基于視點差異和多分類器的三維模型分類
2022-11-29 11:00:16范宇飛何勇軍
電子與信息學報 2022年11期
丁 博 范宇飛 高 源 何勇軍
(哈爾濱理工大學計算機科學與技術學院 哈爾濱 150080)
1 引言
近年來,隨著3維成像傳感器和3維重建技術的發展,人們可以從生活中便捷地捕獲大量的3維物體結構信息。同時,計算機網絡的發展進一步促進了3維模型呈指數型增長,其多樣性與復雜度更是顯著提高。越來越多的3維模型數據集可供研究者分析,也為數字幾何處理帶來全新的挑戰[1]。目前,3維模型分類作為3維數據分析的基礎,已經成為計算機視覺領域的一個重要研究方向。
3維模型的多視圖表示結合深度學習成為該研究方向的一個熱點。卷積神經網絡通過一系列的卷積池化操作可以很好地表達圖像特征信息,因此被廣泛用于基于視圖的3維模型特征學習中[2]。基于多視圖的3維模型分類方法可以分為兩大類:基于多視角特征結合特征級融合和基于獨立視角特征結合決策級融合。特征級融合是將各視角下的視圖通過特征編碼融合為一個特征,通常又稱特征描述符。決策級融合重點在于將每個獨立視角表示成對應的視角特征。利用視角間空間位置關系提升特征描述能力,進而進行分類[3]。
在特征級融合方面,Su等人[4]提出了多視角卷積神經網絡(Multi-View Convolutional Neural Networks, MVCNN),可使用View-Pooling層對一個對象的多個渲染視圖表示為形狀描述符。然而View-Pooling層只保留特定視圖中的最大元素,忽略了連續視圖序列中包含的上下文信息。為此,Liu等人[5]提出了語義和上下文信息融合網絡(Semantic and Context Information Fusion Network, SCFN),對每個視圖的特征提取都加入了軟注意力機制,且采用3D CNN融合多視圖的上下文信息,增強了網絡對輸入變化的敏感性。多重判別和成對卷積神經網絡(Multiple Discrimination and Pairwise CNN,MDPCNN)將Slice層和Concat層加入到網絡中,可以同時輸入多批次和多個視圖,采用對比損失與對比中心損失優化網絡,加快了網絡的收斂速度[6]。FusionNet方法結合體素和多視圖表示3維模型,然后用CNN提取模型特征后分類[7]。Liu等人[8]提出的多視角注意卷積神經網絡(Multi-View Attentional Convolutional Neural Network, MVACNN)引入軟注意力機制來調整形狀描述符,同時利用長短期記憶網絡(Long Short-Term Memory, LSTM)發掘多視角上下文的對象特征,實驗展示出了較好的結果。Liang等人[9]提出了多視角卷積LSTM網絡(Multi-View Convolutional LSTM Network, MVCLN),同時利用時間和空間信息進行3維模型分類,該方法在多個數據集中展示出了良好的分類效果。
在決策級融合方面,VS-MVCNN首先采用CNN提取不同視角下的視圖特征,然后利用支持向量機對目標進行分類,其準確率可以達到90%以上[10]。CNN-VOTE采用深度學習模型CaffeNet作為弱分類器分類2維視圖,然后利用加權投票方式作為強分類器完成3維模型分類[11]。Kanezaki等人[12]以多視圖為輸入,構建了一個基于CNN的RotationNet分類器,聯合3維模型的位姿信息對3維模型進行分類。同時,該方法將視點標簽視為潛在變量,這些變量在使用未對齊的數據集進行訓練時以非監督的方式學習。該方法在ModelNet10和ModelNet40數據集上取得了較好的分類效果。
除此之外在3維模型的描述和表示方面,有些學者采用全景視圖表征3維模型,進而實現3維模型分類。DeepPano方法將3維模型圍繞其主軸的圓柱進行投影,得到全景視圖,然后通過改進的CNN,直接學習深度表示[13]。Geometry image方法首先將3維模型投影到球面上,然后進行切割,獲得平坦且規則的幾何圖像[14]。采用全景視圖進行3維模型分類的方法還有PANORAMA-NN[15],但全景圖大小相當于多視圖,計算復雜度很高。
目前基于多視圖的3維模型分類方法中,主流的3維模型表示方法仍是從不同的角度對3維模型進行投影,獲得一組2維視圖表示3維模型,以此通過圍繞3維模型的多個視圖表示其全局特征[16]。但是這種方法在模型分類的時候要產生大量視圖,通過對視圖的分類達到對模型分類的目的。雖然取得了較高的準確率,但是還存在兩個問題。首先,在訓練分類器時,將同類3維模型的所有視圖看作同一類,這降低了分類器的區分性。3維模型不同視點上的視圖存在巨大差異,籠統地放在一起作為一個類別的訓練數據,無法訓練出一個好的分類器。其次,在分類階段,對每個3維模型的分類要做大量的視圖分類,這降低了3維模型分類效率。如圖1所示,在綠色虛線框中,同一類別的3維模型Desk1,Desk2和Vase1, Vase2,在不同視點下,投影得到的視圖差異大。在相同的視點下,投影得到的視圖基本沒有差異。有的不同類別的3維模型,在某個視點組下,極具相似性。如在紅色實線框中,Desk2與Dresser在上視點組下的投影視圖都近似矩形,Vase2與Bottle在上視點組下的投影視圖都近似圓環。因此,在該視點組下很難區分他們的類別。而Desk2與Dresser, Vase2與Bottle在前視點組下的視圖存在很大區分性。由此可以看出,當僅用1張視圖有時難以有效判斷3維模型的類別。針對以上兩個問題:(1)本文通過將3維模型限定在正多面體中,根據劃分的多個視點組訓練對應分類器,以此充分利用視點差異下的視圖信息對3維模型分類;(2)通過本文的視圖選擇方法,在差異甚遠的視點下選擇少量視圖用于分類,旨在提高3維模型的分類準確率和效率。
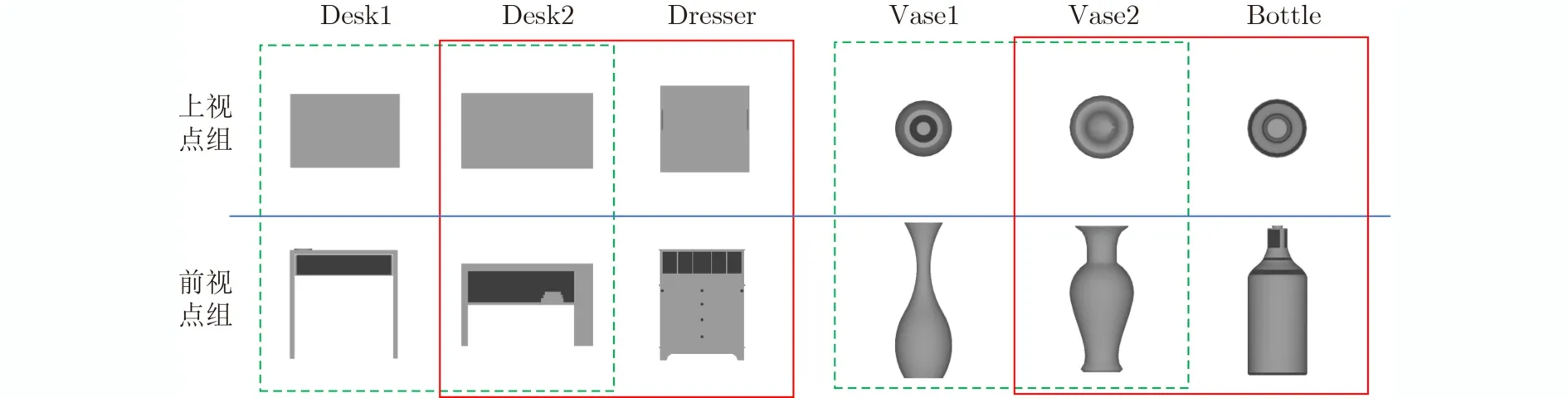
圖1 不同視點組下的視圖
本文方法建立在決策級融合的層面上,本文的3維模型分類網絡分為特征提取網絡和分類網絡兩部分。特征提取網絡采用卷積神經網絡(Convolutional Neural Network, CNN),并加入輕量級的卷積塊注意力模塊(Convolutional Block Attention Module, CBAM)來挖掘視圖區分性特征[17]。分類網絡中的每個視點組對應一個分類器,所有分類器共享卷積層參數。在分類時,每個視圖分類器輸出一個分類結果,然后采用本文提出的分類策略得出最終的分類結果。
2 本文方法
2.1 總體框架
如圖2所示,本文提出的3維模型分類方法步驟如下:(1)3維模型的多視圖表示;(2)視圖分類器的訓練;(3)3維模型分類。3維模型的多視圖表示的重點在于投影視點的位置和數量的確定。本文首先通過設置主視點和附屬視點,形成多個視點組。3維模型在每個視點組下產生多張投影視圖。在分類器的訓練中,共享的特征提取網絡上增加注意力機制,目的在于抑制無用特征,挖掘視圖區分性特征。每個分類器與一個視點組相對應,采用所有3維模型在該視點組下的視圖和附加類中的視圖進行訓練。當進行3維模型分類時,首先采用本文提出的視圖選擇方法選取視圖,然后將視圖依次輸入分類器中,每個分類器均輸出一個結果。最后采用本文提出的分類策略,以獲得最終的分類結果。
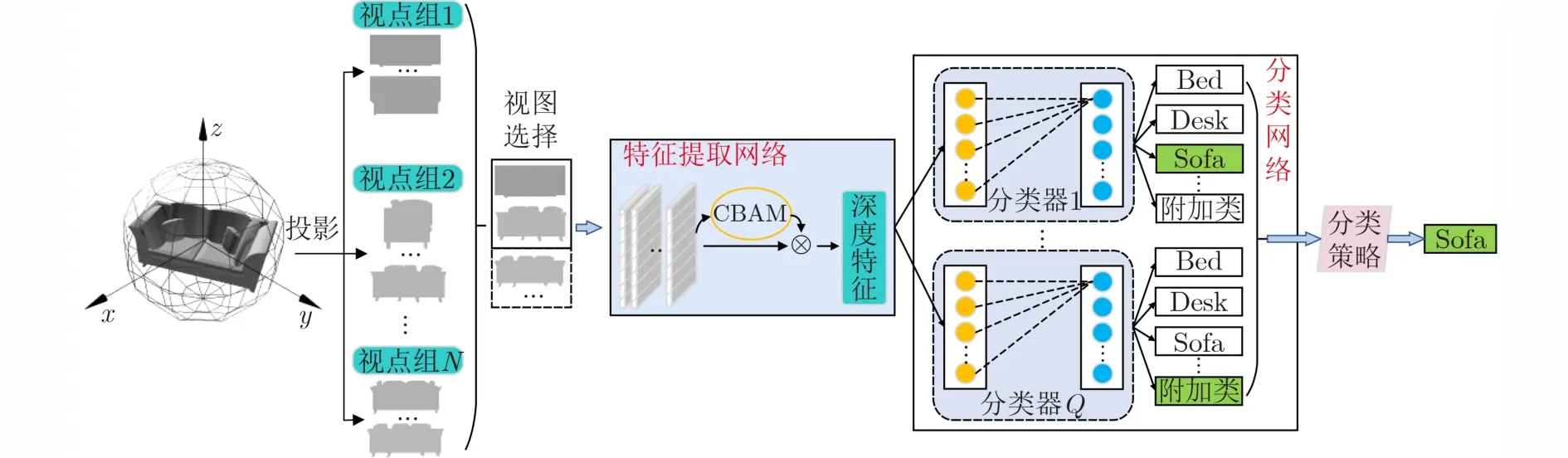
圖2 分類過程
2.2 3維模型的多視圖表示
3維模型的投影視圖受多種因素影響。其中主要因素包括視點的選取和渲染方式的選擇。不同視點下得到的3維模型的視圖不盡相同,而同樣的視點下不同的渲染方式得到的視圖所攜帶的信息量也不同,本文采用了基于馮氏光照[18]的多光源渲染方式。2維視圖的數量與設置視點的數量相同,同時3維模型的姿態與設置視點的位置相對應。
本文選擇設置N個視點組,每個視點組設置M個視點,即一個視點組包含1個主視點與(M–1)個輔助視點。以正方體包裹模型為例,為兼顧從多方位投影視圖,在每個視點組中設置1個主視點和8個輔助視點。主視點分別位于單位正方體的上、下、左、右、前、后6個面的中心。為了增加數據的多樣性,增強CNN的魯棒性,在每個主視點的上、下、左、右、左上、右上、左下、右下設置8個輔助視點,共計M×N(54)個視點。視點組設置如圖3所示。
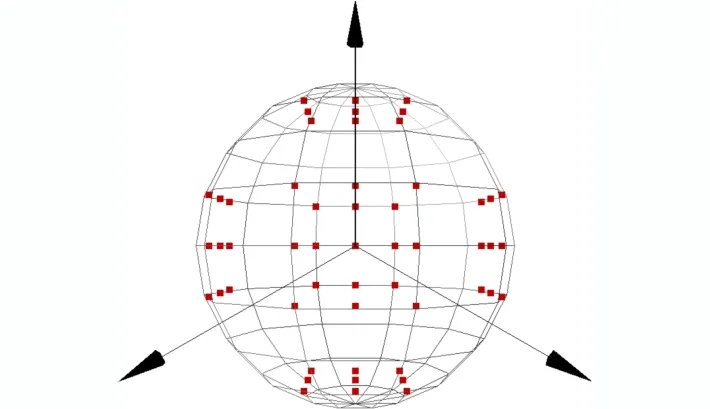
圖3 視點組設置
為了增加每個視點組下視圖的區分性,同時盡可能減小相鄰視點組之間的相似性,本文將輔助視點、3維模型中心與主視點夾角正切值設為tanθ=0.75 ,其中θ的值約為36.87°,俯視圖如圖4所示。本文設置的視點可以全方位表地示3維模型,并且不同視點組下產生的2維視圖差異性大,易于利用3維模型不同視點下的信息對模型進行分類。
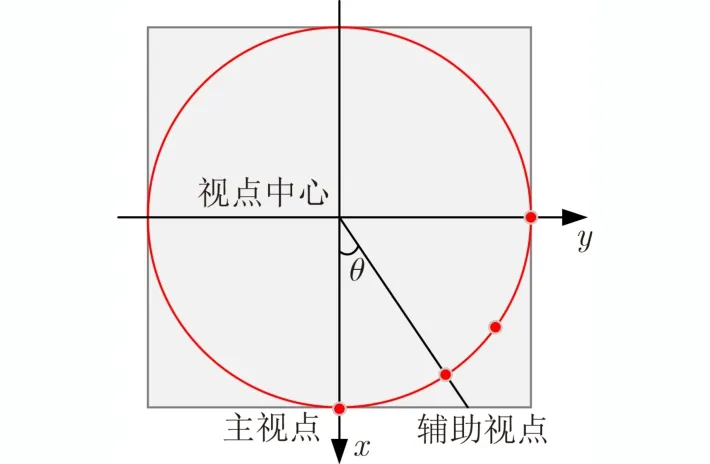
圖4 視點設置俯視圖
2.3 視圖分類器
目前的3維模型分類方法沒有考慮不同視點下的模型差異巨大,這降低了分類器的性能。不同視點下的3維模型和模型類別是緊密耦合的。給定3維模型的一張視圖,通過多分類器可以很容易推斷出該視圖屬于哪一個視點下的視圖,從而推斷出這個模型的類別。
2.3.1 CBAM
如何合理有效地利用投影視圖的信息是特征提取的關鍵。本文采用ResNet50提取視圖的深度特征。為了能讓卷積神經網絡模仿人類觀察物體時,把焦點目光聚集在物體重要的部分上,本文引入了注意力機制。CBAM是在ECCV2018中提出的用于前饋卷積神經網絡的注意力模塊[17]。
一個視圖經過卷積操作后的輸出特征為F,F ∈RC×H×W,CBAM沿通道和空間兩個維度依次生成一個1維通道注意圖(Mc∈RC×1×1)和2維空間注意圖(Ms∈R1×H×W)。再與原特征相乘進行自適應。特征提取表示為
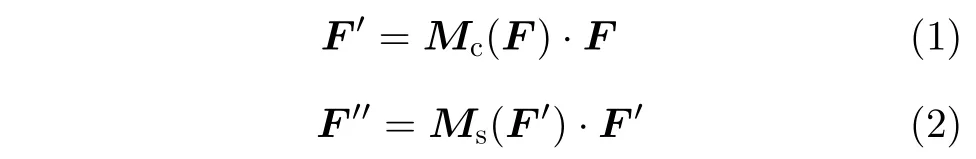
其中,·表示相乘,F′是通過通道注意力后的輸出特征,F′′是通過空間注意力后的輸出特征。通道注意力機制可以表示為
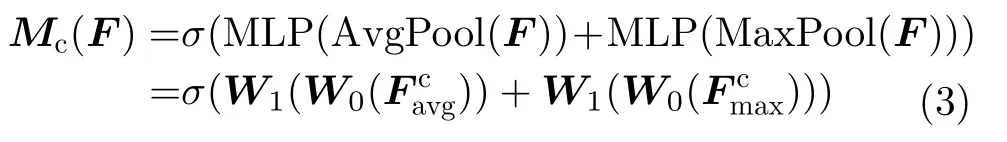
其中,MLP為多層感知器,AvgPool和MaxPool分別表示平均池化和最大池化。平均池化和最大池化后的和共享MLP,σ為Sigmoid激活函數,W0和W1是要學習的參數。空間注意力機制可以表示為
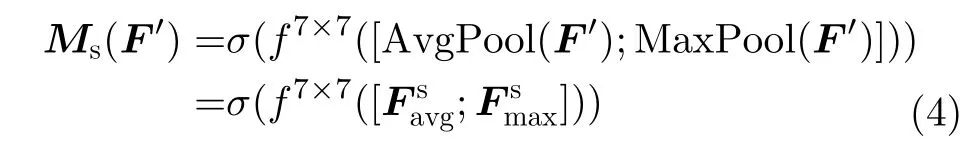
其中,f表示卷積操作,采用7×7卷積核。
本文在ResNet50最后一層卷積與全連接層之間加入CBAM,目的在于增強有用特征,抑制無用特征,從而提取到具有代表性和區分性的視圖特征。特征提取網絡如圖5所示。
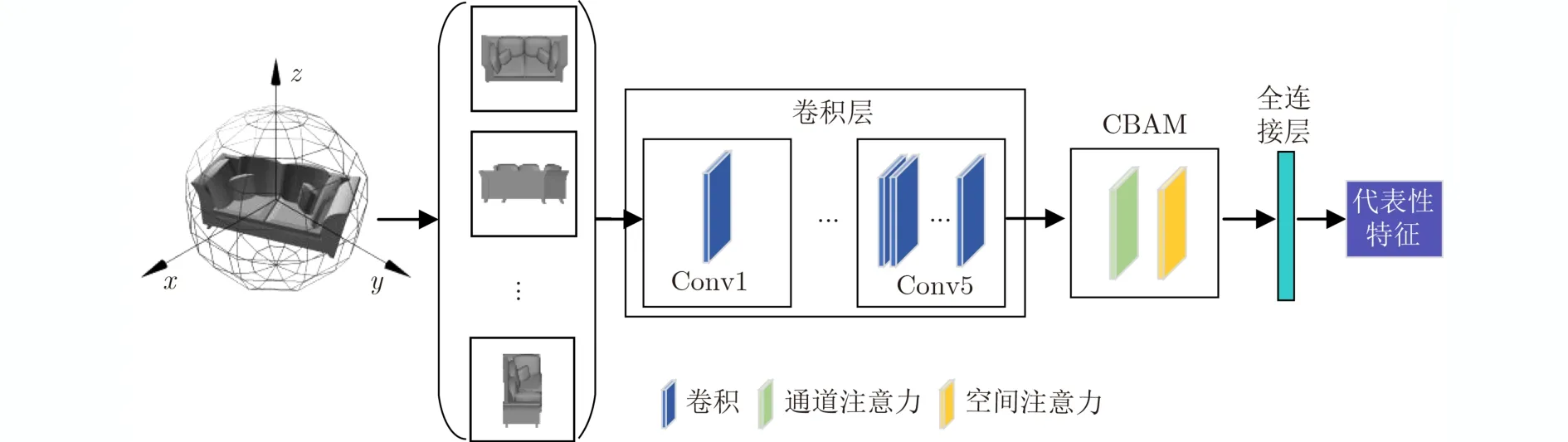
圖5 加入CBAM的特征提取網絡
2.3.2 附加類
傳統方法在分類視圖時認為每個3維模型所有視點上的視圖屬于同一類。事實上,同一模型在不同視點上的視圖差異很大,將其放在一個類別中,將使得分類器很難學習到一個合理的分類面。本文認為3維模型的一個視點組下的視圖屬于一個類別,這個模型其他視點組下的視圖都不屬于這個類,但也不屬于這個分類器上其他的類別。因此我們為這些數據構建一個新的類別,即附加類。這樣可以有效提高分類器的區分性。
本文設置了N個視點組,每個視點組下有M個視點,每個視點對應1張投影視圖。附加類的數據需要覆蓋所有3維模型在非本視點組下的投影視圖。因此附加類視圖取自所有模型在剩余N–1個視點組下的視圖。由于選擇剩余N–1個視點組下的所有視圖,數據量大,本文采用抽樣選擇的方式。同時,由于對稱視點組中的視圖存在一定的相似。因此,本文在含有對稱視點組抽樣選取附加類視圖時,只考慮非對稱視點組,即只在剩下的N–2個視點組中抽取。
2.3.3 視圖分類器的設置
本文共有Q個視圖分類器和N個視點組(Q=N),二者一一對應。Q個視圖分類器共享卷積層,但卻有各自的注意力層、全連接層和Softmax層。把卷積層與注意力層看作特征提取層,把全連接層和Softmax層看作不同視點組下的分類器,每個分類器輸出一個分類結果。這樣做的目的是不同視點組下產生的3維模型的2維視圖差異性大。例如有的3維模型的上視點組得到的2維視圖和前視點組得到的2維視圖截然不同。這種差異性大的視圖放到同一個分類器中訓練是無法得到好的訓練效果的。因此,本文根據3維模型的不同方位確定了N個視點組,為每一個視點組分配一個分類器,目的是為達到好的訓練效果,進而提高分類準確率。
2.3.4 視圖分類器的訓練
本文首先用含有注意力塊的網絡訓練一個基線系統。該系統采用所有視點下的視圖訓練,然后利用訓練好的基線系統參數去初始化Q個視圖分類器的參數。因此,分類器的訓練分為兩步:(1)基線系統訓練。基線系統以所有2維視圖為輸入,并且采用訓練ImageNet得到的權值參數進行初始化。(2)分類器訓練。每個分類器與一個視點組相對應。每個分類器采用對應視點組下的視圖和其余視點組下抽樣選取的視圖的集合進行訓練。以Model-Net10為例,視圖分類器的訓練過程如圖6所示。
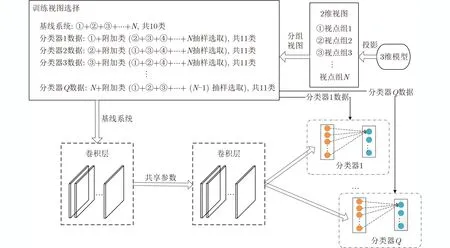
圖6 分類器的訓練過程
3 視圖選擇和分類策略
本文通過構建連通圖選擇視圖,目的在于選取少量的區分性視圖,提高3維模型分類的準確率。由于在現實中對稱的3維模型較多,在視圖選擇時,首先考慮選擇非對稱位置上的視圖,這樣可以有效減少冗余視圖。以正方體包裹3維模型為例,其連通圖如圖7所示。連通圖的頂點和邊與正方體的頂點和邊一一對應,一個面代表一個視點組。視圖選擇策略如下:(1)視點組選擇。首先,從某一頂點出發,選擇含有該頂點的所有面(視點組)。然后,從該頂點進行廣度優先搜索(Breadth First Search, BFS),每遍歷到一個頂點時,選擇過該頂點且未被選擇的面。直至選擇完指定數量的視點組。該方法優先選擇非對稱視點組,在模型對稱的情況下,可有效減少冗余視圖。(2)視圖選擇。每個視點組中隨機且不重復地選擇1張視圖。
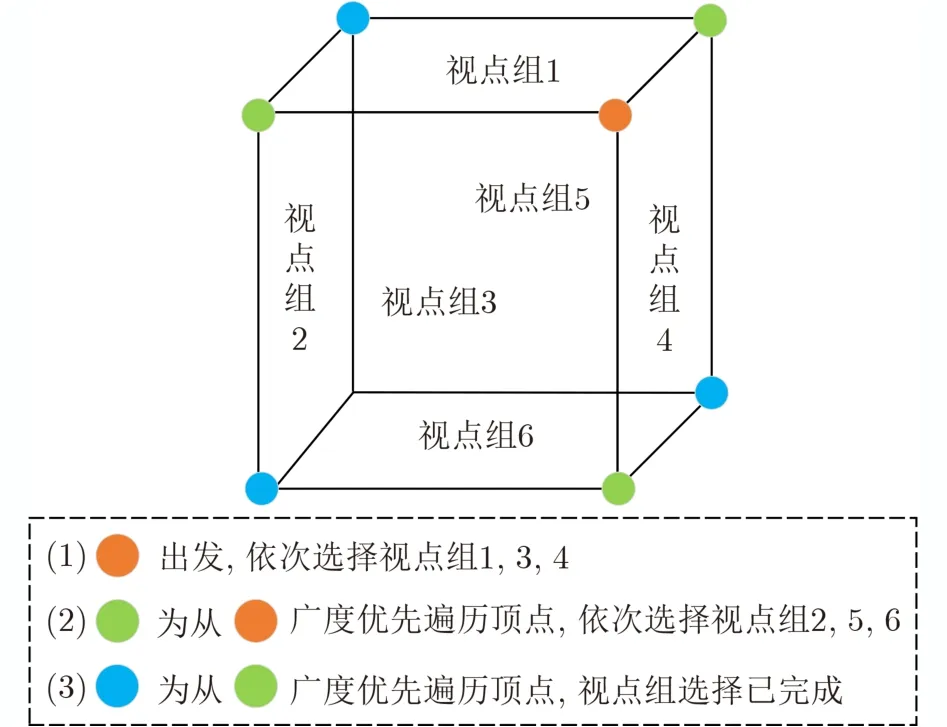
圖7 視點組選擇
分類策略:給定一個3維模型D的P張視圖,將選擇的視圖依次輸入到Q個視圖分類器中,如果所有分類器都將輸入視圖分類到附加類,表明分類信息不足,則在視圖所在的視點組中再選擇1張視圖用于分類。否則累計在類別i所獲分類器分類結果概率值Tva(ωi|D),ωi表示類別i(i=1, 2, ···, I,I為類別數,不包括附加類),Tva(ωi|D)計算過程為
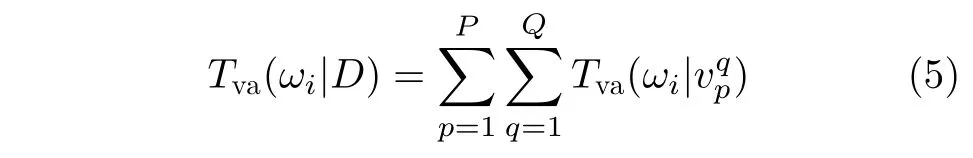
Tva(ωi|)表 示視圖vp在第q個分類器所得分類結果概率值(p=1, 2 , ···, P; q=1, 2, ···, Q),P和Q分別表示視圖與分類器的總數。最終分類結果為
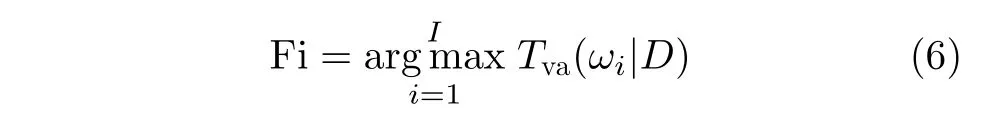
Fi表示3維模型D最終分類結果。通過不同視點組下的多分類器共同決斷,充分利用了3維模型的視點差異對類別預測。
4 實驗結果與分析
本文設置N個視點組,在確定視點組時,可以采用正多面體包裹3維模型,不僅可以兼顧到3維模型的各個角度,且同時可以達到均勻布點的效果。下面以正方體包裹3維模型,設置6個視點組為例,對提出的3維模型分類方法進行性能分析。
實驗基于PYTORCH框架,使用ResNet50和CBAM完成視圖特征提取。在Intel i5 8400 +GTX 1060的PC機上測試。選用的數據集為Model-Net10和ModelNet40[19]。ModelNet10共有4899個模型,分為10類。ModelNet40共有12311個模型,分為40類。ModelNet10和ModelNet40已經將訓練數據和測試數據分離,分別使用3991和9843個模型作為訓練集,908和2468個模型作為測試集。
4.1 ModelNet10數據集
以ModelNet10為例,數據集劃分如表1所示。

表1 ModelNet10數據集
(1)基線系統的視圖選擇。這里的基線系統既是傳統方法中的分類網絡,也是本文方法的特征提取網絡。在訓練時以3維模型為類別,不考慮視點差異。基線系統的最后一層采用Softmax做分類,其分類結果作為基線系統的識別率。基線系統采用ResNet50+CBAM網絡架構。首先使用ImageNet數據集進行預參數訓練,然后使用所有2維視圖進行視圖分類。按照2.2節的投影方式,每個3維模型產生5 4 張視圖。因此,基線系統的測試集有49032(908×54)張視圖,訓練集有215514(3991×54)張視圖。
(2)附加類的視圖選擇。若所有附加類視圖都參與訓練,則訓練集附加類共有143676(3991×9×4)張視圖,與前10類類均3592張視圖數量上差異過大。因此,對于每個模型在剩余的4個視點組下各取1張視圖,組成附加類。即訓練集附加類共有15964(3991×1×4)張視圖。從32688(908×9×4)張視圖中抽取3632(908×1×4)張視圖作為附加類測試數據。
(3)6個視圖分類器的視圖選擇。采用6個視點組下的視圖和附加類中的視圖分別訓練6個分類器。前10類數據的訓練集共有35919(3991×9)張視圖,測試集有8172(908×9)張視圖。則每個分類器的訓練集共有51883(35919+15964)張視圖,測試集有11804(8172+3632)張視圖。
4.2 視圖分類器評價
針對本文提出的3維模型分類網絡中是否含有CBAM以及數據集中是否含有附加類分別進行了實驗,如表2所示。在沒有添加CBAM模塊的基線系統中,視圖的分類準確率是87.28%。添加CBAM模塊后,視圖的分類準確率是88.42%。可見添加CBAM模塊可以有效提高分類準確率。表2展示了不同視點組下的分類準確率,其中高于基線系統的準確率在表中加粗表示。
(1)添加附加類。在沒有添加CBAM模塊時,相比于基線系統,不含附加類的視圖分類器的測試準確率有增有減。其中視點組1和視點組6對應的分類器的準確率較基線系統準確率稍有降低,分別為85.88%和83.92%。視點組2和視點組4對應的分類器準確率與基線系統的準確率基本一致。視點組3和視點組5對應的分類器準確率有所提升,分別是89.72%和89.03%。原因是不同視點下的視圖包含的信息不同,區分性不同,分類準確率也就不同。視點組3和視點組5對應3維模型的前面和后面,數據區分性大,因此分類準確率高。視點組1和視點組6對應3維模型的上面和下面,數據區分性小一些,因此分類準確率低。
含有附加類的分類器測試集的分類準確率除了視點組2和視點組4與基線系統的準確率基本相同,其他分類器的準確率均有所提升。尤其是視點組3對應的視圖分類器,分類準確率達到了89.74%。綜上所述,增加附加類后,對附加類的正確識別可以提升分類準確率。同時,增加附加類可以讓視圖選擇正確分類器的概率更大。可以預見,本文方法對于現實應用中3維模型表面比較復雜、各視點下的視圖差異較大的情況效果會更好。
(2)增加注意力機制。添加CBAM模塊后,在沒有增加附加類的情況下,只有視點組6下的分類器的準確率低于基線系統。增加附加類后,各視點組對應的分類器準確率均高于無附加類的分類器。其中,視點組1和視點組6提升最大,分別提升了2.34%和3.44%。以上結果表明,視圖經過深層卷積以及CBAM后,可以增強重要特征,抑制無用特征,從而達到有效區分差異較小的視圖的目的。并在結合附加類的優勢下,能進一步提高視圖的分類準確率。因此本文選擇表2含有CBAM和附加類的分類器對3維模型進行分類。
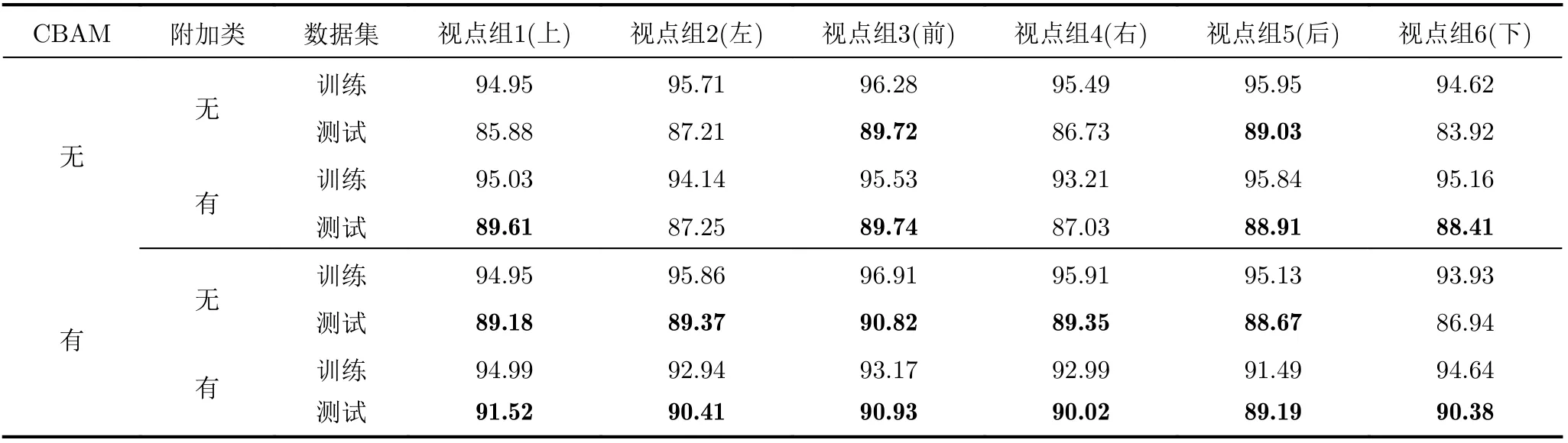
表2 視圖分類準確率(%)
4.3 分類結果
本文研究使用盡量少的視圖對3維模型分類,充分利用視點差異突出3維模型不同角度的區分性,提高3維模型的分類準確率。單張視圖僅是3維模型一個視點下的視圖,難以有效分類3維模型。因此本文最少選取2張視圖,并逐步增加視圖數進行實驗。并分別給出了本文方法選取2, 3和6張視圖時與其他基于視圖的3維模型分類方法的比較,結果如表3所示。
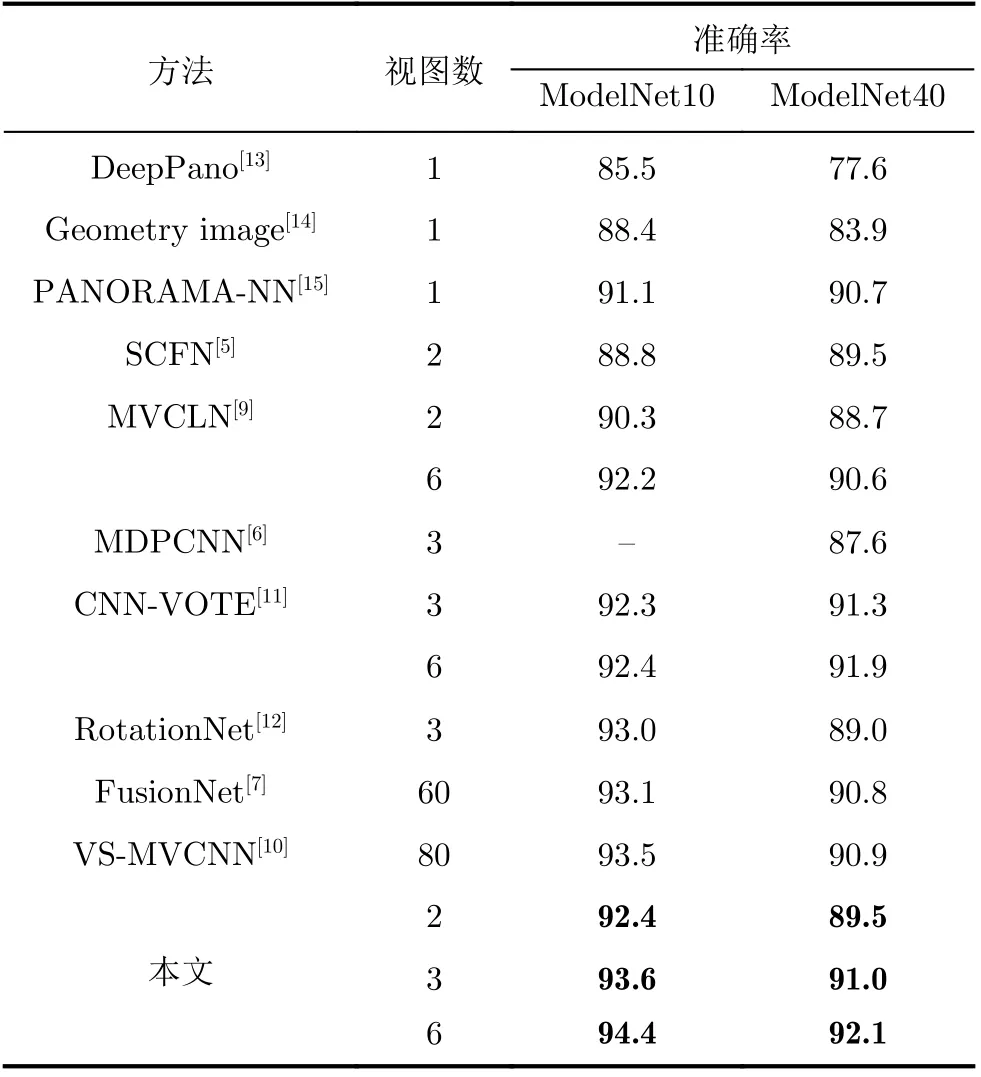
表3 分類準確率比較(%)
DeepPano, Geometry image和PANORAMANN使用的是一張全景視圖進行3維模型分類。全景圖是由多張視圖拼接得到的。當本文方法使用3張視圖時,在ModelNet10和ModelNet40數據集上均高于這3種方法。
在采用多張視圖的3維模型分類方法中,在ModelNet10數據集上,當本文方法采用2張視圖時,分類準確率是92.4%,遠高于SCFN和MVCLN使用2張視圖的方法。當本文方法采用3張視圖時,分類準確率高于CNN-VOTE和RotationNet使用相同數量視圖的方法。FusionNet和VS-MVCNN分別采用60和80張視圖,而本文方法僅采用3張視圖就高于他們的分類準確率。在ModelNet40數據集上,本文方法與其他方法使用相同數量的視圖時,僅比CNN-VOTE低了0.3%,其余均優于其他方法。當本文方法使用6張視圖時,分類準確率遠高于其他算法。
以ModelNet10為例,本文給出了3維模型分類結果的混淆矩陣,結果如圖8所示。從圖中可以看出,大部分模型可以被正確分類,特別是Bed,Chair, Monitor, Sofa和Toilet,分類準確率接近100%。原因在于:(1)充分利用了3維模型的視點差異;(2)這些類比較復雜,視圖含有的信息量大,區分性強,因此能達到高分類準確率。

圖8 基于3張視圖的3維模型分類混淆矩陣
分類不正確的3維模型出現在多個不同的類別中。這是因為這個形狀可能與很多模型的某個視點下的視圖有相似之處,因此分類錯誤時會被分到不同的類別中。同時,形狀相似的類別之間被錯分的可能性很大,如Table和Desk類,以及Night_stand和Dresser類。
4.4 視圖數對分類準確率的影響
圖9給出了隨著視圖數量增多,在ModelNet10和ModelNet40數據集上的分類準確率情況。從圖中可以看出,單張視圖分類準確率最低,當達到3張視圖時,準確率明顯提高。原因是單張視圖包含信息少,無法很好地表示3維模型。當增加視圖數量后,通過視點下的差異很好地增加了類間區分性,因此分類準確率有所提升。當達到6張視圖時,由于部分3維模型具有對稱性,因此產生了冗余視圖,所以準確率增幅較緩。當選擇多于6張視圖時,ModelNet40的準確率基本保持平穩,ModelNet10的準確率有所下降。

圖9 不同視圖數量的分類準確率
4.5 效率分析
本文僅使用3張視圖的準確率接近甚至超過了現有方法。本文方法雖然使用了6個分類器,但這些分類器共享卷積層參數,特征提取只用卷積網絡計算1次。注意力層與分類層雖然要計算6個結果,但CBAM是輕量級注意力塊,并且分類層只有1層,參數與運算量上只有少量增加。以本文3通道的256× 256視圖作為輸入,11個類別作為輸出為例,加入CBAM后參數量增加了2.23%,浮點運算量基本與ResNet50的5.38 GFlops相同。
4.5.1 視圖選擇分析
以ModelNet10為例,該數據集中共有49032張視圖,分別對各類中全部被分到附加類的視圖數量進行統計,如表4所示。從表4可以看出,視圖都被分到附加類的總和共計236張,只占全部視圖的0.5%,并且每個類別中占該類總數最多不超過1%。說明當1個視點組下的1張視圖被6個分類器均分為附加類時,重選1張視圖仍然被分到附加類的概率很低,這說明了本文分類方法的有效性。

表4 視圖被分到附加類的數量統計
4.5.2 訓練與分類效率分析
本文的6個分類器訓練各自的注意力層、全連接層和Softmax層,并增加附加類,目的是讓分類器提高不同視點組下視圖區分度,并提升分類準確率。而分類器的卷積層共享基線系統參數,目的是為了保證特征充分提取的同時提高網絡訓練和分類的效率。以ModelNet10為例,將本文方法(權重共享方式)和單獨訓練6個分類器(非權重共享方式)進行了對比。圖10對不同類別中每個3維模型分類平均耗時進行了統計。
從圖10可以看出,不同類別下的3維模型分類時,本文方法的平均耗時在0.7 s左右,而使用單獨訓練的6個分類器耗時大約在1.1 s。原因是共享卷積層權重使每個分類器對視圖特征僅需提取1次,而單獨訓練6個分類器需要提取6次,導致分類時間變長,分類效率大大降低。而本文方法在保證分類器準確率的同時對3維模型分類時間更短,效率更高。
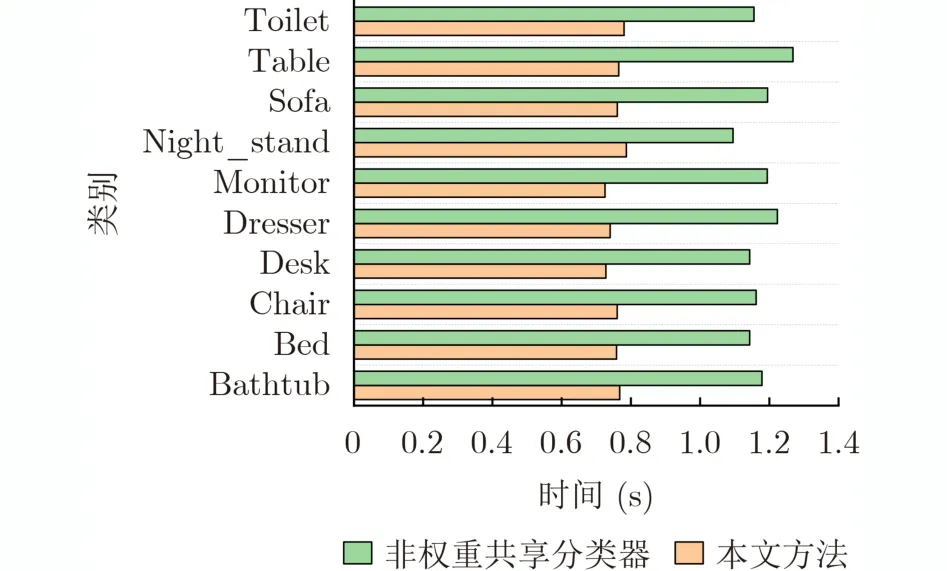
圖10 不同類別中3維模型分類平均耗時
5 結束語
隨著3維模型規模的不斷增加,3維模型的分類準確率和效率成為最大挑戰。本文提出了一種基于視點差異和多分類器的3維模型分類方法。在提高分類準確率方面,通過不同的視點組訓練相應的視圖分類器。在視圖特征提取階段,采用卷積神經網絡和注意力機制相結合的方式提取視圖的代表性特征。通過增加附加類,充分利用不同視點組下的3維模型的姿態信息,提高分類器的區分性。在提高分類效率方面,提出了視圖選擇策略,用少量視圖在保證分類準確率的前提下,有效提高了分類效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
