基于多尺度多分支特征的動作識別
2022-11-24 06:56:40韓廣良
液晶與顯示 2022年12期
張 磊,韓廣良
(1.中國科學院 長春光學精密機械與物理研究所,吉林 長春 130033;2.中國科學院大學,北京 100049)
1 引 言
人體動作識別是指根據輸入的動作時間序列(RGB圖像序列或人體骨骼點序列)進行分析,從而識別出該動作序列所進行的動作類別,是近年來的研究熱點之一。人體動作識別在智能監控系統、人機交互、動作輔助矯正等諸多領域有著廣泛的應用前景。同時由于人體骨架序列的數據量極小,遠小于RGB視頻序列,且結構簡單、計算速度快,幾乎不會受到背景的影響,所以非常適合于動作識別的應用。
在早期的研究中,研究人員常通過人為設計多種動作特征來代表的人體的運動軌跡。Dalal等首先提出使用光流直方圖的方法來獲取運動軌跡[1],隨后Dalal等又提出了方向梯度直方圖的方法[2]。在此基礎上,Wang等提出了密集軌跡法(Dense Trajectory,DT)及其改進方法增強的密集軌跡法(improved Dense Trajectory,iDT),通過大量采樣視頻中隨機的像素點追蹤時間維度的該像素點的運動軌跡[3-4]。由于人工設計的特征工作量較大、準確率低,所以基于神經網絡的方法逐漸應用于動作識別中[5]。Du等于2015年首次提出了將卷積神經網絡(Convolutional Neural Net?work,CNN)應用于骨骼動作識別的SK-CNN,將人體骨架序列結構歸一化為固定大小輸入到CNN網絡中進行動作識別[6]。由于人體骨架序列與CNN的輸入數據結構存在差異,Wang等提出了關節軌跡圖(Joint Trajectory Maps,JTM),將骨架數據投影到3個正交平面從而得到3幅2D骨架數據,歸一化后送入預訓練好的CNN進行動作識別[7]。Li等借鑒共現特征學習的方法提出了HCN網絡[8]。基于CNN的方法往往參數量較大,也存在遮擋、視點變化等問題,所以基于循環神經網絡(Recurrent Neural Network,RNN)和基于圖卷積網絡(Graph Convolution Neural Network,GCN)的算法[9-10]也開始逐漸出現。Shahroudy等提出利用長短時記憶網絡(Long Short-Term Memory,LSTM)進行動作識別,但無法獲得具有競爭力的結果[11]。由于圖卷積網絡(Graph Convolution Neural Network,GCN)對具有拓撲結構的人體骨架數據處理十分有效,所以Yan等首先在GCN的基礎上提出了ST-GCN,利用圖卷積提取人體動作的時空特征[12]。Li等在ST-GCN的基礎上提出AS-GCN,揭示了關節點之間的潛在關系[13]。
基于人體骨架序列的動作識別相比于基于RGB視頻的方法具有數據量小,不受外界環境、光照、人體外貌等因素影響,魯棒性高的優點,成為當下的研究熱點。而在基于骨架的方法中,基于CNN的方法是主流,也取得了較好的成果,但其網絡大多依賴于規模較大的網絡,計算量較大,且難以直接處理人體骨架序列這樣的拓撲結構。基于RNN的方法一般識別準確率不如其他方法,并且隨著神經網絡層數的不斷加深,極易出現梯度消失的現象,使得訓練的準確率突然降低。基于GCN的方法具有CNN的優點,同時由于引入了人體拓撲結構的先驗知識,能夠進一步提升識別性能。除此之外,現階段的算法尚不能在多種運動特征之間發現更深層次的關系,并且對于提取到的多種運動特征信息都很難得到高效的應用。
針對以上問題,本文首先根據動作識別網絡模型的多分支輸入和原始數據的結構,對原始數據進行了特征增強,將多分支的輸入形式改進為多分支的融合特征,并經過多個網絡模塊后融合多層次多種類的特征信息,從而增強了多特征之間的相關性,從特征層面更全面地描述一個人體骨架序列。其次,本文通過多尺度特征對時序卷積進行了改進,并與圖卷積神經網絡結合,使得網絡模型能夠提取不同深度的時間特征和空間特征,提高了動作識別的準確性。通過殘差連接圖卷積神經網絡和多尺度時序卷積,在提取到深層次特征信息的同時很大程度上解決了網絡退化等問題。
2 算法的構成及原理
2.1 原始數據的特征增強
原生的人體骨架序列數據在采集時可能存在數值缺失、數值范圍小等問題,同時由于設備精度問題使得骨架序列在時間維度上存在與動作無關的抖動,并且在不同的動作類別中,骨架序列的幀數也不同。針對以上問題,本文分別在時間和空間兩個維度進行如圖1所示的特征增強。歸一化、坐標轉換、深度優先樹遍歷等基于空間維度的特征增強重點關注于關節點的位置坐標和聯系上,Savitsky-Golay平滑濾波、插幀等基于時間維度的特征增強重點關注于骨架序列幀間的聯系。
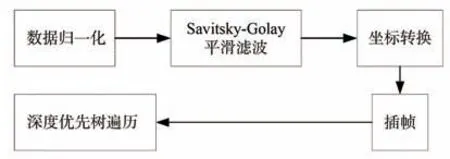
圖1 特征增強處理方法Fig.1 Feature enhancement processing methods
數據集中的關節點坐標的大小常位于小數點后一位或兩位,使得動作的關節點過于密集,不利于動作類別的預測。最好的處理方法是將整體坐標所處的區間放大,所以采用歸一化的方式將關節點坐標的區間擴大至(-1,1),新坐標可表示為:

其 中Jt,c、Jt,c,max、Jt,c,min分 別 表 示 在 某 一 動 作 中t時刻x、y、z分量上的坐標。
原始的人體骨架數據沿著時間維度運動時會存在一些與動作無關但影響類別判斷的噪音,這一噪音是人體骨架數據在可視化時運動中關節點的不自然抖動。針對這一問題,本文使用Savitsky-Golay濾波器進行濾波。Savitsky-Golay濾波器是一種在時域內基于局域多項式最小二乘法擬合的濾波方法,這種濾波器最大的特點在于在濾除噪聲的同時可以確保信號的形狀、寬度不變。Savitsky-Golay濾波器通過多項式對移動窗口內的數據進行多項式最小二乘擬合,算出窗口內中心點關于其周圍點的加權平均和,可表示為:
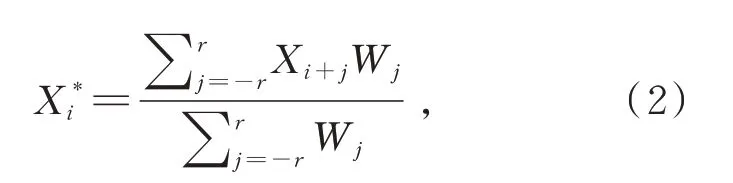
其中Xi和Xi*為濾波前、后的數據,Wj為移動窗口平滑過程中的權重因子,窗口長度為2r+1。窗口長度是平滑濾波中最重要的參數,若窗口長度過小則噪音無法減弱,若窗口長度過長則會將原本正常的動作變化幅度減弱甚至消減至靜止,取r=4。
接著為了確保關節點的參考坐標系一致,同時減少采集過程中設置的相機多視角產生的影響,以圖2所示的骨架結構及編號為基礎,將每個動作序列中的第一幀骨架的脊柱中心點(編號20)設置為參考坐標系的原點,脊柱(編號0和1)所在的直線作為z軸,兩側肩膀(編號4和8)所在的直線作為x軸。原始的骨架結構數據中各個類別的動作幀數不是統一的,多則接近300幀,少則少于50幀,無法直接輸入到后續網絡中。針對這一問題,本文采用插幀的方式,將幀數設置為300,采用三次樣條插值法進行處理。若區間[a,b]可分為n個 區 間[(x0,x1),(x1,x2),(x2,x3),…,(xn-1,xn),],其中a=x0,b=xn,在n個區間中的每個區間都各自存在三次樣條函數Si(x),可表示為:
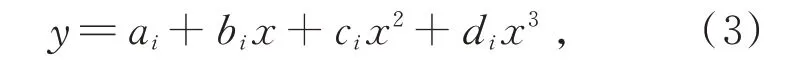
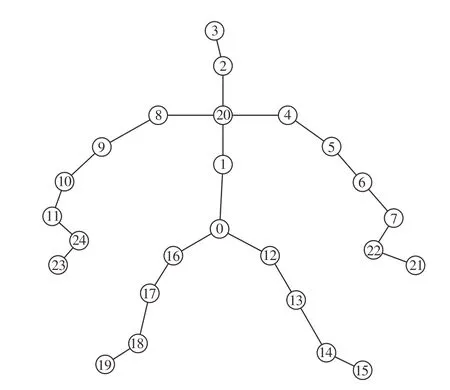
圖2 人體骨架結構及編號Fig.2 Human skeleton structure and number
其中ai、bi、ci和di為Si(x)在n個 區間中的第i個小區間的參數。Si(x)必須滿足3個條件:在每個小區間(xn-1,xn)內Si(x)都是一個三次方程;滿足插值條件,即xn必須在S(x)函數的曲線上;Si(x)的曲線是光滑的,即S(x)、S′(x)、S″(x)是連續的。可計算得到:

其中mi=S″i(xi),hi=xi+1-xi。
為了進一步有效學習人體骨架中關節點的空間關系,引入了深度優先樹遍歷[14]。輸入格式中一對相鄰關節的空間相關性與連接這一對關節的邊有關,若這對關節在物理上是相連的,則空間相關性就強。在動作識別中,空間相關性一般是指人體骨骼結構中相鄰關節點之間的聯系緊密程度。空間相關性越強,最后所反映的動作識別準確率越高。原始數據的輸入形式是將抽象的關節點坐標序列轉化為T×N×C的矩陣,其中T為人體動作序列的幀數,N為人體骨架的關節點數量,C為關節點坐標的維度數。在代表關節點數量的N維度中,人體的25個關節是以0,1,2,3,…,23,24這樣順序編號進行排列的,如圖3(a)所示,相鄰的關節在圖2所示的結構中基本上是不相連的,關節之間便沒有相關性。根據這一理論,可將人體骨架結構改變為圖4所示的樹形骨架結構圖。根據深度遍歷,按照從上到下、從左到右的順序,在輸入數據的N維度上,人體的關節可排序為1,20,2,3,2,20,4,5,6,7,22,21,22,7,6,5,4,20,8,9,10,11,24,23,24,11,10,9,8,20,1,0,12,13,14,15,14,13,12,0,16,17,18,19,18,17,16,0,1,N由原來的25變為49。
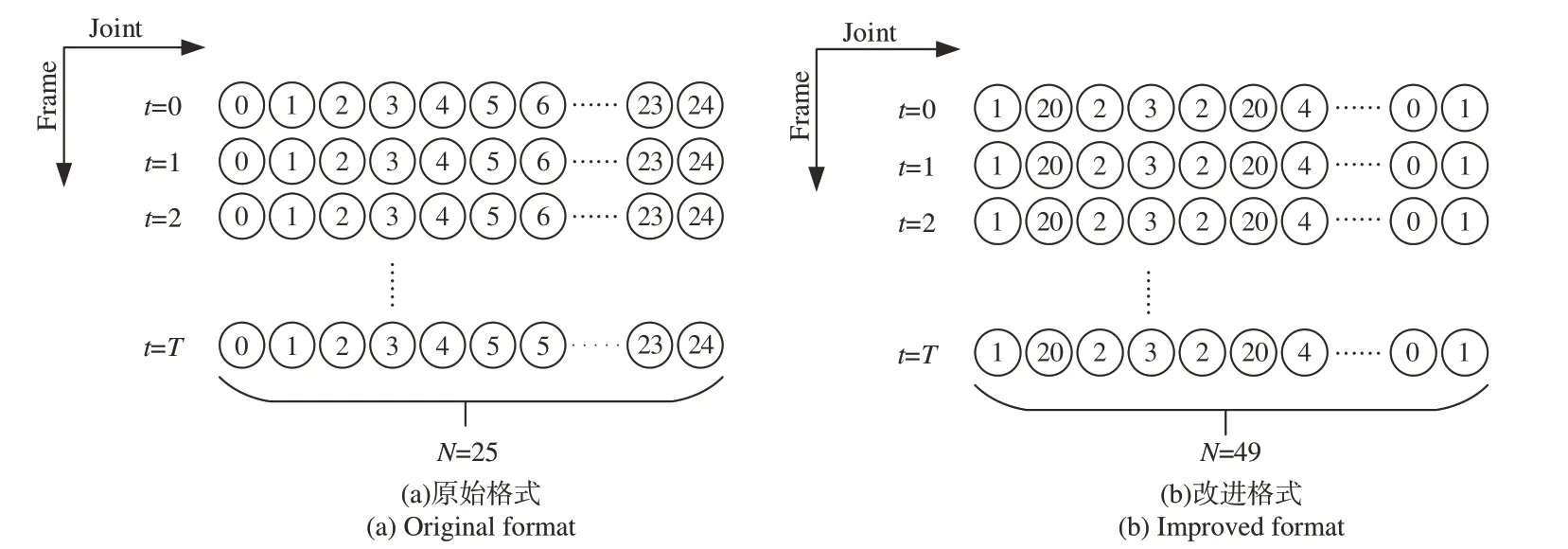
圖3 數據輸入的原始和改進格式Fig.3 Original and improved formats for input
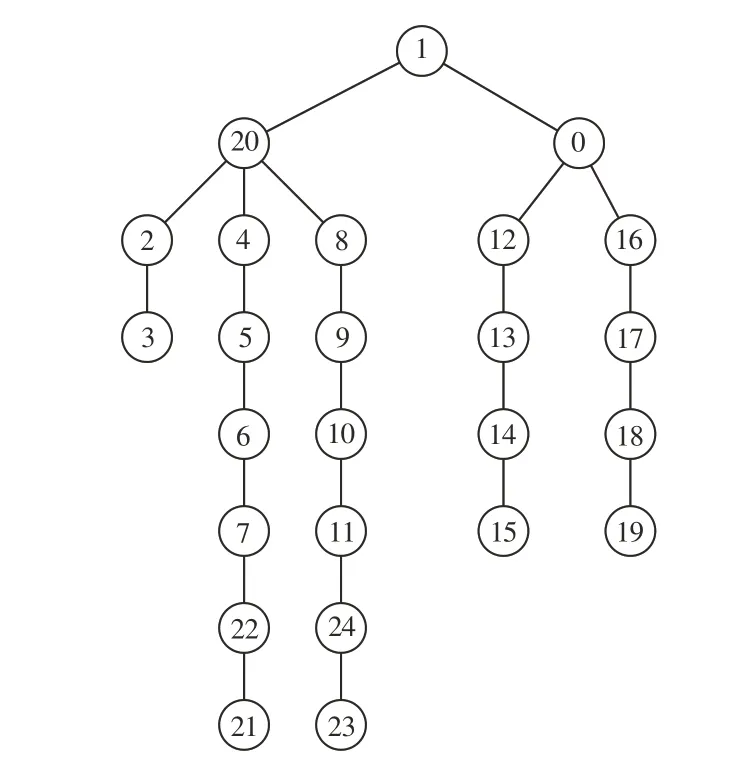
圖4 樹形骨架結構圖Fig.4 Structure diagram of tree structure skeleton
2.2 多分支輸入
經過特征增強后,單一樣本中的人體骨架數據結構可表示為四維向量(C,T,V,M),其中C表示骨架關節點的x、y、z分量;T代表骨架數據的幀數,經過特征增強后固定為300幀;V代表每一幀中的人體關節點數量;M代表每一個動作的參與人數。參考ResGCN[15]中關節點坐標(Joints)、運動向量(Velocities)和骨節(Bones)三分支輸入,為了增加輸入數據的空間相關性,本文將三分支輸入修改為Bone length+Joints、Bone length+Ve?locities和Bone length+Bone angle。
多分支輸入的操作需要將特征融合在一起,從而將經過一定深度的神經網絡提取到的特征拼接在一起,此時的特征在經過多層神經網絡后具有一定的深層信息,而特征融合的具體位置在哪一層神經網絡之后則需要進一步的實驗與研究。
2.3 多尺度時空卷積
本文網絡模型的基本結構由可提取時間和空間特征的多尺度時空卷積構成。多尺度指的是對網絡中不同深度的特征進行采集融合。多尺度時空卷積模塊由負責提取時間特征的多尺度時序卷積和負責提取空間特征的圖卷積組成,使得網絡能夠分別提取網絡中的時間特征和空間特征。
本文中的多尺度時序卷積模塊如圖5所示。網絡模塊中的第一層是卷積核為1×1的普通卷積,其作用是降低輸入數據的通道維數;模塊中的第二層為膨脹系數分別為1,2,3的膨脹卷積[16],卷積核為m×1。原本大小為m×n的卷積核要對兩個維度的特征進行處理,但當n=1時,卷積核只會處理一個維度的特征,因此通過這種方式來只對時間維度進行特征提取。多尺度特征通過設置不同的膨脹系數來體現,當膨脹卷積擁有不同的膨脹系數時,卷積核的感受野也隨之變化,卷積所能提取到的特征也會有所區分。膨脹卷積的優點在于在保持參數個數不變的情況下增大了卷積核的感受野,讓每個卷積輸出都包含較大范圍的信息,同時它可以保證輸出的特征映射的大小保持不變。
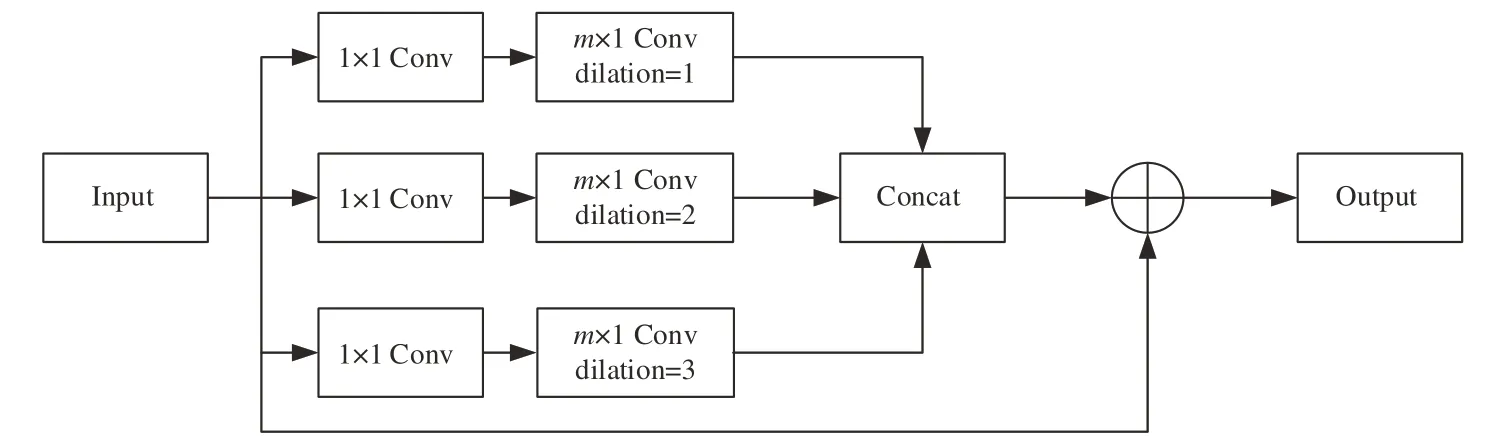
圖5 多尺度時序卷積模塊結構圖Fig.5 Structure diagram of multi-scale temporal convolution
輸入特征在經過多個并列的膨脹卷積提取多尺度時間特征后,使用Concat函數進行拼接,得到的特征通道維度與輸入一致,此時使用殘差將輸入特征與輸出特征相連接,使得輸出同時具有淺層網絡的特征表現和深層網絡的特征表現,有助于解決梯度消失和梯度爆炸問題,在網絡層數不斷加深的同時,又能保證良好的性能。
GCN處理的主要對象是骨架數據、交通網絡數據、化學分子結構數據等具有一定拓撲結構的數據。在動作骨架的每一幀中,圖卷積可表示為
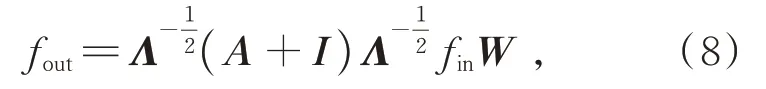
其中fin和fout分別代表輸入和輸出特征,A表示鄰接矩陣,I為單位矩陣,W為權重矩陣表示歸一化鄰接矩陣。
本文圖卷積的鄰接矩陣使用距離分區(Dis?tance partitioning)的方法。對于一個龐大的圖結構而言,不可能把所有的節點特征直接相加。為了劃分圖結構中每一個節點的鄰居節點,即骨骼結構中節點附近的節點,采用距離分區的方法將不同的鄰居節點編為不同的序號,如圖6所示,同一個序號的鄰居節點看作一個鄰居子集,也就形成了多個鄰接矩陣。本文中分區子集設為4個,即距離目標節點的距離分別為0,1,2,3。距離為0為節點自身,位于鄰接矩陣的一個子集中;距離為1的節點為與目標節點直接相連,位于鄰接矩陣的第二個子集中;距離為2和3的節點則分別位于鄰接矩陣的第三和第四個子集中。
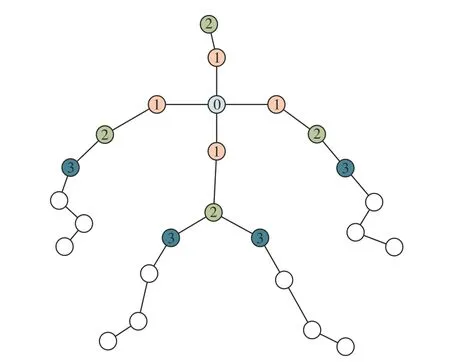
圖6 距離分區的劃分原理Fig.6 Division principle of distance partitioning
由此得到的鄰接矩陣可視化結果如圖7所示。使用了距離分區的分區策略后,圖卷積可表示為:
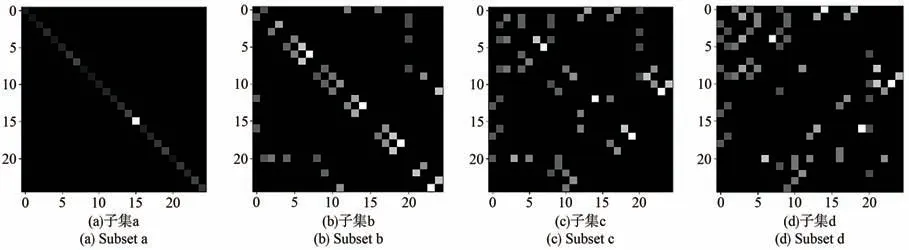
圖7 鄰接矩陣可視化結果Fig.7 Visualization results of adjacency matrix
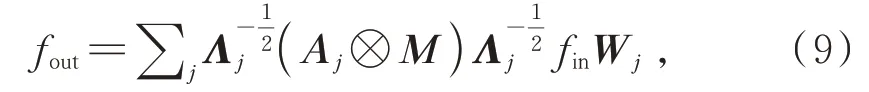
其中j=0,1,2,3,表示鄰接矩陣的子集;M為權重矩陣,使用了距離分區的鄰接矩陣依照距離的大小為子集劃分不同的權重。基于距離分區的分區策略能夠建模如關節之間的相對平移等關節點的局部差異性,增加圖卷積提取空間特征的多樣性。
多尺度時空卷積模塊的結構如圖8所示。在一定程度上,網絡的層數越深則表達能力越強,越能夠提取到深層次的特征信息,性能也越好。但隨著網絡深度的增加,也帶來了許多問題,如梯度消散、網絡退化等,殘差連接可以在很大程度上解決這一問題。

圖8 多尺度時空卷積模塊結構圖Fig.8 Structure image of multi-scale spatial-temporalconvolution
2.4 整體網絡結構搭建
整體網絡結構如圖9所示,由多尺度時空卷積模塊堆疊而成。原始的人體骨架序列存在諸多缺陷,特征提取階段通過基于時間維度和空間維度的特征增強加強了數據的表達能力。將處理好的數據以Bone length+Joints、Bone length+Velocities和Bone length+Bone angle的 融 合 特 征的方式分別輸入到三分支中,利用改進的多尺度卷積提取特征并融合在一起。動作分類階段將拼合后的數據輸入帶有注意力機制的多尺度卷積進行多次訓練,最后進入分類器進行動作分類。
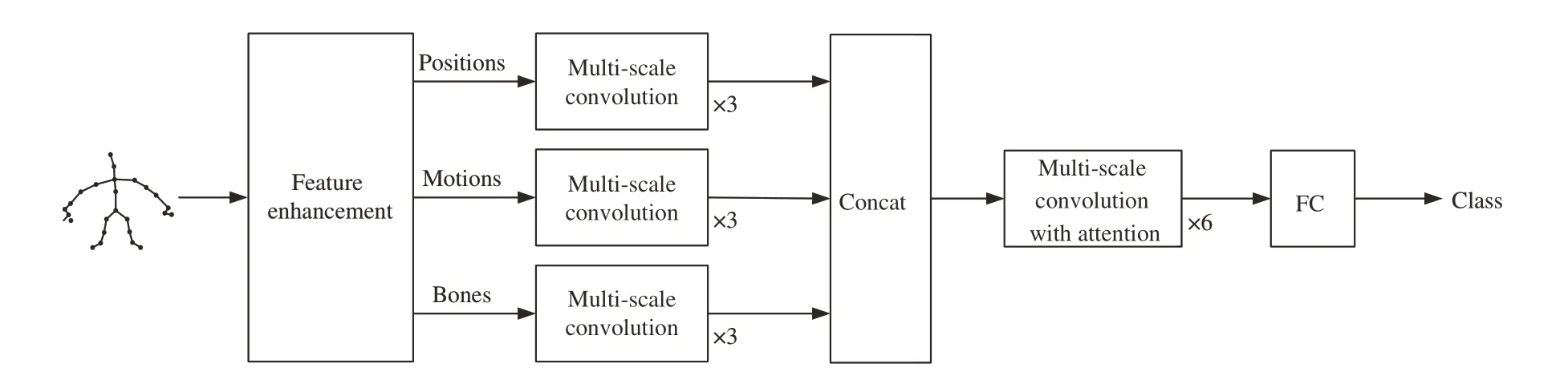
圖9 網絡結構示意圖Fig.9 Schematic diagram of network structure
為了更加全面地認識本文所設計的網絡結構,本節詳細給出了多尺度時空卷積模塊的結構和在每一層所使用的參數,如表1所示。表1中Conv_gcn代表圖卷積模塊,Conv_tcn代表多尺度時間卷積模塊,包含多個不同尺度的卷積。
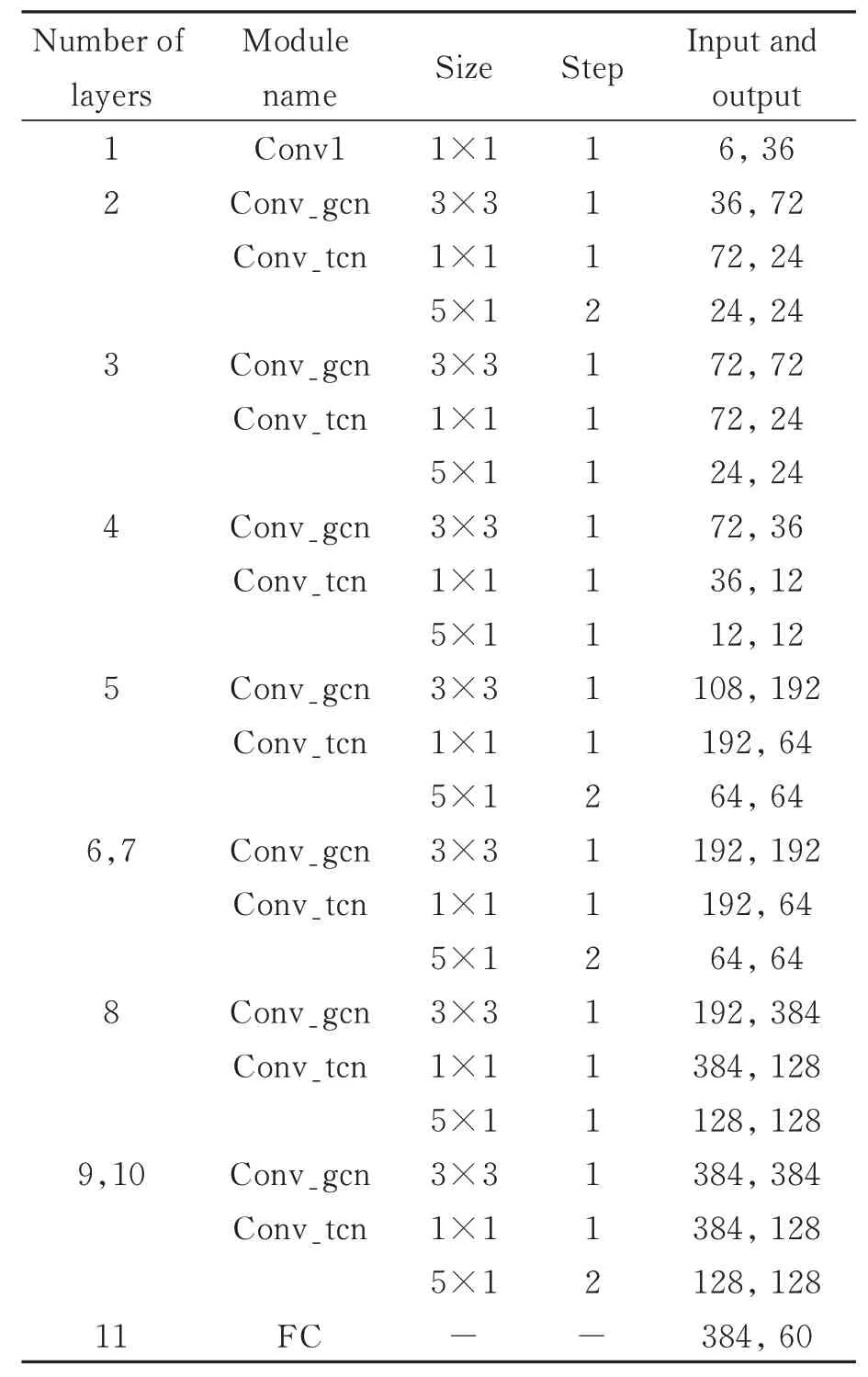
表1 多尺度卷積網絡參數表Tab.1 Network parameter table of multi-scale convolution
3 實驗結果與分析
3.1 實驗環境
本實驗使用的數據集為NTU RGB-D 60和NTU RGB-D 120的人體骨架結構數據。在RTX 3090上進行訓練,顯存為25.4 GB。所利用的環境為Python 3.6,PyTorch 1.10.0。
在訓練過程中,所有需要學習的參數均用Xavier方法進行初始化。網絡模型使用交叉熵損失函數(Cross Entropy)進行訓練,優化器采用隨機梯度下降法(Stochastic Gradient Descent,SGD)對網絡參數進行優化,學習率為0.1,數據集在迭代70次(Epoch)后停止訓練,批(Batch)大小設置為16。
3.2 特征增強方法對比實驗分析
為了充分證明每種特征增強方法對于動作識別的作用,需要分別對每一種方法進行實驗測試。基于NTU RGB+D 60數據集的Crossview(CV)劃分標準,將經過各自方法進行特征增強后的數據輸入到網絡中,得到的識別準確率如表2所示。

表2 不同特征增強方法在NTU RGB-D 60數據集的準確率Tab.2 Accuracy of different feature enhancement method on NTU RGB-D 60 dataset
由實驗結果可以看出,每種方法都取得了一定的識別準確率。在這5種特征增強方法單獨的實驗結果中,只使用深度優先樹遍歷的模型得到了最高的識別準確率,說明基于深度優先樹遍歷的方法的有效性得到了實驗驗證。其次識別準確率最高的是基于坐標轉換的動作識別,接著3種普通的數據增強方法排在后面,且與前兩種的準確率差別較大,說明網絡對于從多個層次描述空間特征是十分認可的。將所有方法一起使用的動作識別準確率為95.1%,與單獨的特征增強方法得到的識別準確率相差至少2.5%,說明本文使用的5種特征增強方法都或多或少發揮了其應有的作用,對于人體骨架動作的識別都有正向的作用,為后續網絡提取到多層次、多尺度的時間和空間特征打下了堅實基礎。
3.3 多分支輸入方法對比實驗分析
本文改善了三分支輸入的人體骨架特征,使得三分支的輸入變為Bone length+Joints、Bone length+Velocities和Bone length+Bone angle,增加了輸入特征的關節相關性。為了驗證每一分支對于動作類別判斷的有效性,分別將3種特征輸入網絡中進行實驗,在NTU RGB+D 60數據集的Cross-view(CV)評價標準上的識別準確率如表3所示。

表3 不同特征在NTU RGB-D 60數據集的準確率Tab.3 Accuracy of different feature on NTU RGB-D 60 dataset
由實驗結果可知,3種人體骨架結構特征都在網絡中取得了相接近的動作識別準確率。在3種 特 征Bone length+Joints、Bone length+Ve?locities和Bone length+Bone angle分 別 得 到 的 動作識別準確率中,特征Bone length+Joints的識別準確率最高,而特征Bone length+Velocities和特征Bone length+Bone angle緊隨其后,二者之間的識別準確率差別不大,僅在0.2%,說明3種特征均有一定的能力獨自作為網絡的輸入,可以從中提取到一定程度的信息用以動作分類。當三分支同時輸入3種特征時,其結果為95.1%,與3種特征分別輸入得到的結果相比,有了一定程度的提升,說明3種特征以三分支的形式輸入到網絡中對動作識別的準確率起到積極的促進作用。
3.4 多分支輸入方法對比實驗分析
本小節主要探討三分支特征在特征融合時的位置對動作類別判斷產生的影響。若特征融合時的位置在第k個多尺度卷積模塊的后方,則取k=1,2,3,4時網絡的識別準確率如表4所示。

表4 不同融合位置在NTU RGB-D 60數據集的準確率Tab.4 Accuracy of different feature fusion location on NTU RGB-D 60 dataset
3.5 多尺度時序卷積結構對比實驗分析
本小節主要探討多尺度時序卷積的卷積核大小對人體動作識別性能的影響。使用NTU RGB-D 60數據集的Cross-view(CV)劃分標準作為消融實驗的數據集,時序卷積的卷積核m=3,5,7,9時的動作識別準確率如表5所示。

表5 不同時序卷積核在NTU RGB-D 60數據集的準確率Tab.5 Accuracy of different temporal convolution kernel on NTU RGB-D 60 dataset
由消融實驗的結果可知,不同的k值取得了不同的動作識別準確率。當k值為3時,人體動作的識別準確率最高,所以本文中特征融合的階段選擇在第三個多尺度卷積模塊之后。在本實驗中,當k值過小時,多分支的特征融合后雖然具有很強的淺層次相關性,但在融合后經過神經網絡層數的不斷深入,提取到的深層次特征趨為一致,缺少了多樣化的深層次特征;而當k值過大時又缺少了早期特征之間的相關性。所以,要選擇合適的k值。
實驗結果表明,特征融合的位置會對動作識別的準確率產生影響,應該選擇能夠使準確率達到最大的位置。
多尺度時序卷積的卷積核是提取時間維度特征的核心。卷積核越大,特征信息的感受野也隨之變大,多尺度時序卷積能夠提取到的時間維度的跨度就越大,也就是說能夠提取距離更長的視頻幀間的特征信息,但同時也容易漏掉更多的細節信息,所以選擇合適的卷積核大小尤為重要。由實驗結果可知,當卷積核的大小m=5時,人體動作識別在RGB-D 60數據集Cross-view(CV)的準確率最高,為95.1%。當卷積核過小時,提取到的特征在時間維度的跨度不夠長,幀間特征無法高效地表達動作,同時網絡的參數量和計算量也相較較大;當卷積核過大時,容易漏掉更多的細節信息,幀間特征無法完整地表達動作。所以多尺度時序卷積的卷積核大小設為5×1。
3.6 對比實驗
使用NTU RGB-D 60數據集與NTU RGB-D 120數據集展示本文提出的網絡模型的結果,并與目前提出的其他基于人體骨架數據的動作識別算法進行對比與分析,在NTU RGB-D 60數據集上的人體動作識別準確率如表6所示。
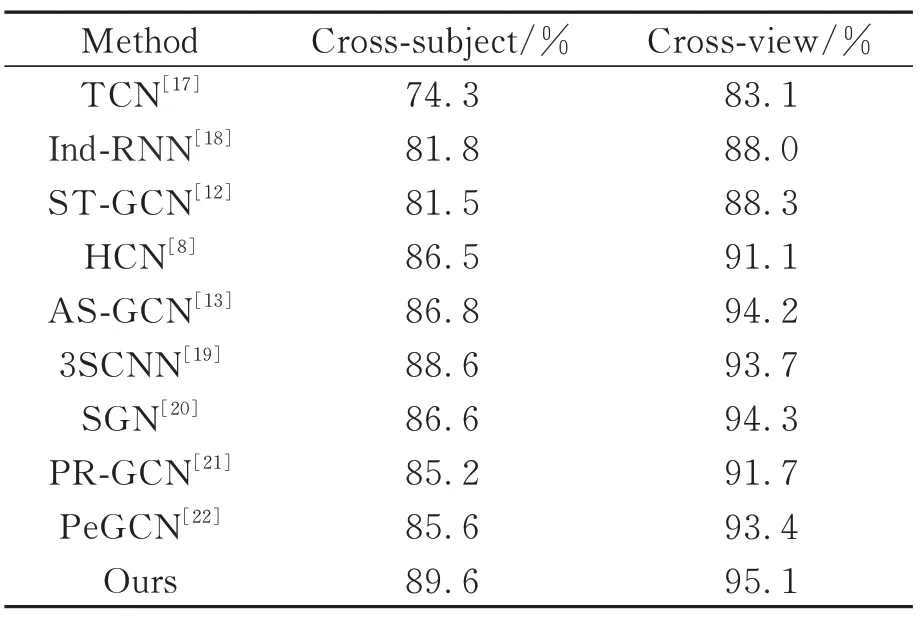
表6 不同動作識別方法在NTU RGB-D 60數據集的準確率Tab.6 Accuracy of different action recognition methods on NTU RGB-D 60 dataset
本文提出的網絡模型在NTU RGB-D 60數據集的Cross-subject劃分標準上獲得了89.6%的識別準確率,在Cross-view劃分標準上獲得了95.1%的準確率。與基于循環神經網絡的Ind-RNN網絡模型相比,在兩個指標上分別高出7.8%和7.1%;與基于卷積神經網絡的3SCNN網絡模型相比,在兩個指標上分別高出1.0%和1.4%;與同樣基于圖卷積神經網絡的SGN相比,在兩個指標上分別高出3.0%和0.8%。與其他基于人體骨架數據的動作識別算法相對比的結果說明了本文所使用網絡的優越性。
橫向對比基于NTU RGB-D 60數據集的Crosssubject和Cross-view劃分標準的識別準確率結果,可以發現所有識別準確率在Cross-view評價標準上的結果均要高于Cross-subject評價標準,兩者之差最大能夠達到8.8%,最小能夠達到4.6%。
為了對實驗結果進行更深入的分析,得到圖10所示的Cross-subject和Cross-view劃分標準下的混淆矩陣圖,圖中橫坐標為具體動作類別的編號,縱坐標為具體動作類別的準確率。由圖10可知,模型在Cross-subject中可準確識別絕大部分的動作類別。其中類別11(Reading)、12(Writing)、29(Play with phone/Tablet)、30(Type on a keyboard)、34(Rub two hands)、41(Sneeze/Cough)、44(Head?ache)的準確率明顯低于其他類別。這些動作類別聚焦于局部肢體動作,動作幅度不大,動作之間的區別也不明顯。模型無法確切區分這些動作類別,這是影響本文模型準確率的主要因素之一。
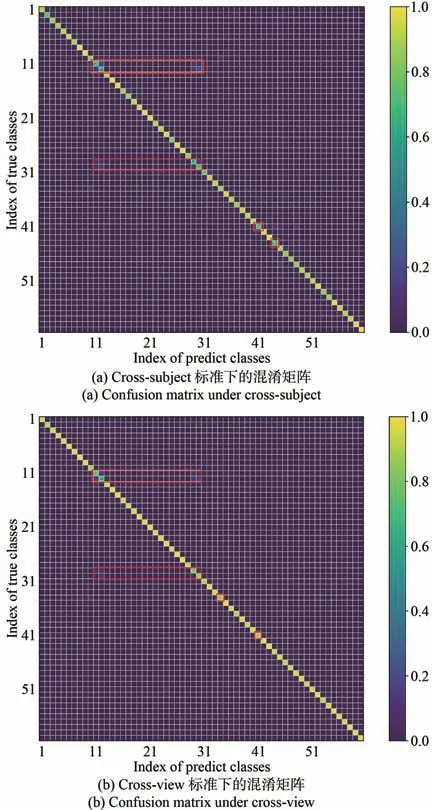
圖10 NTU RGB-D 60數據集下的混淆矩陣Fig.10 Confusion matrix under NTU RGB-D 60 dataset
除了NTU RGB-D 60數據集之外,本文也在其擴展版本NTU RGB-D 120數據集上進行了實驗與分析,如表7所示。該數據集相比于NTU RGB-D 60數據集,其動作類別數更多且人物、場景情況更復雜,因此基本上所有主流方法在該數據集上的識別準確率均出現了明顯的下降。在NTU RGB-D 120數據集中,本文提出的網絡模型在Cross-subject劃分標準上的識別結果為84.1%,在Cross-setup劃分標準上的識別結果為86.0%,均保持在一個較好的水平,相比于其他方法呈現出了更為明顯的優勢,證明了本文提出的網絡模型在性能上的優越性。
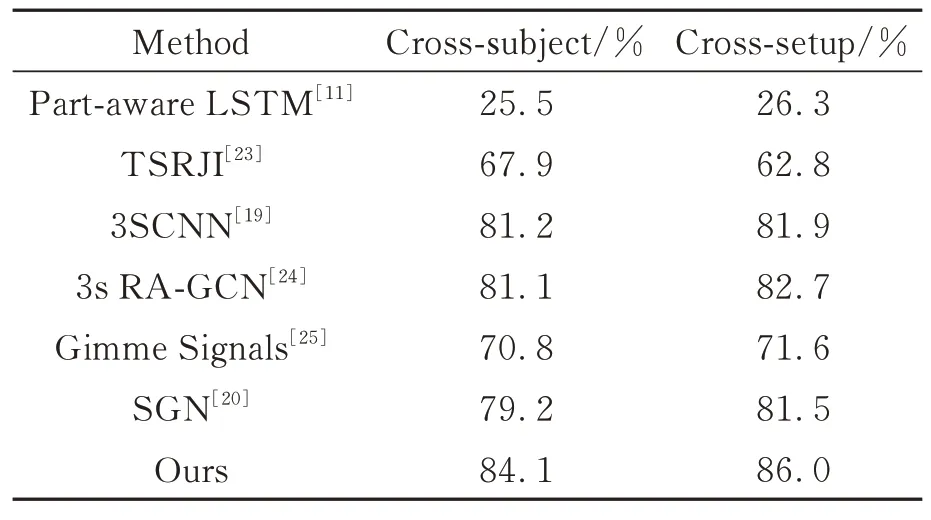
表7 不同動作識別方法在NTU RGB-D 120數據集的準確率Tab.7 Accuracy of different action recognition methods on NTU RGB-D 120 dataset
4 結 論
如今基于視頻的人體動作識別需求層出不窮。基于人體骨架數據的動作識別相比于RGB視頻具有數據量小、無環境干擾等優點,從而成為了研究重點。本文從多特征、多分支以及多特征之間的關聯為主線出發,首先基于輸入的骨架數據,利用多種特征增強方法并通過改進的多分支融合特征輸入到本文的神經網絡中,然后使用多尺度時空卷積模塊提取多尺度特征信息。在NTU RGB-D 60數據集的兩種劃分標準Cross-subject和Cross-view上的識別準確率分別為89.6%和95.1%,在NTU RGB-D 120數據集的兩種劃分標準Cross-subject和Cross-setup上的識別準確率分別為84.1%和86.0%,較好地提升了模型的動作識別準確率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
