine上, 由圖1~圖3可見, 黃色實線和虛線基本重合且基本無波動, 即在數(shù)據(jù)集UCI-wine上, 模糊參數(shù)m對MSFCM算法和MFCM-NMF算法的影響很小, 這主要是因為數(shù)據(jù)集UCI-wine的樣本數(shù)少且維度低, 數(shù)據(jù)結構簡單; 在數(shù)據(jù)集mnist1上, 易見表示MFCM-NMF算法的綠色實線始終位于表示MSFCM算法的綠色虛線上方, 即MFCM-NMF算法在3個評價指標上均優(yōu)于MSFCM算法.
實驗結果表明, 在結構簡單的低維度數(shù)據(jù)集上, MFCM-NMF算法和MSFCM算法無明顯區(qū)別, 但在高維度的復雜數(shù)據(jù)集上, 無論是數(shù)據(jù)集UCI還是圖片數(shù)據(jù)集, MFCM-NMF算法均更優(yōu). 因此, 在數(shù)據(jù)集UCI-satimage上, 選擇模糊參數(shù)m=2.2; 在數(shù)據(jù)集UCI-wine上, 選擇模糊參數(shù)m=2; 在數(shù)據(jù)集mnist1上, 選擇模糊參數(shù)m=1.4; 在數(shù)據(jù)集COIL-20上, 選擇模糊參數(shù)m=1.2; 在數(shù)據(jù)集YaleB上, 選擇模糊參數(shù)m=1.8.所有結果均為20次實驗的平均值.
3.2 實驗結果與分析
為直觀地觀察實驗結果, 將最終的實驗結果列于表2.由表2可見, 對于小樣本數(shù)據(jù)集如UCI-wine, MFCM-NMF算法與MSFCM算法結果一致, 但在大樣本數(shù)據(jù)集中, 例如在圖片數(shù)據(jù)集COIL20中, MFCM-NMF算法在F*上相比于FCM,LFCM和MSFCM算法分別有0.217 7,0.217 7和0.202 6的提高, 在ARI上分別有0.219 3,0.219 3和0.207 6的提高, 在NMI上分別有0.251 9,0.251 9和0.171 9的提高. 在手寫數(shù)字圖片數(shù)據(jù)集mnist1的實驗結果中, MFCM-NMF算法在F*上相比于FCM,LFCM和MSFCM算法分別有0.255 3,0.255 3和0.255 2的提高, 在ARI上分別有0.188 0,0.188 0和0.187 9的提高, 在NMI上分別有0.239 2,0.239 2和0.239 2的提高. 在較大維度數(shù)據(jù)集UCI-satimage的實驗結果中, MFCM-NMF算法在F*上相比于FCM,LFCM和MSFCM算法分別有0.225 9,0.226 0和0.156 4的提高, 在ARI上分別有0.428 5,0.428 5和0.330 4的提高, 在NMI上分別有0.093 2,0.093 2和0.052 1的提高. 由實驗結果可見, MFCM-NMF算法得到3個評價指標的值明顯高于其他算法, 特別是在大維度的數(shù)據(jù)集上聚類效果評價指標有顯著提高, 表明MFCM-NMF算法在大樣本數(shù)據(jù)集上有明顯優(yōu)勢, 可有效提高聚類效果.

表2 實驗結果
3.3 過濾方案的效率

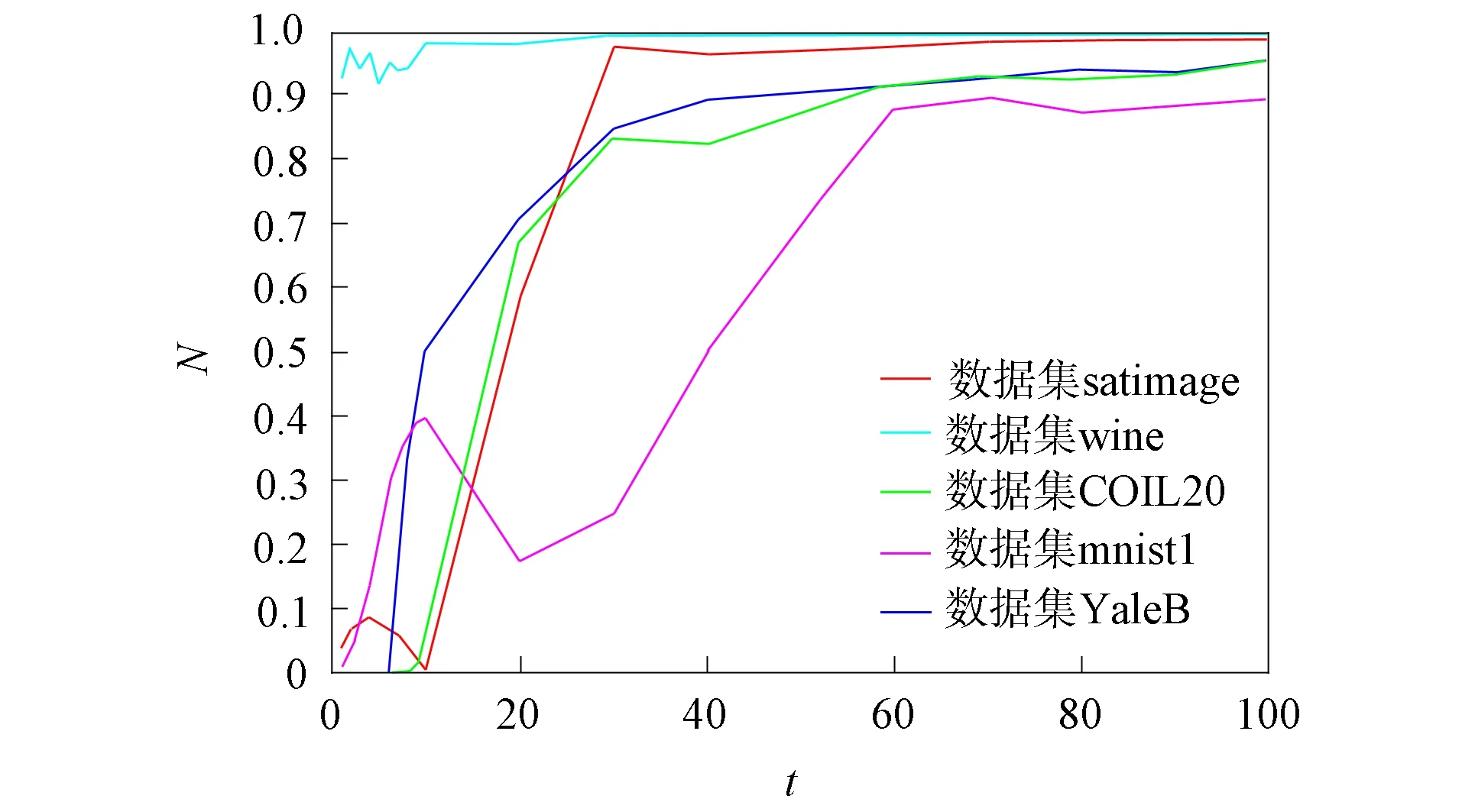
圖4 N隨迭代次數(shù)t的變化曲線
綜上所述, 針對傳統(tǒng)模糊聚類在解決復雜高維度數(shù)據(jù)集時出現(xiàn)大規(guī)模計算量導致聚類性能下降的問題, 本文將NMF與MFCM相融合, 提出了一種基于非負矩陣分解的修正模糊聚類算法(MFCM-NMF), 并用實驗證明了該算法的有效性. 該算法將NMF的基矩陣與模糊聚類的聚類中心相結合, 提出了新的目標函數(shù), 采用新算法進行交替迭代, 并采用新的隸屬度更新公式, 對高維數(shù)據(jù)減少了計算量, 提高了聚類性能.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
