
基于用電與環保指標對比學習的企業排污量動態監測方法
2022-11-22 07:07:30梁小姣馬春玲馬傳國辛少菲史玉良
中國測試 2022年10期
梁小姣,馬春玲,馬傳國,辛少菲,程 林,史玉良,3
(1. 國網山東省電力公司東營供電公司,山東 東營 257100; 2. 山東大學軟件學院,山東 濟南 250101;3. 山大地緯軟件股份有限公司,山東 濟南 250200)
0 引 言
當前企業環保監測多依賴于環保監測設備采樣進行離線分析/在線監測,故不可避免由于多重因素干擾(如設備老化、設備故障、采集點環境因素等)而影響監測精準度,甚至存在監測數據造假、故意破壞監測設備等惡劣事件。電力作為工業生產活動中必不可少的能源,尤其在“雙碳”目標推動下,作為公認的清潔能源[1],工業生產電氣化水平必然將進一步提高,而電力數據高實時性、高滲透性和高覆蓋性等特點,可及時、準確、全方位地反映企業生產狀況和環保設備使用狀況[2],進而可對相應環保指標監測數據進行監測/校正。故本文基于重點排污監測企業用電數據,實現企業排污量的監測,輔助完善環保指標檢測。當前有關機構已開展電能產出/消耗與排污量間關聯性的研究。如楊訓政等[3]基于歷史污染物排放數據與發電機組輸出功率間的關系,采用遞歸網絡+批規范化等算法,實現對發電機組污染物排放量的預測,但當前工業企業未實現針對運行機組的用電量監測,且僅部分企業實現排污量日監測;安軍等[4]針對雙高企業建立“企業甄別-污染預警-配合停/限電-用電監測-異常糾正-恢復生產”的限時工作響應流程,通過電力綠色調度降低大氣污染排放量,然而并未量化計量企業用電量與排污量的關聯;劉忠輝[5]通過改進智能電表實現對治污設備啟停的實時在線監測,旨在細化監測目標提升對企業氣體污染物排放的監測,但硬件改進及運維成本高,不利于推廣應用。上述文獻均表明,電力數據與環保數據之間存在關聯性,但均未實現二者的跨域量化關聯。在當前算法研究中,GAN[6]在跨領域學習中表現優異,其基于博弈論的領域對抗訓練,可實現不同領域的自適應學習。本文基于已有的研究基礎及技術開展企業排污量監測,主要改進內容如下:
1)為實現企業用電負荷與環保特征的關聯分析,并保留不同企業及設備間的細節差異信息[7],本文采用對比學習實現用電-環保特征的跨域動態關聯映射,通過在投影空間中拉近相似實例,推遠不相似實例,實現在企業缺乏排污數據時,也可根據充足的相似樣本及自身用電負荷做出合理排污預測。
2)為提高生成數據與實際數據的全局相似度與一致性,監測數據生成是以相似企業歷史排污均值數據為基礎,結合映射編碼數據提取數據分布間的差異和動態的變化量信息進行的數據復現,故并采用Wasserstein距離構建損失函數,有效避免生成數據失真。
3)鑒于GAN生成數據存在不穩定性,故采用模型預測控制(model predictive control, MPC)構建最小化控制目標函數,通過多目標及多約束條件限制,保證生成數據的穩定性及動態跟蹤性能,且在后期離線模型產生偏移時,其滾動優化可參數微調保證模型監測的準確性。
1 整體模型構建過程
本文通過用電信息采集系統、煙氣連續排放監測系統獲取用電負荷數據和煙氣環保指標監測數據,對獲取的各類采集數據基于行業、生產規模、監測方式及監測設備進行階梯級分類,并完成數據預處理后,構成可用樣本集。整體數據處理流程如圖1所示。
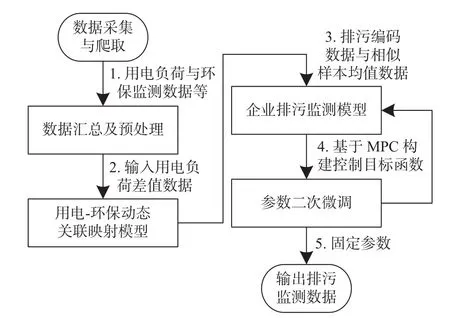
圖1 整體模型數據處理流程圖
本文針對樣本分類分別開展建模訓練及測試,并以某區域某類重點排污監測企業的用電數據與氮氧化物監測指標作為背景。首先企業將基于時間窗口的用電負荷差值數據作為輸入數據,通過用電-環保動態關聯映射模型,即以對比學習算法實現用電負荷差值數據與環保指標監測差值數據的關聯映射及聚類分類,實現不同企業的差異化動態特征提取,輸出排污監測數據的Encoder編碼數據;隨后,Encoder編碼[8]數據結合相似企業歷史排污均值數據輸入企業排污監測模型,該模型通過GAN生成器生成排污監測數據,判別器保證生成數據符合真實樣本數據分布規律,并采用Wasserstein距離構建的損失函數,完成模型的初步參數調節;最后,以模型預測控制(model predictive control, MPC)構建以誤差最小為目標的控制函數,并基于數據預測趨勢進行企業排污監測模型微調,保證輸出企業排污量監測數據的精準度與穩定性。
1.1 對比動態關聯特征提取
本文基于實際用電數據與實際環保數據開展用電-環保動態關聯映射模型訓練,具體過程如圖2所示。以小時級為時間窗口,通過時間窗口滑動分別獲取企業的歷史用電負荷差值數據[9]和歷史排污監測差值數據,共同構成訓練數據集合 τ,隨機從訓練數據集合抽取M個企業樣本數據構成一個分枝訓練集合A,共計生成作用于上下2個分枝的兩個訓練集合,分別為歷史排污監測差值數據集合A1、歷史用電負荷差值數據A2,每個分枝中包含M個企業的樣本數據,其中,上分枝樣本數據固定,下分枝數據動態更新。隨機抽取某一企業的歷史某類排污監測差值數據輸入上分枝,并將對應時刻的用電負荷差值數據輸入下分枝,t表示采樣時間窗口,為采樣時序同維列向量,n表示某一企業的日監測采樣數量,兩者互為正例,i,j∈ (1,2,···,n)。訓練時,上枝與下枝內的其他任意輸入同企業或不同企業的樣本數據Pj與Xj,均為的負例。

圖2 用電-環保動態關聯映射訓練過程
然后,構造一個表示學習架構,通過該架構將訓練數據投影到一個超平面表示空間內。為使正例距離能夠拉近,負例距離推遠,上下分枝采用雙塔非對稱結構,內部層級和神經元數均不同。歷史排污監測數據集合Pt數據進入上分枝,經特征編碼器Encoder,Encoder模塊共計4層,每層包含多注意力機制+求和歸一化處理+前饋神經網絡(采用兩層全連接層+層級規范化(layer normalization,LN)+ReLU激活函數+線性激活函數)+求和歸一化處理[10],從而將輸入樣本數據映射為超平面表示空間中的向量zp。下分枝前一部分架構與上分枝架構相同,但中間各層的神經元個數不同,且參數不共享,輸出表示為hx=fθ′(x),接著輸入非線性變換結構Projector(采用兩層全連接層+ LN+ReLU),輸出為zx=gθ′(hx)。向量zx和zp矩陣內部結構與數量一致。在表示空間中,為實現電量數據與環保指標的關聯分析,需使表示正例電量差值數據和排污監測差值數據映射后的表示向量z重合或者距離盡可能相近,距離負例樣本較遠,故采用表示向量L2正則后的點積作為距離度量標準,以表示空間向量間的相似性:

為在表示空間中使正例距離近,同時任意負例之間的距離遠,故采用如下損失函數:
上分枝損失函數:

下分枝損失函數:

式中:τ——溫度超參,表示難度識別懲罰系數,用以拉開正例樣本與相似度高的負例樣本的距離,避免模型基于高難度負樣本進行參數調整導致模型崩潰;
M——企業個數;
n——某一企業的日監測采樣數量;
上分枝基于損失函數loss反向傳播進行梯度更新模型參數 θ,由于企業用電負荷數據的樣本數據量相對排污監測數據多,故下分枝歷史用電負荷數據A2的負例樣本是不斷更新的,即不斷有新的負例樣本進入A2,并按照先進先出更新負樣本隊列,上下分枝參數不共享。下分枝采用動量更新機制,參數更新方式如下:

式中:θ′——下分枝的模型參數;
m——權重調節系數。
當開始進行模型訓練時,隨機初始化模型參數θ′,當一個批次的訓練數據集計算完成后,上分枝模型參數θ經反向傳播進行梯度更新,同時,使用式(4)更新下分枝對應的參數θ′,m取較大數值0.9~0.99。相對上分枝參數更新,下分枝為維護更大的負樣本隊列,故參數變動緩慢而穩定,從隨機數值小步而緩慢地向最優值迭代。故模型整體表示空間分布會根據排污監測樣本的相似度與距離實現上枝的映射分布,用電負荷差值數據跟隨排污監測差值數據映射空間移動并結合用電負荷數據樣本間距離進行映射分布。
通過損失函數反向調節模型參數完成模型訓練,輸出為表示數據分布映射的Encoder數據。對比學習使相似企業相似的用電負荷差值數據分布和排污監測差值數據分布經過上下分枝的生成器編碼后,可獲取對應的動態數據分布空間映射,而不同的企業或不同時間段的樣本數據在空間映射中相離,從而在實現關聯分析的同時保持樣本數據的個體差異。
1.2 構建企業排污監測模型
基于用電-環保動態關聯映射模型獲取訓練數據集的Encoder輸出編碼[11],即企業歷史電量數據和歷史排污監測數據經過Encoder/Encoder+Projector的輸出編碼,由于在對比學習過程中,相似企業相似樣本的歷史電量數據和歷史排污監測數據在表示空間是近鄰關系,故二者的Encoder輸出編碼距離是相近的,本文旨在通過用電量數據監測企業排污量。故在企業排污監測模型訓練階段,輸入樣本的Encoder數據提取的為企業排污動態變量信息,基于對比學習聚類分類后的均值排污數據基礎進行數據生成。此部分的訓練過程如圖3所示。

圖3 排污監測數據生成訓練過程
本文借鑒基于自動編碼器的GAN算法構建監測模型,并在此基礎上進行算法適應性改進。企業排污監測模型輸入數據為Encoder排污編碼+相似企業歷史排污均值數據,生成器[12]架構與Encoder層級相同,均為4層,每層為多注意力機制+求和歸一化處理+編碼器-生成器注意力機制+求和歸一化處理+前饋神經網絡(采用兩層全連接層+層級規范化+ReLU激活函數+線性激活函數)+求和歸一化處理,4層輸出末端為單層全連接神經網絡+ReLU激活函數,輸出生成排污數據;判別器為3層神經網絡結構,為卷積層+求和歸一化處理+卷積層+求和歸一化處理+全連接層,輸出損失函數。對生成排污數據與對應輸入數據的真實排污監測數據計算Wasserstein距離,結合相似樣本生成的損失函數loss如下:
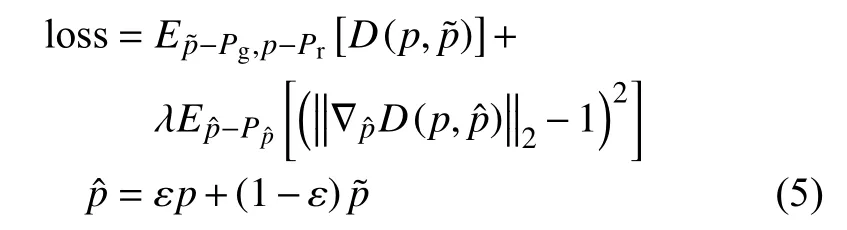
式中:Pg——生成數據的集合;
Pr——實際數據的集合;
——生成數據樣本;
p——實際數據樣本;
用以保證生成數據靠近真實樣本數據,但不會超過真實樣本數據;
——生成數據與真實數據間的抽樣構成數據,通過對抽樣構成數據加梯度懲罰來穩定梯度變化;
λ——權重;
D(p,)——生成樣本與實際樣本的Wasserstein距離,表示點從曲線移動到pi曲線的最短距離集合,計算公式如下:

式中:pi——t時刻的實際排污監測數據;
——生成數據;
σ(t)——t時刻的真實數據映射到生成數據的σ(t)時刻的生成排污監測數據,由于實際數據與生成數據的元素個數相同,且數據測度相同,故Wasserstein距離采用二次差值衡量;
ΣN——N個元素的所有排序排列構成的集合。
訓練過程如下:
1)初始化生成器參數 θg和 判別器 θd。
2)迭代訓練過程中,生成器訓練一次,而判別器需進行多次訓練。主要過程包括訓練判別器,固定生成器參數,更新最大化判別器損失函數。判別器損失函數公式如下:
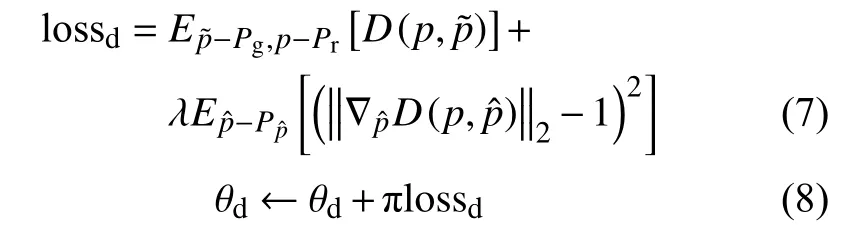
其中,為實現基于相似樣本數據實現曲線擬合生成,加入歷史相似樣本的均方誤差判別條件。
訓練生成器,固定判別器參數,更新最小化生成器損失函數:
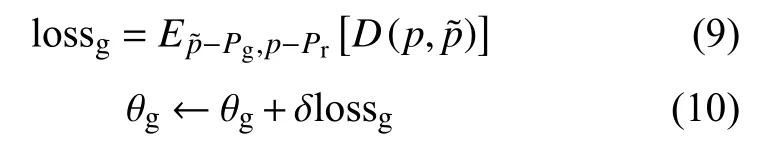
其中,δ為可學習參數。
3)在基于上述獲取的生成器基礎上,進行生成器參數微調,即采用MPC建立目標函數,從而保證生成樣本數據的穩定性。定義控制目標為:在連續時間步內,生成排污數據與實際排污數據總量誤差盡可能小,從而保證生成排污數據的連續性與穩定性;在用電數據產生變量時,生成排污數據與實際排污數據變化時間點誤差盡可能小,從而保證生成數據可以有效捕獲用電數據變動量而非僅擬合排污數據值;用電數據變動量生成的監測輸出變動量與實際排污變動量誤差盡可能小,從而約束生成排污數據產生不必要的跳變。控制目標如下:

滿足約束如下:

式中:J——目標函數;
p(t+1)——在t+1時間步內的實際排污數據;
Δt′——指在用電數據發生百分比超過20%的跳變時,生成排污數據與實際排污數據變化時間點誤差;
Γ——未來 Γ個時間步;
隨后,隨機o次微調生成器參數 θd,并求解未來Γ個時間步的控制目標函數值,得到o組控制序列并排序,獲取最小控制目標函數值J,并將其第一個微調控制量 θd作用于生成器,并進入下一個時刻,重復上述過程直至J小于設定閾值或者其梯度值接近于0,固定參數,輸出模型。基于預測跟蹤控制可有效提高生成器生成數據的穩定性,并在輸入數據發生變化時可動態跟蹤其變化軌跡,從而保證企業設備在不同運行狀態切換時,生成排污監測數據接近實際排污數據。
訓練完成后,用電-環保動態關聯映射模型輸入電量數據及部分排污采樣點數據,輸出Encoder編碼,編碼輸入企業排污監測模型,輸出企業排污量監測數據,由于Encoder編碼關注數據的差異性、動態性和泛化性,而并不是數據本身,故監測數據是基于聚類獲取的相似企業的歷史排污均值數據基礎,并結合用電數據變化量進行的數據復現,保證基于企業用電量數據實現其排污量的監測。尤其隨著該類企業的排污監測數據樣本的增加與更新,可基于預測跟蹤控制模塊不斷微調模型參數,從而提高監測精準度。
2 算例分析
本文以國網某市公司建設的黃河流域污染防止監測系統作為實驗數據源,系統界面如圖4所示。

圖4 黃河流域污染防止監測系統界面圖示
其中,用電數據、環保數據的數據采集頻率為24點/日,電力采集數據為用電負荷數據,環保監測指標為大氣污染指標中的氮氧化物濃度,結合網絡爬取氣象及節假日數據。對獲取的采集數據進行數據轉換、數據標準化、異常值刪除等預處理操作后,獲取可用樣本數據。對2 385家重點排污監測企業基于行業進行分類建模,選擇2020年1月-2021年12月的歷史數據為模型訓練樣本集,2022年1月-2022年4月的歷史數據為模型驗證樣本集,為避免樣本類別不均衡,僅選取企業正常生產的1/5的歷史樣本參與訓練與驗證,以2022年5月歷史數據為模型測試數據樣本集,實現企業排污量監測效果評估。
2.1 動態特征數據的空間分布
在訓練階段用電負荷數據與氮氧化物監測數據輸入用電-環保動態關聯映射模型后,于上下分枝獲取企業排污監測模型的Encoder編碼。為可視化展現用電負荷數據通過對比學習跟蹤氮氧化物監測數據的空間分布規律,在保留企業排污細節信息的前提下,實現相似樣本數據聚類與不相似樣本在表示空間的相對均勻分布,為展示上下分枝分別生成的氮氧化物監測數據與用電數據的Encoder編碼數據,采用極坐標進行展示,如圖5所示。
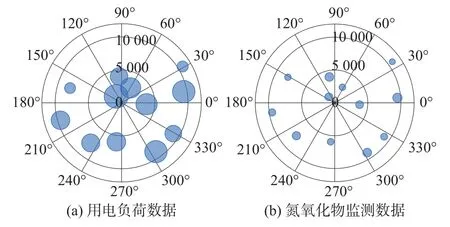
圖5 編碼數據在極坐標中的對比圖
由圖5展現了“雙塔”結構生成用電數據Encoder編碼和排污數據Encoder編碼在空間中的對稱分布與關聯性,其中,極坐標中的氣泡的大小代表樣本數據量,氣泡數量代表樣本聚類數量,氣泡間的距離代表樣本的相似度與差異距離。由于當前僅部分重點排污企業可實現氮氧化物的小時級采集監測,采集監測數據受限于有限量氮氧化物監測數據,故在訓練過程中,上分枝氮氧化物監測數據樣本不變,下分枝歷史電量數據A2的負例樣本是不斷更新的,即不斷有新的負例樣本進入A2,并按照先進先出更新負樣本隊列,故下分枝映射后獲取的左側用電數據氣泡樣本量較大。從圖中可以看出,二者的聚類中心基本重合,在訓練過程中用電數據是根據氮氧化物監測數據的分布進行跟蹤,故可基于用電數據提取氮氧化物監測數據的變量信息。同時對比學習使電量數據分布和排污監測數據分布經過上下分枝的生成器編碼后,相似樣本數據聚集到較近區域,在實現特征相關性分析的同時,可基于樣本數據的個體差異進行聚類劃分。受限于有限量氮氧化物監測數據,導致下分枝基于用電量數據擬合排污數據的編碼產生偏差,如圖5(b)的左側三個樣本集數據,此部分區域企業的氮氧化物平均單位電量排放氮氧化物指數低于5.89,排放氮氧化物的日監測數據采集樣本數據未實現小時級,導致用電數據對應排污數據映射出現偏差。但在排污監測數據充分時,用電-環保動態關聯映射模型能夠忽略數據分布的淺層因素,可基于用電數據提取其排污指標數據的變化分布規律。
2.2 消融實驗對比曲線精準度分析
本文在模型數據處理過程中,主要從以下3點內容進行改進:
1)企業排污監測模型生成器的輸入編碼為用電數據與氮氧化物監測數據對比學習獲取的氮氧化物動態編碼數據[13]。
2)在企業排污監測模型訓練階段,生成器生成的檢測數據是根據企業S用電數據獲取的動態編碼結合相似企業歷史排污均值數據復現企業S排污數據,同時損失函數采用Wasserstein距離計算生成排污數據與真實排污監測數據差值。
3)在模型初步訓練完成的基礎上,采用MPC建立以曲線誤差最小為目標的控制函數,從而進行模型的二次微調。
本文通過消融實驗,對上述內容以企業S為例進行生成曲線展示,如圖6所示,為用電-環保動態關聯映射模型、企業排污監測模型訓練完成后,將用電數據輸入用電-環保動態關聯映射模型后,輸出Encoder數據,隨后Encoder數據輸入企業排污監測模型,輸出企業S氮氧化物排放量監測數據。示例企業S為某鋼鐵制品加工企業,企業S基于生產計劃進行,小時級氮氧化物排放監測樣本數據充分。對比實驗方法如下:

圖6 氮氧化物生成曲線數據對比圖
方法1:本文方法,即用電負荷數據作為用電-環保動態關聯映射模型輸入,采用對比學習獲取Encoder排污編碼,結合相似企業歷史排污均值數據作為企業排污監測模型的輸入數據,監測模型采用GAN生成器(生成監測數據)+判別器(判別曲線真假),采用MPC進行二次微調,輸出氮氧化物監測數據。
方法2:在方法1的基礎上,將企業S真實排污監測數據作為映射模型輸入(即不采用對比學習獲取Encoder排污編碼),其他一致。
方法3:在方法1的基礎上,將企業S排污監測設備故障時獲取的排污監測數據作為映射模型輸入(即不采用對比學習獲取Encoder排污編碼),其他一致。
方法4:在方法1的基礎上,采用對比學習獲取Encoder排污編碼作為企業排污監測模型的輸入數據(未結合相似企業歷史排污均值數據),其他一致。
方法5:在方法1的基礎上,不采用MPC進行二次微調,其他一致。
如圖6所示,采用文中方法的方法1,與實際排污的真實曲線擬合度較高,小時級均值誤差為1.89%,標準差為0.02,方法2直接將企業S真實排污監測數據作為映射模型輸入,基本復現實際排污曲線,小時級均值誤差為1.39%,標準差為0.02,由方法1和方法2可以說明,采用對比學習方法,用電數據可以捕獲排污數據的動態變化信息,并通過本文方法實現排污曲線復現;方法3為企業S排污監測設備故障時獲取的排污監測數據,并將其直接作為映射模型輸入,由曲線可以看出其更多地基于相似企業排污數據均值進行變化,進一步說明采用用電數據提取動態特征,可以在排污監測設備故障時進行預警并復現實際排污數據;方法4為GAN生成器未結合相似企業歷史排污均值數據進行數據生成,小時級均值誤差為9.88%,標準差為0.1,由此可以看出僅基于GAN生成數據存在不穩定性及數據分散,難以擬合實際排污數據;方法5為不采用MPC進行二次微調,由曲線可以看出,生成曲線與實際曲線不僅誤差較大,且由于其數據監測缺乏前瞻連續性,故導致其未捕獲排污數據滯后于用電數據這一實際狀態。
此外,本文選取29家重點排污企業進行5日氮氧化物排放濃度監測,采用均方根誤差(root mean squared error,RMSE)對 12次實驗結果進行排放濃度監測效果評價,并采用KL散度[14]衡量一個監測曲線數據分布相比實際數據分布的信息損失,二者均為數據越小,曲線擬合度越高,并對擬合曲線進行積分運算,從而獲取企業累計排污量監測值,以平均絕對百分比誤差(mean absolute percentage error,MAPE)對監測值與實際排污量進行監測精準度評價,如表1所示。
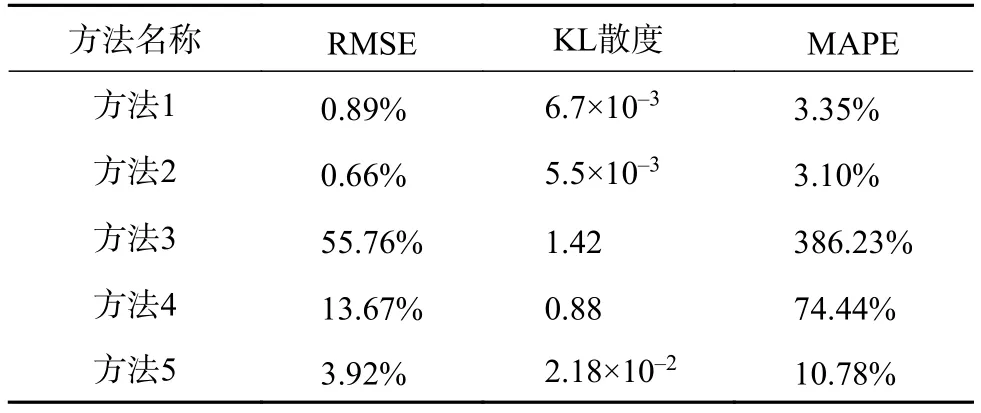
表1 曲線相似度評價表
由RMSE和KL散度可得,采用本文所述方法可對企業排污量進行相對準確的監測,可有效實現基于用電數據實現對排污監測數據的監測與預警。
2.3 生成數據的穩定性對比分析
為進一步說明本文采用MPC對模型監測數據的穩定性與連續性影響,以實際排污數據為基線,分別以本文采用MPC的排污監測數據曲線、本文不采用MPC的排污監測數據曲線、采用GAN生成器(此處無相似企業排污歷史均值數據輔助輸入)與實際排污數據計算誤差進行對比分析,如圖7所示。
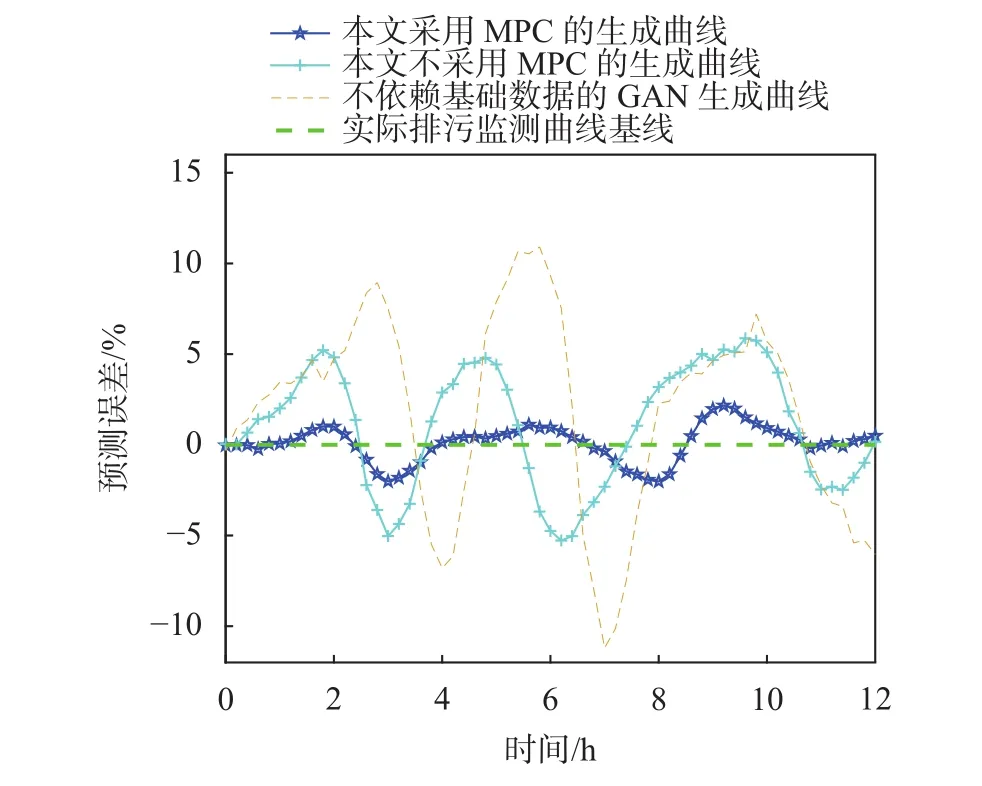
圖7 12 h排污監測數據誤差對比圖
由圖可以看出,本文所述方法為代表的采用MPC的排污監測生成數據曲線,與實際曲線誤差較小,數據波動性較小,其通過定義控制目標為總量誤差、時間點誤差和變動量誤差的降低,在模型二次微調階段,基于該控制目標在實現時域預測追蹤控制,從而提高了生成排污數據的連續性、穩定性與實時性;對比不采用MPC的排污監測生成數據曲線,其跟蹤連續性與穩定性明顯降低,表明模型二次微調階段的可行性與有效性;而不依賴基礎數據的GAN生成曲線,由于未基于歷史數據基礎進行數據生成,GAN生成數據的不穩定性,即使模型加入采用MPC的二次微調,其生成監測數據仍然與實際數據誤差較大,表明本文采用相似企業排污歷史均值數據輔助輸入生成排污監測數據曲線可有效保障監測數據的穩定性,即在實際歷史排污數據的基礎上,通過用電數據捕獲排污動態變量信息,從而生成排污監測數據。
3種方法的監測誤差數據如表2 所示。通過對比分析可知,本文方法排污監測數據準確率均值能夠達到98.92%,相較于不采用MPC,模型監測數據準確率均值提升2.36%,相較于不依賴基礎數據的GAN生成曲線,模型監測數據準確率均值提升5.85%,對比分析可知采用MPC可提高生成數據準確率。通過對比分析3種方法的標準差可知,采用MPC生成的監測曲線相對的穩定性。與此同時, 本文方法監測誤差跨度不高于5%,說明模型可有效捕獲用電數據中的表現排污量的動態信息,模型趨勢監測準確率明顯提升。綜上所述,仿真實驗表明,本文方法不僅可基于用電數據監測排污量,且模型監測準確度與穩定性均較好,可輔助實現環保指標監測預警。

表2 12 h排污監測數據誤差對比表
3 結束語
本文通過對比學習算法實現用電數據與環保指標的差值數據關聯映射,作為上分枝環保差值數據的正例增強樣本的下分枝用電負荷差值數據,與對應正例映射數據分布相擬合,并實現了“正例相吸,
負例相斥”樣本數據聚類分類;基于排污編碼數據結合相似樣本排污均值數據,采用GAN算法生成企業排污監測數據,并以模型預測控制構建符合預測趨勢發展的目標控制函數,進一步保證生成數據的穩定性與連續性。
由于根據用電數據實現企業的排污量監測尚處于初期探索階段,故本文僅對某類型企業充足樣本的氮氧化物24 點指標數據進行了研究與測試,后續隨著點源排放監測數據的增多,可探索在樣本不充分的情況下的多類指標的預測,從而為環保監測提供技術研究參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南畫報(2020年9期)2020-10-27 02:03:26
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
