面向邊緣計算的差分分塊運動目標快速檢測方法研究
2022-11-22 05:59:00賀志洋
物聯網技術 2022年11期
賀志洋,秦 蕾,陳 璽,李 楊
(北京計算機技術及應用研究所,北京 100854)
0 引 言
基于機器視覺的運動目標檢測是根據視頻序列圖像在時間和空間上的信息,經過一定推理計算來確定運動目標的位置。運動目標檢測也稱前景檢測,是視頻分析技術領域的重要內容,也是目標跟蹤和行為分析的前提,它在AR、人機交互、視頻監控等多領域得到廣泛應用[1]。在物聯網的視頻監控領域,運動目標檢測過程往往是在本地邊緣計算層完成的。由于本地的計算能力有限,所以邊緣計算中亟需計算成本低且不影響準確率和精度的輕量化檢測算法。
目前已有專家學者提出多種運動目標檢測方法,主要有幀間差分法、背景建模法、光流法和機器學習法四類。
幀間差分法是利用視頻中時間相近的若干幅圖像(幀)的差異,檢測出運動目標[2]。楊嘉琪等人[3]采用基于自適應學習率的混合高斯背景建模,以像素點間的匹配次數作為參考量來修正模型的學習速率,提高算法對動態環境的適應性;通過基于邊緣提取的三幀差分改進算法對視頻圖像的目標輪廓進行提取,保證目標信息的完整。余長生等人[4]提出了一種將TFDM與混合高斯模型(GMM)相結合的運動目標檢測方法;與單獨的TFDM和GMM算法相比,既能得到相對完整的運動目標,又能減小噪聲等外部干擾帶來的影響。幀間差分法雖然簡單,但目標中往往出現空洞,需要累積多幅圖像(幀)后才能得到完成的目標。
光流法是利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關系,從而計算出相鄰幀之間物體的運動信息的一種方法。它是通過視頻中多個點在不同幀間的移動,檢測移動的目標[5]。Xia等人[6]利用光流的高階特征進行復雜背景下的人體動作識別。崔捷等人[7]為了保證生成器能夠利用正常的視頻幀產生清晰的高質量預測結果,而讓異常的幀預測不清晰,基于U-Net設計了輸入具有時間差的兩幀雙流生成器,并取得較佳的檢測效果。但是光流法計算量相對較大,不適合性能較低的視頻采集分析設備,尤其是邊緣計算設備。
背景建模法是建立視頻中的背景模型,再利用當前圖像幀與背景模型的差異,分離出運動目標[8]。劉志豪等人[9]提出一種以ViBe算法為基礎的改進算法,采用多幀初始化背景模型的方式,為背景模型引入可靠真實的背景樣本。楊國萍[10]在動態場景中準確高效地檢測到監控內的環境異常變化,并展開研究,提出一種參數自適應的高斯混合背景模型,并獲得較佳的測試效果。但是背景建模法計算量較大,不適合性能較低的視頻采集分析設備。
機器學習法是利用待識別對象的多幅圖像訓練神經網絡,再用訓練好的神經網絡分離圖像中的目標[11]。王震宇等人[12]利用深度卷積神經網絡在公開的OPPORTUNITY傳感器數據集中進行運動識別,實驗證明該方法能夠改進以前手工設計的模型結構,且是可行有效的。但是機器學習法需要大量的訓練圖像、大量的訓練時間、高性能的計算設備,對運行模型的設備性能要求也較高。
上述研究在運動目標檢測中均取得了較大進展,但是針對物聯網的邊緣計算均難以滿足輕量化的計算需求。因此本文提出一種差分分塊運動目標快速檢測算法。該算法的輸入是相近兩幀圖像,避免了背景模型的構建和更新步驟。同時,該算法具有計算復雜度和時間復雜度較低的優點。
1 差分分塊運動目標快速檢測算法
差分分塊運動目標快速檢測算法是對采集視頻中時間相近的兩幅圖像(幀)進行差分,并將圖像分塊,選擇移動塊對圖像進行二分法查找,最終確定運動目標。該算法主要包括如下步驟:采集視頻中時間相近的兩幅圖像(幀)并將圖像分塊,計算采集到的兩幅圖像的差異圖像并二值化,在采集時間靠后的圖像上選擇移動塊,在選擇的移動塊的鄰接塊中選擇移動塊,組成運動目標,其流程如圖1所示。
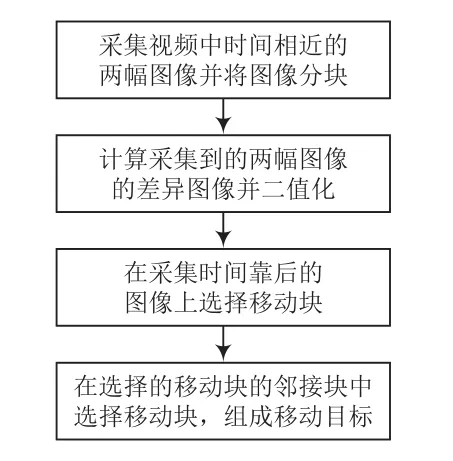
圖1 差分分塊的運動目標快速檢測算法流程
采集視頻中時間相近的兩幅圖像(幀)并將圖像分塊。采集到的兩幅圖像(幀)分別為圖像I1和圖像I2,圖像I2的采集時間靠后,通常時間差在200 ms左右。圖像I1和圖像I2的大小相同,為M行N列,劃分為m行n列的小塊,m 圖2 圖像分塊示意圖 計算采集到的兩幅圖像的差異圖像并二值化。首先,進行差分運算,兩幅圖像I1和I2的差異圖像I3的像素值是圖像I1和I2對應像素值之差的絕對值,即I3(x, y)=|I2(x, y)-I1(x, y)|,其中圖像I3的大小與圖像I1和I2相同,也劃分為m行n列的小塊。其次,對差分圖像I3進行二值化。二值化的閾值根據經驗設定為:閾值T=均值+標準差。 在采集時間靠后的圖像上選擇移動塊。二值化后圖像I3中的塊包含的差異像素數目大于等于塊中像素數目的1/10時,標記為差異塊。如果采集時間靠后的圖像I2的某個塊在差異圖像I3中對應塊的鄰接塊是差異塊,則圖像I2中的這個塊就標記為候選移動塊。圖像I2的某個塊在差異圖像I3中對應塊的上、下、左、右、左上、左下、右上、右下等8個鄰接塊中,有一個鄰接塊是差異塊,則圖像I2中的這個塊就標記為候選移動塊。計算候選移動塊在圖像I1中對應的運動向量和運動向量處的差異。如果圖像I2中的這個塊在運動向量處的差異小于等于閾值T,則標記為移動塊,否則不標記。運動向量個數計算可以采用視頻圖像編碼的方法計算,運動向量的絕對值不超過圖像塊的大小。 在選擇的移動塊的鄰接塊中選擇移動塊,組成運動目標。具體實施時,如果采集時間靠后的圖像I2的某個塊與某個移動塊鄰接,且其在圖像I1中的運動向量與移動塊的運動向量相近,差值在-1~min(M/m,N/n)范圍內,且在運動向量處的差異小于等于閾值T,則這個塊也標記為移動塊。所有鄰接的移動塊組成運動目標。 為了驗證提出的差分分塊運動目標快速檢測算法的有效性,利用MATLAB2019軟件在ThinkPadE450c硬件平臺上進行實驗驗證。實驗對象為2007年英國的基于視頻和信號的監控系統會議提供的AVSS數據集。 通過實驗發現,該方法對上述實驗對象均可有效識別其運動目標,其中一組的實驗過程及效果如圖3所示。其中,測試視頻的幀率為30 fps,視頻的單幀圖像像素為240×320。實驗所使用的樣本視頻為50組,每組樣本視頻時間長度為10 s。圖3中:(a)是視頻中前幀圖像,(b)是視頻中后幀圖像,(c)是兩幀圖像的差分圖像,(d)是對差分圖像做二值化運算并分塊得到的圖像,(e)是在視頻中的后幀圖像中檢測并標記出的移動塊,將移動塊合并后則得到圖像(f),圖像(f)也是所得到的運動目標識別結果。 圖3 實驗過程及效果 為了進一步驗證差分分塊運動目標快速檢測算法的實時性,引入了光流法和已經訓練好的YOLO3作為對比方法。其中,光流法是基于光流假設的一種傳統運動目標識別方法;YOLO3是近年來提出的一種圖像快速分割的網絡模型,將對象檢測重新定義為一個回歸問題。它將單個卷積神經網絡(CNN)應用于整個圖像,將圖像分成網格,并預測每個網格的類概率和邊界框。這兩種對比方法均可有效識別出視頻中的運動目標。 利用上述實驗平臺和實驗對象分別使用光流法和YOLO3進行定位識別,其平均耗時見表1所列,其中光流法和YOLO3的平均耗時分別為8.437 s和0.352 s。 表1 運動目標識別耗時 為了滿足物聯網中視覺設備邊緣計算的輕量化需求,提出了差分分塊運動目標快速檢測算法,并通過實驗進行了驗證。結果表明,本文所提出的算法可有效識別視頻圖像中運動目標,且計算復雜度和時間復雜度低,具有耗時低的特點。對硬件設備的計算能力要求不高,能夠滿足邊緣計算的輕量化需求。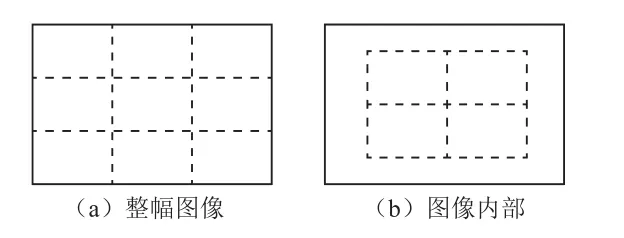
2 實驗驗證


3 結 語
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
中國特種設備安全(2018年11期)2019-01-08 02:08:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
海峽科技與產業(2016年3期)2016-05-17 04:32:12
