AeDNA: 水生生物eDNA數據庫
2022-11-25 05:58:38方成池吳志剛崔永德王寶強姜傳奇宋立榮王洪鑄劉煥章陳曉飛凌海波蔡俊雄何舜平曾宏輝
水生生物學報 2022年11期
陳 凱 方成池 吳志剛 熊 凡 俞 丹 崔永德 張 琪 王寶強 姜傳奇 宋立榮 王洪鑄 劉煥章 陳曉飛 凌海波 蔡俊雄 李 濤 何舜平 繆 煒 熊 杰 曾宏輝
(1. 中國科學院水生生物研究所, 武漢 430072; 2. 湖北省生態環境科學研究院, 武漢 430072)
人類活動和氣候變化造成了水生態系統受損、水生生物多樣性衰退、物種組成改變等負面影響[1—5]。開展全面、準確的水生生物多樣性調查是建立水生態評估方法并開展生物多樣性保護的基礎[6]。重要的水生生物包括魚類、水生植物、底棲動物、浮游動物和浮游植物等[7—9]。當前, 水生生物調查主要是通過形態鑒定這一手段。然而, 這一方法存在諸多缺陷, 包括成本高、耗時、對從業人員專業水平要求高及方法難以標準化等[10]。環境DNA(eDNA)技術的產生則彌補了上述形態鑒定方法的不足, 是一種生態和生物多樣性監測的新手段, 也是當前的前沿熱點技術[6,11—15]。eDNA技術通過采集水樣, 富集并提取DNA, 進行建庫和高通量測序, 最后通過將測序序列與數據庫序列比對獲得物種注釋信息[15]。盡管eDNA技術在過去10來年中被廣泛應用, 但是用于物種鑒定的數據庫各式各樣, 并存在分類標準不統一、分類錯誤和覆蓋度不高等問題[16], 這些問題直接影響了應用eDNA技術調查水生生物多樣性的準確性, 從而制約了eDNA技術的推廣, 因此亟待建立準確的、綜合性的水生生物eDNA數據庫。
針對eDNA參考序列數據分散和整合度差, 且缺乏我國各類水環境水生生物eDNA參考序列庫的問題, 我們通過梳理公共數據庫中eDNA數據庫的序列信息、Meta信息和分類信息, 同時整合自有的大量水生生物eDNA參考序列, 設計了eDNA數據的收錄標準和存儲格式, 矯正了部分數據的分類錯誤,進而構建了水生生物eDNA數據庫——AeDNA(http://aedna.ihb.ac.cn/)。AeDNA是中國首個綜合性的水生生物eDNA數據庫, 將大大促進eDNA技術在水生生物調查領域的應用。
1 材料與方法
1.1 數據收集
數據來源包括公共數據庫和AeDNA團隊貢獻的序列。公共數據庫包括NCBI(https://www.ncbi.nlm.nih.gov/)、BOLD(http://www.boldsystems.org/)、SILVA(https://www.arb-silva.de/)和MitoFish(http://mitofish.aori.u-tokyo.ac.jp/download.html)。Ae-DNA團隊貢獻的序列主要有各團隊自行鑒定和測序的各類水生生物條形碼序列數據。
1.2 數據處理
數據處理包括分類信息矯正和數據格式標準化。AeDNA數據庫的分類信息以NCBI taxonomy為基礎, 并輔以人工矯正。首先通過NCBI taxid構建NCBI全部生物類群分類學數據庫, 分類系統以標準的界、門、綱、目、科、屬、種共7個分類層級進行展示, 然后將收錄序列的物種名稱與物種庫進行匹配, 繼而得到序列的標準分類信息。最后將計算得到的標準分類信息進行人工校正。數據格式標準化包括制定標準Meta信息收集表, Meta信息(Meta-information)是指與序列相關的基礎信息, 包括序列名稱、分類信息、序列類型、采樣位置(經緯度)、樣品采集地生境、數據來源信息和描述信息。標準化格式制定后采用自行編寫的腳本進行統一匯編, 并且統一自動化重命名。
1.3 數據庫構建
本數據庫基于CentOS 8系統, React與TypeScript用于網頁前端頁面展示, Django用于網頁后端功能模塊開發, Python用于文本操作和邏輯運行, MongoDB用于數據管理。
2 結果與討論
2.1 數據庫結構和功能呈現
AeDNA主體結構包括6部分: 主頁、DNA條形碼、基因組、分析平臺、數據提交和關于我們(圖1)。數據資源包括收錄的序列、分類學數據、序列相關的Meta信息及將序列構建成用于同源分析的索引。數據存儲包括MongoDB和BLAST database, 其中MongoDB用于網頁數據原始數據展現和Meta信息存儲; BLAST database用于存儲同源分析的索引序列。分析工具包括數據展示、數據提交和分析平臺。主要功能包括搜索功能、數據統計功能、分析功能和數據更新功能。
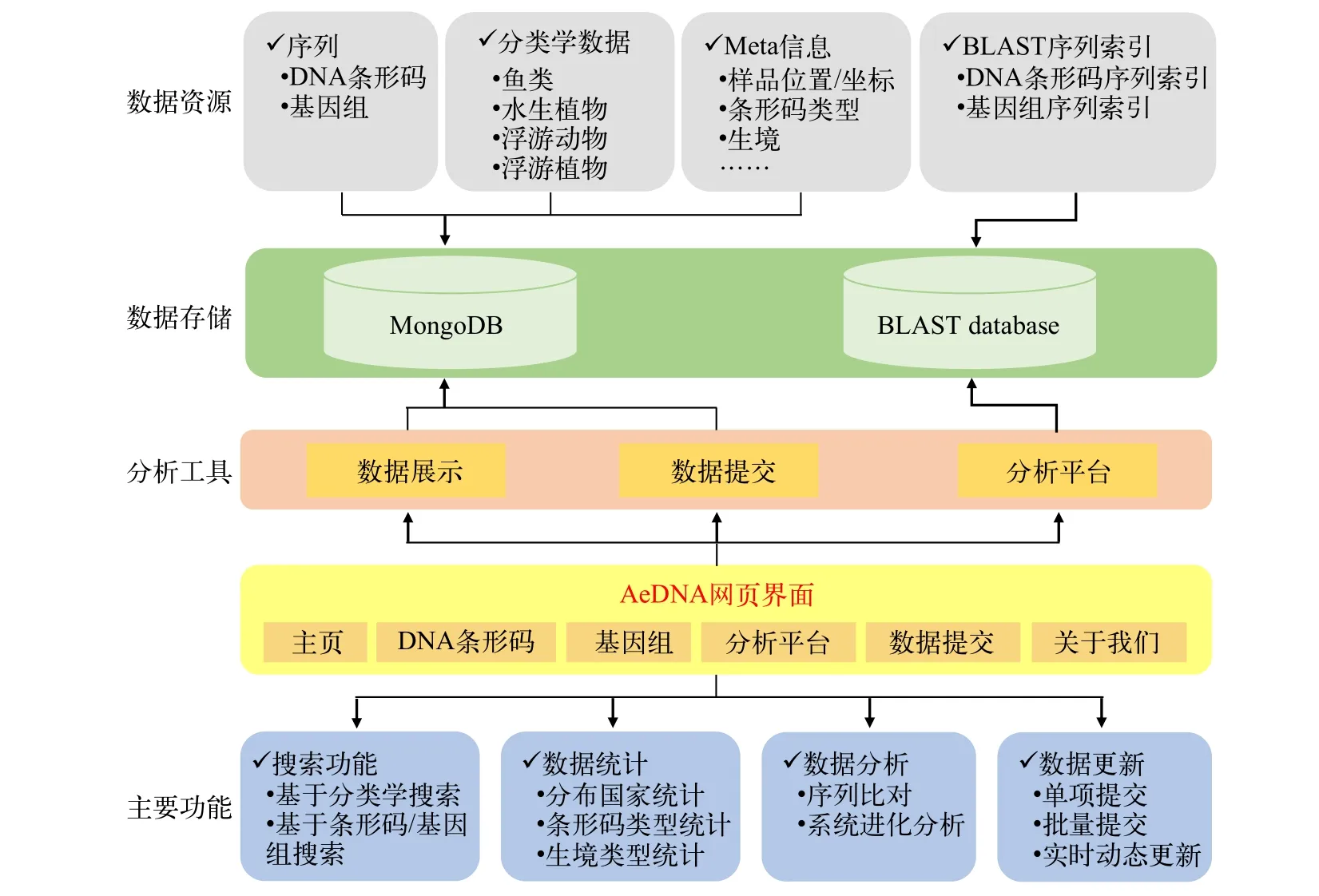
圖1 AeDNA數據庫網站構架示意圖Fig. 1 Web interface and framework of AeDNA database
搜索功能用戶可以通過分類信息在AeDNA數據庫搜索數據, 也可以結合通過分類信息、序列名稱、樣品采集地(國家/地區)和生境進行搜索。通過搜索用戶可以獲得目標序列及與目標序列有關的分類學信息和Meta統計信息。
數據統計功能包括序列統計和Meta信息統計。序列統計呈現了各分類階元的條形碼或基因組數量; Meta信息統計呈現了各分類階元條形碼序列類型和與其相關的樣品分布數據, 如分布國家統計, 地理坐標呈現。
分析功能數據庫支持用戶提交序列并通過BLAST程序搜索目標序列在AeDNA數據庫中的同源序列, 進一步基于搜索到的同源序列構建系統發育分析(圖1)。BLAST默認程序為BLASTN, 默認比對序列為DNA條形碼數據庫的所有類群、所有序列, 默認比對E值為0.1。用戶可以自行選擇比對程序、比對序列類型、比對E值和其他參數。系統發育分析中多序列比對工具為Muscle v5, 系統樹算法為TreeBeST, 可視化工具為MSAView。
數據更新功能數據庫提交分為單項提交和批量提交兩種不同的模式(圖1)。單項提交允許用戶將eDNA數據逐條提交到AeDNA, 批量提交允許用戶通過填寫標準信息收集表格提交序列。提交的序列需要經過AeDNA后臺審核, 審核通過的序列匯入AeDNA數據庫并反饋給用戶, 審核不通過的序列提示用戶再次按照要求提交。
2.2 數據類型
AeDNA包含水生生物DNA條形碼和基因組數據, 通過整合公共數據和AeDNA構建團隊測定的條形碼數據構建而成。數據庫集成了60余萬條序列, 其中數據庫構建團隊貢獻了6萬余條, 以我國各類水體水生生物條形碼數據為特色。數據庫涉及的生物類型包括2萬余種魚類、1萬余種水生植物、1萬余種底棲動物、1萬余種浮游動物和1萬余種浮游植物(圖2)。

圖2 AeDNA數據總覽Fig. 2 Landscape of the data of AeDNA
DNA條形碼DNA條形碼是物種特有、能穩定遺傳、可以作為身份標簽的一段DNA序列。每個物種具有多種條形碼序列, 本數據庫收錄多個物種多種條形碼序列, 包括18S、ITS、COI、12S、rbcL等38種條形碼數據。數據由AeDNA團隊通過檢索公用數據庫、單一物種條形碼測序、eDNA多物種批量測序和挖掘基因組獲得的條形碼序列組成。DNA條形碼數據將為水生生物鑒定、多樣性調查、保護種/入侵種監測及研究提供參考。
數據庫包含23418種魚類、11750種水生植物、8817種底棲動物、10320種浮游動物和8953種浮游植物(圖3A)。總計592758條DNA條形碼序列,其中魚類376201條、水生植物103227條、底棲動物11214條、浮游動物67689條、浮游植物34427條(圖3B)。不同生物類群收錄的條形碼序列有較大差異, 其中魚類以線粒體基因為主, 例如COI、12S等, 還有少量核糖體基因序列和基因組上其他基因序列(圖3C); 水生植物包含葉綠體和ITS序列(核糖體基因); (圖3D); 浮游動物包含以COI為代表的線粒體序列和以18S為代表的核糖體序列(圖3E);除藍藻以外的浮游植物則包含rbcL為代表的葉綠體序列、COI為代表的線粒體序列和18S為代表的核糖體序列(圖3F)。我們發現高等動植物DNA條形碼多采用進化速率更快的線粒體基因、葉綠體基因和ITS序列, 而浮游動植物除了上述基因外, 還采用更為保守的18S序列(真核藻類)或者16S序列(藍藻), 這與已有研究結果一致[17—19]。另外, 最新的研究表明以線粒體12S序列作為魚類鑒定的參考條形碼序列相較于COI等條形碼序列能鑒定更多的物種, 鑒定的結果更準確[19]。本數據庫收錄的12S序列5000余條, 后期還將持續進行增量更新。
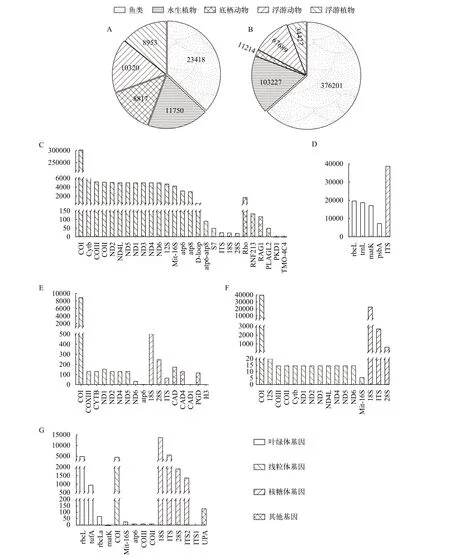
圖3 DNA條形碼數據統計Fig. 3 Statistics of DNA barcodesA. 數據庫已收錄DNA條形碼的物種數量統計; B. DNA條形碼數量統計; C—F. 不同水生生物類群DNA條形碼類型統計[C、D、E、F和G分別代表魚類、水生植物、底棲動物、浮游動物和真核浮游植物(僅含真核藻類)]A. The number of species with DNA barcode in the database; B. Statistics of the number of DNA barcodes; C—F. Statistics of the types of DNA barcodes [C, D, E and F represent the DNA barcodes of the fish, plant, Zoobenthos, zooplankton and phytoplankton (only eukaryotic Algae, respectively)]
AeDNA構建團隊貢獻了該數據庫中的6萬余條DNA條形碼序列, 其中魚類序列5.7萬余條, 水生植物序列500余條, 底棲動物200余條, 浮游動物和浮游植物序列1200余條; AeDNA團隊貢獻的條形碼數據具有完備的Meta信息, 除了條形碼類型信息外還包括樣品采集地點、生境類型、圖片、視頻等。從序列所在生境的分布圖可以看出這些序列主要來源于我國各類水體中水生生物, 具有鮮明的特色。樣品采集地除中國臺灣外的其他所有省份均有覆蓋(圖4), 以長江流域和青藏高原為特色。內蒙古自治區、中國臺灣和新疆維吾爾自治區等沒有分布或分布較少, 未來需要加大采樣力度, 使之覆蓋更廣、更全。
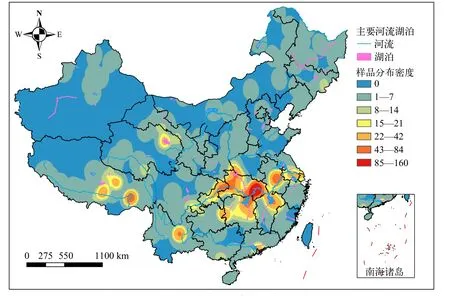
圖4 AeDNA團隊貢獻的DNA條形碼序列地域分布圖Fig. 4 The distribution of DNA barcode sequences contributed by AeDNA team根據中華人民共和國自然資源部監管的標準地圖編輯[審圖號為GS (2016) 1569]Edited based on a standard map supervised by the Ministry of Natural Resources of the People’s Republic of China [No. GS (2016) 1569]
基因組條形碼如上文所述, 每個物種具有多種條形碼序列, 不同類型的條形碼序列長度不同,序列保守性不同, 鑒定精度和解析度不一致, 因此,研究人員針對各類群物種鑒定所用的條形碼不一致。例如, 過去COI序列是魚類鑒定的金標準, 最近發現12S序列比COI鑒定精度高[19]; 用于大部分真核藻類鑒定的條形碼是18S、ITS、28S、tufA和rbcL等, 但甲藻和異鞭藻用COI, 輪藻則采用與很多高等植物類似的atpA/B、psbA/B等[18]; 藍藻(原核浮游植物)通常采用16S、ITS、rbcL和rpoC1等。原生動物的鑒定通常用18S和COI[17]。因此, 采用DNA條形碼進行物種鑒定缺乏統一標準。
基因組是指某一特定物種細胞內的一整套遺傳物質, 是一個物種所有DNA序列信息的集合。基因組某種意義上說是一種 “超級條形碼”, 其鑒定精度和解析度將遠遠超過單獨使用某一個標記基因。當前, 大量細胞器基因組和物種基因組的產生,使得基因組的數目到達了一定的量級, 因此, 利用基因組進行物種鑒定也變為可行。
本數據庫的基因組數據包含線粒體基因組、葉綠體基因組以及由“萬種魚基因組計劃”[20]和“萬種原生生物基因組計劃”[21]產出的全基因組測序數據。數據庫共搜集了5872條細胞器基因組序列, 其中線粒體基因組共3377條, 魚類3118條, 水生植物18條, 浮游動物49條, 浮游植物192條; 葉綠體基因組共2495條, 水生植物1568條, 浮游植物927條(圖5)。后期數據庫將大力整合基因組數據, 尤其是旗艦物種和入侵物種基因組數據, 同時結合基因組測序和通過大規模水環境樣品采集、測序, 從宏基因組數據挖掘環境基因組來補充未測定基因組的空白。此外, AeDNA進一步將開發基于基因組水平進行物種鑒定和生物多樣性研究的新方法、新標準。
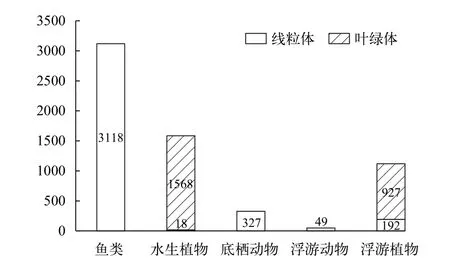
圖5 AeDNA數據庫中基因組數據的統計Fig. 5 Statistics of genomes in AeDNA database
3 展望
AeDNA為水生生物調查提供參考序列數據庫,整合了現有DNA條形碼和基因組數據, 將促進eDNA技術在水生生物調查中的應用。當前, 數據庫為第一版, 未來將進行持續的數據更新, 同時整合更多分析功能, 包括: (1)數據庫將新增兩棲動物、藍藻等類群水生生物eDNA數據, 將繼續收集、匯編國內同行測定的水生生物條形碼數據和通過大規模采集樣品、測序來完善中國境內條形碼數據庫, 構建更具綜合性的水生生物eDNA數據庫。樣品來源將涉及中國大部分水域, 將實現對國內水生生物eDNA數據的全覆蓋。數據庫將收集水生生物圖片、視頻信息, 將展現序列、分類信息、影像和Meta信息等數據。(2)除了實現對數據增量更新的同時, 本數據庫將著力于eDNA數據質量的提升。包括: 基于NCBI分類學體系的分類系統矯正; 基于聚類分析去除冗余序列和錯誤序列; 基于HMM模型對序列進行修剪等。(3)數據庫已建設有序列比對和系統發育樹構建功能, 后續將新增: 多樣性分析功能, 如α和β多樣性等; 入侵種和保護種監測功能; 各類水生態指標分析功能和基于eDNA的水生生物評價功能。(4)數據庫將建立用戶管理系統, 即用戶可以在AeDNA數據庫創建賬號, 實現對個人數據和分析任務的長期管理。總體來說,AeDNA將由專業團隊進行長期維護, 持續迭代, 旨在實現水生生物的調查、監測、追溯和預警的綜合能力。
致謝:
AeDNA網站首頁視頻由中國科學院水生生物研究所熊雄博士和王浩驊提供素材并進行剪輯。網頁中各類水生生物照片由中國科學院水生生物研究所谷思雨、繆榮麗、魏朝軍、王府臣、高欣欣、潘婷婷、王慧君、邴厚驊和王紅霞提供。中國科學院水生生物研究所陳佳在網站網絡安全管理和維護方面提供了幫助。網站構建得到了中國科學院超級計算環境武漢分中心的支持。
猜你喜歡
英語世界(2023年10期)2023-11-17 09:18:18
天天愛科學(2022年9期)2022-09-15 01:12:54
天天愛科學(2022年4期)2022-05-23 12:41:48
當代水產(2022年3期)2022-04-26 14:26:56
航空世界(2020年10期)2020-01-19 14:36:20
科學大眾(中學)(2019年3期)2019-05-17 10:04:30
汽車觀察(2018年10期)2018-11-06 07:05:26
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
