
基于混合深度網(wǎng)絡(luò)的電站鍋爐NOx排放預(yù)測(cè)
2022-11-22 07:07:40馬永光
中國(guó)測(cè)試 2022年10期
武 松,馬永光
(華北電力大學(xué)自動(dòng)化系,河北 保定 071003)
0 引 言
燃煤電站是我國(guó)電力生產(chǎn)工業(yè)的主體,同時(shí)也是NOx等大氣污染物重大排放源。尤其是隨著“雙碳”目標(biāo)的提出,我國(guó)近年來(lái)不斷提高燃煤電站NOx的排放標(biāo)準(zhǔn)。如何有效降低電站鍋爐NOx等污染物排放成為了企業(yè)面臨的一個(gè)重要難題。為了降低NOx的排放,建立準(zhǔn)確的NOx排放預(yù)測(cè)模型是基礎(chǔ)。準(zhǔn)確預(yù)測(cè)NOx排放量有利于優(yōu)化鍋爐燃燒過(guò)程,降低選擇性催化還原(Selective Catalytic Reduction,SCR)煙氣脫硝成本[1-2]。
NOx生成機(jī)理十分復(fù)雜,傳統(tǒng)的機(jī)理分析建模難以準(zhǔn)確估計(jì)NOx的排放量[3]。基于數(shù)據(jù)驅(qū)動(dòng)和智能算法的建模因其不涉及復(fù)雜的過(guò)程機(jī)理計(jì)算而受到研究人員越來(lái)越多的重視[4]。智能建模算法主要包括人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Network,ANN)[5]、支持向量機(jī)(Support Vector Machine,SVM)[6]、深度學(xué)習(xí)網(wǎng)絡(luò)(Deep Learning Network,DNN)[7]等。劉岳[8]等人提出了一種基于特征優(yōu)化的長(zhǎng)短期記憶(Long Short-Term Memory,LSTM)的NOx建模方法,并使用通過(guò)網(wǎng)格搜索和改進(jìn)粒子群算法確定 LSTM神經(jīng)網(wǎng)絡(luò)的超參數(shù),但是該模型收斂速度慢,容易發(fā)生過(guò)擬合。LI[9]等人使用卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)對(duì)鍋爐NOx排放進(jìn)行預(yù)測(cè),但并未利用數(shù)據(jù)的時(shí)間依賴特征。王英男[10]建立了一種結(jié)合注意力機(jī)制(Attention Mechanism, AM)與LSTM的混合預(yù)測(cè)模型AM-LSTM,所建立的模型預(yù)測(cè)精度高,泛化能力好。李楠[11]設(shè)計(jì)了基于深層自動(dòng)編碼網(wǎng)絡(luò)(Deep De-noising Auto-Encoder Network,DDAEN)的NOx預(yù)測(cè)算法,但是深度學(xué)習(xí)框架結(jié)構(gòu)復(fù)雜,特征學(xué)習(xí)較為耗時(shí)。
針對(duì)以上問(wèn)題,本文基于某電站鍋爐歷史運(yùn)行數(shù)據(jù),提出了一種融合全局注意力機(jī)制(Global Attention Mechanism, GAM)與CNN、雙向長(zhǎng)短期記憶(Bi-directional Long Short-Term Memory,BiLSTM)的混合深度學(xué)習(xí)模型來(lái)預(yù)測(cè)未來(lái)時(shí)刻電站鍋爐出口NOx排放量。首先對(duì)歷史數(shù)據(jù)進(jìn)行預(yù)處理,去除離群值和噪聲,然后確定模型輸入變量并估計(jì)輸入變量與NOx排放量之間的時(shí)間延遲,重構(gòu)數(shù)據(jù)序列,實(shí)現(xiàn)輸入輸出數(shù)據(jù)序列在時(shí)間維度的對(duì)齊。然后基于Matlab平臺(tái)構(gòu)建CNN-BiLSTMGAM模型,CNN用于提取序列數(shù)據(jù)的局部空間結(jié)構(gòu)特征,BiLSTM可以利用其前后兩個(gè)方向的時(shí)間依賴特性,GAM可以自動(dòng)分配神經(jīng)元隱藏狀態(tài)輸出權(quán)重,突出重要信息的影響,進(jìn)一步提高模型預(yù)測(cè)精度。另外還采用了正則化技術(shù)(Dropout)結(jié)合Adam優(yōu)化算法提高模型收斂速度并防止過(guò)擬合。最后將所提出模型的預(yù)測(cè)效果與其他幾種典型預(yù)測(cè)模型進(jìn)行對(duì)比,以說(shuō)明所提出模型的有效性。
1 模型原理
1.1 CNN網(wǎng)絡(luò)
CNN是一種前饋神經(jīng)網(wǎng)絡(luò),主要用于從原始數(shù)據(jù)中提取特征,具有很好的非線性學(xué)習(xí)能力。它的主要特點(diǎn)體現(xiàn)在稀疏連接與權(quán)值共享,這種網(wǎng)絡(luò)結(jié)構(gòu)更類似于生物神經(jīng)網(wǎng)絡(luò),降低了網(wǎng)絡(luò)模型的復(fù)雜度,減少了權(quán)值的數(shù)量。
CNN網(wǎng)絡(luò)具有多層結(jié)構(gòu),卷積層是CNN的核心,用來(lái)提取對(duì)象局部特征。池化層在卷積層之后,通過(guò)最大池化或平均池化操作對(duì)卷積層所得特征圖(Feature Maps)再次提取其更深一層的特征。全連接層將池化層提取的特征進(jìn)行匯總,把池化層輸出的張量重新拼接成一個(gè)一維向量,形成最終輸出[12]。CNN結(jié)構(gòu)見(jiàn)圖1。
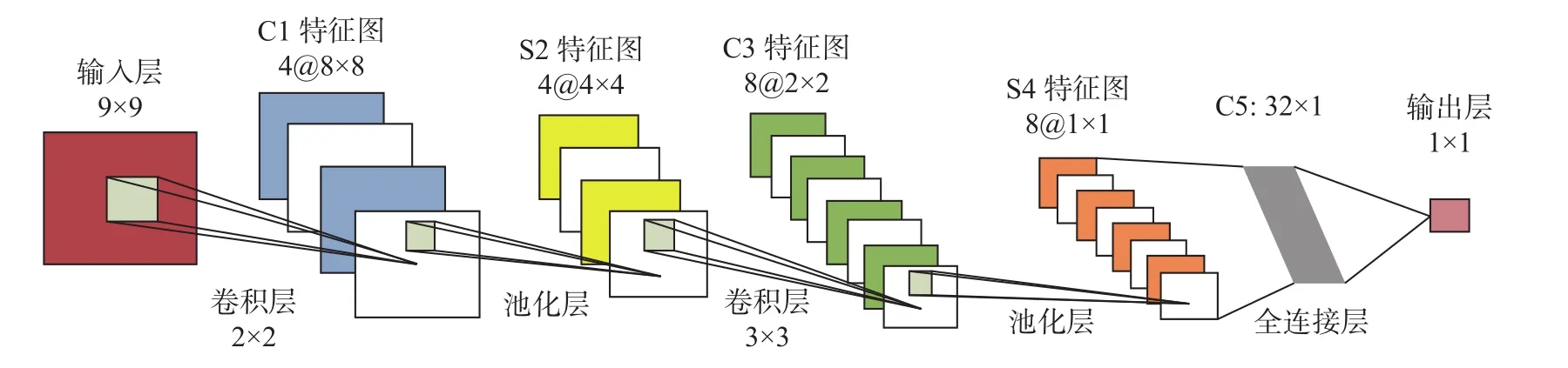
圖1 CNN網(wǎng)絡(luò)結(jié)構(gòu)圖
CNN網(wǎng)絡(luò)卷積層計(jì)算過(guò)程為:
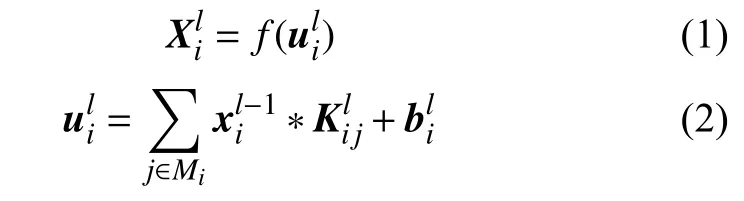
f(·)——激活函數(shù),這里選擇ReLU;
Mi——計(jì)算的輸入特征圖子集;
“*”——卷積;
1.2 BiLSTM網(wǎng)絡(luò)
LSTM是一種循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN),通過(guò)其內(nèi)部的門結(jié)構(gòu)可以解決RNN在處理較長(zhǎng)的時(shí)間序列時(shí)出現(xiàn)的梯度消失和梯度爆炸問(wèn)題,是對(duì)RNN的一種改進(jìn),每個(gè)LSTM神經(jīng)元細(xì)胞一般包括遺忘門(Forget gate)、輸入門(Input gate)和輸出門(Output gate)[13-14]。LSTM 神經(jīng)元細(xì)胞結(jié)構(gòu)如圖2所示。
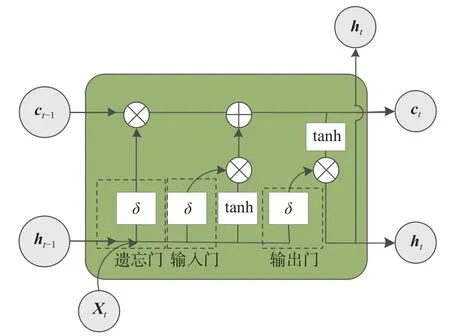
圖2 LSTM細(xì)胞結(jié)構(gòu)圖
圖2中,LSTM網(wǎng)絡(luò)計(jì)算過(guò)程為:

式中:Xt——當(dāng)前輸入;
ht-1——上一時(shí)刻神經(jīng)元細(xì)胞輸出;
ft、it、ot——當(dāng)前時(shí)刻細(xì)胞遺忘門、輸入門、輸出門的輸出;
W——權(quán)重系數(shù)矩陣;
b——偏置項(xiàng)向量;
ct-1——上一時(shí)刻神經(jīng)元細(xì)胞狀態(tài);
——當(dāng)前時(shí)刻細(xì)胞更新量;
ct——當(dāng)前時(shí)刻細(xì)胞最終狀態(tài)更新;
ht——當(dāng)前時(shí)刻細(xì)胞最終輸出;
“?”—— 矩陣對(duì)應(yīng)位置元素相乘(Hadamard乘積);
δ(sigmoid)和tanh——激活函數(shù)。
BiLSTM 由兩個(gè)方向相反的LSTM層組成,可以獲取序列前后兩個(gè)方向的信息。BiLSTM網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。
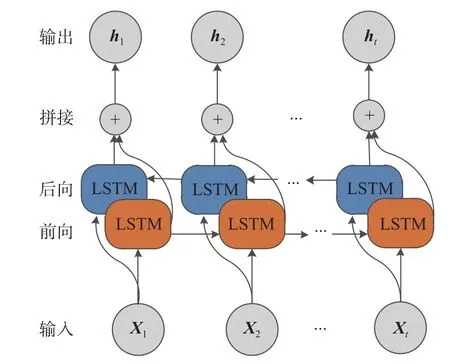
圖3 BiLSTM結(jié)構(gòu)圖
1.3 全局注意力機(jī)制
全局注意力機(jī)制由Luong等在2015年提出,它是對(duì)傳統(tǒng)注意力機(jī)制的改進(jìn)。它在經(jīng)典Seq2Seq編碼器—解碼器(Encoder-Decoder)結(jié)構(gòu)基礎(chǔ)上構(gòu)造一個(gè)注意力層(Attention Layer),通過(guò)計(jì)算網(wǎng)絡(luò)隱含層神經(jīng)元?dú)v史時(shí)刻隱藏狀態(tài)與當(dāng)前時(shí)刻隱藏狀態(tài)之間的關(guān)聯(lián)程度,將更多的注意權(quán)重分配到關(guān)聯(lián)程度大的部分,實(shí)現(xiàn)對(duì)數(shù)據(jù)特征的自適應(yīng)關(guān)注[15]。計(jì)算過(guò)程如下:
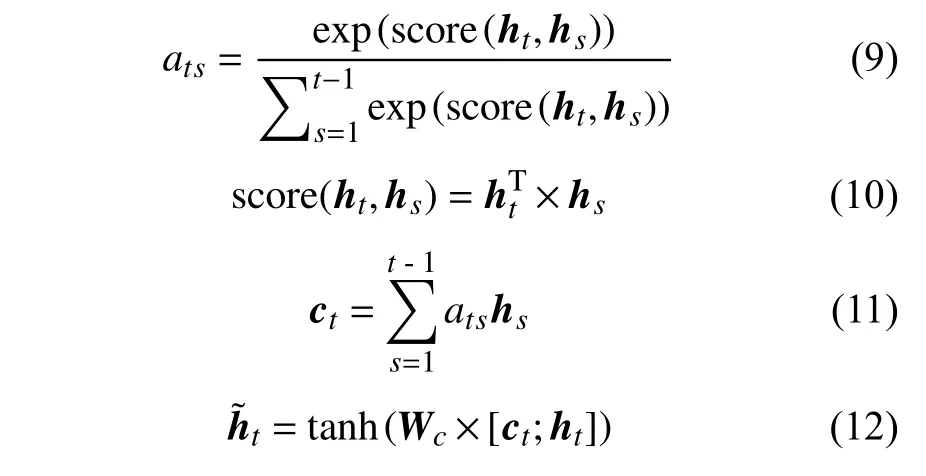
式中:ats——神經(jīng)元?dú)v史時(shí)刻隱藏狀態(tài)輸出對(duì)當(dāng)前時(shí)刻隱藏狀態(tài)輸出的注意力權(quán)重;
score——評(píng)分函數(shù);
hs——神經(jīng)元?dú)v史隱藏狀態(tài);
ht——神經(jīng)元當(dāng)前隱藏狀態(tài);
ct——中間變量;
——經(jīng)注意力加權(quán)計(jì)算后的神經(jīng)元當(dāng)前時(shí)刻最終隱藏狀態(tài)輸出。
2 數(shù)據(jù)準(zhǔn)備
本文數(shù)據(jù)來(lái)自某2×300 MW電站超臨界鍋爐分散控制系統(tǒng)(Distributed Control System,DCS),采樣周期10 s,從中篩選了一段負(fù)荷變化范圍大(84~300 MW)的連續(xù)運(yùn)行數(shù)據(jù),共10 069條數(shù)據(jù)樣本。
2.1 變量選擇
基于數(shù)據(jù)驅(qū)動(dòng)的模型對(duì)數(shù)據(jù)精度十分敏感,建模之前首先對(duì)數(shù)據(jù)中的離群點(diǎn)和噪聲進(jìn)行預(yù)處理,消除其對(duì)模型精度的不利影響。對(duì)于離群點(diǎn),使用箱線圖法(Box-whisker Plot)進(jìn)行篩選,然后使用均值填充進(jìn)行修正;對(duì)于噪聲,使用小波半軟閾算法(Wavelet Semi-soft Threshold Denoising, WSTD)進(jìn)行處理,半軟閾值介于軟閾和硬閾之間,可以均衡硬閾值去噪帶來(lái)的信號(hào)局部抖動(dòng)以及軟閾值去噪峰值信噪比低的問(wèn)題。
鍋爐燃燒過(guò)程中影響NOx生成的變量有很多,通過(guò)對(duì)NOx生成機(jī)理分析并充分結(jié)合電站運(yùn)行人員的實(shí)際經(jīng)驗(yàn),共篩選了包含總風(fēng)量、爐膛氧含量、燃燒器擺角、給煤機(jī)給煤量等26個(gè)特征變量的歷史數(shù)據(jù)作為模型的輸入,詳見(jiàn)表1。
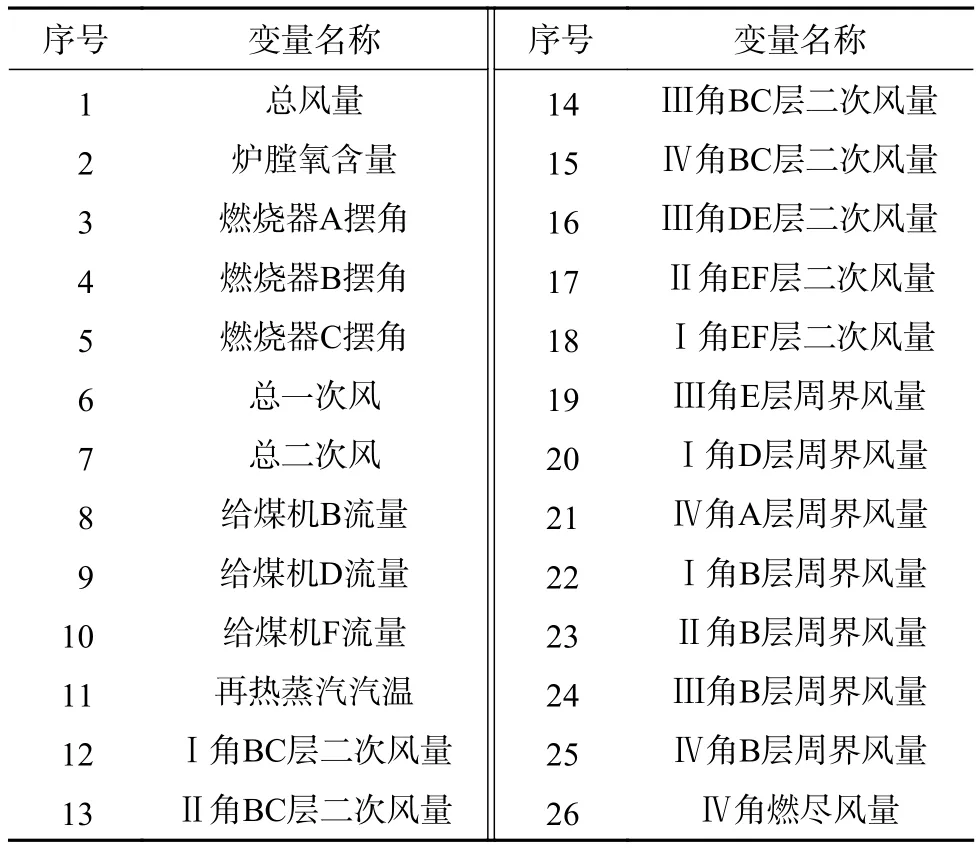
表1 模型輸入變量
2.2 變量延遲時(shí)間估計(jì)
電站鍋爐具有大延遲、大慣性的特點(diǎn),且各個(gè)輸入特征變量的測(cè)量和NOx測(cè)量值之間存在不同的時(shí)間延遲,導(dǎo)致DCS 記錄的同一時(shí)刻運(yùn)行數(shù)據(jù)中的各相關(guān)參數(shù)之間未形成準(zhǔn)確對(duì)應(yīng)關(guān)系,DCS原始數(shù)據(jù)并不能反應(yīng)變量之間真實(shí)的時(shí)序關(guān)系。因此建模之前還需要校準(zhǔn)輸入變量與輸出NOx之間的時(shí)間延遲,重構(gòu)數(shù)據(jù)序列,實(shí)現(xiàn)建模數(shù)據(jù)在時(shí)間維度對(duì)齊。
互信息(Mutual Information, MI)是一種對(duì)信息的量化表達(dá),能夠反應(yīng)變量之間的相關(guān)程度。定義兩個(gè)離散隨機(jī)變量X與Y之間的互信息為:
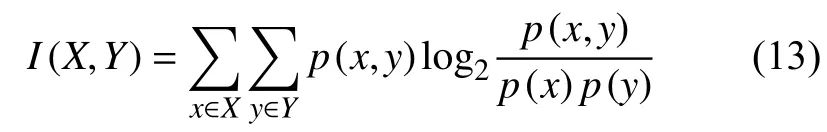
式中:p(x,y)——X與Y的聯(lián)合概率分布,
p(x),p(y)——X與Y的邊緣概率分布。
為了計(jì)算各輸入變量與輸出NOx之間的互信息值,設(shè)輸入變量數(shù)據(jù)序列矩陣為X:
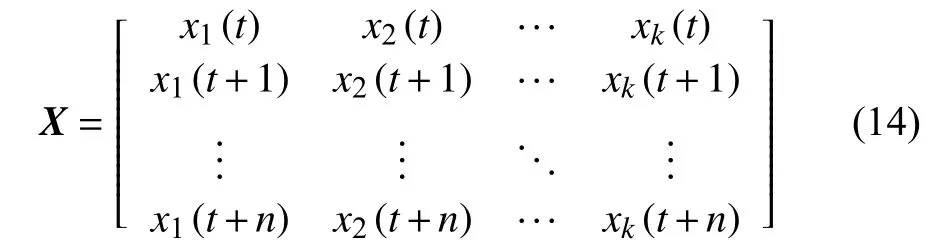
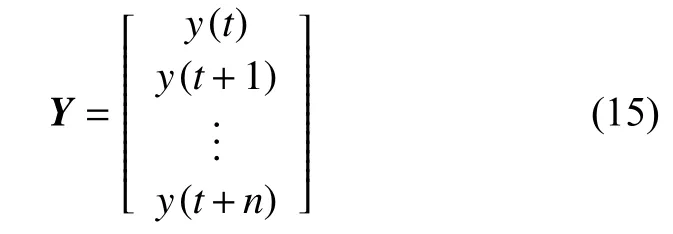
式中:n——時(shí)間序列長(zhǎng)度或時(shí)間步長(zhǎng)(1個(gè)時(shí)間步長(zhǎng)度為采樣周期10 s);
k——輸入變量個(gè)數(shù)。
τi(τi∈[τmin,τmax])為第i個(gè)輸入變量Xi(i∈(1,k))與Y之間的時(shí)間遲延,X可以重構(gòu)為:

其中,第i個(gè)變量Xi重構(gòu)為:

根據(jù)現(xiàn)場(chǎng)實(shí)際運(yùn)行情況,變量延遲時(shí)間范圍一般在 0~300 s之間,采樣周期為 10 s,因此選擇τmin=0,τmax=30。為了求每個(gè)輸入變量Xi的最佳延遲時(shí)間,計(jì)算過(guò)程為:
1)分別計(jì)算式(17)中等號(hào)右側(cè)矩陣每一列與式(15)輸出Y之間的互信息值,其中互信息值最大的那一列對(duì)應(yīng)的τ就是該變量的延遲時(shí)間估計(jì)。
2)重復(fù)步驟1)得到所有變量的延遲時(shí)間。
輸入變量的延遲時(shí)間計(jì)算如表2所示。
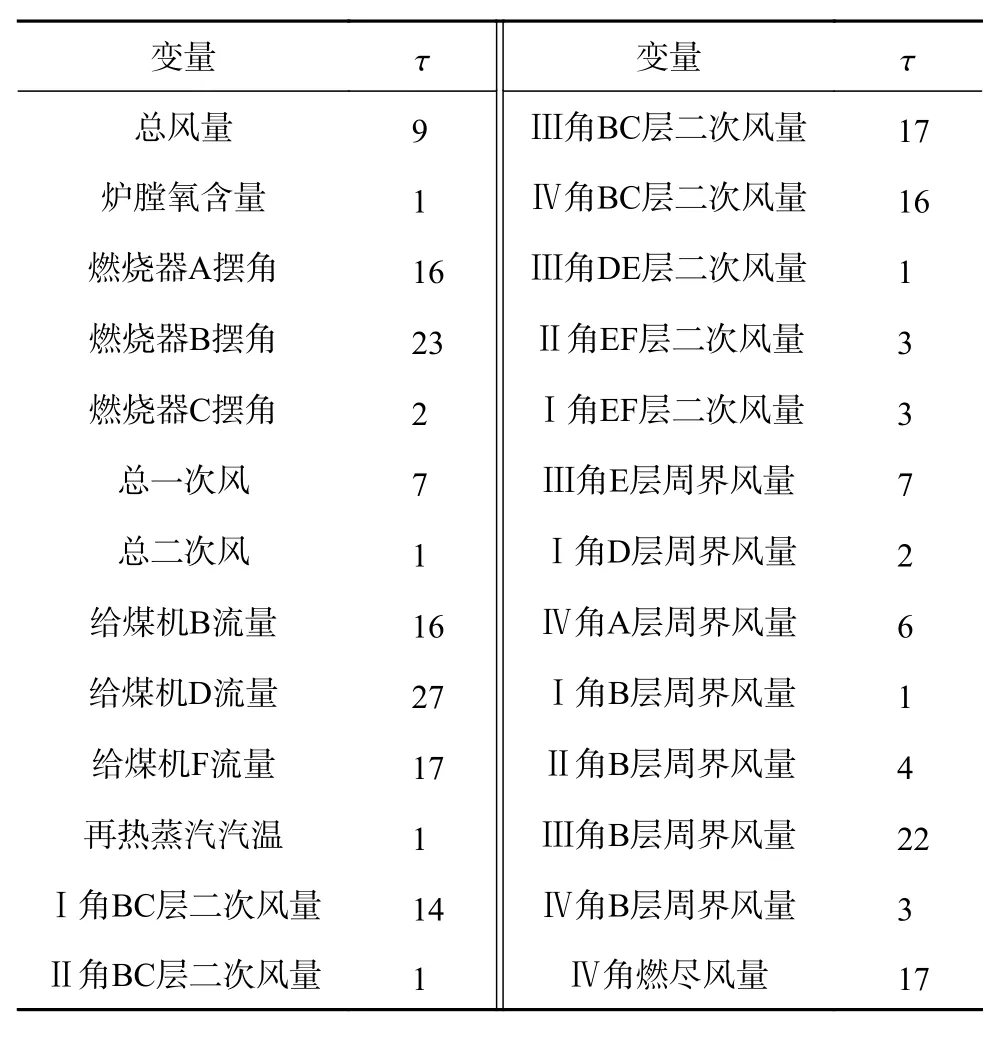
表2 輸入變量延遲時(shí)間估計(jì)
在得到各輸入變量的時(shí)間延遲后,對(duì)原始數(shù)據(jù)序列進(jìn)行重構(gòu),實(shí)現(xiàn)輸入變量與輸出NOx之間在時(shí)間維度的對(duì)齊。
為了進(jìn)一步提高模型預(yù)測(cè)的準(zhǔn)確性,考慮到數(shù)據(jù)序列的時(shí)間依賴特性,在所選26個(gè)變量歷史時(shí)刻數(shù)據(jù)的基礎(chǔ)上,又加入了鍋爐出口NOx排放量歷史時(shí)刻數(shù)據(jù)共27個(gè)變量的歷史時(shí)刻數(shù)據(jù)形成模型最終輸入,輸出為未來(lái)1個(gè)時(shí)間步的鍋爐出口NOx排放量,即輸入輸出之間相差1個(gè)時(shí)間步。
3 模型構(gòu)建
3.1 模型結(jié)構(gòu)
CNN-BiLSTM-GAM混合模型結(jié)構(gòu)圖如圖4所示。其中CNN有一個(gè)一維卷積層和一個(gè)最大池化層,對(duì)序列數(shù)據(jù)每個(gè)時(shí)間步輸入都進(jìn)行一次卷積池化運(yùn)算,經(jīng)全連接層后將結(jié)果輸入到后兩個(gè)含Dropout的BiLSTM層,之后由GAM層計(jì)算第二個(gè)BiLSTM層神經(jīng)元隱藏狀態(tài)輸出權(quán)重分配,經(jīng)全連接得到最終輸出結(jié)果。
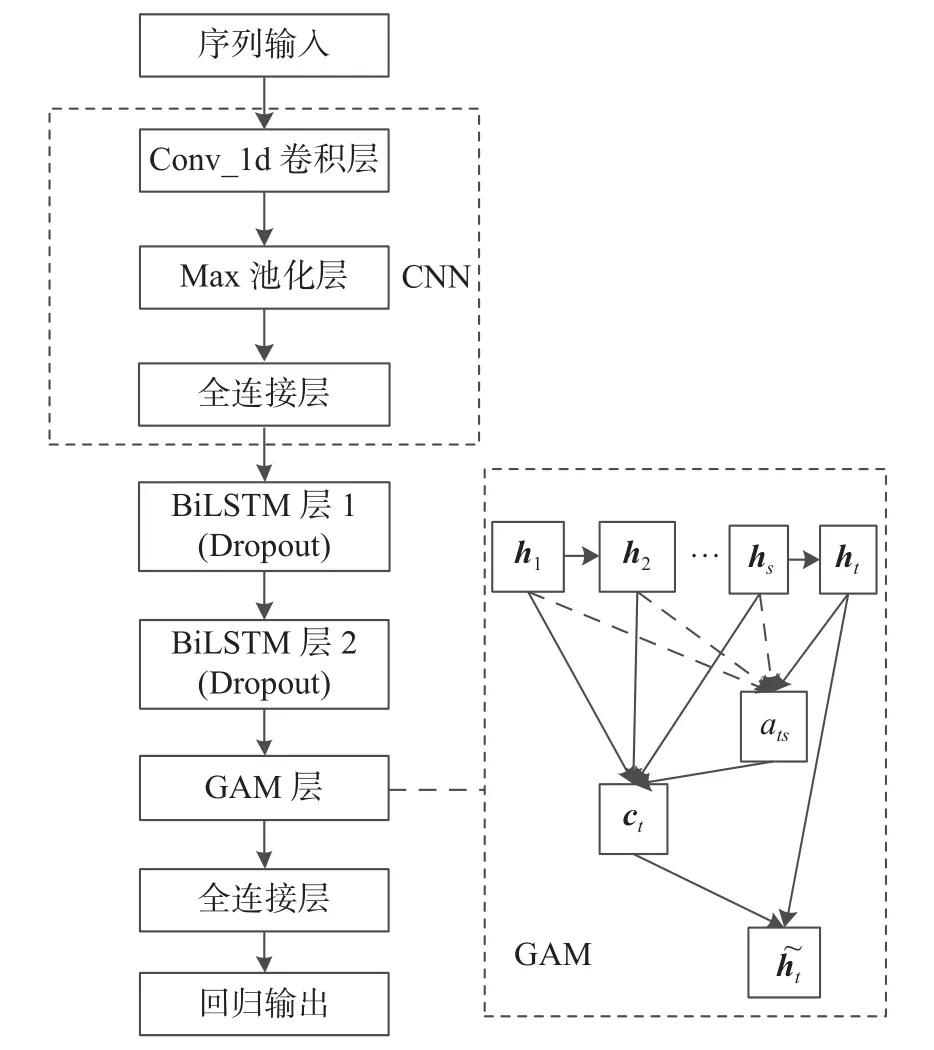
圖4 CNN-BiLSTM-GAM結(jié)構(gòu)圖
3.2 模型超參數(shù)設(shè)置
本文實(shí)驗(yàn)環(huán)境為Matlab R2020b,經(jīng)過(guò)反復(fù)多次實(shí)驗(yàn),模型最優(yōu)超參數(shù)設(shè)置如表3所示。
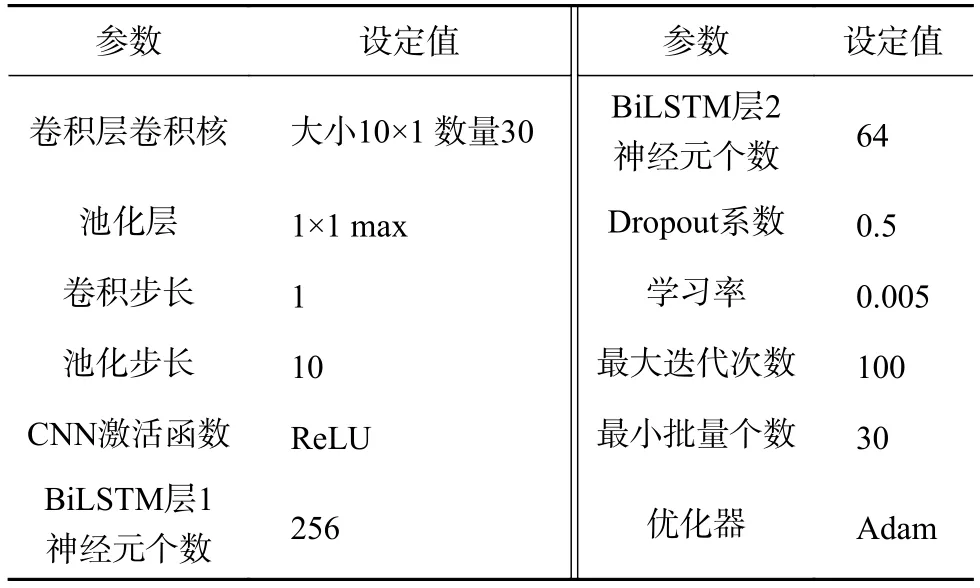
表3 超參數(shù)設(shè)置
3.3 模型輸入輸出
該混合模型串聯(lián)過(guò)程中,上一層的輸出是下一層的輸入。CNN卷積層先接受某一個(gè)時(shí)刻數(shù)據(jù)樣本序列的輸入(一個(gè)維度為特征變量個(gè)數(shù)的列向量),然后進(jìn)入模型的下一層進(jìn)行運(yùn)算直到最終輸出,之后CNN卷積層再次接受下一時(shí)刻的輸入,以此類推。各層輸入輸出數(shù)據(jù)格式如表4所示。
4 實(shí)驗(yàn)與對(duì)比
對(duì)2.2中最后得到的數(shù)據(jù)序列取其前10 000條作為最終實(shí)驗(yàn)數(shù)據(jù)并進(jìn)行數(shù)據(jù)集劃分,將這10 000條數(shù)據(jù)中前9 000組作為模型訓(xùn)練數(shù)據(jù),后1 000組為測(cè)試數(shù)據(jù),用以驗(yàn)證模型的性能。
4.1 數(shù)據(jù)標(biāo)準(zhǔn)化
將實(shí)驗(yàn)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理,將其轉(zhuǎn)化為無(wú)量綱的表達(dá)式,提升模型的收斂速度。這里使用ZScore方法對(duì)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化。
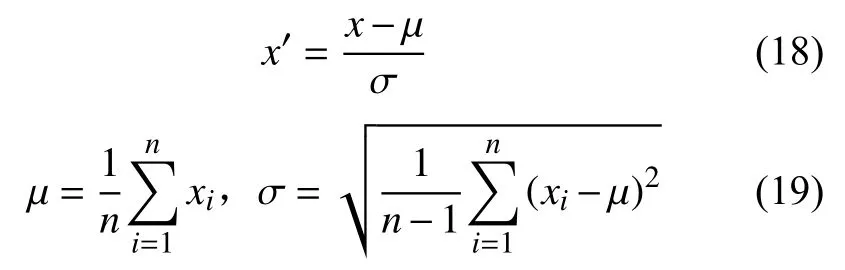
式中:μ——數(shù)據(jù)樣本均值;
σ——標(biāo)準(zhǔn)差;
x——原數(shù)據(jù);
x′——標(biāo)準(zhǔn)化數(shù)據(jù)。
4.2 評(píng)價(jià)指標(biāo)
本次實(shí)驗(yàn)選擇均方根誤差(Root Mean Square Error,RMSE)、平均絕對(duì)百分比誤差 (Mean Absolute Percentage Error,MAPE)、決定系數(shù)(R-square,r2)作為檢驗(yàn)?zāi)P蜏?zhǔn)確性的評(píng)價(jià)指標(biāo)。其中,RMSE和MAPE值越接近0說(shuō)明模型越精確,r2越接近1(r2∈(0,1))說(shuō)明輸入變量對(duì)輸出變量的解釋程度越高,變化曲線擬合優(yōu)度越好。
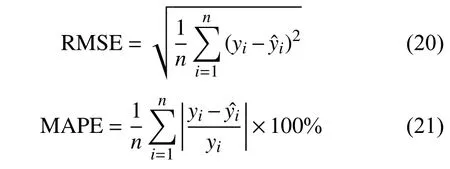
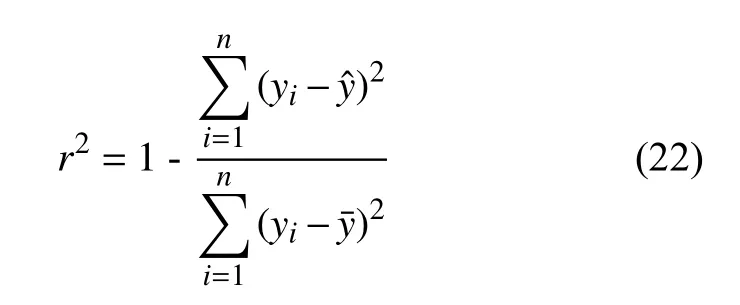
式中:yi——NOx實(shí)測(cè)值;
——模型預(yù)測(cè)值;
——NOx實(shí)測(cè)平均值;
n——樣本總數(shù)。
4.3 實(shí)驗(yàn)結(jié)果與分析
4.3.1 變量延遲時(shí)間估計(jì)對(duì)模型精度的影響
為了說(shuō)明2.2中變量延遲時(shí)間估計(jì)的有效性,分別選取未進(jìn)行時(shí)延估計(jì)的數(shù)據(jù)與校正時(shí)延后的數(shù)據(jù)作為所提出的混合深度神經(jīng)網(wǎng)絡(luò)模型CNNBiLSTM-GAM的建模數(shù)據(jù),同時(shí)使用3.2中設(shè)置的超參數(shù)對(duì)模型進(jìn)行訓(xùn)練,并預(yù)測(cè)鍋爐NOx輸出,最后計(jì)算預(yù)測(cè)結(jié)果的性能指標(biāo)。性能指標(biāo)計(jì)算結(jié)果對(duì)比如表5所示。
由表5可以看出,模型使用含有時(shí)延估計(jì)的數(shù)據(jù),其預(yù)測(cè)結(jié)果的三個(gè)性能指標(biāo)均比使用不含時(shí)延估計(jì)數(shù)據(jù)所得結(jié)果要好,充分說(shuō)明了對(duì)變量的延遲時(shí)間估計(jì)提高了建模數(shù)據(jù)的精度,從而提高模型的預(yù)測(cè)精度。
4.3.2 模型預(yù)測(cè)結(jié)果的對(duì)比驗(yàn)證
利用3.2中設(shè)置的超參數(shù)對(duì)所提出混合網(wǎng)絡(luò)模型CNN-BiLSTM-GAM進(jìn)行訓(xùn)練,并預(yù)測(cè)鍋爐NOx輸出。
為更好說(shuō)明所提出模型的預(yù)測(cè)效果,使用相同的實(shí)驗(yàn)數(shù)據(jù)與實(shí)驗(yàn)條件,選取另外三個(gè)預(yù)測(cè)模型即BiLSTM、BiLSTM-GAM、CNN-BiLSTM進(jìn)行對(duì)比實(shí)驗(yàn),為了使各個(gè)模型的總體結(jié)構(gòu)復(fù)雜度盡可能接近,所選三個(gè)對(duì)比模型中的BiLSTM層均采用三層設(shè)計(jì),各層神經(jīng)元數(shù)量分別為128、116、96;且CNNBiLSTM中的CNN層與所提出混合模型CNNBiLSTM-GAM中CNN層結(jié)構(gòu)相同。學(xué)習(xí)率等其他超參數(shù)設(shè)置也均相同。
四個(gè)模型的預(yù)測(cè)結(jié)果評(píng)價(jià)指標(biāo)對(duì)比如表6所示,時(shí)間耗費(fèi)情況對(duì)比見(jiàn)表7。
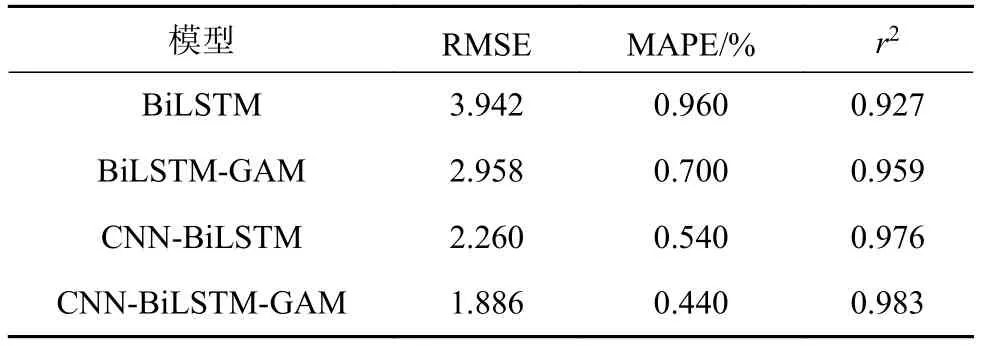
表6 模型評(píng)價(jià)指標(biāo)對(duì)比

表7 模型時(shí)間耗費(fèi)情況對(duì)比
由表6可以看出,CNN-BiLSTM-GAM模型的RMSE和MAPE值最小,說(shuō)明該模型的預(yù)測(cè)精度最高,且該模型的r2系數(shù)最大,說(shuō)明該模型的數(shù)據(jù)跟蹤能力最好;BiLSTM-GAM模型的指標(biāo)計(jì)算結(jié)果比不含GAM的BiLSTM要好,說(shuō)明GAM的使用可以在一定程度上提高模型的預(yù)測(cè)精度;CNNBiLSTM要比BiLSTM的計(jì)算結(jié)果好,說(shuō)明CNN的使用可以深入提取對(duì)象的特征,提高特征學(xué)習(xí)效果,從而提高預(yù)測(cè)精度;所提出模型的預(yù)測(cè)效果最好,說(shuō)明三種不同算法的結(jié)合使用實(shí)現(xiàn)了三種算法之間的優(yōu)勢(shì)互補(bǔ),提高了模型性能。
考慮到模型耗時(shí)與其內(nèi)部因素(模型本身結(jié)構(gòu)復(fù)雜度)以及外部因素(數(shù)據(jù)量大小、計(jì)算機(jī)硬件環(huán)境等)有關(guān),對(duì)于外部因素,表7中模型時(shí)間耗費(fèi)數(shù)據(jù)都是在Intel Core i5-2400 CPU(主頻3.1 GHz),內(nèi)存4 GB,集成顯存2 GB的硬件環(huán)境下取得的,其他實(shí)驗(yàn)條件也都相同。由表7可以看出,無(wú)論是訓(xùn)練時(shí)間還是預(yù)測(cè)時(shí)間,四個(gè)模型之間相差并不大,且CNN-BiLSTM-GAM耗時(shí)最少。CNN-BiLSTM-GAM之所以比CNN-BiLSTM耗時(shí)少,是因?yàn)镚AM計(jì)算開(kāi)銷很小,不會(huì)過(guò)多增加額外計(jì)算量,而CNNBiLSTM比CNN-BiLSTM-GAM多一個(gè)BiLSTM層,其網(wǎng)絡(luò)權(quán)重參數(shù)數(shù)量要比CNN-BiLSTMGAM多,導(dǎo)致訓(xùn)練過(guò)程網(wǎng)絡(luò)學(xué)習(xí)速度低,耗時(shí)增加;CNN-BiLSTM-GAM相比于 BiLSTM、BiLSTMGAM耗時(shí)少,除了因?yàn)镚AM計(jì)算開(kāi)銷小的緣故,還因?yàn)镃NN-BiLSTM-GAM串聯(lián)了一個(gè)CNN層代替了一個(gè)BiLSTM層,CNN權(quán)重參數(shù)數(shù)量比BiLSTM少,計(jì)算效率高,且CNN通過(guò)卷積核池化操作可以充分提取對(duì)象的特征,加快特征學(xué)習(xí)速度,從而減少模型所耗費(fèi)的時(shí)間。另外,所有模型的訓(xùn)練時(shí)間都要比其預(yù)測(cè)時(shí)間大得多,是因?yàn)橛?xùn)練過(guò)程要不斷學(xué)習(xí)特征以更新網(wǎng)絡(luò)各個(gè)權(quán)重參數(shù),因此比較耗時(shí),模型一旦訓(xùn)練好其網(wǎng)絡(luò)權(quán)重也就固定下來(lái)了,進(jìn)行預(yù)測(cè)時(shí)只需與輸入進(jìn)行常規(guī)代數(shù)運(yùn)算即可,因此耗時(shí)很少。
CNN-BiLSTM-GAM預(yù)測(cè)結(jié)果如圖5所示,四個(gè)模型的預(yù)測(cè)結(jié)果對(duì)比見(jiàn)圖6。
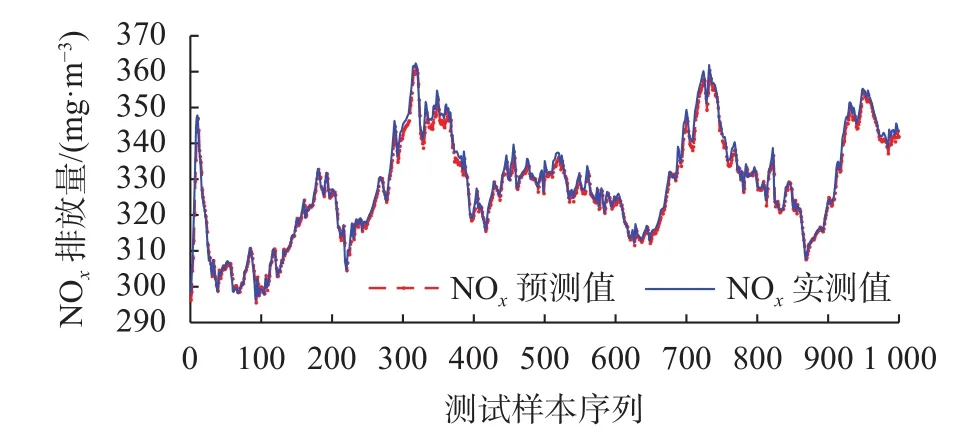
圖5 CNN-BiLSTM-GAM模型預(yù)測(cè)結(jié)果

圖6 四種模型預(yù)測(cè)結(jié)果對(duì)比
由圖 5可以看出,CNN-BiLSTM-GAM模型NOx預(yù)測(cè)值與實(shí)測(cè)值之間差距極小,曲線幾乎完全重合;由圖6可以看出,四個(gè)模型的NOx預(yù)測(cè)值都可以很好地跟蹤實(shí)測(cè)值變化,且CNN-BiLSTMGAM模型最貼近實(shí)測(cè)數(shù)據(jù)。
為了進(jìn)一步分析對(duì)比模型的泛化能力,分別將四個(gè)模型的預(yù)測(cè)結(jié)果進(jìn)行線性擬合,見(jiàn)圖7。
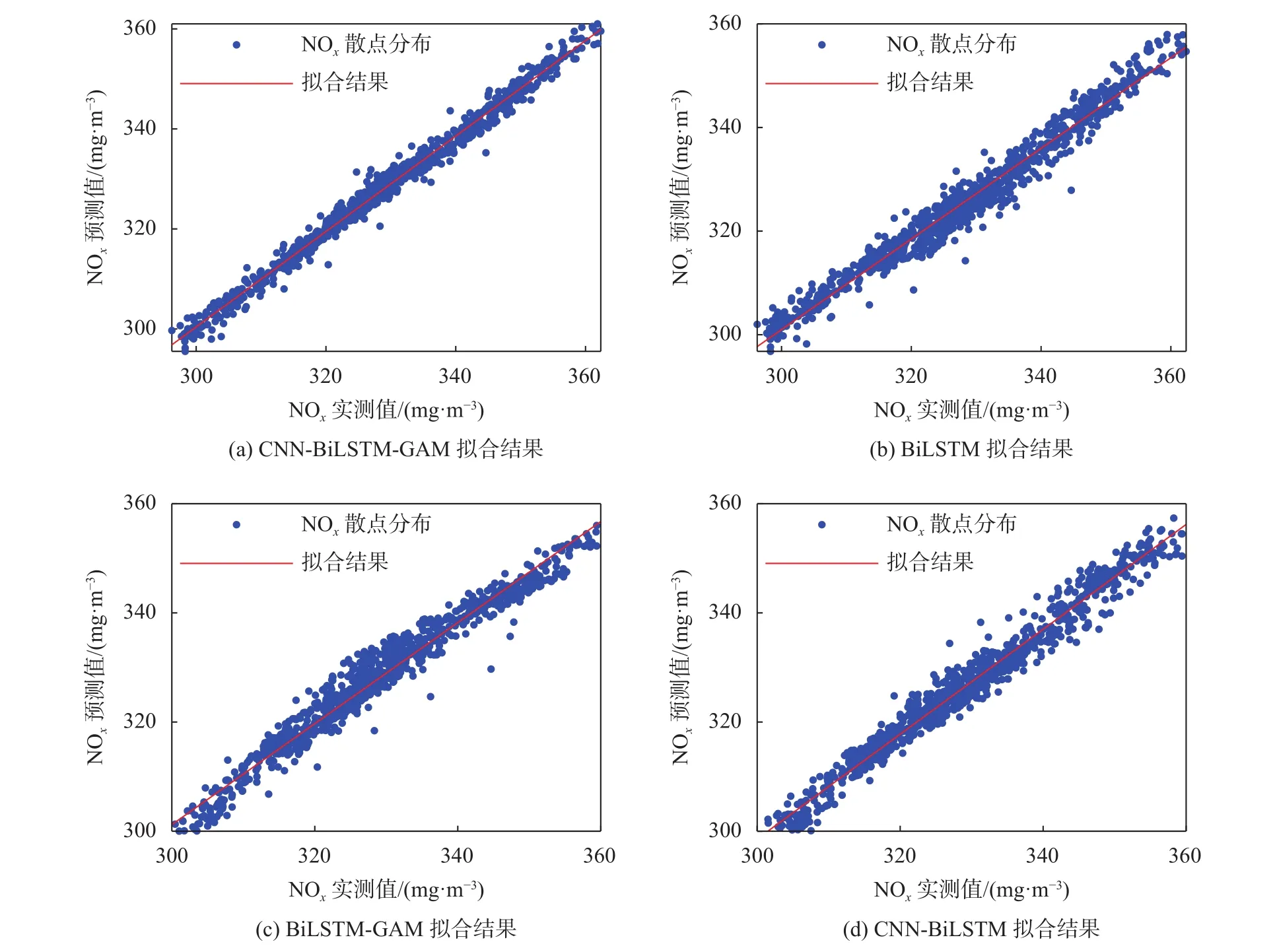
圖7 四種模型線性擬合結(jié)果對(duì)比
如圖7所示,四個(gè)模型預(yù)測(cè)值和實(shí)際值散點(diǎn)基本都均勻分布在擬合直線附近,擬合直線均比較接近理想直線(直線方程:x-y=0),且CNN-BiLSTMGAM模型擬合直線最接近理想直線,擬合效果最好。
5 結(jié)束語(yǔ)
本文提出一種基于數(shù)據(jù)驅(qū)動(dòng)的融合CNN與BiLSTM并引入全局注意力機(jī)制GAM的混合學(xué)習(xí)模型來(lái)預(yù)測(cè)未來(lái)時(shí)刻電站鍋爐NOx排放量,所提出的模型能充分提取數(shù)據(jù)序列的空間和時(shí)序特征,自適應(yīng)分配網(wǎng)絡(luò)隱含層狀態(tài)輸出權(quán)重,收斂速度快,且不容易發(fā)生過(guò)擬合。實(shí)驗(yàn)驗(yàn)證該模型與其他典型預(yù)測(cè)模型相比,RMSE僅有1.886,而r2系數(shù)達(dá)到0.983,模型預(yù)測(cè)精度高,誤差小,泛化能力好。在今后的研究中計(jì)劃尋找一種優(yōu)化算法對(duì)模型的超參數(shù)進(jìn)行自動(dòng)尋優(yōu)而不是通過(guò)經(jīng)驗(yàn)手動(dòng)調(diào)節(jié),以提高工作效率,進(jìn)一步提高模型的性能。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
